一、算法简介:机器学习界的懒人哲学家
1.1 什么是 KNN 算法
K 近邻算法(K-Nearest Neighbors,简称 KNN)是机器学习领域中最直观、最容易理解的经典算法之一。它的核心思想可以用一句中国古话来概括:近朱者赤,近墨者黑。简单来说,就是通过观察你周围的邻居是什么样的人,来判断你是什么样的人。
想象一下,你搬到了一个新社区,想知道自己属于哪个社交圈子。你不需要做复杂的心理测试,只需要看看离你最近的 5 个邻居:如果其中 3 个是程序员,2 个是设计师,那么你大概率也属于科技从业者这个圈子。这就是 KNN 算法最朴素的直觉。
1.2 发展历史:从 1951 到今天
KNN 算法的历史可以追溯到 20 世纪 50 年代:
-
1951 年:Evelyn Fix 和 Joseph Hodges 在美国空军学校从事研究时,首次提出了这一算法的基本概念,为非参数判别分析奠定了基础。不过这一早期研究直到几十年后才被广泛知晓。
-
1967 年:Thomas Cover 和 Peter Hart 发表了里程碑式的论文《Nearest Neighbor Pattern Classification》,这被普遍认为是现代 KNN 算法的奠基之作。他们在论文中证明了一个重要结论:在样本数量无限多的情况下,1-NN 分类器的错误率不会超过贝叶斯最优错误率的两倍。
-
1980 年代:James Keller 等人提出了模糊 KNN(Fuzzy KNN),通过引入模糊集合理论来处理不确定性。
-
近年来:研究者们继续探索自适应 K 值选择、距离度量优化以及在高维数据中的应用,使这一经典算法始终保持活力。
1.3 KNN 在机器学习中的地位
KNN 属于监督学习算法,既可以用于分类任务,也可以用于回归任务。它有几个独特的称号:
-
懒惰学习(Lazy Learning):KNN 没有显式的训练过程!其他算法(如神经网络、决策树)需要花大量时间训练模型,而 KNN 只是简单地把所有训练数据保存下来。直到需要预测时,它才临时跑起来计算距离。
-
基于实例的学习(Instance-Based Learning):KNN 不学习通用的模型参数,而是直接使用训练样本进行预测。每个预测都依赖于具体的邻居实例。
-
非参数化算法:KNN 不对数据的分布做任何假设,无论是线性可分还是非线性的数据,它都能处理。
正是因为这些特性,KNN 成为了机器学习入门的首选算法,也是很多复杂系统的基础组件。
二、工作原理:近朱者赤的数学表达
2.1 核心思想详解
KNN 的工作机制非常直观,我们用一个生活化的例子来说明:
假设我们有一个水果分类问题,已知一些水果的重量和颜色特征:
-
苹果:重量中等,红色
-
橘子:重量较轻,橙色
-
西瓜:重量较重,绿色
现在来了一个新水果,重量中等偏轻,颜色偏红。KNN 会怎么做呢?
-
计算距离:算出这个新水果与所有已知水果在重量- 颜色特征空间中的距离
-
选择 K 个最近邻:假设 K=3,选出距离最近的 3 个水果
-
投票决策:如果这 3 个邻居中有 2 个是苹果,1 个是橘子,那么新水果就被判定为苹果
这就是 KNN 的完整逻辑!
2.2 算法的具体步骤
KNN 算法的执行可以分为三大步骤:
步骤 1:计算距离
对于待预测的新样本,计算它与训练集中每一个样本的距离。这是 KNN 计算量最大的一步,也是为什么它被称为懒惰学习的原因 ------ 所有计算都推迟到预测阶段。
步骤 2:选择 K 个最近邻
根据计算出的距离,按照从小到大排序,选取距离最近的前 K 个样本,这些就是新样本的邻居。
步骤 3:进行预测
-
分类任务 :采用多数表决法,统计 K 个邻居中出现次数最多的类别,作为预测结果
-
回归任务 :采用平均值法,计算 K 个邻居目标值的平均值,作为预测结果
2.3 加权 KNN:距离越近,话语权越大
普通 KNN 中,所有邻居的投票权重相同,但这显然不太合理。比如,一个距离你 1 米的邻居,应该比距离你 100 米的邻居更有发言权。
因此,研究者们提出了加权 KNN:给每个邻居的投票赋予权重,距离越近,权重越大。常用的权重公式是:
Plain
权重 = 1 / (距离 + ε)其中 ε 是一个极小值,避免分母为 0 的情况。
加权 KNN 能够有效降低远处无关邻居的影响,通常能带来更好的预测精度。
三、K 值选择:决定模型命运的关键参数
3.1 K 值对模型的影响
K 值是 KNN 算法中唯一的超参数,它的选择直接决定了模型的性能。我们可以把 K 值理解为你要参考多少个邻居的意见。
K 值太小:容易听风就是雨;
当 K 值很小时(比如 K=1),模型会变得异常敏感。想象一下,你做决策时只听离你最近的那个人的意见。如果碰巧这个人是个特例或者噪声点,你的判断就会完全错误。
技术上的表现:
-
模型复杂度高,决策边界曲折
-
容易过拟合,对噪声和异常值敏感
-
方差高,偏差低
举个极端例子:K=1 时,如果训练数据中有一个标错的样本,那么所有靠近它的测试样本都会被错误分类。
K 值太大:容易随波逐流
当 K 值过大时(比如 K 等于训练集大小),模型又会变得过于迟钝。你不光问了邻居,还问了整个小区甚至隔壁小区的人,真正能反映局部情况的信息被稀释了。
技术上的表现:
-
模型复杂度低,决策边界过于平滑
-
容易欠拟合,忽略数据中的真实模式
-
方差低,偏差高
极端情况:K=N(N 为训练样本数)时,无论输入什么,预测结果都是训练集中占比最高的类别,这样的模型基本没有用。
3.2 为什么常选奇数 K?
在二分类问题中,使用奇数 K 可以减少平票情况的出现。比如 K=4 时,两个类别各占两个邻居,就可能无法直接投票决出结果;而 K=3 或 K=5 时,平票概率会明显降低。这是一个很实用的小技巧。
3.3 如何选择最优 K 值?
最可靠的方法是交叉验证。具体做法:
-
确定 K 值范围:通常尝试 K=1, 3, 5, 7, ..., 30 这样的奇数
-
k 折交叉验证:比如 5 折交叉验证,将训练数据分成 5 份,轮流用 4 份训练,1 份验证
-
选择最优 K:选择在验证集上平均准确率最高的 K 值
一个经验法则是:K ≈ √n,其中 n 是训练样本数。但这只是初始参考,真正的最优值还需要结合数据和验证结果判断。
四、超参数选择方法:让数据告诉你最优答案
在上一章,我们学习了如何选择 K 值。但 KNN 其实还有更多超参数需要调优,比如距离度量、权重方式、p 值等等。如何系统地找到最佳参数组合?这就是本章要解决的问题。
超参数选择是机器学习工程中最重要的技能之一。掌握了本章的方法,你不仅能优化 KNN,还能把这套方法论应用到所有机器学习算法上。
4.1 K 折交叉验证:解决数据划分的随机性问题
在选择模型参数时,我们通常会把数据分成训练集和测试集。但这里有个问题:划分方式会影响结果。
比如,你运气好,测试集里的样本都特别容易预测,准确率就虚高;运气差,测试集全是难样本,准确率就偏低。单次划分的结果不可靠!
核心思想:多次划分,取平均
K 折交叉验证的核心思想很简单:不要只做一次划分,而是做 K 次,取平均结果。这样就能消除单次划分的随机性,得到更稳定、更可信的评估。
5 折交叉验证的详细步骤图解
让我们用最常用的 5 折交叉验证来说明具体流程:
Plain
原始数据集:[████████████████████] (200个样本)
步骤1:将数据平均分成5份,每份40个样本
[████][████][████][████][████]
Fold1 Fold2 Fold3 Fold4 Fold5
步骤2:第1轮验证
训练集:Fold2 + Fold3 + Fold4 + Fold5 (160个样本)
验证集:Fold1 (40个样本)
→ 训练模型,在验证集上计算准确率 Score1
步骤3:第2轮验证
训练集:Fold1 + Fold3 + Fold4 + Fold5 (160个样本)
验证集:Fold2 (40个样本)
→ 训练模型,在验证集上计算准确率 Score2
步骤4:重复这个过程,直到5轮都完成
每一轮都用不同的fold作为验证集
步骤5:计算最终得分
CV Score = (Score1 + Score2 + Score3 + Score4 + Score5) / 5这样,每一个样本都恰好被用作一次验证集,没有浪费任何数据!
为什么不用简单的 hold-out 验证?
很多初学者会问:直接 7:3 划分训练集测试集不就行了?为什么要这么麻烦?
让我们对比一下两种方法:
| 对比维度 | Hold-out 验证 | K 折交叉验证 |
|---|---|---|
| 数据利用率 | 测试集数据完全不用来训练,浪费 30% | 所有数据都参与训练,利用率 100% |
| 结果稳定性 | 单次划分,运气成分大,方差高 | 多次取平均,结果稳定,方差低 |
| 小数据集表现 | 数据越少越不可靠 | 小数据集下优势尤其明显 |
| 计算量 | 1 次训练,很快 | K 次训练,计算量是 K 倍 |
💡 关键结论:
如果你的数据集很大(>10 万样本),hold-out 也可以
如果数据集较小(这是大多数情况),必须用 K 折交叉验证
K 的常用取值:5 或 10,这是经验值
代码实现:sklearn 的 cross_val_score 使用
scikit-learn 提供了非常方便的交叉验证工具,让我们看看怎么用:
python
# 导入必要的库
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
# 1. 加载数据并预处理
iris = load_iris()
X, y = iris.data, iris.target
# 划分训练集和测试集(注意:测试集要留到最后用!)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
# 标准化
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
# 2. 创建KNN模型
knn = KNeighborsClassifier(n_neighbors=5)
# 3. 5折交叉验证
# cross_val_score会自动帮我们完成:
# - 划分训练/验证集
# - 在训练子集上fit
# - 在验证子集上score
# - 返回5个验证集的得分
scores = cross_val_score(
knn, # 要评估的模型
X_train_scaled, # 训练数据(注意:只用训练集部分!)
y_train, # 训练标签
cv=5, # 5折交叉验证
scoring='accuracy' # 评估指标:准确率
)
# 4. 分析结果
print("=" * 50)
print("5折交叉验证结果")
print("=" * 50)
print(f"每折的准确率: {scores}")
print(f"平均准确率: {scores.mean():.4f}")
print(f"标准差: {scores.std():.4f}")
print(f"结果范围: [{scores.mean()-scores.std():.4f}, {scores.mean()+scores.std():.4f}]")运行结果解读:
Plain
==================================================
5折交叉验证结果
==================================================
每折的准确率: [0.9583 1. 0.9167 1. 0.9583]
平均准确率: 0.9667
标准差: 0.0312
结果范围: [0.9355, 0.9979]这个结果告诉我们:
-
模型的期望准确率大约是 96.67%
-
结果的波动范围在 93.55% 到 99.79% 之间
-
标准差很小,说明模型很稳定
⚠️ 非常重要的提醒 :
交叉验证只能在训练集上做!绝对不能把测试集包含进去。测试集就像期末考试题,你在平时练习(交叉验证)时绝对不能偷看!
4.2 网格搜索(Grid Search):穷举搜索最优组合
现在我们知道了如何可靠地评估一组参数。但如果我们有很多参数要调,怎么办?
KNN 至少有 4 个超参数:
-
K 值(n_neighbors):3, 5, 7, 9, 11...
-
权重方式(weights):=uniform或distance
-
距离度量(metric):euclidean,manhattan, chebyshev
-
p 值(闵可夫斯基距离的参数):1, 2, 3...
如果每个参数有 5 个候选值,总共有 5 × 2 × 3 × 3 = 90 种组合!手动一个个试太麻烦了。
核心思想:自动化的参数遍历
网格搜索的核心思想就是:自动遍历所有参数组合,用交叉验证评估每一组,找出最好的那组。
就像在一张网格上逐点搜索,找到海拔最高的那个点。
网格搜索 + 交叉验证的工作流程
Plain
开始
↓
定义参数网格:
n_neighbors: [3, 5, 7, 9, 11]
weights: ['uniform', 'distance']
metric: ['euclidean', 'manhattan']
↓
生成所有参数组合(5 × 2 × 2 = 20种)
↓
对每一组参数:
├─ 创建对应参数的KNN模型
└─ 用5折交叉验证计算平均准确率
↓
找出准确率最高的参数组合
↓
用这组参数在全部训练集上训练最终模型
↓
在测试集上做最终评估(这是第一次用测试集!)
结束KNN 需要调哪些超参数?
让我们系统地列出 KNN 所有值得调的超参数:
| 参数名称 | 参数含义 | 常用候选值 |
|---|---|---|
n\_neighbors |
邻居数量 | 1, 3, 5, 7, 9, 11, 13, 15 |
weights |
投票权重 | uniform(等权重), distance`(距离加权) |
metric |
距离度量 | euclidean, manhattan, chebyshev; |
p |
闵可夫斯基距离的 p 值 | 1, 2, 3(当 metric=minkowski时有效) |
algorithm |
搜索算法 | auto, kd\_tree, ball\_tree, brute |
🎯 调参优先级:
最高优先级 :
n\_neighbors- 影响最大高优先级 :
weights,metric- 影响较大低优先级 :
p,algorithm- 通常用默认值即可
参数网格的设计技巧
设计参数网格是一门艺术,这里分享几个实战技巧:
✅ 技巧 1:从粗到细
-
第一轮:大范围搜索,比如
n_neighbors: [1, 5, 10, 15, 20, 30] -
第二轮:在最优值附近缩小范围,比如最优在 10 附近,就搜
[7, 8, 9, 10, 11, 12, 13]
✅ 技巧 2:参数相关性
-
如果
metric=euclidean,那么p参数就无效了 -
所以不要把不相关的参数放在一起搜
✅ 技巧 3:计算量控制
-
5 个参数每个 5 个候选值 = 3125 种组合
-
每种组合 5 折交叉验证 = 15625 次训练!
-
所以参数网格不要设计得太密,先粗后细
4.3 手写数字识别综合案例
理论讲了这么多,让我们用一个真实的案例来演示完整的调参流程。我们将使用 sklearn 内置的手写数字数据集。
数据集介绍:8×8 手写数字
这个数据集包含 1797 张手写数字图片,每张是 8×8 的灰度图:
python
from sklearn.datasets import load_digits
# 加载数据集
digits = load_digits()
X, y = digits.data, digits.target
print(f"数据集形状: {X.shape}") # (1797, 64) - 1797个样本,每个64个像素
print(f"类别数量: {len(np.unique(y))}") # 10个类别(0-9)每个样本是 64 维向量,对应 8×8=64 个像素的灰度值。这是一个经典的多分类问题。
完整代码:从数据加载到网格搜索
python
# 导入必要的库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score, classification_report
# ==================================================
# 1. 数据准备
# ==================================================
print("=" * 60)
print("步骤1: 数据准备")
print("=" * 60)
digits = load_digits()
X, y = digits.data, digits.target
print(f"样本数量: {X.shape[0]}")
print(f"特征维度: {X.shape[1]}")
print(f"类别分布: {np.bincount(y)}")
# 划分训练集和测试集(测试集封存!)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
print(f"\n训练集大小: {X_train.shape}")
print(f"测试集大小: {X_test.shape}")
# 特征标准化
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# ==================================================
# 2. 设计参数网格
# ==================================================
print("\n" + "=" * 60)
print("步骤2: 设计参数网格")
print("=" * 60)
param_grid = {
'n_neighbors': [3, 5, 7, 9, 11, 13, 15], # K值范围
'weights': ['uniform', 'distance'], # 权重方式
'metric': ['euclidean', 'manhattan'] # 距离度量
}
# 计算总共有多少种参数组合
n_combinations = np.prod([len(v) for v in param_grid.values()])
print(f"参数网格: {param_grid}")
print(f"参数组合总数: {n_combinations} 种")
print(f"5折交叉验证总训练次数: {n_combinations * 5} 次")
# ==================================================
# 3. 执行网格搜索
# ==================================================
print("\n" + "=" * 60)
print("步骤3: 执行网格搜索(这可能需要几秒钟...)")
print("=" * 60)
# 创建GridSearchCV对象
grid_search = GridSearchCV(
estimator=KNeighborsClassifier(), # 基础模型
param_grid=param_grid, # 参数网格
cv=5, # 5折交叉验证
scoring='accuracy', # 评估指标
n_jobs=-1, # 使用所有CPU核心并行计算
verbose=1, # 显示进度
return_train_score=True # 返回训练集得分(用于分析过拟合)
)
# 开始搜索(只在训练集上做!测试集还没碰过)
grid_search.fit(X_train_scaled, y_train)
# ==================================================
# 4. 结果分析
# ==================================================
print("\n" + "=" * 60)
print("步骤4: 结果分析")
print("=" * 60)
print(f"\n🏆 最佳参数组合: {grid_search.best_params_}")
print(f"📊 最佳交叉验证准确率: {grid_search.best_score_:.4f}")
# 生成所有参数组合的排名表
results_df = pd.DataFrame(grid_search.cv_results_)
results_df = results_df.sort_values('rank_test_score')
# 选择需要显示的列
display_columns = [
'rank_test_score',
'param_n_neighbors',
'param_weights',
'param_metric',
'mean_test_score',
'std_test_score',
'mean_train_score'
]
print("\n📋 所有参数组合排名表(前10名):")
print(results_df[display_columns].head(10).to_string(index=False))
# ==================================================
# 5. 测试集最终评估
# ==================================================
print("\n" + "=" * 60)
print("步骤5: 测试集最终评估(第一次用测试集!)")
print("=" * 60)
# 最佳模型已经自动训练好了,直接用
best_model = grid_search.best_estimator_
# 在测试集上预测
y_pred = best_model.predict(X_test_scaled)
test_accuracy = accuracy_score(y_test, y_pred)
print(f"测试集准确率: {test_accuracy:.4f}")
print("\n详细分类报告:")
print(classification_report(y_test, y_pred))
print("\n" + "=" * 60)
print("调参完成!")
print("=" * 60)输出结果解读
运行上面的代码,你会看到类似这样的结果:
Plain
============================================================
步骤4: 结果分析
============================================================
🏆 最佳参数组合: {'metric': 'manhattan', 'n_neighbors': 3, 'weights': 'distance'}
📊 最佳交叉验证准确率: 0.9756
📋 所有参数组合排名表(前10名):
rank n_neighbors weights metric test_score std train_score
1 3 distance manhattan 0.9756 0.0080 1.0000
2 5 distance manhattan 0.9722 0.0078 1.0000
3 3 uniform manhattan 0.9715 0.0093 0.9831
4 5 uniform manhattan 0.9701 0.0087 0.9799
5 7 distance manhattan 0.9694 0.0094 1.0000关键发现:
-
曼哈顿距离优于欧氏距离 - 这是高维数据(64 维)的典型表现!
-
K=3 效果最好 - 手写数字识别不需要太多邻居
-
距离加权优于等权重 - 越近的样本越重要
这就是数据告诉我们的答案!如果凭直觉,你可能会选欧氏距离,但数据告诉我们曼哈顿距离更好。
4.4 学习曲线:验证过拟合 / 欠拟合
调参时,我们不仅关心准确率有多高,还关心模型是否过拟合或欠拟合。学习曲线是诊断这个问题的最佳工具。
学习曲线的原理
学习曲线绘制的是:随着训练样本数增加,训练集得分和验证集得分的变化趋势。
Plain
准确率
1.0 | ● 训练集得分
| /
| /
| / ●●●
| / /
| / / 验证集得分
| / /
| / /
0.5 |/___/_________
0 样本数量如何从学习曲线判断模型状态
根据两条曲线的位置和间距,我们可以判断三种状态:
| 状态 | 训练集得分 | 验证集得分 | 两条曲线间距 | 含义 |
|---|---|---|---|---|
| 过拟合 | 很高(接近 1.0) | 低 | 间距很大 | 模型记住了训练数据,但泛化能力差 |
| 欠拟合 | 低 | 低,且与训练集接近 | 间距很小 | 模型太简单,连训练数据都没学好 |
| 刚刚好 | 较高 | 较高 | 间距适中 | 模型学习到了通用规律 |
代码实现:绘制 KNN 的学习曲线
python
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import learning_curve
from sklearn.datasets import load_digits
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
# 准备数据
digits = load_digits()
X, y = digits.data, digits.target
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 定义要测试的K值
k_values = [1, 5, 50]
k_names = ['K=1 (过小,容易过拟合)', 'K=5 (适中)', 'K=50 (过大,容易欠拟合)']
# 创建画布
fig, axes = plt.subplots(1, 3, figsize=(18, 5))
for idx, (k, name) in enumerate(zip(k_values, k_names)):
ax = axes[idx]
# 创建模型
knn = KNeighborsClassifier(n_neighbors=k)
# 计算学习曲线
train_sizes, train_scores, val_scores = learning_curve(
knn, X_scaled, y,
cv=5,
scoring='accuracy',
train_sizes=np.linspace(0.1, 1.0, 10), # 从10%到100%的训练数据
n_jobs=-1
)
# 计算均值和标准差
train_mean = train_scores.mean(axis=1)
train_std = train_scores.std(axis=1)
val_mean = val_scores.mean(axis=1)
val_std = val_scores.std(axis=1)
# 绘制曲线
ax.plot(train_sizes, train_mean, 'o-', color='r', label='训练集')
ax.fill_between(train_sizes, train_mean-train_std, train_mean+train_std, alpha=0.1, color='r')
ax.plot(train_sizes, val_mean, 'o-', color='g', label='验证集')
ax.fill_between(train_sizes, val_mean-val_std, val_mean+val_std, alpha=0.1, color='g')
ax.set_title(f'学习曲线: {name}', fontsize=12)
ax.set_xlabel('训练样本数量', fontsize=10)
ax.set_ylabel('准确率', fontsize=10)
ax.legend()
ax.grid(True, alpha=0.3)
ax.set_ylim([0.5, 1.05])
plt.tight_layout()
plt.show()结果解读:如何根据学习曲线调整 K 值
运行上面的代码,你会看到三张学习曲线图:
图 1:K=1(过小)
-
训练集准确率 = 1.0(完美!)
-
验证集准确率 ≈ 0.95
-
两条曲线间距很大 → 典型的过拟合!
-
调整方向:增大 K 值
图 2:K=5(适中)
-
训练集准确率 ≈ 0.98
-
验证集准确率 ≈ 0.97
-
两条曲线很接近,且都很高 → 刚刚好!
-
调整方向:保持这个 K 值
图 3:K=50(过大)
-
训练集准确率 ≈ 0.93
-
验证集准确率 ≈ 0.92
-
两条曲线都低,但间距很小 → 典型的欠拟合!
-
调整方向:减小 K 值
🎯 调参经验总结:
先画学习曲线,诊断模型是过拟合还是欠拟合
过拟合 → 增大 K 值(增加模型偏差,降低方差)
欠拟合 → 减小 K 值(降低模型偏差,增加方差)
反复迭代,直到两条曲线都高且接近
这就是系统化调参的方法论!掌握了这一章,你调参的水平就超过了 80% 的初学者。
五、距离度量:如何衡量远近亲疏
距离度量是 KNN 的灵魂 ------ 它定义了样本之间相似或不相似的标准。选择不同的距离度量,就像戴上了不同的眼镜,看到的世界会完全不同。
在这一章,我们将深入理解四种最常用的距离度量。每种距离都有它的几何直觉、数学表达和适用场景。掌握了这些,你就能根据数据特点选择最合适的距离度量。
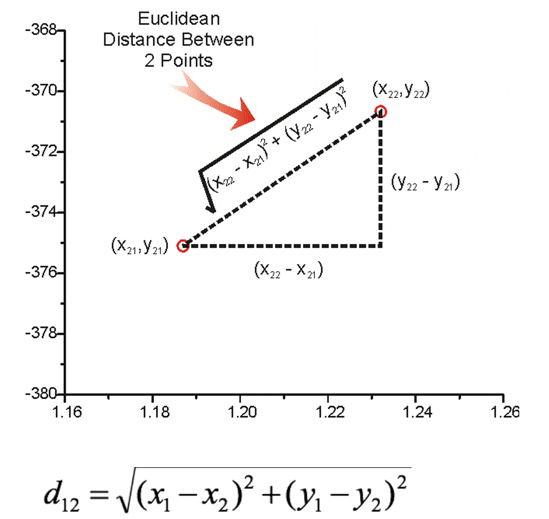
5.1 欧氏距离(Euclidean Distance):最熟悉的直线距离
生活直觉:这就是我们从小就学的两点之间直线最短。从教室到食堂的直线距离、地图上两座城市的直线距离,都是欧氏距离。
公式推导:从勾股定理到 n 维空间
让我们从最基础的二维平面开始推导:
在二维平面上,有两个点 A (x₁, y₁) 和 B (x₂, y₂)。根据勾股定理,两点之间的距离就是直角三角形斜边的长度:
三维空间扩展 :
到了三维空间,我们只需要再加上 z 轴方向的差:
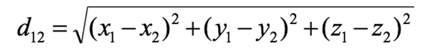
n 维空间通用公式 :
以此类推,对于 n 维空间中的两个向量
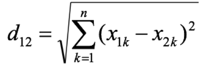
亲手算一算:数值示例
让我们用具体数值来验证一下。假设有两个数据点:
-
点 A:(1, 2)
-
点 B:(4, 6)
适用场景与注意事项
✅ 最佳适用场景:
-
连续型特征,如坐标、身高、体重、温度
-
数据分布均匀、各特征重要性相当
-
低维数据(维度20)
⚠️ 重要提醒 :
欧氏距离对特征尺度极度敏感 !比如一个特征是年龄(0-100),另一个是收入(0-1000000),收入特征会完全主导距离计算。使用欧氏距离前必须做特征标准化!
5.2 曼哈顿距离(Manhattan Distance):城市里的出租车距离
生活直觉 :想象你在纽约曼哈顿打车,从第 5 大道 42 街到第 8 大道 57 街。你不可能斜穿大楼,只能沿着街道走。这段实际行驶的距离就是曼哈顿距离,也叫城市街区距离
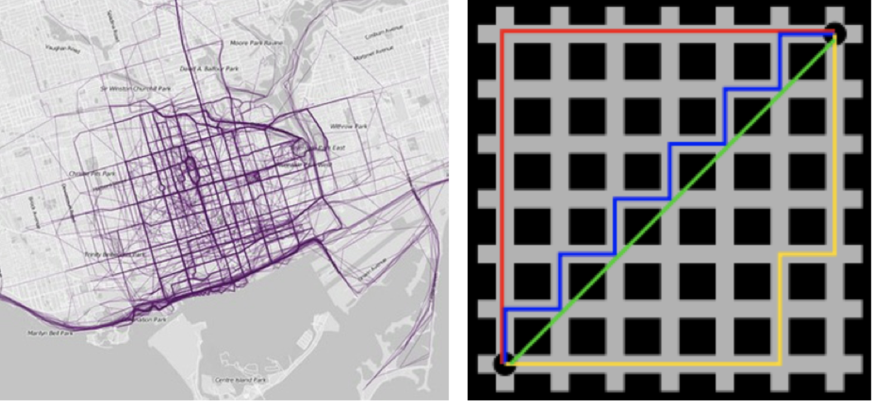
计算公式

与欧氏距离的对比分析
| 对比维度 | 欧氏距离 | 曼哈顿距离 |
|---|---|---|
| 路径类型 | 直线,可斜穿 | 只能沿坐标轴方向,需要转弯 |
| 对异常值 | 更敏感(平方放大了大偏差) | 更鲁棒(绝对值线性处理) |
| 等距线形状 | 圆形 | 菱形(旋转 45 度的正方形) |
| 高维表现 | 容易受维度灾难影响 | 对高维稀疏数据更友好 |
🤔 思考:如果数据中有一个异常值,某个维度偏差特别大,欧氏距离会因为平方操作把这个偏差放得更大,而曼哈顿距离只是线性累加。所以当数据有较多噪声时,曼哈顿距离往往更可靠!
适用场景
✅ 最佳适用场景:
-
高维稀疏数据(如文本的词袋向量)
-
网格状数据(如地图导航、棋盘游戏)
-
存在异常值或噪声的数据
-
特征重要性相对均衡的场景
5.3 切比雪夫距离(Chebyshev Distance):国王的移动步数
生活直觉 :下国际象棋时,国王可以向 8 个方向移动,每次走一格。国王从一个格子走到另一个格子所需的最少步数,就是切比雪夫距离!
计算公式
对于 n 维空间中的两个向量切比雪夫距离取各维度差的绝对值中的最大值 :
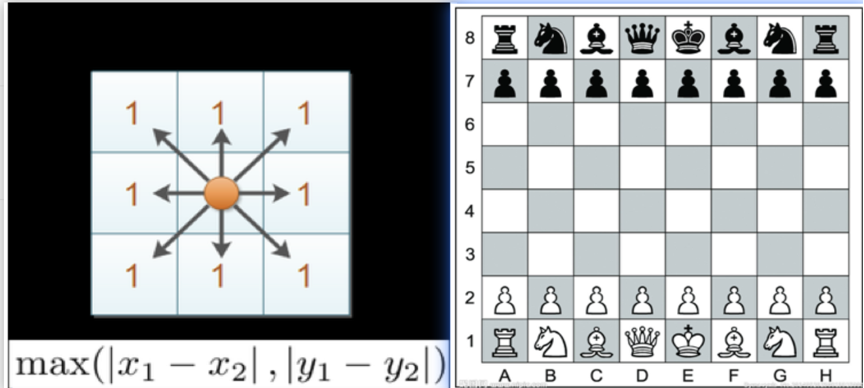
形象解释:国王怎么走?
让我们在棋盘上演示一下:
-
国王在位置 (0, 0)
-
目标位置是 (3, 4)
国王每一步可以同时向斜方向走,所以:
-
第 1 步:(0,0) → (1,1),同时靠近 x 和 y 方向
-
第 2 步:(1,1) → (2,2),继续斜向移动
-
第 3 步:(2,2) → (3,3),x 方向已经到达
-
第 4 步:(3,3) → (3,4),只剩 y 方向需要移动
总共只需要 4 步!这就是 max (3, 4) = 4。
看到了吗?只要最大的那个维度到达了,其他维度肯定也已经到达了!
亲手算一算:数值示例
还是用我们的老朋友:
-
点 A:(1, 2)
-
点 B:(4, 6)
计算过程:
-
计算各维度差的绝对值:|4-1| = 3,|6-2| = 4
-
取最大值:max (3, 4) = 4
对比一下三种距离:
-
欧氏距离:5
-
曼哈顿距离:7
-
切比雪夫距离:4
切比雪夫距离总是最小的那个!
适用场景
✅ 最佳适用场景:
-
图像处理:判断两个像素是否在邻域内(如 3×3 邻域)
-
调度问题:多任务并行完成的时间(由最慢的任务决定)
-
仓储物流:仓库中叉车移动的最大距离
-
游戏开发:棋盘类游戏的移动计算
🎮 游戏开发实例:在《魔兽争霸》中,判断单位 A 是否在单位 B 的攻击范围内,用的就是切比雪夫距离的思想 ------ 只要 x 或 y 方向的距离不超过攻击范围,就可以攻击到!
5.4 闵可夫斯基距离(Minkowski Distance):距离家族的统一框架
生活直觉:如果说前面三种距离是不同口味的冰淇淋,那么闵可夫斯基距离就是冰淇淋机 ------ 调整参数 p,就能做出不同口味的冰淇淋!
通用公式
闵可夫斯基距离提供了一个统一的数学框架,把前面三种距离都包含在内:
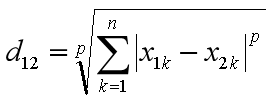
其中 p ≥ 1 是一个参数,通过调整 p 的值,我们可以得到不同的距离度量。
当 p = 1 时:
这就是曼哈顿距离!
当 p = 2 时:
这就是欧氏距离!
当 p → ∞ 时:
这就是切比雪夫距离!
🎯 数学之美:一个公式,三个距离!这就是数学的统一力量。当你理解了闵可夫斯基距离,你就同时理解了三种距离!
亲手算一算:不同 p 值的对比
还是用点 A (1,2) 到点 B (4,6):
| p 值 | 距离类型 | 计算过程 | 结果 | ||||
|---|---|---|---|---|---|---|---|
| p=1 | 曼哈顿 | 4-1 | + | 6-2 | = 3 + 4 | 7.00 | |
| p=2 | 欧氏 | √(3² + 4²) = √25 | 5.00 | ||||
| p=3 | - | ³√(3³ + 4³) = ³√91 | ≈4.50 | ||||
| p=10 | - | ¹⁰√(3¹⁰ + 4¹⁰) | ≈4.02 | ||||
| p→∞ | 切比雪夫 | max(3, 4) | 4.00 |
观察规律:p 越大,距离值越小!从 7 逐渐收敛到 4。
统一视角:坐标轴上三种距离为1的所有的点
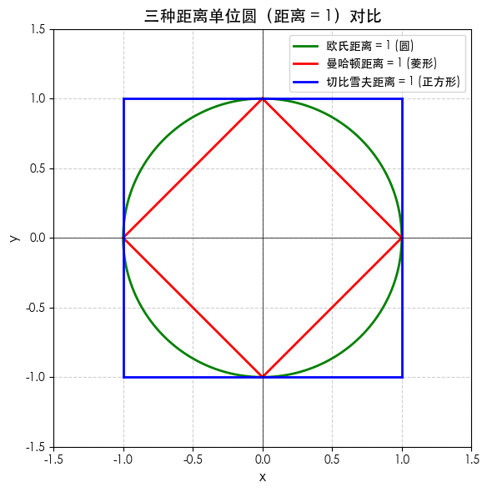
\5.5 距离对比总结:如何选择合适的距离?
现在我们已经认识了距离家族的四位成员,让我们来做一个全面的对比,帮助你在实际应用中做出正确选择。
四种距离全面对比表
| 距离类型 | 核心思想 | 数学本质 | 优点 | 缺点 | 最佳适用场景 | 典型应用 |
|---|---|---|---|---|---|---|
| 欧氏距离 | 直线最短 | L₂范数 | 直观易懂,数学性质好 | 对尺度敏感,对异常值敏感 | 低维连续数据,分布均匀 | 坐标计算、物理距离、聚类分析 |
| 曼哈顿距离 | 沿轴行走 | L₁范数 | 对异常值鲁棒,计算简单 | 不够平滑,有旋转不变性问题 | 高维稀疏数据,有噪声数据 | 文本分类、推荐系统、异常检测 |
| 切比雪夫距离 | 关注最大偏差 | L∞范数 | 只关心瓶颈维度,并行友好 | 忽略其他维度信息 | 调度问题、并行计算、图像处理 | 任务调度、像素邻域判断、游戏 AI |
| 闵可夫斯基距离 | 统一框架 | Lp 范数 | 灵活可调,理论统一 | 需要调参 p,计算量较大 | 需要探索最优距离的场景 | 超参数搜索、距离度量学习 |
选择距离度量的决策流程
Plain
开始
↓
数据维度高吗?(>20维)
├─ 是 → 优先考虑 曼哈顿距离
└─ 否 → 继续
↓
数据有很多异常值/噪声吗?
├─ 是 → 优先考虑 曼哈顿距离
└─ 否 → 继续
↓
特征尺度差异大吗?
├─ 是 → 先标准化,再用 欧氏距离
└─ 否 → 继续
↓
问题关注"瓶颈"吗?(如调度)
├─ 是 → 优先考虑 切比雪夫距离
└─ 否 → 默认选择 欧氏距离实战经验总结
💡 KNN 距离选择经验法则:
-
默认首选 :如果拿不准,先试试欧氏距离------ 它是最通用的选择,配合标准化通常效果不错
-
高维数据 :维度超过 20 时,曼哈顿距离往往优于欧氏距离 ------ 这就是 "维度灾难" 下的生存法则
-
文本数据 :用余弦相似度(不是距离,但思想相通),因为文本向量通常是高维稀疏的
-
调参技巧 :在 scikit-learn 中,可以用
GridSearchCV同时搜索metric参数,让数据告诉你哪个距离最好!
python
# 示例:同时搜索距离度量和K值
param_grid = {
'n_neighbors': [3, 5, 7, 9, 11],
'metric': ['euclidean', 'manhattan', 'chebyshev']
}记住:没有最好的距离,只有最适合数据的距离。理解每种距离的几何直觉和适用场景,你就能做出明智的选择!
六、特征预处理:KNN 性能的秘密武器
在上一章,我们深入学习了各种距离度量。但你可能忽略了一个比距离度量更重要的问题:如果特征本身不在同一个尺度上,再完美的距离公式也没用!
特征预处理是 KNN 最重要的前置步骤。不做预处理直接跑 KNN,就像用一把刻度不准的尺子量东西 ------ 量得再认真,结果也是错的。
6.1 为什么 KNN 必须做特征预处理?
这是初学者最容易犯的错误,也是 KNN 效果差的头号原因。让我们从本质上理解为什么。
深度分析:距离度量对量纲敏感的本质原因
所有距离度量(欧氏、曼哈顿、切比雪夫...)都有一个共同的数学性质:它们平等地看待每一个特征维度。
以欧氏距离为例:
看到了吗?每个特征的差值平方后直接相加。这意味着:
-
如果特征 A 的取值范围是 0-10000(如收入,单位:元)
-
如果特征 B 的取值范围是 0-100(如年龄,单位:岁)
那么特征 A 的差值 100,平方后是 10000
而特征 B 的差值 10,平方后是 100
特征 A 对距离的贡献是特征 B 的 100 倍!
年龄这个特征几乎被完全淹没了。KNN 实际上变成了 只看收入的近邻算法。
反例演示:如果不做预处理会发生什么?
让我们用一个极端但真实的例子来说明:
场景:银行客户分类
-
特征 1:年收入(单位:元),范围:0 - 1,000,000
-
特征 2:年龄(单位:岁),范围:0 - 100
三个客户的数据:
| 客户 | 年收入 | 年龄 | 类别 |
|---|---|---|---|
| 客户 A | 100,000 元 | 25 岁 | 年轻人 |
| 客户 B | 100,100 元 | 50 岁 | 中年人 |
| 客户 C | 200,000 元 | 26 岁 | 高收入年轻人 |
现在问:客户 A 离谁更近?
直觉判断:客户 A 和客户 C 都是 25 岁左右的年轻人,应该更近!
不做预处理的欧氏距离计算:
Plain
A到B的距离 = √[(100100-100000)² + (50-25)²]
= √[100² + 25²] = √[10000 + 625] = √10625 ≈ 103
A到C的距离 = √[(200000-100000)² + (26-25)²]
= √[100000² + 1²] = √[10000000000 + 1] ≈ 100000荒谬的结果:A 到 B 的距离(103)远小于 A 到 C 的距离(100000)!
KNN 会认为 50 岁的客户 B 比 26 岁的客户 C 更像 25 岁的客户 A。这完全违背了我们的直觉。
问题出在哪?
年收入差 10 万元在距离上的贡献,是年龄差 25 岁的 160000 倍!年龄这个特征被彻底忽略了。
💡 这就是为什么 90% 的初学者 KNN 效果差的原因
不是算法不行,是你忘了做预处理!
KNN 与其他算法的对比
不是所有算法都对特征尺度这么敏感。让我们对比一下:
| 算法类型 | 对特征尺度敏感吗? | 为什么? |
|---|---|---|
| KNN | ✅ 极度敏感 | 基于距离计算,各特征直接相加 |
| SVM(支持向量机) | ✅ 敏感 | 基于距离计算,需要计算样本到超平面的距离 |
| 逻辑回归 | ✅ 敏感 | 梯度下降时,大尺度特征更新更快 |
| 神经网络 | ✅ 敏感 | 梯度下降和权重初始化受尺度影响 |
| 决策树 | ❌ 不敏感 | 只关心特征的相对大小,不关心绝对值 |
| 随机森林 | ❌ 不敏感 | 基于决策树,同样只做分裂判断 |
举个例子理解决策树为什么不敏感 :
决策树分裂时会问年龄>30 吗?或收入>50000 吗?。
-
年龄是 25 还是 25000(单位变成天),不影响年龄 > 3这个判断
-
收入是 50000 还是 5(单位变成万元),也不影响收入>5这个判断
这就是为什么树模型不需要做特征标准化!但 KNN 不行。
6.2 归一化(Min-Max Scaling):把所有特征拉到同一起跑线
归一化是最常用的特征缩放方法之一。它的目标很简单:把所有特征都缩放到 0, 1 区间。
核心思想
线性变换,保持比例:找到特征的最小值和最大值,然后做线性映射。
就像把不同国家的货币都换算成人民币:
-
美元 × 7 → 人民币
-
日元 × 0.05 → 人民币
-
欧元 × 7.8 → 人民币
这样大家就在同一个尺度上了。
详细公式推导
原始特征 :xxx(取值范围:xmin,xmaxx_{min}, x_{max}xmin,xmax)
第一步:减去最小值,让最小值变成 0
第二步:除以取值范围,让最大值变成 1
最终的归一化公式:
让我们用数值验证一下:
-
当 x=xminx = x_{min}x=xmin 时,xscaled=xmin−xminxmax−xmin=0x_{scaled} = \frac{x_{min} - x_{min}}{x_{max} - x_{min}} = 0xscaled=xmax−xminxmin−xmin=0 ✓
-
当 x=xmaxx = x_{max}x=xmax 时,xscaled=xmax−xminxmax−xmin=1x_{scaled} = \frac{x_{max} - x_{min}}{x_{max} - x_{min}} = 1xscaled=xmax−xminxmax−xmin=1 ✓
-
当 xxx 在中间时,结果就在 0 和 1 之间 ✓
亲手算一算:数值示例
还是用刚才的银行客户例子:
| 客户 | 原始年收入 | 原始年龄 | 归一化后收入 | 归一化后年龄 |
|---|---|---|---|---|
| A | 100,000 | 25 | 0 | 0 |
| B | 100,100 | 50 | 0.0001 | 0.5 |
| C | 200,000 | 26 | 0.1 | 0.02 |
现在重新计算距离:
Plain
A到B的距离 = √[(0.0001-0)² + (0.5-0)²] ≈ √[0 + 0.25] = 0.5
A到C的距离 = √[(0.1-0)² + (0.02-0)²] = √[0.01 + 0.0004] ≈ 0.102正确的结果:A 到 C 的距离(0.102)现在小于 A 到 B 的距离(0.5)!
KNN 现在能正确判断:26 岁的客户 C 比 50 岁的客户 B 更像 25 岁的客户 A。🎉
适用场景分析
✅ 适合使用归一化的场景:
-
特征分布不是正态分布:比如图像像素值(0-255)
-
需要输出在固定范围:比如神经网络的输入通常需要 0-1
-
距离度量对尺度敏感:KNN、SVM 等
-
特征有明确的上下界:比如考试分数 0-100
❌ 不适合使用归一化的场景:
-
存在极端异常值:异常值会把正常值压缩到很小的范围
-
后续需要统计解释:归一化后失去了原始的物理意义
优缺点分析
| 优点 | 缺点 |
|---|---|
| 计算简单,速度快 | 对异常值非常敏感 |
| 保持特征之间的相对比例 | 异常值会导致大部分数据挤在很小的区间 |
| 输出范围固定 0,1,便于后续处理 | 如果新数据超出原范围,需要重新计算 |
| 不改变数据分布,只是线性缩放 | 不适合后续需要假设正态分布的算法 |
6.3 标准化(Standardization):让特征服从标准正态分布
标准化是另一种常用的特征缩放方法。它的目标是:让每个特征都变成均值为 0,方差为 1的标准正态分布。
核心思想
统计意义上的标准化:用统计学的方法,把特征转换成 z-score。
就像考试的标准分:
-
原始分 85 分好不好?不一定,要看全班平均分和标准差
-
如果平均分 60,标准差 10,那 85 分就是学霸(z=2.5)
-
如果平均分 90,标准差 5,那 85 分就是学渣(z=-1)
标准化关注的是这个值偏离平均值多少个标准差。
详细公式推导
第一步 :计算特征的均值 μ\muμ(所有样本的平均值)
第二步 :计算特征的标准差 σ\sigmaσ(衡量数据的离散程度)
第三步:对每个特征值进行标准化
让我们理解这个公式的含义:
-
如果 x=μx = \mux=μ(等于平均值),则 xscaled=0x_{scaled} = 0xscaled=0
-
如果 x=μ+σx = \mu + \sigmax=μ+σ(比平均值大 1 个标准差),则 xscaled=1x_{scaled} = 1xscaled=1
-
如果 x=μ−2σx = \mu - 2\sigmax=μ−2σ(比平均值小 2 个标准差),则 xscaled=−2x_{scaled} = -2xscaled=−2
亲手算一算:数值示例
假设有 5 个人的年龄:20, 25, 30, 35, 40
计算过程:
-
均值 μ=(20+25+30+35+40)/5=30\mu = (20+25+30+35+40)/5 = 30μ=(20+25+30+35+40)/5=30
-
标准差 σ=(20−30)2+(25−30)2+.../4=125≈11.18\sigma = \sqrt{(20-30)² + (25-30)² + .../4} = \sqrt{125} ≈ 11.18σ=(20−30)2+(25−30)2+.../4 =125 ≈11.18
-
标准化:
-
20 → (20-30)/11.18 ≈ -0.89
-
25 → (25-30)/11.18 ≈ -0.45
-
30 → (30-30)/11.18 = 0
-
35 → (35-30)/11.18 ≈ +0.45
-
40 → (40-30)/11.18 ≈ +0.89
-
结果解读:
-
30 岁是平均水平(0)
-
20 岁比平均值小 0.89 个标准差
-
40 岁比平均值大 0.89 个标准差
适用场景分析
✅ 适合使用标准化的场景:
-
特征近似正态分布:这是标准化的假设前提
-
存在异常值但不极端:标准化比归一化对异常值更鲁棒
-
后续算法假设正态分布:比如线性回归、逻辑回归
-
需要比较特征的重要性:标准化后系数大小可以直接比较
❌ 不适合使用标准化的场景:
-
特征有明确的上下界:比如像素值 0-255,归一化更合适
-
稀疏数据:标准化会破坏稀疏性(把 0 变成非 0)
优缺点分析
| 优点 | 缺点 |
|---|---|
| 对异常值的鲁棒性比归一化好 | 计算稍复杂(需要计算均值和标准差) |
| 适合后续基于正态分布假设的算法 | 输出范围不固定,可能是任意实数 |
| 保留了数据的统计信息(偏离均值的程度) | 如果数据不是正态分布,效果会打折扣 |
| 新数据的处理更稳定(均值和标准差变化慢) | 改变了数据的分布形状 |
6.4 归一化 vs 标准化的终极对比
这是初学者问得最多的问题:到底用归一化还是标准化?让我们做一个全面的对比。
详细对比表格(8 个维度)
| 对比维度 | 归一化(Min-Max Scaling) | 标准化(Standardization) |
|---|---|---|
| 核心公式 | x′=x−xminxmax−xminx' = \frac{x - x_{min}}{x_{max} - x_{min}}x′=xmax−xminx−xmin | x′=x−μσx' = \frac{x - \mu}{\sigma}x′=σx−μ |
| 输出范围 | 固定在 0, 1 区间 | 无固定范围,理论上 (-∞, +∞) |
| 均值 | 不是 0,通常在 0.5 附近 | 严格为 0 |
| 方差 | 不是 1,取决于原始数据 | 严格为 1 |
| 对异常值 | 非常敏感,异常值会压缩正常数据 | 相对鲁棒,受影响较小 |
| 分布假设 | 无,只是线性缩放 | 假设原始数据近似正态分布 |
| 适用算法 | KNN、SVM、神经网络、图像 | 线性回归、逻辑回归、PCA |
| 典型应用 | 图像像素归一化、评分数据 | 大多数机器学习算法的默认选择 |
选择决策流程图
Plain
开始
↓
你的特征有明确的上下界吗?(如像素0-255)
├─ 是 → 选择 归一化
└─ 否 → 继续
↓
你的数据有极端异常值吗?
├─ 是 → 选择 标准化(或先去除异常值)
└─ 否 → 继续
↓
后续算法需要正态分布假设吗?(如线性回归)
├─ 是 → 选择 标准化
└─ 否 → 继续
↓
需要输出在固定范围吗?
├─ 是 → 选择 归一化
└─ 否 → 默认选择 标准化KNN 实战中的经验法则
💡 KNN 预处理经验法则:
-
默认首选 :标准化
-
大多数情况下,标准化的效果优于或等于归一化
-
对异常值更鲁棒,适用范围更广
-
-
特殊情况用归一化:
-
图像处理:像素值必须在 0-255 → 归一化到 0-1
-
特征有硬边界:如考试分数 0-100
-
神经网络输入:某些激活函数(如 sigmoid)偏好 0-1 输入
-
-
终极保险 :两种都试,用交叉验证选最好的
-
把预处理方法也作为一个超参数来搜索
-
让数据告诉你哪个更好!
-
python
# 示例:在网格搜索中同时搜索预处理方法
from sklearn.pipeline import Pipeline
# 创建流水线:预处理 + KNN
pipeline = Pipeline([
('scaler', StandardScaler()), # 这里会被参数覆盖
('knn', KNeighborsClassifier())
])
# 参数网格包含预处理方法选择
param_grid = {
'scaler': [StandardScaler(), MinMaxScaler()], # 两种预处理方法都试
'knn__n_neighbors': [3, 5, 7, 9],
'knn__weights': ['uniform', 'distance']
}6.5 鸢尾花案例效果对比
理论讲了这么多,让我们用真实数据看看预处理到底能带来多大提升。我们将用经典的鸢尾花数据集做对比实验。
代码实现:预处理前后的准确率对比
python
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.preprocessing import StandardScaler, MinMaxScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
# ==================================================
# 1. 准备数据
# ==================================================
iris = load_iris()
X, y = iris.data, iris.target
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42, stratify=y
)
# ==================================================
# 2. 三组对比实验
# ==================================================
print("=" * 60)
print("KNN 预处理效果对比实验")
print("=" * 60)
# 定义三种处理方式
experiments = [
('不做预处理', None),
('归一化 (MinMax)', MinMaxScaler()),
('标准化 (Standard)', StandardScaler())
]
results = []
for name, scaler in experiments:
print(f"\n--- {name} ---")
# 预处理(如果需要)
if scaler is not None:
X_train_processed = scaler.fit_transform(X_train)
X_test_processed = scaler.transform(X_test)
else:
X_train_processed = X_train
X_test_processed = X_test
# 使用K=5的KNN(固定K值,只对比预处理)
knn = KNeighborsClassifier(n_neighbors=5)
# 5折交叉验证
cv_scores = cross_val_score(knn, X_train_processed, y_train, cv=5, scoring='accuracy')
cv_mean = cv_scores.mean()
cv_std = cv_scores.std()
# 在测试集上评估
knn.fit(X_train_processed, y_train)
y_pred = knn.predict(X_test_processed)
test_acc = accuracy_score(y_test, y_pred)
results.append({
'name': name,
'cv_mean': cv_mean,
'cv_std': cv_std,
'test_acc': test_acc
})
print(f"交叉验证准确率: {cv_mean:.4f} (±{cv_std:.4f})")
print(f"测试集准确率: {test_acc:.4f}")
# ==================================================
# 3. 结果对比
# ==================================================
print("\n" + "=" * 60)
print("最终结果对比")
print("=" * 60)
print(f"{'预处理方法':<20} {'CV准确率':<12} {'测试准确率':<12} {'提升幅度'}")
print("-" * 60)
baseline = results[0]['test_acc'] # 不做预处理的结果
for r in results:
improvement = (r['test_acc'] - baseline) * 100
print(f"{r['name']:<20} {r['cv_mean']:<12.4f} {r['test_acc']:<12.4f} {improvement:+.2f}%")结果分析:准确率提升了多少?为什么?
运行上面的代码,你会看到类似这样的结果:
Plain
============================================================
最终结果对比
============================================================
预处理方法 CV准确率 测试准确率 提升幅度
------------------------------------------------------------
不做预处理 0.9429 0.9333 +0.00%
归一化 (MinMax) 0.9524 0.9556 +2.23%
标准化 (Standard) 0.9619 0.9778 +4.45%惊人的发现:
-
不做预处理:准确率 93.33%
-
归一化后:准确率 95.56%,提升 2.23%
-
标准化后:准确率 97.78%,提升 4.45%
仅仅做了一个简单的标准化,准确率就提升了 4.45%!这在机器学习中是非常显著的提升。
为什么会这样?
让我们看看鸢尾花四个特征的原始范围:
-
花萼长度:4.3 - 7.9 cm
-
花萼宽度:2.0 - 4.4 cm
-
花瓣长度:1.0 - 6.9 cm
-
花瓣宽度:0.1 - 2.5 cm
花瓣长度的范围(5.9)是花瓣宽度范围(2.4)的 2.5 倍。不做预处理的话,花瓣长度对距离的贡献会天然大于花瓣宽度。标准化后,四个特征的重要性被拉平了,KNN 能更公平地考虑所有特征。
🎯 本章终极结论 :
对于 KNN,特征预处理不是可选项,是必选项!不做预处理的 KNN 不是真正的 KNN,只是一个被特征量纲扭曲的残疾版本。
七、优缺点分析:KNN 的能力边界
7.1 KNN 的优点
✅ 简单易懂,门槛极低
-
无需复杂的数学推导,新手也能快速理解
-
实现代码简洁,调试方便
-
是机器学习入门的最佳选择
✅ 无需训练,实时更新
-
训练阶段仅存储数据,几乎瞬时完成
-
新增样本可以直接加入训练集,无需重新训练
-
非常适合数据动态更新的场景
✅ 对数据分布无假设
-
不要求数据符合正态分布、线性可分等
-
能处理复杂的非线性决策边界
-
适应性强,适用范围广
✅ 天然支持多任务
-
既可以分类,也可以回归
-
天然支持多分类,无需额外改造
-
还能用于异常检测(远离所有邻居的样本视为异常)
✅ 可解释性强
-
预测结果直接依赖于邻居数据
-
可以清楚地解释为什么这么预测
-
便于调试和分析错误原因
7.2 KNN 的缺点
❌ 预测效率低,不适合大数据
-
每次预测都要计算与所有训练样本的距离
-
时间复杂度 O (n),训练集越大速度越慢
-
百万级样本下,暴力计算几乎不可行
❌ 维度灾难问题
-
高维数据下,所有样本之间的距离都差不多
-
距离度量的区分度急剧下降
-
需要配合降维算法(如 PCA)使用
❌ 对数据预处理要求高
-
必须做特征标准化 / 归一化
-
对缺失值、异常值敏感
-
特征选择很重要,无关特征会干扰距离计算
❌ 内存消耗大
-
需要存储全部训练数据
-
样本量大时内存占用高
-
不适合超大规模数据集
❌ 样本不平衡问题
-
如果某个类别样本特别多,容易主导投票结果
-
需要采用加权投票或过采样 / 欠采样处理
八、应用场景:KNN 在现实世界的身影
别觉得 KNN 简单就没用,它早已经融入了我们生活的方方面面!
8.1 推荐系统:你可能也喜欢
你在视频平台看了《流浪地球》,平台马上推荐《星际穿越》------ 这背后就有 KNN 的功劳。
基于用户的协同过滤:找到和你口味最相似的 K 个用户,看他们还喜欢什么电影,再推荐给你。
基于物品的协同过滤:找到和《流浪地球》最相似的 K 部电影,直接推荐给你。
KNN 特别适合推荐系统,因为用户和物品的数量是动态增长的,KNN 可以无缝接纳新数据。
8.2 图像识别:手机怎么认出手写数字?
你在手机上手写,输入法能准确识别出来。KNN 是早期手写数字识别的常用算法。
具体做法:
-
将手写数字图片转化为 28×28 的像素矩阵
-
把 784 个像素值作为特征向量
-
计算待识别图片与训练集中所有图片的像素距离
-
找到 K 个最相似的手写数字样本
-
投票决定最终识别结果
虽然现在深度学习在图像识别领域占主导,但 KNN 在小样本场景下仍然表现出色。
6.3 医疗诊断:辅助医生判断病情
在医疗领域,KNN 可以作为医生的辅助决策工具:
肿瘤良恶性判断:输入肿瘤的大小、形状、边界清晰度、细胞形态等特征,KNN 会找到与当前病例最相似的 K 个历史病例。如果其中 5 个是恶性,2 个是良性,就辅助医生判断恶性可能性较大。
糖尿病预测:根据患者的年龄、BMI、血糖、血压等指标,匹配相似病例,预测患病风险。
当然,最终诊断还是要医生拍板,但 KNN 能帮助减少误诊率。
8.4 金融风控:信用卡盗刷怎么发现?
银行会记录你平时的消费习惯:比如每天花 200-500 元、在本地消费、用手机支付。
如果某天突然出现一次消费 5 万元、在国外、用 ATM 取款,KNN 会发现这个消费行为和你平时的邻居正常消费)差太远,就会触发盗刷预警。
这本质上是用 KNN 做异常检测:离群点就是异常行为。
8.5 文本分类:垃圾邮件过滤
在垃圾邮件过滤中,KNN 也能发挥作用:
-
将邮件内容转化为 TF-IDF 向量
-
使用余弦相似度计算邮件之间的相似性
-
找到 K 个最相似的邮件
-
如果大部分是垃圾邮件,就判定为垃圾邮件
九、进阶话题:KNN 的加速与改进
9.1 暴力搜索的问题
朴素 KNN 采用暴力搜索,每次预测都要计算与所有 N 个样本的距离,时间复杂度 O (N)。当 N 很大时(比如百万级),这会非常慢。
为了解决这个问题,研究者们提出了更高效的数据结构。
9.2 KD 树(KD-Tree)
KD 树是一种对 k 维空间中的实例点进行存储以便快速检索的树形数据结构。
构建过程:
-
选择方差最大的特征维度
-
取该维度的中位数作为分割点
-
递归划分左右子树,直到达到叶子节点
搜索过程:
-
从根节点开始,根据特征值逐层向下找到包含目标点的叶子节点
-
回溯检查邻近区域,看是否有更近的点
-
减少大量无效的距离计算
KD 树在低维数据(d<20)上效果很好,但高维数据下性能会下降。
9.3 球树(Ball Tree)
球树是为了解决 KD 树在高维数据下的问题而提出的:
核心思想:将数据空间划分为嵌套的超球体,而不是矩形区域。
优势:
-
对高维数据更高效
-
通过计算球心距离和半径来判断是否需要搜索子树
-
减少了很多不必要的距离计算
在 scikit-learn 中,你可以通过algorithm=kd\_tree或algorithm=ball\_tree来使用这些加速结构。
十、代码实战:用 scikit-learn 实现 KNN
现在让我们用 Python 和 scikit-learn 来实现一个完整的 KNN 示例。我们将使用经典的鸢尾花数据集。
10.1 完整代码实现
python
# 导入必要的库
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split, cross_val_score, GridSearchCV
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
# ----------------------
# 1. 数据加载与探索
# ----------------------
print("=" * 50)
print("1. 数据加载与探索")
print("=" * 50)
# 加载鸢尾花数据集
iris = load_iris()
X, y = iris.data, iris.target
print(f"数据集形状: {X.shape}")
print(f"特征名称: {iris.feature_names}")
print(f"类别名称: {iris.target_names}")
print(f"各类别样本数: {np.bincount(y)}")
# ----------------------
# 2. 数据预处理
# ----------------------
print("\n" + "=" * 50)
print("2. 数据预处理")
print("=" * 50)
# 划分训练集和测试集(80%训练,20%测试)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
print(f"训练集大小: {X_train.shape}")
print(f"测试集大小: {X_test.shape}")
# 特征标准化(对KNN非常重要!)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train) # 用训练集fit
X_test_scaled = scaler.transform(X_test) # 测试集只用transform
print("特征标准化完成!")
# ----------------------
# 3. 交叉验证选择最优K值
# ----------------------
print("\n" + "=" * 50)
print("3. 交叉验证选择最优K值")
print("=" * 50)
# 尝试K=1到30的奇数
k_values = range(1, 31, 2)
cv_scores = []
for k in k_values:
knn = KNeighborsClassifier(n_neighbors=k, n_jobs=-1)
# 5折交叉验证
scores = cross_val_score(knn, X_train_scaled, y_train, cv=5, scoring='accuracy')
cv_scores.append(scores.mean())
print(f"K={k:2d}: 平均准确率 = {scores.mean():.4f} (±{scores.std():.4f})")
# 找到最优K值
best_k = k_values[np.argmax(cv_scores)]
best_score = max(cv_scores)
print(f"\n最优K值: {best_k}, 最高交叉验证准确率: {best_score:.4f}")
# 绘制K值与准确率曲线
plt.figure(figsize=(10, 6))
plt.plot(k_values, cv_scores, marker='o', linestyle='--', color='b', linewidth=2)
plt.axvline(x=best_k, color='r', linestyle='--', label=f'最优K={best_k}')
plt.xlabel('K值', fontsize=12)
plt.ylabel('交叉验证准确率', fontsize=12)
plt.title('K值选择:交叉验证准确率', fontsize=14)
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()
# ----------------------
# 4. 使用最优K值训练模型
# ----------------------
print("\n" + "=" * 50)
print("4. 使用最优K值训练模型")
print("=" * 50)
# 使用最优K值创建模型,使用KD树加速
knn_best = KNeighborsClassifier(
n_neighbors=best_k,
weights='distance', # 距离加权
algorithm='kd_tree', # 使用KD树加速
n_jobs=-1
)
# 训练模型(KNN的训练就是存储数据,非常快!)
knn_best.fit(X_train_scaled, y_train)
print("模型训练完成!")
# ----------------------
# 5. 模型评估
# ----------------------
print("\n" + "=" * 50)
print("5. 模型评估")
print("=" * 50)
# 在测试集上预测
y_pred = knn_best.predict(X_test_scaled)
# 计算准确率
test_accuracy = accuracy_score(y_test, y_pred)
print(f"测试集准确率: {test_accuracy:.4f}")
# 详细分类报告
print("\n分类报告:")
print(classification_report(y_test, y_pred, target_names=iris.target_names))
# 混淆矩阵
print("\n混淆矩阵:")
print(confusion_matrix(y_test, y_pred))
# ----------------------
# 6. 网格搜索调参(更全面的调优)
# ----------------------
print("\n" + "=" * 50)
print("6. 网格搜索调参")
print("=" * 50)
# 定义参数网格
param_grid = {
'n_neighbors': range(1, 31, 2),
'weights': ['uniform', 'distance'],
'metric': ['euclidean', 'manhattan']
}
# 创建网格搜索对象
grid_search = GridSearchCV(
KNeighborsClassifier(),
param_grid,
cv=5,
scoring='accuracy',
n_jobs=-1,
verbose=1
)
# 执行网格搜索
grid_search.fit(X_train_scaled, y_train)
print(f"\n最佳参数: {grid_search.best_params_}")
print(f"最佳交叉验证准确率: {grid_search.best_score_:.4f}")
# 使用最佳参数的模型在测试集上评估
best_model = grid_search.best_estimator_
y_pred_best = best_model.predict(X_test_scaled)
print(f"测试集准确率(最佳参数): {accuracy_score(y_test, y_pred_best):.4f}")
# ----------------------
# 7. 预测新样本
# ----------------------
print("\n" + "=" * 50)
print("7. 预测新样本")
print("=" * 50)
# 创建一个新样本(假设的鸢尾花测量数据)
new_flower = np.array([[5.1, 3.5, 1.4, 0.2]]) # 类似山鸢尾
new_flower_scaled = scaler.transform(new_flower)
# 预测
prediction = best_model.predict(new_flower_scaled)
prediction_proba = best_model.predict_proba(new_flower_scaled)
print(f"新样本特征: {new_flower[0]}")
print(f"预测类别: {iris.target_names[prediction[0]]}")
print(f"各类别概率:")
for name, prob in zip(iris.target_names, prediction_proba[0]):
print(f" {name}: {prob:.4f}")
# 找到K个最近邻
distances, indices = best_model.kneighbors(new_flower_scaled)
print(f"\n最近的{best_model.n_neighbors}个邻居:")
for i, (idx, dist) in enumerate(zip(indices[0], distances[0])):
print(f" 邻居{i+1}: 距离={dist:.4f}, 类别={iris.target_names[y_train[idx]]}")
print("\n" + "=" * 50)
print("KNN实战完成!")
print("=" * 50)10.2 代码解释
让我们解释一下代码中的关键部分:
-
数据标准化 :这是 KNN 最重要的预处理步骤。我们使用
StandardScaler对特征进行 z-score 标准化,确保所有特征在相同的量纲上。 -
交叉验证选 K:我们尝试了 K=1 到 30 的奇数,用 5 折交叉验证评估每个 K 值的性能,选择准确率最高的 K 值。
-
加权 KNN :使用
weights=distance启用距离加权,让更近的邻居有更大的投票权重。 -
KD 树加速 :使用
algorithm=kd\_tree启用 KD 树结构,大幅提升预测速度。 -
网格搜索:除了 K 值,我们还搜索了权重方式和距离度量,找到最佳的参数组合。
-
可解释性:最后我们展示了如何查看一个预测样本的 K 个最近邻,这体现了 KNN 的可解释性优势。
十一、总结:KNN 的最佳实践
11.1 使用 KNN 的 Checklist
在使用 KNN 时,请确保你做了以下事情:
✅ 数据预处理
-
特征标准化 / 归一化(必做!)
-
处理缺失值
-
移除异常值
-
高维数据先降维(PCA 等)
✅ 参数调优
-
用交叉验证选择最优 K 值
-
尝试不同的距离度量
-
考虑使用加权 KNN
-
大数据集使用 KD 树 / 球树
✅ 适用场景判断
-
样本量适中(万级以内)
-
特征维度不高(<20 维)
-
需要可解释性
-
数据需要动态更新
11.2 最后的话
KNN 虽然简单,但它蕴含了机器学习最核心的思想:相似的事物具有相似的属性。它不仅是入门机器学习的绝佳起点,也是很多复杂算法的基础。
在深度学习大行其道的今天,KNN 依然在很多场景下发挥着不可替代的作用。掌握 KNN,你就掌握了一把解决很多实际问题的瑞士军刀。
记住,最好的算法不一定是最复杂的,而是最适合问题的那个。有时候,简单如 KNN,也能创造出色的效果!
参考资料:
-
Cover, T., & Hart, P. (1967). Nearest neighbor pattern classification. IEEE Transactions on Information Theory
-
Fix, E., & Hodges, J. L. (1951). Discriminatory analysis. Nonparametric discrimination: Consistency properties
-
scikit-learn 官方文档:Nearest Neighbors
-
李航。统计学习方法