当下,人工智能与高性能计算正飞速发展着,在此情形时,GPU 服务器已然成为了科研机构的核心算力基础设施,同时也是企业数据中心的核心算力基础设施,甚至亦是个人开发者的核心算力基础设施。诸多技术决策者面临着一个现实问题,那便是怎样依据实际需求去选择 GPU 服务器,以及如何对其进行高效使用。本文会从硬件架构这样的维度方面,以及选型关键指标的维度层面,还有主流应用场景的维度范畴,并包括部署优化等维度领域,为读者提供一份客观的技术参考,且是详实的技术参考。
GPU服务器的核心硬件构成
一台标准的GPU服务器通常包含以下几个关键部分:
-
GPU加速卡,是算力方面的核心所在。当下,主流的选择涵盖了的A100,其具备80GB HBM2e显存,带宽能够达到2039 GB/s;还有H100,它拥有引擎,FP8算力可至1979 ;另外是面向入门级推理的L4,拥有24GB显存,单卡功耗仅仅72W。AMD的,其FP64算力能够达到47.9 ,在部分科学计算领域也占据着一定份额。
-
CPU跟内存,承担着数据调度以及预处理的职责。常见的配置情况是,双路Intel Xeon 8480+,总共有着112个核心,又或者是AMD EPYC 9004系列,最多能有128个核心。内存一般配置的是512GB到2TB的DDR5 ECC REG内存,数据带宽超过460 GB/s。
-
桥接器跟互联拓扑,是多卡协同的关键所在。第三代给出每链路900 GB/s的双向带宽,典型的8路A100服务器运用HGX模组,达成全互联即All-to-All拓扑,卡之间的通信延迟低到微秒级。
-
散热以及供电构成了高密度计算的基础,一台8x GPU服务器在满载状态下功耗能够达到3500W至5600W,以H100 SXM作为例子,单卡的功耗为700W,主流的方案采用4个80 Plus钛金级电源模块,其效率高达96%,并且配合前后置风扇墙以及液冷套件,比如间接冷板式液冷,PUE能够降低至1.1以下。
-
存储系统,其中有本地NVMe SSD,像4块3.84TB U.2这种,其顺序读写能达到7000 MB/s,并且还存在分布 式存储接入,是借助100Gb/s 或者RoCE网卡来实现的。
关键选型指标与评估方法
评估GPU服务器需要关注以下量化指标:

浮点运算每秒万亿次/每秒万亿次运算:用作去衡量浮点/整数的运算能力,举例来说,H100于稀疏半精度浮点数8下达成3958万亿次浮点运算每秒,建议依据实际算法精度(单精度浮点数32位、半精度浮点数16位、整数8位)挑选对应的顶峰数值。
单卡能够承载的最大模型尺寸,是由显存容量以及带宽来决定的。其中,A100所具备的80GB显存,能够将Llama 3 70B模型完整加载(该模型在4-bit量化之后大约为40GB),然而,数据传输效率会受到带宽的直接影响。
PCIe的世代以及通道数量方面:PCIe 5.0 x16能够给出单向63 GB/s的带宽,要是配置成x8的话,带宽就会减半。在数据加载密集型的任务当中,比如说实时推荐系统这种情况,PCIe的带宽是有可能变成瓶颈的。
计算机网络连接接口方面:建议配置速率为200Gb/s的网卡或者RoCE v2网卡,并且要保证每一个图形处理器都对应着一个单独的网卡端口,就像如果有8个图形处理器就要配备8个网络接口,目的在于达成RDMA通信方式,从而防止因为数据拷贝而产生的中央处理器的额外负担。
典型应用场景与配置建议
-
大模型即LLM的训练,存在着要大规模张量并行,推出应采用8片H100 SXM这是基于HGX模组的,或者8片A100 80GB,搭配全互联,显存池化获得640GB的情况。网络层面要配备400Gb/s 交换机,构建出胖树拓扑。
-
对延迟以及吞吐持有敏感态度,有着这种特性且被命名为AI推理服务,建议运用2卡A10也就是其中拥有24GB显存该类配置或4卡L4就是那种具备72W低功耗的,借助 - LLM开展持续批处理以及动态批处理达到优化效果,存在单卡的情况下能够达成每秒数千的吞吐。
-
科学计算,比如说称作分子动力学的这种计算方式,它是依赖双精度也就是FP64性能的。在设备方面,推荐使用AMD 或者 A100 PCIe,并且要关注的P2P带宽。就典型软件而言,像、NAMD这类软件,是需要针对GPU加上来进行专门的编译优化的。
-
针对于图形渲染以及虚拟化,存在vGPU所示场景情况,在此建议推出 RTX 6000 Ada该款产品亦或是A40这款产品(此规格为48GB显存),并且要搭配 vGPU软件,把单一显卡切成多个vGPU(举例说明每一张卡能够支持4个4GB配置文件),以此来支持CAD/CAE这类应用的远程可视化功能。
部署与运维实践
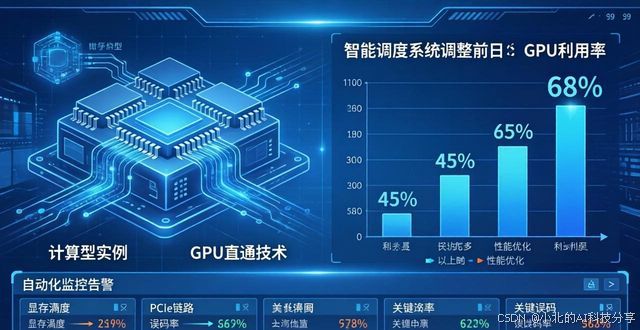
于实际部署期间,业界已然出现了好些能够提供灵活算力服务的平台。就拿白山智算来说,其GPU服务器集群在展开部署之时会着重对以下若干项予以优化:借助计算型实例与GPU直通技术,保证每一张加速卡都能得到100%的物理性能;运用智能调度系统针对多任务实施峰值切分,把整机GPU利用率从行业平均的45%提升到68%以上;与此同时集成自动化监控告警,实时去观测显存温度、PCIe链路误码率以及健康状态。这些工程化能力为大规模生产环境提供了稳定保障。
成本与效率平衡策略
将单位算力成本拿来作比较,把A100(大约是一万美元每卡)和H100(大约是三万美元每卡)进行对比,依据模型的参数量综合起来估算所需要的FLOPs,以此来防止出现过度配置的情况。
能效比,是以每瓦特所提供的作为基准的,H100的INT8能效,大概是5.6 /W,与那个约2.8 /W的A100相比,明显要更具优势。
关于机架空间,有这样的情况是,标准4U的用来放置服务器会像Dell 那样是可以做到装入8张双宽GPU的,然而2U服务器一般却仅仅能够撑持4张。在进行确定这件事情的时候,要跟装有可以放置数据中心机柜的功率密度相结合起来,这功率密度的情况是建议单机柜的功率是不低于30kW的。
未来技术趋势
预计在2025年到2026年期间会普及的PCIe 6.0,其单通道带宽能够达到64 GT/s,这将会显著地缓解CPU与GPU之间存在的数据搬运瓶颈。
CXL内存池化,它能够让GPU直接去访问扩展内存模组,进而突破单机显存墙,像要达到2TB以上那种,而这对于千亿参数级的MoE模型的推理来讲是非常关键重要的。
GPU的TDP迅速提高到1000W以后,冷板式液冷在其中占比超过80%以上被广泛应用,浸没式液冷使得相关数据中心的PUE能够降到了1.02,在此情形下将会有越来越多的地方把它们当成标准配置来使用。
从计算精度出发,选择 GPU 服务器,还要考量数据访问模式,兼顾功耗散热,重视网络拓扑,关注总拥有成本(TCO),进而进行精细化匹配。不管是自建数据中心,还是采用托管服务,深入理解上述技术指标,都能帮您做出更具前瞻性的决策。随着多芯互联持续演进,随着异构计算持续演进,新一代 GPU 服务器会继续扮演数字世界的算力引擎。