发布时间:2026 年 5 月 4 日
作者:Yi Zhang、William McDonald(技术员工)
目录预览
WebRTC lets us make real-time AI products - WebRTC 助力我们打造实时 AI 产品
Choosing a media architecture - 媒体架构选型
The core deployment problem: WebRTC meets Kubernetes 核心部署难题:WebRTC 遇上 Kubernetes
Architecture overview: relay + transceiver - 架构总览:中继 + 收发器
Routing on ICE credentials - 基于 ICE 凭证的路由
Global Relay and geo-steered signaling - 全球中继与地理导向信令
Relay implementation and performance - 中继实现与性能
Results and learnings - 结果与经验总结
transceiver = Transmitter + Receiver,收发器 / 收发一体机。既能发、又能收的设备/服务
steer stɪə(r)
v. 驾驶(交通工具),掌方向盘;引导,指导(某人的行为);引导,带领(某人去某地);(交通工具)行驶,沿(特定路线或方向)行进;选择某种做法,采取某种方式;(机动车)容易(或难以)驾驶
n. (车辆的)驱动方式;<非正式> 建议,忠告
signaling ˈsɪɡnəlɪŋ n. 发信号;打信号
ICE (Interactive Connectivity Establishment)
交互式连通性建立
通俗含义
现在手机 / 电脑都在内网(路由器后面、防火墙后面),没有公网独立 IP,两台设备直接连不上
ICE 干的事就三件:
- 自动探测自己有哪些可用地址(内网 IP、公网映射 IP、中继服务器地址)
- 双方互相交换地址列表
- 按优先级挨个尝试配对,找出一条能通、延迟最低的网络路径
ICE 就是 WebRTC 的 "穿墙大师 + 找路大师"
不管你在什么路由器、什么防火墙后面,帮你自动打通 P2P 或服务器中转通路
关键作用
- 解决 NAT 穿透(家庭路由、公司内网、4G/5G 都能连通)
- 自动选最优链路,不用人工配端口、配 IP
- WebRTC 能全球互通,全靠 ICE
DTLS (Datagram Transport Layer Security)
数据报传输层安全协议
网页 HTTPS 用的是 TLS(基于 TCP,可靠)
WebRTC 语音要用 UDP(低延迟、不重传),普通 TLS 不能用,于是有了 DTLS
DTLS 干的事:
在 UDP 不可靠数据包 之上,做一套和 TLS 几乎一样的:
- 身份握手认证
- 协商加密密钥
- 后续所有语音 / 视频包加密传输
DTLS = 适配 UDP 版的 TLS,专门给 WebRTC 做加密安全的
关键作用
- 全程加密音频、视频、数据通道
- 防窃听、防中间人篡改、防劫持
- WebRTC 默认强制 DTLS,不加密不让建会话
transceiver 在 OpenAI WebRTC 架构里的专属含义
Relay(中继)只转发包,不处理会话;Transceiver 才是真正扛下所有 WebRTC 会话状态的后端服务
它到底干什么?
Transceiver 是有状态服务,负责:
- 终结 WebRTC 连接(ICE 连通性检查、DTLS 握手、SRTP 加解密)
- 维持整个通话会话状态
- 把 WebRTC 音频流,转成内部协议发给大模型 / 语音推理服务
- 把模型返回的语音,再封装回 WebRTC 流发回去
简介
awkward ˈɔːkwəd adj. 令人尴尬的,使人难堪的;难对付的,难处理的;局促不安的;不方便的;笨拙的
pauses ˈpɔːzɪz 停顿
clipped klɪpt
adj. 省略一部分的;发音清楚的
v. 剪除(clip 的过去分词)
barge-in 闯入:突然进入或打断而没有邀请
get in the way
阻碍、妨碍或干扰:使某事无法顺利进行或完成
turn-taking 轮流发言/轮流发言权
crisp krɪsp
adj. 爽口的,脆生的;脆的,易碎的;洁净的,挺括的;(图片或声音)清晰的,清脆悦耳的;清新的,凉爽的;(言行)干脆利落的;轻快的,利索的
n. <英>炸薯片;松脆食品
v. (使)发脆;<旧>(使)变卷,(使)变卷曲
collide kəˈlaɪd v. 冲突,抵触;(迥异的事物)碰在一起;碰撞,相撞
preserve prɪˈzɜːv
v. 保护,维护;保持,维持;腌制,保存(食物);禁止他人捕猎
n. 果酱,腌菜;(某人或某个团体的)专属领域,独有活动;动物保护区,外人禁入的猎地
Voice AI only feels natural if conversation moves at the speed of speech. When the network gets in the way, people hear it immediately as awkward pauses, clipped interruptions, or delayed barge-in. That matters for ChatGPT voice, for developers building with the Realtime API, for agents working in interactive workflows, and for models that need to process audio while a user is still talking.
语音 AI 只有在对话能跟上说话速度时(moves at the speed of speech),才会显得自然。一旦网络出现问题,用户会立刻感受到尴尬的停顿、语音被截断,或是插话延迟。这对 ChatGPT 语音、基于 Realtime API 开发的开发者、交互式工作流中的智能体,以及需要在用户说话同时处理音频的模型而言,都至关重要。
At OpenAI's scale, that translates into three concrete requirements 在 OpenAI 的规模下,这转化为三个明确的需求:
- Global reach for more than 900 million weekly active users 为9 亿 + 周活用户提供全球覆盖
- Fast connection setup so a user can start speaking as soon as a session begins 快速连接建立,用户在会话开始后可立即说话
- Low and stable media round-trip time, with low jitter and packet loss, so turn-taking feels crisp 低且稳定的媒体往返时延,低抖动、低丢包,让对话轮替(turn-taking)流畅自然
The team at OpenAI responsible for real-time AI interactions recently rearchitected our WebRTC stack to address three constraints that started to collide at scale: one-port-per-session media termination does not fit OpenAI infrastructure well, stateful ICE (Interactive Connectivity Establishment) and DTLS (Datagram Transport Layer Security) sessions need stable ownership, and global routing has to keep first-hop latency low. In this post, we walk through the split relay plus transceiver architecture we built to preserve standard WebRTC behavior for clients while changing how packets are routed inside OpenAI's infrastructure.
OpenAI 负责实时 AI 交互的团队近期重构(rearchitected)了 WebRTC 技术栈,以解决在规模化场景下相互冲突的三大约束(three constraints that started to collide at scale):"单会话单端口 one-port-per-session" 的媒体终端与 OpenAI 基础设施不匹配、有状态的 ICE/DTLS 会话需要稳定归属(ownership)、全球路由必须保证首跳(first-hop)时延足够低。
本文将详细介绍我们打造的分离式中继 + 收发器架构(the split relay plus transceiver architecture):在保持(preserve)客户端标准 WebRTC 行为不变的前提下,同时(while)改造 OpenAI 基础设施内部的数据包路由方式
WebRTC 让我们能打造实时 AI 产品
traversal trəˈvərs(ə)l n. 计 遍历;横越;横断物
WebRTC is an open standard for sending low-latency audio, video, and data between browsers, mobile apps, and servers. It's often associated with peer-to-peer calling, but it's also a practical foundation for client-to-server real-time systems because it standardizes the hard parts of interactive media: ICE for connectivity establishment and NAT (Network Address Translation) traversal, DTLS and SRTP (Secure Real-time Transport Protocol) for encrypted transport, codec negotiation for compressing and decoding audio, RTCP (Real-time Transport Control Protocol) for quality control, and client-side features such as echo cancellation and jitter buffering.
WebRTC 是一项开放标准,用于在浏览器、移动应用与服务器之间传输低延迟音频、视频与数据。它常被用于点对点通话(peer-to-peer calling),但同样也是客户端到服务器实时系统的实践/实用基础(practical foundation),因为它标准化了交互式媒体中最复杂的部分:
- ICE:建立连接与 NAT(Network Address Translation) 穿越
- DTLS + SRTP:加密传输
- 编解码协商(codec negotiation for compressing and decoding audio)
- RTCP(Real-time Transport Control Protocol):质量控制
- 回声消除(echo cancellation)、抖动缓冲(jitter buffering)等客户端能力
That standardization matters for AI products. Without WebRTC, every client would need a different answer for how to establish connectivity across NATs, encrypt media, negotiate codecs (the coder-decoders selected for transmission and decompression) and adapt to changing network conditions. With WebRTC, we can build on a protocol stack that's already implemented across browsers and mobile platforms, focusing our own work on the infrastructure that connects real-time media to models.
这种标准化对 AI 产品至关重要。没有 WebRTC,每个客户端都需要单独解决 NAT 穿越、媒体加密、编解码协商、网络自适应(adapt to changing network conditions)等问题。有了 WebRTC,我们可以基于已在各浏览器与移动平台落地的协议栈开发,把精力聚焦在连接实时媒体与大模型(connects real-time media to models)的基础设施上。
mature məˈtʃʊə(r)
adj. 成熟的,理智的;成年的,发育完全的;发酵成熟的,酿成的;中老年的;技艺精湛的,技巧娴熟的;审慎考虑的,深思熟虑的;到期(应该支付)的;(某些食品或饮料)可立即食用的;(经济,行业,市场)成熟的,发展余地不大的
v.(使)成熟,(使)长成;变理智,(举止)变成熟;酿成,制成;到期
interoperable ˌɪntərˈɒpərəbl
adj.(计算机系统或软件、不同机器)可共同操作的,可互换利用信息的,可配合动作的
reinvent ˌriːɪnˈvent
v. 彻底改造,重新创造;以新形象示人(reinvent oneself)
We also build on the WebRTC ecosystem itself, including mature open-source implementations and the standard work that keeps browsers, mobile apps, and servers interoperable. Foundational work by Justin Uberti (one of WebRTC's original architects) and Sean DuBois (creator and maintainer of Pion) made it possible for teams like ours to build on battle-tested media infrastructure rather than reinvent low-level transport, encryption, and congestion-control behavior. We're fortunate that both Justin and Sean are now colleagues here at OpenAI, helping guide how we bring WebRTC and real-time AI closer together.
我们还充分利用了 WebRTC 生态系统本身的优势,包括成熟的开源实现以及确保浏览器、移动应用程序和服务器能够相互兼容的标准工作。贾斯汀·乌贝蒂(WebRTC 的原始架构师之一)和肖恩·杜布斯(Pion 的创建者和维护者)所做的基础性工作使得像我们这样的团队能够基于经过实战检验的(battle-tested)媒体基础设施进行开发,而无需重新设计底层传输、加密和拥塞控制(congestion-control)行为。我们很幸运,贾斯汀和肖恩现在都在 OpenAI 工作,帮助指导我们如何将 WebRTC 和实时人工智能更紧密地结合起来。
For AI, the most important property is that audio arrives as a continuous stream. A spoken agent can begin transcribing, reasoning, calling tools, or generating speech while the user is still talking, instead of waiting for a full upload. That's the difference between a system that feels conversational and one that feels like push-to-talk.
对 AI 而言,最重要的特性是音频以连续流到达。语音智能体可以在用户说话的同时开始转写(transcribing)、推理、调用工具或生成语音,而不必等待完整上传。这就是 "对话感系统 conversational" 与 "按键通话式系统 push-to-talk" 的本质区别。
媒体架构选型
WebRTC 终结点(Termination)的选择,客户端的 WebRTC 连接,由谁来终结?
终结点,就是负责完成 ICE 穿透、DTLS 握手、SRTP 加解密,把 WebRTC 流转换成后端可处理的数据的地方。
Once we chose WebRTC, the next question was where to terminate it (where we'd accept and own the WebRTC connection---for example, at the edge) and how to connect those sessions to the inference backend. Termination matters because it determines how we handle real-time session state, media transport, routing, latency, and failure isolation.
选定 WebRTC 后,下一个问题是在哪里终端 WebRTC(接受并持有连接),以及如何将这些会话连接到推理后端(inference backend)。终端位置决定了会话状态管理、媒体传输、路由、时延与故障隔离策略。
方案 1:SFU 方案 ------ 将 AI 作为 WebRTC 参与者
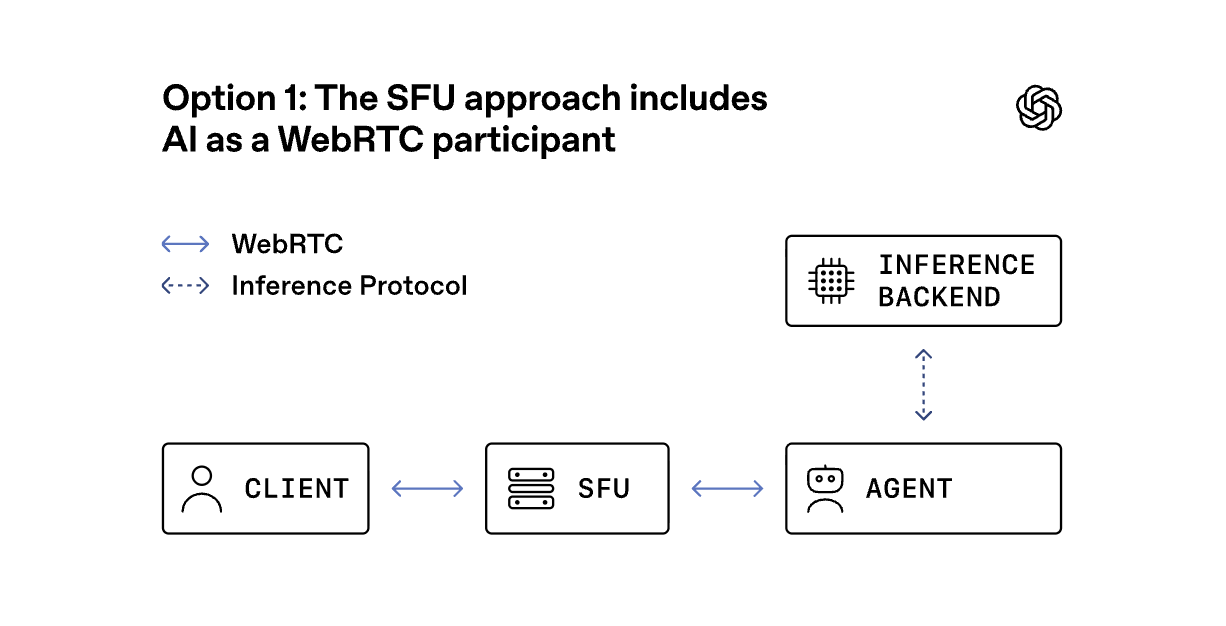
An SFU, or selective forwarding unit, is a media server that receives one WebRTC stream from each participant and selectively forwards streams to the others. In this model, the SFU terminates a separate WebRTC connection for every participant, and the AI joins as another participant in the session. That can be a good fit for products that are inherently multiparty, such as group calls, classrooms, or collaborative meetings. It keeps audio codecs, RTCP messages, data channels, recording, and per-stream policy in one place.1
一个选择性转发单元(selective forwarding unit, SFU)是一种媒体服务器,它会从每位参与者那里接收一个 WebRTC 流,并对这些流进行选择性转发给其他参与者。在这种模式下,SFU 会为每位参与者单独建立一个 WebRTC 连接,而 AI 则作为另一个参与者加入会话。这对于本质上就是多参与方的场景(如群组通话、教室或协作会议)来说是一个很好的选择。它将音频编解码器、RTCP 消息、数据通道、录制以及每条流的策略都集中在一个地方进行管理。
Even in client-to-AI products, an SFU is often the default starting point because it lets teams reuse one proven system for signaling, media routing, recording, observability, and future extensions such as human handoff or adding more participants.
即使是在面向客户的 AI 产品中,软件功能单元(SFU)通常也是默认的起点,因为它能让团队利用一个已被证明过的(proven)系统来实现信号传输、媒体路由、录制、可观测性等功能,并且还能为未来的扩展(如人工转接 handoff 或增加参与方 participant)提供支持。
方案 2:收发器方案 ------ 在边缘终结 WebRTC,转换为后端协议
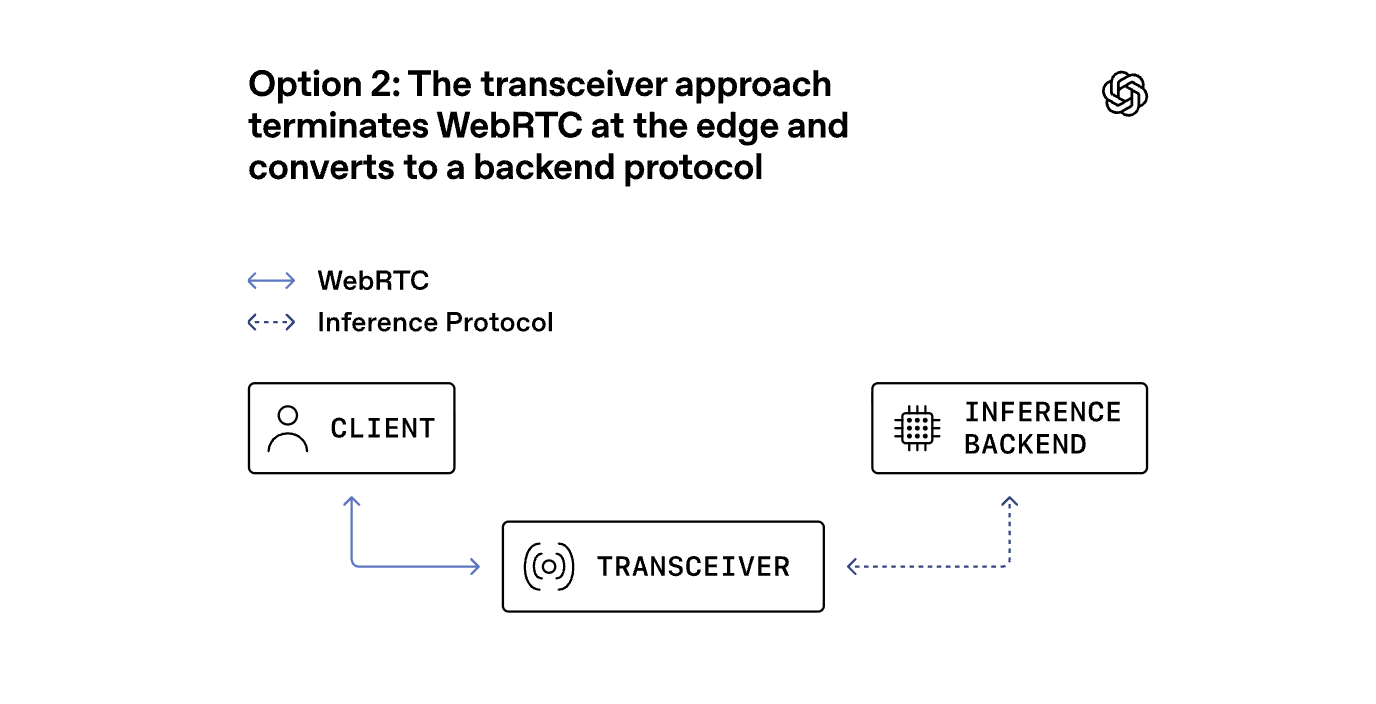
Our workload is different. Most sessions are 1:1---one user talking to one model, or one application talking to one real-time agent---with latency sensitivity on every turn. For that shape of traffic, we chose a transceiver model: a WebRTC edge service terminates the client connection and then converts media and events into simpler internal protocols for model inference, transcription, speech generation, tool use, and orchestration.
我们的工作量有所不同。大多数会话都是 1 对 1 的------一个用户与一个模型交流,或者一个应用程序与一个实时代理交流------每一轮都具有延迟敏感性(sensitivity)。针对这种类型的流量,我们选择了转接器模型:一个 WebRTC 边缘服务 terminate 客户端连接,然后将媒体和事件转换为更简单的内部协议,以便进行模型推理、转录(transcription)、语音生成、工具使用和协调。
In this design, the transceiver is the only service that owns the WebRTC session state, including ICE connectivity checks, the DTLS handshake, SRTP encryption keys, and session lifecycle. "Termination" here means the transceiver is the endpoint that completes those handshakes and encrypts or decrypts the media. Keeping that state in one place made session ownership easier to reason about, and it let backend services scale like ordinary services instead of acting as WebRTC peers themselves.
在该设计中,收发器是唯一拥有 WebRTC 会话状态的服务,包括 ICE 连接检查、DTLS 握手、SRTP 加密密钥以及会话生命周期。这里的"Termination" 指的是收发器是完成这些握手并对媒体进行加密或解密(encrypts or decrypts)的端点。将该状态集中存放在一个地方使得会话所有权更易于理解,并且它使后端服务能够像普通服务一样进行扩展(scale like ordinary services),而无需像 WebRTC 对等体那样自行运作。
方案一的特点

方案二的特点

The core deployment problem: WebRTC meets Kubernetes
After choosing the transceiver model, our first implementation was a single Go service built on Pion that handled both signaling and media termination. It powers ChatGPT voice, the Realtime API's WebRTC endpoint, and a number of research projects.
Operationally, the transceiver service does two jobs:
Signaling: SDP negotiation, codec selection, ICE credentials, and session setup
Media: Terminating downstream WebRTC connections and maintaining upstream connections to backend services for inference and orchestration
We wanted the service to run like the rest of our infrastructure: on Kubernetes, where workloads can scale up and down, and move across hosts as demand changes. But the conventional one-port-per-session WebRTC model fits that environment poorly, because it depends on large public UDP port ranges that are difficult to expose, secure, and preserve as pods are added, removed, or rescheduled.2
在选定 transceiver 后,我们的首个实现方案是基于 Pion 构建的一个单一 Go 服务,该服务负责处理信令和媒体 termination 工作。它为 ChatGPT 语音、实时 API 的 WebRTC 端点以及多个研究项目提供了支持。
从操作层面来看(Operationally),transceiver 服务承担着两项任务:
- 信号传输:SDP 协商、编解码器选择、ICE 证书以及会话设置
- 媒体:Terminating 下游 WebRTC 连接,并维持与后端服务的上游连接以进行推理和编排
我们希望该服务能像我们其余的基础设施一样运行:在 Kubernetes 上运行,其中工作负载可以动态扩展和收缩,并根据需求变化在主机之间移动。但传统的每个会话一个端口的 WebRTC 模型在这种环境中表现不佳,因为它依赖于难以暴露、保护且在添加、删除或重新调度 Pod 时能够保持稳定的大型公共 UDP 端口范围。
Port exhaustion
advertise ˈædvətaɪz v. 为......做广告,登广告;公布,征聘;宣扬;使变得显眼;<古>提醒......注意
elasticity ˌiːlæˈstɪsəti n. 弹性,弹力;灵活性
brittle ˈbrɪt(ə)l
adj. 易碎的,脆的;(关系或局势)不牢固的,易变的;脆弱的;冷淡的;尖利的,刺耳的;(声音)像要哭的
n. 果仁薄脆糖
The first problem was the one-port-per-session model itself. At high concurrency, that means exposing and managing very large UDP port ranges.
Cloud load balancers and Kubernetes services are not designed around tens of thousands of public UDP ports per service. Each additional range adds operational complexity in load balancer config, health checking, firewall policy, and rollout safety.3
Large UDP port ranges are hard to secure because they expand the externally reachable surface area and make network policy harder to audit.
They're also a poor fit for autoscaling. Pods are constantly added, removed, and rescheduled in Kubernetes. Requiring each pod to reserve and advertise a large stable port range makes that elasticity brittle.4
This is why many WebRTC systems move toward a single UDP port per server, with application-level demultiplexing behind that port.5
第一个问题在于每个会话仅使用一个端口这一模式本身。在高并发情况下,这意味着需要公开并管理非常庞大的 UDP 端口范围。
云负载均衡器和 Kubernetes 服务并非是为每项服务配备数万个公共 UDP 端口而设计的。每增加一个端口范围都会在负载均衡器配置、健康检查、防火墙策略以及部署安全性(rollout safety)方面增加操作上的复杂性。3
大型的 UDP 端口范围难以保障安全,因为它们扩大了可对外访问的范围,并使网络策略更难进行审计。
此外,它们也不适合自动扩展(autoscaling)。在 Kubernetes 中,Pod 会不断被添加、删除和重新调度。要求每个 Pod 预留并通告一个大型稳定的端口范围会使这种弹性变得脆弱。4
这就是为什么许多 WebRTC 系统倾向于每个服务器使用一个 UDP 端口,并在该端口后面进行应用层的解复用。5
传统 WebRTC 方案的痛点,"单会话单端口" 模式,有一个致命问题:
- 每个 WebRTC 会话,都要占用一个独立的 UDP 端口
- 高并发场景下,服务器需要管理成千上万的 UDP 端口
这在 Kubernetes、云负载均衡器里非常难实现: - 端口范围难以配置和安全管控
- 服务扩缩容时,端口会频繁变化,会话无法稳定绑定,容易出现 "端口耗尽" 问题
单 UDP 端口:
服务器只对外暴露一个固定的 UDP 端口(比如 3478),所有客户端的 WebRTC 数据包,都发到这同一个端口上
应用层解复用(application-level demultiplexing):服务器收到数据包后,不再靠 "端口号" 区分会话,而是靠数据包里的内容来区分
比如用 ICE ufrag、会话 ID、流 ID 等信息,服务器在应用层解析这些字段,把数据包转发给对应的会话处理逻辑
举个形象的例子
传统方案:每个客户(会话)都走一条单独的 "小路"(端口),路多了就乱了
新方案:所有客户都走一条 "大马路"(同一个端口),然后靠车牌(数据包里的会话标识)来分流
为什么要这么做?
解决端口耗尽问题:一个端口承载所有会话,再也不用管理大量端口了
适配云原生环境:Kubernetes、云负载均衡器天生支持 "单端口多流量",部署和扩缩容都简单了
简化运维与安全:对外只暴露一个端口,安全策略、监控、审计都好做
Relay + Transceiver 架构,就是基于这个思路的升级:
Relay 用一个端口接收所有包,靠 ICE ufrag 做应用层解复用,把包转发给对应的 Transceiver
State stickiness 状态粘性
fleet fliːt
n. 船队,舰队;(某家公司控制的)车队;小湾,水道
adj. <文>快速的;快速的;(水)浅的
adv. 浅,不深地
Single-port-per-server designs solve port count, but they introduce a second problem: preserving ownership of each session across a fleet.
ICE and DTLS are stateful protocols. The process that created a session needs to keep receiving that session's packets so it can validate connectivity checks, complete the DTLS handshake, decrypt SRTP, and process later session changes such as ICE restarts. If packets for the same session land on a different process, setup can fail or media can break.
That gave us a specific target: expose a small, fixed UDP surface to the public internet, while still routing every packet to the transceiver that owns the corresponding WebRTC session.
单服务器每个端口设计解决了端口数量的问题,但同时也带来了另一个问题:如何在服务器集群中保持每个会话的归属权
ICE 和 DTLS 都是具有状态属性的协议。创建会话的进程(process)需要持续接收(keep receiving )该会话的报文,以便能够验证连接状态、完成 DTLS 握手、解密 SRTP,并处理后续的会话变更,如 ICE 重启等。如果同一会话的报文落在不同的进程中,可能会导致设置失败或媒体中断。
这为我们设定了一个明确的目标:将一个小型、固定的 UDP 面板暴露在公共互联网上,同时仍要将每个数据包路由至拥有相应 WebRTC 会话的转接器。
Comparison of WebRTC media architectures
We evaluated several ways to get there, including TURN (Traversal Using Relays around NAT), where an edge relay terminates client allocations and forwards traffic on their behalf.2
我们研究了多种到达目标的方法,其中包括 TURN(利用 NAT 周边的中继节点进行漫游),在这种方式中,边缘中继会 terminate 客户端的分配,并代表客户端转发数据流量。

方案 1:Unique IP:port per session(单会话单端口,原生直连 UDP)
传统、简单,但在大规模云环境里完全玩不转
优点(Pros):
客户端直连服务器,路径最短,没有转发层,延迟天生低
缺点(Cons):
每个会话要一个独立的公网 UDP 端口,并发高了直接端口耗尽
大范围端口,暴露面大,安全管控、审计都非常难
完全不兼容 Kubernetes:K8s 负载均衡器、服务模型,根本不支持 "每个服务开上万个 UDP 端口" 的玩法,扩缩容也会直接把会话搞崩
方案 2:Unique IP:port per server(单服务器单端口)
解决了端口问题,但只适合单机,在集群里有致命缺陷
优点(Pros):
服务器只对外暴露一个 UDP 端口,公网暴露面小了很多
一台服务器可以靠这一个端口,通过「应用层解复用」同时处理成千上万的会话
缺点(Cons):
单机没问题,但跨负载均衡集群时会出问题:
客户端发的第一个包,可能被负载均衡器随机分到集群里任意一台服务器上
只有正确的那台服务器知道这个会话状态,分到别的服务器上的包会被直接丢弃,会话就断了
所以在集群里,还是需要一套确定性路由机制,把每个会话的包,都精准发到它的 "归属进程" 上
方案 3:TURN relay(终结协议的 TURN 中继)
通用的中继方案,但不适合低延迟的 AI 语音场景
优点(Pros):
客户端只需要连接 TURN 服务器的固定地址和端口,公网暴露面小
可以在边缘集中做策略控制(比如限速、鉴权)
缺点(Cons):
建连时要额外走 TURN 分配流程,增加了建连往返时间,延迟会变高
会话在不同 TURN 服务器之间迁移、恢复都非常困难,运维成本高
方案 4:Stateless forwarder + stateful terminator(OpenAI 的 Relay + Transceiver 方案)
OpenAI 为自己的场景量身定做的 "最优解"
优点(Pros):
公网暴露面极小,只有 Relay 服务暴露一个 UDP 端口
Transceiver 作为终结点,完整持有 WebRTC 会话状态(ICE/DTLS/SRTP),逻辑清晰
缺点(Cons):
媒体包要多经过一次 Relay 转发,比原生直连多了一跳
需要自定义的协同机制,让 Relay 能把包正确转发到对应的 Transceiver 上
小结

Architecture overview: relay + transceiver
The architecture we shipped splits packet routing from protocol termination. Signaling still reaches the transceiver for session setup, while media enters through the relay first. The relay is a lightweight UDP forwarding layer with a small public footprint, and the transceiver is the stateful WebRTC endpoint behind it.
我们所交付的架构将数据包路由与协议 termination 分离开来。信令仍会传至 transceiver 以完成会话设置,而 media 则首先通过中继进入系统。中继是一个轻量级的 UDP 转发层,具有较小的公共占用范围,而收发器则是其后端的有状态 WebRTC 端点。
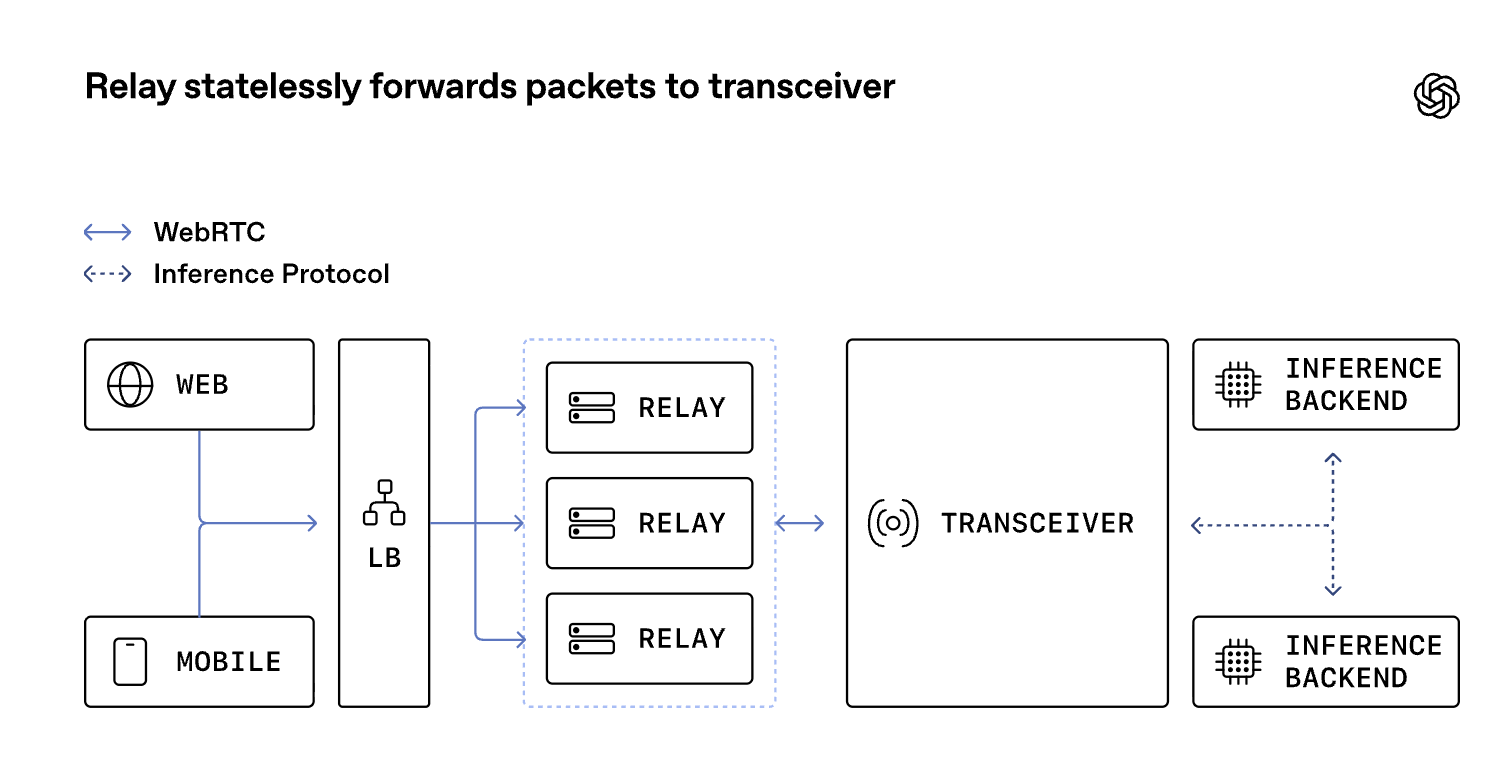
The relay does not decrypt media, run ICE state machines, or participate in codec negotiation. It reads enough packet metadata to choose a destination, then forwards the packet to the transceiver that owns the session. The transceiver still sees a normal WebRTC flow and still owns all protocol state. From the client's perspective, nothing about the WebRTC session changes.
该中继程序不会对媒体内容进行解密,也不会运行 ICE(交互式网络连接)状态机,更不会参与编解码器协商。它仅读取足够的数据包元数据来确定目标位置,然后将数据包转发给拥有会话的 transceiver 。transceiver 仍会看到正常的 WebRTC 流,并且仍然掌控所有协议状态。从客户端的角度来看,WebRTC 会话没有任何变化。
Routing on ICE credentials
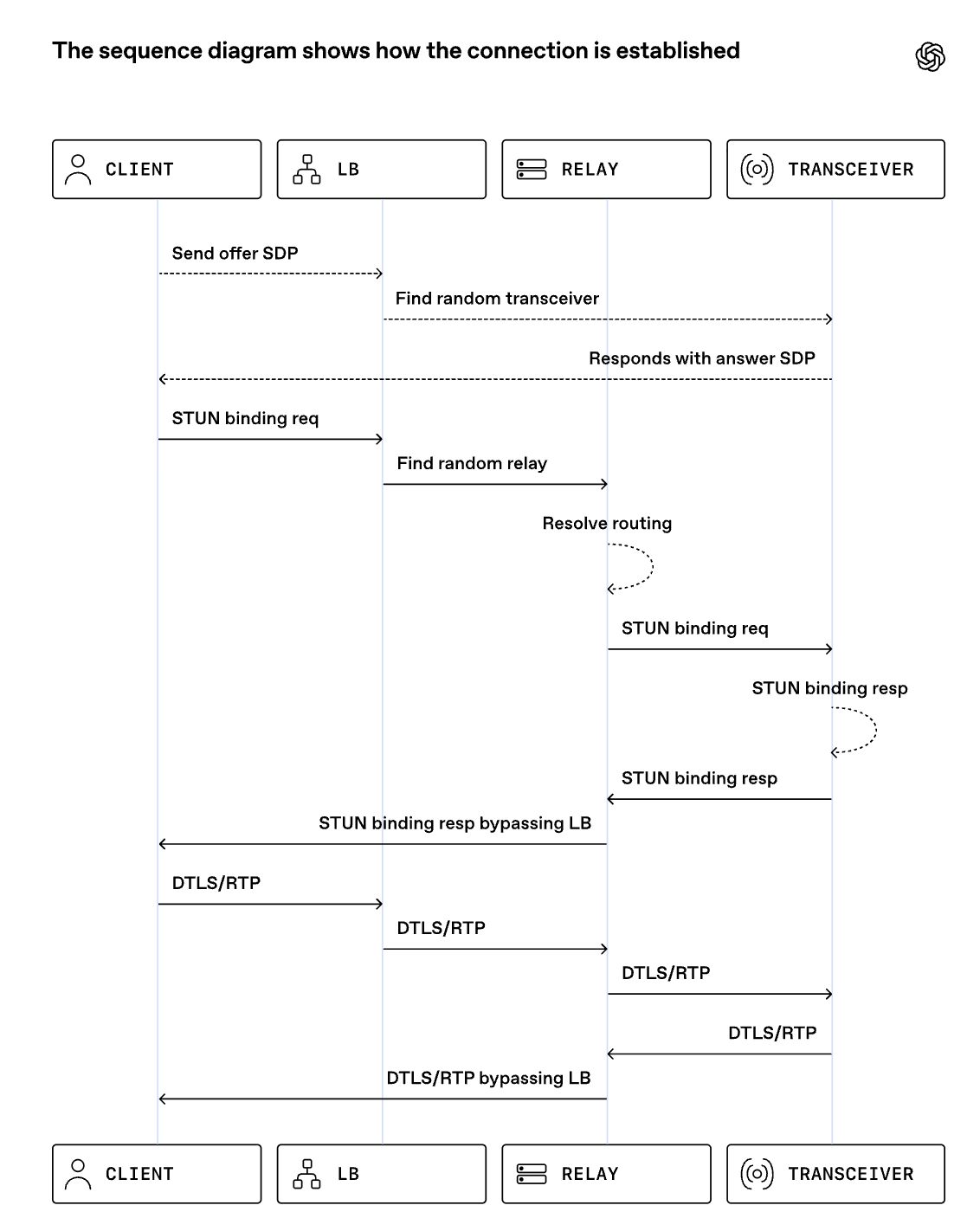
First-packet routing is the key step in this setup. A relay has to route the first packet from a client before any session exists on the packet path itself rather than by pausing on an external lookup service.
Every WebRTC session already carries a protocol-native routing hook: the ICE username fragment, or ufrag, a short identifier exchanged during session setup and echoed in STUN connectivity checks. We generate the server-side ufrag so it contains just enough routing metadata for relay to infer the destination cluster and owning transceiver.
首包路由是此设置中的关键步骤。在数据包路径上不存在任何会话的情况下,必须由中继设备先将数据包从客户端进行路由,而不是通过暂停在外部查找服务上进行处理。
每个 WebRTC 会话都自带一种基于协议的路由机制:即 ICE 用户名片段(ICE username fragment,简称 ufrag),这是在会话建立过程中交换的一个简短标识符,并在 STUN 连接检查中被重复使用。我们生成服务器端的 ufrag,使其仅包含足够的路由元数据,以便中继能够推断出目标集群和所属的transceiver。
STUN 是 WebRTC 里最核心的 "问路协议"
STUN(Session Traversal Utilities for NAT)
NAT 会话穿越工具
让内网设备知道自己在公网的 "地址",打通 P2P 通话的关键一步
想象在家用路由器上网:
手机 / 电脑是内网设备,IP 地址是 192.168.1.100 这种,外面的人根本找不到
路由器做了 NAT 转换,把内网地址伪装成一个公网 IP(比如 203.0.113.5),还分配了一个临时端口(比如 50000)
想和别人直接通话,别人需要知道在公网的真实地址和端口,不然连不上
During signaling, the transceiver allocates session state and returns a shared relay VIP and UDP port in the SDP answer. A VIP is a virtual IP address fronting the relay fleet; combined with the port, it gives the client a single stable destination, such as 203.0.113.10:3478, even though many relay instances sit behind it. The client's first media-path packet is usually a STUN (Session Traversal Utilities for NAT) binding request, which ICE uses to verify that packets can reach the advertised address.
在信号传输过程中,收发器会分配会话状态,并在 SDP 回复中返回一个共享的中继 VIP 和 UDP 端口。VIP 是中继舰队的虚拟 IP 地址;与端口结合使用后,它为客户端提供了一个稳定的单一目标地址,例如"203.0.113.10:3478",尽管其后方可能有许多中继实例。客户端的第一个媒体路径数据包通常是 STUN(网络地址转换会话穿越工具)绑定请求,ICE 利用此请求来验证数据包是否能够到达所公布的地址。
Relay parses just enough of that first STUN packet to read the server ufrag, decode the routing hint, and forward the packet to the owning transceiver. Each transceiver listens on a shared UDP socket, meaning one operating system endpoint bound to an internal IP:port, not one socket per session. After the relay creates a session from the client's source IP:port to that transceiver destination, subsequent DTLS, RTP, and RTCP packets flow within the session without re-decoding the ufrag.
中继程序仅解析该首个 STUN 数据包中的足够部分,以读取服务器的 ufrag 字段、解码路由提示,并将该数据包转发给所属的收发器。每个收发器都在一个共享的 UDP 套接字上进行监听,这意味着一个操作系统端点绑定到内部的 IP:端口,而非每个会话都有一个单独的套接字。在中继从客户端的源 IP:端口创建到该收发器目标端点的会话后,后续的 DTLS、RTP 和 RTCP 数据包会在该会话内传输,而无需再次解码 ufrag 字段。
The relay's session is purposefully minimal, consisting only of an in-memory session to inform packet forwarding, along with necessary counters for monitoring and timers for session expiration and cleanup. This design choice maintains packet routing directly on the packet path. If a relay restarts and loses the session, the next STUN packet rebuilds the session from the ufrag routing hint. To make it even more reliable, a Redis cache is employed to hold the mapping of <client IP + Port, transceiver IP + Port> once the route is established so that it can be recovered much earlier, before the next STUN packet arrives.
该中继的运行模式特意设计得非常简洁,仅包含一个内存中的会话以告知数据包转发,以及用于监控和定时的必要计数器和会话过期及清理的定时器。这一设计选择将数据包路由直接置于数据包路径上。如果中继重启并丢失会话,下一个 STUN 数据包会根据 ufrag 路由提示重新构建会话。为了使其更加可靠,还采用了 Redis 缓存来保存 <客户端 IP + 端口,收发器 IP + 端口> 的映射关系,一旦路由建立,就可以更早地恢复该映射关系,即在下一个 STUN 数据包到达之前。
Global Relay and geo-steered signaling
Once we reduced the public UDP surface to a small number of stable addresses and ports, we could deploy the same relay pattern globally. Global Relay is our fleet of geographically distributed relay ingress points that all implement the same packet-forwarding behavior.
Broad geographic ingress shortens the first client-to-OpenAI hop because a packet can enter our network at a relay close to the user, in both geography and network topology, instead of crossing the public internet to a distant region first. In practical terms, that means lower latency, less jitter, and fewer avoidable loss bursts before traffic reaches our backbone.6
The Global Relay layer receives packets from client and forwards to transceiver cluster
We use Cloudflare geo and proximity steering for signaling so the initial HTTP or WebSocket request reaches a nearby transceiver cluster. The request context dictates the session's location and which Global Relay ingress point is advertised to the client. The SDP answer provides the Global Relay address, while the ufrag contains sufficient information for Global Relay to route media to the designated cluster and relay to route to the destination transceiver.
Together, geo-steered signaling and Global Relay put both setup and media on a nearby entry path while keeping the session anchored to one transceiver. That reduces the round-trip time for signaling and for the first ICE connectivity check, which directly shortens how long a user waits before speech can start.
一旦我们将公共的 UDP surface 缩减为少数几个稳定的地址和端口,我们便能够在全球范围内部署同样的中继模式。全球中继是我们由分布在各地的中继入口点组成的车队,所有这些入口点都执行相同的数据包转发行为。
广泛的地理接入缩短了从客户端到 OpenAI 的首个传输路径,因为数据包可以在靠近用户的中继点进入我们的网络,无论是在地理位置上还是在网络拓扑结构上,而无需先穿越公共互联网到达遥远的地区。从实际角度来看,这意味着更低的延迟、更小的抖动以及在流量到达我们的骨干网之前更少的不可避免的丢包情况。6
全局中继层从客户端接收数据包,并将其转发至收发器集群。
我们使用 Cloudflare 的地理和距离导向技术来进行信令处理,这样初始的 HTTP 或 WebSocket 请求就能到达附近的收发器集群。请求上下文决定了会话的位置以及向客户端通告的全局中继入口点。SDP 回复提供了全局中继地址,而 ufrag 则包含了足够的信息,以便全局中继将媒体路由到指定的集群,并使中继路由到达目的地的收发器。
通过结合地理引导式信令和全球中继技术,将设置过程和媒体传输置于靠近的接入路径上,同时将会话固定在一台收发器上。这样就缩短了信令的往返时间以及首次 ICE 连接检查的时间,从而直接缩短了用户在开始通话前的等待时间。
Relay implementation and performance
We wrote the relay service in Go and kept the implementation narrow on purpose. On Linux, the kernel's networking stack receives UDP packets from the machine's network interface and delivers them to a socket, the operating system endpoint that a process reads after binding an IP:Port. Relay runs in userspace, so a regular Go process reads packet headers from that socket, updates a small amount of flow state, and forwards packets without terminating WebRTC. We did not need any kernel-bypass framework, which would let a userspace process poll network queues directly for higher packet rates but also add operational complexity.
Key design choices:
No protocol termination: Relay parses only STUN headers/ufrag; it uses cached state for subsequent DTLS, RTP, and RTCP, keeping packets opaque.
Ephemeral state: It maintains a small, short-timeout, in-memory map of client address to transceiver destination for flow state and observability.
Horizontal scalability: Multiple relay instances run in parallel behind a load balancer. State is not hard WebRTC state, so restarts cause minimal traffic drops and quick flow recovery.
Efficiency measures:
SO_REUSEPORT is a Linux socket option that allows multiple relay workers on the same machine to bind the same UDP port. The kernel then distributes incoming packets across those workers, which avoids a single read-loop bottleneck.
runtime.LockOSThread pins each UDP-reading goroutine to a specific OS thread. Combined with SO_REUSEPORT, that tends to keep packets from the same flow (the source and destination IP:Port plus protocol) on the same CPU core, improving cache locality and reducing context switching.
Pre-allocated buffers and minimal copying keep parsing and allocation overhead low to avoid garbage collection in Go.
This implementation handled our global real-time media traffic with a relatively small relay footprint, so we kept the simpler design instead of taking on a kernel bypass route.
我们使用 Go 语言编写了这种中继服务,并有意将实现范围控制在较小的范围内。在 Linux 系统中,内核的网络栈会从机器的网络接口接收 UDP 数据包,并将其传递到一个套接字上,该套接字是操作系统中进程在绑定 IP:端口后进行读取的端点。中继服务运行在用户空间,因此一个普通的 Go 进程会从该套接字读取数据包的头部,更新少量的流量状态,并直接转发数据包,而不会终止 WebRTC。我们不需要任何绕过内核的框架,因为这种框架会让用户空间进程直接从网络队列中轮询以获得更高的数据包传输速率,但也会增加操作的复杂性。
关键的设计决策:
无协议终止:中继仅解析 STUN 头部/用户标识符;它使用缓存状态来处理后续的 DTLS、RTP 和 RTCP,保持数据包的不可见性。
临时状态:它维护一个小型、短超时、内存中的客户端地址到收发器目的地的映射,用于流状态和可观测性。
水平扩展性:多个中继实例在负载均衡器后并行运行。状态并非 WebRTC 的硬状态,因此重启只会导致少量的流量中断和快速的流恢复。
效率措施:
SO_REUSEPORT 是一种 Linux 套接字选项,它允许同一台机器上的多个转发工作进程绑定相同的 UDP 端口。内核会将接收到的数据包分配给这些工作进程,从而避免了单个读取循环的瓶颈。
runtime.LockOSThread 会将每个 UDP 读取协程固定到特定的操作系统线程上。与 SO_REUSEPORT 结合使用时,这通常会使来自同一流(源和目标 IP:端口加上协议)的数据包保留在同一个 CPU 核心上,从而提高缓存局部性和减少上下文切换。
预先分配的缓冲区和最小的复制操作将解析和分配开销保持在较低水平,以避免 Go 语言中的垃圾回收。
这种实现方式用相对较小的转发足迹处理了我们的全球实时媒体流量,因此我们保留了更简单的设计,而不是采用内核绕过路径。
Results and learnings
semantic sɪˈmæntɪk 语义的;语义学的
invisible ɪnˈvɪzəb(ə)l adj. 看不见的,隐形的;无形的,非贸易的;被忽视的,不为人注意的
This architecture lets us run WebRTC media in Kubernetes without exposing thousands of UDP ports. That matters because a smaller and fixed UDP surface is easier to secure and load balance, and it lets the infrastructure scale without reserving large public port ranges. With better infra support from Kubernetes and more security due to smaller surface area, this design also preserves standard WebRTC behavior for clients and confirms that an SFU-less design was the right default for our workload. Most of our sessions are point-to-point, latency-sensitive, and easier to scale when inference services don't need to behave like WebRTC peers.
这种架构使我们能够在 Kubernetes 中运行 WebRTC 媒体内容,而无需暴露数千个 UDP 端口。这一点很重要,因为较小且固定的 UDP surface 更易于保护和负载均衡,并且它能让基础设施在无需预留大量公共端口范围的情况下实现扩展。借助 Kubernetes 更出色的基础设施支持以及由于较小的 surface 而带来的更高安全性,这种设计还能保持客户端的标准 WebRTC 行为,并证明无需 SFU 的设计对于我们的工作负载而言是正确的默认设置。我们大多数的会话都是点对点的、对延迟敏感的,并且在推理服务不需要像 WebRTC 对等体那样运行时,更容易进行扩展。
The broader lesson is that the best place to add complexity is in a thin routing layer, not in every backend service, and not in custom client behavior. Encoding routing metadata into a protocol-native field gave us deterministic first-packet routing, a small public UDP footprint, and enough flexibility to place ingress close to users around the world.
更广泛的教训是,添加复杂性的最佳位置应在精简的路由层中,而非在每个后端服务中,也不应在自定义客户端行为中。将路由元数据编码到协议原生字段中,为我们提供了确定性的首包路由、较小的公开 UDP 覆盖范围,并且有足够的灵活性将入口端口设置在世界各地的用户附近。
A few choices were especially important 有几项选择尤为重要:
Preserve protocol semantics at the edge. Clients still speak standard WebRTC, which keeps browser and mobile interoperability intact.
Keep hard session states in one place. Transceiver owns ICE, DTLS, SRTP, and session lifecycle; relay only forwards packets.
Route on information already present in setup. The ICE ufrag gave us a first-packet routing hook without adding a hot-path lookup dependency.
Optimize for the common case before reaching for kernel bypass. A narrow Go implementation with careful use of SO_REUSEPORT, thread pinning, and low-allocation parsing was enough for our workload.
Real-time voice AI only works when infrastructure makes latency feel invisible. For us, that meant changing the shape of our WebRTC deployment without changing what clients expect from WebRTC itself.
在边缘保留协议语义。客户端仍使用标准的 WebRTC 协议,这确保了浏览器和移动设备之间的互操作性不受影响
将硬连接状态保存在一个地方。 Transceiver 负责 ICE、DTLS、SRTP 和会话生命周期;中继器仅负责转发数据包
根据已存在的设置信息进行路由。ICE ufrag 为我们提供了一个初始数据包的路由钩子,而无需添加热路径查找依赖项
在处理核心问题之前先优化常见情况。使用精简的 Go 实现,并谨慎使用 SO_REUSEPORT、线程固定和低分配解析,就足以满足我们的工作负载需求
实时语音人工智能只有在基础设施使延迟变得几乎不可感知时才能发挥作用。对我们而言,这意味着:我们可以改变 WebRTC 在我们后端的部署形态,但丝毫不改变客户端对 WebRTC 本身的预期。 (clients expect what from WebRTC itself)