一、为什么需要多路召回?
单一检索策略总有盲区:
- 向量检索擅长语义匹配,但对专有名词、ID、罕见词容易失准
- 关键词检索(BM25) 对精确匹配强,但无法理解同义词和上下文语义
- 图检索 / 结构化查询能捕捉实体关系,但召回率有限
多路召回的本质是用不同视角弥补单路的偏差 。但多路结果合并时,面临一个核心难题:分数不可比。向量相似度 0~1,BM25 几千几万,图检索是跳数------直接加权融合会失真。
RRF(Reciprocal Rank Fusion,倒数排序融合) 正是为了解决这个痛点而生。
二、RRF 原理:用「排名」代替「分数」
RRF 的核心洞察是:排名位置比绝对分数更稳定、更可比。它不 care 你得了多少分,只问你在自己那一路排第几。
2.1 公式
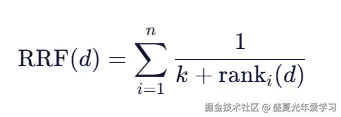
- d:候选文档
- r_i(d):文档 d 在第 i 路召回中的排名(从 1 开始计数)
- k:平滑常数,通常取 60
- n:召回路数
若文档 d 在某一路未命中,通常忽略该路(即不参与累加)。也可选择赋予惩罚排名(如 1000),用于强调"多路共同认可"的文档。
2.2 为什么用「倒数」?
倒数函数天然具备边际收益递减特性:
| 排名 | 贡献分(k=60) | 相比上一名衰减 |
|---|---|---|
| 1 | 1/61 ≈ 0.01639 | --- |
| 2 | 1/62 ≈ 0.01613 | -1.6% |
| 3 | 1/63 ≈ 0.01587 | -1.6% |
| 10 | 1/70 ≈ 0.01429 | -10.5%(累计) |
| 50 | 1/110 ≈ 0.00909 | -44.5%(累计) |
头部排名的微小差异会被放大(第 1 名 vs 第 3 名差距约 3.3%),而尾部几乎被抹平。这符合直觉:只有头部结果才真正可靠。
2.3 参数 k=60 的作用
k 是 RRF 唯一的超参数,其本质是控制头部区分度与稳定性的平衡:
- k→0 :趋近于纯倒数 1/r,第 1 名得分是第 2 名的 2 倍,头部区分度极高,但容易受单路噪声影响
- k→∞:各路贡献趋同,排名失去区分能力
- k = 60:经验最优折中(源自 Cormack et al. 2009 TREC 实验),既能保留头部敏感性,又避免第 1 名过度主导排序
工程建议 :除非有离线评测数据支持,否则直接固定
k=60。这是社区验证最稳定的值。
2.4 RRF vs Borda Count
Borda Count 给第 1 名 N 分、第 2 名 N-1分......是线性递减 。而 RRF 是倒数递减,对头部更敏感,实践中效果几乎总是优于 Borda。
三、Java 实现示例
typescript
/**
* RRF 多路召回融合
*
* @param rankLists 多路召回结果,每路按相关性从高到低排列的文档ID列表
* @param k 平滑因子,默认 60
* @return 按 RRF 得分降序排列的文档及其得分
*/
public static Map<String, Double> rrf(List<List<String>> rankLists, int k) {
if (rankLists == null || rankLists.isEmpty()) {
return new LinkedHashMap<>();
}
Map<String, Double> rrfScores = new HashMap<>();
for (List<String> rankList : rankLists) {
if (rankList == null) continue;
for (int rank = 0; rank < rankList.size(); rank++) {
String docId = rankList.get(rank);
// RRF 公式中 rank 从 1 开始,所以 rank + 1
double score = 1.0 / (k + (rank + 1));
rrfScores.merge(docId, score, Double::sum);
}
}
// 按得分降序排序,保持插入顺序
return rrfScores.entrySet().stream()
.sorted(Map.Entry.<String, Double>comparingByValue().reversed())
.collect(Collectors.toMap(
Map.Entry::getKey,
Map.Entry::getValue,
(e1, e2) -> e1,
LinkedHashMap::new
));
}
public static void main(String[] args) {
// 模拟两路召回:向量检索 vs BM25 检索
List<String> vectorResults = Arrays.asList("A", "B", "C", "D");
List<String> bm25Results = Arrays.asList("B", "A", "E", "C");
List<List<String>> allResults = Arrays.asList(vectorResults, bm25Results);
Map<String, Double> rrfResult = rrf(allResults, 60);
System.out.println("RRF 融合结果: " + rrfResult);
// 输出: {B=0.0325, A=0.0325, C=0.0315, E=0.0159, D=0.0156}
}计算过程拆解
| 文档 | 向量路排名 | BM25 路排名 | RRF 计算 | 最终得分 |
|---|---|---|---|---|
| A | 1 | 2 | 1/61 + 1/62 | 0.0325 |
| B | 2 | 1 | 1/62 + 1/61 | 0.0325 |
| C | 3 | 4 | 1/63 + 1/64 | 0.0315 |
| D | 4 | 未命中 | 1/64 | 0.0156 |
| E | 未命中 | 3 | 1/63 | 0.0159 |
关键观察:
- A 和 B 虽然都不是某一路的冠军,但两路均有命中且排名均衡,因此并列第一
- D 是向量路第 4,但 BM25 未命中,最终得分低于 E(BM25 第 3)------体现了 RRF 抗单路偏差的特性:多路共同认可的文档,优于单路的孤立高分
四、Reranker:语义级的精排
RRF 只基于排名做数学融合,完全不感知文档内容语义。而 Reranker(重排序模型) 通过交互式编码器(Cross-Encoder)对 Query 和文档做深度语义匹配,输出精细的相关性分数。
4.1 调用示例(阿里云 DashScope)
vbnet
curl --location 'https://dashscope.aliyuncs.com/api/v1/services/rerank/text-rerank/text-rank' \
--header 'Authorization: Bearer <YOUR-API-KEY>' \
--data '{
"model": "gte-rerank-v2",
"input": {
"query": "你好啊,我是 arain",
"documents": [
"Judy 你好,我是 XXX",
"arain 你好,我是 XXX",
"你好,我是 XXX"
]
},
"parameters": {
"return_documents": true,
"top_n": 2
}
}'返回结果:
json
{
"output": {
"results": [
{
"document": {"text": "arain 你好,我是 XXX"},
"index": 1,
"relevance_score": 0.8242
},
{
"document": {"text": "你好,我是 XXX"},
"index": 2,
"relevance_score": 0.1945
}
]
}
}Reranker 能识别句法结构和上下文语义,例如区分 "arain" 作为称呼和作为普通名词的差异,这是 RRF 无法做到的。
五、完整架构:RRF 粗排 + Reranker 精排
生产环境的推荐 Pipeline:
分层设计的理由
| 阶段 | 方法 | 候选数量 | 作用 | 成本 |
|---|---|---|---|---|
| 召回 | 向量 / BM25 / 图检索 | 每路 Top 50 | 高召回、粗覆盖 | 低 |
| 粗排 | RRF | 合并后 Top 20 | 跨路融合、去噪 | 极低 |
| 精排 | Reranker | Top 20 → Top 5 | 语义精细排序 | 高 |
| 生成 | LLM | Top 5 | 最终答案生成 | 最高 |
为什么必须先 RRF 再 Reranker? Reranker 是交互式模型,计算复杂度为 O(N×L)( N 为文档数, L 为文本长度),只能承受少量候选(通常 <100)。直接用 Reranker 对多路召回的并集(可能几百条)做精排,延迟和成本都会爆炸。RRF 作为轻量粗排,先把候选池压缩到可接受范围,是成本与效果的必要折中。
六、什么时候可以省略 Reranker?
博客原文说"仅使用向量匹配的 RAG 没必要用 Reranker",这个结论过于绝对。更准确的判断标准是:
| 场景 | 是否需要 Reranker |
|---|---|
| 单路向量召回,且对延迟极度敏感(如实时客服) | 可以省略 |
| 单路召回,但存在语义相近但无关的陷阱(如多义词、反讽) | 需要 |
| Query 涉及复杂语义关系(否定、条件、比较) | 强烈需要 |
| 高精确性场景(医疗、法律、金融合规) | 必须上 |
| 多路召回后的候选池 >50 条 | 必须上 |
核心原则 :Reranker 不是"多路召回的专属配件",而是任何对排序质量有更高要求时的通用精排层。即使单路召回,如果向量匹配的结果中存在大量"看起来语义相近、实则不相关"的噪声,Reranker 的过滤价值依然显著。
七、工程 Checklist
- 去重:多路召回结果合并前,基于 Chunk ID 去重,保留最高原始分的副本
- 截断:每路召回设置 Top-K 上限(如 50),避免尾部噪声进入融合
- RRF 未命中策略:默认忽略未命中的路;如需强调"多路共识",可赋予惩罚排名(如 1000)
- k 值:无特殊理由,固定为 60
- Reranker 候选控制:输入 Reranker 的文档数建议 20~100,太多会拖慢响应
- 监控:分别统计各路的 Hit@K、RRF 融合后的 NDCG@K、Reranker 后的 NDCG@K,用于持续调优
八、一句话总结
RRF 用排名的倒数做民主投票,公平融合异构召回;Reranker 用语义交互做专家精审,过滤深层噪声。两者分层协作,是 RAG 召回层成本与效果的最优平衡。