1. 背景
在分布式微服务架构中,多个事件源可能同时触发相同或相似的计算逻辑。例如,当用户操作、定时任务或外部系统通知等多种来源需要对同一业务对象进行状态计算时,如果每个事件都立即独立触发计算,将导致以下问题:
1.1核心问题分析
- 重复计算问题:短时间内同一业务对象的多个事件触发相同计算逻辑,造成大量重复的CPU、数据库和网络资源消耗。
- 并发控制难题:多实例同时执行相同计算逻辑可能导致中间状态不一致,影响最终结果的准确性。
- 优先级处理缺失:不同重要性的事件(如核心业务流程事件与辅助性更新事件)缺乏差异化处理机制。
- 分布式协调复杂性:在多实例部署环境下,需要确保任务被正确处理且不重复消费。
1.2 解决思路
基于以上问题,我们设计了基于Redis ZSet的分布式优先级队列方案:
- 解耦与缓冲:事件发生时仅将任务标识放入队列,实现事件触发与计算执行的解耦。
- 智能合并:利用ZSet唯一性和分数机制,自动合并同一任务的多次触发。
- 有序消费:通过单线程或有限并发消费队列任务,确保计算按优先级顺序串行执行。
- 弹性调度:支持按业务需求调整任务优先级,确保关键任务优先处理。
1.3 Redis ZSet核心特性
Redis有序集合(ZSet)具有以下关键特性,非常适合实现分布式优先级队列:
| 特性 | 说明 | 队列应用 |
| 唯一性 | 集合中每个成员(member)唯一 | 天然支持任务去重,同一任务ID不会重复存储 |
| 有序性 | 成员按分数(score)从小到大排序 | 通过分数实现优先级控制,高分数优先处理 |
| 高效性 | 添加、删除、查询时间复杂度O(log N) | 支持高并发场景下的快速操作 |
| 原子性 | Redis命令原子执行 | 确保并发环境下的数据一致性 |
| 丰富API | 提供范围查询、分数增减等操作 | 方便实现复杂队列逻辑 |
2. 核心方案
2.1 系统架构
- 生产者: 事件接收器接收多个外部事件,将需要处理的任务ID放入ZSet
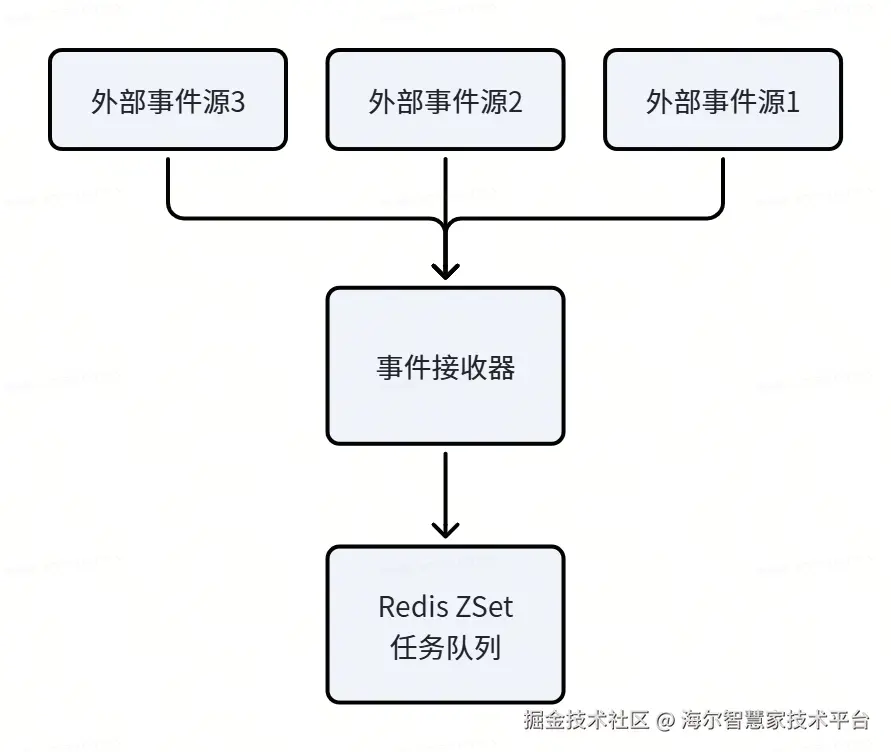
- 队列存储: 按日期分键存储,分数表示任务优先级/触发次数
- 消费者: 单实例定时任务按分数顺序消费,保证处理顺序
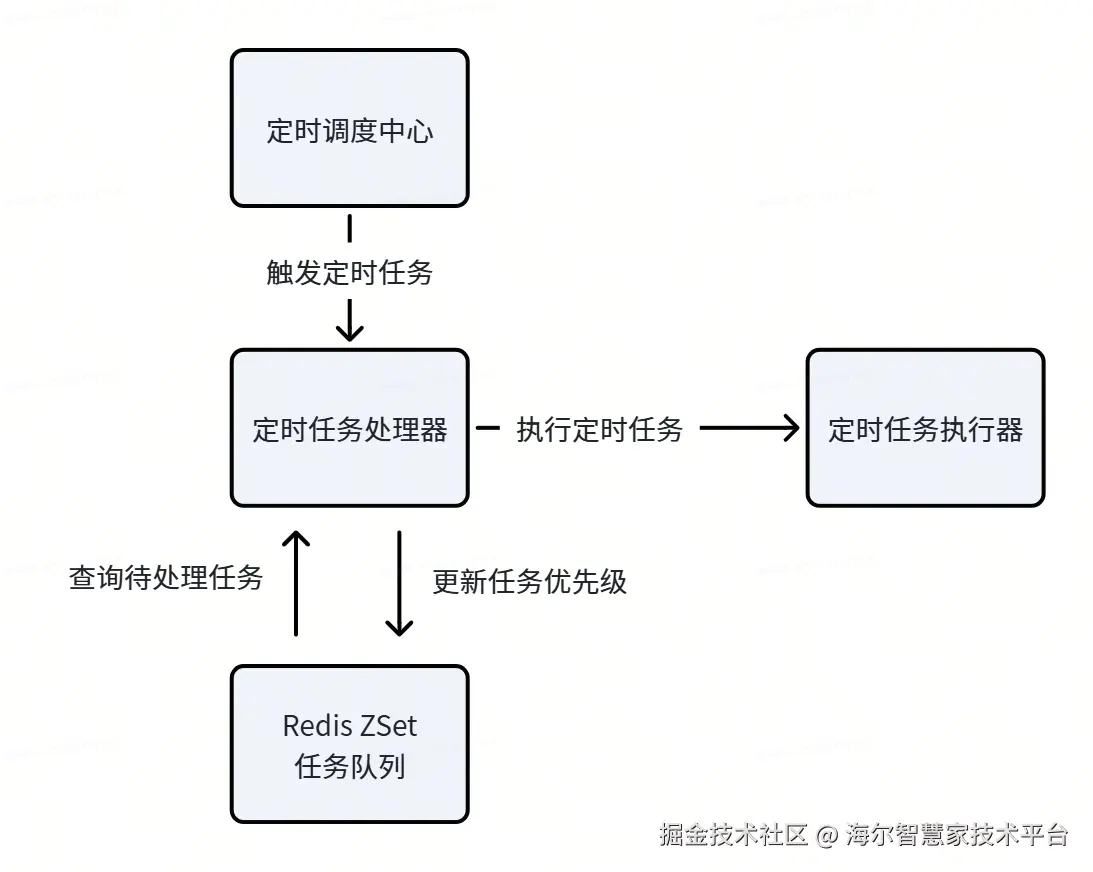
2.2 核心实现机制
2.2.1 任务入队机制
通过incrementScore方法实现智能任务入队,多次添加同一任务仅增加其分数:
typescript
/**
* 将任务ID添加到优先级队列
*/
public void addToQueue(Set<String> ids) {
try {
if (CollectionUtils.isEmpty(ids)) {
return;
}
String key = getKey(LocalDateTime.now());
deliverablesVersionIds.forEach(id -> {
redisTemplate.opsForZSet().incrementScore(key, id, 1);
});
redisTemplate.expire(key, 1, TimeUnit.DAYS); // 1天后过期
log.info("addToQueue:{}", JSON.toJSONString(ids));
} catch (Throwable e) {
log.error("addToQueue error, {}", ids, e);
}
}
/**
* 生成队列键名,格式:queue:task1:calc:yyyyMMdd
*/
private String getKey(LocalDateTime time) {
String dateStr = DateTimeFormatter.ofPattern("yyyyMMdd").format(time);
return String.format("queue:task1:calc:%s", dateStr);
}设计要点:
- 智能去重:使用
incrementScore而非add,确保同一任务多次触发只增加优先级分数 - 资源保护:设置1天过期时间,自动清理历史数据
- 异常处理:捕获Redis异常,避免影响主业务流程
2.2.2 任务出队与消费机制
定时按优先级顺序获取待处理任务,单线程执行
typescript
/**
* 从优先级队列获取待处理任务
* 按分数降序获取最高优先级任务,支持跨天数据保护
*
* @return 任务信息列表,包含队列键、任务ID和当前分数
*/
public List<TaskItem> getFromQueue() {
try {
// 防止跨天时丢失数据,减去1分钟
String key = getKey(LocalDateTime.now().minusMinutes(1));
// 只取Score大于等于1的任务
Set<ZSetOperations.TypedTuple<String>> typedTuples = redisTemplate.opsForZSet()
.reverseRangeByScoreWithScores(key, 1, Double.MAX_VALUE);
List<TaskItem> result = TaskItem.convert(key, typedTuples);
log.info("getFromQueue:{}", JSON.toJSONString(result));
return result;
} catch (Throwable e) {
log.error("getFromQueue error", e);
return new ArrayList<>();
}
}
/**
* 将TypedTuple转换为任务对象
*/
private TaskItem convertToTaskItem(String queueKey, ZSetOperations.TypedTuple<String> tuple) {
if (tuple == null || tuple.getValue() == null) {
return null;
}
TaskItem task = new TaskItem();
task.setKey(queueKey);
task.setValue(tuple.getValue());
task.setScore(tuple.getScore() != null ? tuple.getScore() : 0.0);
return task;
}设计要点
- 任务获取:每次仅处理优先级最高的任务,单个定时任务周期内多个触发事件合并为一次计算。
- 降序优先级:使用
reverseRangeByScoreWithScores确保高分任务优先 - 最小化并发影响:定时任务单线程获取任务批量执行,避免并发处理导致的数据竞争和资源争用
- 时间边界安全:防止午夜时分区键切换导致任务丢失
2.2.3 任务完成确认机制
scss
/**
* 任务完成确认 - 通过减少分数标记任务完成
* 当分数减至0时,任务自动从ZSet中移除
*
* @param taskItem 已完成的任务项
*/
public void removeFromQueue(TaskItem taskItem) {
if (taskItem == null) {
return;
}
try {
redisTemplate.opsForZSet().incrementScore(
taskItem.getKey(), taskItem.getValue(), -taskItem.getScore());
redisTemplate.opsForZSet().removeRangeByScore(keyValueAndCount.getKey(), -1, 0);
log.info("removeFromQueue:{}", taskItem);
} catch (Throwable e) {
log.error("removeFromQueue error, {}", taskItem, e);
}
}设计要点:
- 原子操作:Redis单命令操作保证原子性,避免并发环境下数据竞争
- 自动清理:当分数减至0或负数时,自动移除任务项
- 无漏处理:处理期间的新事件不会丢失,避免漏处理
2.3 设计亮点与优势
2.3.1 基于时间的键命名策略
java
typescript
private static String getKey(LocalDateTime time) {
String suffix = DateTimeUtils.format(time, "yyyyMMdd");
return PREFIX_DELIVERABLES_VERSION_QUALIFY_STATUS_CALCULATION + suffix;
}优势:
- 实现数据的周期性隔离,避免单个键数据量过大导致的性能问题。
- 单个键设计有效期,便于过期自动清理。
2.3.2 跨天数据丢失防护
java
ini
String key = getKey(LocalDateTime.now().minusMinutes(1));优势:
- 在午夜时分同时检查前后两天的队列
- 确保任务不会因时间切换而丢失
2.3.3 任务队列
- 重复添加同一任务只会增加其分数,自动合并相同计算任务
- 任务完成后,减少相应分数,当分数减至0时从集合中删除
- 无漏处理,处理期间的新事件不会丢失,避免漏处理
- 定时任务单线程获取任务批量执行,避免并发处理导致的数据竞争和资源争用
2.4 性能与可靠性优势
- 高性能:基于Redis内存存储,支持高并发读写
- 原子性:Redis操作天然具备原子性,保证数据一致性
- 灵活性:支持动态调整任务优先级
- 可扩展性:支持分布式部署,易于水平扩展
- 可靠性:防止任务重复处理、漏处理,避免并发处理影响数据一致性
3. 应用效果
该方案已在生产环境中稳定运行,有效解决了:
- 重复计算问题,系统资源利用率提升约30%
- 数据一致性问题,计算准确性达到100%
- 任务处理的优先级管理,关键任务处理时效性提升50%
- 解决多线程并发问题,定时任务+单线程执行,避免了多个线程同时修改共享数据造成数据不一致问题
4. 后记
通过Redis ZSet实现的分布式优先级队列,不仅解决了传统队列在优先级管理和分布式部署方面的痛点,还提供了良好的性能和可靠性保障,为构建高效、可靠的后台任务处理系统提供了优秀的解决方案。
5. 团队介绍
「智慧家技术平台-智家APP开发」通过持续迭代演进移动端一站式接入平台为三翼鸟APP、智家APP等多个APP提供基础运行框架、系统通用能力API、日志、网络访问、页面路由、动态化框架、UI组件库等移动端开发通用基础设施;通过Z·ONE平台为三翼鸟子领域提供项目管理和技术实践支撑能力,完成从代码托管、CI/CD系统、业务发布、线上实时监控等Devops与工程效能基础设施搭建。