一、Agent Skills的基本概念与原理
Agent Skills 是什么 ?
Agent Skills(智能体技能)是给智能体安装的"可复用能力模块",提供一种执行特定任务或访问特定资源的能力。就像给机器人安装"技能芯片"------每个技能让AI能多做一个新任务。它不是一句 Prompt,而是一整套的 「指令 + 知识 + 工具 + 脚本」,在需要时自动加载和使用。
- Prompt = 你当场口头吩咐一次
- Skill = 写好的 SOP + 工具箱,智能体随用随查,根据任务自动选择合适的技能或工具来用。
Prompt / RAG / MCP / Agent Skills 对比
📌
不要孤立看待这些技术,而是将它们视为 AI 能力栈中不同层次、不同职责的组成部分 ,根据实际业务目标、任务复杂度和风险容忍度进行组合式选型。Prompt、RAG、MCP 和 Agent Skills 并不存在"谁替代谁"的关系,它们解决的是完全不同层面的约束问题, 共同构成的是一套互补而非竞争 的能力体系**。**
|--------------|--------------|----------------|--------------------|-------------------|
| 维度 | Prompt | RAG | MCP | Agent Skills |
| 本质 | 文本指令 | 检索增强 | 通信协议 | 技能模块 |
| 是否持久 | ❌ | ❌ | ✅ | ✅ |
| 是否可复用 | 低 | 中 | 高 | 极高 |
| 是否有流程 | ❌ | ❌ | ❌ | ✅ |
| 是否有执行逻辑 | ❌ | ❌ | ❌ | ✅ |
| 是否连接外部系统 | ❌ | ❌ | ✅ | ❌ |
| 是否影响上下文 | 高 | 高 | 低 | 极低 |
| 是否可版本化 | 差 | 一般 | 好 | 非常好 |
| 是否适合复杂任务 | ❌ | ❌ | ❌ | ✅ |
| 失败是否可控 | ❌ | ❌ | 中 | 高 |
| 一句话定义 | 一次性指令,控制当次推理 | 为模型临时补充"可检索事实" | 让 Agent 能访问外部系统的协议 | 固化"如何做一类事"的方法论与流程 |
| 记忆口诀 | 控制"想什么" | 控制"知道什么" | 控制"能看到什么" | 控制"怎么做" |
| 适用场景 | 简单对话 | 基于文档的问答 | 多工具集成 | 复杂业务流程集合 |
Agent Skills 的 核心设计理念
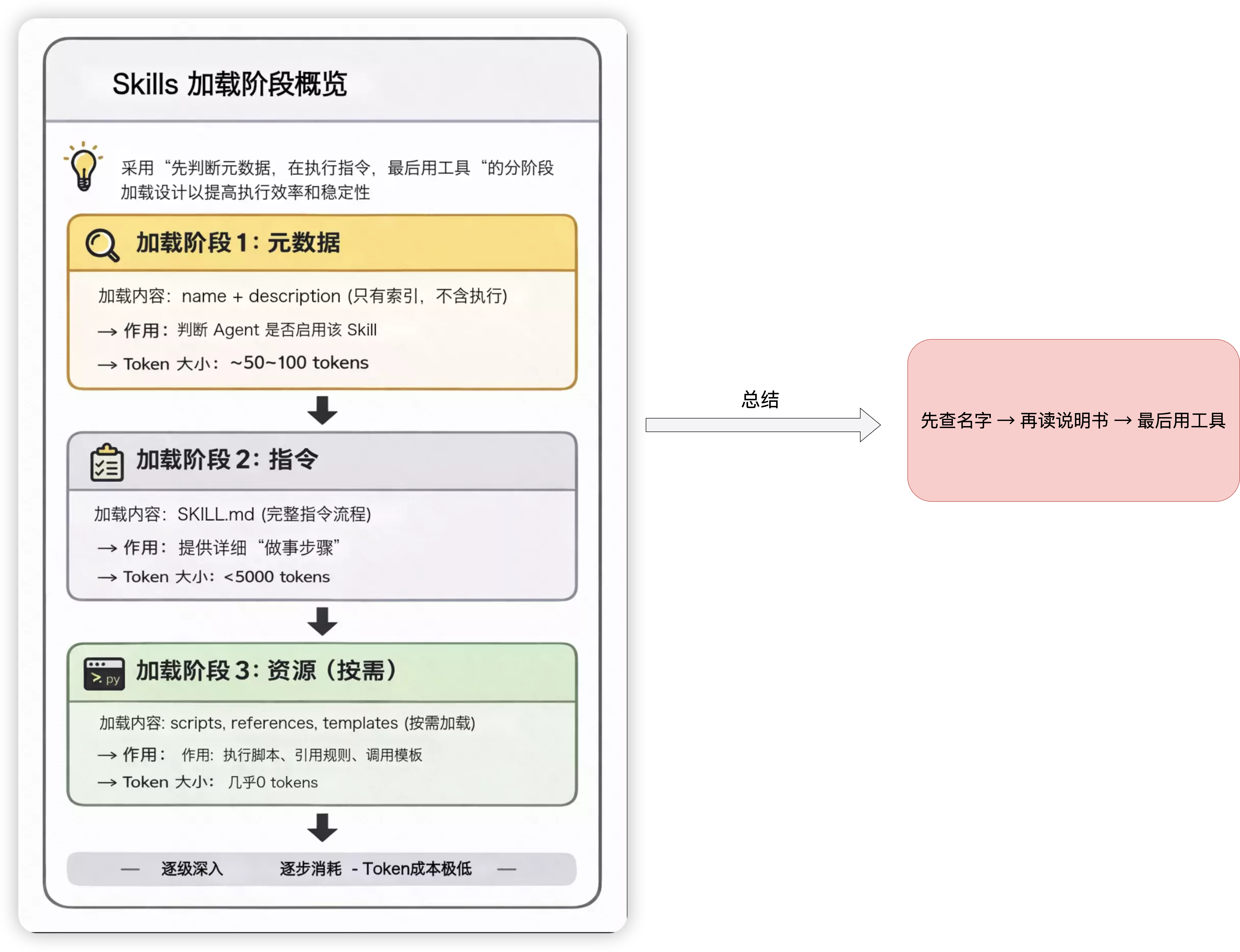
渐进式披露( Progressive Disclosure) : 分阶段加载(Progressive Loading)Skill 的设计不是"一次性把所有内容塞进上下文",而是严格分层、逐级、按需分阶段加载信息,分为三种 Skill 内容类型,三个加载级别。
Agent Skills 的文件结构与规格
每个 Skill 都需要一个带有 YAML 前置数据的 SKILL.md 文件:详细文档参考https://agentskills.io/specification
SKILL.md 是 Skill 的唯一入口 ,Agent **不会跳过 SKILL.md 直接使用其他文件,**其他对应的文件则是辅助工具,可根据自己的需求进行定义。
my-skill/
├── SKILL.md # 【必须】Skill 的入口文件:元数据+核心指令
│
├── reference.md # 【可选】规则 / 标准 / 背景知识
├── examples.md # 【可选】输入输出示例
│
├── scripts/ # 【可选】可执行脚本(确定性逻辑)
│ ├── preprocess.py
│ └── validate.py
│
└── templates/ # 【可选】模板文件(结构约束)
├── input.txt
└── output.txt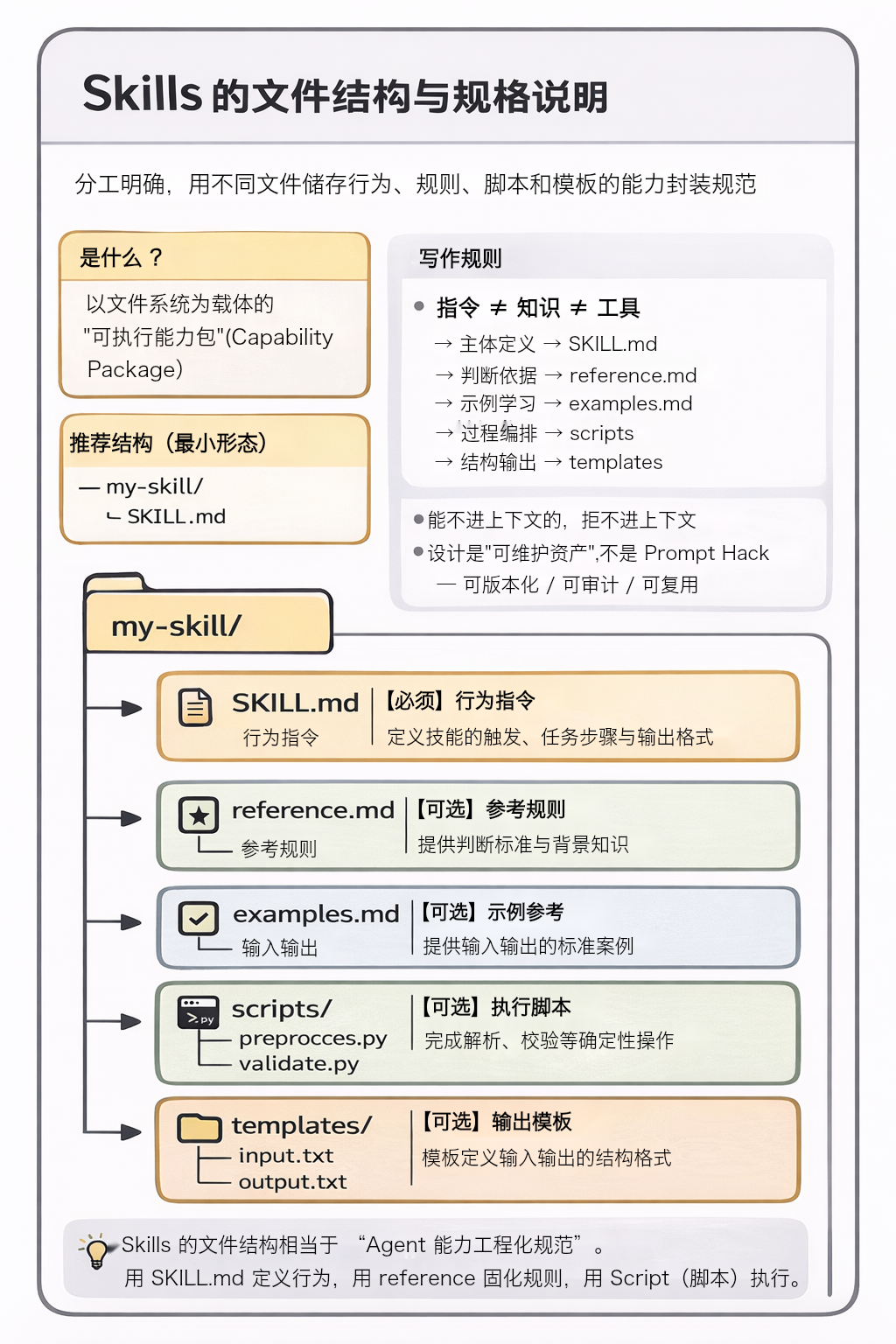
Agent Skills 的运行机制:从推理到执行的渐进式披露能力加载模型
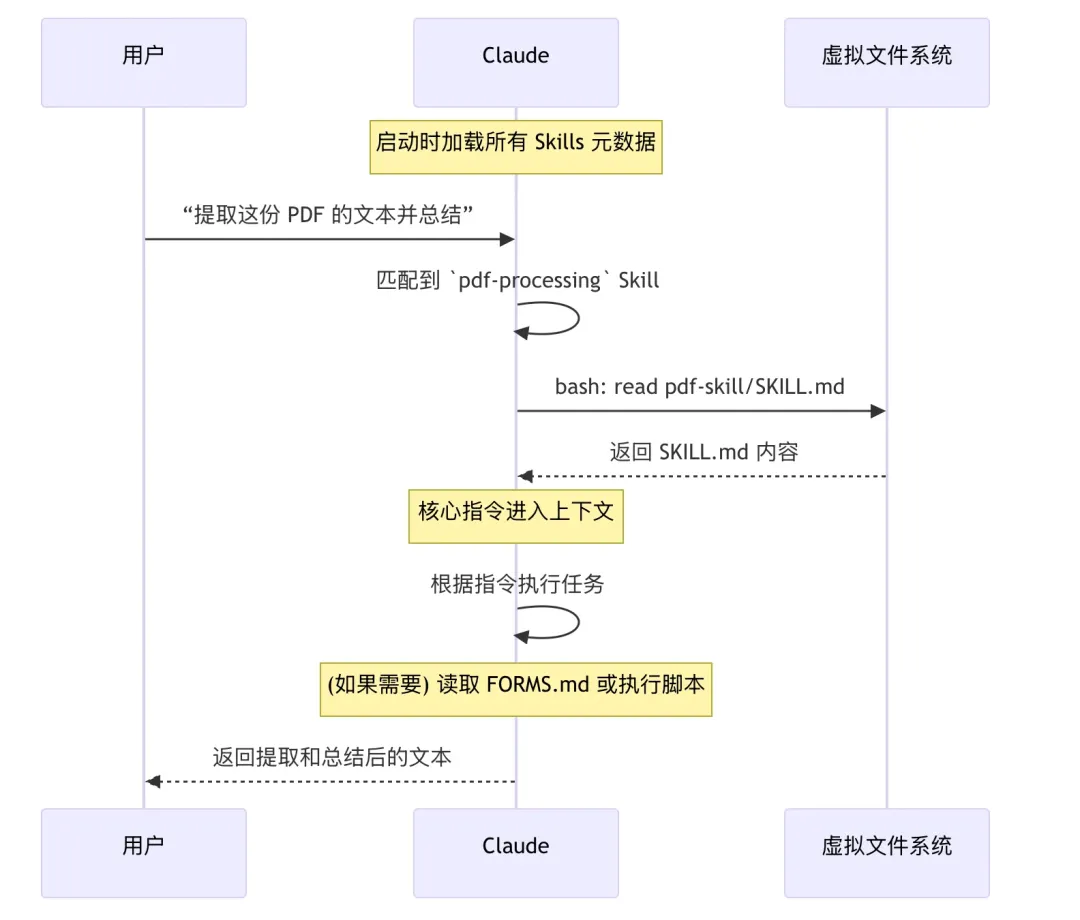
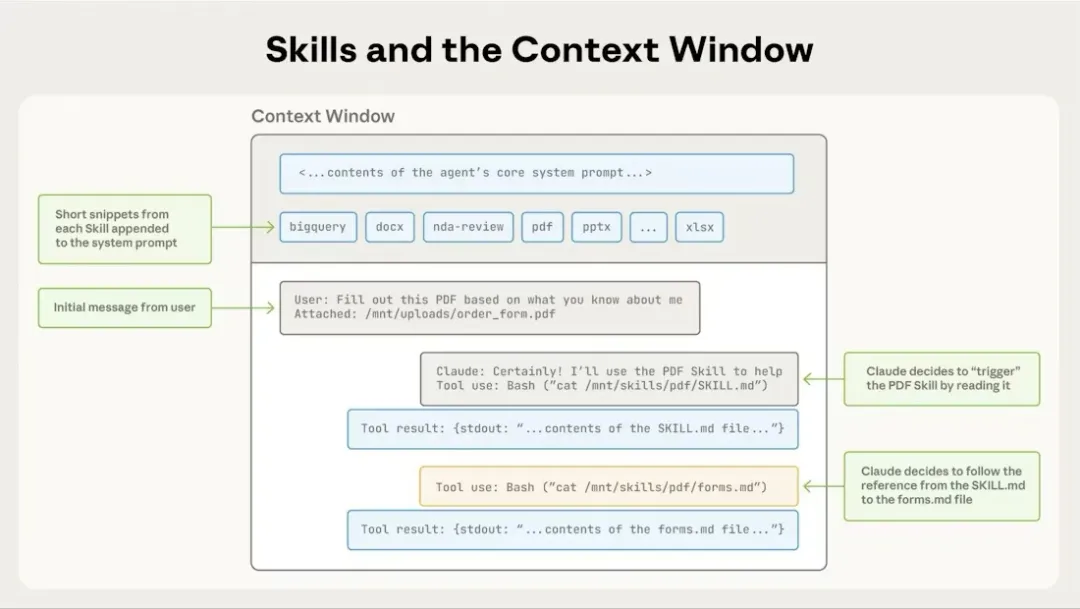
运行本质:让 Agent 在推理过程中,像操作文件系统一样,按需读取"流程说明 + 规则文档 + 可执行脚本",而不是一次性把所有知识塞进上下文。从系统角度看,Agent 并不是"调用 Skill",而是:在一次推理中,动态决定是否「进入某个 Skill 的工作空间」
整个加载过程分为三个大层次,本文详细拆分为5个阶段,下图说明了完整的渐进式披露的信息加载过程:
flowchart TD
U[用户请求] --> A[Agent 推理引擎]
A --> M[Skill 元数据池<br/>name + description]
M -->|相关性判断| D{是否匹配 Skill?}
D -- 否 --> A2[常规 LLM 推理]
A2 --> O1[直接回答]
D -- 是 --> L1[加载 SKILL.md<br/>核心指令 & 流程]
L1 --> P[流程化推理执行]
P -->|需要规则?| R[读取 reference.md]
P -->|需要示例?| E[读取 examples.md]
P -->|需要确定性操作?| S[执行 scripts/*.py]
S -->|仅返回执行结果| P
P -->|需要结构约束?| T[读取 templates/*]
P --> O2[结构化结果输出]|-----------|---------------------------------|-----------------------------------------------------------------------------------------------------------|---------------------------------------------------|----------------------------------------|
| 🟦 阶段 | 阶段名称 | 加载内容 | 特点 | 结论 |
| 阶段 0 | Skill 元数据常驻(Always-on) | Skill 的 name、description(YAML 元数据) | * 常驻系统 Prompt * 极低 token 成本 * 仅「是否相关」判断,不进入具体执行逻辑 | Agent 只知道"有什么能力",不知道"怎么做",Skill 数量可规模化 |
| 阶段 1 | 相关性判断(Skill Routing) | 用户请求 + Skill 描述 | * 无需加载Skill内容 * 几乎无token消耗 | Skill 是被选择的,不是被强行调用的 |
| 阶段 2 | SKILL.md 加载(能力激活) | 进入Skill,Agent 读取 SKILL.md中的角色、流程、约束 | * 流程开始生效 * 模型行为被约束 * 推理路径收敛 | 从「自由 LLM」切换为「流程化 Agent」 |
| 阶段 3 | 按需资源访问(渐进式披露核心) | Agent 在执行过程中: * 遇到规则 → 读 reference.md * 遇到例子 → 读 examples.md * 遇到确定性逻辑 → 跑 scripts * 遇到结构约束 → 读 templates | * 用到才加载 * 避免上下文膨胀 * 高度模块化 | 知识 ≠ 上下文,Skill 可大规模扩展 |
| 阶段 4 | 确定性执行与结果输出(Execution & Output) | scripts/*.py 的执行结果 + 输出模板约束 | * 代码不进上下文 * 结果可校验 * 输出稳定 | 不确定性交给 LLM,确定性交给代码,最终按照模版约束进行输出 |
Agent Skills 与 MCP 的关系
**Agent Skills:**解决「做事的方法问题」,这类事情,应该按什么步骤做?有哪些规则?哪些地方不能自由发挥?它关心的是:流程是否正确、推理是否可控、输出是否稳定、是否可复用、可版本化,Skill 是"方法论的工程化封装"。
**MCP:**解决「系统访问问题」,Agent 能访问哪些工具?工具的输入输出长什么样?怎么安全、统一地调用?它关心的是:Tool 的发现、Tool 的 Schema、Tool 的调用方式、Tool 的权限与隔离,MCP 是"工具访问的标准协议层"。
Agent Skills 与 MCP 的关系,本质上是:一个解决"认知与方法"的问题,一个解决"连接与执行"的问题。真正的优秀的 Agent 系统,必须同时具备这两层能力。
Skill 决定"要不要用工具、用哪个工具、用来干嘛",MCP 决定"工具怎么被安全、标准、可扩展地使用"。

┌─────────────────────────────┐
│ Agent │
│ 目标拆解 / 推理 / 决策 │
├───────────────▲─────────────┤
│ Agent Skills │ ← 如何做(流程 + 方法论)
│ SOP / 规则 / 约束 / 脚本 │
├───────────────▲─────────────┤
│ MCP 协议层 │ ← 能看到什么 / 能连什么
│ Tool Discovery / Invoke │
├───────────────▲─────────────┤
│ 外部系统 / 工具 │
│ DB / API / SaaS / OS │
└─────────────────────────────┘Agent Skills 的适用场景
总结:当一个任务开始具备「流程性、可复用性、风险约束」中的任意两项时,就应该认真考虑 Agent Skills,口诀:重复 + 规则 + 风险 = Skill。
|----------|----------------|----------------|
| 判断维度 | 问题自检 | 是否适合 Skill |
| 流程是否固定 | 有没有明确步骤顺序 | ✅ |
| 是否重复出现 | 是否会反复执行 | ✅ |
| 输出是否有结构 | 是否需要 JSON / 表格 | ✅ |
| 是否有规则约束 | 是否有不能犯的错 | ✅ |
| 失败成本是否高 | 出错是否不可接受 | ✅ |
|-----------|--------------|----------------|
| 场景 | 原因 | 是否适合 Skill |
| 闲聊 / 创意写作 | 过度工程化 | ❌ |
| 一次性探索性任务 | 成本大于收益 | ❌ |
| 无规则、无流程任务 | Skill 没有约束对象 | ❌ |
| 极度主观判断 | 无法工程化 | ❌ |
二、Agent Skills的使用和案例
创建我的第一个 Agent Skill
手动创建(这是一个🌰)
Step 1:创建 Skill 目录结构
plugins/train-ticket/
├── README.md # 插件的主要说明文档
├── USAGE_GUIDE.md # 使用指南
└── skills/train-ticket-query/ # 具体的技能实现目录
├── SKILL.md # 技能的详细说明文档(核心文件)
├── README.md # 技能的快速入门文档
├── examples/ # 使用示例目录
│ ├── basic-query-example.md # 基础查询示例
│ └── complete-usage-example.md # 完整使用示例
├── references/ # 参考文档目录
│ └── api-integration.md # API集成相关文档
└── scripts/ # 脚本目录
├── browser_query.md # 浏览器查询相关文档
├── query_ticket.py # Python脚本
├── train_monitor.sh # Shell脚本
└── test_query.py # 测试查询脚本Step 2:编写 SKILL.md (核心)
---
name: train-ticket-query
description: 这哥skill基于用户提问 "查询火车票余票", "帮我查火车票", "查看车次余票", 通过浏览器访问12306网页获取余票信息并通过markdown的形式返回给用户。
version: 1.2.0
---
# 火车票余票查询
> 本 Skill **仅做一件事:浏览器基础查询余票**。
>
> 说明:12306 的余票 JSON 接口在很多网络环境下会触发风控(302/返回 HTML),因此本 Skill 不提供接口查询。
## 触发场景
- 你说:"帮我查明天北京西到驻马店西的余票"
- 你说:"查询 2026-01-28 北京南到上海虹桥余票"
## 需要你提供的信息
- 出发站(必填)
- 到达站(必填)
- 出发日期(必填):今天/明天/后天/YYYY-MM-DD
- 车次(可选):不填则输出全部车次
## 执行流程
1. 打开页面:`https://kyfw.12306.cn/otn/leftTicket/init`
2. 填写出发站、到达站、日期
3. 点击查询
4. 从结果列表抓取:车次、出发/到达、历时、各席别余票状态
### 人工介入点
如果出现登录/验证码/滑块/弹窗遮挡结果列表:我会暂停并告诉你具体要点哪里。你处理完后回复"已完成",我继续抓取。
## 输出格式(强约束,Markdown 表格)
1) 先输出一行摘要:
- 查询:`{from} → {to}`|日期:`{date}`|查询时间:`{now}`
2) 再输出 **Markdown 表格**(列头固定):
| 车次 | 出发→到达 | 历时 | 余票(按页面列头原样展开) |
|---|---|---|---|
| {trainNo} | {depart}→{arrive} | {duration} | {seat1}={status}<br/>{seat2}={status}<br/>... |
- "余票"这一列中,席别名称与顺序以 12306 页面列头为准;**按座次逐行展示**,使用 `<br/>` 换行。
## 支持文件
- `README.md`
- `scripts/browser_query.md`Step 3:编写其他文件(按需编写)---本案例不需要脚本,脚本文件只做占位,其他示例文件只做参考,大家按需编写。
README.md-插件的主要说明文档
# 火车票查询插件
> 最后更新:2026-01-27 19:38
本插件提供 **火车票余票查询** 能力,统一采用 **浏览器模式**:
- 由 Agent 在浏览器中打开 12306 余票查询页
- 填写出发站/到达站/日期
- 抓取车次与各席别余票,并以 Markdown 表格输出(余票按座次换行)
> 说明:由于 12306 接口风控原因,本插件 **不提供 12306 API 直连查询**、也 **不提供本地定时监控脚本**。
## 包含的 Skills
- `train-ticket-query` - 浏览器模式余票查询
## 使用指引
- [USAGE_GUIDE.md](./USAGE_GUIDE.md) - 插件使用指南
- [skills/train-ticket-query/SKILL.md](./skills/train-ticket-query/SKILL.md) - Skill 行为规范USAGE_GUIDE.md-使用指南
# 火车票余票查询插件使用指南
## 🎯 功能概述
本插件 **仅提供一个能力**:通过 **浏览器模式** 查询 12306 余票,并把结果整理为 Markdown 表格输出。
- 不提供:12306 API 直连查询
- 不提供:本地定时监控 / crontab 监控
- 不提供:通知/提醒/统计/批量脚本
## 📁 文件结构
```
plugins/train-ticket/
├── README.md
├── USAGE_GUIDE.md
└── skills/train-ticket-query/
├── SKILL.md
├── README.md
├── examples/
│ ├── basic-query-example.md
│ └── complete-usage-example.md
├── references/
│ └── api-integration.md
└── scripts/
├── query_ticket.py
├── train_monitor.sh
└── test_query.py
```
> 注:`scripts/query_ticket.py`、`scripts/train_monitor.sh`、`scripts/test_query.py` 为 **结构占位**,用于匹配仓库规范;实际能力以浏览器模式(A2)为准。
## 🚀 快速开始
你只需要在对话中对 Agent 说:
- "帮我查明天北京西到驻马店西的余票"
- "查询 2026-01-28 北京南到上海虹桥余票"
Agent 会在浏览器中打开:`https://kyfw.12306.cn/otn/leftTicket/init`,完成填写并抓取结果。
> 默认使用浏览器查询:本插件/Skill 不运行任何本地查询脚本(`scripts/*.py` 仅为结构占位)。
## ✅ 输出格式(Markdown 表格)
- 查询:`{from} → {to}`|日期:`{date}`|查询时间:`{now}`
| 车次 | 出发→到达 | 历时 | 余票 |
|---|---|---|---|
| {trainNo} | {depart}→{arrive} | {duration} | {seat1}:{countOrStatus}<br/>{seat2}:{countOrStatus}<br/>... |
> "余票"列按 12306 页面列头顺序展开,使用 `<br/>` 换行。
## 🙋 人工协助点
如果出现登录/验证码/滑块/弹窗遮挡结果列表,Agent 会暂停并明确告诉你需要点击哪里。
你处理完回复"已完成",Agent 会继续抓取。
## 📎 参考
- `skills/train-ticket-query/README.md`
- `skills/train-ticket-query/SKILL.md`
- `skills/train-ticket-query/scripts/browser_query.md`basic-query-example.md -基础查询示例
# 基础查询示例
你对 Agent 说:
- "帮我查明天北京西到驻马店西的余票"
Agent 输出(Markdown 表格,余票按座次换行):
- 查询:`北京西 → 驻马店西`|日期:`明天`|查询时间:`YYYY-MM-DD`
| 车次 | 出发→到达 | 历时 | 余票 |
|---|---|---|---|
| Gxxx | 07:05→10:14 | 03:09 | 商务座:有<br/>一等座:有<br/>二等座:候补<br/>无座:有 |complete-usage-example.md -完整使用示例
# 完整使用示例
## 示例:查询指定日期区间余票
你对 Agent 说:
- "查询 2026-01-28 北京西到驻马店西的余票"
Agent 会:
1. 打开 `https://kyfw.12306.cn/otn/leftTicket/init`
2. 填写出发站/到达站/日期
3. 点击查询
4. 抓取结果并按 Markdown 表格输出(余票按座次换行)
输出格式示例:
- 查询:`北京西 → 驻马店西`|日期:`2026-01-28`|查询时间:`YYYY-MM-DD`
| 车次 | 出发→到达 | 历时 | 余票 |
|---|---|---|---|
| Gxxx | 07:05→10:14 | 03:09 | 商务座:有<br/>一等座:有<br/>二等座:候补<br/>无座:有 |
## 常见卡点(需要你协助)
- 若出现登录/验证码/滑块/弹窗遮挡结果列表:按 Agent 提示在页面完成一次操作后回复"已完成",Agent 会继续抓取。api-integration.md - API集成相关文档
# 参考:为什么使用浏览器模式
本 Skill 采用浏览器方式查询 12306 余票,而不是直接调用 12306 JSON 接口。
## 原因
12306 的余票查询接口在很多网络环境下会触发风控,不允许直接通过接口获取余票数据:
- 返回 302 跳转到 `https://www.12306.cn/mormhweb/logFiles/error.html`
- 或返回 HTML 而非 JSON
这会导致"接口直连查询"不稳定。
## 解决方案
使用浏览器方式:
1. 打开 `https://kyfw.12306.cn/otn/leftTicket/init`
2. 填写出发站/到达站/日期
3. 点击查询
4. 抓取结果列表并以 Markdown 表格输出(余票按座次换行)browser_query.md - 浏览器查询相关文档
# 浏览器模式
本 Skill **仅支持浏览器模式**:由 Agent 在浏览器中打开 12306 页面、填写查询条件并抓取结果。
## 为什么不用接口查询
12306 余票查询 JSON 接口在很多网络环境下会触发风控拦截(常见表现:302 跳转到 `https://www.12306.cn/mormhweb/logFiles/error.html` 或返回 HTML),导致脚本不稳定。
## 操作步骤(Agent 自动执行)
1. 打开页面:`https://kyfw.12306.cn/otn/leftTicket/init`
2. 填写:出发站、到达站、日期(今天/明天/后天/指定日期)
3. 点击查询
4. 抓取结果表格:车次、出发到达时间、历时、以及页面列头对应的各席别余票状态
## 人工协助点
若出现以下情况,Agent 会暂停并请你协助:
- 登录
- 验证码 / 滑块 / 人机验证
- 弹窗/浮层遮挡结果列表(例如站点提示浮层)
你只需完成页面操作并回复"已完成/已关闭弹窗/已登录"等,Agent 将继续抓取。
## 输出格式(Markdown 表格)
- 查询:`{from} → {to}`|日期:`{date}`|查询时间:`{now}`
> 默认使用浏览器查询:本 Skill 不运行任何本地查询脚本。
| 车次 | 出发→到达 | 历时 | 余票 |
|---|---|---|---|
| {trainNo} | {depart}→{arrive} | {duration} | {seat1}:{countOrStatus}<br/>{seat2}:{countOrStatus}<br/>... |query_ticket.py - Python脚本
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""query_ticket.py
占位脚本:本仓库内的 train-ticket-query Skill **仅支持浏览器模式(A2)**。
之所以仍保留该文件,是为了匹配插件目录结构规范;它不会执行 12306 API 直连查询。
使用方式:请直接在对话中让 Agent 执行浏览器查询。
"""
def main() -> int:
print("[train-ticket-query] 本 Skill 仅支持浏览器模式(A2),不提供 API 直连查询脚本。")
print("请参考:plugins/train-ticket/skills/train-ticket-query/scripts/browser_query.md")
return 0
if __name__ == "__main__":
raise SystemExit(main())train_monitor.sh - Shell脚本
#!/bin/bash
# train_monitor.sh
#
# 占位监控脚本:本 Skill 仅支持浏览器模式(A2)。
# 由于浏览器自动化与人工介入(验证码/登录等)强相关,本仓库不提供可离线运行的本地监控脚本。
echo "[train-ticket-query] 本 Skill 仅支持浏览器模式(A2),不提供本地监控脚本。"
echo "请在对话中直接让 Agent 执行查询。"
exit 0test_query.py - 测试查询脚本
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""test_query.py
占位测试脚本:本 Skill 仅支持浏览器模式(A2)。
由于浏览器自动化能力由运行时 Agent 提供,这里不做本地可执行的接口测试。
"""
def main() -> int:
print("[train-ticket-query] 本 Skill 仅支持浏览器模式(A2),无需本地 API 测试。")
print("请参考:plugins/train-ticket/skills/train-ticket-query/scripts/browser_query.md")
return 0
if __name__ == "__main__":
raise SystemExit(main())README.md - 技能的快速入门文档
# 火车票余票查询
> 本 Skill **仅做一件事:浏览器基础查询余票**。
## 用法
直接对 Agent 说:
- "帮我查明天北京西到驻马店西的余票"
- "查询 2026-01-28 北京南到上海虹桥余票"
Agent 会在浏览器中打开 `https://kyfw.12306.cn/otn/leftTicket/init`,填写出发站/到达站/日期并抓取结果列表。
## 你需要提供的信息
- 出发站(必填)
- 到达站(必填)
- 出发日期(必填):今天/明天/后天/YYYY-MM-DD
- 车次(可选):不填则输出全部车次
## 输出格式(Markdown 表格)
- 查询:`{from} → {to}`|日期:`{date}`|查询时间:`{now}`
| 车次 | 出发→到达 | 历时 | 余票(按页面列头原样展开) |
|---|---|---|---|
| {trainNo} | {depart}→{arrive} | {duration} | {seat1}={status}<br/>{seat2}={status}<br/>... |
## 人工协助点
如出现登录/验证码/滑块/弹窗遮挡结果列表:按 Agent 提示在页面完成一次操作,然后回复"已完成",Agent 将继续抓取。
## 支持文件
- `scripts/browser_query.md`Step 4:调试你的Skill
🍳按照上面的步骤,已经完成了一个简单的火车票余票查询skill的创建,现在让我们看下效果吧!
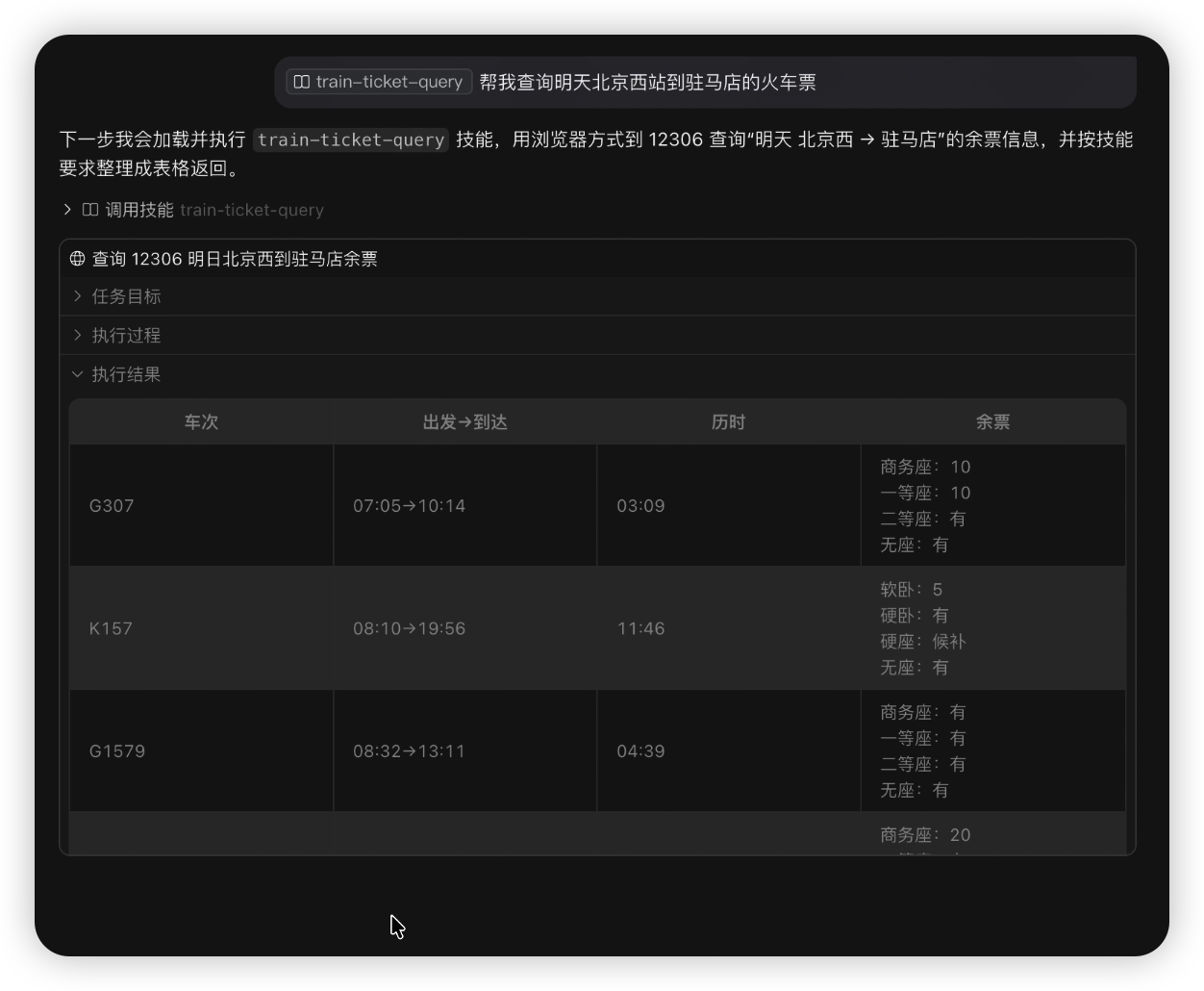
调用Skill自动创建
上面的步骤是手动创建的SKill,当然我们也可以通过公共的Skill根据需求自动创建你的Skill,这样就省时省力多了,你只需要负责check它创建的内容是否符合你的预期并做简单的修改即可。
Step 1:导入Skill
在安装 Skill 之前,你需要先获取需要的 Skill 文件包。比如官方 Skills 仓库:https://github.com/anthropics/skills/tree/main,里面就有很多已经做好的 Skills。
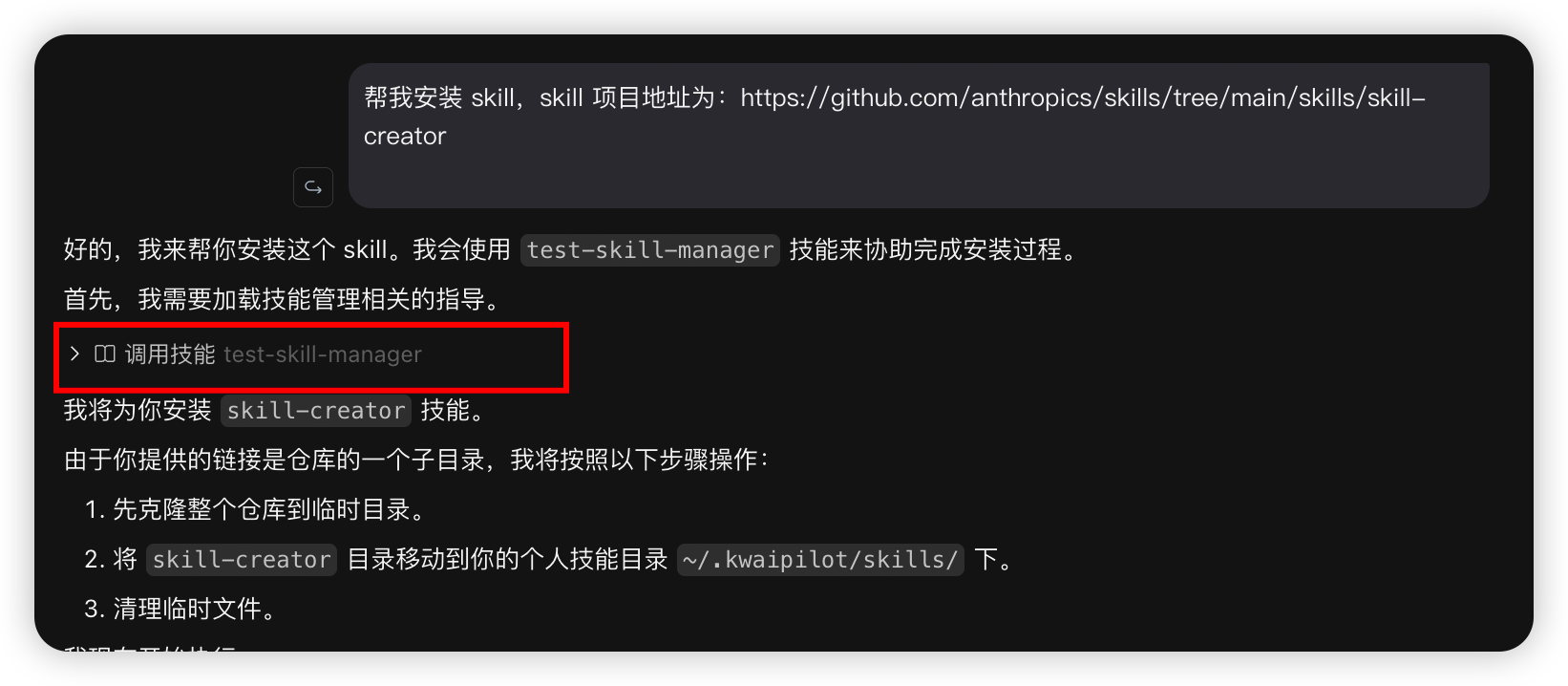
你可以让智能体替你自动安装 Skill,比如直接对Kwaipilot发送:帮我安装 skill,skill 项目地址为:https://github.com/anthropics/skills/tree/main/skills/skill-creator
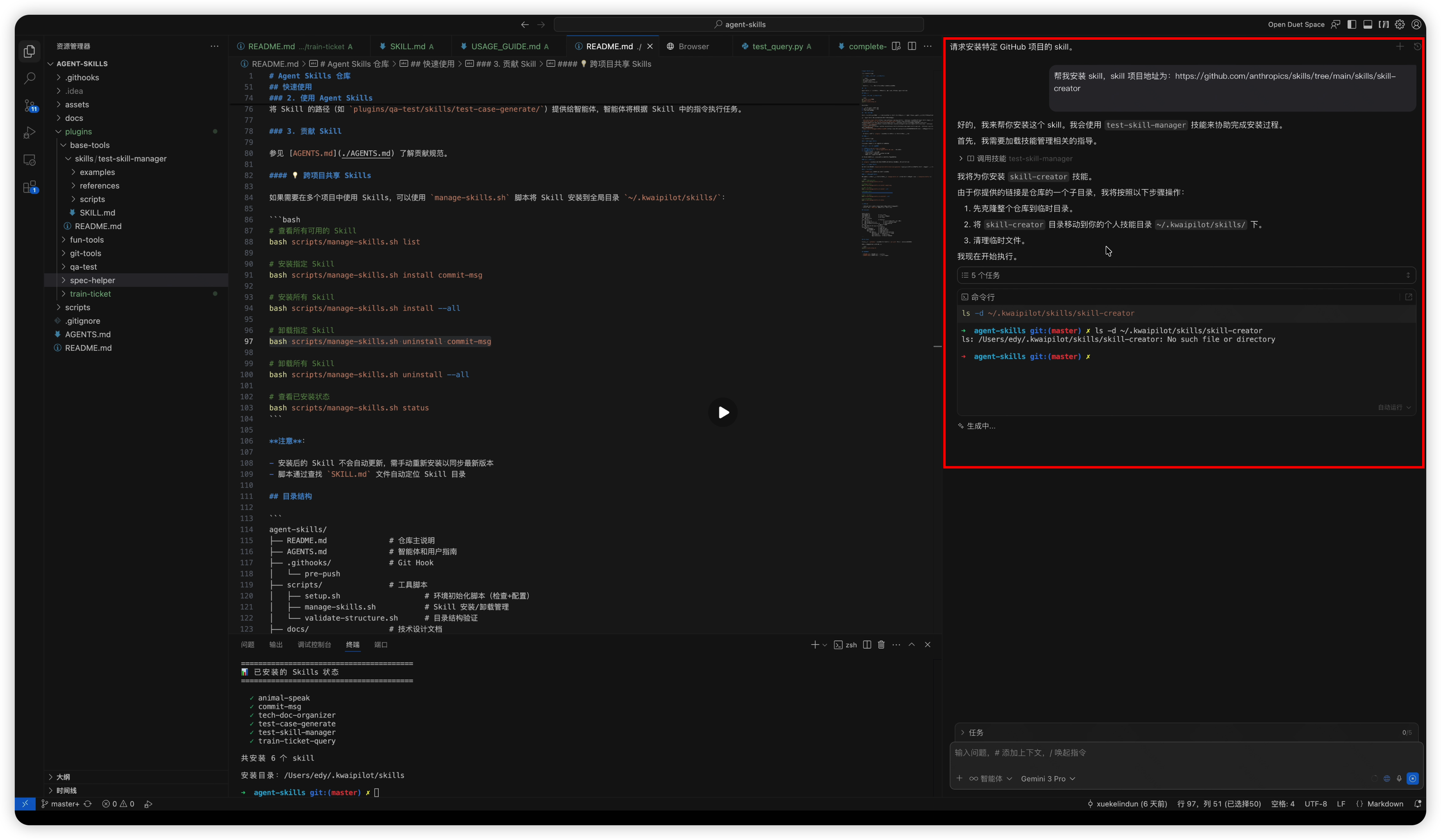
Step 2:调用技能创建skill
调用技能创建自己的skill可以使用skill-manager或者skill-creator,功能效果是差不多的,你可以直接在IDE中引用这个skill并对智能体说:帮我创建一个xxx的skill即可。
Step 3:生成完成,修改+调试
agent会自动调用你引用的skill按照需求帮你生成skill,生成完成后只需要你按照实际使用方式修改+调试即可,就是这么简单!!!

如何使用 Agent Skills(本地IDE)
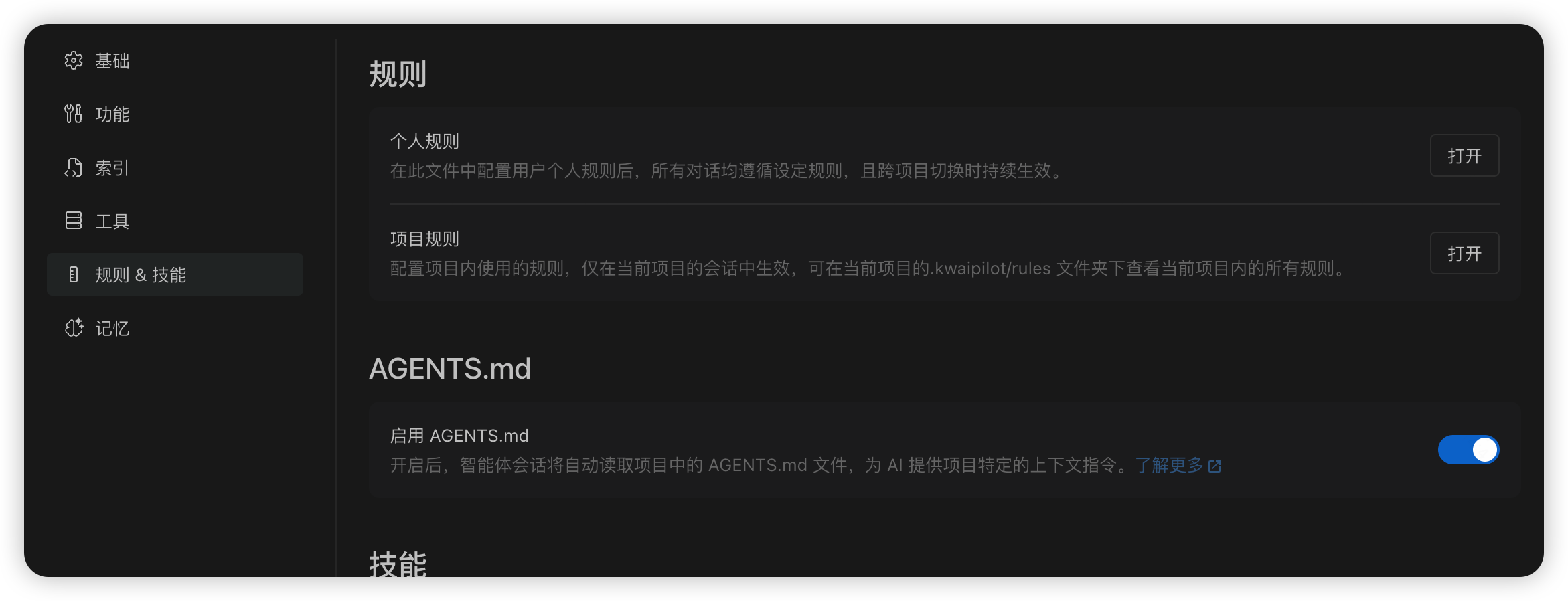
公司的Kwaipilot IDE 目前已经支持使用 skills,前提是你需要安装最新版本的编译器,启用 Early Access 版本和AGENTS.md功能,就可以直接使用啦!其他的外部编译器也支持使用skill,比如Cursor、VS code、Claude等,想了解的话可以自行探索,这里只以Kwaipilot使用为例。
下载Kwaipilot IDE并启用AGENTS.md
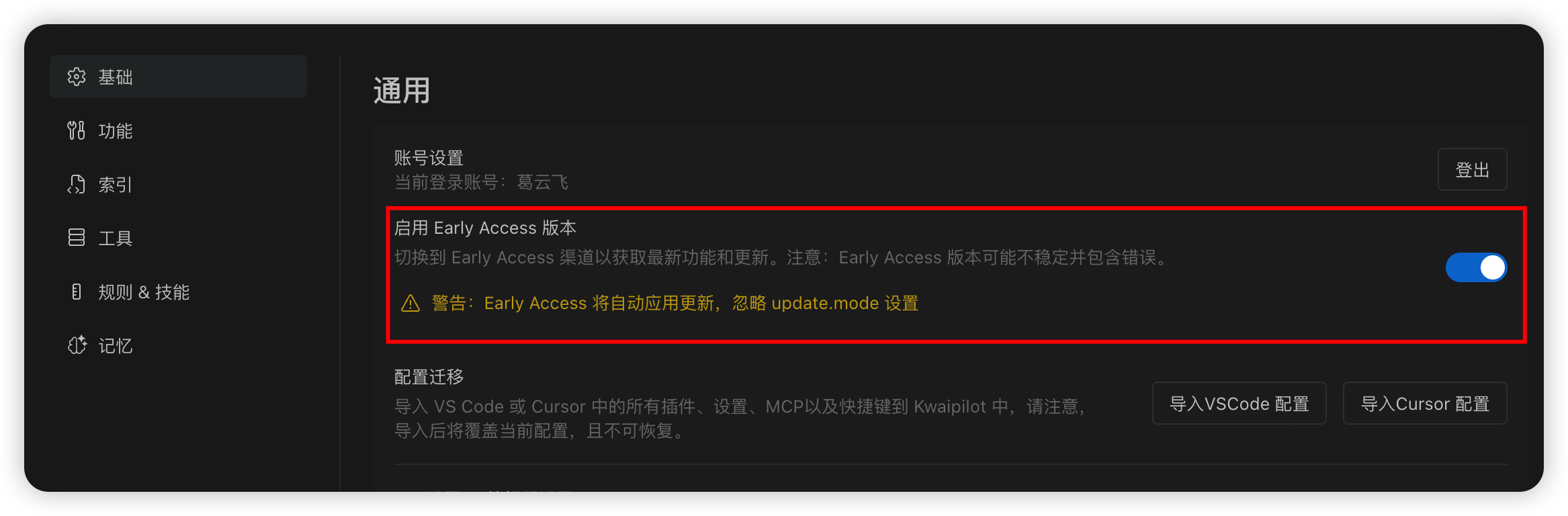
导入需要的skill
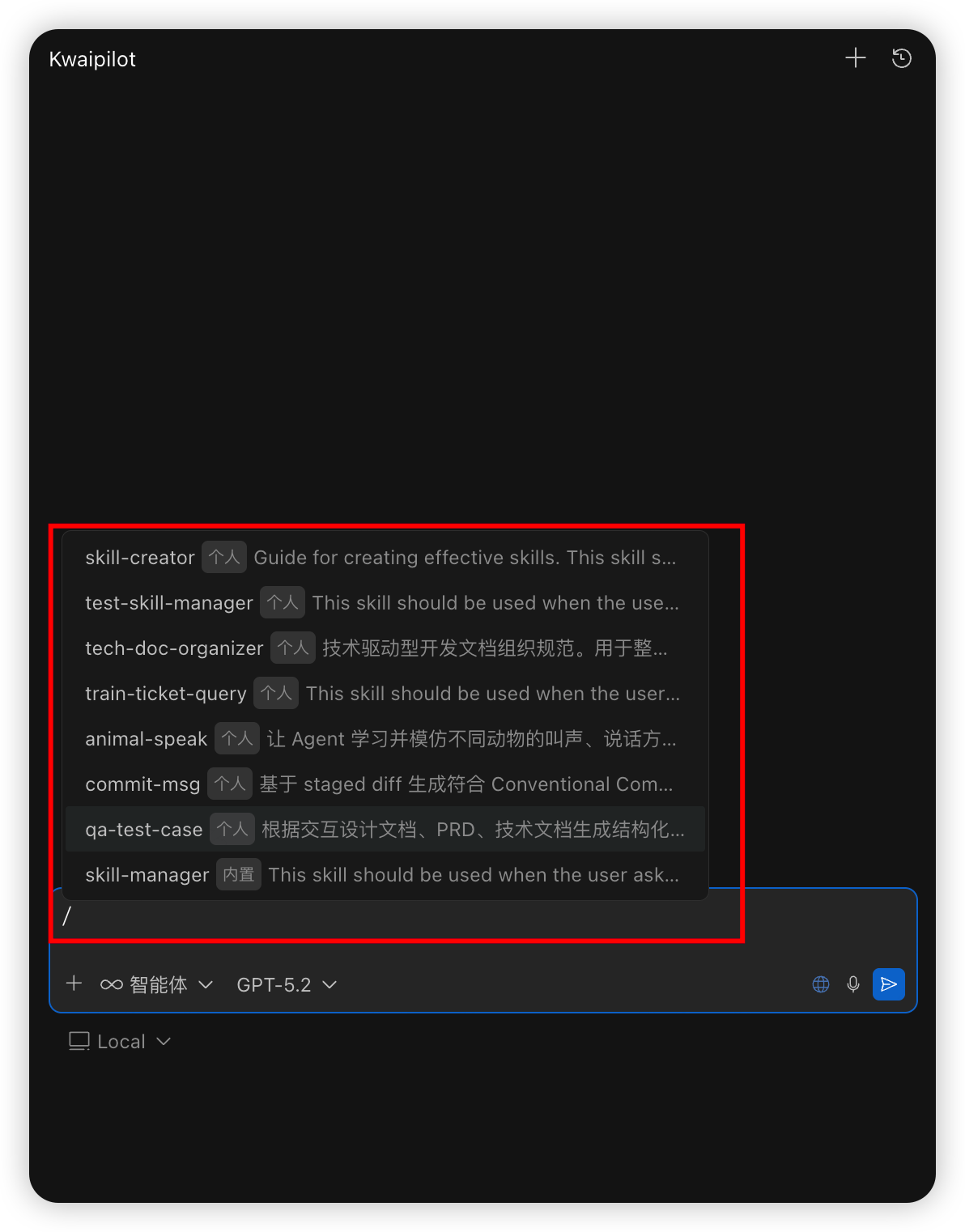
大家可以根据上面的导入skill的方式导入自己所需要的skill到本地,然后进行使用。下面放一些公共的skill链接
一些 Skills 市场:
https://github.com/anthropics/skills#
使用skill
自己需要的skill导入以后直接发送需求开始使用即可,可以直接引用skill使用或者用户提问需求和skill的名称、描述匹配就能自动调用Skills,执行任务。
接下来,创建并使用您的第一个Skill吧!🎉🎉🎉