Redis 主从复制学习总结:从库到底是怎么跟上主库的?
一开始学的时候,容易只记住一句话:主从复制就是一个 Redis 复制另一个 Redis 的数据。
但是只记住这句话其实不够。因为后面会出现几个容易混的词:replicaof、全量同步、增量同步、offset、replication id,还有 info replication 里一堆字段。如果这些不串起来,配置的时候能照着敲,但是问原理就容易断。
这篇我把 Redis 主从复制重新整理一遍。
一、主从复制是干什么的?
Redis 主从复制,简单说就是:
让一个 Redis 服务器作为主节点 Master,其他 Redis 服务器作为从节点 Replica/Slave,从节点自动复制主节点的数据。
大概长这样:
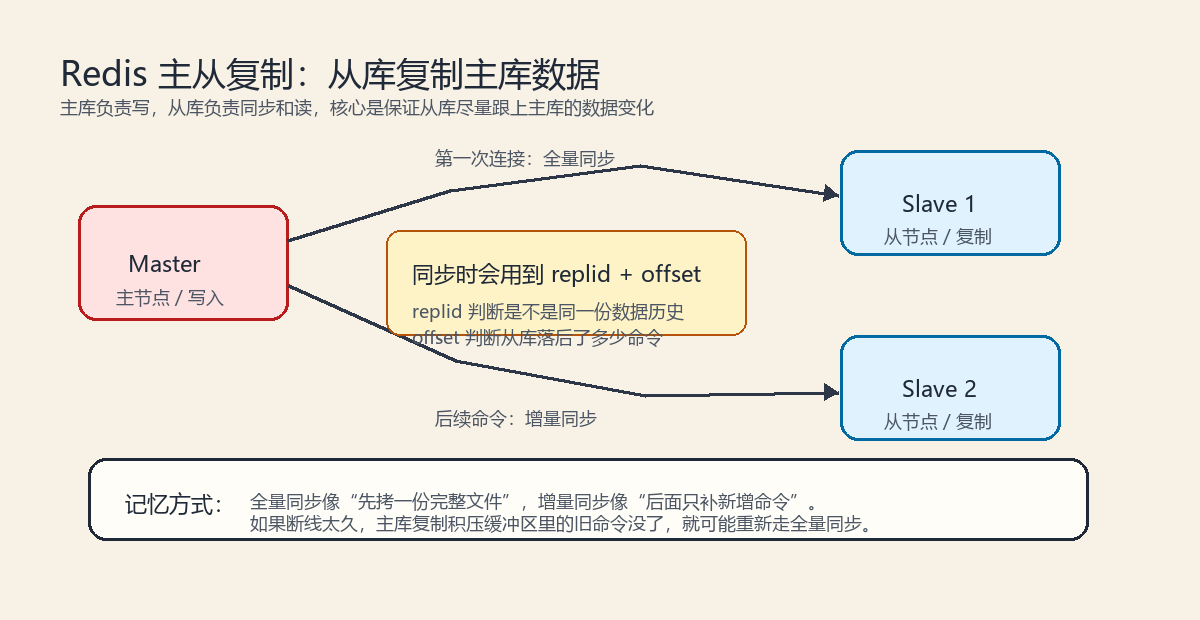
主节点一般负责写数据,从节点负责同步主节点的数据,也可以用来分担读请求。
比如现在有三个 Redis:
text
6379 作为主节点 master
6380 作为从节点 replica1
6381 作为从节点 replica2那么我们希望达到的效果是:
text
客户端往 6379 写入数据
6380、6381 自动同步 6379 的数据也就是说,我只需要在主库写一次,从库就会跟着变。
二、为什么要有主从复制?
我现在这样理解它的作用:
1. 做数据备份
如果只有一个 Redis,一旦这个 Redis 挂了,数据就比较危险。
有了从库之后,主库的数据会复制到从库上,相当于多了一份备份。
当然,这里要注意:主从复制不是严格意义上的"万无一失备份",因为它是异步复制,主库刚写完还没同步给从库时,如果主库突然挂掉,极端情况下还是可能丢一小部分数据。
2. 做读写分离
一般写操作走主库,读操作可以分给从库。
text
写:client -> master
读:client -> replica1 / replica2这样主库压力会小一点。
3. 给哨兵/集群打基础
后面学 Redis 哨兵的时候,会发现哨兵能做故障转移,前提就是先有主从结构。
主从复制是后面高可用的基础。
三、主从结构怎么搭?
现在 Redis 里更推荐用 replicaof,老版本里也经常看到 slaveof。
基本语法是:
bash
replicaof 主节点IP 主节点端口比如让当前 Redis 变成 127.0.0.1:6379 的从库:
bash
replicaof 127.0.0.1 6379如果是在配置文件里写,就是:
conf
replicaof 127.0.0.1 6379如果主库设置了密码,还要在从库配置里写:
conf
masterauth 主库密码这里要记住:
text
谁写 replicaof,谁就变成从库。不是在主库上写"我要带几个从库",而是在从库上告诉它:"你去复制谁"。
四、用 info replication 查看主从状态
配置完之后,可以用:
bash
info replication主库上可能看到类似信息:
text
role:master
connected_slaves:2
master_replid:xxxxxx
master_repl_offset:12345从库上可能看到类似信息:
text
role:slave
master_host:127.0.0.1
master_port:6379
master_link_status:up
slave_repl_offset:12345这些字段不用一开始全背,但是几个关键的要认识。
| 字段 | 含义 |
|---|---|
role:master |
当前 Redis 是主节点 |
role:slave / role:replica |
当前 Redis 是从节点 |
connected_slaves |
当前主库连接了几个从库 |
master_link_status:up |
从库和主库连接正常 |
master_replid |
主库的复制 ID,可以理解成这份数据历史的身份标识 |
master_repl_offset |
主库当前复制偏移量 |
slave_repl_offset |
从库已经同步到的位置 |
我觉得这里最容易懵的是 replid 和 offset,后面单独讲。
五、第一次同步:全量同步
从库第一次连接主库时,一般要先来一次完整同步,也就是全量同步。
可以先把它理解成:
从库刚加入时,自己啥也没有,所以主库先给它一份完整数据。
大概流程是:
Master 主库 Replica 从库 Master 主库 Replica 从库 发送 PSYNC ? -1 执行 bgsave,生成 RDB 文件 发送 RDB 文件 清空旧数据,加载 RDB 发送 RDB 期间积压的新写命令 执行这些命令,追上主库
这里面有几个点要记住。
1. 从库第一次会发送 PSYNC ? -1
? 表示:我还不知道主库的复制 ID。
-1 表示:我也不知道自己同步到哪个位置。
所以主库一看就知道:这是第一次同步,那就走全量同步。
2. 主库会生成 RDB 文件
主库不会一条一条把所有数据重新发过去,而是先生成一份 RDB 快照。
这个动作一般是通过 bgsave 完成的。
text
主库 fork 子进程 -> 生成 RDB -> 发给从库3. 从库加载 RDB
从库收到 RDB 后,会先清空自己的旧数据,然后加载这份 RDB。
所以从库第一次同步时,原来的数据会被覆盖。
4. RDB 生成期间的新命令怎么办?
这个地方很关键。
主库生成 RDB 不是一瞬间完成的。在生成 RDB 的过程中,主库可能还在接收新的写命令。
这些新命令不能丢,所以主库会把它们先记录起来,等 RDB 发完后,再把这段时间产生的新命令补发给从库。
说白了就是:
text
先发一份完整快照
再把快照期间漏掉的新命令补上这样从库最后才能追上主库。
六、后续同步:命令传播
全量同步完成以后,主库后面再收到写命令,就会把这些写命令同步给从库。
比如主库执行:
bash
set name zhangsan
incr age从库会收到对应的命令,然后自己也执行一遍。
所以从库的数据不是"自己算出来的",而是靠主库不断把写命令传过来。
这一块可以理解成:
text
主库执行写命令
主库把写命令发给从库
从库执行同样的写命令
从库数据就跟主库保持一致注意:主从复制默认是异步的,不是主库每次写完都必须等所有从库确认之后才返回。
七、断线重连:增量同步
如果从库和主库之间的网络断了一会儿,后来又连上了,是不是必须重新全量同步?
不一定。
Redis 会尽量走增量同步。
增量同步可以这样理解:
从库告诉主库:"我之前同步到 offset=100 了,你从 101 开始把后面的命令补给我就行。"
大概流程是:
Master 主库 Replica 从库 Master 主库 Replica 从库 alt 可以增量同步 不能增量同步 PSYNC replid offset 判断 replid 是否匹配 判断 offset 后面的命令是否还在复制积压缓冲区 只发送缺失的命令 重新执行全量同步
这里就引出了两个重点:replid 和 offset。
八、offset 是什么?
offset 可以理解成复制进度。
主库每传播一部分复制数据,自己的 master_repl_offset 就会增加。
从库每接收一部分复制数据,自己的 slave_repl_offset 也会增加。
如果两个 offset 一样,说明从库基本追上主库了。
text
master_repl_offset = 10000
slave_repl_offset = 10000如果从库 offset 比主库小,就说明从库落后了。
text
master_repl_offset = 10000
slave_repl_offset = 9800这时候从库大概还差后面 200 个偏移量对应的数据。
注意:offset 不是 key 的数量,也不是命令条数,它更像复制流里的位置编号。
九、replication id 是什么?
replication id,也就是 replid,可以理解成主库这份数据历史的身份证。
为什么需要它?
因为从库断线后再回来,不能只说"我同步到 offset=10000 了"。
还要确认:
text
你之前同步的那个主库,和现在这个主库,是不是同一条复制历史?如果 replid 对得上,说明从库之前确实是从这个主库的数据历史里同步出来的。
如果 replid 对不上,那主库就不能随便按 offset 补数据,因为两边可能根本不是同一份历史。
可以这样记:
text
replid:判断是不是同一份数据历史
offset:判断同步到哪里了这两个要一起看。
十、复制积压缓冲区:为什么有时能增量,有时又要全量?
主库会维护一个复制积压缓冲区,也可以理解成一个环形缓冲区。
它会保存最近传播过的一部分写命令。
从库断线以后,如果很快回来,而且它缺失的那段命令还在缓冲区里,就可以增量同步。
text
从库缺的命令还在 backlog 里 -> 增量同步
从库缺的命令已经被覆盖掉了 -> 全量同步所以,断线重连不一定总是增量同步。
如果从库断线太久,主库写入又很多,复制积压缓冲区里的旧数据被覆盖了,那从库就只能重新全量同步。
这里要记住:
增量同步能不能成功,关键看 replid 是否匹配,以及缺失的 offset 范围还在不在 backlog 里。
十一、主从复制常用配置整理
下面是一个简单的三节点例子。
1. 主节点 6379
主节点正常启动即可,比如配置文件里端口是:
conf
port 6379启动:
bash
redis-server redis-6379.conf2. 从节点 6380
conf
port 6380
replicaof 127.0.0.1 6379启动:
bash
redis-server redis-6380.conf3. 从节点 6381
conf
port 6381
replicaof 127.0.0.1 6379启动:
bash
redis-server redis-6381.conf如果主库有密码,从库还要加:
conf
masterauth 你的主库密码然后进入从库执行:
bash
redis-cli -p 6380
info replication看到类似:
text
role:slave
master_host:127.0.0.1
master_port:6379
master_link_status:up就说明从库连上主库了。
十二、主从复制容易混的几个点
1. 从库可以写吗?
默认情况下,从库一般是只读的。
配置项是:
conf
replica-read-only yes不建议随便改成可写。
因为从库写了以后,这部分数据不会反向同步给主库,还容易造成数据混乱。
2. 主从复制是不是强一致?
不是。
Redis 主从复制默认是异步复制,所以主从之间可能有短暂延迟。
也就是说,主库刚写完,从库可能还没来得及同步。
3. 全量同步是不是每次都发生?
不是。
第一次连接一般会全量同步。
断线重连时,如果条件满足,可以增量同步。
只有增量同步条件不满足时,才会重新全量同步。
4. slaveof 和 replicaof 是什么关系?
以前常用 slaveof,后来 Redis 更推荐 replicaof 这种说法。
实际学习和看旧资料时,两个都可能遇到。
现在写新配置时,优先记:
bash
replicaof 主库IP 主库端口十三、最后总结一下
Redis 主从复制这块,不要死背流程图,先抓住这几句话就够了:
text
1. 主从复制就是从库复制主库数据。
2. 第一次连接通常走全量同步:RDB 快照 + 期间新增命令。
3. 后续正常情况走命令传播。
4. 断线重连时,能不能增量同步,看 replid 和 offset。
5. offset 是复制进度,replid 是复制历史身份。
6. 如果缺失的数据已经不在复制积压缓冲区里,就只能重新全量同步。这一块最容易混的是:全量同步、增量同步、offset、replid 之间的关系。
我的记法是:
text
全量同步:先给你一整份
增量同步:你缺哪段,我补哪段
offset:你同步到哪了
replid:你跟的是不是同一份历史学到这里,主从复制的基本逻辑就能串起来了。后面再学哨兵或者集群时,就不会觉得它们是突然冒出来的新东西。Redis 高可用很多内容,其实都是建立在主从复制这个基础上的。