摘要:本文梳理 RAG 五阶段技术演进------从 Naive RAG 的基础框架到 Agentic RAG 的自主决策,并探讨长上下文窗口时代 RAG 的定位与演进方向。
开发者让 AI 查询公司代码仓库中某个接口的调用规范,返回的函数签名和参数列表与实际代码完全不符;客服系统在回答退换货政策时张冠李戴,把 A 品类的规则套用到了 B 品类上。这类问题的根源在于:大模型的知识停留在训练数据截止的那一天,它无法真正"看"到用户的私有数据。
RAG(Retrieval-Augmented Generation,检索增强生成)正是为解决这一矛盾而生的------先从外部资料库检索相关内容,再让模型基于这些真实信息组织回答。自 2020 年 Meta 提出这一概念以来,RAG 已从学术论文逐步成为企业级 AI 应用的主流方案之一。
本文将梳理 RAG 从基础框架到智能体驱动的五阶段技术演进。
Naive RAG:从文档到回答的三个步骤
Naive RAG 遵循传统的"检索-阅读"框架,主要由三个核心步骤组成。整个过程可以类比成图书馆的运作:先把书拆成章节编目上架,读者提问时检索书架,找到相关内容后用通俗语言总结回答。
1. 索引(Indexing)
这是预处理阶段。系统首先将各种格式的原始数据提取为统一纯文本,再按合理的粒度分割成文本块(Chunks),最后用 Embedding 模型编码为向量并存入向量数据库(如 Milvus、Qdrant)。预处理环节中,文档解析和分块策略的质量直接决定后续所有环节的上限。
2. 检索(Retrieval)
当用户提出查询时,系统使用相同的 Embedding 模型将查询转化为向量。通过计算查询向量与数据库中各文本块向量的语义相似度,检索出相关性最高的前 K 个文本块作为增强上下文。检索环节是全流程的核心瓶颈:若检索召回的内容存在噪声、缺失或因分块导致上下文断层,下游大模型的推理能力将无从发挥。
3. 生成(Generation)
将原始查询与检索到的文档块合成一个连贯的提示词(Prompt),由大语言模型(LLM)据此生成最终答案。模型不仅要理解检索到的内容,还需要判断哪些信息相关、哪些可以忽略,最终用自然语言组织出连贯、准确的回答。
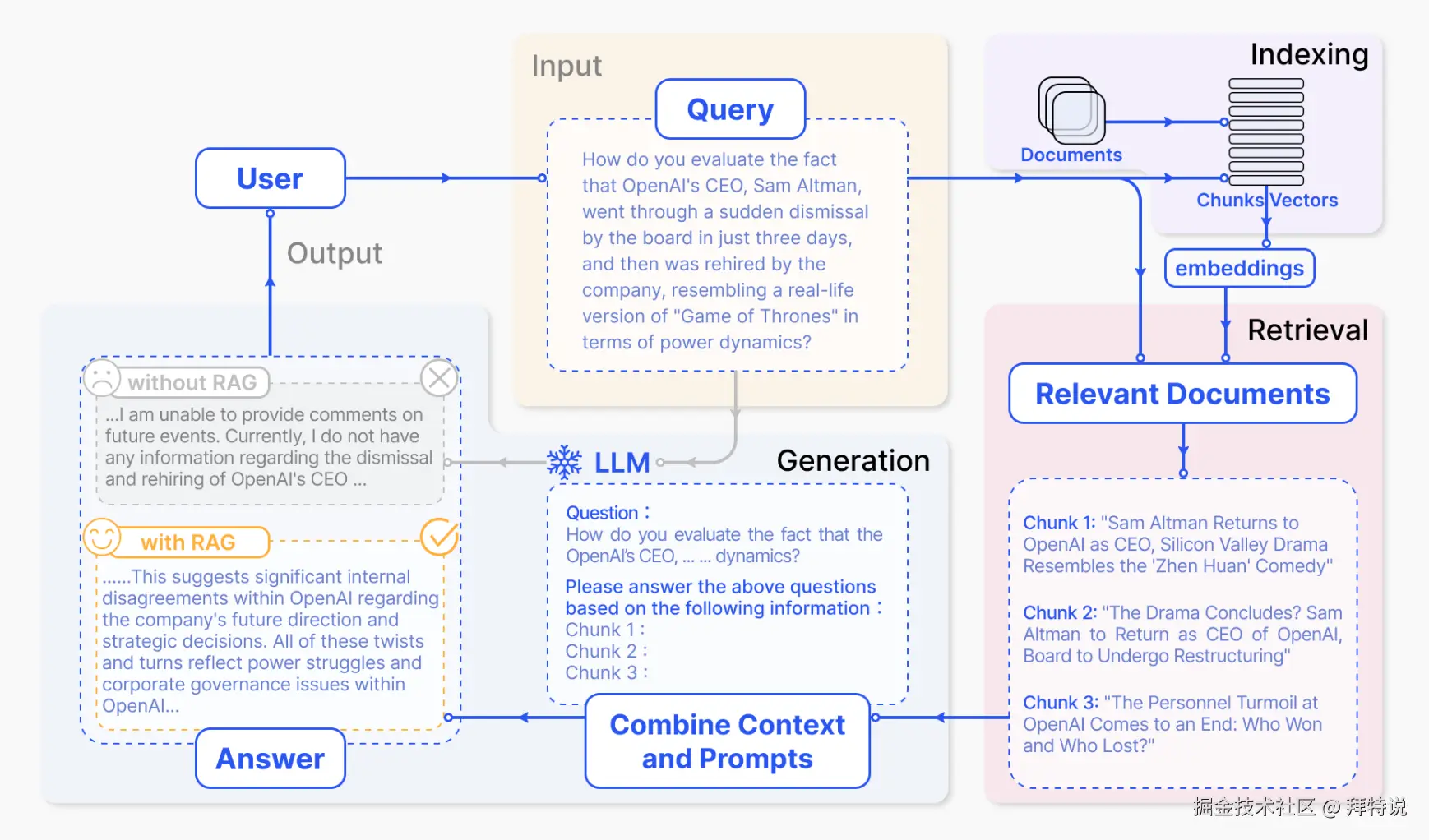
Advanced RAG:从查询到排序的链路升级
Naive RAG 的检索环节存在几个结构性瓶颈:用户查询语义模糊、文本块语义不完整、向量检索对精确关键词不敏感、初步检索排序粒度不足。Advanced RAG 正是针对这些痛点,从查询、分块、检索和排序四个方向展开优化。
1. 查询重写
查询重写解决的是"提问不清晰"的问题。常见的策略有三种:HyDE(Hypothetical Document Embedding)让模型先根据问题"假写"一个答案,再用假答案做检索,从而利用语义空间相似性提升向量匹配精度;Multi-Query 将原始问题改写为多个版本并行检索后合并,降低片面召回的风险;Step-back Prompting 则将具体问题抽象为更加宽泛的上位概念,先检索大背景再缩小范围。
2. 语义分块
语义分块(Semantic Chunking)解决的是"分块方式不当"的问题。固定大小分块最大的风险是把一个完整意思从中间切断。语义分块用 Embedding 模型计算相邻段落的相似度,当语义差异超过阈值时才进行分块。智能体分块(Agentic Chunking)则在此基础上更进一步------直接调用 LLM 的语义理解能力进行自适应边界判定,对文本做细粒度的语义解构,确保每个分块都是一个逻辑完备的语义单元。
3. 混合搜索
混合搜索解决的是"单一检索存在局限性"的问题。向量检索擅长语义层面的匹配,但对精确实体名称并不敏感。BM25 这种传统关键词检索正好相反:精于匹配特定词汇,但无法理解同义表达。混合搜索将两者并行执行,并利用 RRF(Reciprocal Rank Fusion)等算法融合结果。
4. 重排序
重排序(Reranking)解决的是"初步检索排序不够精细"的问题。检索阶段通常返回 50-100 个候选文本块,但受限于模型上下文窗口,实际能使用的仅 3-5 个。Reranker 引入更精细的模型对结果做二次排序:先在初步检索阶段计算整体相似度,再在重排阶段逐词对比问题和文档的对应关系。主流方案包括 Cohere Rerank、BGE-Reranker 和 ColBERT。
Modular RAG:将流水线分解为可组装的组件
无论是 Naive RAG 还是 Advanced RAG,本质上都遵循预设的流水线------Naive RAG 是"索引→检索→生成"的单向流程,Advanced RAG 在检索前后增加了优化环节,但数据仍然从前一个节点单向流向后一个节点,中间没有分叉,也没有回路。当优化手段不断叠加,这种固定流水线结构本身就成了扩展瓶颈。
Modular RAG 的核心思路是将检索和生成的流水线分解为独立且可重用的组件,每个组件都可以被替换、增强或重新配置,以适配不同的任务需求。系统不再是"文档进来、答案出去"的固定流水线,而是一个由可插拔模块组成的可组合流水线(Composable Pipeline)。
在这套组件化架构下,模块间的交互不再局限于单向顺序执行,而是支持条件分支、并行检索和循环迭代。例如,FLARE 根据模型置信度动态决定是否触发检索,CRAG 在文档检索质量不足时自动降级到网络搜索,ITER-RETGEN 将上一轮的生成输出反馈为下一轮的检索输入。通过引入 Search、Routing、Memory、RAG-Fusion 等专业化模块并允许自由编排,同一套架构可以适配从简单问答到多步推理的不同任务类型。
Modular RAG 的核心价值在于将系统搭建从"逐段硬编码"转向"声明式组装"。LlamaIndex、LangChain 和 Haystack 等主流框架均已原生支持模块化编排,开发者可以按需组合检索策略、路由规则和生成逻辑,大幅降低了复杂 RAG 系统的构建和维护成本。
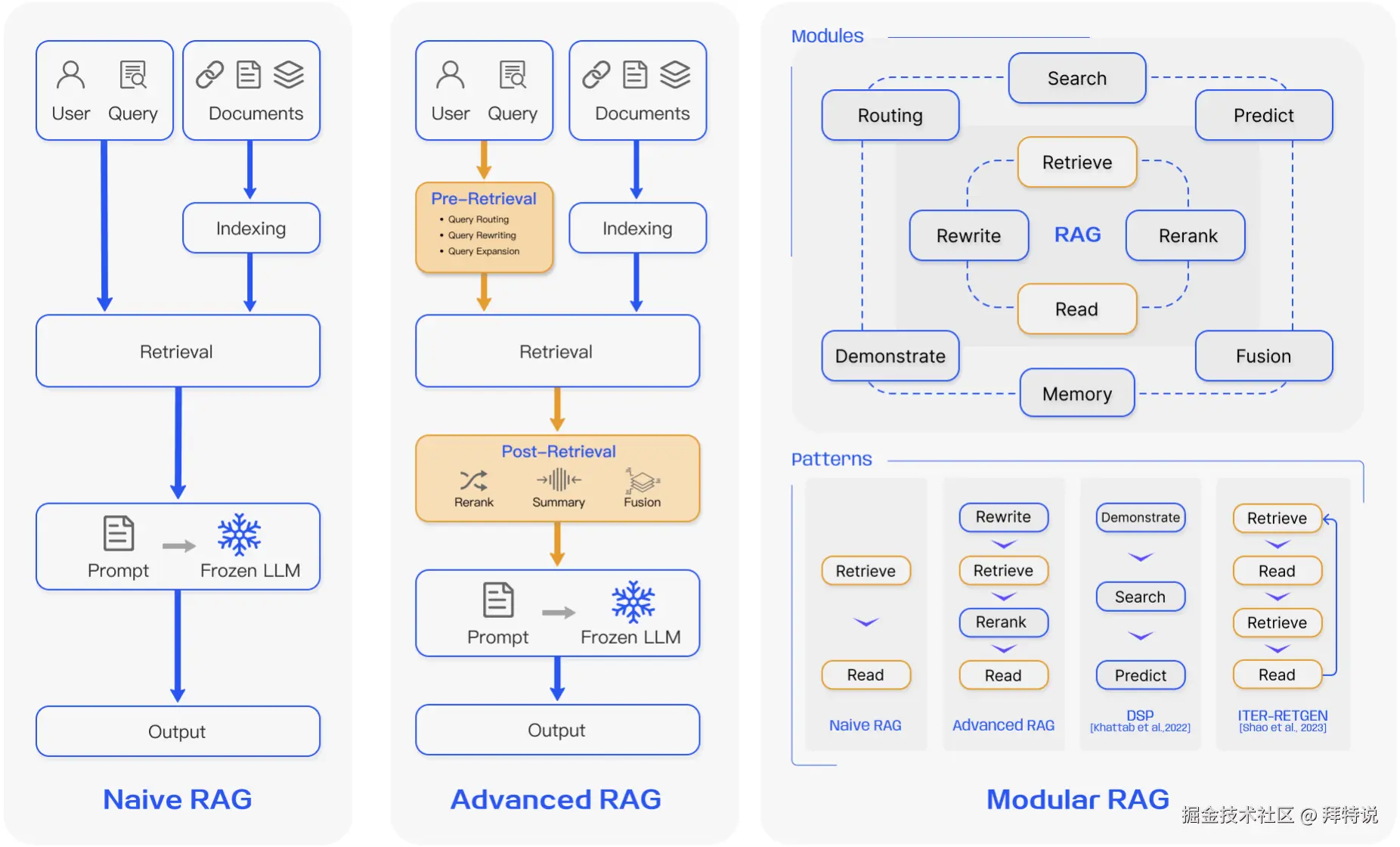
Graph RAG:用知识图谱补齐全局视野
传统 RAG 中采用的向量检索基于语义相似度召回文本块,但无法捕获信息之间的关联关系。面对需要跨文档综合推理的问题,例如归纳多份报告中的趋势因果链,向量检索只能返回各自独立的语义片段,难以重建完整的逻辑脉络。
Graph RAG 的核心思路是通过集成图数据结构来增强 RAG 系统,利用实体间的关系和层级进行多跳推理和上下文增强。微软在 2024 年提出的方案中,先用大模型从文档中提取实体与关系构建知识图谱,再通过社区检测将图谱分层聚类为包含紧密关联实体的"社区",检索时同时查询向量和图谱结构,使系统能够沿实体关系链路进行"顺藤摸瓜"式的推理。
在实体关系密集的垂直领域,Graph RAG 已展现出差异化价值:医疗诊断中的"症状→疾病→用药禁忌"推理链路、法律研究中的"判例→法条→司法解释"跨文档关联,均超出传统向量检索的能力边界。微软论文的评测数据显示,全面性方面,Podcast 数据集中间级摘要胜率达 57%(p<.001),News 数据集低级社区摘要胜率达 64%(p<.001)。Token 效率方面,C3 低级社区摘要比原文总结节省 26%-33% Token,C0 根级摘要节省超 97%。
但 Graph RAG 的代价也不低:构建知识图谱需要消耗大量 LLM Token 做实体与关系抽取,索引阶段的耗时远高于纯向量方案。它更适合文档质量高、需要全局推理的场景,而非对延迟敏感的即时交互领域。
Agentic RAG:让 Agent 自主决策
传统 RAG 的核心局限在于缺乏显式的控制层:系统无法自主决定何时检索、如何改写查询、何时已获取足够信息可以停止检索。这种模式对简单事实问答够用,但面对需要多步推理或动态调整策略的复杂任务就显得力不从心。
Agentic RAG 的核心思路是引入这层控制------由智能体根据问题复杂度和检索结果的充分性,自主决策每一步的操作。目前支撑这一能力的关键设计模式主要有四种:反思(Reflection),即评估自身输出质量并迭代改进;规划(Planning),即将复杂问题分解为子任务按序执行;工具调用(Tool Use),即在检索之外调用搜索引擎、API 等外部工具;多智能体协作(Multi-Agent),即多个专业化智能体分工处理不同子任务。
基于这些模式,目前已形成几种典型的 Agentic RAG 实现形态。CRAG(Corrective RAG)在检索后评估结果相关性,不够好就从向量检索切换到网络搜索重新查,体现了纠错模式;Self-RAG 在生成过程中逐段产生"反思标记",判断是否需要补充检索再继续,将检索决策从"一次性"变成"按需触发",体现了反思模式;Adaptive RAG 根据问题复杂度动态路由------简单问题跳过检索直接回答,复杂问题走多步检索流程,本质上是规划与路由的结合。
一项对比评测在 FiQA、NQ、FEVER 等数据集上的结果显示,Agentic RAG 在用户意图识别和查询重写等方面表现更优,展现了自主决策带来的检索质量提升。但是,Enhanced RAG(即本文中的 Advanced RAG)在处理宽领域问题时(如事实验证)更加高效且稳定。此外,Agentic RAG 的运行成本显著更高,整体成本最高可达 Enhanced RAG 的 3.6 倍。
长上下文窗口,真的能取代 RAG 吗
2026 年,主流前沿模型(DeepSeek V4、GPT-5.5、Claude Opus 4.7 等)的上下文窗口均已突破 1M Token,百万上下文已从前沿实验走向主流模型的标准配置。"RAG 已死"的论断一度甚嚣尘上,但随着企业级场景的大规模落地,行业共识正在收敛到一个更审慎的判断。
长上下文的核心优势在于全局信息处理能力。模型能够一次性接收完整证据集,避免检索过程中的信息损耗,在跨文档综合总结、代码仓库全局分析、复杂关系推理等场景下表现显著优于传统 RAG。换言之,当任务需要"纵观全局"而非"精准定位"时,长上下文提供了更完整的推理基础。
然而 RAG 在工程实践中仍具备不可替代的特性。知识库规模上,企业文档库通常可达数千万甚至数亿 Token 级别,远超单次上下文窗口的上限;数据时效性上,RAG 通过索引更新实现毫秒级知识刷新,无需重新训练或全量注入;成本与延迟上,1M Token 单次调用的费用和响应延迟显著高于 RAG 检索+生成,在高吞吐生产环境中差异尤为明显;可追溯性上,RAG 的检索路径透明、失败可监控可归因,而长上下文的推理黑箱中产生的错误往往难以定位。
当前行业的主流观点是:检索负责缩小范围,长上下文负责深度推理。先用混合检索从海量文档中召回候选集,再由长上下文模型完成综合分析与生成。不同场景下,纯长上下文、纯 RAG 和二者协同各有适用区间,需按具体需求评估。
写在最后
回顾 RAG 五年的演进路径,本质上是在解决同一个问题:如何在有限的计算资源下,让模型"看到"最准确、最完整的外部知识。Naive RAG 建立了基础框架,Advanced RAG 修补了检索环节的漏洞,Modular RAG 将整条流水线分解为独立且可重用的组件,Graph RAG 补上了全局推理的能力,Agentic RAG 让系统拥有了自主判断的灵活性。
RAG 的效果上限由数据质量决定,知识库中的矛盾、噪声和过时信息会沿流水线一直渗透到生成环节。从技术演进趋势看,RAG 正在超越"检索+生成"的单一流水线,向融合知识图谱、Agent 和长上下文窗口的知识增强平台演进。