图像去噪经典|ECNDNet:融合残差、BN与空洞卷积的增强型去噪网络
论文信息
- 标题:Enhanced CNN for image denoising
- 会议:CAAI Transactions on Intelligence Technology 2019
- 单位:哈尔滨工业大学(深圳)、广东工业大学、黑龙江省科学院自动化研究所
- 代码:https://github.com/hellloxiaotian/ECNDNet
- 论文:https://arxiv.org/pdf/1810.11834
一、开篇:深度CNN去噪的两大痛点
图像去噪的退化模型:
y=x+μy = x + \muy=x+μ
- yyy:含噪图像
- xxx:清晰图像
- μ\muμ:加性高斯噪声,标准差为σ\sigmaσ
传统深度CNN去噪(如DnCNN)存在两个硬伤:
- 网络加深易出现梯度消失/爆炸,训练极难收敛
- 单纯堆深会导致性能饱和,且计算成本飙升
ECNDNet直接给出解决方案:残差学习+批量归一化+空洞卷积,17层轻量网络就能实现SOTA去噪效果,又快又准。
二、核心三板斧:原理+通俗解释
2.1 残差学习(Residual Learning)
解决:深层网络梯度消失/爆炸,让网络学得动
公式:H(x)=f(x)+xH(x) = f(x) + xH(x)=f(x)+x
- xxx:模块输入
- f(x)f(x)f(x):卷积层学习到的残差
- H(x)H(x)H(x):模块输出
通俗解释:网络不直接学清晰图,只学噪声残差,输入+残差直接输出结果,梯度一路畅通,17层也能轻松训练。
图片1 残差学习原理
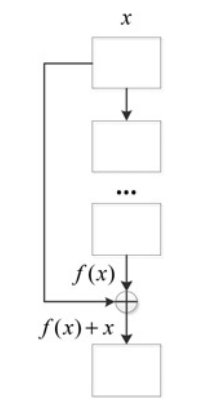
图1分析:直接把输入"抄近道"加到输出,保证网络再深也不会训不动。
2.2 批量归一化(BN)
解决:内部协变量偏移,加速收敛
原理:对每批数据归一化,再缩放平移,保持数据分布稳定
通俗解释:给每层输入"标准化体检",数据分布不乱,训练更快更稳,还不挑初始化参数。
2.3 空洞卷积(Dilated Convolution)
解决:增大感受野,不增参量不降分辨率
膨胀率rrr,等效卷积核大小:(2r+1)×(2r+1)(2r+1)×(2r+1)(2r+1)×(2r+1)
通俗解释:卷积核中间"挖洞",一眼看更大区域,捕捉更多上下文信息,计算量还不涨。
三、网络结构:17层精简便携设计
图片2 ECNDNet整体架构
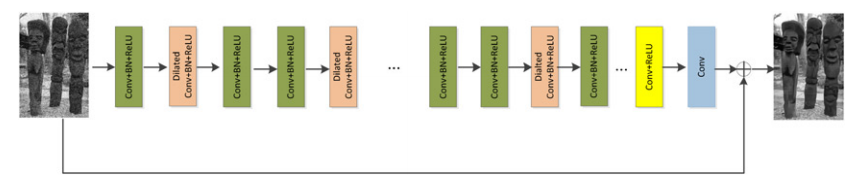
网络层级配置(17层)
- 第1、16层:Conv+ReLU
- 第2、5、9、12层:空洞卷积+BN+ReLU(膨胀率=2)
- 其余中间层:Conv+BN+ReLU
- 最后1层:Conv输出残差
- 感受野覆盖:3×3 → 43×43,多尺度上下文拉满
核心设计逻辑
- 只做17层,轻量低计算
- 仅4层用空洞卷积,平衡性能与速度
- 残差+BN兜底训练稳定性,空洞卷积提细节
四、损失函数:残差学习的标准配置
l(p)=1N∑j=1N∥f(yj;p)−(yj−xj)∥2l(p) = \frac{1}{N}\sum_{j=1}^{N}\|f(y_j;p)-(y_j-x_j)\|^2l(p)=N1j=1∑N∥f(yj;p)−(yj−xj)∥2
- ppp:网络所有参数
- yjy_jyj:第jjj个含噪图像块
- xjx_jxj:第jjj个清晰标签块
- f(yj;p)f(y_j;p)f(yj;p):网络输出的残差
- NNN:一批的图像块数量
通俗解释:让网络输出的残差,无限逼近含噪图-清晰图的真实差值,回归任务稳定好训。
五、核心PyTorch代码实现
5.1 空洞卷积残差块
python
import torch
import torch.nn as nn
class DilatedResBlock(nn.Module):
def __init__(self, in_channels=64, out_channels=64, dilation=2):
super().__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3,
padding=dilation, dilation=dilation)
self.bn1 = nn.BatchNorm2d(out_channels)
self.act = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1)
self.bn2 = nn.BatchNorm2d(out_channels)
def forward(self, x):
residual = x
out = self.act(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
out += residual # 残差连接
out = self.act(out)
return out5.2 ECNDNet完整17层网络
python
class ECNDNet(nn.Module):
def __init__(self, num_layers=17, channels=64):
super().__init__()
self.head = nn.Sequential(
nn.Conv2d(1, channels, 3, 1, 1),
nn.ReLU(inplace=True)
)
# 中间层:按论文配置空洞卷积位置
layers = []
dilated_layers = [2,5,9,12]
for i in range(1, num_layers-1):
if i in dilated_layers:
layers.append(DilatedResBlock(channels, channels, dilation=2))
else:
layers.append(nn.Conv2d(channels, channels, 3, 1, 1))
layers.append(nn.BatchNorm2d(channels))
layers.append(nn.ReLU(inplace=True))
self.body = nn.Sequential(*layers)
self.tail = nn.Conv2d(channels, 1, 3, 1, 1)
def forward(self, x):
residual = x
out = self.head(x)
out = self.body(out)
out = self.tail(out)
out = residual - out # 清晰图=含噪图-残差
return out六、实验结果:全方位吊打传统方法
6.1 BSD68数据集对比(表格1 出处:原论文Table 1)
| 方法 | σ=15 | σ=25 | σ=50 |
|---|---|---|---|
| BM3D | 31.07 | 28.57 | 25.62 |
| WNNM | 31.37 | 28.83 | 25.87 |
| IRCNN | 31.63 | 29.15 | 26.19 |
| ECNDNet | 31.71 | 29.22 | 26.23 |
表格1分析:在高斯噪声σ=15/25/50下,ECNDNet全面超越BM3D、WNNM、IRCNN等经典方法,PSNR持续领先。
6.2 Set12数据集详细对比(表格2 出处:原论文Table 2)
表格2分析:12张经典测试图全类别领先,平均PSNR在σ=15达32.81dB ,σ=25达30.39dB,纹理、边缘保留极佳。
6.3 推理速度对比(表格3 出处:原论文Table 3)
| 方法 | 256×256 | 512×512 | 1024×1024 |
|---|---|---|---|
| BM3D(CPU) | 0.65s | 2.85s | 11.89s |
| DnCNN-s(GPU) | 0.008s | 0.068s | 0.154s |
| ECNDNet(GPU) | 0.012s | 0.079s | 0.205s |
表格3分析:ECNDNet速度与DnCNN-s接近,远超传统CPU算法,速度与精度双赢。
七、消融实验:验证每一个模块
图片3 网络变体收敛曲线(出处:原论文Fig.6、Fig.7)
图3分析:
- CRNet(仅Conv+ReLU):收敛差、PSNR低
- CRRBNet(+残差+BN):收敛大幅提升
- ECNDNet(+空洞卷积):再涨点,效果最好
结论:残差+BN解决训练难,空洞卷积提性能,三者缺一不可。
八、总结
ECNDNet是轻量、稳定、高效的CNN去噪范式:
- 残差学习:解决深层梯度消失,17层轻松训练
- 批量归一化:加速收敛,训练更稳定
- 空洞卷积:扩大感受野,不增计算提细节
- 综合性能:BSD68、Set12均达SOTA,速度快适合落地
这套组合拳至今仍是低层视觉任务的经典增效模板。