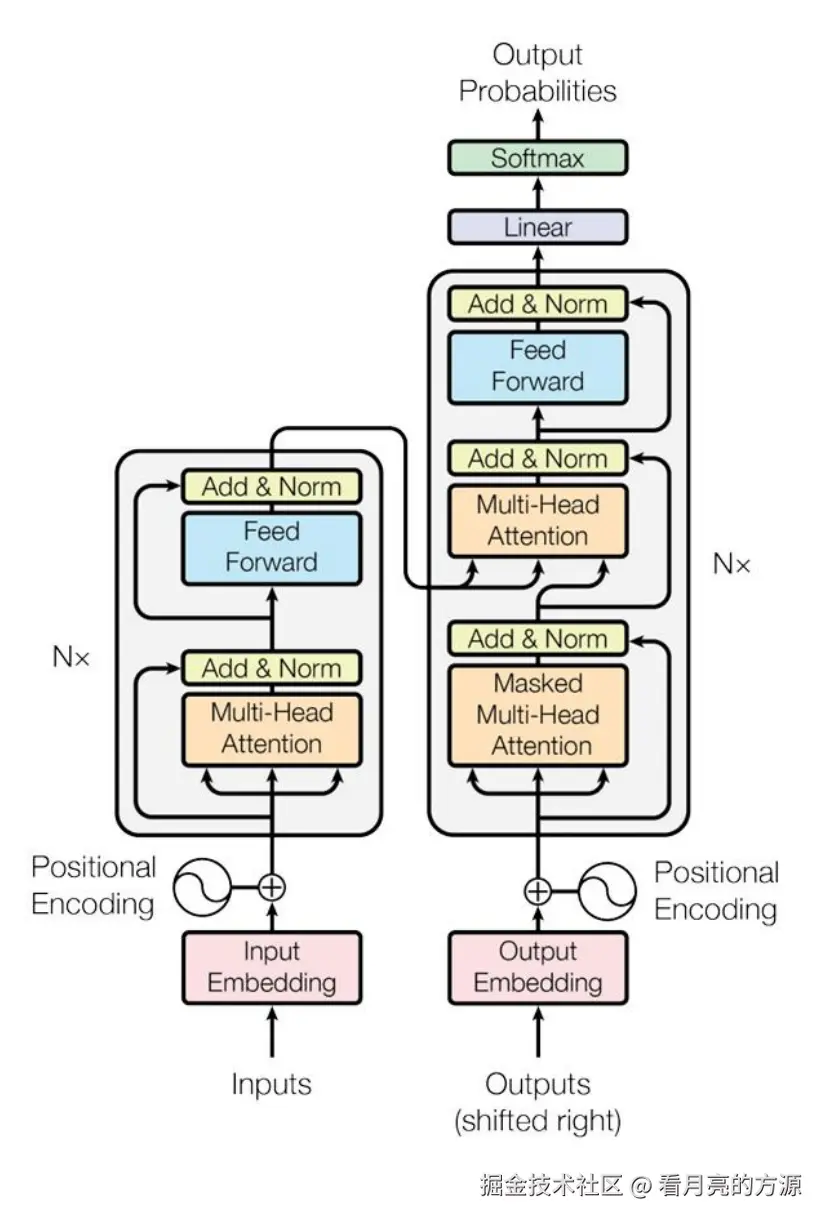
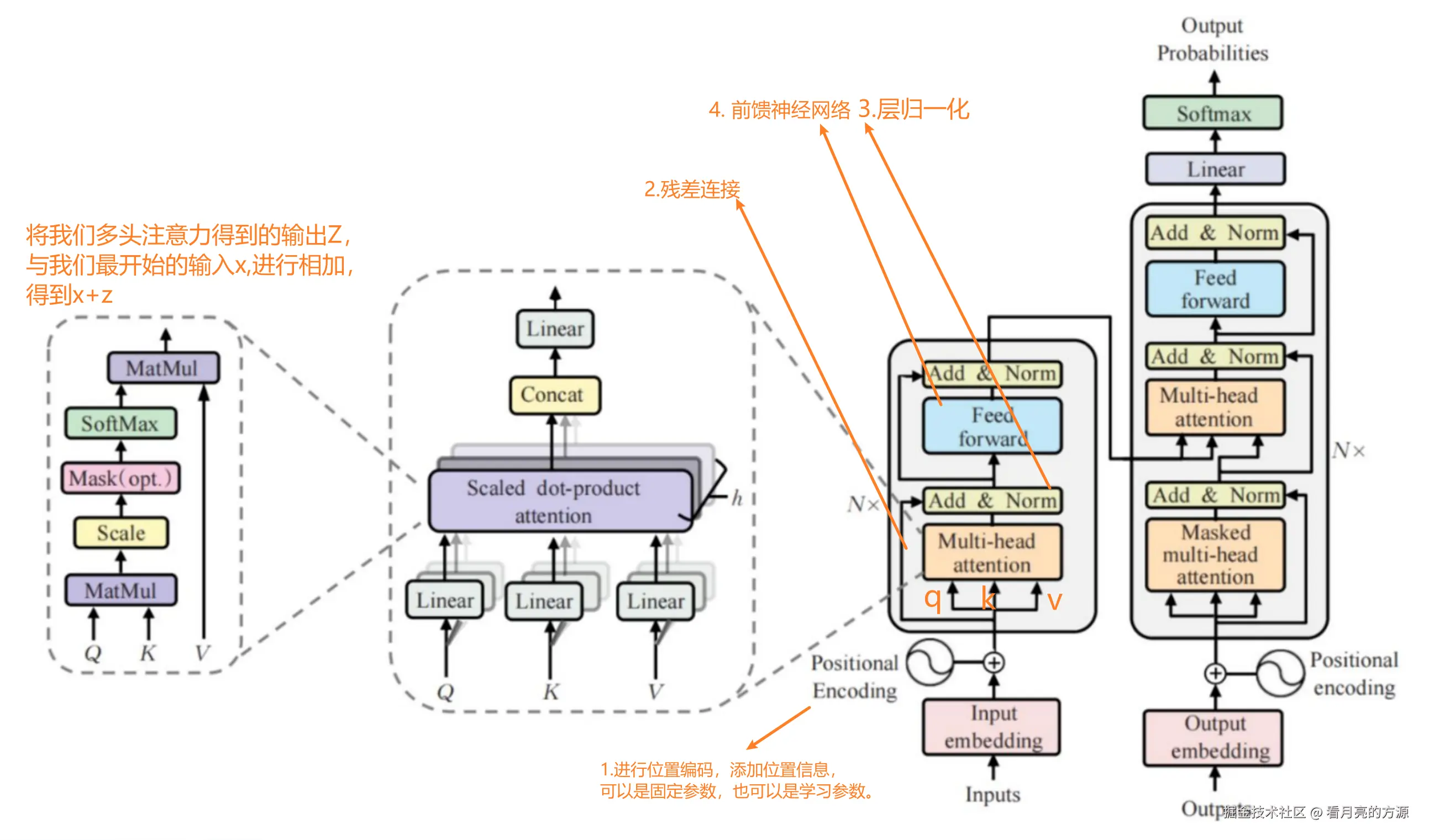
1. 架构图
Transformer的架构图如下所示,先了解结构下面一一进行讲解。
1.1 输入的嵌入
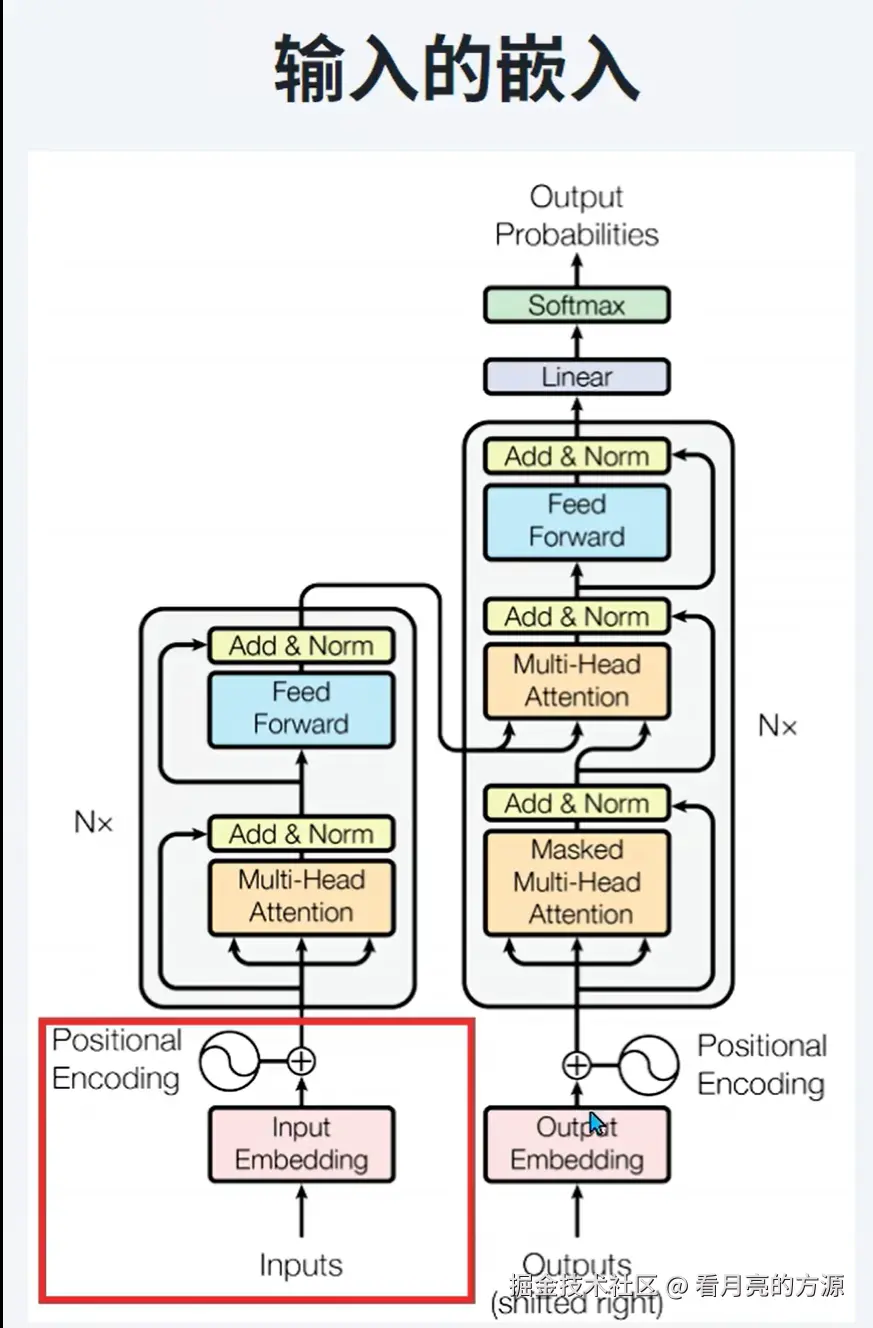
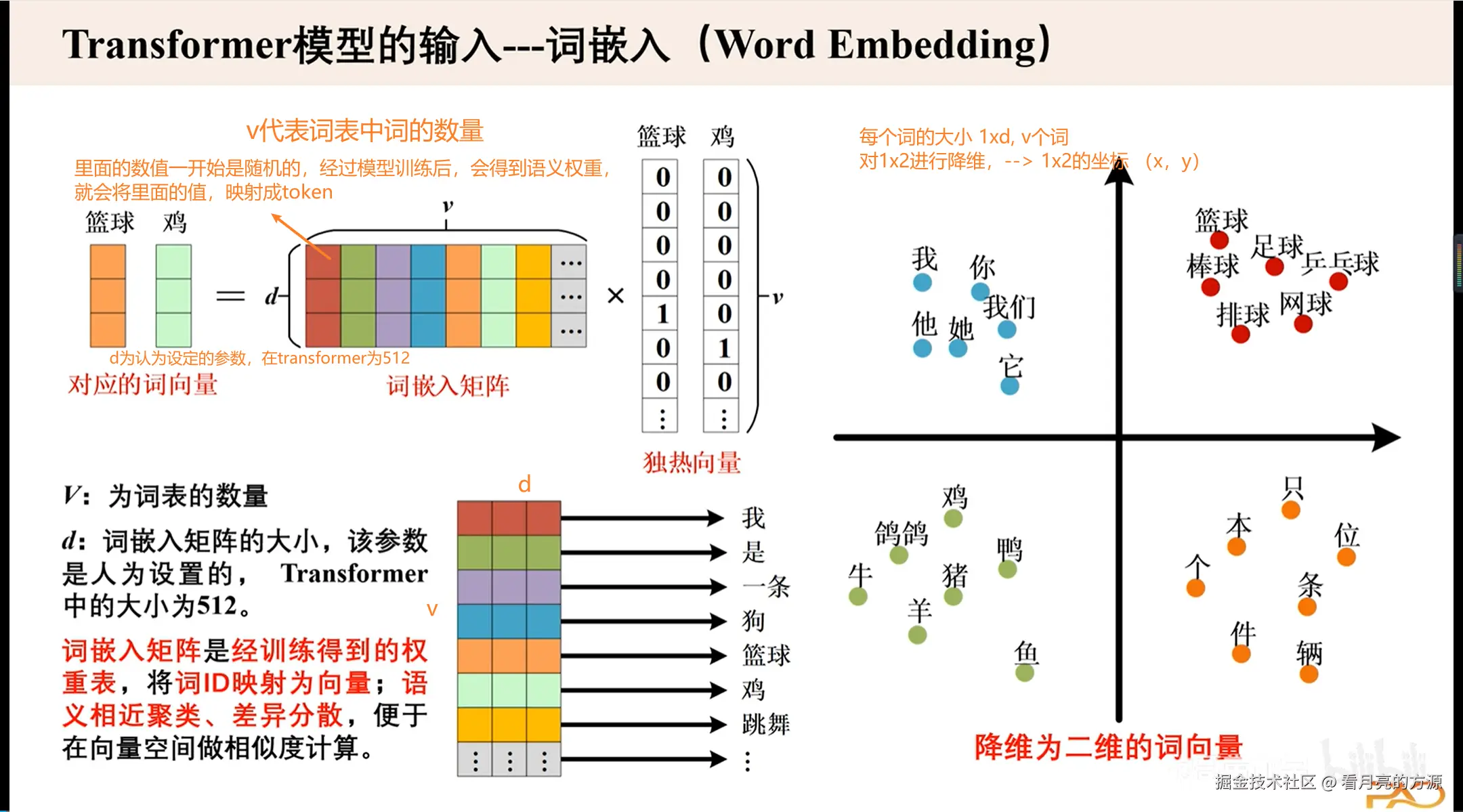
Input Embedding 作用将离散文本转换为连续向量表示,使神经网络能够处理文本信息
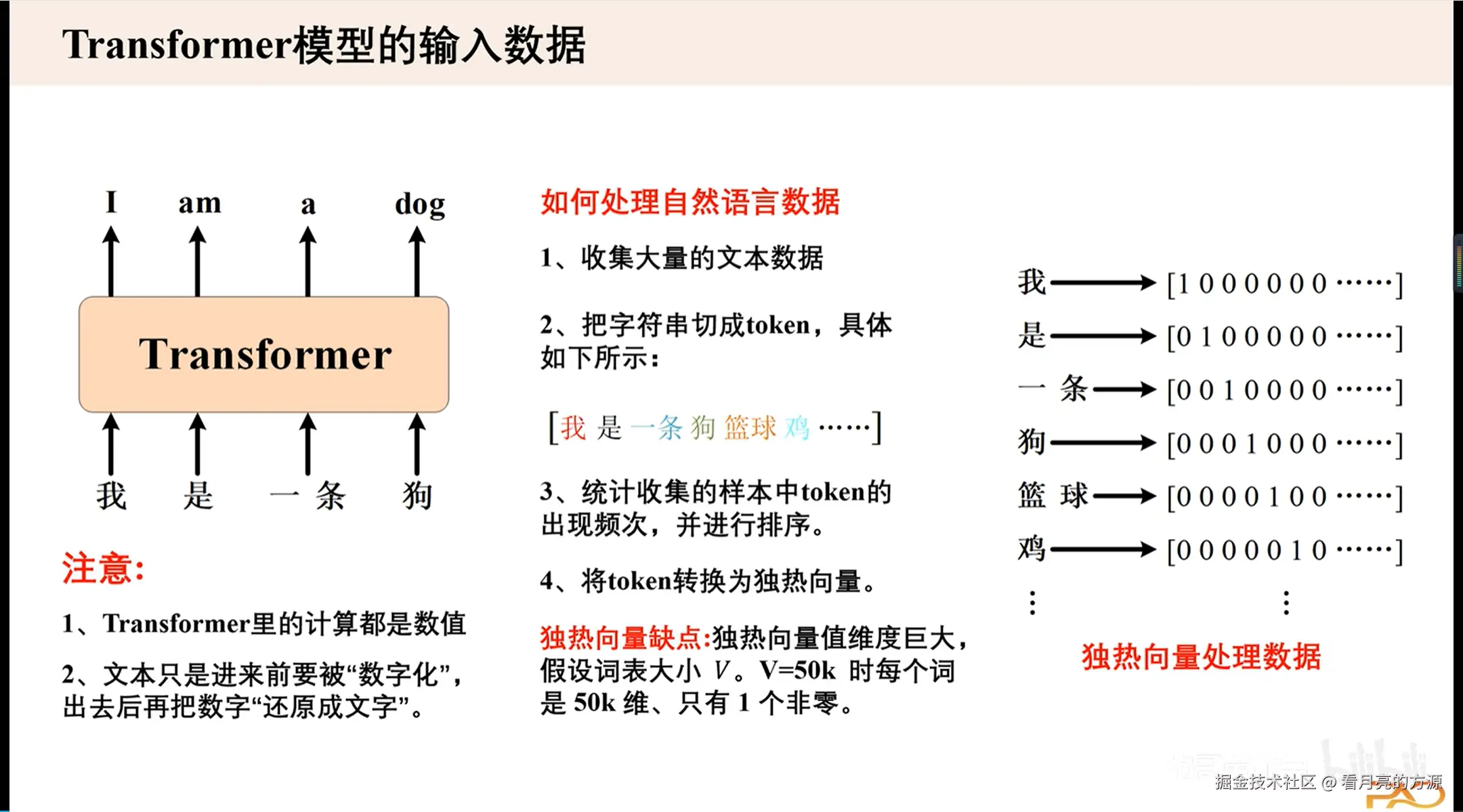 one-hot维度较高,模型难以计算。 如何解决呢?我们引入词嵌入矩阵
one-hot维度较高,模型难以计算。 如何解决呢?我们引入词嵌入矩阵
1.2 位置编码
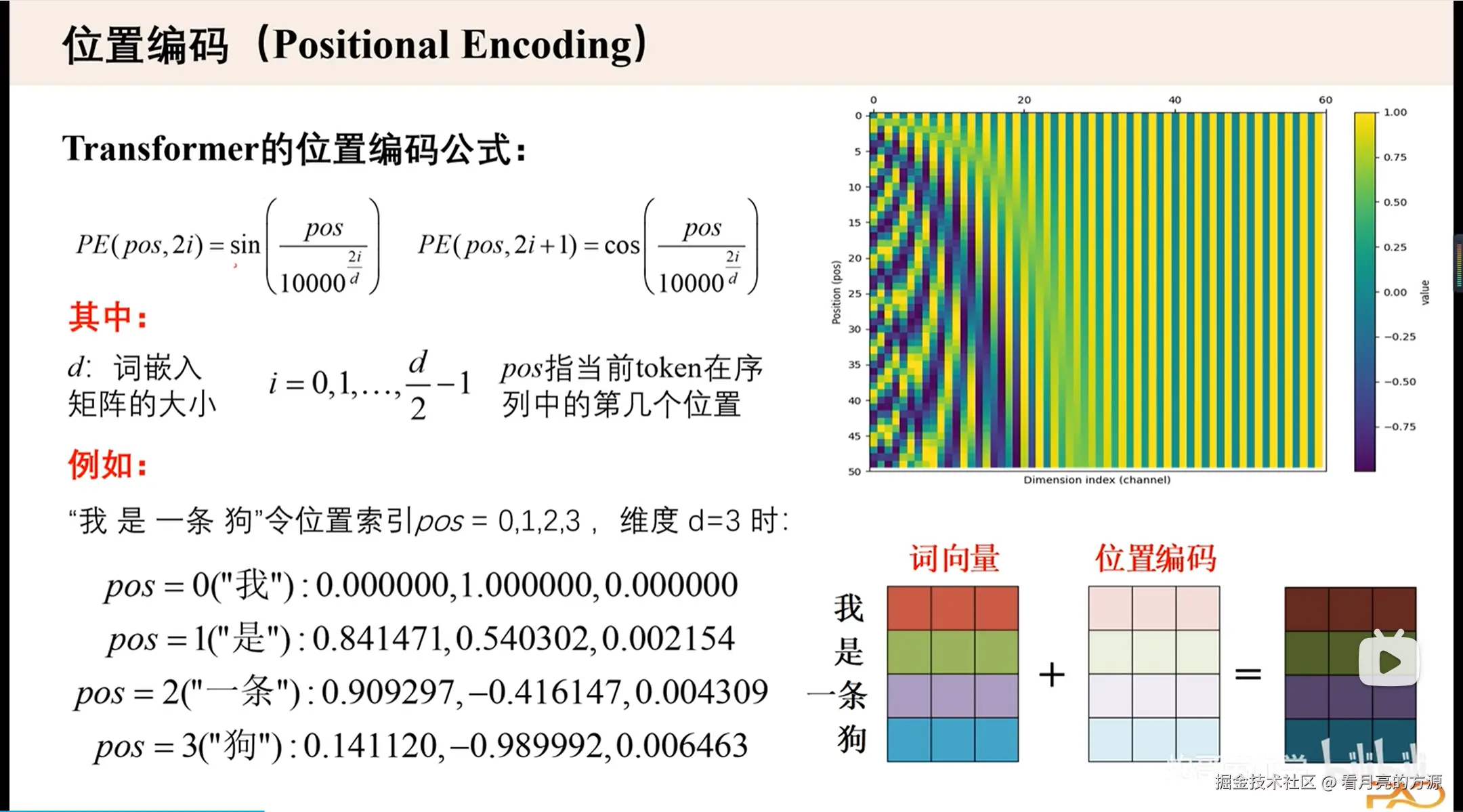
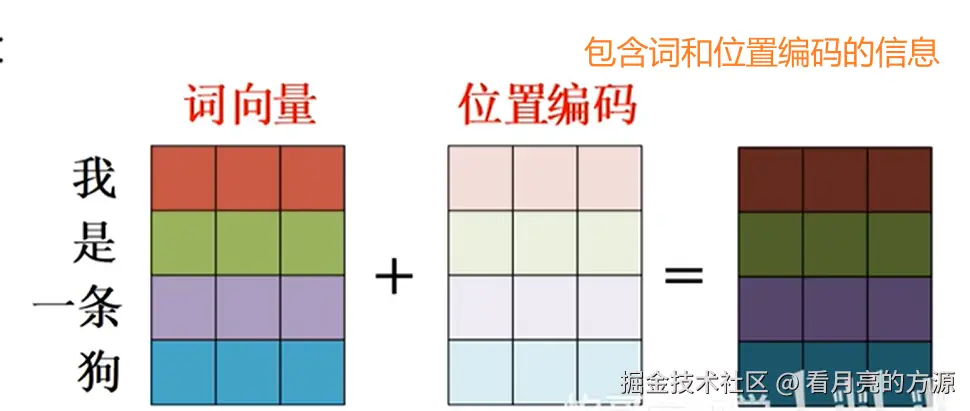
经过 word embedding,我们获得了词与词之间关系的表达形式,但是词在句子中的位置关系还无法体现。
由于 Transformer 是并行地处理句子中的所有词,因此需要加入词在句子中的位置信息,结合了这种方式的词嵌入就是 Position Embedding 了。
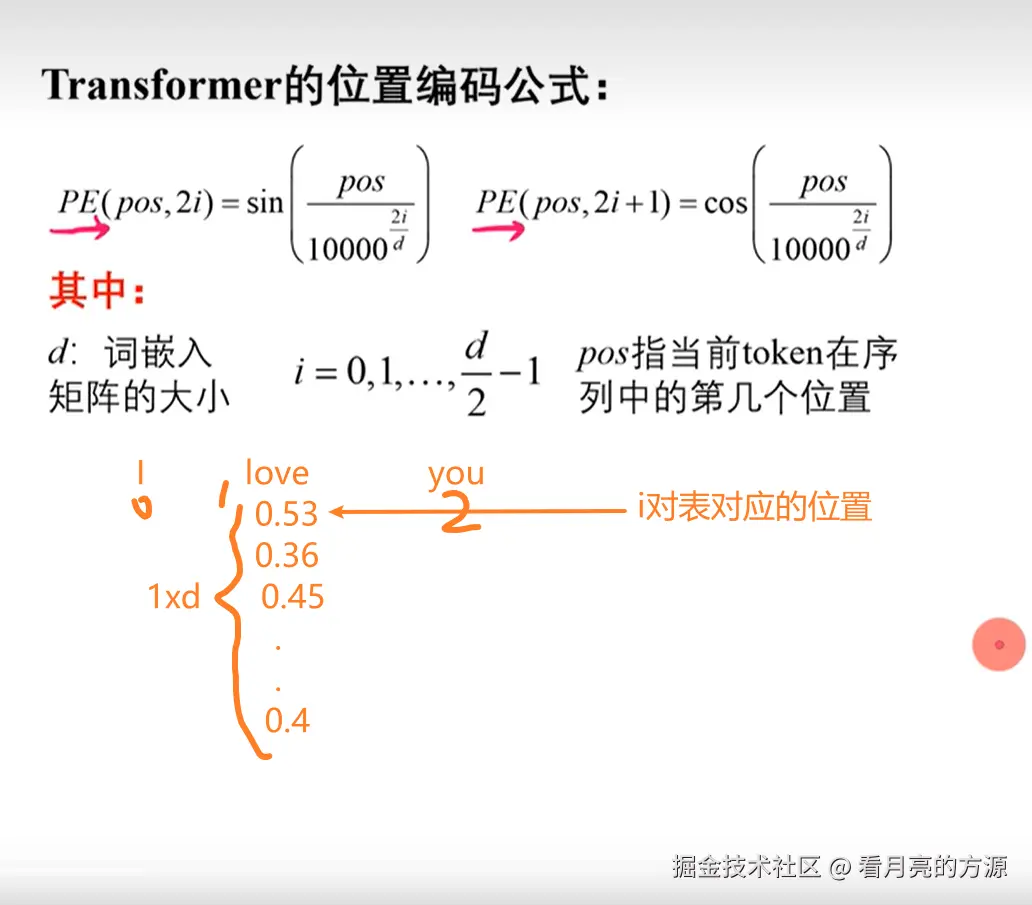 比如图中
比如图中love这个词,pos=1,

2. q,k,v是什么?
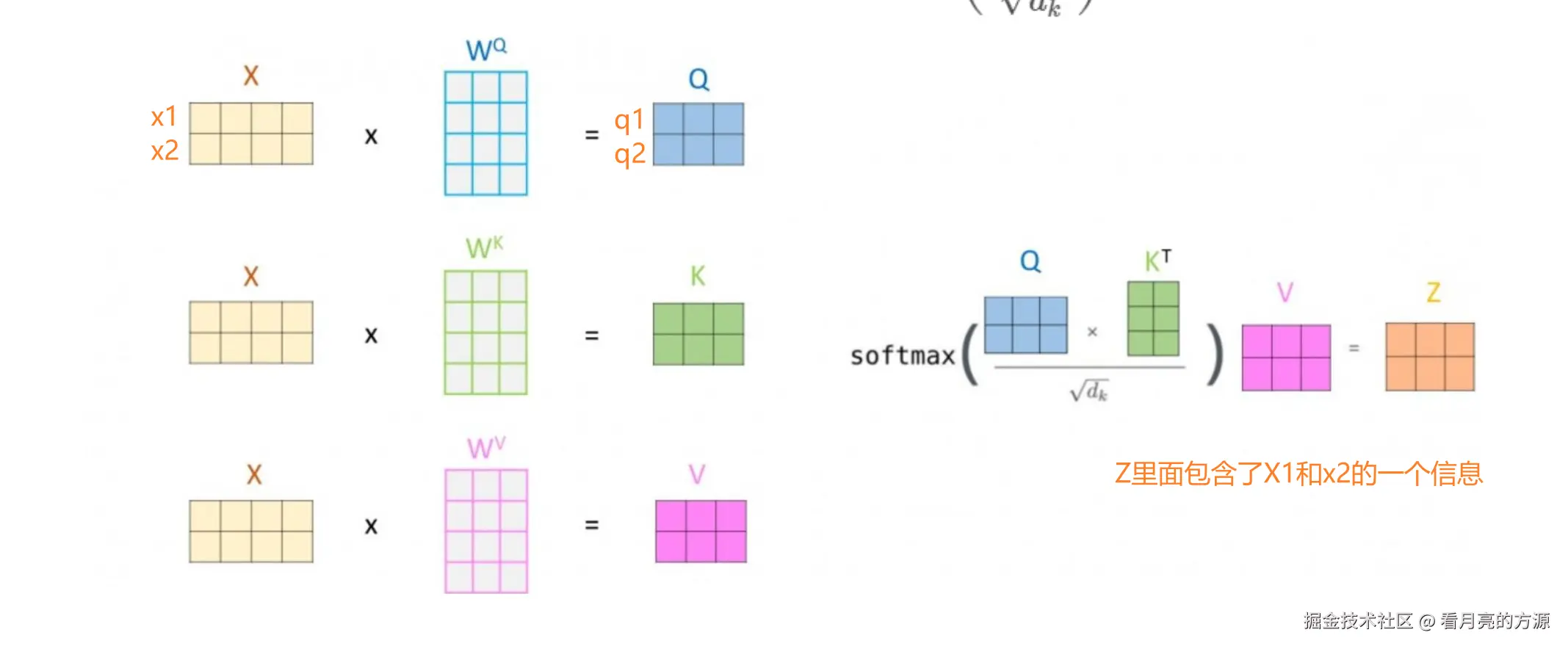
在自注意力计算中,第一步是将编码器的每个输入向量(即词的特征表示)通过线性变换映射为三个新向量:查询向量(Query)、键向量(Key)和值向量(Value),简称为q、k、v向量。
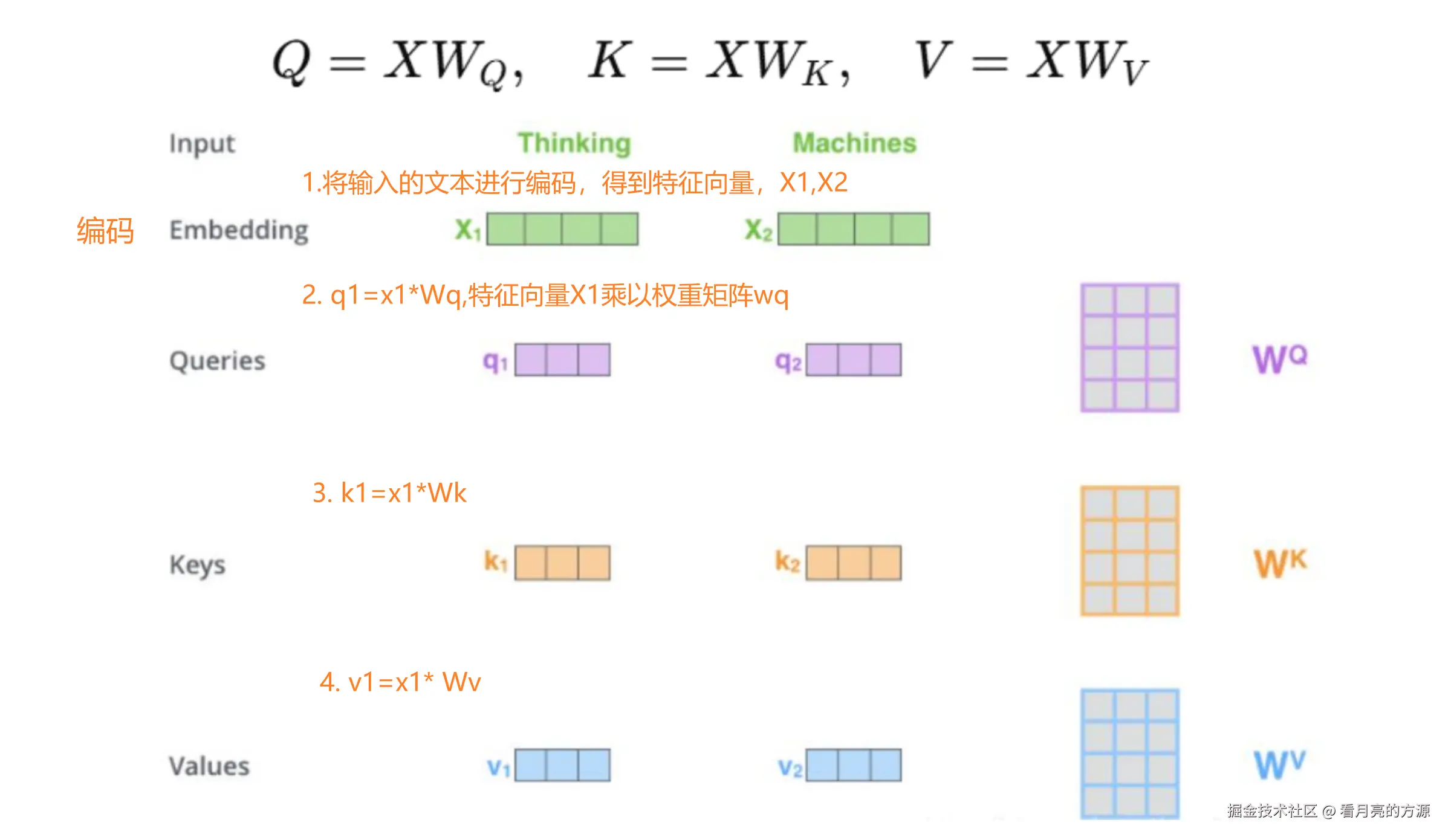 那么q,k,v向量到底是什么呢?
那么q,k,v向量到底是什么呢?
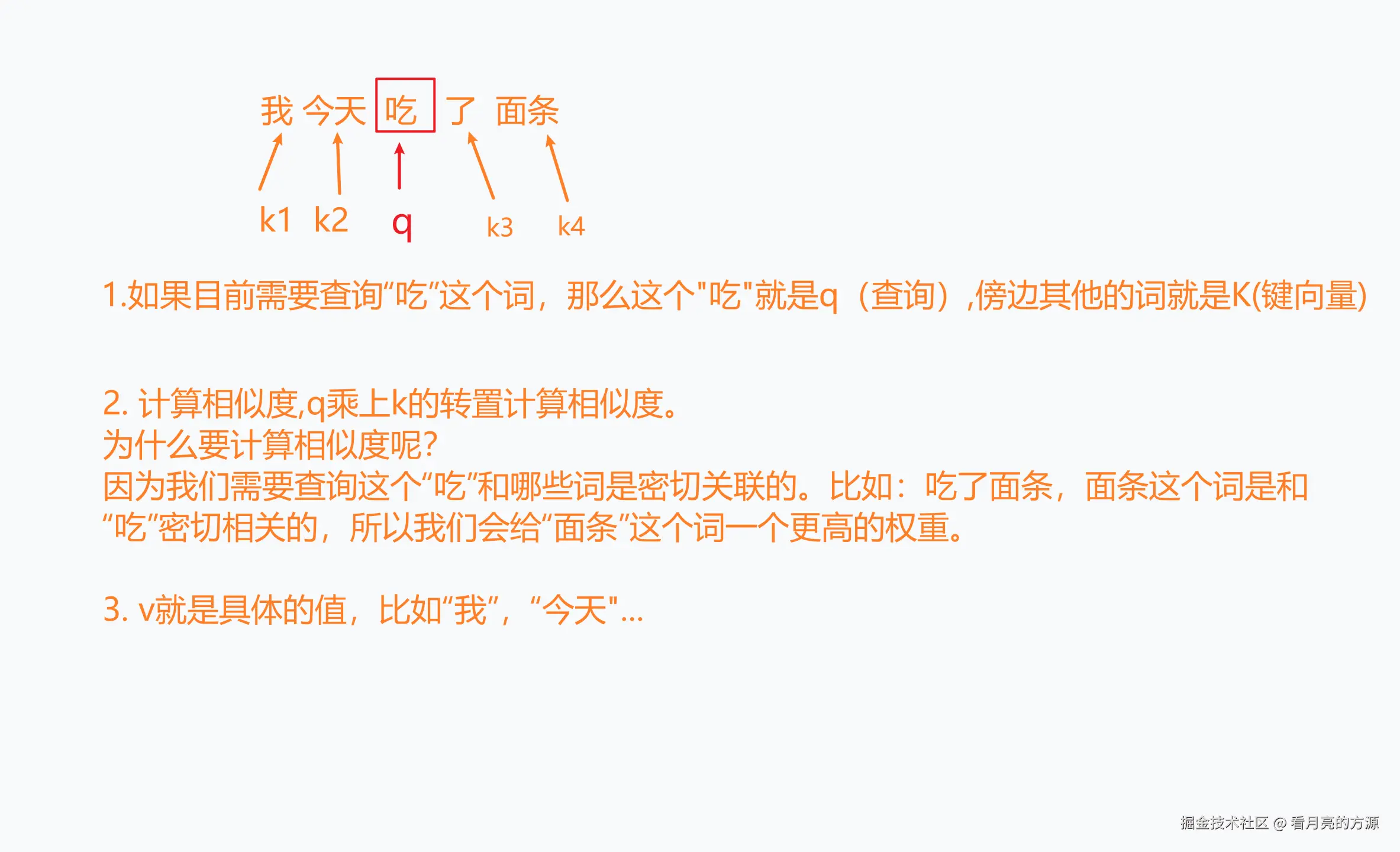
- 如果目前需要查询"吃"这个词,那么这个"吃"就是q(查询),旁边其他的词就是K(键向量)
- 计算相似度,q乘上k的转置计算相似度。为什么要计算相似度呢?
- 因为我们需要查询这个"吃"和哪些词是密切关联的。
- 比如:吃了面条,面条这个词是和 "吃"密切相关的,所以我们会给"面条"这个词一个更高的权重。
- v就是具体的值,比如"我","今天"...。
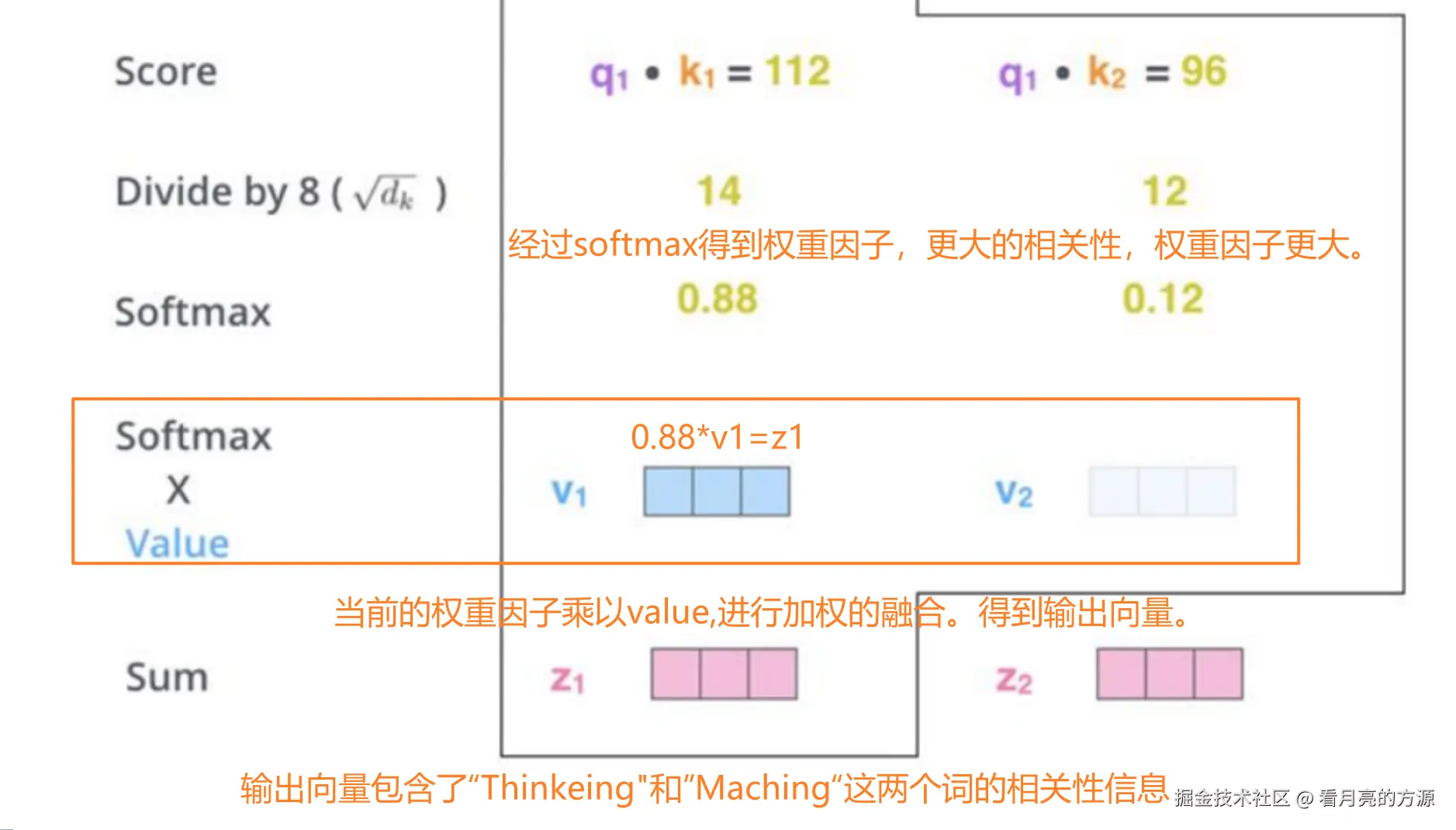
3. 注意力计算过程
计算相关性分数
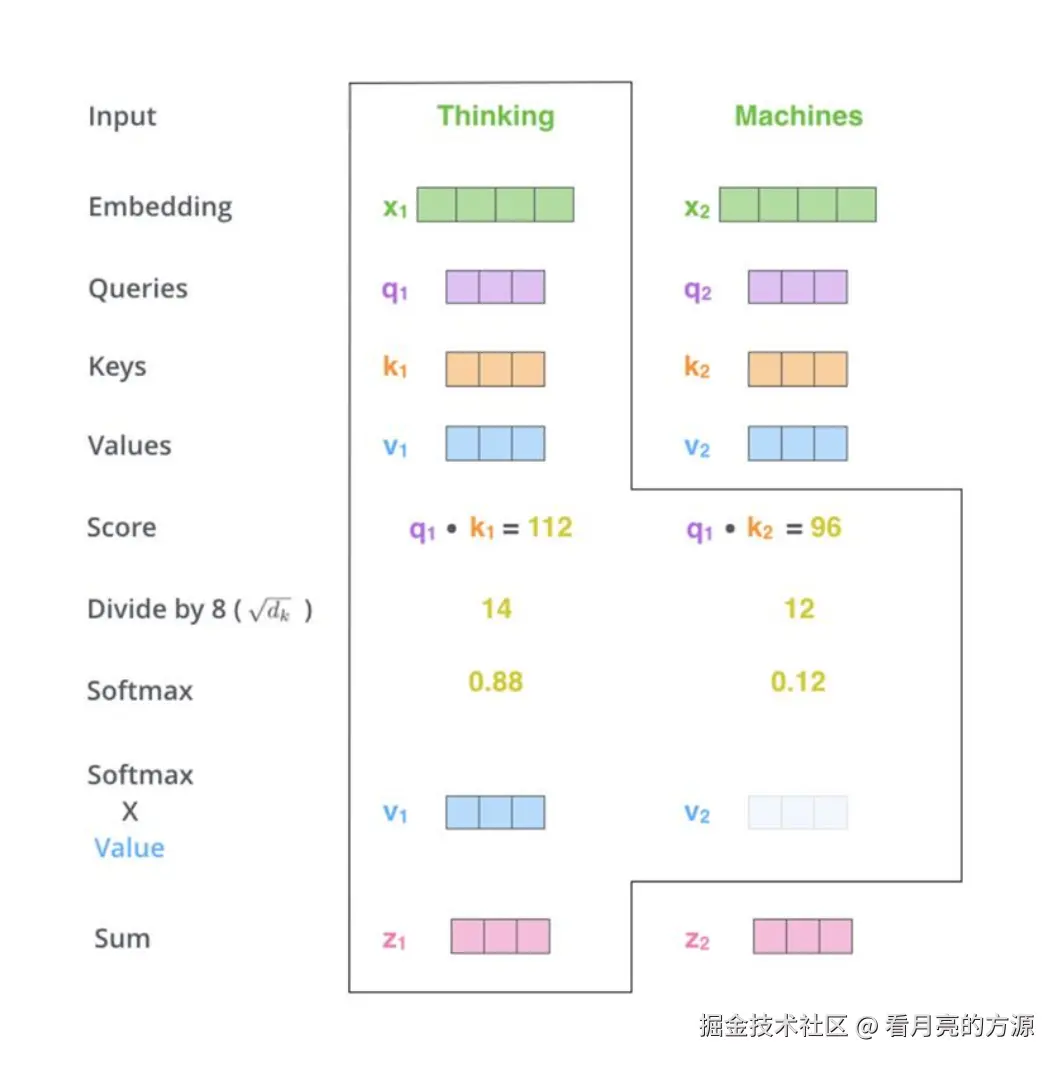
- 计算相关性分数(score):查询向量qi和键向量kj的点积、第i个词(位置)的Query,要和每个词(包括它自己)的Key做点积,得到一组相关性分数。
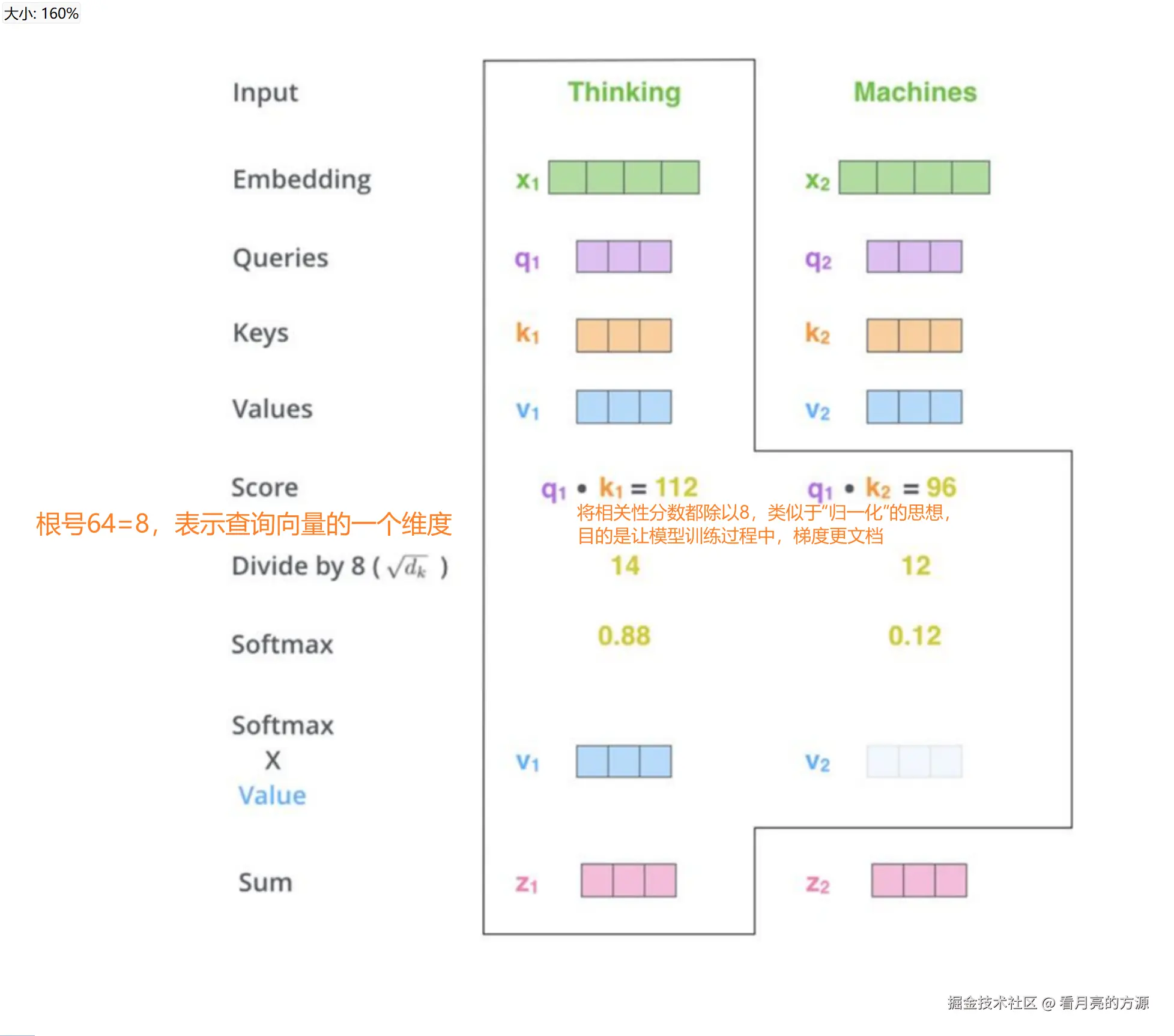
 2. 将相关性分数除以8(8是论文中使用的查询向量维度的平方根,即根号下64),会使模型训练时的梯度更稳定。 将相关性分数都除以8,类似于"归一化"的思想。目的是让模型训练过程中,梯度更稳定。
2. 将相关性分数除以8(8是论文中使用的查询向量维度的平方根,即根号下64),会使模型训练时的梯度更稳定。 将相关性分数都除以8,类似于"归一化"的思想。目的是让模型训练过程中,梯度更稳定。
 3. 经过Softmax得到权重因子。
3. 经过Softmax得到权重因子。
- 将每个值向量乘以对应的Softmax分数加权求和。
4. Self-Attention公式
在实际的实现中,会将输入向量打包成矩阵,以矩阵形式完成此计算,以便更快地在计算机中计算处理。
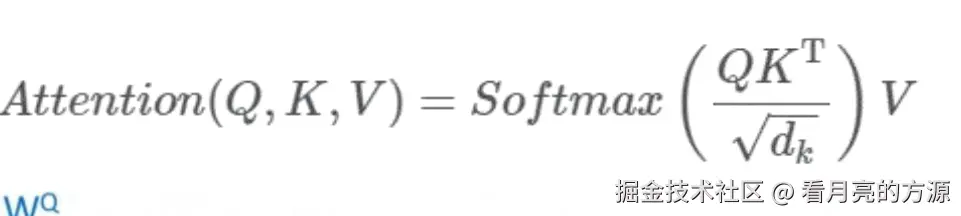
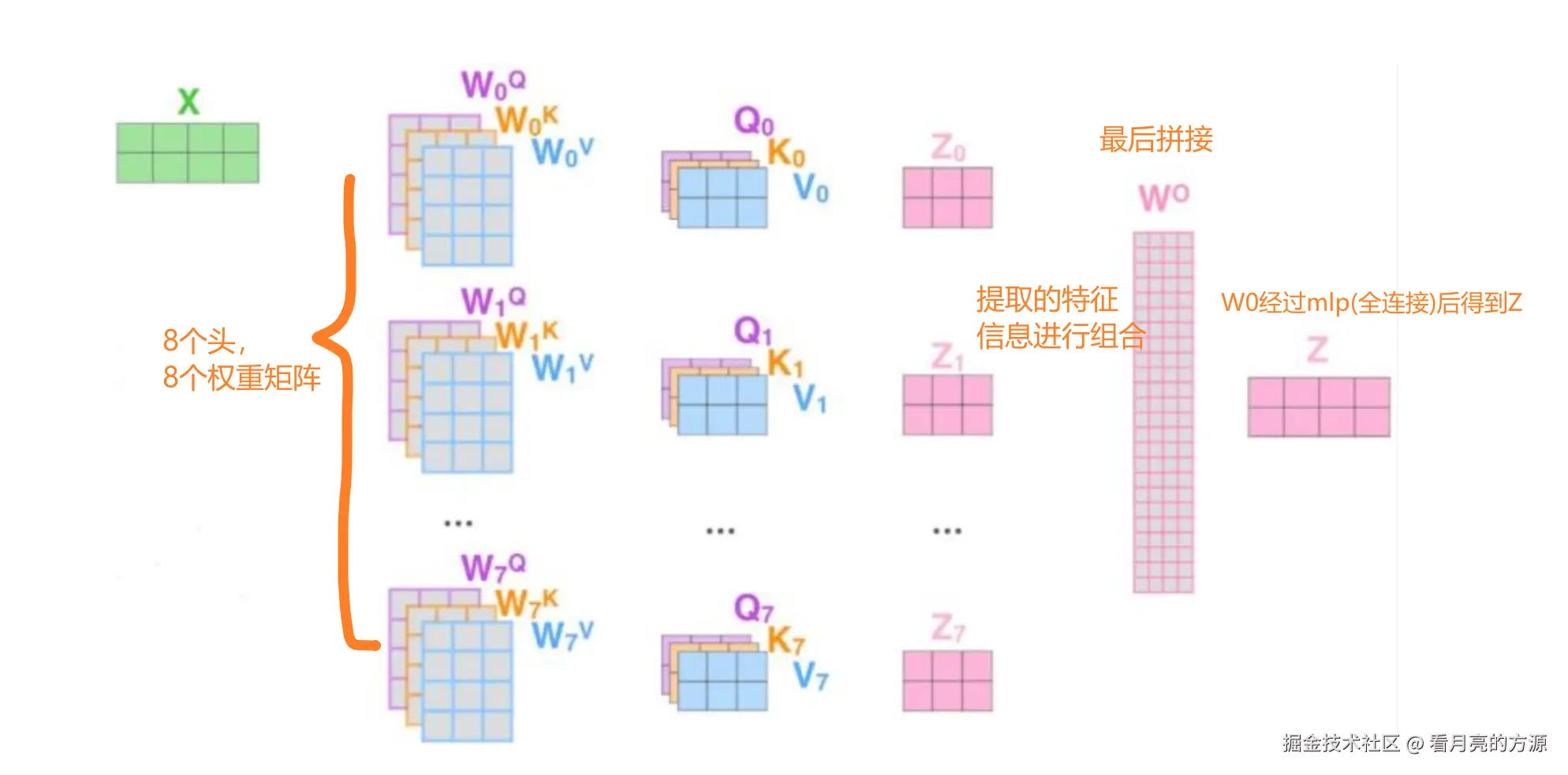
5. 多头注意力机制
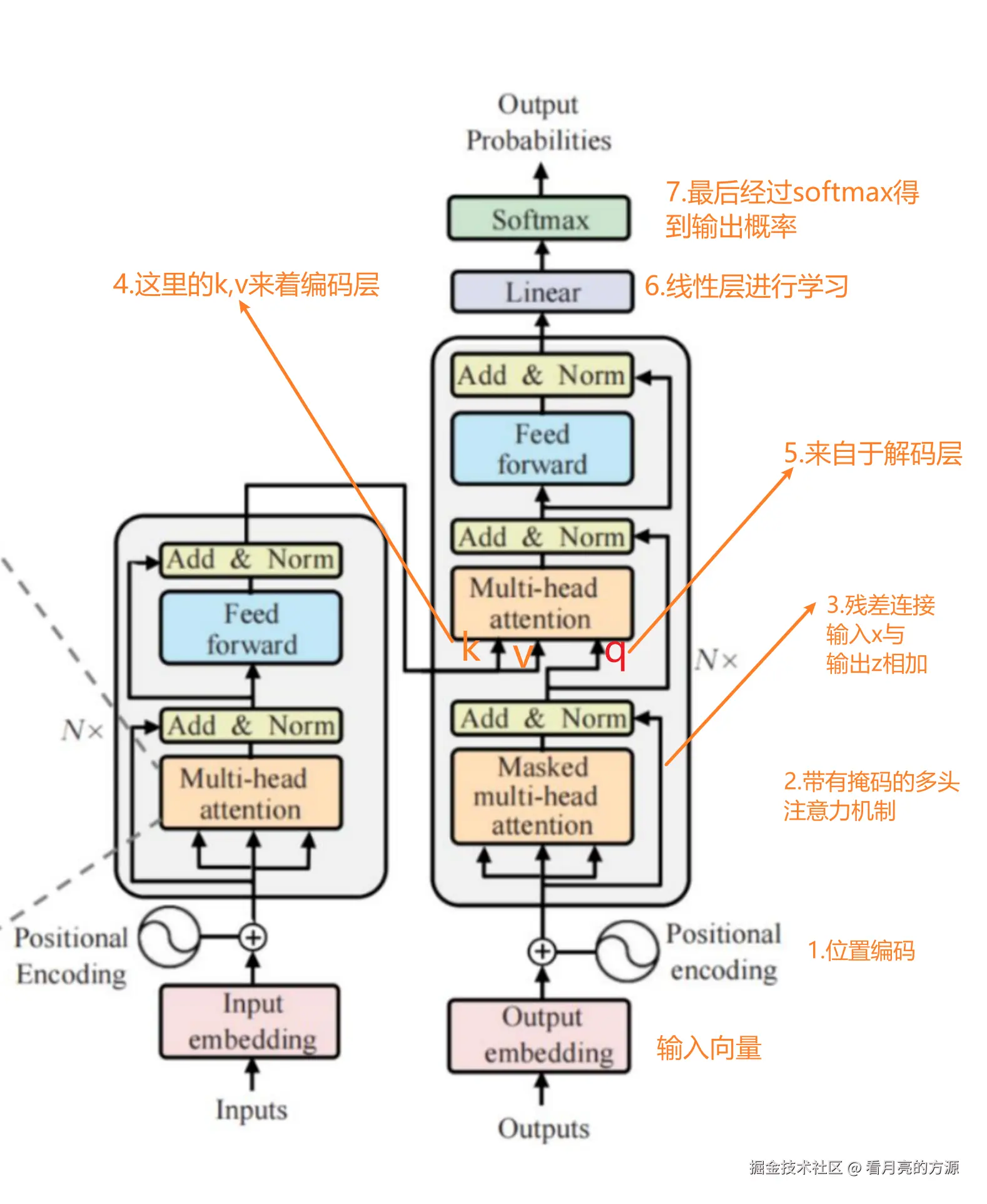
6. 解码层
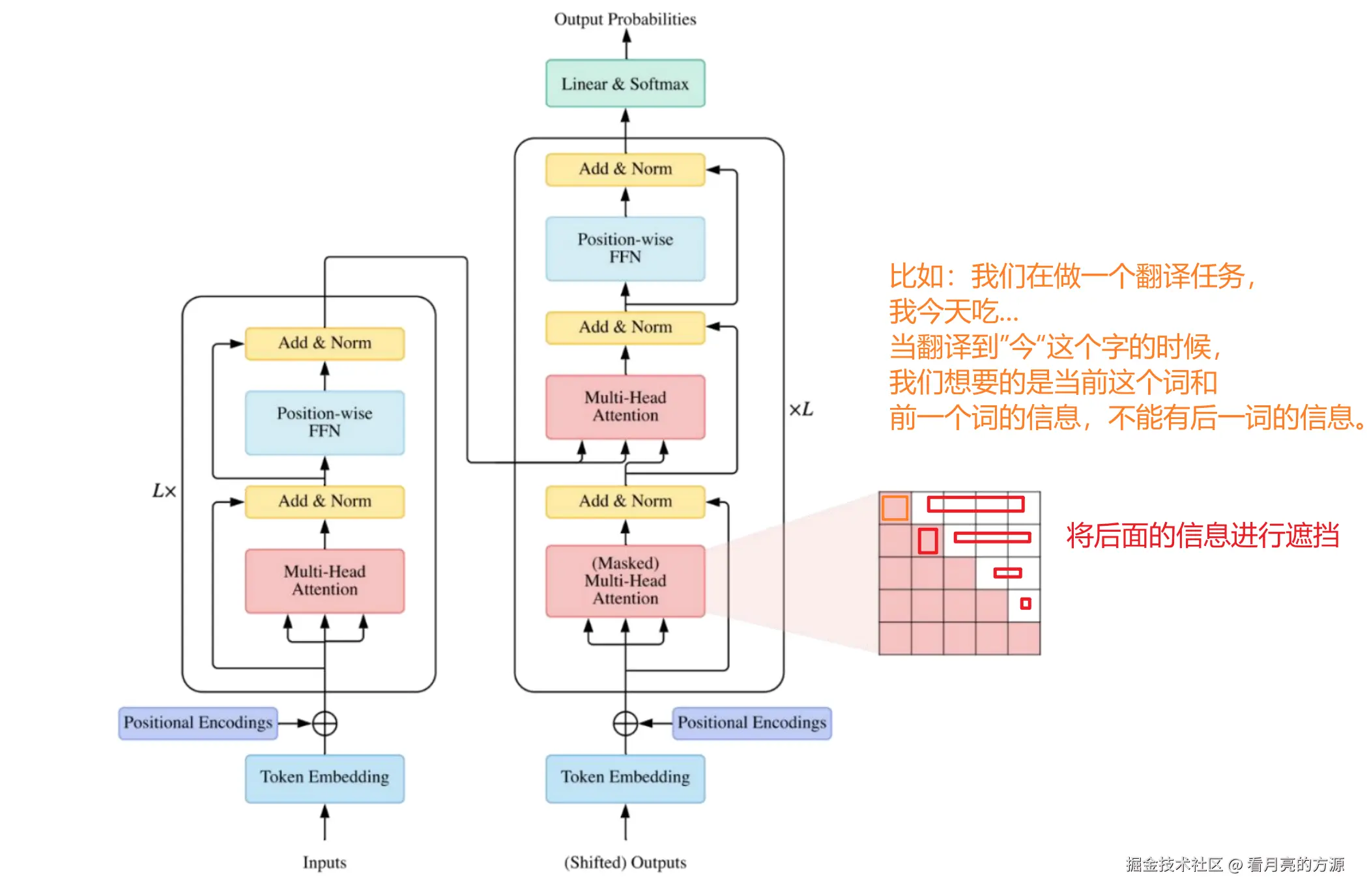
7. Mask多头注意力
8.代码实现
python
import torch
import torch.nn as nn
import math
# 定义自注意力
class SelfAttentionn(nn.Module):
def __init__(self, dropout=0.1):
super().__init__()
self.dropout = nn.Dropout(dropout) # 对10%的神经元做一个随机失活,防止过拟合
self.softmax = nn.Softmax(dim=-1) # 将得分转换成概率分布 在最后一个维度进行
def forward(self, Q, K, V, mask=None):
# X:batch,seq_len,d_model
# batch: 一次送到模型的句子个数;seq_len:一个句子中的token数量;d_model:embedding向量的维度
# Q,query向量 维度:batch,heads,seq_len_q,d_k
# K,Key向量 维度:batch,heads,seq_len_k,d_k
# V,value向量 维度:batch,heads,seq_len_v,d_v
# mask 的目的是为了告诉模型哪些位置需要忽略
d_k = Q.size(-1) # q的最后一维是每个query向量的维度,代表我们对每个query进行缩放
# batch,heads,seq_len_q,d_k , batch,heads,d_k,seq_len_k-> batch,heads,seq_len_q,seq_len_k
scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(d_k) # 进行缩放 让模型训练的梯度更稳定
# 如果提供了mask,则通过mask==0来找到需要屏蔽的位置,masked_fill会将这些为宗旨的值改为-inf(负无穷)
# 然后经过softmax之后这些位置的值会变成0(被忽略)
# 设置mask==0 表示被屏蔽, mask==1则代表当前位置可见
if mask is not None:
scores = scores.masked_fill(mask == 0, float('-inf'))
# batch,heads,seq_len_q,seq_len_k 对最后一维进行softmax,即对key进行,得到注意力权重矩阵,对每一个query的key权重之和为1
attn = self.softmax(scores)
attn = self.dropout(attn) # 对注意力权重进行dropout,防止过拟合
# attn:batch,heads,seq_len_q,seq_len_k ; V:batch,heads,seq_len_v,d_v->attn*V:batch,heads,seq_len_q,d_v
out = torch.matmul(attn, V)
return out, attn
# 定义多头注意力
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, n_heads, dropout=0.1):
super().__init__()
# d_model embdedding的维度 512
# n_heads为多头注意力的头数 8
# d_model 需要被 n_heads 整除 结果为64
assert d_model % n_heads == 0
self.d_k = d_model // n_heads # 每个头的维度
self.n_heads = n_heads
# 将输入映射到Q K V 三个向量,通过线性映射让模型具有学习能力
self.W_q = nn.Linear(d_model, d_model) # query的线性映射,维度不需要改变,方便后续的多头拆分
self.W_k = nn.Linear(d_model, d_model) # key的线性映射
self.W_v = nn.Linear(d_model, d_model) # value的线性映射
self.fc = nn.Linear(d_model, d_model) # 多头拼接后再映射回原来的d_model,让模型融合不同头的信息
self.attention = SelfAttentionn(dropout) # 使用我们定义好的selfattn
self.dropout = nn.Dropout(dropout) # 防止过拟合
self.norm = nn.LayerNorm(d_model) # 用于残差后的归一化
def forward(self, q, k, v, mask=None):
batch_size = q.size(0) # 获取batch的大小
# q 的维度 batch,seq_len,d_model -> batch,seq_len,self.n_heads,self.d_k -> batch,self.n_heads,seq_len,self.d_k
# 为了让每个注意力头独立处理整个序列,方便后续计算注意力权重
Q = self.W_q(q).view(batch_size, -1, self.n_heads, self.d_k).transpose(1, 2)
K = self.W_k(k).view(batch_size, -1, self.n_heads, self.d_k).transpose(1,
2) # batch,self.n_heads,seq_len,self.d_k
V = self.W_v(v).view(batch_size, -1, self.n_heads, self.d_k).transpose(1, 2)
# 计算注意力
out, attn = self.attention(Q, K, V, mask) # attn为注意力权重,out 为注意力加权后的值
# out.transpose(1,2): batch,heads,seq_len_q,d_v ->batch,seq_len_q,heads,d_v -> batch,seq_len,d_model
# contiguous目的是让tensor在内存中连续存储,避免view的时候产生报错
# 多头拼接
out = out.transpose(1, 2).contiguous().view(batch_size, -1,
self.n_heads * self.d_k) # out:batch,seq_len,d_model
out = self.fc(out) # 让输入和输出一致,方便残差连接
out = self.dropout(out) # 在训练阶段随即丢弃一部分神经元,防止过拟合
# 残差连接+layernorm
return self.norm(out + q), attn # 返回输出和注意力权重
class FeedForward(nn.Module):
def __init__(self, d_model, d_ff, dropout=0.1):
super().__init__()
self.fc1 = nn.Linear(d_model, d_ff) # 输入维度为d_model,输出为d_ff,512->2048, 为了让模型学到一个更丰富的特征
self.fc2 = nn.Linear(d_ff, d_model) # 保证第二个线形层输出维度等于第一个线形层的输入维度,为了后续做残差连接
self.dropout = nn.Dropout(dropout) # 做随即丢弃 防止过拟合
self.norm = nn.LayerNorm(d_model) # layernorm对最后一维进行归一化
def forward(self, x):
# X 形状为 batch,seq_len,d_model
out = self.fc2(self.dropout(torch.relu(self.fc1(x)))) # 先经过第一个线性层,在经过relu,再经过dropout,在经过第二个线性层
return self.norm(out + x) # 残差的目的是为了保留输入的低阶信息,避免训练时候信息丢失
# 先经过残差连接,再经过层归一化(为了让模型训练更稳定 能够加快模型收敛)
class EncoderLayer(nn.Module):
def __init__(self, d_model, n_heads, d_ff, dropout=0.1):
super().__init__()
# 多头注意力机制 输入为 src 实现序列内部的信息交互,每个token都可以看到序列中的其它token,从而可以学习到上下文依赖
self.self_attn = MultiHeadAttention(d_model, n_heads, dropout)
# 对每个位置向量独立进行非线性变换,可以提升模型表达能力
self.ffn = FeedForward(d_model, d_ff, dropout)
def forward(self, src, src_mask=None):
# src 输入序列张量 形状 batch,seq_len,d_model
# src_mask 屏蔽padding的位置,避免模型关注无效token(encoder) 在decoder中 mask用来防止看到未来的词
# Q K V = src 对输入序列本身进行自注意力计算
out, _ = self.self_attn(src, src, src, src_mask)
# 经过前馈神经网络,每个位置的token都会单独通过两层线性层映射和激活函数,提升模型的表达能力
out = self.ffn(out)
# 返回编码后的结果
return out
class DecoderLayer(nn.Module):
def __init__(self, d_model, n_heads, d_ff, dropout=0.1):
super().__init__()
# Mask多头注意力机制
# 输入 tgt(目标序列) 在翻译任务中 已经生成的前几个单词
# 计算目标序列内部的自注意力,通过mask遮挡住未来的token
self.self_attn = MultiHeadAttention(d_model, n_heads, dropout)
# 交叉注意力,和encoder做交互
# 输入 Q=当前解码器的输出,K=V = 来自编码器的memory(原序列上下文信息)
# 为了讲目标序列与原序列进行对齐
self.cross_attn = MultiHeadAttention(d_model, n_heads, dropout)
self.ffn = FeedForward(d_model, d_ff, dropout) # 为了提升模型的表达能力
def forward(self, tgt, memory, tgt_mask=None, memory_mask=None):
# tgt 目标序列 memory:编码器输出(原序列的表示)
# tgt_mask: 屏蔽未来的token,memory_mask:PAD 做掩码
# 目标序列内部的自注意力,未来位置被mask
out, _ = self.self_attn(tgt, tgt, tgt, tgt_mask)
# 将目标序列 和原序列进行交互,Q解码器当前的输出out,K=V=memory(编码器的输出)
out, _ = self.cross_attn(out, memory, memory, memory_mask)
out = self.ffn(out)
return out
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_len=5000):
super().__init__()
# d_model 每个词向量的维度 ;max_len:句子的最大长度
# 初始化位置编码矩阵 形状为max_len,d_model
pe = torch.zeros(max_len, d_model)
# 定义记录每个token位置的索引,0-max_len-1
# [max_lenn,1] 方便后续与缩放因子进行相处
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
# div_term 每个维度得到缩放因子,torch.arange(0,d_model,2):生成偶数维度索引 0 2 4 对应公式就是2i
# torch.arange(0,d_model,2).float()*(-math.log(10000.0)/d_model) = (2i/d_model)*-ln(10000.0)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
# 每个token的位置索引pos * 每个维度的缩放因子(div_term) 再套上sin得到偶数维度的位置编码值
pe[:, 0::2] = torch.sin(position * div_term)
# 每个token的位置索引pos * 每个维度的缩放因子(div_term) 再套上cos得到奇数维度的位置编码值
pe[:, 1::2] = torch.cos(position * div_term)
# 增加batch维度,1,max_len,d_model,方便后续与输入embedding进行相加
pe = pe.unsqueeze(0)
# 注册为buffer,把位置编码pe存在 模型里面,不参与训练,但是随着模型保存/加载
self.register_buffer('pe', pe)
def forward(self, x):
# X:输入的embedding 形状 batch,seq_len,d_model
seq_len = x.size(1)
# 每个token 的 embedding加上对应位置的编码
# self.pe[:,:seq_len,:] 取前seq_len个位置,形状会变成 1 ,seq_len,d_model,可以和输入X对齐
# x + self.pe[:,:seq_len,:] : batch,seq_len,d_model;embedding加上位置编码,transformer就可以知道token的顺序
return x + self.pe[:, :seq_len, :]
class Encoder(nn.Module):
def __init__(self, vocab_size, d_model, n_heads, num_layers, d_ff, dropout=0.1, max_len=5000):
super().__init__()
# 词嵌入层,vocab_size:词表大小,包含了不同token的总数
# 将输入的token ID(对原始文本分词得到词表,不同词对应不同ID)转换成连续向量,维度为d_moedl
self.embedding = nn.Embedding(vocab_size, d_model)
# 位置编码加入序列中token的位置信息
self.pos_encoding = PositionalEncoding(d_model, max_len)
# 构建编码器的堆叠结构
# 堆叠num_layers个encoder
# nn.ModuleList 为网络层准备的列表 用来存放多个子模块
# 列表推导式,用来生成num_layers个encoder
self.layers = nn.ModuleList([
EncoderLayer(d_model, n_heads, d_ff, dropout) for _ in range(num_layers)
])
def forward(self, src, src_mask=None):
# 将输入 token ID 转换成 embedding向量
# 输出 shape batch,seq_len,d_model
# 乘上 sqrt(d_model),进行缩放,让后续注意力计算更稳定
out = self.embedding(src) * math.sqrt(self.embedding.embedding_dim)
# 经过位置编码
out = self.pos_encoding(out)
# 逐层经过encoderlayer
for layer in self.layers:
out = layer(out, src_mask) # self_attn+ffn
return out # 返回编码后的输出 batch,seq_len,d_model
class Decoder(nn.Module):
def __init__(self, vocab_size, d_model, n_heads, num_layers, d_ff, dropout=0.1, max_len=5000):
super().__init__()
# 将目标序列的 token id 转换为向量 维度为 d_model
self.embedding = nn.Embedding(vocab_size, d_model)
# 经过位置编码
self.pos_encoding = PositionalEncoding(d_model, max_len)
# 定义解码器列表
self.layers = nn.ModuleList([
DecoderLayer(d_model, n_heads, d_ff, dropout) for _ in range(num_layers)
])
# 输出投影层 将decoder的输出映射回原词汇表的大小,从而得到 每个token预测分布
self.fc_out = nn.Linear(d_model, vocab_size)
def forward(self, tgt, memory, tgt_mask=None, memory_mask=None):
# tgt 目标序列 解码器的输入 memory编码器的输出 也叫上下文信息
# tgt_mask 目标序列的mask 用来屏蔽未来的位置 memory_mask: 用来屏蔽pad
out = self.embedding(tgt) * math.sqrt(self.embedding.embedding_dim)
# 添加位置编码
out = self.pos_encoding(out)
# 逐层经过 decoderlayer
for layer in self.layers:
out = layer(out, memory, tgt_mask, memory_mask)
# 将解码器最后一层输出的隐藏向量映射回原词汇表的维度,得到每个token的预测向量
return self.fc_out(out)
class Transformer(nn.Module):
def __init__(self,
src_vocab, # 原语言词表大小
tgt_vocab, # 目标语言词表大小
d_model=512, # embedding向量的维度
n_heads=8, # 多头注意力的头数
num_encoder_layers=6, # 编码器的层数
num_decoder_layers=6, # 解码器的层数
d_ff=2048, # ffn隐藏层维度
dropout=0.1, # 丢弃比例
max_len=5000): # 最大序列长度
super().__init__()
# 编码器 将源语言token 编码为上下文表示
self.encoder = Encoder(
src_vocab, d_model, n_heads, num_encoder_layers, d_ff, dropout, max_len
)
# 解码器 根据编码器的输出和目标语言输入生成预测
self.decoder = Decoder(
tgt_vocab, d_model, n_heads, num_decoder_layers, d_ff, dropout, max_len
)
def forward(self, src, tgt, src_mask=None, tgt_mask=None, memory_mask=None):
# 编码器前向传播 src_mask用来屏蔽pad
memory = self.encoder(src, src_mask)
# 解码器前向传播 tgt_mask用来屏蔽未来token
out = self.decoder(tgt, memory, tgt_mask, memory_mask)
# 返回transformer输出 batch,seq_len_tgt,tgt_vocab
return out
def generate_mask(size):
# 防止解码器看到未来的token size为序列长度
# torch.triu(torch.ones(size,size),diagonal=1) 会生成上三角,不含对角线
mask = torch.triu(torch.ones(size, size), diagonal=1).bool()
# 这样做的目的是明确生成了上三角(需要屏蔽的位置),然后通过mask==0得到可见部分
return mask == 0 # True可见,False 屏蔽
src_vocab = 10000 # 源语言词表大小
tgt_vocab = 10000 # 目标语言词表大小
# 初始化模型
model = Transformer(src_vocab, tgt_vocab)
src = torch.randint(0, src_vocab, (32, 10)) # 原序列 batch=32 src_len=10 每个元素是token ID
tgt = torch.randint(0, tgt_vocab, (32, 20)) # 目标序列 batch=32 tgt_len=20 每个元素是token ID
# (tgt.size(1) 取目标序列长度
tgt_mask = generate_mask(tgt.size(1)).to(tgt.device)
out = model(src, tgt, tgt_mask=tgt_mask) # 前向传播
# 每个目标token 对应词表中每个词的预测概率
print(out.shape) # batch,tgt_len,tgt_vocab