欠拟合与过拟合:
出现原因、解决方法、L1正则化、L2正则化
(欠拟合是模型过于简单,模型在训练集和测试集都不好;过拟合是模型过于复杂,模型在测试集好、训练集不好;正好拟合是两个都好;
欠拟合的解决方式只有一个,欠拟合是由于模型简单导致,所以增加模型的复杂度即可,如何增加模型复杂度?:增加特征!即原本基于一项特征做操作,现在增加特征列。)
1. 欠拟合与过拟合
1.1 欠拟合与过拟合概念
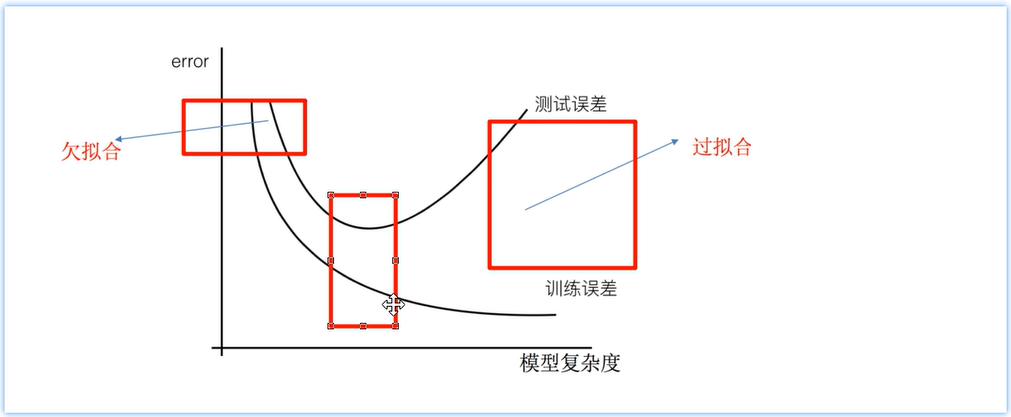
欠拟合 :模型在训练集上表现不好,在测试集上也表现不好。模型过于简单 ;
过拟合 :模型在训练集上表现好,在测试集上表现不好。模型过于复杂 。
欠拟合在训练集和测试集上的误差都较大;过拟合在训练集上误差较小、而测试集上误差较大;
(L1和L2正则化解决过拟合问题;它解决不了欠拟合、只能解决过拟合。)
1.2 L1和L2正则化解决过拟合问题
代码演示:
python
"""
案例:演示 欠拟合、正好拟合、过拟合、L1正则化、L2正则化的 效果图
回顾:
欠拟合:模型在训练集和测试集表现效果都不好。
正好拟合:模型在训练集和测试集表现效果都好。
过拟合:模型在训练集表现好、测试集表现不好。
"""
# 导包
import numpy as np
import matplotlib.pyplot as plt
from fontTools.diff import color
from sklearn.model_selection import train_test_split # 数据集划分
from sklearn.linear_model import LinearRegression # 正规方程的回归模型
from sklearn.metrics import mean_squared_error,root_mean_squared_error,mean_absolute_error # 均方误差评估,RMSE,MAE
from sklearn.linear_model import Ridge,RidgeCV
# 1.定义函数,模拟欠拟合
def demo01_under_fitting():
# 1.准备数据
# 1.1 指定随机种子,则每次生成(噪声)的数据都是固定的
np.random.seed(23) # 23期
# 1.2 随机生成x轴100个数据,模拟:特征
x=np.random.uniform(-3,3,100) # 参1:最小值,参2:最大值,参3:数据个数(生成100个-3到3的数值)
# 1.3 基于x轴值,通过线性公式y=kx+b=0.5x+1,生成y轴 100个数据,模拟:标签
# 线性公式y = kx + b = 0.5 * x + 1 + 噪声 ==》 = 0.5 * x的平方 + x + 2 + 噪声
y=0.5*x**2+x+2+np.random.normal(0,1,100) # 参1:均值,参2:标准差,参3:数据个数(生成100个均值为0、标准差为1的数值)
# 1.4 查看生成的x轴(特征)和y轴(标签)数据
# print(f'特征(x):{x}')
# print(f'标签(y):{y}') # 只打印5条数据
print(f'特征(x):{x[:5]}') # [1, 2, 3, 4, 5]
print(f'标签(y):{y[:5]}')
# 2.数据预处理,把x轴(特征)转成 多行1列的形式
X=x.reshape(-1,1)
print(f'处理后的特征(X):{X[:5]}') # [[1], [2], [3], [4], [5]]
# 3.特征工程,这里不做了,直接用100条数据,先训练后预测
# 4.模型训练
# 4.1 创建模型对象
estimator=LinearRegression() # 正规方程 线性回归模型
# 4.2 模型训练
estimator.fit(X,y) # 参1:处理后的特征数据,参2:标签数据
# 5.模型预测
y_predict=estimator.predict(X) # 参1:处理后的特征数据
# 6.模型评估
print(f'均方误差:{mean_squared_error(y,y_predict)}') # 参1:真实值,参2:预测值
# 7.绘图
plt.scatter(x,y) # 以散点图的形式绘制 真实值
plt.plot(x,y_predict,color='red') # 以线图绘制 预测值
#(只有在模型训练、模型预测时会用大X,其他地方如绘图时用的都是之前原始的不带嵌套的小x)
plt.show()
# 2.定义函数,模拟正好拟合
# 3.定义函数,模拟过拟合
# 4.
# 5.测试
demo01_under_fitting()