一、高并发内存池概述
- 高并发内存池是一种针对高并发场景优化设计的内存管理机制,它预先分配一定数量的内存块,通过统一的管理策略实现内存的高效分配与释放,避免频繁调用系统级内存分配接口(如malloc、free)带来的性能开销
- 同时解决高并发下内存碎片、线程安全 等核心问题。与普通内存池相比,高并发内存池更侧重并发场景下的性能稳定性、锁竞争优化和资源利用率
- 广泛应用于互联网后端、游戏服务器、数据库等对内存操作响应速度和并发能力要求极高的领域。
二、内存池的定义与作用
内存池(Memory Pool)是一种内存预分配技术,核心是在程序启动时或初始化阶段,向操作系统申请一块连续或离散的内存空间作为"内存池",后续程序中所有的内存分配、释放操作,均在该内存池内部完成,无需直接与操作系统交互。
其核心作用主要体现在三个方面:
-
降低性能开销:系统级内存分配接口(malloc/free)会涉及内核态与用户态的切换,且每次分配都需遍历空闲内存链表,高并发场景下频繁调用会严重拖慢程序性能;内存池预先分配内存,分配/释放操作均在用户态完成,大幅减少系统调用次数。
-
控制内存碎片:频繁分配、释放不同大小的内存块,会导致内存空间中产生大量无法利用的"碎片"(分为内部碎片和外部碎片),内存池通过固定大小块分配、碎片整理等策略,有效减少碎片产生,提高内存利用率。
-
外部碎片:一些空闲的连续内存区域太小,这些内存空间不连续,以至于合计内存够,但是不能满足一些内存分配申请需求
-
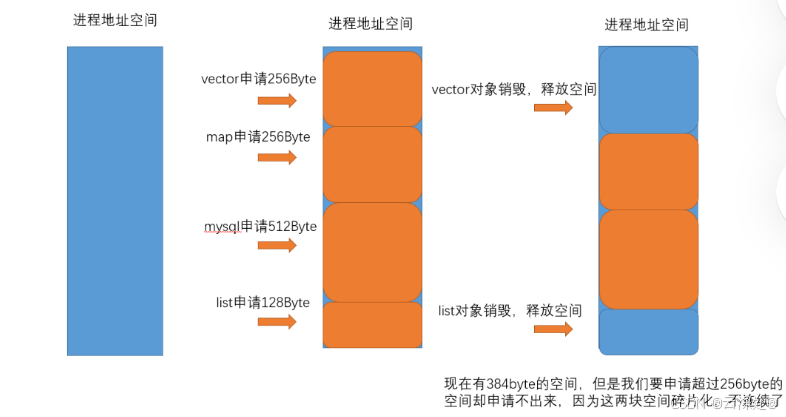
-
-
统一内存管理:内存池提供统一的内存分配、释放、回收接口,便于开发者管理内存资源,避免内存泄漏、重复释放等问题,同时可根据业务需求定制分配策略,适配不同场景。
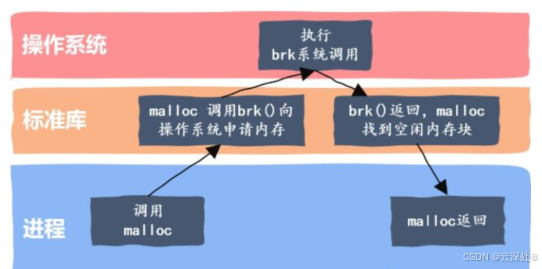
- C、C++中的动态内存申请都是通过malloc去申请内存,该操作并不是直接去堆上申请,而malloc就是一个内存池。
- malloc相当于向操作系统批发了一块较大的内存空间,然后零售给程序使用,当全部售完或程序有大量的内存需求时,根据实际需求向操作系统获取内存块。
- malloc实现方式有很多种,一般不同编译器平台用的不同,比如Windows的vs系列通过调用系统接口VirtualAllocated,Linux通过调用brk和mmap系统接口
demo:定长内存池的设计
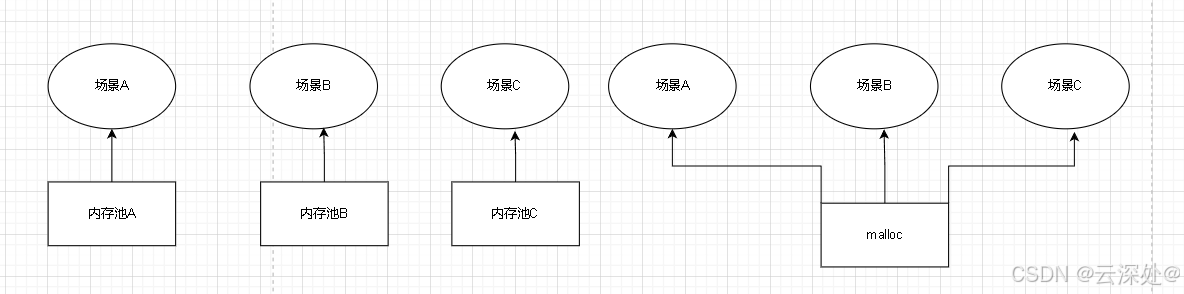
- 定长内存池是只管理固定内存块的内存池,是高并发内存池,对象池的基础核心组件
- 每一个固定大小的内存池只能应对特定的场景
- 但是定长内存池在什么场景下都可用,意味着什么场景下都不会有很高的性能
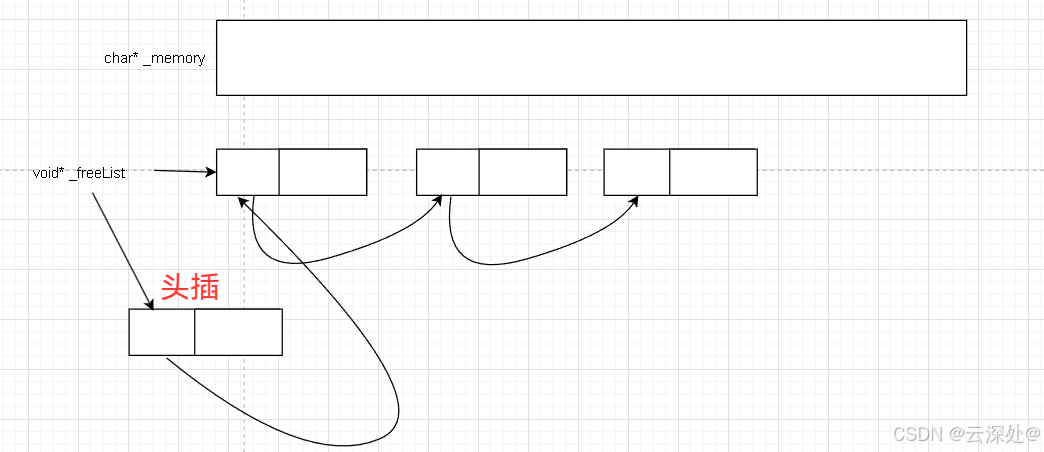
定长内存池,使用char类型来开辟空间,以字节为单位,可以将内存池最大利用,后续通过指针移动对应一个对象所需的字节数,切割所需对象的空间,方便后面的使用
通过维护一个释放链表,将已经使用过的内存块插入到释放链表中,并将里面的数据清空,该链表不需要显示释放,当一个线程结束时,由操作系统回收
从memory内存块中申请的空间通过切割后,得到的新内存块的前4、8字节存储下一个内存块的地址 ,由于在32位平台下,指针大小为4字节,在64位平台下,指针大小为8字节,使用(void**)进行强转类型转化,例如使用int*将4字节的地址内容赋值,使用void* *是将void*大小的地址内容赋值,则可以使用*(void**)obj = nullptr使小内存块的前几个字节指向下一个小内存块


代码及测试:
cpp
#pragma once
#include<iostream>
#include<time.h>
#include<vector>
using std::cout;
using std::endl;
//template<size_t N> //定长内存池--非类型模板参数
//class Object_pool //定长内存池可以是对象池
//{
//};
#ifdef _WIN32
#include<Windows.h>
#else
//
#endif
inline static void* SystemAlloc(size_t kpage)
{
#ifdef _WIN32
void* ptr = VirtualAlloc(nullptr, kpage << 13, MEM_COMMIT | MEM_RESERVE,
PAGE_READWRITE);
#else
//LInux下的mmap,brk
#endif
if (ptr == nullptr) throw std::bad_alloc();
return ptr;
}
template<class T> //定长内存池--非类型模板参数
class Object_pool //定长内存池可以是对象池
{
public:
T* New()
{
T* obj = nullptr;
//如果_freeList不为空,优先使用_freeList中的内存块
if (_freeList)
{
T* next = (T*)NextAddr((T*)_freeList);
obj = (T*)_freeList;
_freeList = next;
}
else
{
if (_remainSize < sizeof(T)) //当剩余字节数小于一个对象所需要的大小时,重新申请空间
{
size_t request_size = 128 * 1024; //申请空间
//_memory = (char*)malloc(request_size);
_memory = (char*)SystemAlloc(request_size >> 13); //8kb大页优化
_remainSize = request_size;
if (_memory == nullptr)
{
throw std::bad_alloc();
}
size_t objSize = sizeof(T) < sizeof(void*) ? sizeof(void*) : sizeof(T); //返回该内存块对象,当objSize小于一个地址的大小时,扩展至一个地址的大小
obj = (T*)_memory;
_memory += objSize;
_remainSize -= objSize;
new (obj)T; //定位new,在已有的空间上构造对象,用于应对string,vector类型的容器,可能会进一步在堆上开辟空间
}
}
return obj;
}
void*& NextAddr(T* obj) //返回该对象块指向的下一个对象块
{
return *(void**)obj;
}
void Delete(T* obj)
{
if (obj == nullptr) return;
obj->~T(); //清空该对象残留的数据,将该对象挂到释放列表中
T* next = (T*)NextAddr(obj);
next = (T*)_freeList;
_freeList = obj;
}
private:
char* _memory = nullptr; //使用char将大块内存切成小块
void* _freeList = nullptr; //自由链表
size_t _remainSize = 0;
};
struct TreeNode
{
TreeNode* _left;
TreeNode* _right;
int _val;
TreeNode() :_left(nullptr), _right(nullptr), _val(0) {}
};
void testObjPool()
{
const int round = 3;
const int N = 10000000;
std::vector<TreeNode*> vec(N);
Object_pool<TreeNode> obj_pool;
std::vector<TreeNode*> vec2(N);
size_t b1 = clock();
for (int i = 0; i < round; i++) //对比new和delete下的malloc内存申请释放效率和内存池申请释放效率,即申请一块内存还是多块内存效率高
{
for (int j = 0; j < N; j++)
{
vec.push_back(new TreeNode);
}
for (int j = 0; j < N; j++)
{
delete vec[i];
}
}
size_t e1 = clock();
size_t b2 = clock();
for (int i = 0; i < round; i++)
{
for (int j = 0; j < N; j++)
{
vec2.push_back(obj_pool.New());
}
for (int j = 0; j < N; j++)
{
obj_pool.Delete(vec2[j]);
}
}
size_t e2 = clock();
cout << "new and delete : " << e1 - b1 << endl;
cout << "obj_pool : " << e2 - b2 << endl;
}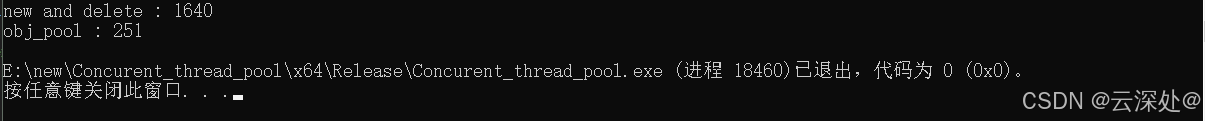
一些知识点:

- VirtualAlloc 是 Windows 系统提供的「申请虚拟内存」API,它是操作系统级别的内存分配,比 malloc、new 更底层
- VirtualAlloc按页分配,整页释放,开辟的内存在堆上,其中new就是通过调用该系统调用接口分配内存的

三、高并发场景下的内存管理挑战
高并发场景(如每秒数万、数十万次内存操作)下,传统内存管理方式(直接使用malloc/free)会面临诸多难以解决的挑战,主要集中在以下四点:
-
锁竞争剧烈:普通内存分配器为保证线程安全,会使用全局锁保护空闲内存链表,高并发下大量线程同时竞争同一把锁,会导致线程阻塞、上下文切换频繁,成为性能瓶颈。
-
内存碎片严重:高并发场景中,内存分配的大小往往不规则(如请求包体、用户会话等),频繁分配和释放不同大小的内存块,会快速产生大量外部碎片,导致内存利用率急剧下降,甚至出现"内存耗尽但实际有大量碎片"的情况。
-
系统调用开销大:每一次malloc/free都需要陷入内核态,执行内存分配、链表维护等操作,高并发下频繁的系统调用会占用大量CPU资源,导致程序响应延迟增加。
-
线程本地开销:多线程环境中,线程间共享内存池时,即使没有锁竞争,也会存在缓存一致性问题(如CPU缓存失效),进一步降低内存操作效率。
四、高并发内存池的核心目标
高并发内存池的设计围绕"适配高并发、提升性能、保障稳定性"展开,核心目标包含三个维度,三者相互关联、缺一不可:
4.1 性能优先
核心是降低内存分配/释放的延迟,提高吞吐量。具体要求:单次内存操作(分配/释放)耗时尽可能短(通常在纳秒级),支持高并发场景下的大量并发请求,避免因内存管理成为整个系统的性能瓶颈。同时,要减少CPU缓存失效、上下文切换等额外开销,最大化利用硬件资源。
4.2 碎片控制
在保证性能的前提下,尽可能减少内存碎片的产生,提高内存利用率。目标是避免因碎片累积导致内存耗尽,同时减少内存整理带来的性能损耗,实现"高效分配"与"低碎片"的平衡。对于长期运行的服务(如7×24小时互联网后端),碎片控制尤为重要,直接决定服务的稳定性和资源占用率。
4.3 线程安全
高并发场景下,多个线程会同时进行内存分配和释放操作,内存池必须保证线程安全,避免出现内存竞争、数据错乱、重复释放、内存泄漏等问题。同时,线程安全的实现不能以牺牲性能为代价,需通过无锁设计、细粒度锁等方式,减少锁竞争带来的性能损耗。
五、内存池的核心设计思想
高并发内存池的设计核心是"分层管理、按需分配、减少竞争",通过合理的架构设计和策略优化,兼顾性能、碎片控制和线程安全,其核心设计思想主要包含以下四点:
5.1 固定大小内存块分配策略
将内存池划分为多个不同大小的"内存块组",每个组内的内存块大小固定(如8字节、16字节、32字节、64字节、128字节等,通常按2的幂次划分)。当线程申请内存时,根据申请大小匹配最接近的固定大小内存块,分配给线程;释放时,将内存块归还给对应的块组,无需重新整理内存空间。
该策略的优势的是:避免了不规则大小内存块分配导致的外部碎片,同时简化了内存分配和释放的逻辑,提高操作效率;缺点是会产生少量内部碎片(如申请10字节内存,分配16字节块),但可通过合理划分块大小,将内部碎片控制在可接受范围。
5.2 多层级内存管理
采用"全局内存池+线程本地缓存"的多层级架构,是高并发内存池解决锁竞争的核心设计。
-
线程本地缓存(Thread Local Cache, TLC):每个线程拥有独立的本地缓存,缓存一定数量的固定大小内存块。线程申请内存时,优先从自身的本地缓存中获取,无需竞争全局锁,操作完全在本地完成,性能极高;释放内存时,也优先归还给本地缓存。
-
全局内存池(Global Pool):作为所有线程本地缓存的"后备资源",当线程本地缓存没有可用内存块时,会从全局内存池批量申请一定数量的内存块,补充到本地缓存;当线程本地缓存的内存块过多时,会将多余的内存块归还给全局内存池,实现资源复用。全局内存池通常采用细粒度锁或分段锁,减少线程间的竞争。
部分高级内存池还会增加"中央堆""页缓存"等层级,进一步优化内存分配效率和碎片控制。
5.3 无锁或细粒度锁的并发控制机制
并发控制的核心是"减少锁竞争",主要有两种实现方式:
-
无锁设计:基于原子操作(如CAS、原子加载/存储)实现内存块的分配和释放,无需使用锁,从根本上避免锁竞争。适用于线程本地缓存、小粒度内存块管理等场景,性能最优,但实现复杂度较高。
-
细粒度锁:将全局内存池划分为多个独立的分区(如按内存块大小分区),每个分区配备一把独立的锁,线程操作不同分区时,竞争不同的锁,大幅降低锁冲突的概率。相比全局锁,细粒度锁能显著提升高并发场景下的性能,实现难度适中,是目前主流的并发控制方式。
六、常见高并发内存池实现方案
目前工业界有多种成熟的高并发内存池实现,各自有其设计特点和适用场景,其中TCMalloc、Jemalloc、Boost.Pool最为常用,覆盖了大多数高并发场景的需求。
6.1 TCMalloc(Thread-Caching Malloc)
TCMalloc由Google研发,是Google开源项目gperftools的核心组件,专为高并发场景设计,广泛应用于Google的各类后端服务(如搜索、地图),也是Go语言标准库中内存分配器的核心参考实现。其核心设计亮点是"线程本地缓存与中央堆的深度结合",重点优化小对象分配。
6.1.1 线程本地缓存与中央堆的结合
TCMalloc采用"线程本地缓存(TLC)+ 中央堆(Central Heap)+ 页堆(PageHeap)"的三层架构:
-
线程本地缓存(TLC):每个线程拥有独立的缓存,存储不同大小的小对象内存块(通常小于256KB),线程申请/释放小对象时,直接操作本地缓存,无锁且高效。
-
中央堆(Central Heap):管理所有线程本地缓存的后备资源,按内存块大小分为多个跨度(Span),每个跨度对应一种固定大小的内存块。当线程本地缓存无可用块时,从中央堆批量申请跨度,补充到本地缓存;当本地缓存块过多时,将跨度归还给中央堆。中央堆采用细粒度锁,每个跨度对应一把锁,减少竞争。
-
页堆(PageHeap):管理大内存块(通常大于256KB)和物理内存页,中央堆的跨度由页堆分配,当中央堆无可用跨度时,向页堆申请新的内存页,再划分为对应大小的跨度。
6.1.2 小对象分配优化
TCMalloc的核心优势的是小对象分配(占内存分配请求的90%以上)的高效性:
-
将小对象划分为多个大小等级(如8、16、32、...、256KB),每个等级对应一个跨度,避免不规则分配导致的碎片。
-
线程本地缓存采用"空闲链表"管理内存块,分配时直接从链表头部取块,释放时将块插入链表头部,操作时间复杂度为O(1)。
-
当小对象释放时,优先归还给本地缓存,只有当本地缓存的块数量超过阈值时,才归还给中央堆,减少跨线程的资源交互,降低开销。
此外,TCMalloc还优化了内存回收机制,当进程内存占用过高时,会自动回收中央堆和页堆中未使用的内存,归还给操作系统,减少内存浪费。
6.2 Jemalloc
Jemalloc由Jason Evans研发,最初为FreeBSD系统设计,后被广泛应用于高并发场景(如Redis、MongoDB、Firefox),其核心特点是"高效的多线程内存分配策略"和"优秀的内存碎片控制能力",在大对象分配和长期运行服务中表现突出。
6.2.1 多线程环境下的内存分配策略
Jemalloc采用"线程缓存(Arena)+ 中央分配器"的架构,与TCMalloc的分层思路类似,但在细节上有所不同:
-
Arena(线程缓存):Jemalloc会预先创建多个Arena(默认数量为CPU核心数),每个线程绑定一个Arena,线程的内存分配/释放操作优先在绑定的Arena中完成,减少不同线程间的竞争。与TCMalloc的"每个线程一个缓存"不同,Jemalloc的Arena是共享的,当某个Arena资源不足时,线程可切换到其他Arena,提高资源利用率。
-
中央分配器:管理所有Arena的后备资源,负责向操作系统申请内存页,并将内存页划分为不同大小的内存块(称为"run"),分配给各个Arena。中央分配器采用细粒度锁,每个内存页组对应一把锁,降低锁竞争。
Jemalloc还支持"内存隔离",可将不同类型的内存分配(如业务数据、临时变量)分配到不同的Arena,避免相互干扰,进一步优化缓存效率。
6.2.2 内存碎片控制机制
Jemalloc在碎片控制上做了大量优化,核心策略包括:
-
分层块大小划分:将内存块分为小对象(<=4KB)、中对象(4KB~2MB)、大对象(>2MB),不同类型对象采用不同的分配策略,小对象采用固定大小块分配,中/大对象采用页级分配,减少碎片。
-
run回收机制:当一个run中的所有内存块都被释放时,Jemalloc会将该run归还给中央分配器,中央分配器可将连续的run合并,形成更大的内存块,用于分配大对象,减少外部碎片。
-
内存对齐优化:所有内存块都按CPU缓存行对齐,避免因内存对齐问题导致的内部碎片和缓存失效,同时提升内存访问效率。
6.3 Boost.Pool
Boost.Pool是Boost库中的一个轻量级内存池实现,基于C++模板开发,适用于C++项目,其核心特点是"简单易用、轻量高效",主要针对小对象分配优化,适用于对内存管理复杂度要求不高、但需要提升小对象分配性能的场景(如C++服务、桌面应用)。
6.3.1 C++中的内存池实现
Boost.Pool基于C++模板封装,提供了两种核心内存池类型:
- simple_pool:简单内存池,适用于固定大小的小对象分配,内部维护一个空闲链表,分配/释放操作简单高效,支持线程安全(可通过模板参数开启锁保护)。