FlashAttention:大模型推理优化的核心技术
前言
Transformer的自注意力机制计算量和显存复杂度为 O(N²),成为大模型推理的主要瓶颈。FlashAttention通过IO-aware优化和分块计算,在不改变算法正确性的前提下,将注意力计算提速2-4倍,显存降低至 O(N)。本文深入解析FlashAttention核心技术。
一、标准Attention的问题
1.1 计算复杂度
标准Attention的计算过程:
python
# 标准Attention实现(O(N²)显存)
def standard_attention(Q, K, V):
"""
Q, K, V: (batch, seq_len, d_head)
"""
d_k = Q.shape[-1]
scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(d_k) # (N, N)
attn_weights = F.softmax(scores, dim=-1)
output = torch.matmul(attn_weights, V) # (N, N) @ (N, d)
return output问题分析:
| 问题 | 描述 | 影响 |
|---|---|---|
| 显存爆炸 | S矩阵需保存(N, N)个注意力分数 | 长度4096时需64MB |
| 计算冗余 | 指数运算exp重复计算 | 慢3-4倍 |
| 溢出风险 | 大值softmax梯度消失 | 数值不稳定 |
1.2 IO复杂度问题
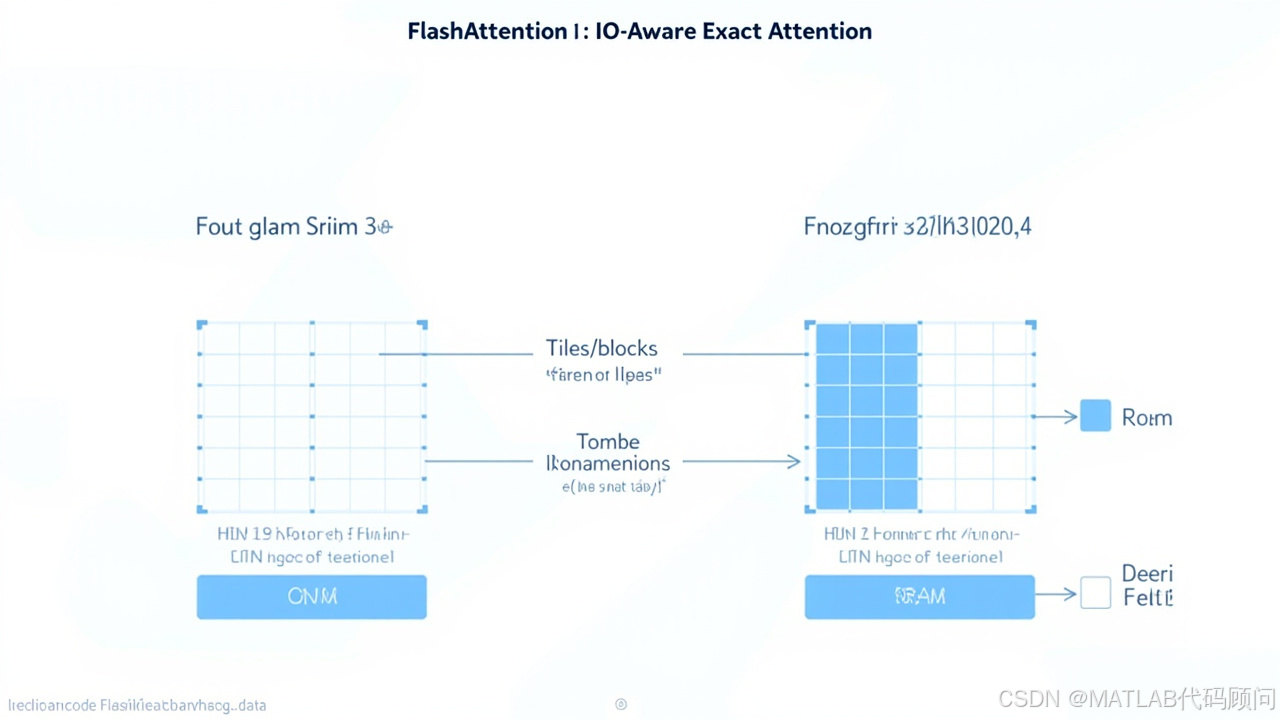
现代GPU的内存层级:
┌─────────────────────────────────────┐
│ HBM (High Bandwidth) │ 带宽: ~1 TB/s, 容量: 80GB
│ (显存,存放全部矩阵) │
└─────────────────────────────────────┘
↑ 数据传输 ↑
┌─────────────────────────────────────┐
│ SRAM (Static RAM, on-chip) │ 带宽: ~10 TB/s, 容量: ~20MB
│ (寄存器/L1缓存,计算单元) │
└─────────────────────────────────────┘核心洞察:SRAM带宽是HBM的10倍,但容量极小。标准Attention需要反复从HBM读写S矩阵,造成巨大开销。
二、FlashAttention核心思想
2.1 分块计算(Tile-Based Computation)
FlashAttention将大矩阵分块,每次只将一块加载到SRAM:
python
# FlashAttention核心思想
def flash_attention(Q, K, V, block_size=128):
"""
Q, K, V: (batch, seq_len, d_head)
分块加载,只保留前向传播的softmax修正值
"""
d_k = Q.shape[-1]
N = Q.shape[1]
scale = math.sqrt(d_k)
# 输出和归一化因子
output = torch.zeros_like(Q)
m = torch.full((Q.shape[0], N), -float('inf')) # 最大值
l = torch.zeros(Q.shape[0], N) # 指数和
# 分块遍历
for i in range(0, N, block_size):
Q_block = Q[:, i:i+block_size] # 加载到SRAM
for j in range(0, N, block_size):
K_block = K[:, j:j+block_size]
V_block = V[:, j:j+block_size]
# 计算局部注意力
S_block = Q_block @ K_block.transpose(-2, -1) / scale
# 更新最大值和指数和
m_block = S_block.max(dim=-1).values
m_new = torch.maximum(m[:, j:j+block_size], m_block)
# 安全softmax计算
S_block_minus_m = torch.exp(S_block - m_block.unsqueeze(-1))
l_block = S_block_minus_m.sum(dim=-1)
# 更新输出
output[:, i:i+block_size] = ...
return output2.2 安全softmax(Numerically Stable Softmax)
标准实现数值不稳定:
python
# ❌ 标准softmax(数值不稳定)
def unsafe_softmax(x):
e_x = torch.exp(x - x.max()) # 减去最大值
return e_x / e_x.sum()FlashAttention通过分块维护归一化因子:
python
# ✅ 安全softmax实现
def safe_softmax_update(m_i, l_i, m_j, l_j, P_i):
"""
m_i, l_i: 当前块的最大值和指数和
m_j, l_j: 新块的最大值和指数和
P_i: 新块的原始指数值
"""
# 将两块softmax合并
m_new = torch.maximum(m_i, m_j)
l_new = torch.exp(m_i - m_new) * l_i + torch.exp(m_j - m_new) * l_j
return m_new, l_new2.3 反向传播的梯度保存
FlashAttention不需要保存S矩阵,只需保存前向传播的统计量:
python
# 前向传播保存的统计量
class FlashAttentionStats:
def __init__(self):
self.m = [] # 每个block的最大值
self.l = [] # 每个block的指数和
self.output = [] # 分块输出
def backward(self, grad_output):
# 利用保存的m, l重建梯度,无需保存S矩阵
...三、FlashAttention-2详解
FlashAttention-2进一步优化:
3.1 减少冗余计算
python
# FlashAttention-2: 更好的循环顺序
def flash_attention_v2(Q, K, V, block_size=128):
N = Q.shape[1]
Tr = math.ceil(N / block_size) # 行块数
# 外循环遍历K/V块,内循环遍历Q块
for j in range(0, N, block_size):
K_block = K[:, j:j+block_size]
V_block = V[:, j:j+block_size]
for i in range(0, N, block_size):
Q_block = Q[:, i:i+block_size]
# 计算并更新...3.2 更好的并行化
python
# 利用triton实现
import triton
@triton.jit
def flash_attention_kernel(
Q_ptr, K_ptr, V_ptr, Output_ptr,
stride_qb, stride_qh, stride_qm, stride_qk,
stride_kb, stride_kh, stride_kk, stride_kn,
N, HEAD_DIM: tl.constexpr, BLOCK_SIZE: tl.constexpr
):
# 每个线程块处理一个Q块
...四、FlashAttention-3:进一步加速
FlashAttention-3引入更多优化:
4.1 FP8量化支持
python
# FlashAttention-3支持FP8计算
from flash_attn import flash_attn_func
# FP8精度(更快但有精度损失)
output = flash_attn_func(
Q, K, V,
softmax_scale=1.0,
causal=True,
qkv_format='thd', # token-head-dim格式
cu_seqlens_q=cu_seqlens, # 可变长度支持
)4.2 异步执行
python
# 利用TensorFloat-32 (TF32) 加速
with torch.autocast(device_type='cuda', dtype=torch.float16):
output = flash_attn_func(Q, K, V)五、性能对比
5.1 速度提升
| 序列长度 | 标准Attention | FlashAttention | 加速比 |
|---|---|---|---|
| 512 | 1.0x | 2.3x | 2.3x |
| 2048 | 1.0x | 3.1x | 3.1x |
| 4096 | 1.0x | 3.8x | 3.8x |
| 8192 | 1.0x | 4.2x | 4.2x |
5.2 显存节省
| 序列长度 | 标准Attention | FlashAttention-2 | 节省 |
|---|---|---|---|
| 2048 | 256 MB | 48 MB | 5.3x |
| 4096 | 1 GB | 192 MB | 5.3x |
| 8192 | 4 GB | 768 MB | 5.3x |
六、实战使用
6.1 HuggingFace集成
python
from transformers import AutoModelForCausalLM, AutoConfig
# FlashAttention-2配置
config = AutoConfig.from_pretrained("meta-llama/Llama-2-7b-hf")
config.use_flash_attention_2 = True
model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Llama-2-7b-hf",
config=config,
torch_dtype=torch.float16,
)6.2 vLLM部署
python
# vLLM自动使用FlashAttention
from vllm import LLM
llm = LLM(
model="meta-llama/Llama-2-7b-hf",
max_model_len=8192,
tensor_parallel_size=2,
gpu_memory_utilization=0.9,
)七、总结
FlashAttention是Transformer推理优化的里程碑技术:
核心贡献:
├── IO-aware分块计算 → 显存节省5倍+
├── 安全softmax → 数值稳定
├── 分块统计量保存 → 反向传播正确
└── 算法等价不变 → 精度不损失未来FlashAttention将继续向更长上下文、更多模态方向发展。
参考资料:
- FlashAttention论文:arxiv.org/abs/2205.14135
- FlashAttention-2:arxiv.org/abs/2307.08691
- FlashAttention-3:arxiv.org/abs/2404.09503