文章目录
前言
我们需要搭建一个大型的ClickHouse集群,用来承接多个完全不同Traffic规模的Kafka表的数据落地。
在集群的规划和设计过程中,我们预想了两种完全不同的集群架构: 横向平铺式以及纵向切分式。
本文详细分析了我们在衡量两种不同架构时候的考虑因素,以及,我们最终形成解决方案时做的必要的补充测试和验证,基于我们做的测试和验证,当每一个细节都完全清楚了,我们做出了最终决定。
同时,我们还考虑到,基于我们集群架构的方案选择,这种集群以后的扩容、缩容、机器的修复流程是否都有合理方案?
本文就详细讲解了整个集群的设计考量,多方案的准备以及最终方案的选择,测试验证的过程,以及可运维的推论。
需求描述
我们需要构建一个ClickHouse集群,用来持久化来自Kafka的Realtime数据。目前,我们的机器资源是固定的:
- 集群规模 :
66 Nodes - 单机规格 :
64 Core/700 GB Memory/900 GB NVMe SSD - 资源合计数 :
4,224 CoresCPU /45.1 TBRAM /58 TB高速存储
可以看到,作为一个ClickHouse集群,整个集群机器数量偏多,但是集群的CPU较小,内存较大,磁盘较
小。
我们的ClickHouse的数据冗余是2, 即采用Active-Passive架构,每一个Shard两台Replica机器,一台Replica机器只负责消费数据,另外一台Passive Replica负责从Active Replica上fetch part,然后承接查询。
其实ClickHouse本身的Shard是没有Active/Passive架构,只不过我们为了Kafka Ingestion这种场景的管理方便和拓扑简单,我们让Ingestion只发生在每一个Shard的一台机器上,并且将这台有Ingestion任务的机器定义为Active,没有Ingestion的机器定义为Passive机器。
整个ClickHouse集群通过DNS + H5 Proxy来暴露唯一的查询接口,用户的Initial Query通过DNS + H5 Proxy可以打到任何一台Passive机器上(确切将是任何一台Passive):
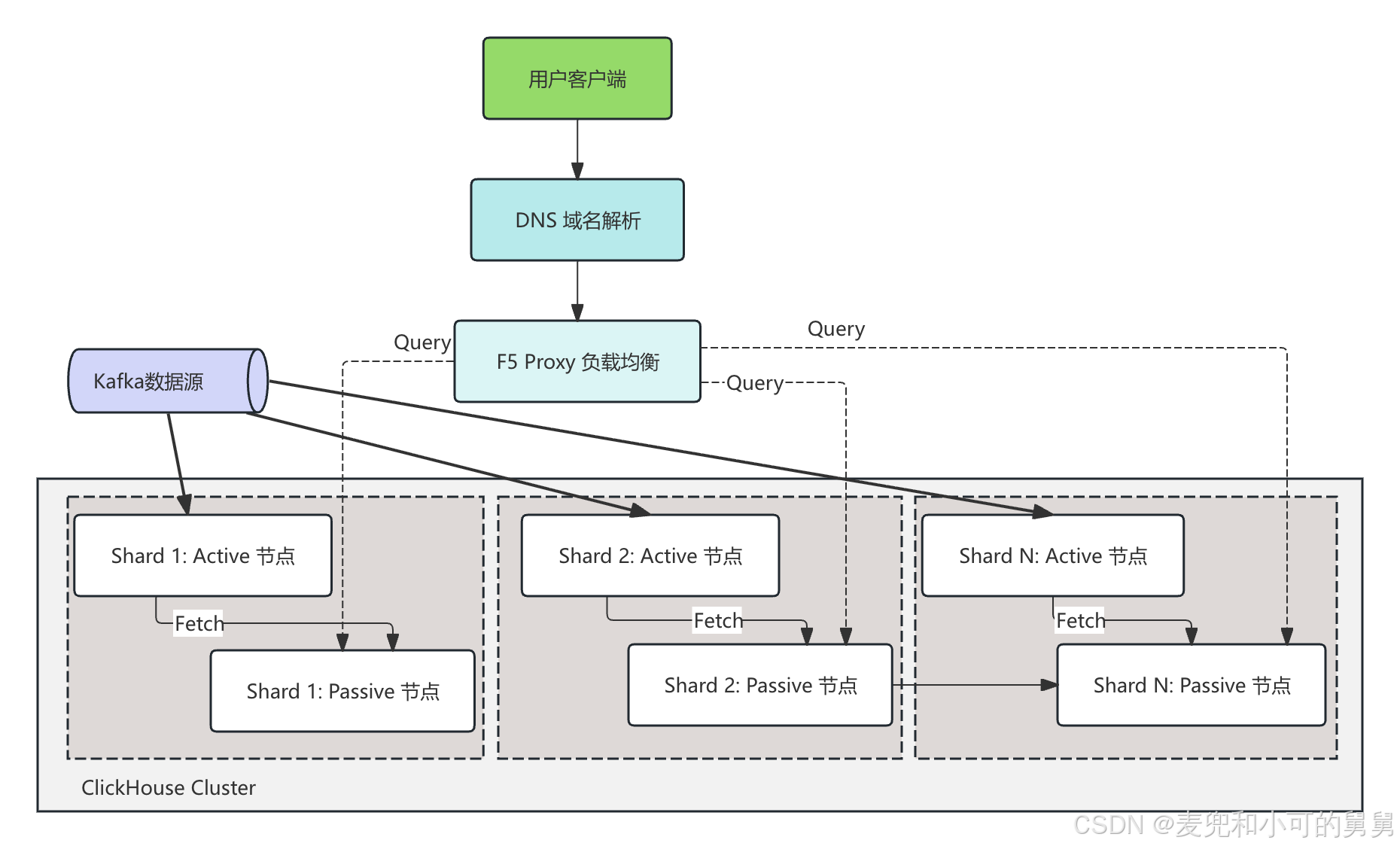
从上图中可以看到:
- 流量分层与查询路由层(从上至下)
- 接入与负载均衡:用户的客户端请求通过 DNS 域名解析 路由到 F5 Proxy 负载均衡器。
- 计算与查询分发:F5 负责将查询流量(Query)均匀且无状态地分发给后端的各个 Shard。查询不需要感知具体的物理分片,由接收到流量的 ClickHouse 节点(作为 Initiator)利用分布式表向全集群(Shard 1 到 Shard N)分发子查询并聚合结果。
- 存储与数据摄入层(计算/存储分层解耦)
图中的大灰色方框代表整个 ClickHouse Cluster,其核心采用了 Active-Passive(单侧消费、双侧存储) 的精巧高可用设计,具体分为:- Kafka 数据源 -> Active 节点(数据摄入线):
- 每个 Shard 的 Active 节点 负责从 Kafka 消息队列中拉取数据(本地直写 Local Insert)。
- 只有 Active 节点部署了
Kafka Table -> Materialized View(物化视图),承担了全量的数据摄入计算压力。
- Active -> Passive 节点(高可用同步线):
- 每一个 Shard 内部包含 2 个 Replica。Passive Replica 自身不触碰 Kafka、不参与流式消费,它本地的数据完全是通过
ReplicatedMergeTree的底层日志复制机制,从 Active 节点 Fetch(拉取)过来的。这种设计彻底避免了双侧同时消费时复杂的 ZooKeeper 抢锁去重开销。
- 每一个 Shard 内部包含 2 个 Replica。Passive Replica 自身不触碰 Kafka、不参与流式消费,它本地的数据完全是通过
- Kafka 数据源 -> Active 节点(数据摄入线):
我们的数据从Kafka表最终落地到ClickHouse的整个过程是 Kafka Table -> Materialized View -> ReplicatedMergeTree Local Table,查询则是通过Distributed Table映射到对应的 ReplicatedMergeTree Local Table。 这里其实暗含了一个关键架构特征,它将影响我们的整个架构设计和考量: 数据的写入是无状态的rand分发,数据不跟Kafka的TopicPartition绑定(根据user_id做严格的shard路由),Kafka的TopicPartition也不跟ClickHouse的Shard绑定(比如,规定每一个Shard必须消费那些TopicPartition)。这种自由和灵活,这让我们的扩容、缩容可以完全基于Kafka的自动Rebalance,因此变得及其方便。
为了评估我们当前的机器资源是否足够支撑我们实时的数据流量,我们对ClickHouse中Consumer的消费能力进行了测试和评估。
| Kafka Topic 名称 | 监控面板显示流量 | 换算实际流量 (messages/s) |
|---|---|---|
| realtime-ss-vendor-a | 174 K | 174,000 |
| realtime-ss-main | 141 K | 141,000 |
| realtime-ss-alpha | 64.9 K | 64,900 |
| realtime-ss-beta | 41.2 K | 41,200 |
| realtime-ss-gamma-d2c | 31.2 K | 31,200 |
| realtime-ss-omega | 30.8 K | 30,800 |
| realtime-ad-ss | 26.2 K | 26,200 |
| realtime-ss-epsilon | 24.3 K | 24,300 |
| realtime-ad-ss-vendor-a | 17.8 K | 17,800 |
| realtime-ss-gamma-intl | 11.3 K | 11,300 |
| realtime-ad-ss-gamma-d2c | 9.03 K | 9,030 |
| realtime-ss-zeta | 7.95 K | 7,950 |
| realtime-ss-theta | 7.41 K | 7,410 |
| realtime-ad-ss-beta | 6.33 K | 6,330 |
| realtime-ss-sigma | 5.54 K | 5,540 |
| realtime-ss-iota | 4.01 K | 4,010 |
| realtime-ad-ss-theta | 3.35 K | 3,350 |
| realtime-ad-ss-zeta | 2.90 K | 2,900 |
| realtime-ad-ss-omega | 1.66 K | 1,660 |
| realtime-ss-kappa | 1.34 K | 1,340 |
| realtime-ad-ss-epsilon | 721 | 721 |
| realtime-ss-delta | 519 | 519 |
| realtime-ad-ss-gamma-intl | 408 | 408 |
| __consumer_offsets | 247 | 247 |
| strimzi.cruisecontrol.metrics | 203 | 203 |
| strimzi.cruisecontrol.partitionmetricssamples | 125 | 125 |
| strimzi.cruisecontrol.modeltrainingsamples | 0.667 | 0.667 |
| realtime-ad-ss-kappa | 0.133 | 0.133 |
| 【全局实时总吞吐量】 | 614K msg/s | 614,443.8 msg/s |
所以,对于我们的ClickHouse集群中的每一个Active Replica:
- 我们会创建一个Kafka表,会用来消费某一个Kafka Topic的数据;
- 每一个Kafka表的数据会通过
Kafka Table -> Materialized View -> ReplicatedMergeTree Table的方式,落地到ReplicatedMergeTree table - 同时,在
Active/PassiveReplica上会有一个Dist表,用来查询整个集群上的ReplicatedMergeTree Table中的全量数据
为了确定在这个Traffic下面我们需要设置多少的Consumer才能够保证消费能力够用,我们进行了测试,测试结果如下:
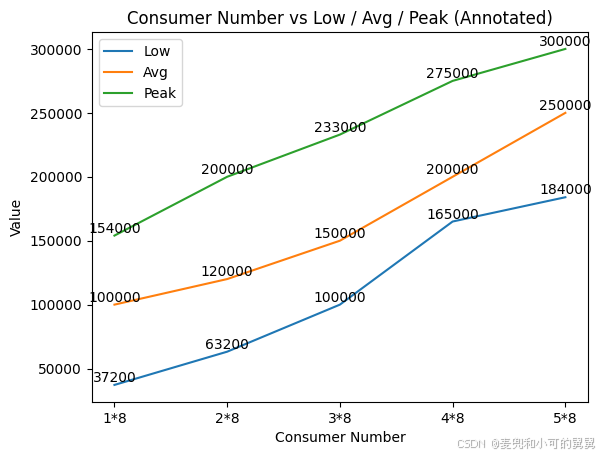
上图显示了我们基于8台机器的ClickHouse集群的测试结果,我们在每台机器上设置不同的Consumer Number(1,2,3,4,5),然后统计一段时间内的消费能力。
从上面的统计结果可以看到,我们实际的数据总量(所有DataSource 加在一起的Input Traffic )大概为614K msg/s,因此:
- 按照上图显示的消费能力线性变化的趋势,我们大概只需要
10 * 8即总共80个Consumer; - 但是,由于一个Data Source的数据是放在一个独立的Kafka Table中的,即,对于每一个Data Source,我们需要一个独立的Kafka表;
- 对于最小的Data Source,如果我们在33个Shard上的每一个Active Replica上建立对应的Kafka表,即使这个Kafka表只有一个Consumer,消费能力也过过剩。总的Consumer的数量甚至超过了这些小的DataSource的Kafka的Partition的数量。
- 对于比较大的Data Source,我们测试发现,在33个Shard上的每一个Active Replica上创建只有一个Consumer的Kafka表,消费lag会逐渐增大,当增加成2个的时候,可以消费,但是其实也过剩,并且,由于我们有33个Shard,这些Data Source的Partition数量不是Shard数量的整数倍,没法做到严格的复杂均衡,有些Consumer还是在空转。
所以,总的说来,我们面临两种不同的集群架构:
-
Flat Mesh Cluster : 66台机器组成一个大的Cluster,我们在整个Cluster的每个Shard上为每一个Kafka Topic都同时创建Dist表 , Kafka表,MV 表 和 Local 表。但是很显然,有些Topic的数据量很少,只需要数量很少的Consumer,但是这种架构下,我们却需要在整个33个Active Replica上至少为这个Topic建一个consumer,整个集群范围内就是每一个Data Source都至少有33个consumer。
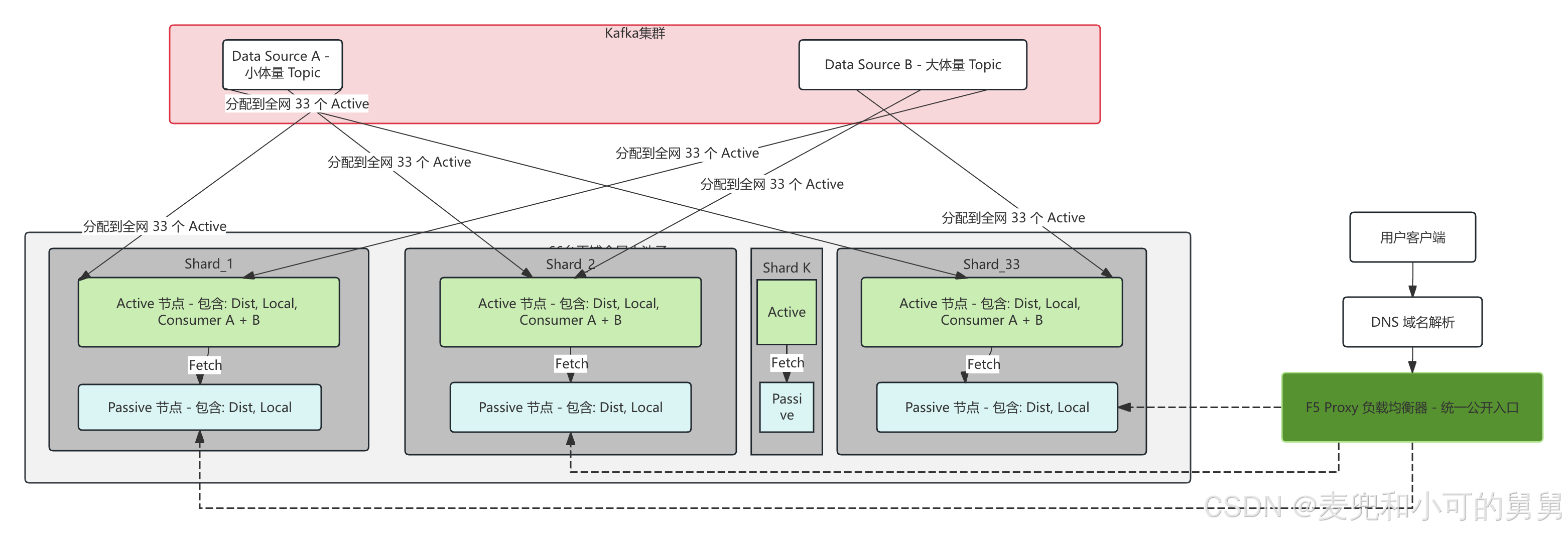
-
Vertical Split Clusters: 我们将66台机器进一步逻辑划分LogicalGroup,每一个LogicalGroup和一个Database一一对应,LogicalGroup中的DataSource所包含的表就放在这个Database中。同时,我们为这个LogicalGroup定义对应的Cluster以确定这个LogicalGroup对应的数据库的部署范围。
- 我们通过定义和管理Logical Cluster的Member,来定义和管理这个LogicalGroup的Data Source所在的机器。
- 但是,由于这些LogicalCluster我们最终还是想通过DNS + H5 对外暴露成一个单独的Cluster,不想让外部用户看见内部的复杂性,因此需要一些更复杂的考量来隐藏内部复杂性。
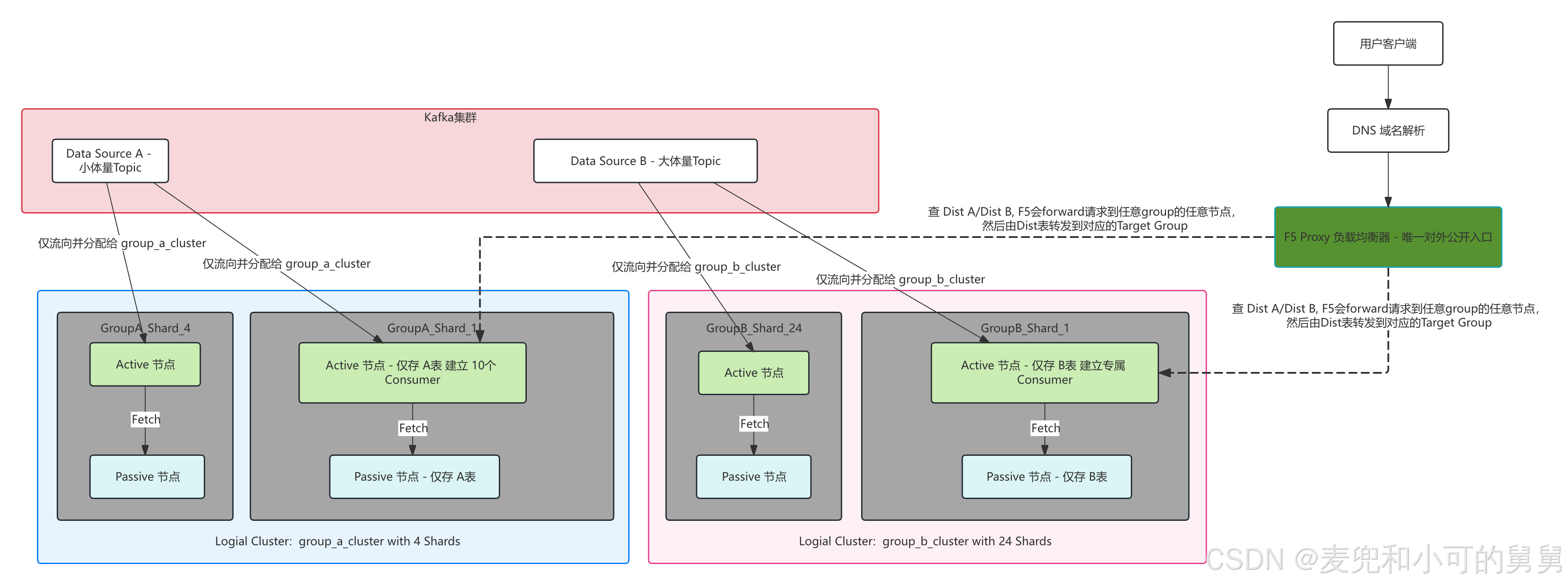
根据超大规模高并发实时查询的真实生产残酷环境,对两种设计方式进行工业维度的客观拆解:
下面的表格清晰地展示了两种集群架构的优劣点:
| 评估维度 | 方案 A:60台机器完全平铺大池子 (Flat Mesh Cluster) | 方案 B:纵向切分逻辑集群 (Vertical Split Clusters) | 胜出者 |
|---|---|---|---|
| 设计核心思想 | 60台机器作为一个无状态的大计算网格,全部资源共享,通过配置和空转实现动态平衡。 | 在路由和计算层,将大集群静态拆分为 2~3 个独立的逻辑集群(每组 20~30 台机)。 | - |
| 日常运维心智 (扩缩容/坏机替换) | 极佳。新机上线直接无脑分发全量脚本;坏机时 Kafka 自动 Rebalance 匀给空转机器,近乎无人值守。 | 一般。扩缩容需要严格走确定性的运维时序(先 Local -> 后 Dist -> 热加载 -> 开消费),存在少量手工或脚本成本。 | 方案 A |
| 分布式扇出 (Fan-out RPC 压力) | 极差。每一次 Dist 表查询都必须强行向 60 台机器同时发起网络调用。RPC 连接数过高,网络风暴风险大。 | 极佳。单次查询的网络并发扇出硬性拦截在 20~30 台机器的"高安全水位区",网络压力降幅达 3 倍。 | 方案 B |
| 长尾延迟 (Tail Latency / P99) | 极差。由于连乘效应,每一次查询都有极高概率撞上至少一台机器微观抖动,导致 P99 延时频繁被 Fallback 重试拉长。 | 极佳。完美规避了超大集群的连乘抖动效应,组内即使触发 Replica 重试也在毫秒级内完成,P99 延时表现极度平稳。 | 方案 B |
| 爆炸半径 (Blast Radius 故障域) | 无限大 (100%)。没有任何物理/计算隔离。某一业务线偶发流量暴涨、慢 SQL 或脏数据,会瞬间卷入全集群 60台 机器,导致全线实时业务陪葬。 | 受控在局部 ( 1 / 3 1/3 1/3)。各组计算资源刚性隔离。一旦 Group A 遭遇大查询被打满或崩溃,Group B 和 C 的 realtime 核心服务依然安然无恙。 | 方案 B |
| 中/小体量业务表 应对大促容量规划 | 极具弹性,对大促极不敏感 。 由于 60 台机器组成的计算存储资源池(Pool)极其庞大,中小体量的表进行大促时,其爆发流量在总池子中占比微乎微。天然形成弹性缓冲,根本不需要对小表所在的集群做任何扩容运维。 | 局部弹性,需精细规划 。 由于集群被切分为 20~30 台的局部逻辑组,当其中某个小表或中等体量业务爆发大促时,其流量在局部组内的占比相对凸显,仍需在逻辑组内部进行定制化的容量规划与资源调拨。 | 方案 A |
| 小体量 Kafka 表 (Partition数 < 10) 空转开销 | 空转副作用大,引发严重的线程池污染 。 · 计算侧限制 :由于小表元数据在 60 台机全量平铺,每一个分布式查询(Dist query)都会被无差别转发到所有机器上。虽然有 50 多台机实际上只会查询到空数据,但这些空子查询在响应返回前会真实占用节点的执行线程 。这迫使运维不得不放宽安全红线,将集群的 max_concurrent_queries(最大并发查询数)强行设置得非常大,埋下并发雪崩隐患。 · 消费侧浪费:全集群部署导致大量的 Consumer 实例实际上根本没有被分配到(Assign)对应的 Topic Partition,白白耗费 Kafka Broker 的全局长连接(Sockets)与维持心跳的系统句柄。 |
精确掌控,计算/消费资源零浪费 。 · 计算隔离 :小表只定向分发到其中一个逻辑组(20~30台机甚至更少),其余组完全感知不到该表结构。分布式查询的转发被严格限制在组内,彻底熄灭了无效空查询对全集群线程池的污染,max_concurrent_queries 可维持在健康的紧凑红线内。 · 按需消费:消费端只在对应的局部组内建立,Consumer 与 Partition 的比例紧凑合理,绝无大面积空转和无谓的句柄空耗。 |
方案 B |
| 多租户/多业务线 高并发抗冲击能力 | 较差。缺乏隔离大闸,大促期间高并发查询与高并发消费极易在物理层互相"踩脚",引发大面积资源争抢。 | 极佳。天然的舱壁隔离模式(Bulkhead),不同级别的业务线被锁在不同的 Group 算力内,抗突发冲击韧性极强。 | 方案 B |
综合上述对比,我们可以看到,在 66 台超大规模集群的实时高并发场景下,"平铺"是高可用和低延迟的敌人,"切分"才是对抗长尾抖动和故障雪崩的唯一银弹。 无脑追求平铺大池子看似节省了早期的运维建表步骤,但在真实的工业级大规模高并发生产环境下,它触碰了分布式系统的扇出天花板,单点长尾延迟以及共享故障域导致的全局雪崩会彻底摧毁前端的 SLA。
因此,我们得出结论:纵向切分逻辑集群(Vertical Split)是目前兼顾"运维可控"、"算力隔离"与"秒级容灾"的最成熟、最合理的最高工业级标准解。
💡 架构核心概念:连乘效应 (Multiplication Effect)
- 一句话解释 :在全扁平的分布式架构中,一个分布式查询(Distributed Query)的整体成功率,不是取决于平均值,而是取决于所有单机可用性的乘积。
- 底层物理真相:当一个 Query 需要同时扇出到 N 台机器获取结果时,只要其中任何一台机器因为网络抖动、慢盘、垃圾回收(GC)导致失败,整个 Query 就会坍塌。
- 数学模型 :假设单机稳定率为 99.5%(即只有 0.5% 的极低单点故障率):
- 在 20台 机器的集群中,整体查询成功率为:99.5% 的 20 次方,约等于 90.46%
- 在 60台 机器的集群中,整体查询成功率瞬间暴跌至:99.5% 的 60 次方,约等于 74.02%
- 架构启示 :机器基数越大,分布式查询撞上长尾延迟和莫名报错的概率就呈指数级飙升。"平铺大池子"是线上实时高可用和低延迟的硬伤。
💣 架构核心概念:爆炸半径 (Blast Radius)
- 一句话解释 :线上某个局部组件、某条业务线或某台物理机器发生突发故障时,受其冲击波波及、导致一起崩溃或不可用的业务范围有多大。
- 工业级灾难对齐 :
- 扁平大池子架构 :由于全集群 60 台机器在计算、路由、磁盘资源上完全共享且毫无边界。一旦业务 A 偶发突发流量暴涨、由于写错 SQL 产生恶劣的全局大计算,会瞬间将 60 台机器的算力同时榨干。此时,故障的爆炸半径是 100%,导致完全独立的业务 B、业务 C 一起陪葬。
- 纵向切分逻辑集群 (Vertical Split) :引入造船业的舱壁隔离模式 (Bulkhead) 。将集群静态切分为 3 个独立的逻辑组(每组 20 台)。A 组的业务就算彻底"炸毁",其网络风暴和算力黑洞也被死死锁在 A 组内部。爆炸半径被刚性压缩在局部 1 / 3 1/3 1/3 以内,B 组和 C 组高并发实时服务依然稳如泰山。
- 架构启示:优秀的分布式架构师,每天都在做的一件事,就是通过物理/逻辑隔离把故障的爆炸半径控制到最小。
🌪️ 架构核心概念:扇出压力 (Fan-Out RPC Grid Pressure)
- 一句话解释 :指一个分布式查询作为 Initiator(发起者)时,单次查询在空间维度上同时向后端物理节点发起的网络并发连接数(RPC 数量)和网络风暴密度。
- 底层瓶颈拆解 :
- 平铺大池子:Fan-Out 值为 60。每一次前端查询砸过来,Initiator 机器都要在几毫秒内瞬间建立、管理并维系 60 个远程 TCP 长连接。在大促高并发查询时,这种高密度的扇出会导致 Initiator 节点的网卡队列瞬间被打满,网络风暴极其恐怖。
- 纵向切分集群 :Fan-Out 值硬性拦截在 20 左右的安全线。单次分布式查询的网络并发和 RPC 压力整整降低了 3 倍。
- 架构启示:超大规模分布式存储中,Fan-Out 越高的集群,对网络底座的压迫越极端,系统出现网络长尾延迟(Tail Latency)和连接数句柄耗尽的灾难率就越高。
在我们选择了Vertical Split集群架构以后,意味着我们至少需要在ClickHouse中定义以下Cluster才能完成整个集群功能。这里,我们假设整个66台机器的集群被切分成两个Group, group_a_cluster和group_b_cluster:
global_cluster: 包含大池子里全部66台机器(包括所有 Group 的 Active 节点、Passive 节点,以及处于待命状态的 Buffer Pool 机器)。active_replica_cluster: 全集群中所有被设定为 Active 角色的消费节点集合passive_replica_cluster: 全集群中所有被设定为 Passive 角色的消费节点集合group_a_cluster: 属于 Group A 业务线独立的物理机器集合,包含其对应的 Active 存储节点与 Passive 存储节点(例如:host-01~host-22,共 22 台机器)。group_b_cluster: 属于 Group B 业务线独立的物理机器集合,包含其对应的 Active 存储节点与 Passive 存储节点(例如:host-23~host-44,共 22 台机器)。- 或者,我们可以对
group_a_cluster进行Active/Passive的进一步拆分,group_a_active_cluster和group_b_active_cluster等。
注意,我们这里举的例子中,group_a_cluster和group_b_cluster的机器没有重合,但是实际操作时,完全不存在这种物理隔离,比如,一台机器可以同时存放group_a和group_b的数据,目的都只有一个:集群范围内的负载均衡。
DatabaseReplicated是否合适
由于我们打算把不同的DataSource切分到不同的LogicalGroup,一个LogicalGroup对应一个Database,一个Database通过定义一个Cluster来规定这个Database的数据的部署范围,因此,我们很容易想到DatabaseReplicated,因为ClickHouse中DatabaseReplicated就是天然和Cluster绑定在一起的。同时,DatabaseReplicated具有一些优良特性,比如,支持动态创建,可以自动帮我们同步元数据。因此,我们最初考虑,可否使用DatabaseReplicated来完成我们Vertical Split Clusters的方案设计。
在传统的 ClickHouse 集群里,每一个 Shard 内部如果新加了机器,运维人员必须手动(或者写脚本)去新机器上创建 Local 表。不仅Table DDL要对齐,由于 ReplicatedMergeTree 依赖固定路径,还必须人肉去修改 DDL 里的Shard和Replica宏定义(如 /clickhouse/tables/shard_X/{replica})。步骤稍有错漏,底层同步就会直接卡死。
所以,我们最开始的时候决定使用DatabaseReplicated,而不是普通的Database(在ClickHouse中属于DatabaseAtomic)来作为每一个Group的
最初动机是,我们希望把新机器扔进 group_a_cluster 的瞬间,DatabaseReplicated 引擎能够利用它的 ZooKeeper 强一致元数据重放机制,一揽子(原子化地)自动把这个物理组内的 Kafka 表 -> MV 表 -> Local 表 全部在两台新机器上瞬间复活出来。
-
- 运维人员只需要执行一句
CREATE DATABASE,剩下的环境对齐全部交给引擎自动完成。我们最初是在追求一种**"像在单机上增加一个分区一样简单"的极简扩容体验**
- 运维人员只需要执行一句
但是仔细研究发现,DatabaseReplicated并不适合我们的场景,其中最重要的原因有两个:
- 无法控制内部个别表的创建: 基于我们Active-Passive的架构,同名的Database,在Active Replica中有
Kafka表 -> MV表,但是在Passive Replica中没有Kafka -> MV表。可是DatabaseReplicated一旦创建,所有机器上在该数据库中就有相同的表,因此无法完美支持我们的使用场景 - 不适合Dist表: 由于我的Dist表必须建在所有表上,那么一个
DatabaseReplicated中的对应的Dist表,就不可以建在这个DatabaseReplicated数据库中,因为DatabaseReplicated只能负责有自己的数据库的机器;-
但是这个似乎有临时的解决方案(Workaround), 我们可以把所有的Dist表都建在default数据库中,但是Dist表背后的
Kafka 表 -> MV 表 -> Local 表存放在我们划分的group所对应的DatabaseReplicated中,这对于Dist表是完全可以做到的:sql-- 这条语句可以通过 ON CLUSTER 分发到全集群 66 台机器的 default 库中 CREATE TABLE default.a_dist ON CLUSTER all_66_nodes ( -- 这里定义和 local 表一模一样的列结构 id UInt64, timestamp DateTime, ... ) ENGINE = Distributed('static_cluster_a', 'db_replicated_a', 'local_table', rand());这里,
group_a对应的dist表建立在default数据库中,我们在所有66台机器(all_66_nodes)上建立dist表,dist表指向group a对应的clusterstatic_cluster_a(我们上面说过,Kafka表 -> MV表 -> Local表)中的db_replicated_a.local_table; -
但是这样明显增加了运维的复杂程度。
-
- 无法控制表的创建顺序:由于
DatabaseReplicated数据库在某台机器上创建的时候,内部的表同时全部被创建,即,内部表创建的先后顺序我们无法控制。可是,在实际的运维场景下,我们往往需要手动干预这个顺序, 比如,在扩容的场景下,我一般需要这么做: 1) 在新机器上把路由打开,2) 修改cluster配置让所有机器都看到新机器,3) 建kafka和mv表注入数据,这样,在整个扩容运维过程中,用户通过dist表查询到的数据始终没有遗漏和丢失。可是,如果Kafka表 -> MV表创建在DatabaseReplicated中,这意味着步骤 1) 和 3) 只能同时进行,这时候,无论是创建DatabaseReplicated然后再更新cluster.xml让Dist表感知到新机器的加入,还是先更新cluster.xml然后再创建DatabaseReplicated,都会有问题:- 如果先创建
DatabaseReplicated(表已经创建,本地数据已经在新机器上有注入)然后再更新cluster.xml,那么期间有一部分查询可能只会touch到一部分数据,查询数据不完整 - 如果先更新
cluster.xml然后再创建DatabaseReplicated,那么期间查询可能会碰到local表不存在的情况而报错;- 注意,
skip_unavailable_shards参数指的是ClickHouse是否对Shard不存在保持静默。而我们经常遇到的情况是,Shard中的某一个Replica报错(表还没来得及创建),所以,当Shard中的某一个Replica上的表不存在的时候,即使Shard内部的Failover策略会忽略掉有问题的Replica(在我的另一篇文章中讲的ConnectionPoolWithFailover),也还是有报错的风险,令人不安;
cpp M(Bool, skip_unavailable_shards, false, "If true, ClickHouse silently skips unavailable shards. Shard is marked as unavailable when: 1) The shard cannot be reached due to a connection failure. 2) Shard is unresolvable through DNS. 3) Table does not exist on the shard.", 0) \
- 注意,
- 如果先创建
综上考虑,我们觉得DatabaseReplicated的方案给我们带来的麻烦要多余给我们带来的便利。在分布式系统设计中,有一条黄金定律:"如果一个高阶特性(DatabaseReplicated)带来的便利,需要我们用更多的底层 Trick(比如节点级配置隔离、分库管理)去修补它引发的副作用,那就果断放弃它,回归最纯粹、最可控的底层基石。"
放弃 DatabaseReplicated,回归纯粹的 cluster.xml(静态,但前提是ClickHouse可以热加载cluster.xml以完成无感的集群扩容缩容) + 手动/脚本控制 DDL,虽然在扩容时需要多敲几行建表语句,但它带给我们带来的回报是:对 Active-Passive 架构 100% 的绝对掌控力,以及毫无魔法、完全透明的运维确定性。
所以,我们首先需要验证的,就是clusters.xml是否支持热加载。
需要进行的验证和测试
- ClickHouse是否支持动态刷新
clusters.xml
我们需要快速验证ClickHouse是否支持动态刷新clusters.xml中的变更,而且,各种变更我们都需要覆盖,包括:- 往一个cluster中添加一台机器,是否能够动态加载
- 删掉一个Cluster中的一台机器,是否能够动态加载
- 替换掉一个Cluster中的一台机器,是否能够动态加载
我们通过测试发现,整个ClickHouse的cluster.xml是完全可以实现各种形式的动态加载的,包括往cluster中添加机器,从cluster中删掉机器,以及,将cluster中的某台机器替换成另外一台机器。
- Distributed表中的Cluster参数是否支持
DatabaseReplicatedCluster,还是只支持我们配置在Cluster.xml中的静态Cluster?
- 这个验证过程很简单,不做描述;验证证明,Distributed表中的Cluster参数支持DatabaseReplicated Cluster
- 一个Shard中的Replica不存在,或者这个Replica上不存在这张表,查询时是否报错;
- 我们的测试方式是, 在一个
2 Shards * 2 Replica的集群中,我们将Local表只建立在每个Shard的其中一个Replica中,然后我们基于Dist表进行查询,所有查询都能成功。这说明基于ConnectionPoolWithFailover的Shard内部的 failover策略生效了,不会报错,查询会通过Failover的方式,只去Healthy的replica上查找数据,这背后的细节是: 我在我的另外一篇文章《ClickHouse Dist表的Replica选择逻辑深度解析-- Custom Key以及Sample的执行逻辑》详细讲过其中的具体原理,第一次是通过failover的方式完成选择,然后坏机器会在一定时间内被标记并且以后的查询都不会再解除,然后有效期解除,如果机器依然没有修复,就再次进行尝试,如此循环往复。
- 如果整个Shard中这张表都不存在,查询时是否报错;
-
我们的测试方式是,在一个
2 Shards * 2 Replica的集群中,我们将Local表只建立在Shard 1的第一个Replica中,而Shard 2中的所有Replica上都不建这张表。 -
测试证明,默认情况下,没有enable
skip_unavailable_shards,查询会报错:sqlcmdp101-1d.cjs2.dev.mycorp.com :) select * from test_db.web_log_dist_3; Received exception from server (version 24.8.4): Code: 279. DB::Exception: Received from localhost:9000. DB::Exception: All connection tries failed. Log: There is no table `test_db`.`web_log_local_3` on server: cmdp102-1c.cjs2.dev.mycorp.com:9000 There is no table `test_db`.`web_log_local_3` on server: cmdp102-1d.cjs2.dev.mycorp.com:9000上面的报错显示,查询试图在Shard 2中的两台机器中查找表web_log_local_3,但是都没有找到,因此报错。
当我们设置了skip_unavailable_shards以后,异常的shard 2被忽略,查询返回成功:sqlcmdp101-1d.cjs2.dev.mycorp.com :) set skip_unavailable_shards = 1 cmdp101-1d.cjs2.dev.mycorp.com :) select * from test_db.web_log_dist_3; SELECT * FROM test_db.web_log_dist_3 Query id: efc6fa04-4372-4995-8e88-a0483f0f5ebb ┌─id─┬─url───┬──────────────────ts─┐ 1. │ 3 │ Alice │ 2026-05-21 13:47:19 │ 2. │ 4 │ Bob │ 2026-05-21 13:47:19 │ └────┴───────┴─────────────────────┘ 2 rows in set. Elapsed: 0.007 sec.
扩容,缩容和机器替换的策略
注意,我们这里讲的扩容、缩容和机器替换策略是基于我们的数据特性和部署场景而言的,包括:
- 数据的TTL很短,基本不需要进行数据迁移。比如,我们所有的Realtime表的TTL都是1个小时,这给我们节省了数据迁移的精力。比如,当我们下线一台机器的时候,只要数据的Ingestion停止,那么我们只需要再等待一个小时,就可以直接重新re-image这台机器;
- 我们的数据本身通过
Kafka Table -> MV Table -> Local Table的流动最终落地,数据本身不和ClickHouse Shard进行绑定(比如,我们没有为数据设置如下的路由策略:hash(user_id) = shard index),因此整个扩缩容过程可以完全依赖于Kafka 消费者组(Consumer Group)的自动再平衡(Rebalance)和负载均衡机制,变得特别丝滑。
因此,我们设计扩缩容和机器替换方案的终极原则就是:
- 在扩缩容过程中数据本身不丢失;
- 在数据不丢失的情况下,查询在扩缩容过程中不受影响,包括: 1)查询不中断,2) 数据不重, 3) 数据不漏;
扩容
当某一个逻辑集群(Logical Cluster,如 group_a_cluster)的流量上涨或存储水位达到阈值时,需要向该集群中追加 1 个全新的 Shard(包含一台 Active 消费节点和一台 Passive 存储节点)。
-
为新增节点配置本地环境
登录准备上线的两台新机器,配置各自的
macros.xml宏定义文件,明确指定其分片(Shard)与副本(Replica)身份:- Active 节点:
{shard} = 'X', {replica} = 'host_new_active' - Passive 节点:
{shard} = 'X', {replica} = 'host_new_passive'
配置完成后,直接在两台新节点上本地执行 DDL,创建数据库和底层存储表(由于此时大集群配置文件尚未更新,无法使用
ON CLUSTER广播):SQLCREATE DATABASE IF NOT EXISTS group_a ENGINE = Atomic; CREATE TABLE group_a.web_log_local ON CLUSTER mycorp_leader ( id UInt64, url String, ts DateTime ) ENGINE = ReplicatedMergeTree('/clickhouse/tables/group_a/web_log_local/shard_{shard}', '{replica}') PARTITION BY toYYYYMMDD(ts) ORDER BY id; - Active 节点:
-
更新集群配置文件并触发热加载
修改全集群所有机器的
clusters.xml配置文件,将这两台新机器的 IP 或 Hostname 追加到对应逻辑集群(如group_a_cluster)的新增分片(Shard X)配置中。保存后,ClickHouse 会在秒级内自动热加载变更。- 查询侧表现:热加载生效后,大集群内部已有的节点在转发分布式查询时,会开始并发请求这两台新机器的存储层。由于上一步已提前在本地建好了 web_log_local 表结构,根据测试结果(3),即使此时新节点体内数据为空,集群内部的 Failover 机制也会正常向发起端返回 0 rows 结果,查询保持连续,不会引发 UNKNOWN_TABLE 报错。
-
补齐新节点上的分布式表元数据
登录两台新机器,在本地创建面向前端查询的 Distributed 分布式表。这一步是为了确保下一步新节点并入 F5 后,能够正常承载和解析分发给它的查询请求:
sqlCREATE TABLE group_a.web_log_dist ON CLUSTER global_cluster ( id UInt64, url String, ts DateTime ) ENGINE = Distributed('group_a_cluster', 'group_a', 'web_log_local', rand()); -
F5 负载均衡器并网(公开前端计算能力)
在 F5 负载均衡器的 Pool 中,将这两台新节点的 IP 和端口追加到对应的 Backend 列表中。
此时,新节点开始接收来自前端 DNS/F5 分发过来的直接查询请求。由于步骤 3 已经补齐了分布式表壳,新节点作为 Initiator 接收到请求后,能够完美地向全组分发子查询并聚合数据返给用户,实现计算层的无缝挂载。
-
创建 Kafka 消费链路并激活数据写入
仅在新增的 Active 消费节点上单台执行 DDL,创建 Kafka 引擎表与物化视图(MV),正式开启流式数据接入:
sqlCREATE TABLE group_a.web_log_kafka (...) ENGINE = Kafka SETTINGS ...; CREATE MATERIALIZED VIEW group_a.web_log_mv TO group_a.web_log_local AS SELECT ... FROM group_a.web_log_kafka;写入侧表现:全新的 Active 消费节点启动后,会使用相同的 Consumer Group 向 Kafka Broker 申请分配 Partition。Kafka 触发自动再平衡(Rebalance),将一部分流量匀给该节点。数据开始写入新 Shard 的 Active 节点,并通过 ReplicatedMergeTree 底层日志自动 Fetch 同步给同 Shard 的 Passive 节点,扩容流程全部结束。
缩容
大促或高峰期结束,需要将某个逻辑集群(如 group_a_cluster)中的某个 Shard 移出,释放两台物理机器退回 Buffer Pool(待命机器池)。
-
从F5 中移除这两台机器
首先登录 F5 负载均衡器,将准备下线的这两台物理机器从对应的 Backend 列表中删除(或优雅下线/Disable)。
控制外部流量:此时,前端新的用户查询请求将绝对不会再直接打到这两台机器上。这两台机器不再承担 Initiator 的计算角色。但需要注意,此时它们依然存在于其他节点的
clusters.xml路由中,仍会作为存储节点响应其他 Initiator 节点的分布式子查询。 -
销毁下线节点的 Kafka 消费端
登录准备下线的 Shard 中的 Active 节点,直接执行 DDL 销毁该节点上的物化视图和 Kafka 引擎表:
sqlDROP TABLE IF EXISTS group_a.web_log_mv; DROP TABLE IF EXISTS group_a.web_log_kafka;写入侧变化:该节点的 Consumer 实例离线,Kafka Broker 触发 Rebalance,原先由其负责的 Partition 会自动漂移到其他健康的 Active 消费节点上,继续保持不丢数写入。
数据不丢保障:此时最新一小时的数据依然安全的留存在这两台机器的磁盘上。当整个集群其余健康的 F5 Backend 节点发起分布式查询时,仍会通过后台集群路由访问该分片,数据能够被完整查到,绝对不掉数。
-
静置 1 小时等待本地数据自然过期
由于当前业务数据的 TTL 仅为一个小时,在断绝了新数据流入后,随着 ClickHouse 后台物理 Merge 线程的推进,1 小时前本地遗留的数据块(Data Parts)到期后会被自动擦除。因此,我们仅仅保持两台下线节点在线挂载 1 个小时,不进行任何操作。 1小时后状态:两台机器本地的
web_log_local表由于历史数据过期,自动变为 0 rows 的干净空表。 -
从逻辑集群视图中移出目标节点
修改全集群所有机器的
clusters.xml配置文件,将这两台下线机器从该逻辑集群(如group_a_cluster)的成员列表中移除。查询侧表现:配置热加载生效后,全集群其余健康的计算节点将彻底不再向这两台机器发送分布式子查询请求。由于此时它们体内已无任何数据,切断路由对前端的总聚合结果完全无影响,实现了内外部完全无感的下线。
-
清理本地残留元数据并清空物理机
登录两台下线机器,在本地执行物理清理,清空宏配置并将机器退回 Buffer Pool(备用机器池):
sqlDROP TABLE IF EXISTS group_a.web_log_local; DROP DATABASE IF EXISTS group_a;
机器替换
在最初的设计构想中,当 group_a_cluster 中 Shard 2 的 Active 节点 host-03 突发硬件故障离线时,我们本来倾向于采用"原地物理修补"的闪电替换流:
-
伪装:直接调拨一台全新机器
host-new,将其macros.xml中的分片号对齐为 Shard 2,但副本名直接硬编码为新机器的真实名称({replica} = 'host-new')。 -
并网:在全集群的
clusters.xml中,直接用host-new的 IP 覆盖掉死掉的host-03,触发热加载,并让其与同分片一直存活的 Passive 节点host-04建立连接,秒级 Fetch 同步过去 1 小时内的残存历史数据。 -
复活:同步完成后,在新机
host-new上单台创建Kafka表和MV,重新唤醒数据流。
但是这种方式可能破坏我们整个集群架构的不变性: 一个shard中有两个replica。当我们用新机器替换掉就机器并且上线的时候,Keeper中对应的ReplicatedMergeTree的路径中,这个shard下可能有三个replica:
shell
ZK 路径:/clickhouse/tables/group_a/web_log_local/shard_2/replicas/
📂 host-03 (变成了一个无人认领的僵尸节点,因为机器已经死了,但 ZK 里的元数据还在!)
📂 host-04
📂 host-new (新追加进来的第三个副本名字)这个host-03可能带来DDL的锁死: 后续如果我们在这个库上执行 DROP TABLE 或者 ALTER TABLE 的 ON CLUSTER 广播,ClickHouse 会尝试去通知 ZK 里注册的所有副本。由于 host-03 已经物理脑死亡,你的分布式 DDL 变更会因为死死等待 host-03 的响应而无休止地卡住或报错。
所以,我们倾向于选择一种更优雅的替换方案: 先局部缩容下线故障 Shard,再将健康副本连同新机一起作为全新 Shard 扩容加回来。 这种方案和我们上面的直接的节点替换方案相比,我们不去做任何局部的物理修补,而是直接把整个 Shard 视作一个不可变的单元。一旦它残缺了(某一个replica失效了),我们就按照标准、经过严格验证的"缩容 SOP"把残缺的干掉,再按照标准的"扩容 SOP"把全新的合龙。
在我们的 1小时数据 TTL 和 Kafka 自动再平衡 的红利加持下,这个过程不仅完全可行,而且在工程上由于完全复用了现有的、验证过的 SOP 路径,其稳定性达到了 100%。