We developed two VQ algorithms, each tailored to a specific objective. The first algorithm is designed to minimize the MSE between the original and reconstructed vectors after quantization. The second algorithm is optimized for unbiased inner product estimation, addressing the bias inherent in MSE-optimal quantizers. These algorithms are detailed in the following subsections.
我们开发了两种向量量化(VQ)算法,每种算法都针对一个特定目标进行了专门设计:
第一种算法的目标是:最小化量化后原始向量与重建向量之间的均方误差(MSE)。
第二种算法则为无偏内积估计进行了优化,旨在解决均方误差最优量化器中固有的偏差问题。
这两种算法的详细说明见后续小节
Furthermore, in Section 3.3, we establish information-theoretic lower bounds on the best achievable distortion rates for any vector quantizer. This analysis demonstrates that TURBOQUANT achieve near-optimality, differing from the lower bound by only a small constant factor across all bit-widths.
此外,在第 3.3 节中,我们为任意向量量化器的最优可实现失真率,建立了信息论下界。分析结果表明,TurboQuant 实现了接近最优的性能:在所有位宽设置下,其性能与理论下界之间仅相差一个很小的常数因子。

composition 合成
decomposition 分解
randomizing ˈrændəmaɪzɪŋ
adj. 随机的,随机化
v. 形成不规则分布;使......随机化(randomize 的 ing 形式)

reduce rɪˈdjuːs v. 减少,降低;(烹调中)使变浓稠,收汁;<美>节食减肥;使沦为,使陷入
uniformly distributed 均匀分布
adhere ədˈhɪə(r) v. 黏附,附着;遵守,遵循(规定或协议);拥护,持有(观点或信仰)
midpoint ˈmɪdpɔɪnt n. 中点;正中央
continuous k-means problem: 连续 k-means 问题,在连续空间中寻找一组中心点,使得所有点到最近中心点的均方误差最小
Voronoi tessellation: Voronoi 划分,一种空间划分方法,每个区域由距离其中心点最近的所有点构成
centroids: 质心,即量化后的重建值或中心点
The optimal scalar quantization problem, given a known probability distribution, can be framed as a continuous k-means problem in dimension one. Specifically, we aim to partition the interval −1,1 into 2^b clusters/buckets. The optimal solution adheres to a Voronoi tessellation 42, meaning interval boundaries are the midpoints between consecutive centroids, when arranged in sorted order. Therefore, with ci's denoting the centroids in ascending order, we can formulate the scalar quantization as the following k-means optimization problem:
给定一个已知的概率分布,最优标量量化问题可以被表述为一维连续 k-means 问题。具体来说,我们的目标是将区间 −1,1 划分为 2^b 个簇 / 桶。其最优解遵循 Voronoi 划分,这意味着当按升序排列时,区间的边界是相邻两个质心的中点。因此,用 ci 表示按升序排列的质心,我们可以构建标量量化器为如下k-means优化问题:

需要注意的是,公式 (4) 中的 C(fX, b) 表示位宽为 b 时的最优均方误差成本函数。我们将通过对该值进行上界估计,来证明 TurboQuant 端到端均方误差的上界。公式 (4) 中的优化问题,可以通过迭代数值方法求解,达到任意所需的精度。我们会一次性求解多个实际常用位宽
b 下的最优解,并将结果存储起来,供后续量化器使用。





We are now ready to prove our main theorem for TURBOQUANTmse
至此,我们已经为证明 TURBOQUANT 的均方误差最优版本(TURBOQUANTmse)的主定理做好了准备




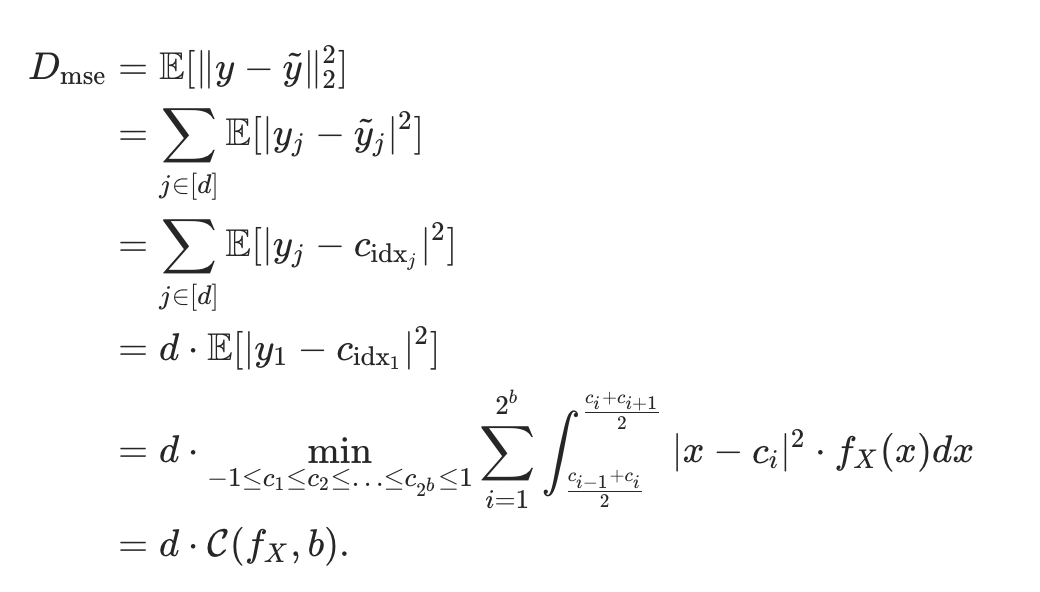




Entropy Encoding Codebook Pointers. 码书指针的熵编码
TURBOQUANT's efficiency can be further increased by applying entropy encoding to the indices that point to the closest codebook elements.
通过对指向最近码书元素的索引应用熵编码,可以进一步提升 TURBOQUANT 的效率
Entropy Encoding:熵编码,一种无损压缩技术,根据符号出现的概率分配不等长编码(高频符号用短码,低频符号用长码),从而降低平均码长
Codebook Pointers:码书指针,指量化后每个坐标对应的质心索引,用于在反量化时查找重建值


