前言
在 Vue3.2 的版本里面还通过位运算优化动态依赖收集的性能,那么具体是怎么做的呢?首先我们来看看原来为什么会存在性能问题,我们回顾一下第5篇文章讲解 Vue3 响应式原理的时候,在收集依赖的时候有以下一段代码。
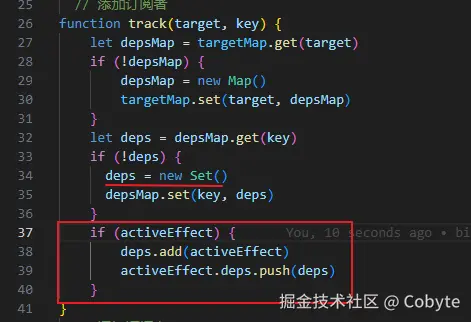
首先是只要存在 activeEffect 变量,我们就会往 deps 中添加依赖,如果存在重复的依赖,会利用 Set 数据的特性来去重。目前这种依赖管理方式在高频更新或深层递归场景下存在性能瓶颈。具体表现为副作用函数(effect)的依赖可能随条件分支动态变化。例如:
js
const state = reactive({ a: '掘金签约作者', b: 'Cobyte', flag: true })
effect(() => {
if (state.flag) {
// 依赖 state.a
console.log(state.a);
} else {
// 依赖 state.b
console.log(state.b);
}
});
state.flag = false
state.a = '小前端'我们运行上述例子,结果如下:
掘金签约作者
Cobyte
Cobyte从上述测试结果我们可以看到当设置 state.flag 为 true 时,打印了 Cobyte,这是正确的,但当改变state.a 值时,也打印了 Cobyte,其实当 state.flag 为 true 时,该副作用就跟 state.a 没有关系了,因为不管 state.a 的值怎么变,副作用的打印结果都是一样的,所以此时当 state.a 改变就触发副作用更新的行为就是浪费性能。
所以我们目前的实现存在以下问题,当 state.flag 变化时,依赖需从 state.a 切换到 state.b 时无法自动清理过期依赖,导致冗余触发而引发性能瓶颈。
对此 Vue3.2 创新性地引入 位运算(Bitwise Operations)优化依赖收集,解决了动态依赖切换导致的冗余依赖问题,从而大幅提升了响应式系统的性能。本文将从设计背景、实现原理、性能优势等方面展开分析,揭示位运算在这一场景下的核心价值。
此外对位运算还不熟的同学,可以先复习一下位运算相关知识。
为什么要使用位运算来设计依赖优化?
我们在前言的例子中讲到当 state.flag 变化时,依赖需从 state.a 切换到 state.b,传统 Set 数据结构无法自动清理过期依赖,导致冗余依赖。那么怎么实现自动清理过期的依赖呢?
普通实现方案
原来的数据结构如下:
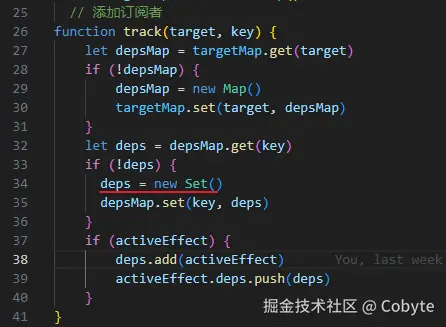
那么实现这个清除失效的依赖,按我们普通的实现方案可以这样设计,设计一个记录该依赖在 之前的层级 是否被追踪的变量 wasSet = new Set();再设计一个记录该依赖在 当前层级 是否被追踪的变量 newSet = new Set();这样我们在一轮循环中判断是否记录新的依赖的时候,先往变量 newSet 中添加该依赖,再从 wasSet 变量中判断是否已经存在该依赖,如果已经存在,那么就不再记录,如果不存在,那么就需要往原来记录依赖的变量 deps 中添加新的依赖。这样在一轮循环的最后,再去判断该依赖如果只存在 wasSet 变量中,而没有在 newSet 变量中时,则说明该依赖需要从 deps 变量中清除掉了,这样将来该依赖发生变化都不会响应式到渲染函数的重新执行。那么 wasSet 中的数据怎么来呢?可以在初始化的时候从 deps 中进行赋值。
我们上面通过文字描述大概讲了一遍普通方案的实现,那么我现在通过伪代码再还原展示一偏。
状态记录相关变量:
wasSet: Set<Dep>:记录上一轮执行中所有被追踪的依赖。newSet: Set<Dep>:记录当前轮次执行中所有被追踪的依赖。deps: Dep[]:实际存储依赖的集合。
初始化阶段:
ini
wasSet = new Set(deps); // 初始化为上一轮的依赖
newSet = new Set(); 依赖收集阶段:
scss
if (!newSet.has(dep)) {
newSet.add(dep);
if (!wasSet.has(dep)) {
deps.push(dep); // 新增依赖
}
} 依赖清理阶段:
scss
for (const dep of wasSet) {
if (!newSet.has(dep)) {
deps.splice(deps.indexOf(dep), 1); // 移除失效依赖
}
}
wasSet = newSet; // 更新历史状态从上述伪代码可以清晰看出通过比对 wasSet 和 newSet 的差异,移除不再被使用的依赖,从而实现了条件分支的支持。
但这种普通方案存在以下性能瓶颈:
-
内存开销:
- 需维护多个
Set实例(wasSet、newSet),存储大量依赖时内存占用高。 - 每次递归层级变化需复制依赖集合(如
wasSet = new Set(deps))。
- 需维护多个
-
操作效率:
- 集合操作 :
has、add、delete的时间复杂度为 O(1),但哈希表操作仍存在性能损耗(如哈希碰撞)。 - 清理阶段 :遍历
wasSet并检查newSet的时间复杂度为 O(n²)。
- 集合操作 :
-
递归层级管理:
- 深层递归时需为每层维护独立的
Set,内存和计算开销指数级增长。
- 深层递归时需为每层维护独立的
所以 Vue3 并没有采用这种实现方式,那么接下来让我们继续探讨 Vue3 的实现方案吧。
位运算优化方案(Vue3 实现)
在 Vue3 中则巧妙地创建一个兼具 依赖存储 和 追踪状态标记 的复合数据结构的变量。设计如下:
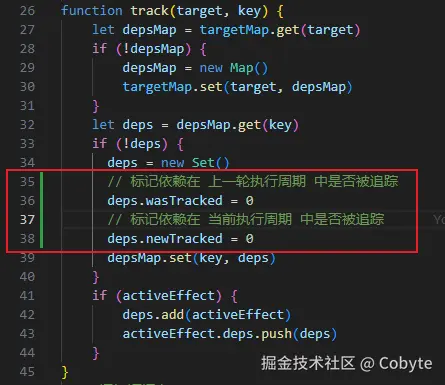
通过扩展 Set 而非创建全新数据结构,复用 Set 的高效存储,仅添加 wasTracked 和 newTracked 两个整数字段,就创建一个兼具 依赖存储 和 追踪状态标记 的复合数据结构了。具体 wasTracked 和 newTracked 两个字段的作用是:
wasTracked:记录该依赖在 之前的层级 是否被追踪。newTracked:记录该依赖在 当前层级 是否被追踪。
wasTracked 和 newTracked 的值都是一个二进制数字,例如:若某依赖在之前的层级(如父组件渲染)中被访问过,wasTracked 对应的位会被标记;newTracked 则是在当前渲染中如果被访问了,对应的位也会被标记。
那么为什么要使用位运算来设计呢?我们从传统的权限管理的痛点说起,因为上述的依赖优化管理机制与权限系统的位掩码设计异曲同工。
假设需要为一个用户管理系统设计权限控制,包含以下权限:
- 读(R) :
0b001(二进制) → 1(十进制) - 写(W) :
0b010→ 2 - 执行(X) :
0b100→ 4
传统实现方式:
arduino
const userPermissions = {
read: true,
write: false,
execute: true
};
// 检查是否有读权限
if (userPermissions.read) { /* ... */ }这种方案存在以下问题:
- 存储冗余:每个权限需独立布尔字段,内存占用高。
- 组合权限复杂:判断用户是否同时有读和执行权限需多次检查。
- 扩展性差 :新增权限(如
admin)需修改数据结构。
使用位运算设计权限管理系统:
通过 位掩码(Bitmask) 将权限编码为单个整数:
arduino
// 权限定义
const PERMISSIONS = {
READ: 0b001, // 1
WRITE: 0b010, // 2
EXECUTE: 0b100 // 4
};用户初始权限:
ini
// 用户权限(初始为 0)
let userPermissions = 0;添加读和执行权限:
arduino
// 添加读和执行权限
userPermissions |= PERMISSIONS.READ; // 0b001 → 1
userPermissions |= PERMISSIONS.EXECUTE; // 0b101 → 5检查是否有写权限:
ini
const hasWrite = (userPermissions & PERMISSIONS.WRITE) > 0; // false检查是否有读和执行权限:
vbscript
const hasReadAndExecute =
(userPermissions & (PERMISSIONS.READ | PERMISSIONS.EXECUTE))
=== (PERMISSIONS.READ | PERMISSIONS.EXECUTE); // true优势分析
(1) 内存高效
- 传统方式:每个权限占用一个布尔值(通常 4 字节)。
- 位运算 :所有权限压缩为单个整数(4 字节),内存占用减少 75% 。
(2) 操作快速
- 添加权限 :
userPermissions |= PERMISSIONS.WRITE(O(1))。 - 移除权限 :
userPermissions &= ~PERMISSIONS.WRITE(O(1))。 - 检查权限:按位与操作(O(1))。
(3) 组合权限灵活
ini
// 检查是否同时有读和写权限
const required = PERMISSIONS.READ | PERMISSIONS.WRITE;
const hasAll = (userPermissions & required) === required;那么根据上述权限系统的实现的启发,我们就可以设计如果当前依赖层级为 1,那么历史层级的追踪状态变量 wasTracked 就会被设置为 0b1,当前层级为 2 那么 wasTracked 就会被设置为 0b10,同样地 3,4 ... 层就会被设置为 0b100、0b1000,如果一个变量在1、2、3、4层都被引用,那么 wasTracked 就会被设置为:0b1111。同样地当前层级的追踪状态 newTracked 也是如此设计。
同样地,层级变量也可以使用二进制表示,比如,1层为:0b1;2层为:0b10;3层为:0b100。这样标记和判断等相关操作都可以通过位运算进行。比如当前层级为2,那么 层级变量 = 0b10,那么标记添加则是 wasTracked = wasTracked | 0b10;而判断当前历史层级是否已被标记则是 has = wasTracked & 0b10。
位运算的原子性操作(如 |=、&)速度远超传统 Set 的操作(如遍历、过滤),且位运算具有极致的性能优势,这就是为什么使用为什么要使用位运算来设计依赖优化。
组件嵌套的 effect 实现原理
我们前面讲到多层嵌套的 effect,会存在内存占用高操作缓慢的缺点。而我们前面实现的 Vue3 响应式源码是还没实现嵌套 effect 的,所以我们先要实现嵌套 effect。例如下面的例子:
js
window.state = reactive({ parent: 'parent', child: 'child' })
effect(() => {
effect(() => {
console.log(`我是子组件:${state.child}`)
})
console.log(`我是父组件:${state.parent}`)
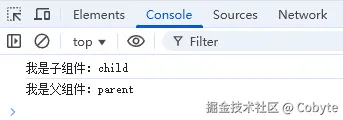
})执行结果如下:
我们给 state.child 重新赋值:
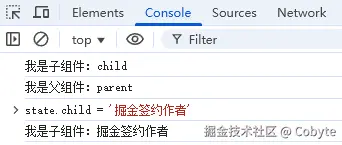
这时子组件的 effect 执行了,这是正常的。
接著我们给 state.parent 重新赋值:
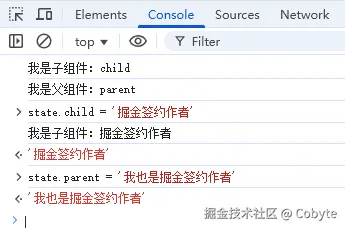
这时我们发现父组件的 effect 不执行了。这是为什么呢?我们来观察一下我们之前实现的 ReactiveEffect 类:
js
class ReactiveEffect {
deps = []
constructor(fn) {
this._fn = fn
}
run () {
activeEffect = this
this._fn()
activeEffect = null
}
stop () {
this.deps.forEach(dep => dep.delete(this))
}
} 我们知道 activeEffect 变量是唯一的,当嵌套之后,子组件执行完之后,activeEffect 将被设置了 null,这时父组件如果还有响应式数据需要收集的时候,由于 activeEffect 为 null 而会导致父组件的响应式数据的依赖收集不到。
为了解决这个问题,Vue3 底层设置了一个副作用函数栈变量 effectStack,我们要确保 activeEffect 始终指向当前正在运行的响应式副作用 effect。实现代码如下:
js
// 用于管理嵌套 effect 的调用栈
const effectStack = []
class ReactiveEffect {
// 存储所有包含本 effect 的依赖集合(Set)
// 用于实现 stop 功能时快速清理依赖
deps = []
constructor(fn) {
// 包装的副作用函数(开发者传入的原始函数)
this._fn = fn
}
// 执行副作用函数,并触发依赖收集
run () {
// 这里为什么要用try...finally呢?比如如果_fn中有错误,finally块仍然会执行,保证栈的平衡。
try {
// 1. 设置当前激活的 effect 为自身
activeEffect = this;
// 2. 压入 effect 调用栈(处理嵌套 effect 的关键)
effectStack.push(this);
// 3. 执行原始函数,触发响应式属性的 getter,进行依赖收集
return this._fn(); // 返回函数执行结果(支持 computed 等场景)
} finally {
// 4. 无论执行是否抛出异常,确保以下清理逻辑一定执行
effectStack.pop(); // 当前 effect 出栈
// 5. 恢复 activeEffect 为上一个 effect(栈顶元素)或 undefined
activeEffect = effectStack.length > 0 ? effectStack[effectStack.length - 1] : undefined;
}
}
// 停止当前 effect 的响应式追踪
stop () {
// 遍历所有关联的依赖集合,从中删除本 effect
this.deps.forEach(dep => dep.delete(this))
}
} 主要的实现思路也很简单,就是在执行原始函数之前,先把当前的响应式副作用压入 effectStack 调用栈,通过使用 try...finally 确保无论 this._fn() 是否抛出异常,effectStack 都会被正确弹出,activeEffect 会被恢复为上一个响应式副作用 effect 或 undefined。这样通过维护 effectStack,确保嵌套的响应式副作用 effect 的执行顺序正确,activeEffect 变量始终指向当前正在运行的响应式副作用 effect。
我们再来看看迭代后的执行结果:
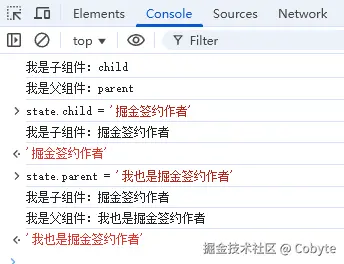
我们可以看到当父组件的响应式变量 parent 被改变后,相关的嵌套代码都被执行了。
到此,我们就实现了嵌套 effect。
依赖标记流程
初始化依赖的追踪状态标记
初始化依赖的追踪状态标记的核心逻辑就是在副作用函数执行前,记录所有 已有依赖 的追踪状态,即某个依赖在 上一轮执行 中被追踪过,其对应的位会被标记到 wasTracked 中。具体就是将每个依赖的 wasTracked 字段的 当前层级对应位 设为 1。我们可以设置一个全局变量 effectTrackDepth 来表示当前副作用执行的 递归深度,也就是所谓层级,初始为 0,每递归一次就增加 1。在每一轮的副作用函数执行前,将全局递归深度加 1,表示进入新一层级,执行完副作用函数后,将全局递归深度减 1,表示返回到上一层级的执行环境。
然后通过位运算 1 << effectTrackDepth 生成一个二进制掩码,也就是 第 effectTrackDepth 位为 1 ,其余位为 0。例如,若 effectTrackDepth = 2,则掩码为 0b100(十进制 2)。这样每个递归层级 effectTrackDepth 对应独立的二进制位,避免嵌套 effect 的依赖状态相互干扰。最后通过按位或操作(|),将 wasTracked 的对应二进制位设为 1,其他位保持不变。
具体代码实现如下:
diff
// 用于管理嵌套 effect 的调用栈
const effectStack = []
+ // 当前副作用执行的递归深度
+ let effectTrackDepth = 0
class ReactiveEffect {
// 存储所有包含本 effect 的依赖集合(Set)
// 用于实现 stop 功能时快速清理依赖
deps = []
constructor(fn) {
// 包装的副作用函数(开发者传入的原始函数)
this._fn = fn
}
// 执行副作用函数,并触发依赖收集
run () {
// 这里为什么要用try...finally呢?比如如果_fn中有错误,finally块仍然会执行,保证栈的平衡。
try {
// 1. 设置当前激活的 effect 为自身
activeEffect = this;
// 2. 压入 effect 调用栈(处理嵌套 effect 的关键)
effectStack.push(this);
+ // 将全局递归深度加 1,表示进入新一层级
+ effectTrackDepth++;
+ // 初始化标记
+ this.initDepMarkers();
// 3. 执行原始函数,触发响应式属性的 getter,进行依赖收集
return this._fn(); // 返回函数执行结果(支持 computed 等场景)
} finally {
+ // 将全局递归深度减 1,表示返回到上一层级的执行环境
+ effectTrackDepth--;
// 4. 无论执行是否抛出异常,确保以下清理逻辑一定执行
effectStack.pop(); // 当前 effect 出栈
// 5. 恢复 activeEffect 为上一个 effect(栈顶元素)或 undefined
activeEffect = effectStack.length > 0 ? effectStack[effectStack.length - 1] : undefined;
}
}
// 停止当前 effect 的响应式追踪
stop () {
// 遍历所有关联的依赖集合,从中删除本 effect
this.deps.forEach(dep => dep.delete(this))
}
+ // 初始化依赖的追踪状态标记
+ initDepMarkers() {
+ const { deps } = this
+ if (deps.length) {
+ for (let i = 0; i < deps.length; i++) {
+ // 若某个依赖在 上一轮执行 中被追踪过,其对应的位会被标记到 wasTracked 中
+ deps[i].wasTracked = deps[i].wasTracked | 1 << effectTrackDepth
+ }
+ }
+ }
} 小结一下:当副作用函数 effect 执行时,会进入不同的递归层级,每个层级对应一个位。在初始化时,会通过 initDepMarkers 方法设置对应依赖的 wasTracked 属性的位,表示上一轮这个依赖是否被跟踪。
通过位运算判断是否收集依赖
我们在之前的依赖收集的判断逻辑是这样的,判断全局变量 activeEffect 是否存在,存在就进行收集, 那么现在我们要判断当前依赖的当前层级是否标记该依赖为已追踪,也就是 deps.newTracked 的对应层级 (1 << effectTrackDepth) 是否为 1。这就要通过与运算(&)来判断。我们通过封装一个函数来实现这个功能,代码如下:
js
function newTracked(dep) {
return (dep.newTracked & (1 << effectTrackDepth)) !== 0;
}若当前层级未标记该依赖为已追踪(!newTracked(dep)),则需要将当前依赖 newTracked 设置为当前层级 (1 << effectTrackDepth) ,也就是标记为 1。我们通过封装一个函数来实现这个功能,代码如下:
js
function setNewTracked(dep) {
dep.newTracked |= (1 << effectTrackDepth); // 按位或操作
}最后我们还要检查依赖的 wasTracked 字段的当前层级(1 << effectTrackDepth) 对应 是否为 1(即是否在上一轮执行中被追踪过)。我们通过封装一个函数来实现这个功能,代码如下:
js
function wasTracked(dep) {
return (dep.wasTracked & (1 << effectTrackDepth)) !== 0;
}整体代码迭代如下:
diff
function track(target, key) {
let depsMap = targetMap.get(target)
if (!depsMap) {
depsMap = new Map()
targetMap.set(target, depsMap)
}
let deps = depsMap.get(key)
if (!deps) {
deps = new Set()
// 标记依赖在 上一轮执行周期 中是否被追踪
deps.wasTracked = 0
// 标记依赖在 当前执行周期 中是否被追踪
deps.newTracked = 0
depsMap.set(key, deps)
}
- if (activeEffect) {
- deps.add(activeEffect)
- activeEffect.deps.push(deps)
- }
+ trackEffects(deps)
}
+ function trackEffects(dep) {
+ let shouldTrack = false
+ if (!newTracked(dep)) {
+ setNewTracked(dep)
+ shouldTrack = !wasTracked(dep)
+ }
+ if (shouldTrack) {
+ dep.add(activeEffect)
+ activeEffect.deps.push(dep)
+ }
+ }
+ function newTracked(dep) {
+ return (dep.newTracked & (1 << effectTrackDepth)) !== 0;
+ }
+ function setNewTracked(dep) {
+ dep.newTracked |= (1 << effectTrackDepth); // 按位或操作
+ }
+ function wasTracked(dep) {
+ return (dep.wasTracked & (1 << effectTrackDepth)) !== 0;
+ }在执行 effect 函数的过程中,当访问响应式属性时,会调用 track 函数,进而调用 trackEffects,设置 newTracked 的位,表示当前层级这个 dep 被跟踪了。
接着我们测试一下我们写的代码,测试代码如下:
js
window.state = reactive({ flag: false, a: 'parent', b: 'child' })
effect(() => {
if (state.flag) {
console.log(`条件一:${state.a}`);
} else {
console.log(`条件二:${state.b}`);
}
});我们运行上面的测试代码,结果输出:条件二:child。这是正确的输出结果。说明我们上述的迭代代码是正确的。
我们现在改变 flag 的值, state.flag = true,结果输出:条件一:parent。这也是正确的输出结果。这时我们再改变 b 的值, state.b = '掘金签约作者',结果输出:条件一:parent,这个结果不是我们期待的,因为 b 属性我们已经不再使用了,b 属性值的改变不应该再触发更新才对。所以我们还要实现最后一个功能,通过位运算实现动态依赖的精准管理。
实现动态依赖精准管理
我们通过上文知道当effect执行时,会进入不同的递归层级,每个层级对应一个位。在初始化时,会通过initDepMarkers方法设置wasTracked的位,表示上一轮这个dep是否被跟踪。然后在执行effect函数的过程中,当访问响应式属性时,会调用track函数,进而调用trackEffects,设置newTracked的位,表示当前层级这个dep被跟踪了。
我们现在需要做的就是比较这两个标记,如果一个dep在之前被跟踪(wasTracked为真),但在当前没有被跟踪(newTracked为假),说明这个dep在当前层级不再被需要,因此需要从dep的集合中移除这个effect。这样我们就可以实现清理那些不再被依赖的effect,防止内存泄漏和无效的触发。
代码迭代如下:
diff
// 用于管理嵌套 effect 的调用栈
const effectStack = []
let effectTrackDepth = 0
class ReactiveEffect {
// 存储所有包含本 effect 的依赖集合(Set)
// 用于实现 stop 功能时快速清理依赖
deps = []
constructor(fn) {
// 包装的副作用函数(开发者传入的原始函数)
this._fn = fn
}
// 执行副作用函数,并触发依赖收集
run () {
// 这里为什么要用try...finally呢?比如如果_fn中有错误,finally块仍然会执行,保证栈的平衡。
try {
// 1. 设置当前激活的 effect 为自身
activeEffect = this;
// 2. 压入 effect 调用栈(处理嵌套 effect 的关键)
effectStack.push(this);
//
effectTrackDepth++;
// 初始化标记
this.initDepMarkers();
// 3. 执行原始函数,触发响应式属性的 getter,进行依赖收集
return this._fn(); // 返回函数执行结果(支持 computed 等场景)
} finally {
+ this.finalizeDepMarkers();
effectTrackDepth--;
// 4. 无论执行是否抛出异常,确保以下清理逻辑一定执行
effectStack.pop(); // 当前 effect 出栈
// 5. 恢复 activeEffect 为上一个 effect(栈顶元素)或 undefined
activeEffect = effectStack.length > 0 ? effectStack[effectStack.length - 1] : undefined;
}
}
// 停止当前 effect 的响应式追踪
stop () {
// 遍历所有关联的依赖集合,从中删除本 effect
this.deps.forEach(dep => dep.delete(this))
}
// 初始化依赖的追踪状态标记
initDepMarkers() {
const { deps } = this
if (deps.length) {
for (let i = 0; i < deps.length; i++) {
// 若某个依赖在 上一轮执行 中被追踪过,其对应的位会被标记到 wasTracked 中
deps[i].wasTracked = deps[i].wasTracked | 1 << effectTrackDepth
}
}
}
+ // 清理无效依赖 并 优化依赖集合
+ finalizeDepMarkers() {
+ const { deps } = this
+ if (deps.length) {
+ for (let i = 0; i < deps.length; i++) {
+ const dep = deps[i]
+ // 根据依赖的跟踪状态,清理不再需要的依赖
+ if (wasTracked(dep) && !newTracked(dep)) {
+ // 移除当前 effect 对该 dep 的依赖
+ dep.delete(this)
+ }
+ }
+ }
+ }
} 我们再运行上面的测试代码,结果输出:条件二:child。我们接着改变 flag 的值, state.flag = true,结果输出:条件一:parent。这也是正确的输出结果。这时我们再改变 b 的值, state.b = '掘金签约作者',结果输出:条件一:parent,这个结果还是不是我们期待的,为什么呢?
主要是因为现在只要我们的依赖的层级只要被标记上了,就一直是这个状态了。假设当前层级为 2,上述测试代码中需要删除的 b 属性依赖的层级初始标记状态为:wasTracked = 0b100, newTracked = 0b100,那么后续 b 属性的层级状态就一直是这个状态了,当判断是否需要删除的时候,我们需要判断 wasTracked 是否为 true,因为已经被标记过了,所以为 true,同样判断 newTracked 是否为 false 时,因为已经被标记过了,所以为 true。
所以在退出当前层级前,清除该层级对应的位掩码,确保下一层级的标记从干净状态开始。具体代码实现如下:
diff
class ReactiveEffect {
// ...
// 清理无效依赖 并 优化依赖集合
finalizeDepMarkers() {
const { deps } = this
if (deps.length) {
for (let i = 0; i < deps.length; i++) {
const dep = deps[i]
// 根据依赖的跟踪状态,清理不再需要的依赖
if (wasTracked(dep) && !newTracked(dep)) {
// 移除当前 effect 对该 dep 的依赖
dep.delete(this)
}
+ // 清除该层级对应的位掩码
+ const trackOpBit = 1 << effectTrackDepth
+ dep.wasTracked = dep.wasTracked & ~trackOpBit
+ dep.newTracked = dep.newTracked & ~trackOpBit
}
}
}
}总的来说就是当 effect 执行完成后,通过比较 wasTracked 和 newTracked 的位掩码,可以快速确定哪些依赖在本次执行中没有被访问,从而进行清理。同时退出当前层级前,清除该层级对应的位掩码,确保下一层级的标记从干净状态开始。
递归层级限制30层的设计原因
Vue3 底层选择 30 层作为最大递归层级,因为 V8 引擎对 31/32 位整数直接存储于指针,无需堆分配,读写速度提升 10 倍,30 层限制确保位运算结果始终为 SMI,避免退化为堆内存对象导致性能退化,所以选择 30 层是为了确保现代JS引擎在所有平台上都能使用 SMI(小整数)优化。当超出 30 层时,回退到全量清理,保障极端场景稳定性。
代码优化迭代如下:
diff
+ const maxMarkerBits = 30
class ReactiveEffect {
// ...
run () {
try {
// 1. 设置当前激活的 effect 为自身
activeEffect = this;
// 2. 压入 effect 调用栈(处理嵌套 effect 的关键)
effectStack.push(this);
effectTrackDepth++;
- this.initDepMarkers()
+ if (effectTrackDepth <= maxMarkerBits) {
+ this.initDepMarkers()
+ } else {
+ // 当递归深度超过30层时,回退到完全清理模式
+ this.cleanup()
+ }
// 初始化标记
this.initDepMarkers();
// 3. 执行原始函数,触发响应式属性的 getter,进行依赖收集
return this._fn(); // 返回函数执行结果(支持 computed 等场景)
} finally {
- this.finalizeDepMarkers()
+ if (effectTrackDepth <= maxMarkerBits) {
+ this.finalizeDepMarkers()
+ }
effectTrackDepth--;
// 4. 无论执行是否抛出异常,确保以下清理逻辑一定执行
effectStack.pop(); // 当前 effect 出栈
// 5. 恢复 activeEffect 为上一个 effect(栈顶元素)或 undefined
activeEffect = effectStack.length > 0 ? effectStack[effectStack.length - 1] : undefined;
}
}
// ...
+ // 完全清理模式
+ cleanup() {
+ const { deps } = this
+ if (deps.length) {
+ for (let i = 0; i < deps.length; i++) {
+ deps[i].delete(this)
+ }
+ deps.length = 0
+ }
+ }
} SMI(Small Integer)优化的核心原理
我们上面提到 Vue3 底层选择 30 层作为最大递归层级,是为了确保现代JS引擎在所有平台上都能使用 SMI(小整数)优化。
首先,我们得看一下 SMI 的概念。SMI 代表 Small Integer,是 V8 引擎对特定范围内整数的优化存储方式。在 V8 引擎中,SMI(Small Integer)优化 的核心原理是通过 指针标签(Pointer Tagging) 技术,将小整数直接嵌入指针值中,而非存储在堆内存中。以下是其性能优势的详细解析:
指针的结构
-
指针的本质 :
指针是一个内存地址,通常用 32 位(32 位系统)或 64 位(64 位系统)表示。
-
标签位(Tagging Bits) :
V8 利用指针的低位(如最低 1~2 位)作为 类型标记,例如:
- 表示该指针是一个 SMI(直接存储整数值)。
- 表示该指针是一个 堆对象地址(需要解引用获取实际值)。
SMI 的存储方式
直接嵌入指针 :
V8 将小整数的二进制值 左移 1 位(腾出最低位作为标签),然后存入指针。
堆分配的数字 :
若数字超出 SMI 范围(如大整数、浮点数),V8 会在堆内存中分配一个 Number 对象,并将指针指向该对象。
内存访问开销
-
SMI(指针存储) :
值直接存储在指针中,读取时 无需访问堆内存,直接解析指针值即可。
-
堆分配的数字 :
需要 两次内存访问:
- 读取指针地址。
- 根据指针地址访问堆内存中的
Number对象。
内存分配开销
- SMI :
无堆内存分配和释放操作,避免 内存管理开销(如垃圾回收)。 - 堆分配的数字 :
需调用内存分配器,可能触发 垃圾回收(GC) ,增加延迟。
CPU 缓存友好性
- SMI :
数值直接存储在指针中,与其他指针数据一起被 CPU 缓存,缓存命中率高。 - 堆分配的数字 :
Number对象分散在堆内存中,缓存局部性差,缓存未命中率高。
指令优化
SMI 操作 :
通过简单的位运算(如移位、掩码)即可完成数值解析,CPU 指令周期短。
堆分配数字操作 :
需要额外的解引用指令和类型检查,指令周期长。
设计哲学
空间换时间
- SMI:牺牲 1 位指针空间(用于标签),换取极致性能。
- 堆分配:以内存和速度为代价,支持更大数值范围。
高频场景优化
- 现实场景 :
大多数 JavaScript 程序中的整数是小范围的(如循环计数器、数组索引),SMI 覆盖了 99% 的用例。 - 收益最大化 :
对高频操作(如依赖收集、循环计数)进行极致优化,显著提升整体性能。
综上所述,V8 通过 指针标签技术 将小整数(SMI)直接存储在指针中,实现了以下优势:
- 零内存分配:避免堆操作和垃圾回收开销。
- 直接访问:无需解引用,减少内存访问次数。
- CPU 友好:位运算指令快,缓存命中率高。
这些优化使得 SMI 的读写速度比堆分配的数字快 10 倍以上,成为 JavaScript 高性能引擎的核心技术之一。Vue3 的依赖收集系统正是基于此特性,通过位运算和层级限制,实现了高效的响应式更新。
总结
最后我们来总结一下,Vue3 通过位运算设计实现以下响应式系统的优化:
- 层级化状态标记:通过位掩码精准管理递归层级依赖。
- 动态清理机制:按位比对移除失效依赖,避免冗余触发。
- 性能与内存平衡:SMI 优化保障操作速度,30 层限制避免边界问题。
这一机制在复杂组件、高频更新及深层嵌套场景下表现卓越,是 Vue3 响应式系统的核心创新之一。
我是程序员Cobyte,现在已转向研究 AI Agent,欢迎添加 v: icobyte,学习交流 AI Agent 应用开发。