内容参考于:图灵AI大模型全栈
LangChain框架把,向量数据库、调用大模型的过程给我集成好了,不需要像之前一样写实现
安装LangChain,它有多个版本最新的版本是3.0,这里使用1.0,3.0不兼容1.0
shell
pip install langchain==1.1.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install langchain-openai==1.1.0 -i https://pypi.tuna.tsinghua.edu.cn/simpleLangChain调用大模型,它调用大模型还是使用的OpenAI
python
# 导入第三方库:从python-dotenv包中导入load_dotenv函数
# 作用:专门用来读取项目根目录下的 .env 隐藏配置文件
from dotenv import load_dotenv
# 导入第三方库:从langchain_openai包中导入ChatOpenAI类
# 作用:LangChain封装的调用大模型的核心工具,兼容OpenAI格式接口(火山引擎也用这个格式)
from langchain_openai import ChatOpenAI
# 导入Python内置模块os
# 作用:用来读取系统/环境变量中的配置(比如密钥、地址)
import os
# ===================== 核心配置加载 =====================
# 函数作用:加载项目根目录下的 .env 文件
# 传值:无入参,直接调用
# 值来源:你项目文件夹里必须新建一个 .env 文件,里面写 huoshan=你的火山引擎API密钥
load_dotenv()
# ===================== 初始化大模型对象 =====================
# 创建llm变量:大模型的调用实例,后续所有提问都用这个对象
# 入参:都是ChatOpenAI类的初始化参数,必须按要求传值
llm = ChatOpenAI(
# 参数1:api_key
# 入参类型:字符串(str)
# 可以传什么:火山引擎平台申请的API访问密钥
# 传值来源:从 .env 文件中读取 key 为 huoshan 的配置(严格保留huoshan,不能改)
api_key=os.getenv("huoshan"),
# 参数2:base_url
# 入参类型:字符串(str)
# 可以传什么:大模型服务的接口地址
# 传值来源:火山引擎官方固定接口地址(固定写死,不能修改)
base_url="https://ark.cn-beijing.volces.com/api/v3",
# 参数3:model_name
# 入参类型:字符串(str)
# 可以传什么:火山引擎平台上的模型名称
# 传值来源:火山引擎后台提供的模型ID(当前用的是glm-4-7-251222)
model_name="glm-4-7-251222",
# 参数4:streaming
# 入参类型:布尔值(bool),只能传 True 或 False
# 可以传什么:True=开启流式输出,False=关闭流式输出
# 传值来源:自定义设置,True会逐字返回结果,False一次性返回全部结果
streaming=True,
# 参数5:timeout
# 入参类型:数字(int/float),单位:秒
# 可以传什么:任意正整数(比如30、60、120)
# 传值来源:自定义设置,60代表请求超时时间为60秒,超过没响应会报错
timeout=60
)
# ===================== 流式调用大模型 =====================
# 方法作用:llm.stream() 是流式调用方法,核心优势:不会卡住程序,逐字返回结果
# 入参:必须传 列表(list) 格式,列表里是 字典(dict)
# 字典固定格式:{"role": "角色", "content": "提问内容"}
# 字典参数说明:
# role:只能传 "user"(用户)、"assistant"(助手)、"system"(系统提示)
# content:传你要问大模型的问题
# 传值来源:content 是你自定义的问题(这里写的是:什么是大模型)
for chunk in llm.stream([{"role": "user", "content": "什么是大模型"}]):
# 循环作用:遍历流式返回的每一段结果(逐字/逐词)
# chunk.content:每一段结果的文本内容
# end="":打印不换行(保证文字连贯输出)
# flush=True:实时刷新控制台(立刻显示文字,不缓存)
print(chunk.content, end="", flush=True)向量存储,这里使用faiss数据存储向量数据,向量模型依旧使用本地的,注意向量数据库需要分片,向量数据库可能一次只能处理10条数据,我们有100条,所以就要分片10次传递,下图Faiss数据的文件
python
import os
import warnings
# 作用:屏蔽langchain_community的弃用警告,不影响功能
# 入参:action=忽略, category=警告类型, module=指定模块
# 可传:固定参数,无需修改
# 来源:代码固定写法
warnings.filterwarnings("ignore", category=DeprecationWarning, module="langchain_community")
from langchain_community.document_loaders import WebBaseLoader
import bs4
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_community.vectorstores import FAISS
# 作用:设置浏览器标识,防止网站拒绝爬虫请求
# 入参类型:字符串
# 可传:浏览器UA标识
# 来源:固定通用Chrome标识
os.environ["USER_AGENT"] = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36"
# 作用:本地向量模型的文件路径
# 入参类型:字符串
# 可传:本地模型文件夹路径
# 来源:你电脑上的模型位置
LOCAL_EMBEDDING_MODEL_PATH = r"E:\AiModel\Local_model\BAAI\bge-large-zh-v1___5"
# 作用:创建网页加载器,读取政府网文档
# 入参1:网页链接,字符串
# 可传:任意政策文档url
# 来源:中国政府网官方链接
# 入参2:bs4解析规则,只提取正文区域
# 可传:标签id,固定UCAP-CONTENT
# 来源:政府网正文固定标识
loader = WebBaseLoader(
'https://www.gov.cn/zhengce/content/202510/content_7043916.htm',
bs_kwargs=dict(parse_only=bs4.SoupStrainer(id='UCAP-CONTENT'))
)
# 作用:执行网页加载,获取文档内容
# 入参:无
# 来源:loader对象执行方法
docs = loader.load()
# 作用:创建文本分块工具
# chunk_size:单块最大字符数,int,可传200-500,来源自定义设置
# chunk_overlap:分块重叠字符数,int,可传30-80,来源自定义设置
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=300,
chunk_overlap=50,
)
# 作用:对文档进行分块切割
# 入参:加载好的文档
# 来源:上一步的docs变量
documents = text_splitter.split_documents(docs)
# 作用:打印总分块数量
print(f"总文档数量: {len(documents)}")
# 作用:初始化本地向量模型
# model_name:模型路径,str,可传本地模型路径,来源上方变量
# model_kwargs:运行设备,dict,可传cpu/cuda,来源固定cpu(无显卡)
# encode_kwargs:归一化+批次,dict,固定参数,来源模型要求
embeddings = HuggingFaceEmbeddings(
model_name=LOCAL_EMBEDDING_MODEL_PATH,
model_kwargs={"device": "cpu"},
encode_kwargs={"normalize_embeddings": True, "batch_size": 16}
)
# 作用:初始化向量库变量
vector = None
# 作用:每批处理的文档数量
# 入参:int,可传5-20,来源自定义(根据内存调整)
batch_size = 10
# 作用:循环分批处理文档
# 入参:从0到总文档数,步长为批次大小
# 来源:documents总长度+分批数量
for i in range(0, len(documents), batch_size):
# 作用:截取当前批次文档
batch_docs = documents[i:i + batch_size]
print(f'第{i // batch_size + 1}批次 文档数量: {len(batch_docs)}')
# 作用:第一批创建向量库
if i == 0:
vector = FAISS.from_documents(batch_docs, embeddings)
# 作用:后续批次合并到向量库
else:
new_vector = FAISS.from_documents(batch_docs, embeddings)
vector.merge_from(new_vector)
# 作用:将向量库保存到本地文件夹
# 入参:文件夹名称,str,可传自定义名称,来源自定义
vector.save_local("faiss_index")
print("✅ FAISS 索引已保存到 faiss_index 文件夹")调用在线的向量模型,这里是阿里百炼平台,它需要安装下发的三个库
shell
pip install faiss-cpu
pip install langchain_community
pip install dashscope
python
# 导入Python内置模块:用于读取环境变量、文件操作
import os
# 导入网页加载器:用于爬取网页文本内容
# 来源:langchain_community 社区库
from langchain_community.document_loaders import WebBaseLoader
# 导入网页解析库:用于过滤网页无关内容,只提取正文
# 来源:第三方库 beautifulsoup4
import bs4
# 导入文本分块工具:将长文本切割成小片段
# 来源:langchain_text_splitters 官方库
from langchain_text_splitters import RecursiveCharacterTextSplitter
# 导入阿里通义嵌入模型:将文本转为向量
# 来源:langchain_community 社区库
from langchain_community.embeddings import DashScopeEmbeddings
# 导入向量数据库:存储和检索向量
# 来源:langchain_community 社区库
from langchain_community.vectorstores import FAISS
# 导入环境变量工具:读取.env文件中的密钥
# 来源:第三方库 python-dotenv
from dotenv import load_dotenv
# 作用:加载项目根目录的.env文件
# 入参:无
# 可传:无
# 值来源:固定调用
load_dotenv()
# 作用:创建网页加载器,抓取政府网文档
# 入参1:网页URL
# 可传:任意网页链接
# 值来源:中国政府网官方政策链接
# 入参2:bs4解析规则,只提取id为UCAP-CONTENT的正文区域
# 可传:HTML标签id
# 值来源:政府网正文固定标识
loader = WebBaseLoader(
'https://www.gov.cn/zhengce/content/202510/content_7043916.htm',
bs_kwargs=dict(parse_only=bs4.SoupStrainer(id='UCAP-CONTENT'))
)
# 作用:执行网页加载,获取文档内容
# 入参:无
# 值来源:loader对象方法
docs = loader.load()
# 作用:创建文本分块工具
# chunk_size:单块最大字符数,int类型
# 可传:200-500
# 值来源:自定义设置
# chunk_overlap:分块重叠字符数,int类型
# 可传:30-80
# 值来源:自定义设置
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=300,
chunk_overlap=50,
)
# 作用:对文档进行分块
# 入参:网页加载的原始文档
# 值来源:上一步的docs变量
documents = text_splitter.split_documents(docs)
# 作用:打印总分块数量
print(f"总文档数量: {len(documents)}")
# 作用:初始化阿里通义在线嵌入模型,将文本转换为向量
# 来源:langchain_community.embeddings 模块
# dashscope_api_key:阿里API密钥,字符串类型
# 可传:阿里云百炼平台申请的API Key
# 值来源:.env环境变量文件中的 DASHSCOPE_API_KEY 配置项
# model:嵌入模型名称,字符串类型
# 可传:text-embedding-v4、text-embedding-v3、text-embedding-v2
# 值来源:阿里云百炼官方指定的嵌入模型版本
embeddings = DashScopeEmbeddings(
dashscope_api_key=os.getenv("DASHSCOPE_API_KEY"),
model="text-embedding-v4",
)
# 作用:初始化向量库变量
vector = None
# 作用:每批处理的文档数量
# 入参:int类型
# 可传:5-20
# 值来源:自定义(根据电脑内存调整)
batch_size = 10
# 作用:循环分批处理文档,避免内存溢出
# 入参:从0开始,步长为批次大小
# 值来源:文档总数量+分批大小
for i in range(0, len(documents), batch_size):
# 作用:截取当前批次的文档
batch_docs = documents[i:i + batch_size]
print(f'第{i // batch_size + 1}批次 文档数量: {len(batch_docs)}')
# 作用:第一批文档,直接创建向量库
if i == 0:
vector = FAISS.from_documents(batch_docs, embeddings)
# 作用:后续文档,合并到已有的向量库中
else:
new_vector = FAISS.from_documents(batch_docs, embeddings)
vector.merge_from(new_vector)
# 作用:将向量库保存到本地文件夹
# 入参:文件夹名称
# 可传:自定义英文名称
# 值来源:自定义设置
vector.save_local("faiss_index")
print("FAISS 索引已保存到 faiss_index 文件夹")查询Faiss数据库中的向量
python
import os
import warnings
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_community.vectorstores import FAISS
warnings.filterwarnings("ignore", category=DeprecationWarning, module="langchain_community")
LOCAL_EMBEDDING_MODEL_PATH = r"E:\AiModel\Local_model\BAAI\bge-large-zh-v1___5"
# 必须使用与构建索引完全相同的嵌入模型参数
embeddings = HuggingFaceEmbeddings(
model_name=LOCAL_EMBEDDING_MODEL_PATH,
model_kwargs={"device": "cpu"},
encode_kwargs={"normalize_embeddings": True}
)
# 加载本地索引
vector_store = FAISS.load_local(
"faiss_index",
embeddings,
allow_dangerous_deserialization=True # 必须添加此参数
)
# 测试检索
query = "密云水库水源保护条例什么时候开始施行?"
results = vector_store.similarity_search(query, k=2)
for i, doc in enumerate(results, 1):
print(f"\n=== 第{i}条结果 ===")
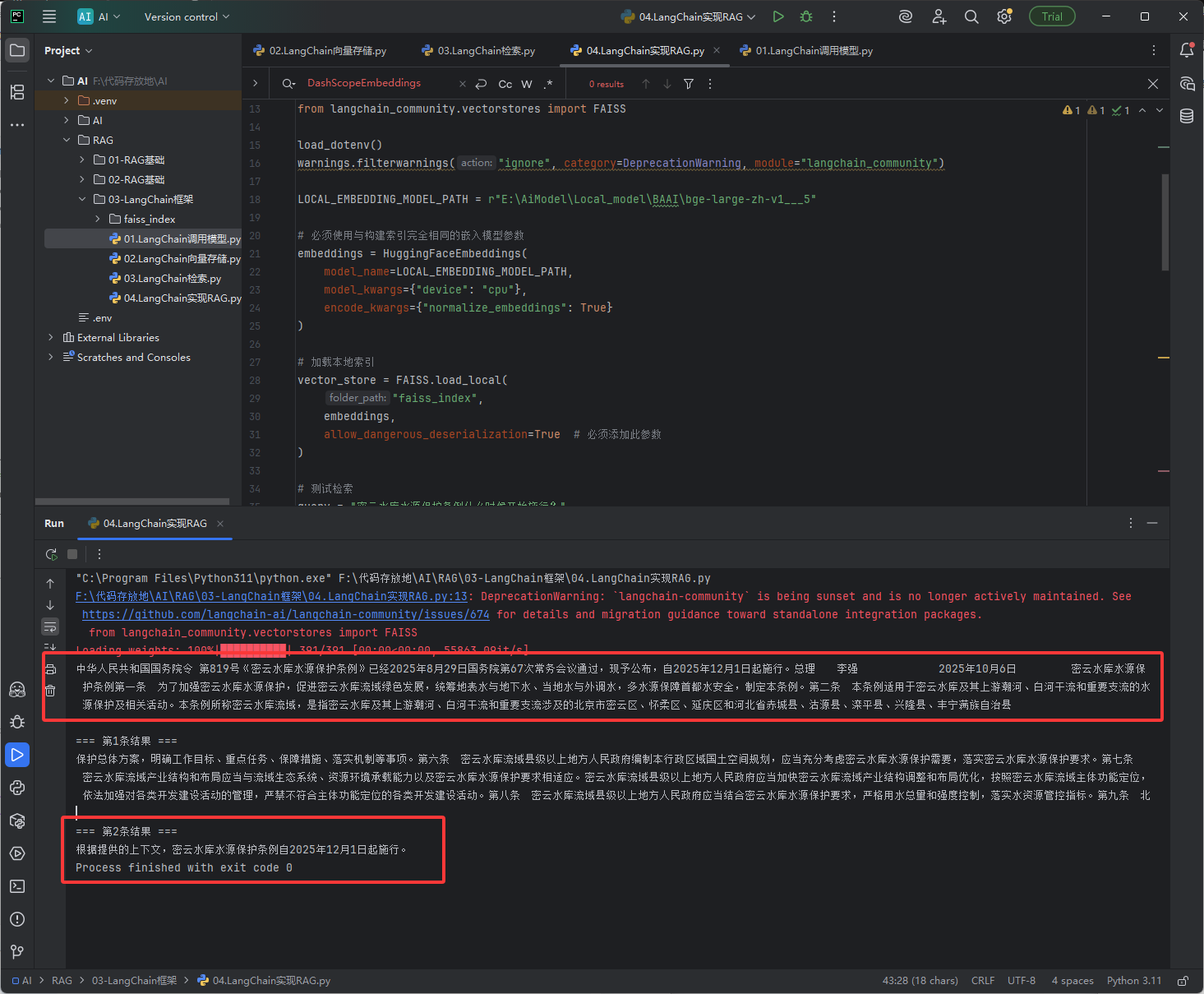
print(doc.page_content)LangChain实现RAG
效果图:
python# 导入Python内置模块:操作系统交互,读取环境变量 # 来源:Python官方内置库 import os # 0.3版本能进行导入 替换导入方式 # 原导入方式(已注释):langchain高版本弃用,无法使用 # from langchain.chains.combine_documents import create_stuff_documents_chain # langchain_classic 提供向下兼容模块 # 作用:导入文档组合链,将检索的文档拼接后传入大模型 # 来源:langchain_classic 兼容库 from langchain_classic.chains.combine_documents import create_stuff_documents_chain # 作用:导入对话提示词模板,构建自定义提问规则 # 来源:langchain_core 核心库 from langchain_core.prompts import ChatPromptTemplate # 作用:导入大模型调用类,对接火山引擎GLM-4 # 来源:langchain_openai 官方库 from langchain_openai import ChatOpenAI # 作用:导入检索链,整合检索功能+问答功能 # 来源:langchain_classic 兼容库 from langchain_classic.chains import create_retrieval_chain # 作用:导入环境变量加载工具,读取.env密钥 # 来源:第三方库 python-dotenv from dotenv import load_dotenv # 作用:导入警告模块,屏蔽无用弃用警告 # 来源:Python官方内置库 import warnings # 作用:导入本地嵌入模型,加载BGE向量模型 # 来源:langchain_huggingface 官方库 from langchain_huggingface import HuggingFaceEmbeddings # 作用:导入FAISS向量库,加载本地索引 # 来源:langchain_community 社区库 from langchain_community.vectorstores import FAISS # 作用:加载项目根目录下的.env环境变量文件 # 入参:无 # 可传值:无 # 值来源:固定调用 load_dotenv() # 作用:忽略langchain_community模块的弃用警告,不影响运行 # 入参:固定参数 # 可传值:无 # 值来源:代码固定写法 warnings.filterwarnings("ignore", category=DeprecationWarning, module="langchain_community") # 作用:本地BGE嵌入模型的绝对路径 # 入参类型:字符串 # 可传值:本地模型文件夹路径 # 值来源:你电脑的模型存储位置 LOCAL_EMBEDDING_MODEL_PATH = r"E:\AiModel\Local_model\BAAI\bge-large-zh-v1___5" # 必须使用与构建索引完全相同的嵌入模型参数 # 作用:初始化嵌入模型(必须和建库时一致) # model_name:模型路径,字符串 # 可传值:本地模型路径 # 值来源:上方变量 # model_kwargs:运行设备,字典 # 可传值:cpu/cuda # 值来源:无显卡固定用cpu # encode_kwargs:向量归一化,字典 # 可传值:True/False(BGE必须True) # 值来源:模型官方要求 embeddings = HuggingFaceEmbeddings( model_name=LOCAL_EMBEDDING_MODEL_PATH, model_kwargs={"device": "cpu"}, encode_kwargs={"normalize_embeddings": True} ) # 作用:加载本地保存的FAISS向量索引 # 入参1:索引文件夹名,字符串 # 可传值:建库时的文件夹名 # 值来源:固定faiss_index # 入参2:嵌入模型对象 # 可传值:初始化好的embeddings # 值来源:上方变量 # 入参3:安全参数,布尔值 # 可传值:True(必传) # 值来源:FAISS强制要求 vector_store = FAISS.load_local( "faiss_index", embeddings, allow_dangerous_deserialization=True # 必须添加此参数 ) # 测试检索 # 作用:定义测试检索的问题 # 入参类型:字符串 # 可传值:任意自定义问题 # 值来源:自定义输入 query = "密云水库水源保护条例什么时候开始施行?" # 作用:执行相似度检索,返回最相关的文档 # 入参1:检索问题 # 入参2:k=返回结果数量,整数 # 可传值:1-5 # 值来源:自定义设置 results = vector_store.similarity_search(query, k=2) # 作用:循环遍历打印检索结果 for i, doc in enumerate(results, 1): print(doc.page_content) print(f"\n=== 第{i}条结果 ===") # 作用:创建提示词模板,约束大模型仅根据上下文回答 # 入参:模板字符串(固定包含context上下文、input问题) # 可传值:自定义提示词 # 值来源:自定义编写 prompt = ChatPromptTemplate.from_template("""仅根据提供的上下文回答以下问题: <context> {context} </context> 问题: {input}""") # 创建 LLM 连接(继续使用阿里云 qwen-plus) # 作用:初始化火山引擎大模型 # api_key:API密钥,字符串 # 可传值:火山引擎AK # 值来源:.env文件huoshan变量 # base_url:接口地址,字符串 # 可传值:官方固定地址 # 值来源:火山引擎官方 # model_name:模型名,字符串 # 可传值:模型ID # 值来源:官方提供 # streaming:流式输出,布尔值 # 可传值:True/False # 值来源:自定义开启 # timeout:超时时间,整数 # 可传值:30/60/120 # 值来源:自定义设置 llm = ChatOpenAI( api_key=os.getenv("huoshan"), # 严格保留:huoshan 不变 base_url="https://ark.cn-beijing.volces.com/api/v3", model_name="glm-4-7-251222", streaming=True, timeout=60 ) # 创建文档组合链 # langchain_core\prompts\chat.py可以看到提示词拼接 # format_messages 方法拼接提示词 # 作用:创建文档组合链,将上下文+问题传给大模型 # 入参:大模型对象 + 提示词模板 # 可传值:上方定义的llm、prompt # 值来源:自定义对象 document_chain = create_stuff_documents_chain(llm, prompt) # 作用:将向量库转为检索器 # search_kwargs={"k": 3}:返回3条最相关结果 # 可传值:k=1-5 # 值来源:自定义设置 retriever = vector_store.as_retriever(search_kwargs={"k": 3}) # 限制检索 3 个文档 # 创建检索链 # 在langchain_community\vectorstores\faiss.py 可以查看向量检索的实现 # similarity_search_with_score_by_vector 是检索的方法 return docs[:k] # 作用:创建检索链,整合检索+问答 # 入参:检索器 + 文档链 # 可传值:上方定义的retriever、document_chain # 值来源:自定义对象 retrieval_chain = create_retrieval_chain(retriever, document_chain) # 调用检索链并获取回答 # openai\resources\chat\completions\completions.py # create方法中 self._post() 调用模型请求的api # 【注释代码保留】:非流式调用方式,已注释,改用下方流式输出 # response = retrieval_chain.invoke({"input": "密云水库水源保护条例什么时候执行"}) # print("\n回答:", response["answer"]) # 作用:流式调用检索链,逐字实时打印答案 # 入参:用户问题,字典格式 # 可传值:任意自定义问题 # 值来源:自定义输入 # 判断answer字段:只输出大模型回答内容 for chunk in retrieval_chain.stream({"input": "密云水库水源保护条例什么时候执行"}): if "answer" in chunk: # 只处理LLM流式输出部分 print(chunk["answer"], end="", flush=True)