
大家好,在这篇文章中我将继续介绍我的毕业设计项目 S.A.A.U.S.O ------ 一个轻量级 Python 虚拟机。
在前面的分享中,我已经从整体上介绍过这个项目:它希望用相对轻量、结构清晰、便于学习和定制的方式,构建一个能够执行 Python 核心功能子集的虚拟机后端。
从这一篇开始,我会把毕业论文中比较核心的几章拆成几篇技术文章,系统介绍这个虚拟机是如何设计和实现的。
本文对应论文第 2 章,主要讨论实现一个 Python 虚拟机之前必须理解的理论基础:Python 虚拟机(PVM) 到底如何执行 Python 程序?函数、栈帧、闭包、对象系统、异常和模块机制在虚拟机内部又是如何运作的?
1. Python 代码并不是直接被 CPU 执行的
很多人刚开始学习 Python 时,会把 Python 理解成"解释型语言":写一行代码,解释器就执行一行。
这个说法并不完全错,但如果我们站在虚拟机实现的角度看,它还不够准确。
以 CPython 为例,Python 程序的执行大致可以分成两个阶段:
第一步,前端编译器会把源代码编译成 代码对象(Code Object)。代码对象中保存了字节码指令序列、常量表、符号名表等静态信息。
第二步,后端虚拟机,也就是我们所讨论的 PVM,会逐条解释执行这些字节码指令。
也就是说,PVM 并不是直接理解 if、while、def 这些高级语法,而是执行编译器生成的字节码。
举个简单例子:
python
x = 1
y = 2
z = 3
x + y * z这段代码在虚拟机眼中,大致会变成类似这样的指令序列:
LOAD_CONST 1
STORE_NAME x
LOAD_CONST 2
STORE_NAME y
LOAD_CONST 3
STORE_NAME z
LOAD_NAME x
LOAD_NAME y
LOAD_NAME z
BINARY_OP *
BINARY_OP +这里的 LOAD_CONST 负责加载常量,STORE_NAME 负责把对象绑定到名称上,LOAD_NAME 负责按名称取值,BINARY_OP 负责执行二元运算。
所以,从虚拟机视角来看,Python 程序的执行本质上是:
编译器把高级语法翻译成字节码,虚拟机维护运行时状态,并逐条解释执行这些字节码。
这也说明了 S.A.A.U.S.O 这个项目的基本出发点:复用 CPython 3.12 中的编译器前端与字节码执行模型,从而将开发内容聚焦于虚拟机后端。
2. PVM 本质上是一台"栈机"
从执行模型来看,PVM 可以被理解为一台虚拟的栈机。
所谓栈机,就是它的大部分计算都围绕一个 操作数栈 展开。字节码指令会不断从栈中取出对象、执行操作,再把结果压回栈里。
例如表达式:
python
x + y * z对应到虚拟机执行过程,大致是:
- 读取 x,压入操作数栈;
- 读取 y,压入操作数栈;
- 读取 z,压入操作数栈;
- 执行乘法,从栈顶弹出 y 和 z,计算 y * z,再把结果压回栈;
- 执行加法,从栈中弹出 x 和 y * z 的结果,计算最终结果。
这说明 PVM 的核心工作并不是"翻译语法",而是围绕操作数栈执行一组低层指令。
不过,仅仅有操作数栈还不够。一个真正可运行的 Python 虚拟机,还需要维护:
- 当前执行到哪条字节码指令;
- 当前函数调用的局部变量;
- 当前模块的全局变量;
- 函数调用栈;
- 异常状态;
- 模块缓存;
- 内建函数和内建类型;
- 对象系统与内存管理。
也就是说,PVM 并不是一个简单的 while + switch 字节码解释器,而是一个完整的运行时系统。
3. Python 中的变量,本质是"名称到对象的绑定"
在 C/C++ 里,我们经常会把变量理解为一块固定内存空间。
但在 Python 中,变量更接近于一种 名称到对象的绑定关系。
例如:
python
a = 1从 PVM 的角度看,这不是把整数 1 填进某个名为 a 的固定内存槽里,而是让名称 a 绑定到一个整数对象上。
因此,虚拟机必须维护各种命名空间,用来保存这些绑定关系。
常见的命名空间包括:
- 局部命名空间:函数调用时产生,保存函数内部的局部变量;
- 全局命名空间:通常对应模块级变量;
- 内建命名空间:保存 print、len、isinstance 等内建函数和对象。
例如:
python
def add(a, b):
result = a + b
return result
c = add(1, 2)
print(c)在这个例子中:
- add 和 c 属于模块级全局命名空间;
- a、b、result 属于函数调用产生的局部命名空间;
- print 来自内建命名空间。
所以,虚拟机执行 LOAD_NAME 或 LOAD_GLOBAL 这类指令时,本质上就是在不同命名空间中按规则查找对象。
4. if 和 while 在虚拟机中都是跳转
从语言层面看,if、while、break、continue 是控制流语句。
但在字节码层面,它们最终都会变成条件跳转和无条件跳转。
例如:
python
while condition:
i += 1
print(i)它对应的核心字节码逻辑可以抽象为:
css
LOAD_NAME condition
POP_JUMP_IF_FALSE 跳出循环
LOAD_NAME i
LOAD_CONST 1
BINARY_OP +=
STORE_NAME i
JUMP_BACKWARD 回到循环开始这里最关键的两类指令是:
- POP_JUMP_IF_FALSE:如果栈顶对象判定为假,就跳转;
- JUMP_BACKWARD:无条件向后跳回循环开始位置。
这说明 Python 中的循环并不是虚拟机里的特殊结构,而是由跳转指令组合出来的执行路径。
不过这里还有一个很重要的细节:Python 的条件判断依赖 真值语义(Truthiness)。
也就是说,虚拟机不能只判断对象是不是布尔值 True 或 False,还要支持类似这样的规则:
python
if []:
...
if 0:
...
if "hello":
...空列表、数字 0、空字符串都要按 Python 语义转换为真假值。因此,控制流指令还必须和对象系统中的真值判断能力协同工作。
5. 函数不是静态代码片段,而是运行时对象
在 Python 中,函数也是对象。
这一点非常重要。
例如:
python
def add(a, b):
return a + b从 CPython 的执行模型来看,这个函数并不是在编译阶段就直接变成一个固定入口地址。更准确地说,编译器会先为函数体生成一个代码对象,然后在运行时通过 MAKE_FUNCTION 指令创建函数对象,并把它绑定到当前命名空间中的 add 这个名称上。
也就是说,上面的代码大致对应:
csharp
LOAD_CONST <code object add>
MAKE_FUNCTION
STORE_NAME add为什么函数一定要在运行时创建?
一个很典型的例子是默认参数:
python
default_k = 3
def linear_f(x, b, k=default_k):
return k * x + b这里的默认参数 default_k 是运行时求值的。虚拟机需要先读取 default_k 当前绑定的对象,再构造默认参数元组,最后把它和代码对象一起封装进函数对象。
因此,Python 函数不能简单理解成一段静态代码,而应该理解成一个运行时对象。它不仅包含代码对象,还可能携带默认参数、闭包信息、全局命名空间等运行时数据。
6. 函数调用的核心:栈帧
当 Python 调用函数时,PVM 会创建一个新的 栈帧(Stack Frame)。
栈帧可以理解成一次函数调用的运行现场。它通常需要保存:
- 当前执行的代码对象;
- 程序计数器;
- 操作数栈;
- 局部变量;
- 全局命名空间引用;
- 闭包变量;
- 异常处理相关信息。
例如:
python
def callee(x, y):
return x + y
def caller():
a = 1
b = 2
c = callee(a, b) 当 caller 调用 callee 时,虚拟机会为 callee 创建新的栈帧,并把它压入调用栈。callee 返回后,它的栈帧再从调用栈中弹出,控制权回到 caller 的栈帧。
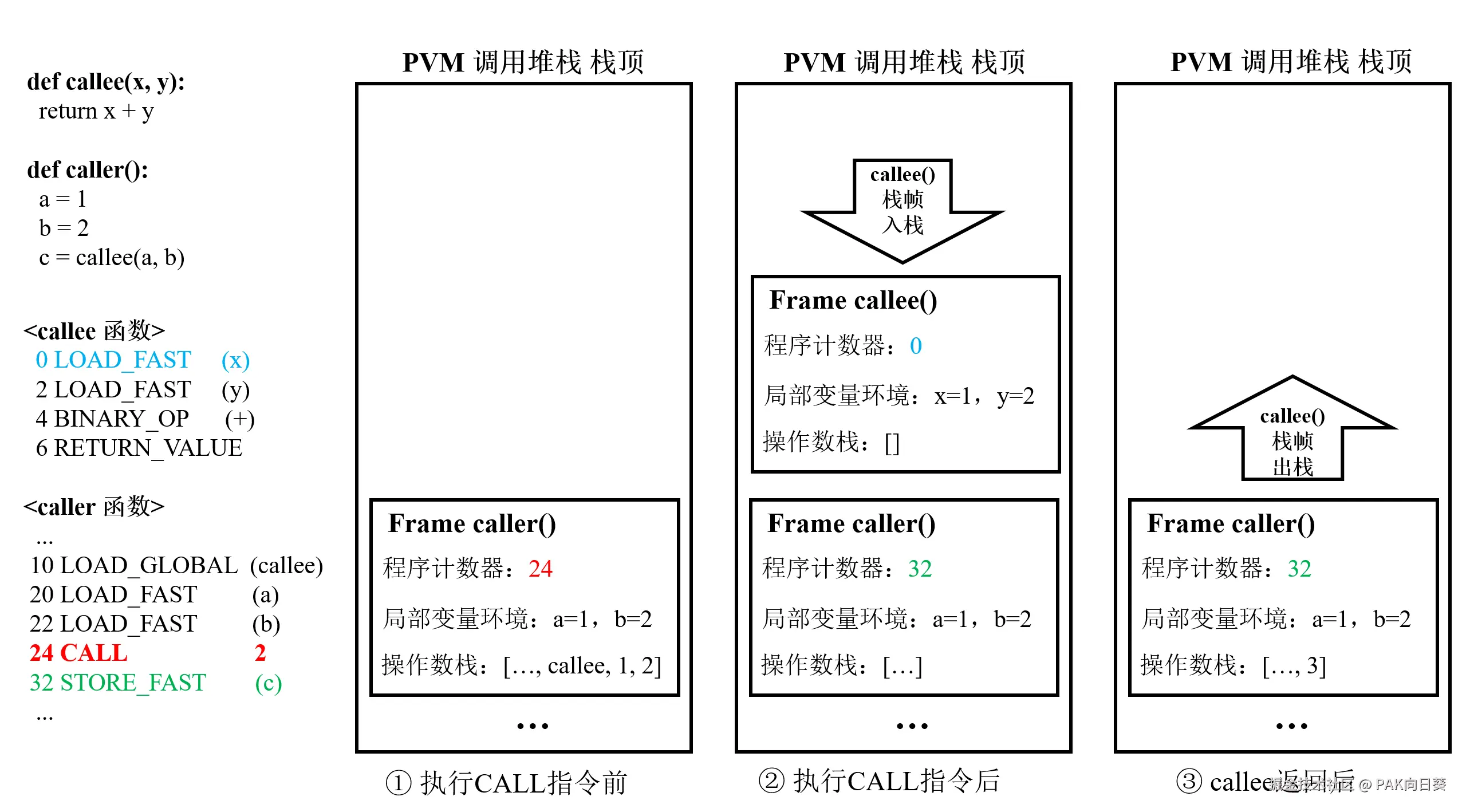
7. 保存变量的核心:locals、globals 与 localsplus
从实现角度看,若让所有局部变量都通过字典按名字查找,执行代价会过高。
因此,PVM 通常会在栈帧中引入一个槽位区(即定长数组)。编译阶段会由编译器前端负责统计函数体内局部变量的数量并分别为它们分配槽位下标;运行阶段完成槽位区的实际创建,并通过 LOAD/STORE 指令参数中的槽位下标直接实现读写局部变量。
在 CPython 3.12 的执行模型中,对字典和槽位区这两种方案进行了结合。
首先,由于 Python 语言中"文件即模块"的机制设计,对于单个 Python 文件的顶层代码,也就是可视作"根函数"的那部分代码,因为其中的顶层变量可能会通过变量符号名被暴露给其他 Python 文件,所以栈帧通常会提供一个被称为 locals 的字典用于保存这些顶层变量。而要通过变量符号名读写这些顶层变量,就需要通过 LOAD_NAME 和 STORE_NAME 等字节码指令实现。
这里还需要进一步说明 LOAD_NAME 与 STORE_NAME 指令的语义差异。对于 STORE_NAME 而言,其语义是在当前按名字解析的局部命名空间中建立或更新绑定关系,因此它会直接把值写入当前栈帧的 locals 字典。然而,LOAD_NAME 的语义并不仅仅是查询当前栈帧的 locals 字典;当目标名称在当前栈帧的 locals 字典中不存在时,PVM 还需要继续在全局以及内建命名空间中进行查找。这样设计的原因在于,在 CPython 3.12的执行模型中,可能会复用这条指令用于查找模块级全局变量或内建函数。
相对地,对于一般 Python 函数中的局部变量,则采用了槽位区方案。这个槽位区在 CPython 的源代码中被称为 localsplus 数组。另外,Python 函数中的形参以及闭包场景下出现的自由变量,同样会被安排在槽位区中进行维护。在此基础之上,面向普通局部变量的 LOAD_FAST、STORE_FAST 指令和面向闭包的 LOAD_DEREF 和 STORE_DEREF 的指令就是直接按槽位下标读写对应变量值的。
与此同时,栈帧中还会预留一个 globals 字段用于指向与当前函数绑定的全局命名空间字典。函数内部可以使用 LOAD_GLOBAL 指令读取其所在模块中的全局名称:PVM 会先查该函数绑定的全局命名空间,再查内建命名空间作为兜底。相应地,若函数体内部代码需要显式对全局变量赋值,则通过 STORE_GLOBAL 指令落到该函数绑定的全局命名空间之中。
既然顶层代码中的变量会直接被放进根函数栈帧的 locals 字典中维护,为什么还需要引入 globals 字段呢?下面的这个例子可以解释这个疑问。
python
# mod_a.py
x = 10
def func():
print(x)
# mod_b.py
from mod_a import func
x = 999
func()在这个例子中,我们假设有两个模块 mod_a.py 和 mod_b.py。当 PVM 执行 mod_a.py 模块的顶层代码时,会为该模块准备一个模块级全局命名空间。在 CPython 3.12 的执行模型中,当前根函数对应栈帧中的 locals 与 globals 字段均直接指向这一个字典。当 MAKE_FUNCTION 指令创建 func 时,会把栈帧中 globals 字段所指向的该字典一并绑定进新生成的函数对象中。
于是,当我们在 mod_b.py 中调用 func 时,PVM 首先会将当前栈帧中的 globals 字段指向与该函数绑定的全局命名空间。接下来,因为函数读取变量 x 的操作是通过 LOAD_GLOBAL 字节码指令完成的,所以 PVM 会在当前栈帧中 globals 所指向的全局命名空间中进行查找,从而得出的输出结果为 10 而非 999。
到此为止,已经对 locals、globals 和 localsplus 三个与变量环境相关重要字段的语义和职责进行了说明与辨析。下面通过一个综合例子,总结一下它们的职责以及具体指向。
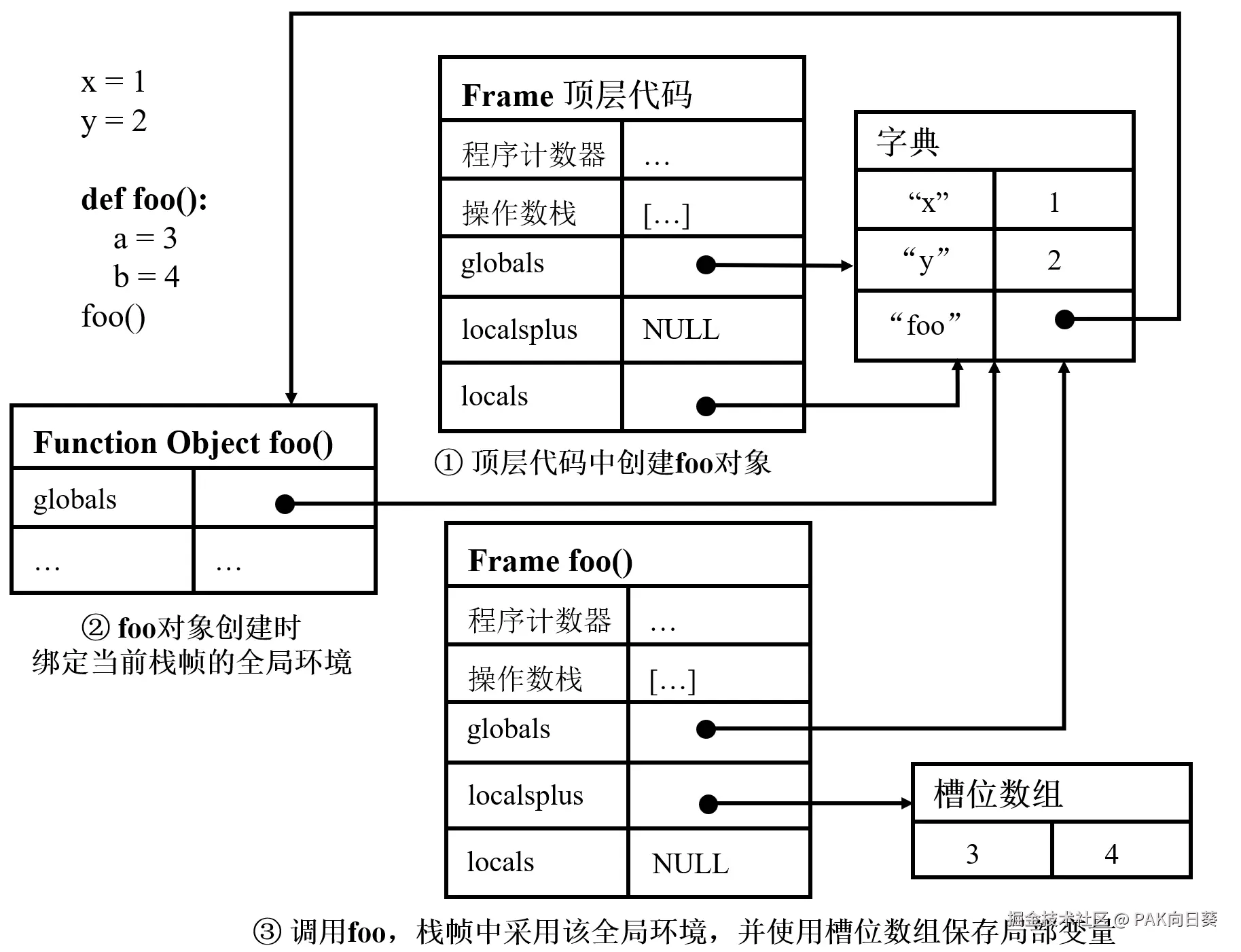
8. 闭包的关键:Cell Object
Python 语言支持定义嵌套函数,并且被嵌套的内部函数可以捕获(Capture)外部函数中的变量,从而形成闭包。闭包是 Python 词法作用域的重要体现。
下面给出一个具体的 Python 闭包例子。在这段代码中,内部函数 inner 对外部函数 outer 中的局部变量 x 形成引用。因此 inner 称为闭包函数(Closure Function);变量 x 则称为被 inner 捕获的自由变量(Free Variable)。
python
def outer():
x = 10
def inner():
print(x)
return inner站在 PVM 的视角,要实现闭包机制,至少需要解决几个核心问题:
- PVM 需要能够区分普通的函数局部变量和自由变量。
- PVM 需要保证自由变量在外部函数返回后不会立即消失,而是继续随内部函数对象一起存活。
- PVM 需要保证闭包函数运行时,观察到的是自由变量的当前实际值,而非闭包函数创建时自由变量的副本值。
- PVM 需要保证外部函数和内部闭包函数均支持对自由变量进行读写。
下面为了进一步说明 CPython 3.12 执行模型中是如何解决这几个核心问题的,再给出这段代码对应的删节字节码指令:
scss
outer 函数的字节码指令序列:
MAKE_CELL 1 (x)
LOAD_CONST 1 (10)
STORE_DEREF 1 (x)
LOAD_CLOSURE 1 (x)
BUILD_TUPLE 1
LOAD_CONST 2 (<code object inner>)
MAKE_FUNCTION 8 (closure)
inner 函数的字节码指令序列:
COPY_FREE_VARS 1
LOAD_DEREF 0 (x)从这段代码中可以看出,闭包机制并不是依靠某一条孤立指令完成的,而是由多条字节码指令配合形成一条完整链路。
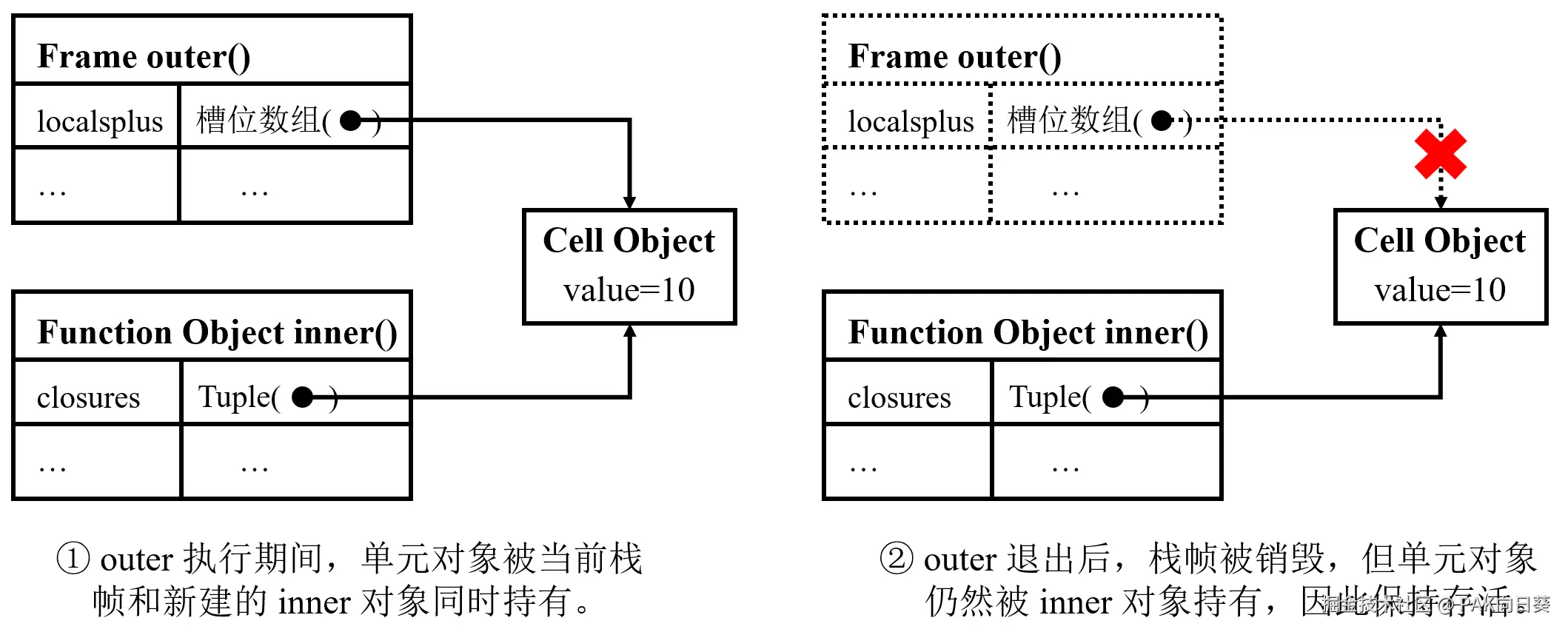
首先,在外层函数 outer 中,MAKE_CELL 字节码指令会在变量 x 所对应的局部变量槽位中新创建一个单元对象(Cell Object);随后,STORE_DEREF 字节码指令并不是把常量 10 直接写入 x 对应的槽位,而是写入该槽位的单元对象当中。
这意味着从这一时刻开始,x 在运行时就已经不再以"普通局部变量值"的形态存在,而是变成了一个可被多个函数共享的间接引用单元。与此同时,这部分字节码指令表明,Python 代码中普通局部变量和自由变量是在编译阶段完成区分的,这就首先回答了问题(1)。
接下来,在内部函数 inner 被创建之前,LOAD_CLOSURE 指令会把 x 对应的单元对象压入操作数栈。随后,BUILD_TUPLE 指令会将操作数栈顶的全体单元对象打包成一个 Python 元组。
最后,被编译器前端添加特殊参数标记的 MAKE_FUNCTION 指令会在创建函数对象时,把这个装有单元对象的元组绑定进内部函数。如下图所示,内部函数拿到的并不是 x 当前变量值的一份副本,而是对同一个单元对象的引用;因此,当外层函数 outer 后续返回时,只要这个函数对象仍然存活,它就能够继续持有该单元对象,从而解决问题(2)。
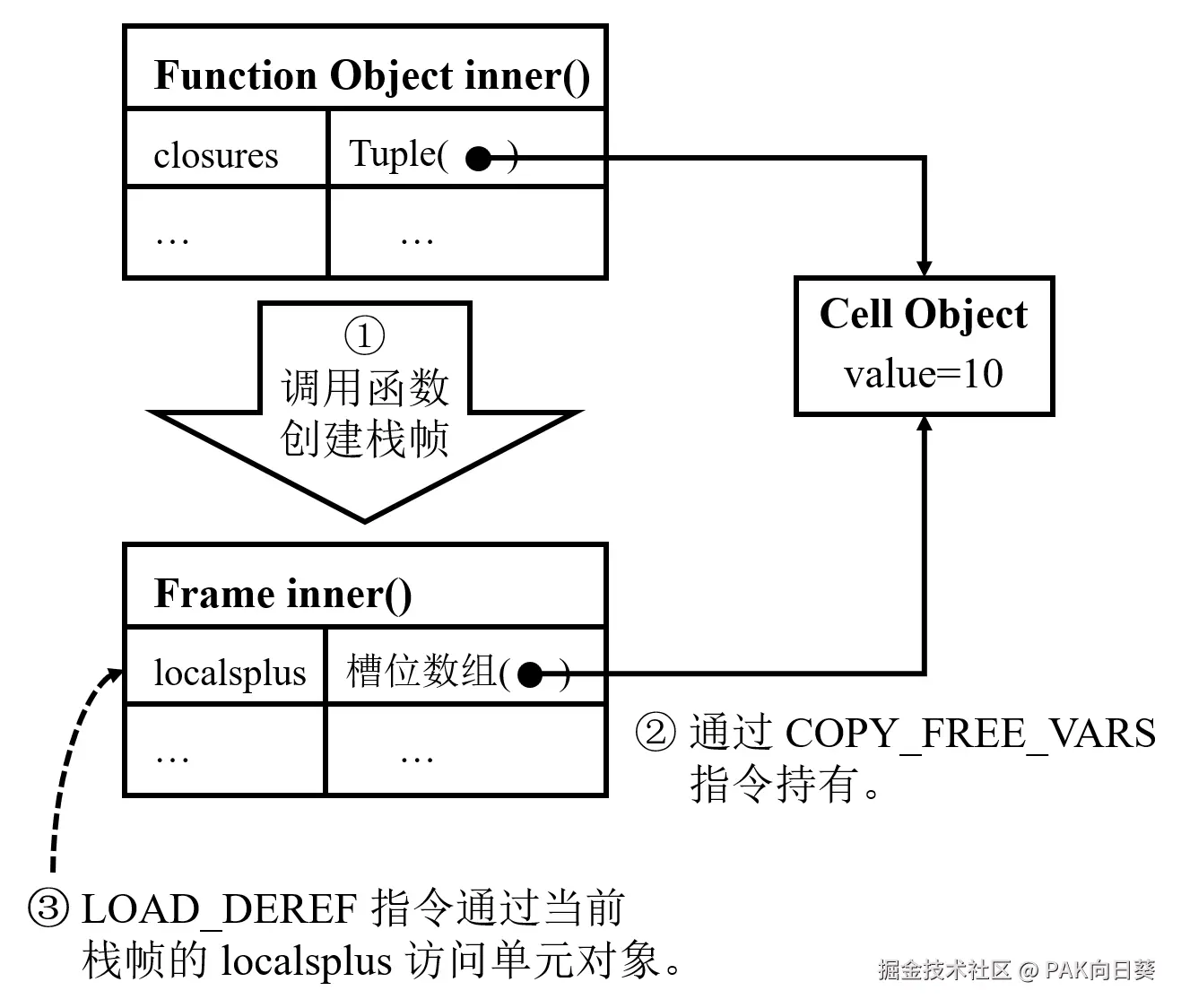
当内部函数 inner 真正被调用时,COPY_FREE_VARS 指令又会把函数对象里保存的这些单元对象重新注入新建立的 inner 对应的栈帧中,使该栈帧的局部变量槽位区持有同一个单元对象。
随后,LOAD_DEREF 指令才真正执行对自由变量的读取操作。换言之,内部函数运行时读取到的,并不是当初创建函数对象时复制下来的一份静态值,而是通过单元对象间接解析出来的"当前值"。
因此,无论是外层函数还是内部函数,只要它们操作的是同一个单元对象,就都能够观察到对该变量所做的更新。这就解释了 PVM 是如何解决问题(3)与(4)的。
总结一下,Python 语言中的闭包是一套需要由编译器前端、单元对象间接层和专用字节码指令共同协作完成的完整机制。
9. 内建函数也要被建模为"可调用对象"
除了用户自己定义的函数,Python 还提供了很多内建函数,例如:
python
print()
len()
isinstance()这些函数通常不是用 Python 自己实现的,而是由虚拟机内部的本地代码实现,并提前注册到内建命名空间中。
但是从语言层面看,用户调用它们的方式和调用普通函数没有本质区别:
python
print("hello")
len([1, 2, 3])因此,PVM 需要把内建函数和 Python 函数统一建模为"可调用对象"。
也就是说,编译器只需要生成通用的调用指令,真正执行时由虚拟机判断目标对象到底是:
- Python 函数对象;
- 内建函数对象;
- 绑定方法;
- 类型对象构造调用;
- 其他可调用对象。
这种统一的调用模型,是实现 Python 动态语言语义的重要基础。
10. Python 的对象系统:万物皆对象
Python 是一门面向对象的动态语言。
在 Python 中,不仅普通实例是对象,数字、字符串、列表、字典、函数、模块也都是对象。更进一步,类本身也是对象,也就是类型对象。
这意味着 PVM 必须建立一套统一的对象表示机制。解释器执行过程中操作的所有值,最终都应该落到统一的对象模型之上。
一个最小可用的 Python 虚拟机,通常至少需要支持这些基础内建类型:
- object
- int
- float
- str
- tuple
- list
- dict
- 函数对象
- 模块对象
- 类型对象
这些类型并不只是为了让用户代码能创建数据,它们本身也支撑着虚拟机内部机制。
例如:
- 函数默认参数可能需要用 tuple 保存;
- 模块命名空间需要用 dict 保存;
- 属性查找依赖对象和类型对象的字典;
- 函数调用、闭包、模块导入都离不开对象系统。
所以,对象系统不是虚拟机的附属功能,而是整个 PVM 的核心基础设施之一。
12. 属性查找不只是字典查询
Python 的封装机制和 C++、Java 这类静态语言不太一样。
在 Python 中,一个对象可以在运行时动态添加属性:
python
obj.name = "Alice"类也可以在运行时修改属性和方法:
python
MyClass.new_method = some_function因此,Python 虚拟机不能简单采用"字段偏移固定、方法入口固定"的静态对象模型。
通常来说,对象实例会有自己的属性字典,类对象也会有自己的属性字典。当读取一个属性时,虚拟机需要按照一定规则查找:
- 先查实例自己的属性;
- 再查类对象;
- 再沿着继承链继续查找;
- 必要时触发描述符、补救查找等机制。
另外,方法绑定也是 Python 对象系统中的一个关键点。
例如:
python
class MyClass:
def foo(self):
print("hello")
instance = MyClass()
instance.foo()当虚拟机查找 instance.foo 时,foo 实际上定义在类中,而不是实例自己的属性字典里。此时虚拟机会把函数对象和当前实例组合成一个绑定方法。调用这个绑定方法时,虚拟机会自动把 instance 作为 self 参数传入。
但如果我们这样写:
python
def bar():
print("bar")
instance.bar = bar
instance.bar()这里的 bar 是直接放在实例属性字典里的普通函数对象,不会自动绑定 self。
所以,Python 的属性访问不是简单的哈希表查询,而是包含实例属性、类属性、继承链和方法绑定等多种语义的动态解析过程。
13. 继承与 MRO
Python 支持继承,也支持多继承。
多继承带来的一个问题是:如果多个父类中存在同名方法,应该先调用哪一个?
Python 使用 MRO(Method Resolution Order,方法解析顺序) 来解决这个问题。MRO 描述了类属性和方法查找时应该遵循的顺序。对于多继承场景,Python 使用 C3 线性化算法计算 MRO。
从虚拟机实现角度看,这意味着类型对象创建时不只是简单分配一个对象,还需要计算并保存该类的 MRO 序列。后续属性查找时,虚拟机必须按照 MRO 顺序查找对应属性或方法。
因此,在一个支持 Python 面向对象机制的 PVM 中,类型系统、继承关系、MRO 和属性查找是紧密绑定在一起的。
14. Python 的多态来自运行时动态解析
在 C++ 或 Java 中,多态通常和接口、虚函数表、静态类型系统等机制有关。
但 Python 的多态更接近鸭子类型:
如果一个对象走起来像鸭子,叫起来像鸭子,那么它就可以被当作鸭子使用。
例如:
python
def do_say(animal):
animal.say()
class Cat:
def say(self):
print("meow")
class Dog:
def say(self):
print("woof")
do_say(Cat())
do_say(Dog())do_say 并不关心传进来的对象到底是 Cat 还是 Dog,只关心它有没有一个可以调用的 say 方法。
从虚拟机角度看,这种多态依赖运行时属性查找与方法绑定。调用点在编译阶段不需要绑定到某个确定实现,而是在运行时根据对象实际类型动态解析。
不过,对于虚拟机内部来说,如果所有行为都退化为动态字典查找,性能会非常差。
例如整数加法:
1 + 2如果每次都要完整查找 int.add 再调用,开销会非常高。
因此,一个实际可用的 PVM 通常需要区分两层多态:
第一层是语言语义层面的动态多态,也就是用户在 Python 代码中观察到的属性查找和方法绑定。
第二层是虚拟机内部的高效行为分派,例如对加法、比较、迭代等核心操作建立更直接的调度路径。
S.A.A.U.S.O 在后续实现对象系统时,也采用了类似的分层思路:既保留 Python 语言层面的动态性,又为虚拟机内部核心行为设计更高效的分派机制。
15. 异常是一种特殊控制流
Python 的异常机制从用户角度看很直观:
python
try:
risky()
except RuntimeError:
handle()但从 PVM 的角度看,异常其实是一种特殊控制流。
普通控制流通过顺序执行和跳转指令改变程序计数器,而异常会打断当前执行流程,并尝试把控制权转移到最近的异常处理器。
当异常发生时,虚拟机需要做几件事:
- 创建或记录异常对象;
- 保存异常状态;
- 在当前函数中查找匹配的异常处理器;
- 如果当前函数处理不了,就弹出当前栈帧;
- 继续向上一层调用者查找;
- 直到找到处理器,或者调用栈被完全展开。
这个过程通常称为 栈展开(Stack Unwinding)。
在 CPython 3.12 的执行模型中,异常处理器的查找依赖函数级别的异常表。异常表会记录某段字节码范围对应的异常处理入口,以及恢复操作数栈所需的信息。
这种设计的好处是:正常执行路径不需要频繁维护额外异常状态,只有真正发生异常时,虚拟机才根据异常表查找处理逻辑。
所以,实现异常机制并不是简单支持 raise 和 except 语法,而是要把异常状态、异常表查询、操作数栈恢复和调用栈展开整合进解释器主循环中。
16. import 背后是一套模块加载系统
最后再看模块机制。
对用户来说,导入模块只是一行代码:
python
import math或者:
python
from package import module但对 PVM 来说,模块导入是一套系统级流程,涉及:
- 模块名称解析;
- 搜索路径查找;
- 模块对象创建;
- 模块代码加载;
- 模块体执行;
- 模块命名空间初始化;
- 导入缓存;
- 父子模块绑定。
一次典型的模块导入大致可以理解为:
- 先检查模块是否已经在缓存中;
- 如果已经存在,直接复用;
- 如果不存在,根据搜索路径查找模块文件;
- 创建模块对象;
- 执行模块代码,初始化模块命名空间;
- 把模块登记到缓存;
- 返回模块对象或导入其中的名称。
也就是说,import 并不是简单的文件包含,而是在运行时创建和初始化模块对象,并维护模块缓存。
对于一个可用的 Python 虚拟机来说,模块系统是非常重要的一环。没有模块机制,代码组织、复用和多文件项目支持都会受到很大限制。
17. 小结:实现 PVM 前,必须先理解这些核心机制
本文主要介绍了实现一个轻量级 Python 虚拟机后端之前,需要掌握的一组关键机制:
- PVM 通过解释字节码执行 Python 程序;
- PVM 本质上是一台围绕操作数栈运行的栈机;
- Python 变量是名称到对象的绑定;
- 控制流最终会变成条件跳转和无条件跳转;
- 函数是运行时创建的对象;
- 函数调用依赖栈帧保存执行现场;
- 闭包依赖 Cell Object 实现自由变量共享;
- 内建函数需要和普通函数统一建模为可调用对象;
- Python 对象系统需要支持动态属性、方法绑定、继承和 MRO;
- Python 多态依赖运行时动态解析;
- 异常是一种特殊控制流,需要异常状态和栈展开机制;
- 模块导入背后是一套完整的模块加载与缓存系统。
这些机制共同构成了 S.A.A.U.S.O 这个轻量级 Python 虚拟机后端的理论基础。
后续文章中,我会继续介绍这个系统的总体架构设计,包括运行时容器、虚拟机堆、句柄机制、对象系统、执行层和嵌入接口层是如何组织起来的。