LoRA大模型微调:轻量化训练新范式
前言
随着大模型参数规模突破千亿,全参数微调(Full Fine-tuning)的算力和显存成本让大多数企业望而却步。LoRA(Low-Rank Adaptation)通过低秩矩阵分解实现了"小成本微调大模型",成为2024-2025年最流行的微调技术。本文深入解析LoRA原理与实战。
一、为什么需要LoRA?
传统全参数微调的问题:
| 问题 | 描述 | 影响 |
|---|---|---|
| 显存巨大 | 7B模型全参数微调需要80GB+显存 | 只有顶级GPU才能训练 |
| 存储昂贵 | 每个下游任务需要保存完整模型 | N个任务=N份模型权重 |
| 训练缓慢 | 梯度更新所有参数 | 收敛慢、成本高 |
| 灾难遗忘 | 新任务覆盖原有权重 | 影响预训练能力 |
LoRA的核心思想:冻结预训练权重,只训练少量新增参数。
二、LoRA核心原理
2.1 低秩分解
LoRA的核心假设:大模型微调过程中的权重更新矩阵是低秩的。
假设预训练权重为 W 0 ∈ R d × d W_0 \in \mathbb{R}^{d \times d} W0∈Rd×d,更新量为 Δ W \Delta W ΔW,则:
W = W 0 + Δ W W = W_0 + \Delta W W=W0+ΔW
LoRA将 Δ W \Delta W ΔW 分解为两个小矩阵:
Δ W = B ⋅ A \Delta W = B \cdot A ΔW=B⋅A
其中 A ∈ R r × d A \in \mathbb{R}^{r \times d} A∈Rr×d, B ∈ R d × r B \in \mathbb{R}^{d \times r} B∈Rd×r, r ≪ d r \ll d r≪d。
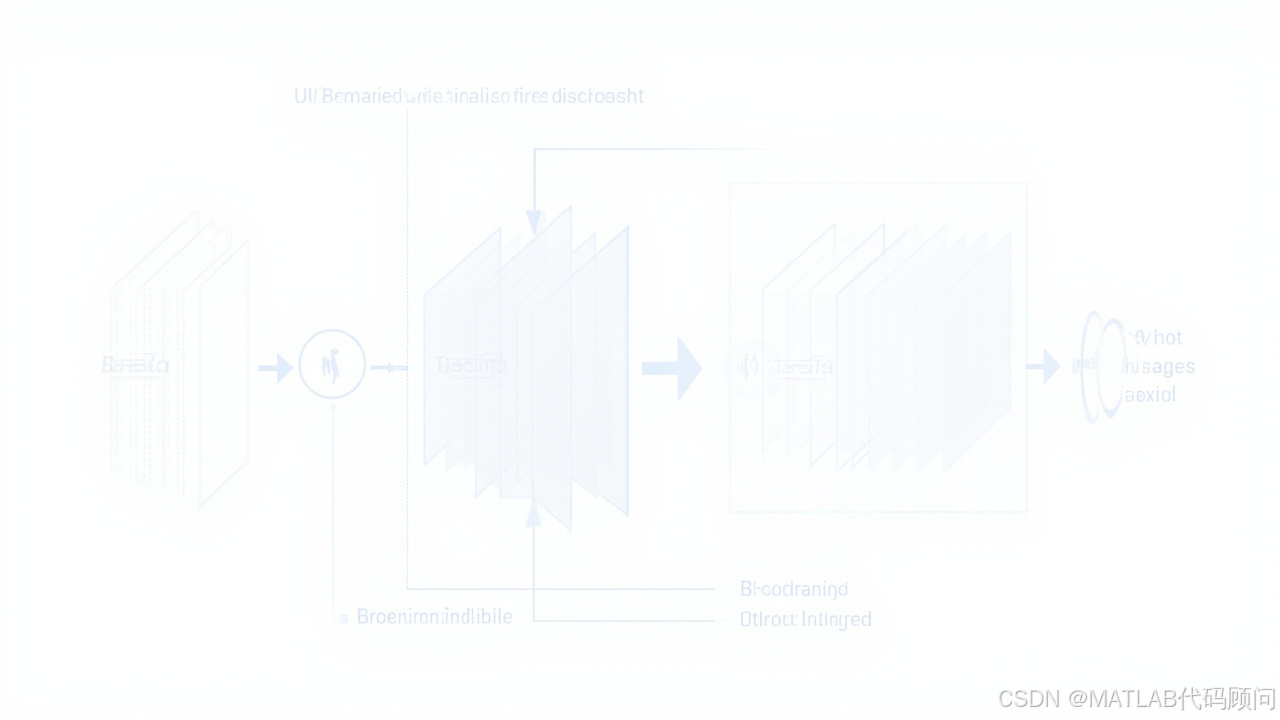
LoRA架构图解:
2.2 前向传播
python
import torch
import torch.nn as nn
class LoRALinear(nn.Module):
"""
LoRA实现的核心:冻结原权重,只训练A和B
"""
def __init__(self, in_features, out_features, rank=4, alpha=1.0):
super().__init__()
self.rank = rank
self.alpha = alpha
self.scaling = alpha / rank
# 冻结原始权重
self.weight = nn.Parameter(
torch.randn(out_features, in_features),
requires_grad=False
)
# LoRA新增的可训练参数
self.lora_A = nn.Parameter(torch.randn(rank, in_features))
self.lora_B = nn.Parameter(torch.zeros(out_features, rank))
# 初始化A为随机,B为零(确保初始状态=原模型)
nn.init.normal_(self.lora_A, std=0.02)
def forward(self, x):
# 原模型输出 + LoRA调整
origin_output = F.linear(x, self.weight)
lora_output = F.linear(x, self.lora_B @ self.lora_A)
return origin_output + self.scaling * lora_output2.3 参数规模对比
以LLaMA-7B为例:
| 微调方式 | 可训练参数量 | 显存需求 | 训练时间 |
|---|---|---|---|
| 全参数微调 | 7B | ~80GB | 基准 |
| LoRA (r=4) | 8.3M | ~12GB | ~1/10 |
| LoRA (r=16) | 33M | ~16GB | ~1/5 |
| QLoRA | 8.3M | ~6GB | ~1/10 |
三、动手实现LoRA
3.1 替换注意力层
python
import torch
import torch.nn as nn
import torch.nn.functional as F
from peft import get_peft_model, LoraConfig, TaskType
# 定义原始模型(以LLaMA为例)
from transformers import LlamaForCausalLM, LlamaTokenizer
model = LlamaForCausalLM.from_pretrained("meta-llama/Llama-2-7b-hf")
tokenizer = LlamaTokenizer.from_pretrained("meta-llama/Llama-2-7b-hf")
# 配置LoRA
lora_config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
r=8, # 秩,越大越接近全参数微调
lora_alpha=16, # 缩放因子
lora_dropout=0.05, # Dropout概率
target_modules=[ # 要替换的模块
"q_proj", "v_proj", # Attention的Q/V
"k_proj", "o_proj", # 可选,加上效果更好
"gate_proj", "up_proj", # FFN层
],
bias="none",
)
# 转换为LoRA模型
model = get_peft_model(model, lora_config)
model.print_trainable_parameters()
# 输出: trainable params: 8,388,608 || all params: 6,738,415,616 || trainable%: 0.124%3.2 训练配置
python
from transformers import TrainingArguments, Trainer
training_args = TrainingArguments(
output_dir="./lora_llama2",
num_train_epochs=3,
per_device_train_batch_size=4,
gradient_accumulation_steps=4, # 梯度累积
learning_rate=1e-4, # LoRA通常用较大lr
warmup_ratio=0.03,
lr_scheduler_type="cosine",
logging_steps=10,
save_steps=100,
fp16=True, # 混合精度
optim="paged_adamw_32bit", # 分页AdamW,省显存
max_grad_norm=0.3,
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
data_collator=data_collator,
)
trainer.train()四、QLoRA:更极致的优化
QLoRA(Quantized LoRA)在LoRA基础上增加了量化,大幅降低显存:
4.1 核心技术创新
- 4-bit NormalFloat(NF4)量化:对权重进行4位量化
- 双重量化:对量化常数也进行量化
- 分页优化器:处理梯度检查点时的显存峰值
python
# QLoRA实现
from transformers import BitsAndBytesConfig
from peft import prepare_model_for_kbit_training
# 4bit量化配置
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True, # 双重量化
bnb_4bit_quant_type="nf4", # NF4量化
bnb_4bit_compute_dtype=torch.bfloat16,
)
# 加载量化模型
model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Llama-2-7b-hf",
quantization_config=bnb_config,
device_map="auto",
)
# 准备kbit训练
model = prepare_model_for_kbit_training(model)
# 应用LoRA
model = get_peft_model(model, lora_config)4.2 训练效果对比
| 方法 | 7B模型显存 | 13B模型显存 | 性能 |
|---|---|---|---|
| 全参数FP16 | ~80GB | ~160GB | 100% |
| LoRA FP16 | ~12GB | ~24GB | ~98% |
| QLoRA 4bit | ~6GB | ~12GB | ~97% |
五、LoRA的超参数调优
5.1 秩(Rank)的选择
python
# 不同秩的效果实验
ranks = [2, 4, 8, 16, 32, 64]
results = {}
for rank in ranks:
config = LoraConfig(r=rank, lora_alpha=rank*2, ...)
model = get_peft_model(base_model, config)
# 训练和评估
trainer = Trainer(model=model, ...)
trainer.train()
results[rank] = evaluate(model)经验法则:
- r=4~8:基础任务,效果一般
- r=16~32:大多数任务,推荐
- r=64~128:复杂任务,但显存增加明显
5.2 目标模块选择
效果对比(从高到低):
q_proj + v_proj + k_proj + o_proj + gate_proj + up_proj > down_proj
↑
全包含(效果最好,但训练最慢)5.3 学习率设置
LoRA参数是"额外新增"的,lr通常比全参数微调大:
| 微调方式 | 推荐学习率 |
|---|---|
| 全参数微调 | 1e-5 ~ 3e-5 |
| LoRA | 1e-4 ~ 5e-4 |
| QLoRA | 1e-4 ~ 3e-4 |
六、LoRA实战:对话模型微调
6.1 数据准备
python
# 构建对话格式数据
def format_instruction(sample):
return f"""<|im_start|>user
{sample['instruction']}<|im_end|>
<|im_start|>assistant
{sample['output']}<|im_end|>"""
# 示例
samples = [
{
"instruction": "用Python写一个快速排序",
"output": "def quicksort(arr):\n if len(arr) <= 1:\n return arr\n ..."
},
# ... 更多数据
]6.2 保存和加载
python
# 保存LoRA权重(只占几MB)
model.save_pretrained("./lora_weights")
# 加载
from peft import PeftModel
base_model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b-hf")
model = PeftModel.from_pretrained(base_model, "./lora_weights")
# 推理
inputs = tokenizer("用Python写一个快速排序", return_tensors="pt").to("cuda")
outputs = model.generate(**inputs, max_new_tokens=200)
print(tokenizer.decode(outputs[0]))6.3 权重合并
python
# 合并LoRA权重到基础模型(用于部署)
merged_model = model.merge_and_unload()
merged_model.save_pretrained("./merged_model")七、LoRA家族扩展
7.1 AdaLoRA:自适应秩分配
python
# 不同层分配不同秩,节省参数
from peft import AdaLoraConfig
ada_config = AdaLoraConfig(
r=8,
lora_alpha=16,
target_modules=["q_proj", "v_proj"],
lora_dropout=0.05,
)7.2 DoRA:权重分解
DoRA将权重分解为方向和幅度两部分:
python
# DoRA核心思想
output = (m + Δm) @ x = m @ x + Δm @ x
# 分解为:模长变化 + 方向变化7.3 LoRA+ / VeRA / LoRA-FA
| 变体 | 核心改进 | 效果 |
|---|---|---|
| LoRA+ | A/B用不同学习率 | 收敛更快 |
| VeRA | 共享随机投影 | 参数更少 |
| LoRA-FA | 每层独立初始化 | 效果提升 |
八、总结与展望
LoRA开启了"轻量化微调"的时代,让每个开发者都能用自己的数据定制大模型。
2025年微调学习路线:
阶段1:掌握LoRA原理和基本实现
阶段2:熟练使用HuggingFace PEFT库
阶段3:理解QLoRA和量化技术
阶段4:实践多任务微调、增量学习未来LoRA将继续向更高效、更多模态、更自动化的方向演进。
延伸阅读:
- LoRA原论:arxiv.org/abs/2106.09685
- QLoRA论文:arxiv.org/abs/2305.14314
- HuggingFace PEFT库:github.com/huggingface/peft