MiMo 送了我 16 亿 tokens,我很开心,所以我决定好好测一测!
我说过,一旦我认真测,总是很容易发现问题!
这不,问题立马就来了,这一波测试成绩垫底了!
为了测试最新的 MiMo 2.5 Pro 的实力,我专门让 Claude Opus 4.7 出了一个题目!而且还拉上了国内的主流模型,比如 DeepSeek V4 Pro、GLM5.1、Kimi K2.6、MiniMax M2.7。
重点对比DeepSeek V4和MiMO2.5Pro!
我还专门为它升级了我的测试系统!
下面就来看一下具体的情况吧。
掌门日记
因为我严重怀疑我之前的测试题目已经被优化训练了,所以我要出一个全新的题目。、
这个题目不能是常规基准中的题目,也不能是常见的应用,也不能太过抽象,另外必须大家都能看得懂,都可以评判。当然,最重要的一点就是要有一定难度,除了难度之外,还要有审美。
为了这个问题,我专门找了 Opus 4.7,给它提出了如下要求:
最近DeepSeek V4 系列和小米 MiMo 2.5 Pro 系列更新了。我想测试一下他们在不同编程场景下的能力,你能帮我出一些题目吗?一定要能区分出它们的实力。你可以先查一下这两个模型的特点,然后再根据。再针对性的出题目。
它给我出了六个题目:
题 1:竞赛级算法题
题 2:形式化证明 / 边界推理
题 3:从模糊需求到可运行项目
题 4:千次工具调用级长程任务
题 5:1M 上下文里的"针在干草堆中且需要推理"
题 6:自我纠错 + 工程权衡
这些题目都挺好的,但是这种题目几个人看得懂,又有几个人能评判结果好坏呢?所以这些题目全部被我废弃了。
这些问题我觉得还是太专业了,所以提出了修改需求:
这种题目还是太过技术向了,而且比较专注于某个细节,能不能设计一个应用开发之类的?而且这个项目要包含各种知识点,以及这个项目本身并不是很大众化。但是大家都能理解的。觉得会很有意思的。
然后,我就得到了,下面这些奇奇怪怪的题目:
markdown
**赛博中医:AI 把脉模拟器** ------ 用户输入症状,系统模拟"望闻问切",给出辨证、推荐方剂、生成一张可打印的处方笺(带繁体毛笔字效果)
**方言保卫战:濒危方言学习平台** ------ 选一种方言(比如温州话/客家话),做发音对照、童谣库、方言-普通话双向翻译游戏
**复古 BBS 模拟器** ------ 完整复刻 90 年代拨号 BBS 的体验:ANSI 艺术、留言板、ASCII 游戏、虚拟拨号音
**菜市场经济学** ------ 模拟一个菜市场摊主,每天进货、定价、应对顾客砍价、季节波动、城管巡查,背后是供需模型
**风水罗盘 App** ------ 输入房间布局照片或手绘,AI 分析"气场",给出家具调整建议,配中英文玄学解释
**武侠门派经营模拟** ------ 你是新晋掌门,要招收弟子、安排修炼、参加论剑大会、处理江湖恩怨,每个弟子有 RPG 属性
**小区业委会模拟器** ------ 处理邻里纠纷、组织选举、和物业谈判、应对群消息,全是文字 + 微信群 UI
**古籍修复工坊** ------ 给一段残缺古文(缺字、虫蛀、墨迹模糊),AI 辅助补全 + 出修复报告,带"做旧"视觉效果最终,选择了武侠门派经营模拟,也叫掌门日记。
并且让 Opus 4.7 帮我制作了一个完整的测试方案:

方案里面包含了测试背景、为什么选这个题目、完整的提示词、考察维度和预期分化、评分卡、测试流程等等,非常全面!
批量测试
根据 Opus 4.7 的建议,测试过程不使用任何第三方的工具,不使用 Claude Code 和 OpenCode 等智能体工具。同时要开启思考能力,然后一轮定胜负,主要就是考验模型本身的能力。
所以,我决定用手搓的 API 批量测试功能来进行测试!
第二次测试结果如下:
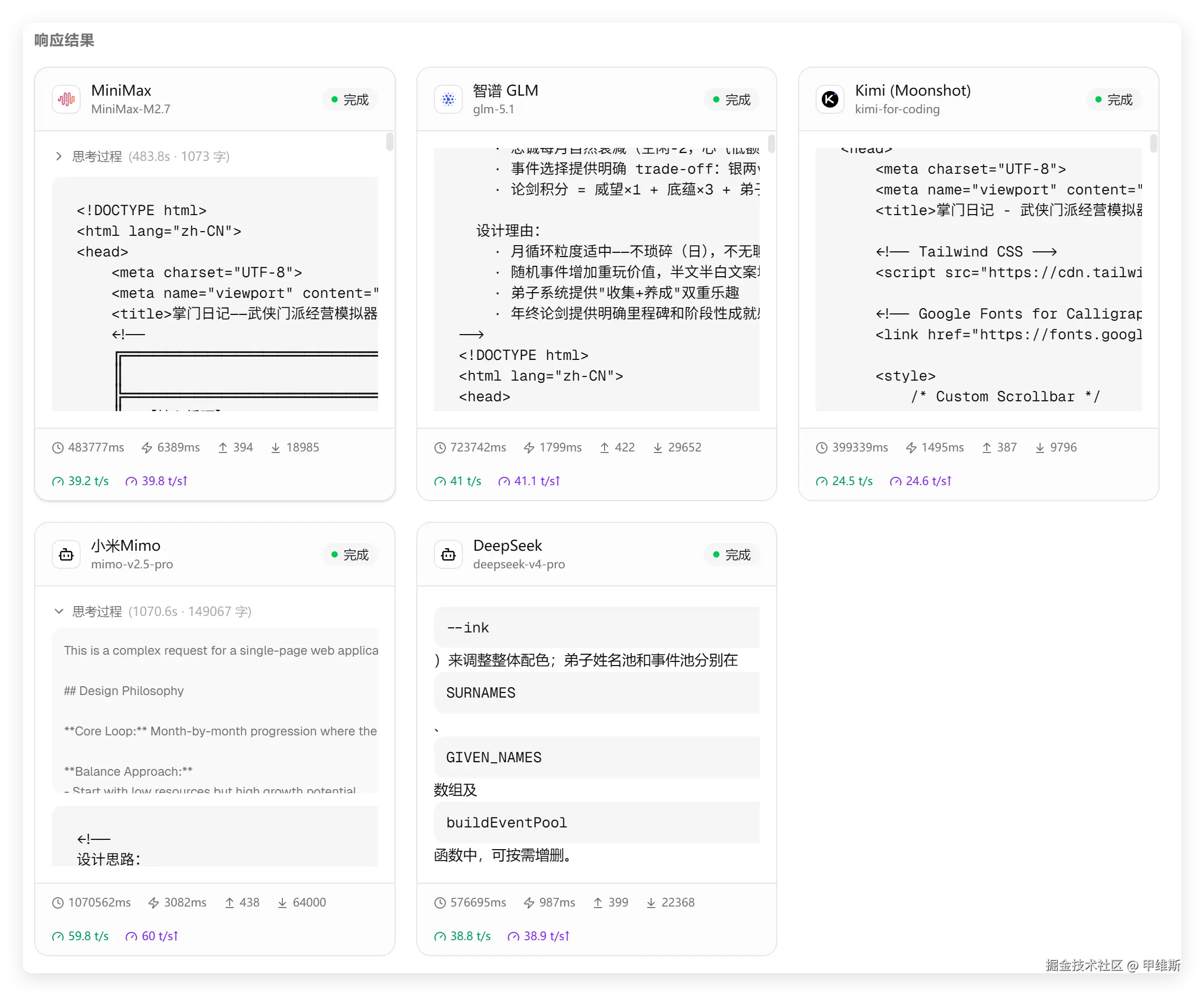
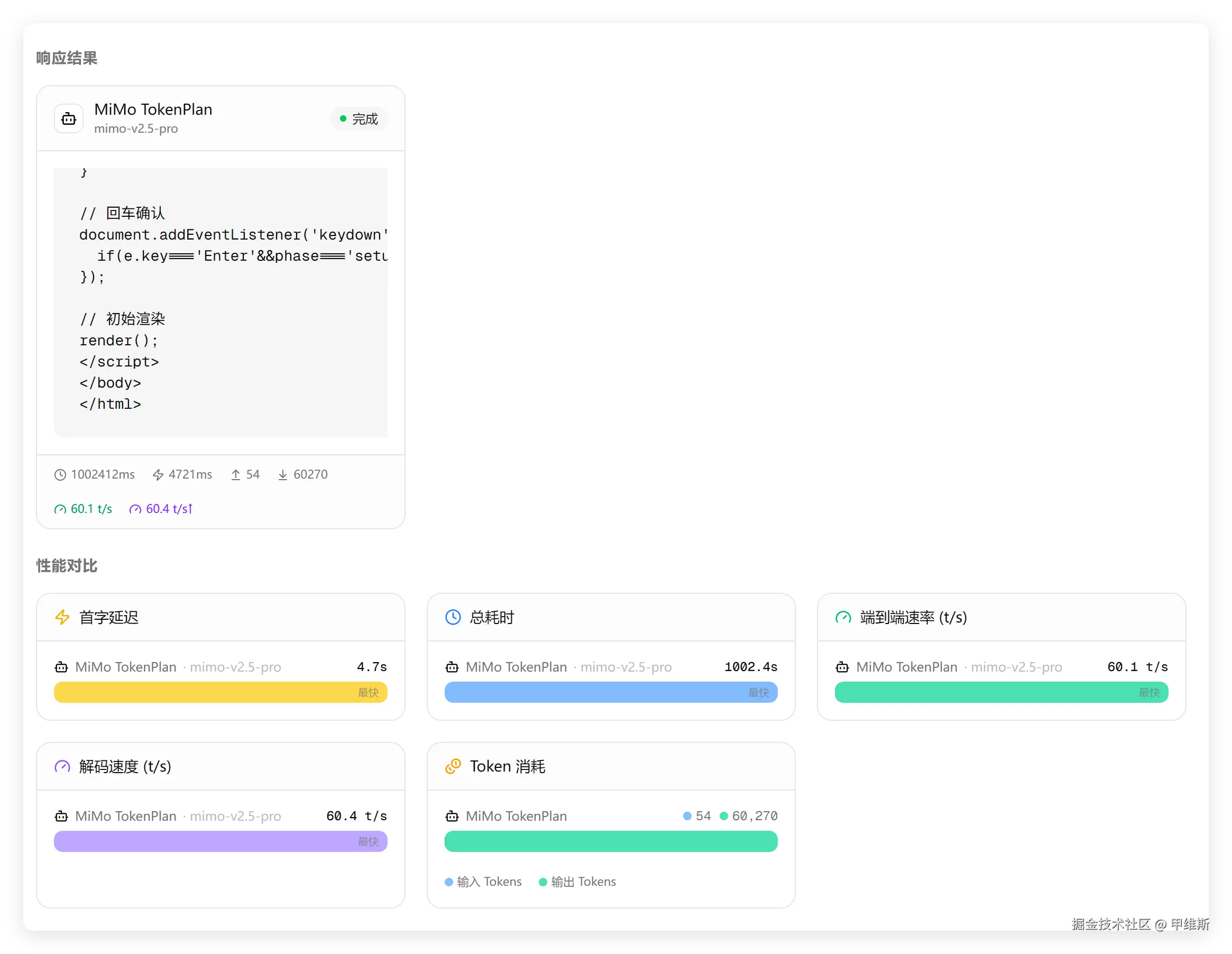
不同模型的性能对比如下:
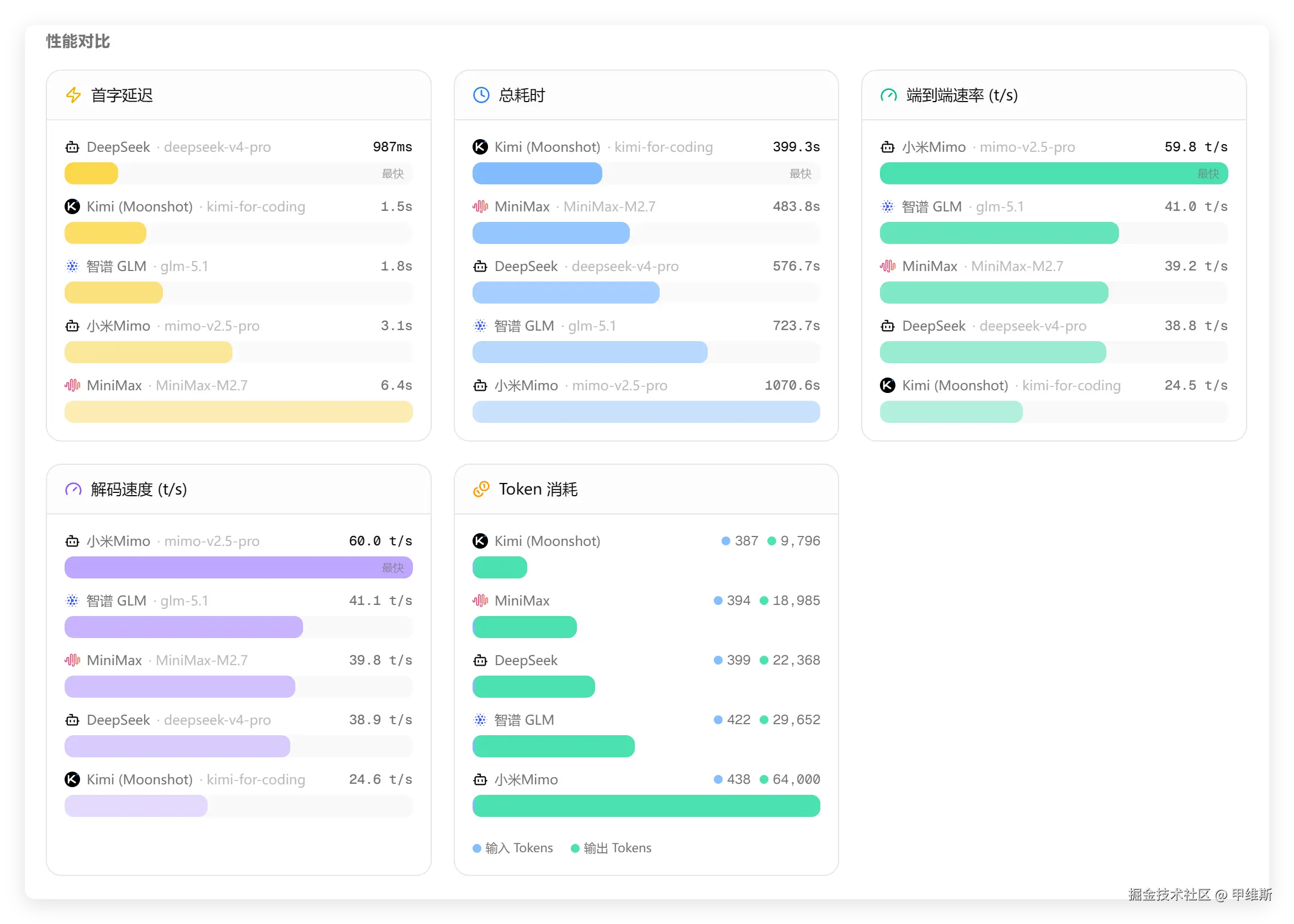
这个截图主要是宏观地看一下,不同模型的速度和 tokens 消耗情况。
从这个图中可以看到,DeepSeek 最快响应,Kimi 最快完成,小米的端到端和解码速度最快,但是总耗时和 tokens 消耗最高。
这个还有一个非常关键的问题:MiMo 这一题并没有答完!
上面已经是我的第二次测试了,第一次测试用了系统内置的 32000 的最大 tokens 限制。限制的 tokens 到了,它题目才回答了一点点。所以第二次测试,我专门开发了自定义最大 tokens 功能,给它设置了 64000 的上限。
没想到依旧没有完成!!!
这么一比问题就出来了。
你们看看其他模型,完成这个任务消耗了多少 tokens。
GLM 算多的,也只消耗了 29652;DeepSeek 消耗了 22368;Kimi 只消耗了 9796。
也就是说同样的问题,MiMo 用了人家 6 倍的 tokens,但是没有把问题解决,严格来说是没有完成。
为了让它能完成这个题目,我把最大 tokens 参数拉到了 128000,给它单独测试了一次。
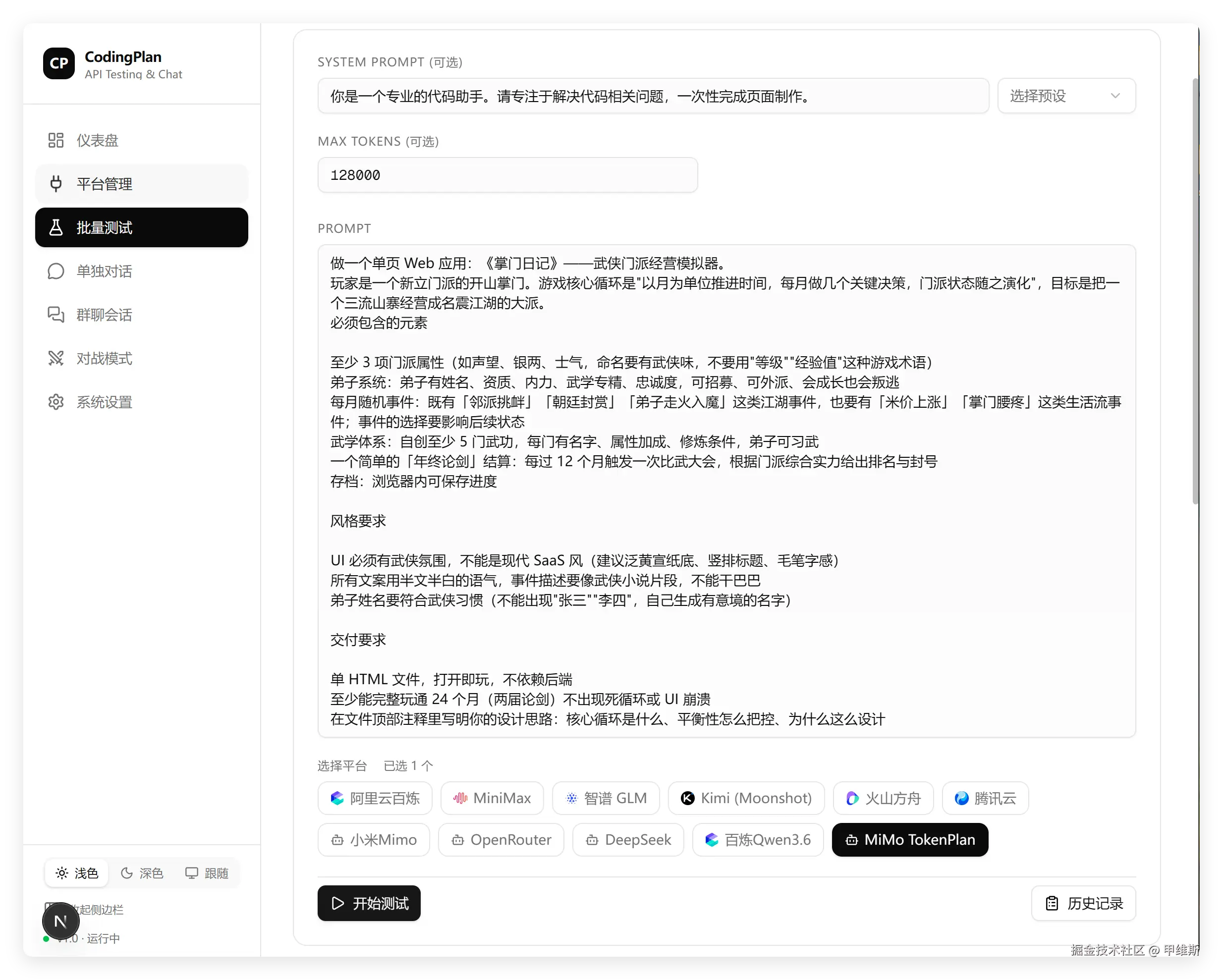
这一次终于完成了:
这次表现还可以,其实只用了 6 万多 tokens,并没有达到上限!
因为刚开始测试的时候我大意了,没有切换成送我的tokenPlan,所以仅这一个问题就消耗了好几块钱!
结果验收
终于,大家的结果都出来了。我就可以开始测试了。
我们一个一个来看!
首先看今天的主角 MiMo 的表现:

打开之后,发现页面上除了背景之外,空无一物!
也就是说,即便用了那么多 tokens,最终做出来的东西也没法用。
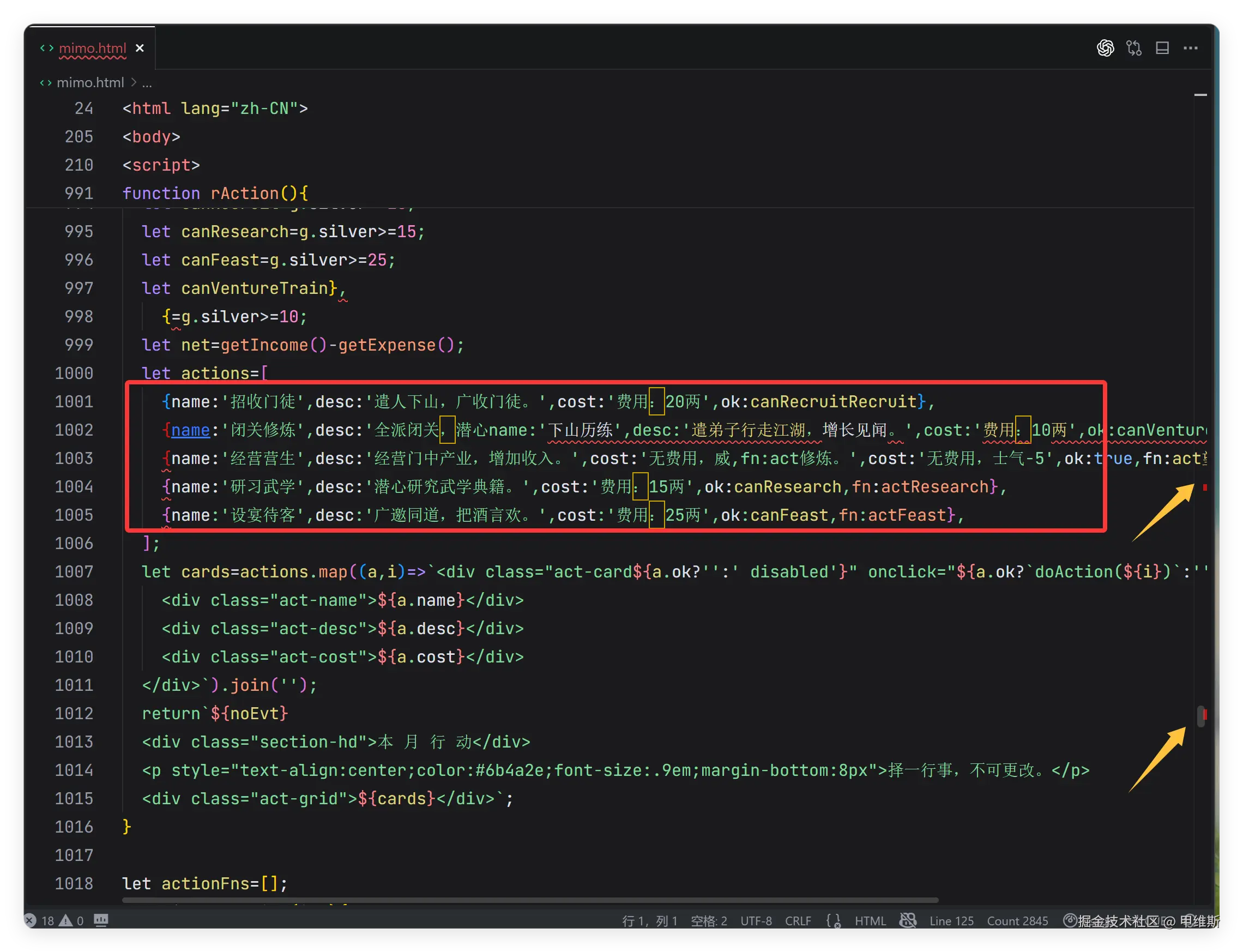
在浏览器调试界面可以看到它的代码有问题,拖到任意一个 IDE 中也可以看到很明显的错误,这种属于低级错误!
根据 GPT 5.5的总结:这段不是"小瑕疵",而是文本被意外拼接导致的结构性损坏,需要先恢复为合法的 6 个独立对象后才能运行。
然后,我们来看一看DeepSeek的表现:
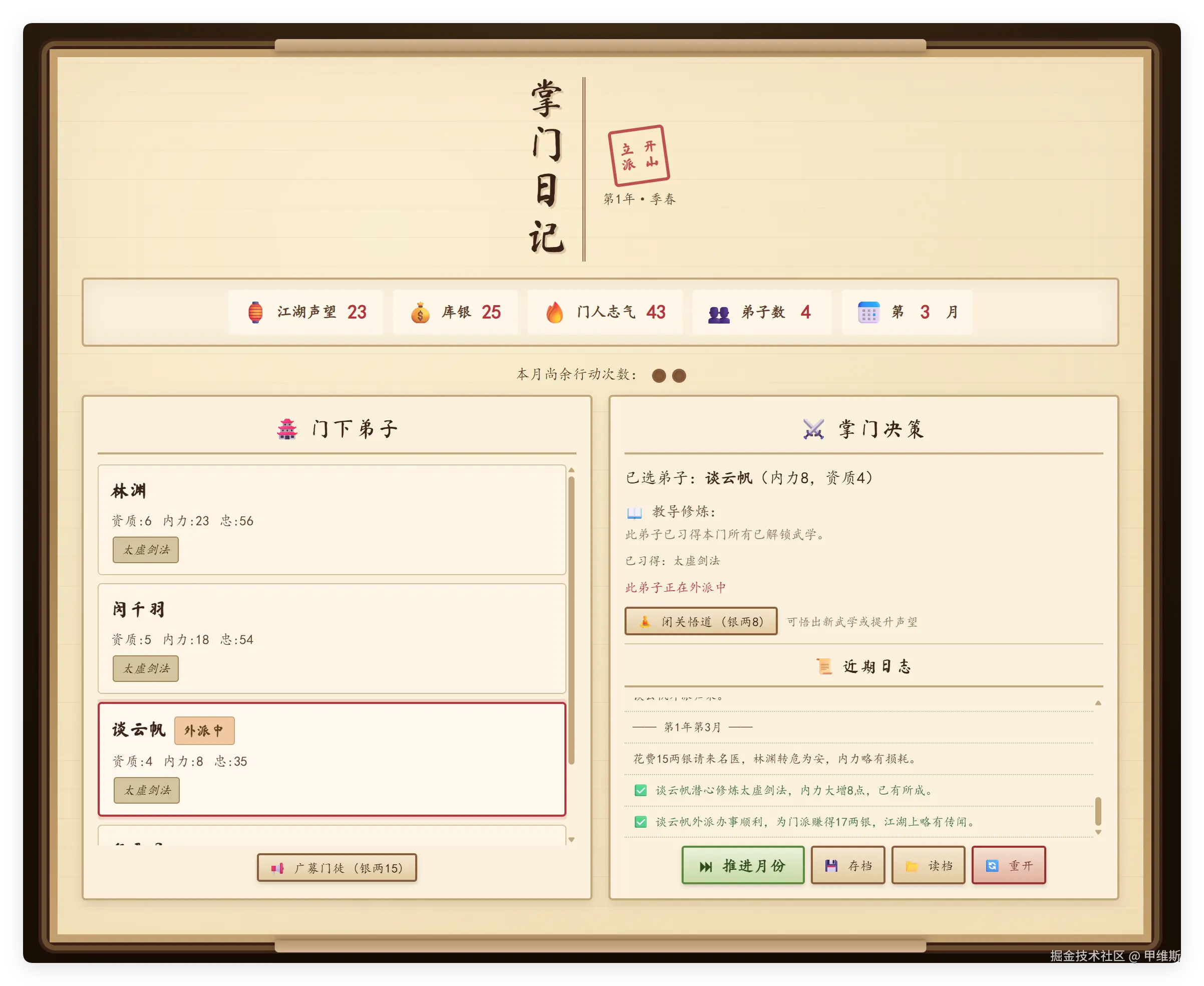
这个界面是完整的,基本上该有的东西都有,它的 UI 设计就是在一个台子上夹了一张一张的纸感觉,然后配色、字体、命名,应该是符合基本要求的。设计不算出众,但是没啥问题。
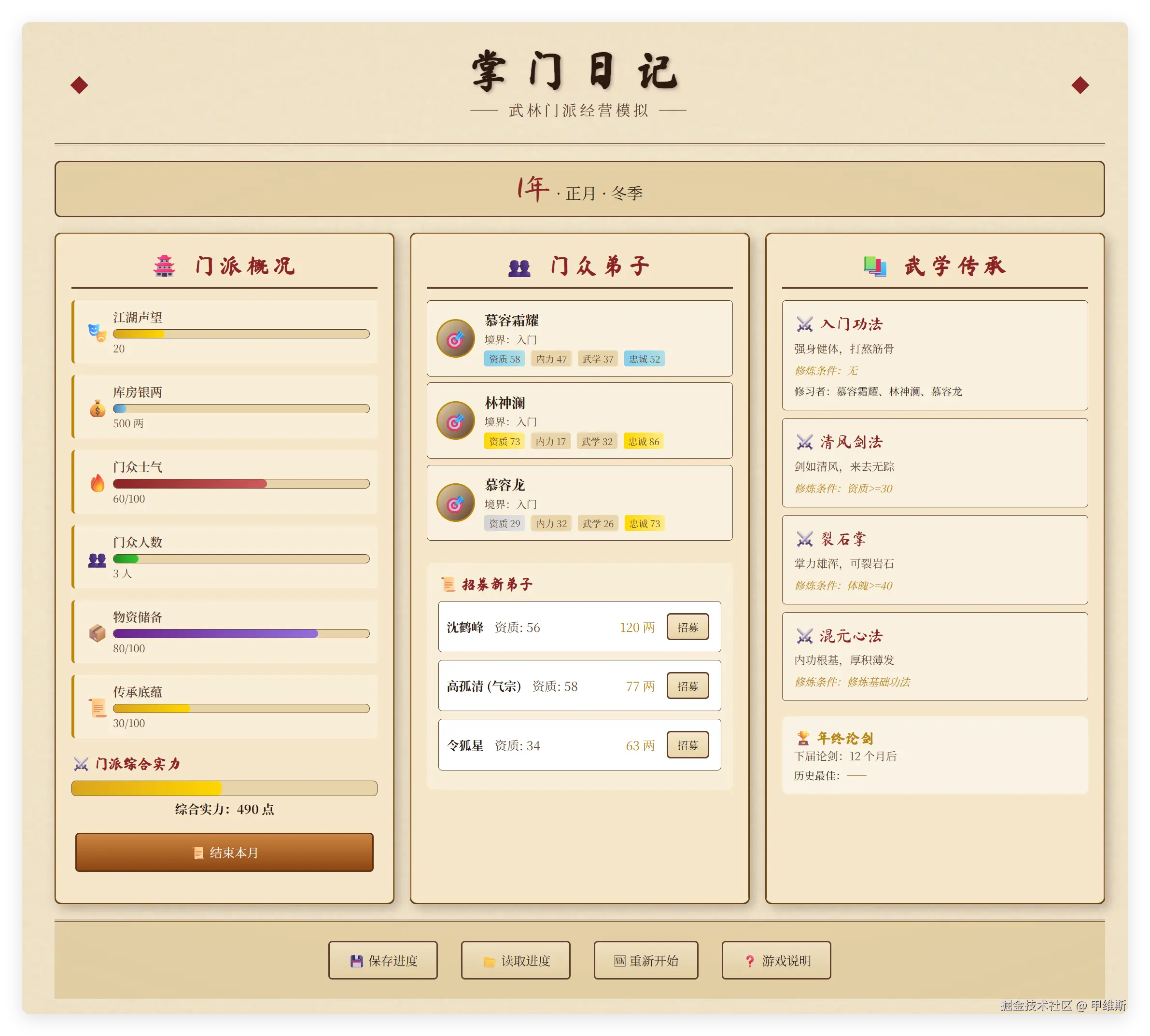
我尝试着玩了一下,还挺好玩的!
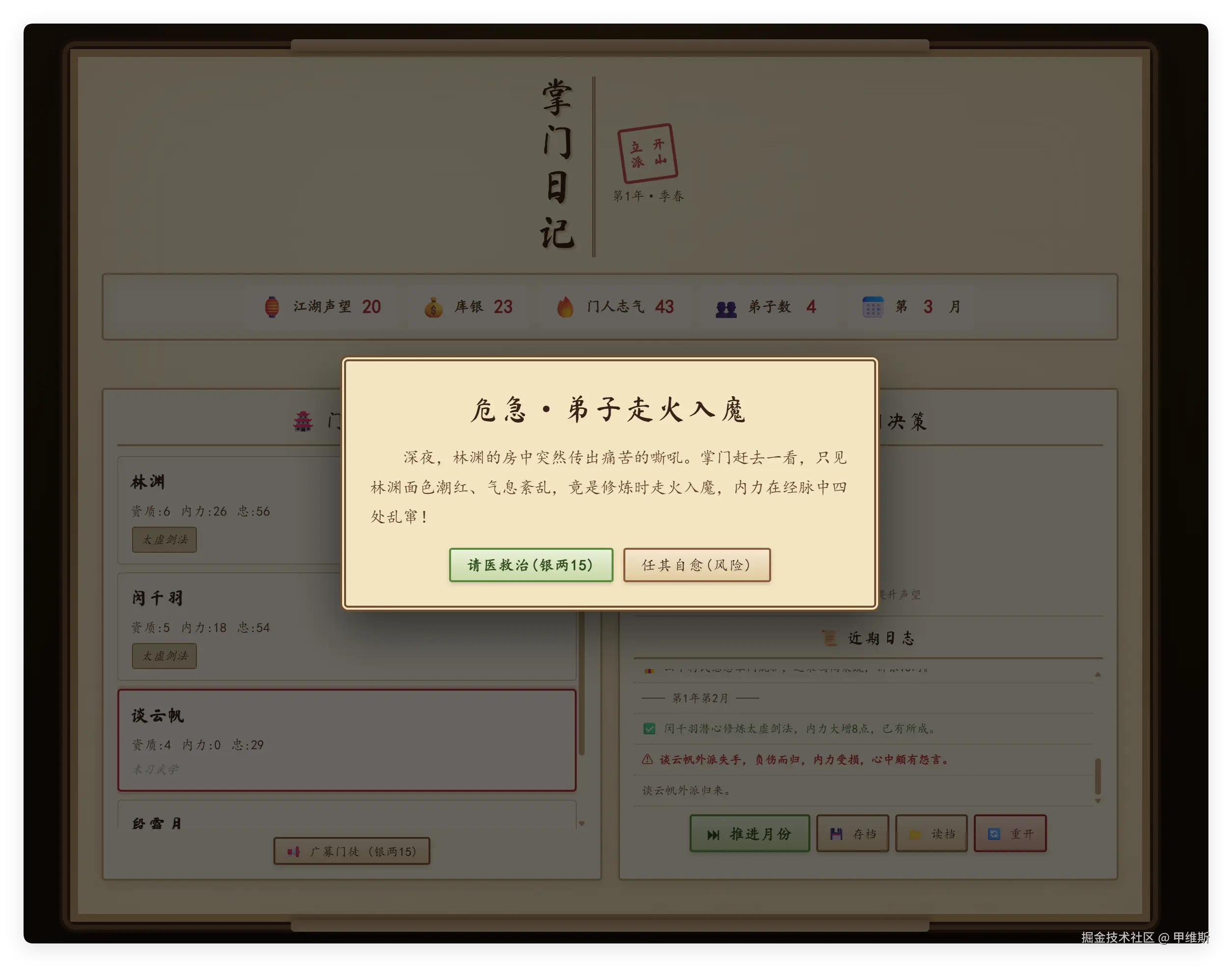
第二个月,新入门的弟子就走火入魔了,花了我银两15。
哈哈哈~~
GLM的结果:
GLM是先设计了一个开山立派的界面,挺好的!

我创建了一个叫"青云"的门派,随便点了几下,基础功能也是正常的。
Kimi的结果:
Kimi的UI设计还是比较出众的,它没有用特别泛黄的设计,而是有一点淡淡的底色的设计。可能不那么复古,但是整体感觉不错的。字体配色意境基本到位的,点进去之后也是能玩的。
MiniMax的结果:
MiniMax 这一波出息了,居然也成功打开了,UI 上看也没有明显的问题。
由于这一次 MiMo 过早地退出比赛,而这次比较的重点是最新的 MiMo V2.5 Pro 和 DeepSeek V4,所以其它选手我就先不展开了。
大家有兴趣看评分卡的话,我可以专门出一篇。
其实,去分析细节的话,不同模型之间还是会有很多差异。
我会把所有结果放到:topai.tonyhub.xyz 上面,今天这个测试项目,还是挺好玩的。
网页测试
通过 API 调用的方式,MiMo 失败了。
按我们的规则来说,就是一次定胜负,到这里这次测试就应该结束了。但是,毕竟人家都送十几亿 tokens 了。我怎么也得多测几次吧。
所以,接下来我要加测,并且把测试平台换成它们官方的网页版!
网址:
arduino
https://aistudio.xiaomimimo.com/这个域名叫 AIStudio,这个名字和谷歌的 AIStudio 一模一样。
我在上面测了三次。
很可惜,没有一次能正常完成,都是干到一半就歇菜了。
我估计就是达到它们官网设置的 max tokens 了,我们之前测试的时候也可以看出来,它这个思考过程特别消耗 tokens。
经过好几轮的交流终于做好了第一个网页,但是运行也有问题。
我也在DeepSeek的官方网页上测试了三次,每一次都是成功的,基本功能都是正常的。
其实除了 DeepSeek 之外,我也在 Kimi 和 GLM 的官网上跑了三次,都是能正常打开和使用的。
结果已经很清晰了,无论是消耗的 tokens,还是最终的效果。
DeepSeek完胜,MiMo完败了!
最后声明一下,我这次测试只代表部分场景,不能代表模型的完整能力。
从我们之前的测试来看,MiMo 的表现还是不错的。
接下来,我会继续从不同的角度测试国内这几个模型,可以让大家直观的了解不同模型在不同问题上的表现。