广义表

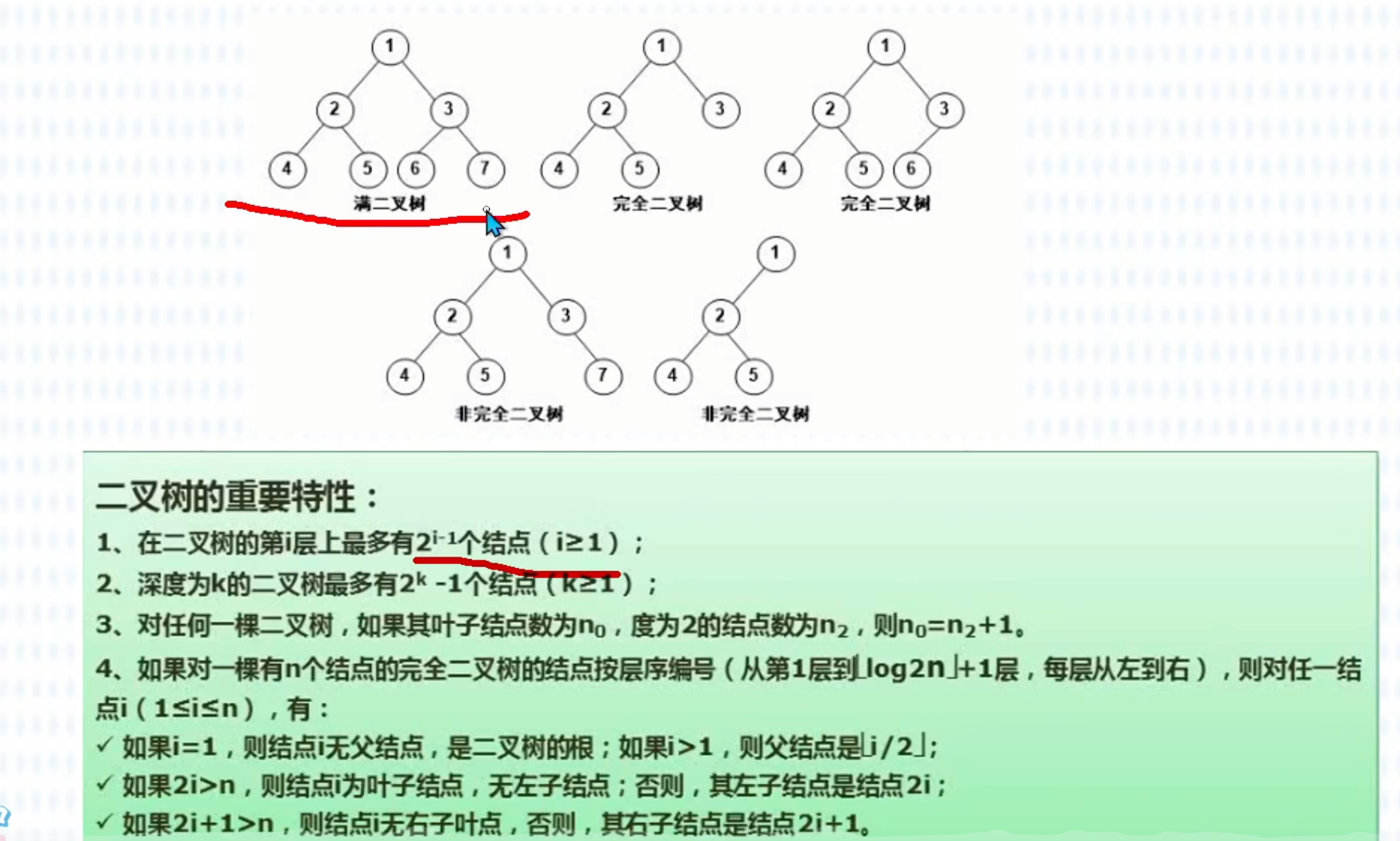
二叉树的基本特性
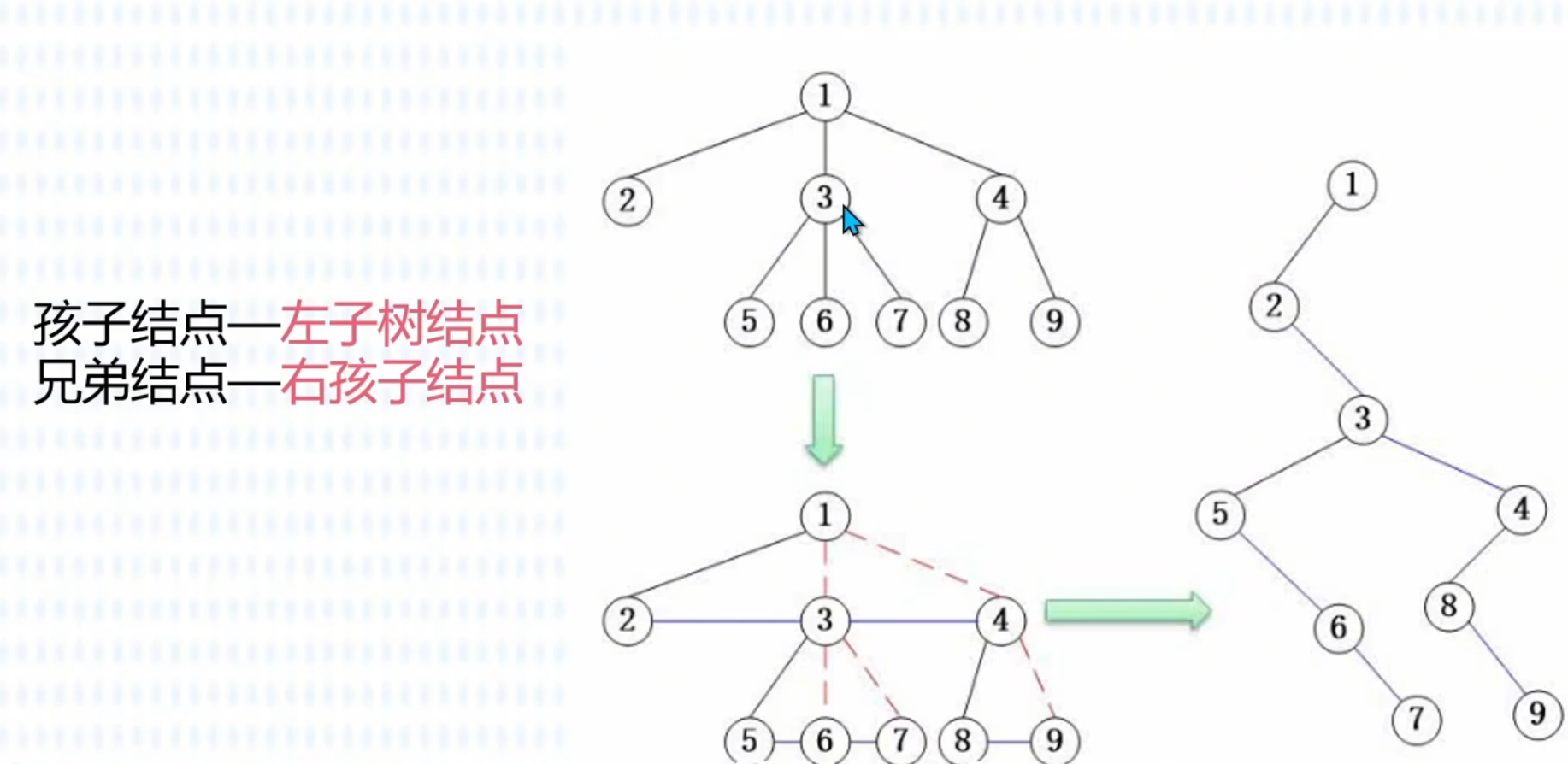
旋转二叉树
构造霍夫曼树(最优)
步骤:
- 初始化 :
- 给定一组权值(通常是字符的频率),每个权值视为一个叶子节点。
- 将所有权值按照大小顺序放入一个最小堆(或优先队列),确保可以每次取出最小的权值。
- 构造过程 :
- 循环构建 :重复以下过程,直到堆中只剩下一个节点:
- 从堆中取出两个最小的节点(这两个节点具有最小的权值)。
- 创建一个新的节点,其权值是这两个节点的权值之和。这个新节点成为父节点,连接两个最小节点(作为它的左右子节点)。
- 将新节点插回堆中。
- 循环构建 :重复以下过程,直到堆中只剩下一个节点:
- 终止 :
- 当堆中只剩一个节点时,说明霍夫曼树已经构造完毕。这个节点就是树的根节点。

- 当堆中只剩一个节点时,说明霍夫曼树已经构造完毕。这个节点就是树的根节点。
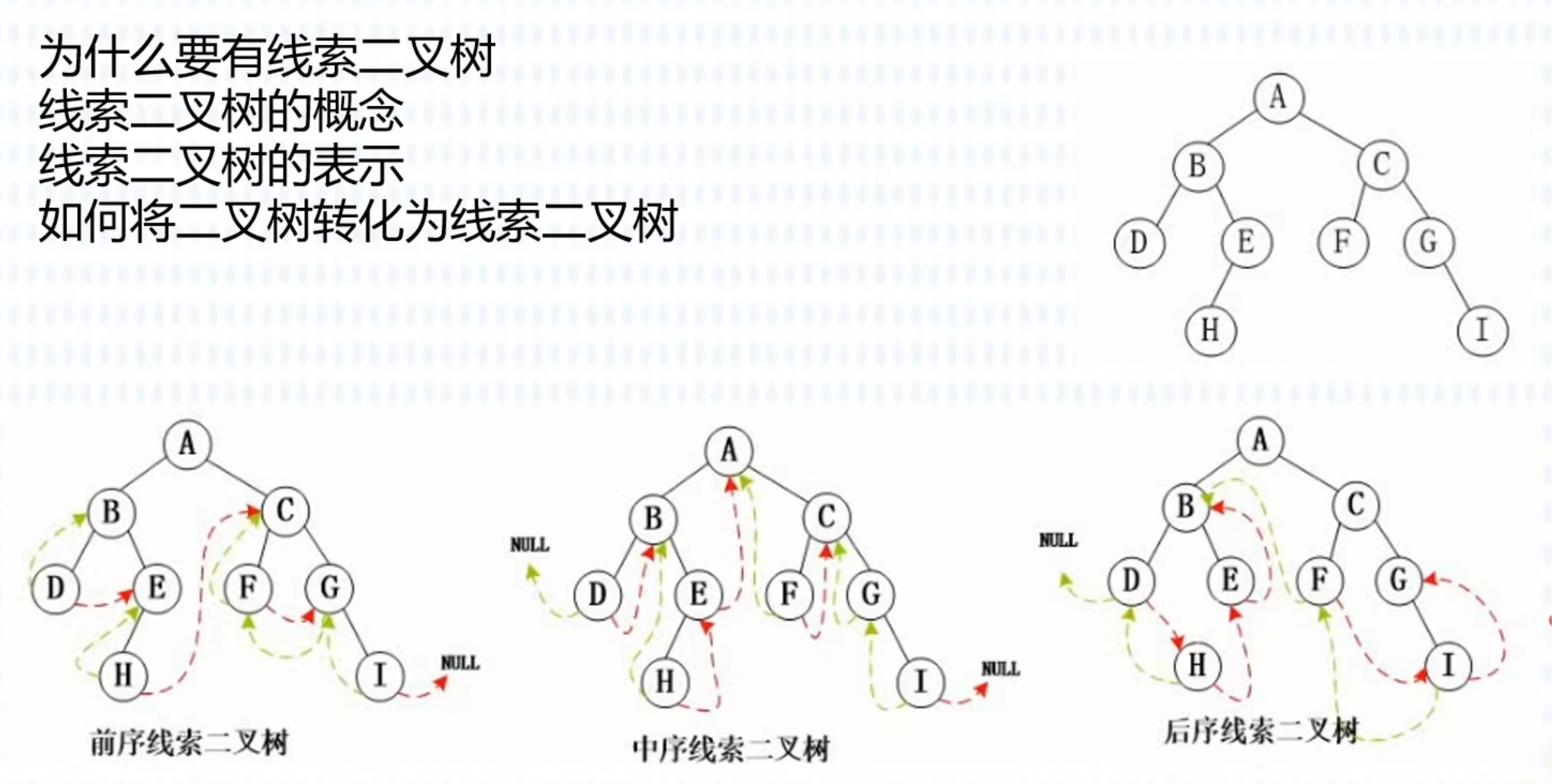
线索二叉树
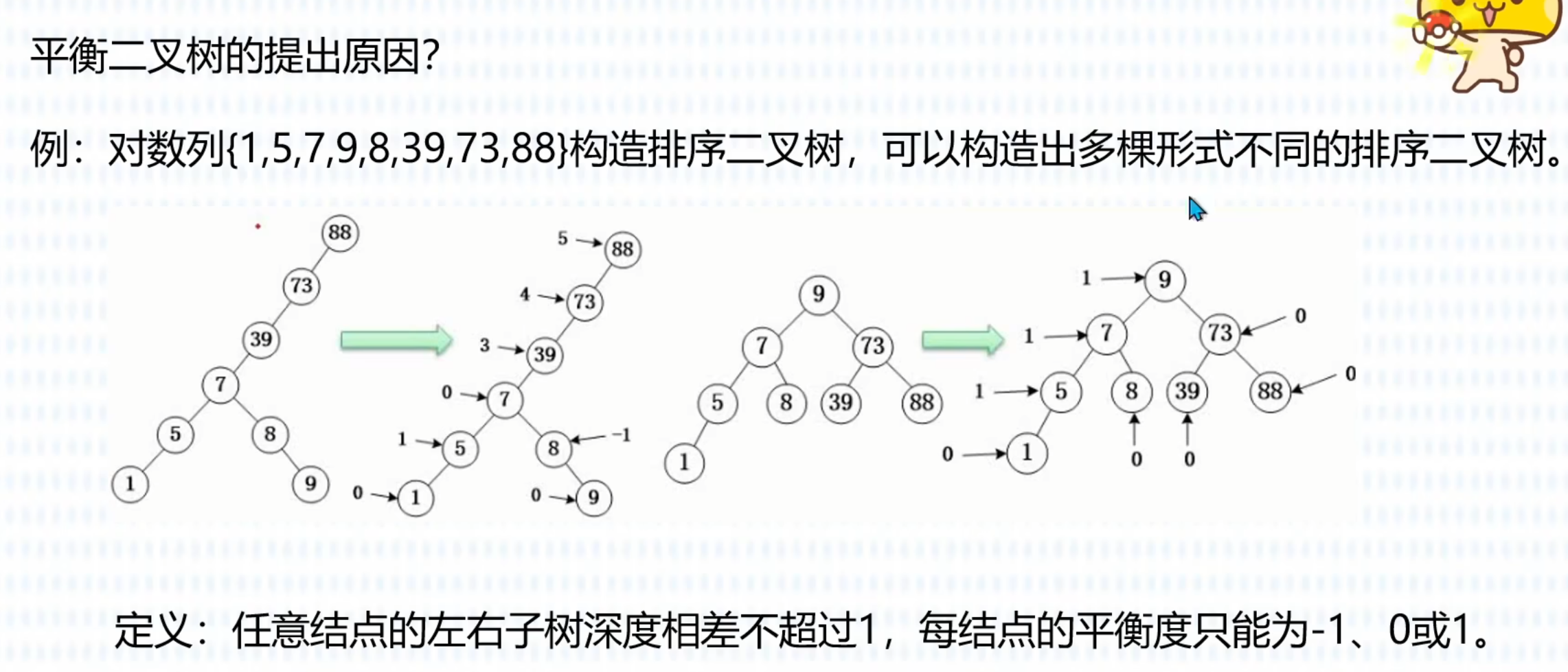
平衡二叉树
图
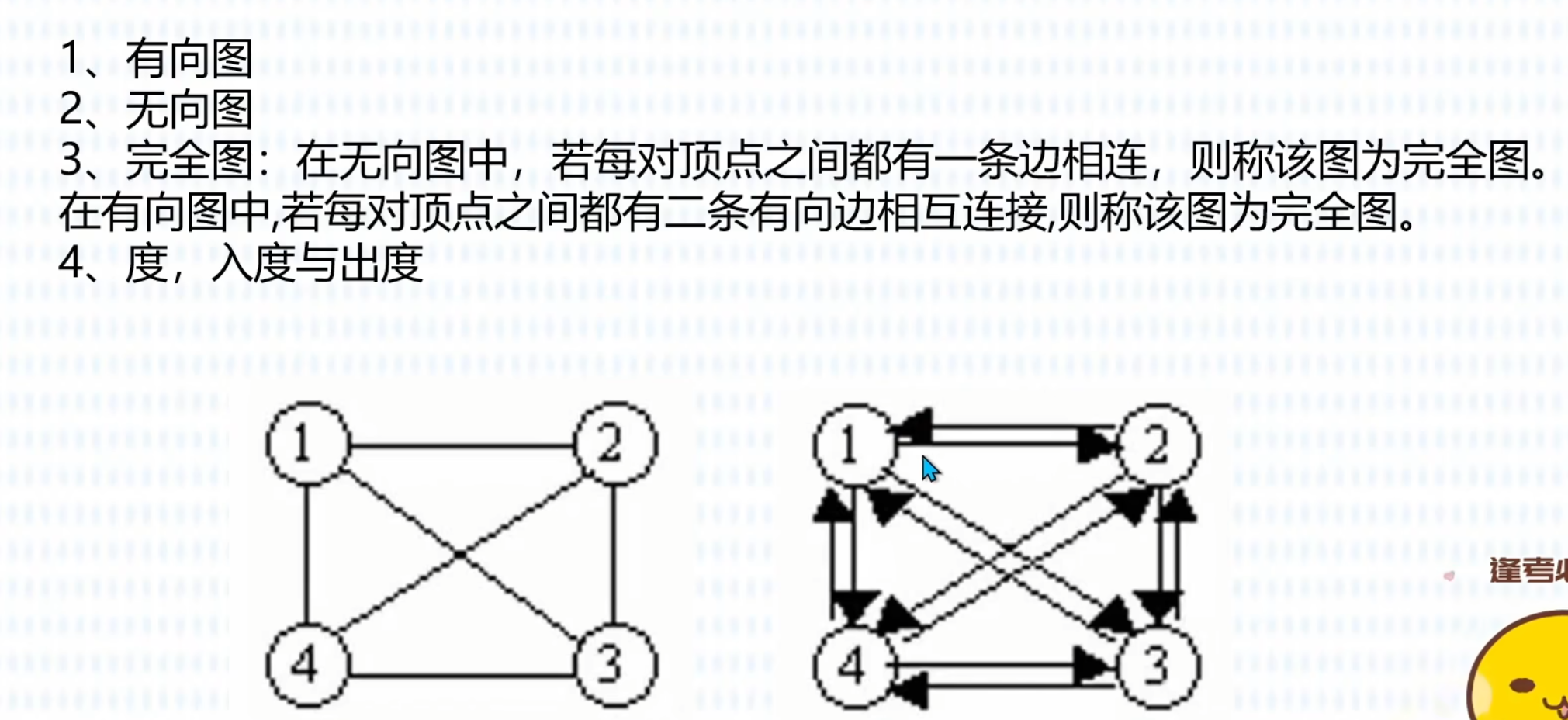
邻接矩阵
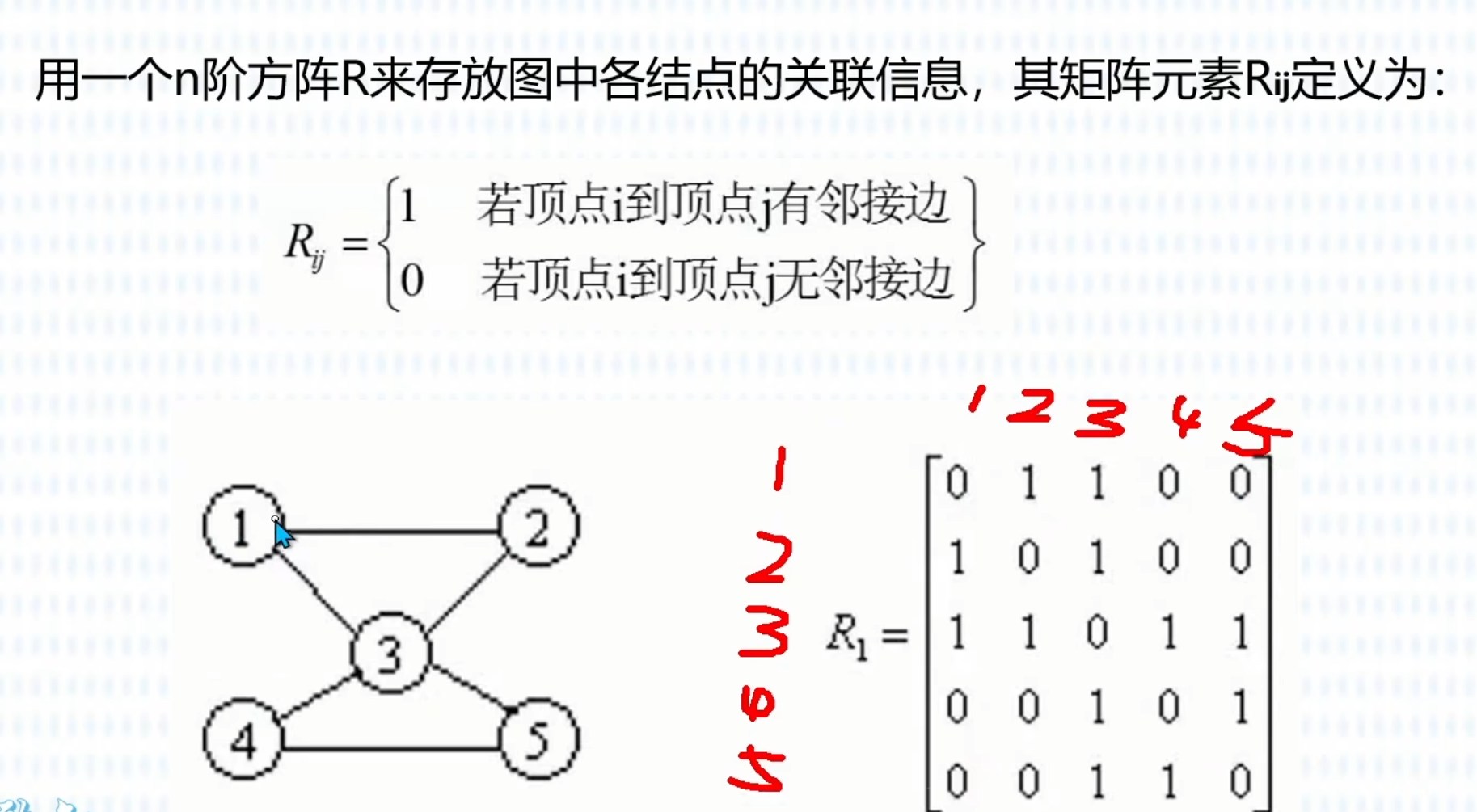
邻接表
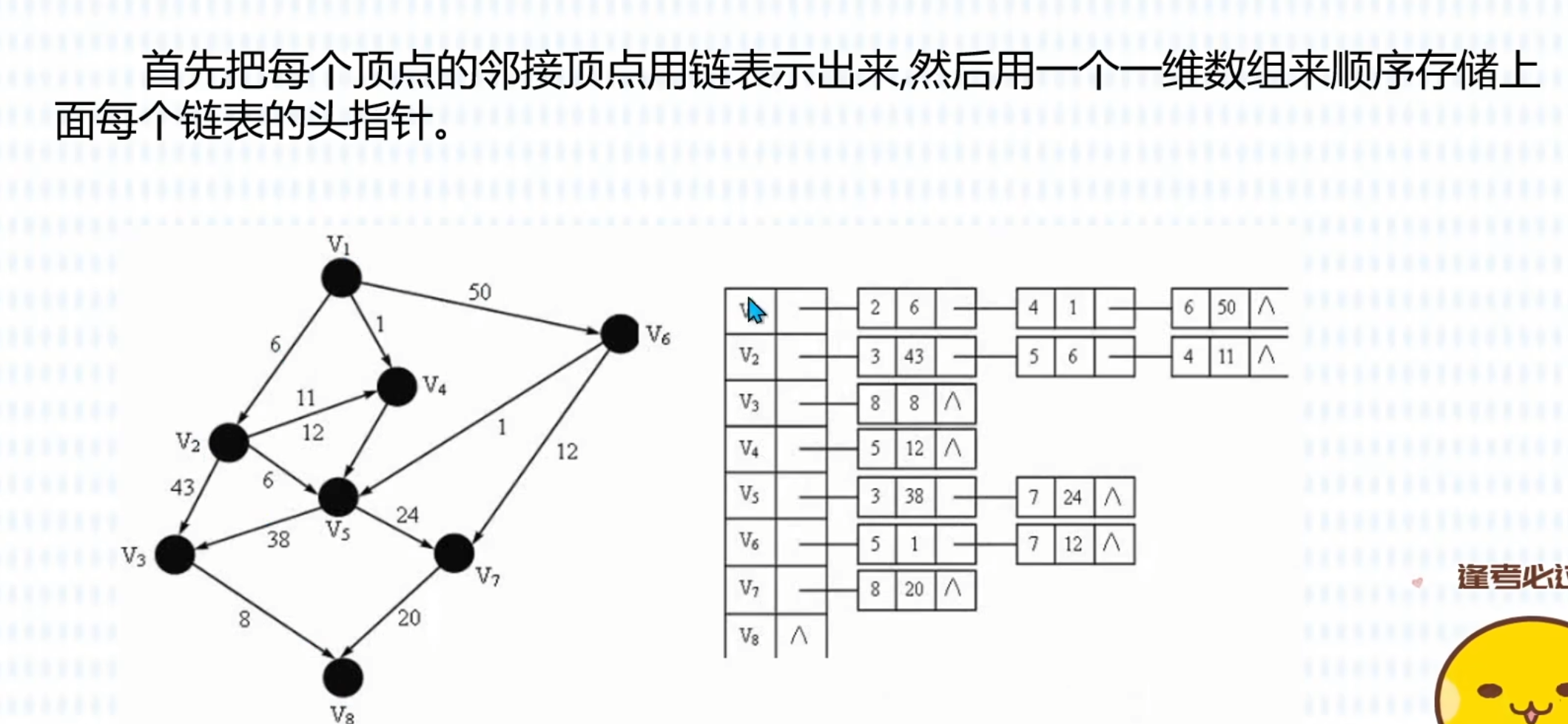
图的遍历
拓扑排序
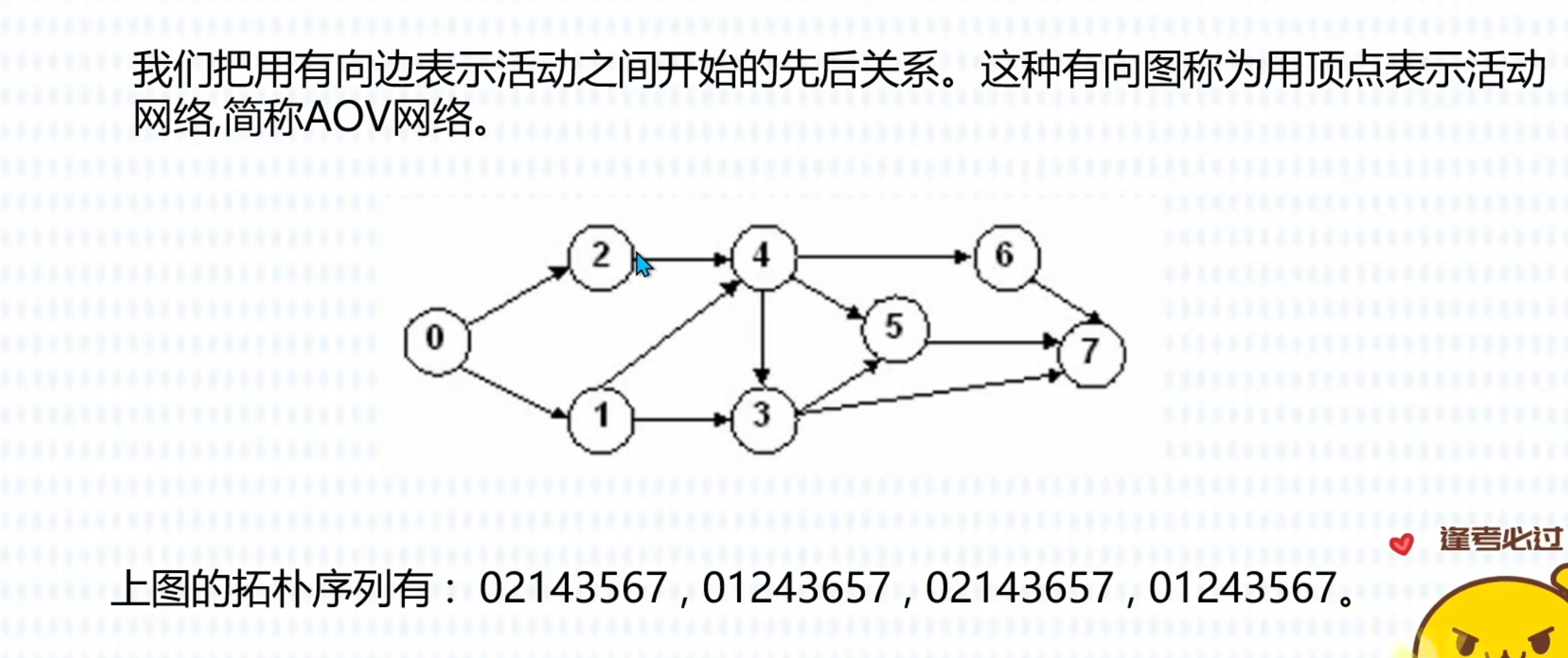
最小生成树
普利姆算法
普利姆算法 (Prim's Algorithm)是求解最小生成树(MST, Minimum Spanning Tree)的一种贪心算法。最小生成树是图中包含所有顶点且边权和最小的生成树。普利姆算法通过逐步扩展生成树来构造最小生成树,每次选择一条最小的边,连接树中的顶点与图中未连接的顶点。
普利姆算法的步骤:
- 初始化 :
- 从图中任选一个顶点作为起始点(称为生成树的初始顶点)。
- 设定一个标记集合,用来标记已加入生成树的顶点。
- 初始化一个数组(或优先队列),用于记录从已加入生成树的顶点到其他顶点的最短边(权值最小的边)。
- 构建过程 :
- 重复以下步骤直到所有顶点都加入生成树:
- 从标记集合外的顶点中,选择一条权值最小的边,将该边对应的顶点加入生成树。
- 更新与新加入顶点相连的边的权值,确保下次选择时会选取最小的边。
- 重复以下步骤直到所有顶点都加入生成树:
- 终止 :
- 当所有顶点都被加入生成树时,算法终止。
示例:普利姆算法
假设有如下带权图:
A
/ \
2 3
/ \
B-------C
1
图的邻接矩阵表示如下:
A B C
A 0 2 3
B 2 0 1
C 3 1 0
步骤1:初始化
- 选择顶点
A作为起始顶点,生成树包含顶点A。 - 初始化一个数组记录从顶点
A出发到其他顶点的最小边,边的权值为:A -> B权值为 2A -> C权值为 3
步骤2:构建生成树
-
从
A开始,选择权值最小的边A -> B,将顶点B加入生成树,生成树现在包含顶点A和B。更新边权:
- 从
B出发的边为B -> C,权值为 1。
此时最小边为
B -> C。 - 从
-
选择边
B -> C,将顶点C加入生成树,生成树现在包含顶点A、B和C。此时所有顶点都已被加入生成树,算法结束。
步骤3:结果
最终的最小生成树边为:
A -> B权值 2B -> C权值 1
最小生成树的总权值为 2 + 1 = 3。
总结:
普利姆算法通过贪心策略逐步扩展生成树,每次选择当前生成树与未加入顶点之间的最小边。其时间复杂度通常为 O(E log V),其中 E 为图中的边数,V 为顶点数。对于稠密图(边数较多),普利姆算法比克鲁斯卡尔算法(Kruskal's Algorithm)更有效。
克鲁斯卡尔算法
克鲁斯卡尔算法 (Kruskal's Algorithm)是解决最小生成树(MST, Minimum Spanning Tree)问题的另一种经典贪心算法。它的核心思想是将图中的所有边按权重排序,然后逐步选择权重最小的边,确保不会形成环,最终形成一棵最小生成树。
克鲁斯卡尔算法的步骤:
- 初始化 :
- 将图中的所有边按照权值升序排列。
- 初始化每个顶点所在的集合(可以用并查集(Union-Find)来管理)。
- 生成一个空的最小生成树。
- 构建过程 :
- 遍历所有边,选择权值最小的边,判断它的两个端点是否属于同一个集合:
- 如果它们属于不同的集合,将这条边加入最小生成树,并合并这两个集合。
- 如果它们已经在同一个集合中,说明加入这条边会形成环,跳过这条边。
- 遍历所有边,选择权值最小的边,判断它的两个端点是否属于同一个集合:
- 终止 :
- 当最小生成树包含
V-1条边(V是图中的顶点数)时,算法结束。
- 当最小生成树包含
示例:克鲁斯卡尔算法
假设有如下带权图:
A
/ \
2 3
/ \
B-------C
1
图的邻接矩阵表示如下:
A B C
A 0 2 3
B 2 0 1
C 3 1 0
步骤1:初始化
- 将所有边按权值升序排列:
B -> C权值 1A -> B权值 2A -> C权值 3
步骤2:构建生成树
- 选择边
B -> C(权值 1) :B和C还不在同一个集合中,加入生成树,合并集合。
- 选择边
A -> B(权值 2) :A和B也不在同一个集合中,加入生成树,合并集合。
- 选择边
A -> C(权值 3) :A和C已经在同一个集合中,加入这条边会形成环,所以跳过。
步骤3:结果
最小生成树的边为:
B -> C权值 1A -> B权值 2
最小生成树的总权值为 1 + 2 = 3。
并查集(Union-Find)
克鲁斯卡尔算法依赖于并查集(Union-Find)来有效地管理和合并不同的集合。并查集是一种用于处理集合合并和查询问题的数据结构,支持两个主要操作:
- Find:查找元素所在的集合。
- Union:合并两个集合。
并查集的优化:
- 路径压缩:在查找操作中,将查询路径上的所有节点直接连接到根节点,降低树的高度,从而加速后续的查询操作。
- 按秩合并:在合并两个集合时,总是将较小的树合并到较大的树上,避免树的高度过大。
总结:
克鲁斯卡尔算法通过贪心策略,从图中选择权值最小的边并确保不形成环,直到构建出最小生成树。它的时间复杂度是 O(E log E),其中 E 是图中的边数。对于稀疏图(边数较少),克鲁斯卡尔算法通常比普利姆算法更加高效。