聚合
对比于传统的数据库如mysql ,要使用聚合的时候,全量算一遍这种思路。
clickhouse 的解决方案更加智慧。
它用另外一张表去存储聚合结果,然后通过数据变动实时(准实时)写入结果表,来达到聚合的目的。
如果对实时性要求不高的场景是非常适合的
先看下例子:
建表
先建立明细表
sql
create table learning.money_detail(
id UInt8,
user_time Date,
money UInt64
) engine = MergeTree()
partition by toDate(user_time)
order by id;插入数据
sql
insert into learning.money_detail values(1,'2026-05-04',10);
insert into learning.money_detail values(1,'2026-05-04',10);
insert into learning.money_detail values(2,'2026-05-05',15);
insert into learning.money_detail values(2,'2026-05-05',35);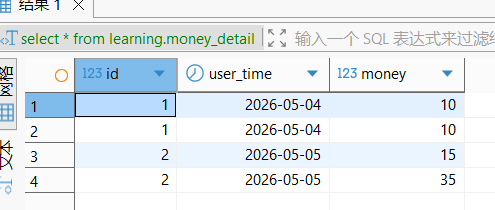
聚合表
sql
create table learning.money_agg(
id UInt8,
user_time Date,
cnt AggregateFunction(count,UInt64),
total_money AggregateFunction(sum,UInt64)
) engine = AggregatingMergeTree()
partition by toDate(user_time)
order by id;执行同步sql
sql
insert into learning.money_agg
select id,user_time,countState(id),
sumState(money)
from learning.money_detail
group by id,user_time查询
sql
select id,user_time,countMerge(cnt),sumMerge(total_money)
from learning.money_agg
group by id,user_time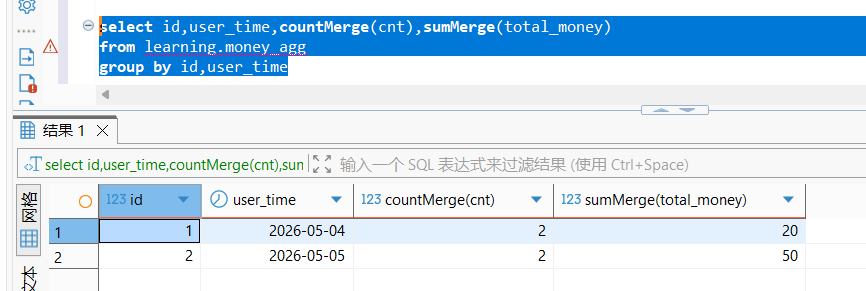
注意
insert 聚合表的时候一定要 countState,sumState + group by
查询聚合表的时候一定是 countMerge,sumMerge+ group by
物化视图
刚才的操作是人工同步的,真正生产上不可能每次源表写入都sql同步一次
正确的做法是写一个物化视图
sql
create materialized view m_v_daily_agg to learning.money_agg as
select id,user_time,countState(id) as cnt,
sumState(money) as total_money
from learning.money_detail
group by id,user_time其中 materialized view m_v_daily_agg to learning.money_agg 是指定目标表,
select id,user_time,countState(id) as cnt,
sumState(money) as total_money
from learning.money_detail
group by id,user_time
就是写字段映射
执行物化视图后再插入源表数据就可以同步聚合表了 。
注意
物化视图创建前的数据不会被同步,如果需要同步需要
对比
对比于这段聚合sql
sql
select id,user_time,count(money) as cnt,avg(money) as total_money
from learning.money_detail group by id,user_time ;它也能查出聚合,但是是它是传统的查法,每次都把全量数据做了一次聚合,遇到数据量大的场景,分钟级响应甚至卡死
然而clickhouse的 AggregatingMergeTree 做法更聪明,它在源数据每次插入的时候都做了一次增量聚合计算。计算量小,查询的时候只要去聚合表中查询结果就好,完全绕过了大数据量带来的相应慢问题。
附上 AggregatingMergeTree 的时序图
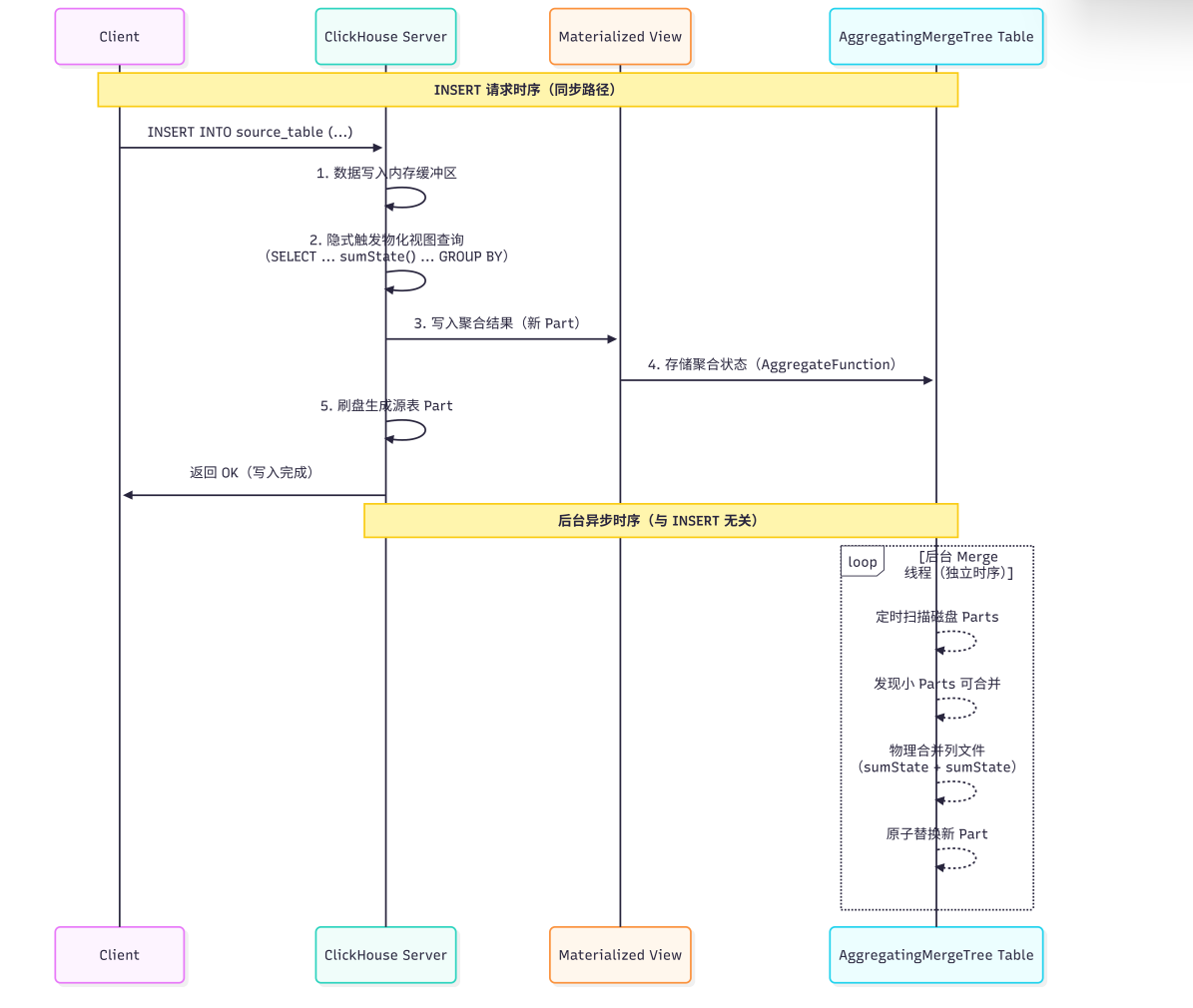
AggregatingMergeTree 的问题
它解决了大数据的聚合慢问题,但是它不是实时的,它的刷盘会有一定的延时,在那种要求实时响应的场景会出现数据不准的情况(还未刷盘)
所以并不适合精确要求高的场景
而且相比之前的源表操作,写入的整体压力肯定会增加
SummingMergeTree
如果你的业务逻辑只有求和(sum)和计数(count),不需要去重(uniq)或其他复杂聚合,用它更简单高效