从Hydra到storage_engine:PostgreSQL列存引擎的性能跃迁与技术进化
Hydra 是一个为 PostgreSQL 提供列存储功能的扩展,使得 PostgreSQL 的 OLAP 性能大幅提升。它通过列式存储、查询并行化、向量化执行等技术,实现了高效的数据分析和处理。但是hydra分支最近提交的代码都是2年前的了,已经不再活跃了。由saulojb发起的替代品出现了--storage_engine--,该插件从Hydra演进而来,借鉴业界先进数据库,开发了三个关键特性:ClickHouse MergeTree的块内排序:每个表有orderby指定的排序键,可以实现Zone Map最大值/最小值 chunk和stripe级别的裁剪;Apache Parquet:Row-group级别统计信息,列投影和字典编码;DuckDB:对于列batch的向量化表达式计算。该插件的开源协议为AGPL-3.0。
该插件实现了列级别压缩和行级别压缩,面向列的压缩支持并行扫描和向量化执行,行级别压缩支持并行扫描。
1、使用方法
makefile
@font-face{font-family:"Times New Roman";}@font-face{font-family:"宋体";}@font-face{font-family:"Calibri";}p.MsoNormal{mso-style-name:正文;mso-style-parent:"";margin:0pt;margin-bottom:.0001pt;mso-pagination:none;text-align:justify;text-justify:inter-ideograph;font-family:Calibri;mso-fareast-font-family:宋体;mso-bidi-font-family:'Times New Roman';font-size:10.5000pt;mso-font-kerning:1.0000pt;}span.msoIns{mso-style-type:export-only;mso-style-name:"";text-decoration:underline;text-underline:single;color:blue;}span.msoDel{mso-style-type:export-only;mso-style-name:"";text-decoration:line-through;color:red;}@page{mso-page-border-surround-header:no; mso-page-border-surround-footer:no;}@page Section0{}div.Section0{page:Section0;}CREATE EXTENSION storage_engine; -- Column-oriented analytics tableCREATE TABLE events ( ts timestamptz NOT NULL, user_id bigint, event_type text, value float8) USING colcompress; -- Row-oriented compressed table (good for append-heavy workloads)CREATE TABLE logs ( id bigserial, logged_at timestamptz NOT NULL, message text) USING rowcompress; -- Insert normallyINSERT INTO eventsSELECT now(), g, 'click', random()FROM generate_series(1, 1000000) g; -- Query normally --- column projection, vectorized execution,-- and parallel scan are transparent and automatic.SELECT event_type, count(*), avg(value)FROM eventsWHERE ts > now() - interval '1 day'GROUP BY 1;2、列压缩
2.1 存储格式
每一列在磁盘上以列进行存储,每一列默认以150000行为单位分割成stripes,每隔stripe进一步分割成chunk group(默认10000行)。每个chunk记录了该chunk范围内的最大值和最小值,并且查询时可以利用最大值和最小值跳过不满足条件的chunk进行IO加载。
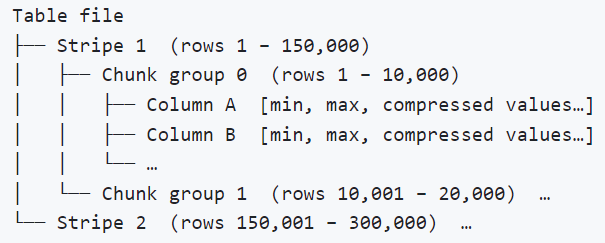
2.2 列级别缓存
内存中维护一个列缓存,存储已解压的列数据块。当同一条带区域被多次访问时(例如嵌套循环、重复执行计划或自连接),系统直接从缓存中提供已解压的数据,无需重新读取文件或再次进行解压操作:
cs
SET storage_engine.enable_column_cache = on; -- default: on2.3 向量化执行
对于查询中的谓词,下推到列存后,可以近存储向量化执行。该引擎以每调用最多处理10000 个值的列式批次来处理 WHERE 子句和聚合操作,而非逐行求值。这种机制与列数据块自然映射,并消除了逐行解释器的开销。需要通过配置项开启:
cs
SET storage_engine.enable_vectorization = on; -- default: on向量化操作支持的类型:

2.4 并行扫描
通过以下配置项:
sql
SET storage_engine.enable_parallel_execution = on; -- default: onSET storage_engine.min_parallel_processes = 8; -- minimum workers (default: 8)-- Standard PostgreSQL parallel knobs also apply:SET max_parallel_workers_per_gather = 4;SET parallel_setup_cost = 0;SET parallel_tuple_cost = 0;利用动态共享内存(DSM)实现了完整的 PostgreSQL 并行表访问方法协议。协调器将条带范围分配给各个工作进程;每个工作进程独立读取并解压其分配的条带,然后通过 Gather 节点返回结果。也就是基于条带级别的并行。
2.5 stripe级别和chunk级别的min/max裁剪
colcompress 利用存储在 engine.chunk 中每个数据块的 minimum_value / maximum_value 统计信息,实现了两层 zone-map 剪枝。
条带级剪枝(粗粒度) ------在读取任何数据之前,扫描过程会聚合每个条带内所有数据块的最小/最大值,并使用 PostgreSQL 的 predicate_refuted_by 函数,将生成的条带级范围与查询的 WHERE 谓词进行测试。任何其范围被证明与谓词不相交的条带都将被完全跳过------无需解压,也无需进行 I/O 操作。通过这种方式跳过的条带数量会在 EXPLAIN 输出中报告:
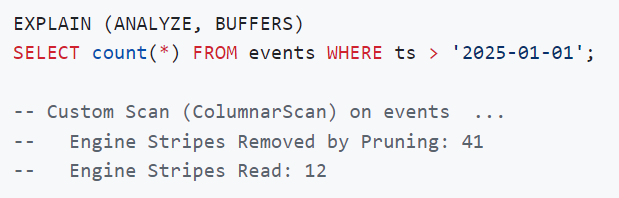
在engine.colcompress_merge() 建立全局排序后,条带剪枝的效果最佳,但它也适用于任何部分排序的数据。
块级剪枝(细粒度)------对于通过粗粒度过滤的每个条带,自定义扫描会将每个独立数据块组的最小/最大值范围与相同的谓词进行评估。那些范围无法满足谓词条件的数据块组将被跳过。
这两层剪枝机制协同工作:针对大型且排序良好的表的查询,通常会在访问之前就直接排除整个条带,然后在剩余条带中进一步剪枝数据块组,从而即使在没有索引的情况下也能实现极低的I/O 放大效应。
剪枝效率与数据的有序程度直接相关。建议结合使用orderby 选项和 engine.colcompress_merge() 来建立全局排序,以最大化两个层级的剪枝效果。
2.6 支持索引
自定义索引扫描路径允许使用B 树及其他索引来驱动对 colcompress 表的查找操作,仅解压由索引匹配到的行数据。
sql
-- Session GUC (applies to all colcompress tables in the session)SET storage_engine.enable_columnar_index_scan = on; -- default: off-- Per-table override (persisted in engine.col_options, survives reconnect)SELECT engine.alter_colcompress_table_set('documents'::regclass, index_scan => true);推荐使用方式:
1)分析型负载(聚合、范围查询、宽表):关闭索引扫描,利用顺序向量化扫描和chunk级别裁剪就够用
2)文档存储库(存储用于压缩的 XML、PDF 和 JSON 二进制大对象,并通过主键或唯一标识符进行检索):开启索引扫描,希望获得具备点查询速度的列式压缩,而非全表扫描。
索引扫描使用:要么将配置项开启,要么将表的index_scan选项设置为true。这使您可以在全局范围内保持 GUC 关闭,同时按表选择性启用它:
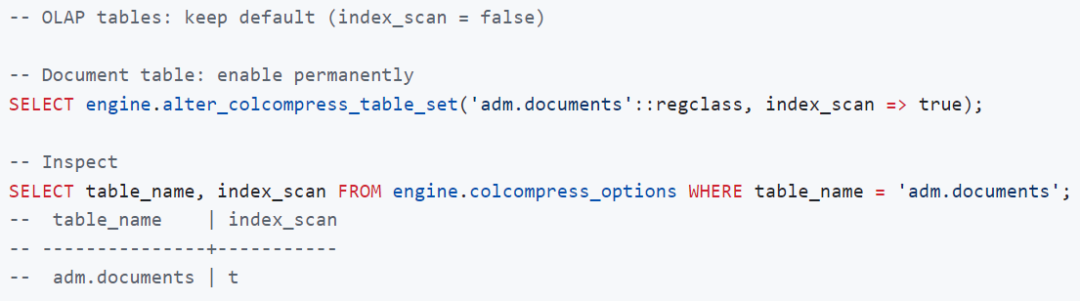
对于文档存储库而言,这种组合极具吸引力:采用zstd 的列式压缩 可将大型二进制或文本文档压缩 3 到 10 倍;而在启用索引扫描的情况下,诸如 WHERE id = 1 或 WHERE document_key = 1 的检索操作仅解压匹配的行,无需触及条带中的其余数据。
推荐使用场景:
1)文件/文档存储(XML、PDF、json通过主键或唯一键获取):index_scan = true。您希望通过列式压缩来节省存储空间,并在无需解压整个数据条带(stripe)的情况下实现高速的点查询。此时数据的排序顺序无关紧要,因为每次读取都针对特定的行。
2)分析型(聚合、data范围、group by、对数百万行数据进行模式扫描(LIKE)):index_scan = false + colcompress_merge()。按查询的过滤列对数据进行排序(orderby = 'event_date ASC'),然后合并以生成全局有序的数据条带(stripes)。在解压任何数据之前,基于条带级别的最小/最大值剪枝会直接跳过不相关的条带。
在同一张表上混合使用这两种方式虽然可行,但并非理想之选:在排序列(orderby column)上建立 B-tree 索引会导致查询规划器在执行范围查询时优先选择索引扫描(IndexScan),从而禁用条带剪枝功能。如果需要在分析型表上进行偶尔的点查询,建议在会话级别设置 GUC 参数 storage_engine.enable_columnar_index_scan = on,而不是创建 B-tree 索引。
2.7 支持删除和更新
colcompress 通过存储在engine.row_mask 中的行掩码完全支持 DELETE 和 UPDATE 操作。每个被删除的行会在每个块组(chunk-group)的位掩码中标记为一个比特位;扫描引擎会跳过这些被掩码标记的行,而无需重写数据条带(stripe)。UPDATE 操作则是通过"先删除后插入"的方式实现。
sql
SET storage_engine.enable_dml = on; -- 默认值:onDELETE FROM events WHERE ts < now() - interval '1 year';UPDATE events SET value = value * 1.1 WHERE event_type = 'purchase';被删除的行会在执行VACUUM 时被回收,该过程会重写受影响的数据条带并清除行掩码。
2.8 支持Upserts
支持标准的INSERT...ON CONFLICT,包括DO NOTHING和D UPDATE SET...。冲突目标列上需要唯一索引:
java
INSERT INTO events (ts, user_id, event_type, value)VALUES (now(), 42, 'click', 1.0)ON CONFLICT (user_id, event_type) DO UPDATE SET value = EXCLUDED.value;2.9 MergeTree类似的排序和colcompress_merge
受 ClickHouse MergeTree 引擎的启发,colcompress 支持为每张表设置全局排序键 。设置后,写入表的每个新数据条带(stripe)在压缩前都会按该键进行排序 。engine.colcompress_merge() 函数通过一次全局排序的重写操作重构整张表,从而使所有数据条带上的条带级和块级最小/最大值剪枝达到最佳效果。
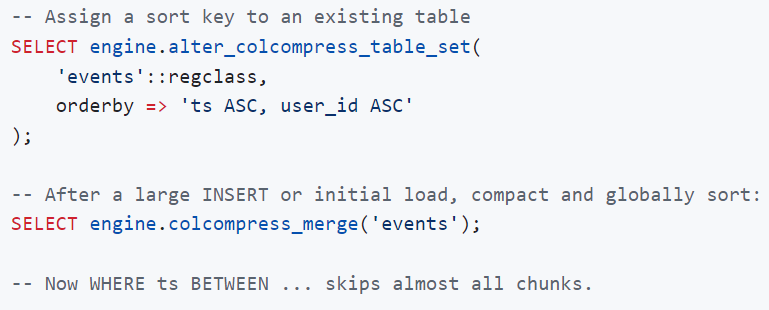
colcompress_merge 内部执行流程:
1)将所有存活(未删除)的行复制到临时堆表
2)清空目标表
3)按照 orderby 定义的顺序重新插入行,写入全新的全局有序数据条带
3、行压缩
3.1 存储格式

行压缩将行以固定大小的批次进行存储(默认每批 10,000 行)。每个批次使用堆元组格式进行序列化,然后作为一个整体单元进行压缩。批次元数据(文件偏移量、字节大小、起始行号、行数)存储在 engine.row_batch 中。
此存储引擎适用于追加密集型工作负载,这类场景重视压缩效果但无需列投影------例如事件日志、审计追踪以及多列常被一起查询的时间序列数据。使用 zstd 算法通常可实现 2--10 倍的存储空间节省。
与 colcompress 相比:
1)读取整行数据(不支持列投影)
2)每行写入延迟更低(无需列式转置)
3)不支持向量化执行或块级剪枝
4)支持并行读取和索引扫描
5)支持多种压缩算法