CH表引擎的四大分类
MergeTree 家族:ClickHouse 的核心,用于海量数据分析。
Log 家族:用于轻量级、快速写入的临时数据场景。
Integration 引擎:用于与外部系统(如 MySQL, Kafka, S3)集成。
Special 引擎:用于特殊用途(如 Memory, Distributed, MaterializedView)
log
Log 家族是 ClickHouse 中最简单的表引擎,适用于那些一次写入、多次读取的轻量级场景。它们的设计目标是快速地将数据追加到磁盘,结构简单。
不支持索引:无法利用索引进行快速查询。
并发写锁定:当有写操作时,表会被锁定,所有读写操作都会被阻塞,因此不适合高并发写入。
原子性写入:数据写入是原子性的,要么成功,要么失败。
追加式写入:数据总是以块的形式追加到文件末尾。
适用场景
临时存储中间计算结果。
小批量、非核心业务的日志快速写入。
数据量不大(通常建议百万行以下)的配置表或元数据表。
警告:绝对不要在生产环境的核心分析业务中使用 Log 家族引擎!
建表
tiny_log
sql
create table learning.tiny_log_table(
timestamp DateTime,
level String,
message String
) engine = TinyLog;写入
sql
insert into learning.tiny_log_table values (now(),'debug','logining');
insert into learning.tiny_log_table values (now(),'info','disk speed is low');查看文件
打开 cd /var/lib/clickhouse/data/learning/tiny_log_table/
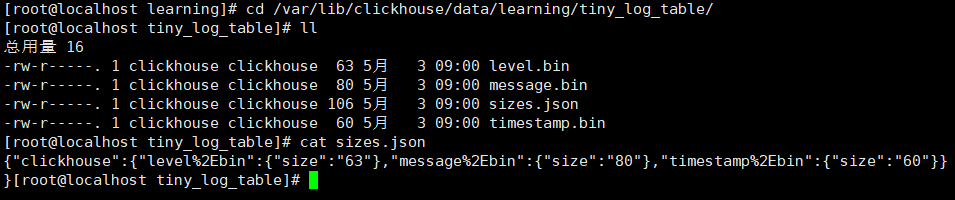
可以看到 tiny_log_table 表中的每个列都有一个独立的.bin文件存储
size.json 存的是 每个列的大小
当你执行 SELECT level FROM ...时,TinyLog只需要读取 level.bin这一个文件,而不需要扫描整行数据。这在分析型场景(OLAP)中非常高效。
对于 TinyLog这种轻量级引擎,这种"一列一个文件"的结构实现最简单,开销最小。
LOG
sql
create table learning.log_table(
timestamp DateTime,
level String,
message String
) engine = Log;
Log 和tinyLog 有点区别,额外包含一个小型的元数据文件(__marks.mrk),记录了每个数据块的偏移量。
支持并发读取:多个客户端可以同时读取不同数据块。
跳过数据块:读取时可以直接跳过不需要的数据块,提升查询性能。
性能略好于 TinyLog。
StripeLog
sql
create table learning.StripeLog_table(
timestamp DateTime,
level String,
message String
) engine = StripeLog;
StripeLog 把数据全部放到一个文件下 data.bin
总结
ClickHouse 的设计理念是"One Size Does Not Fit All"(没有一种引擎能解决所有问题)。
MergeTree 是为了解决 PB 级数据分析。
Log 是为了解决 MB 级临时存储。
不支持分布式和副本,恰恰是它的优势所在:这意味着它没有协调节点的网络开销,没有数据同步的延迟,实现了极致的单点性能。
什么时候该用 Log?
记住这个简单的决策树
数据量是否 < 100 万行?
是否只需要快速写入和全量读取?
数据是否允许丢失(无副本)或只是临时性的?
如果以上答案都是"是",那么 Log 引擎就是比 MergeTree 更优的选择。 它用"功能阉割"换来了"极致的轻量与速度"。