一、核心理念:Harness 思维 --- 让 AI 模仿,而不是凭空创造
全栈 AI 开发最容易踩的坑
全栈 SDD 开发中,最常见也最致命的错误是:让 AI 从零开始写代码。AI 模型具备"通识能力",给它一个需求描述,它确实能生成可运行的代码。但问题在于,这些代码往往是"外星代码":风格不一致 (命名规范、目录结构、分层方式与项目现有代码不同)、复用率低 (没有利用项目已有的公共组件、工具函数、请求封装)、采纳率低(Code Review 时后端同学看到"外来风格"的代码,会产生大量修改意见)。结果就是:AI 生成了代码,但 Review 成本和返工成本反而更高了。
Harness 思维的核心:给 AI 一个"模仿对象"
Harness(约束)思维的本质是:给 AI 一个已有的实现作为参照,让它照着复刻一份,而不是凭空创造。就像给一个新入职的工程师说"你照着这个模块的风格,写一个类似的",而不是"你自由发挥"------前者往往能更快产出符合团队规范的代码。

在提示词中体现 Harness
不推荐(凭空创造):
请实现一个结束语管理的 CRUD 接口推荐(Harness 约束):
bash
请参照现有"场景欢迎语"功能(后端接口 /api/v1/feature/list,前端入口 FeatureTable/index.tsx:53-58)实现"结束语"功能。数据结构、分层方式、命名风格都保持一致。新增场景 code:categoryCode = "SCENARIO_CLOSING"两者的差距不在于 AI 是否"聪明",而在于你给了 AI 多少约束和上下文。约束越精准,生成代码的可用性越高。
二、全栈工作区搭建与 Codebase Indexing
为什么要搭多仓工作区?
前后端代码通常分布在两个独立仓库。如果分开打开,AI 生成后端接口时看不到前端的调用方式,生成前端代码时看不到后端的返回结构,接口字段对不上是家常便饭。将前后端代码放在同一个工作区下,有三个核心价值,Codebase Indexing :Cursor 对工作区内所有代码进行向量化嵌入,建立语义索引。AI 能跨仓库理解代码关系,生成质量大幅提升。上下文完整 :AI 同时能看到前后端代码,接口字段、命名风格自然对齐。SDD 文档集中管理:前后端 SDD 文档在同一工作区,便于接口契约对齐。
Codebase Indexing 的价值
Cursor 的 Codebase Indexing 会对工作区内的代码进行向量化嵌入,建立语义索引。这意味着:当你问 AI "场景欢迎语是怎么实现的",它不需要你手动指定文件,能通过语义检索自动找到相关的 Controller、Service、前端组件。当你让 AI "照着欢迎语写结束语",它会检索到欢迎语的前后端完整实现链路,而不只是单个文件。
前后端放在同一个工作区,Codebase Indexing 覆盖两侧代码。AI 生成后端接口时能参考前端的调用方式,生成前端代码时能参考后端的返回结构。
Tips:Cursor 打开工作区后,首次索引可能需要几分钟。可以在 Cursor 设置查看索引进度。确保索引完成后再开始让 AI 生成代码,效果会明显更好。
Cursor vs Claude Code:选哪个?
在全栈 AI 开发场景下,两款工具各有侧重,下表是实测对比:
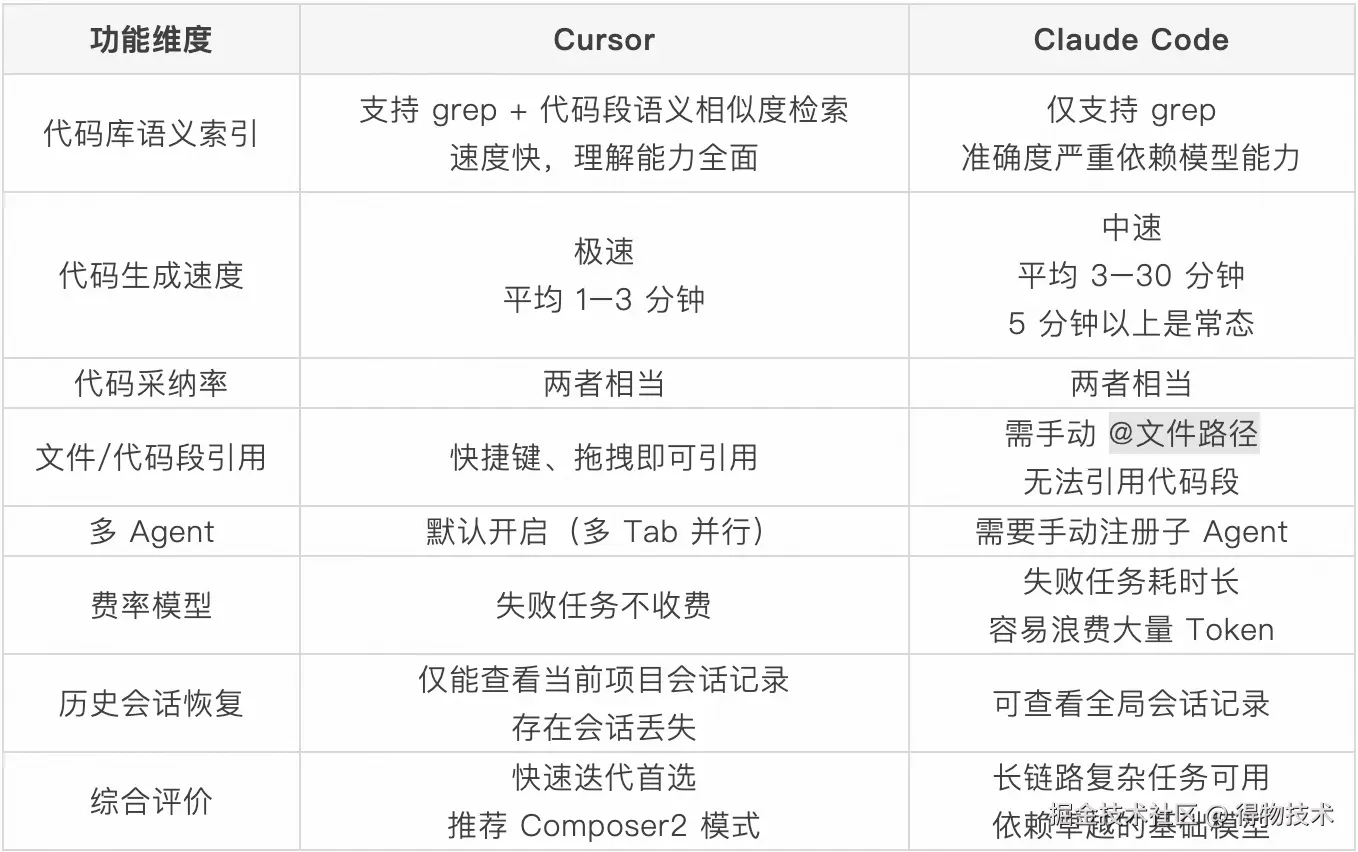
全栈工作区搭建&SDD初始化--内部全栈研发插件
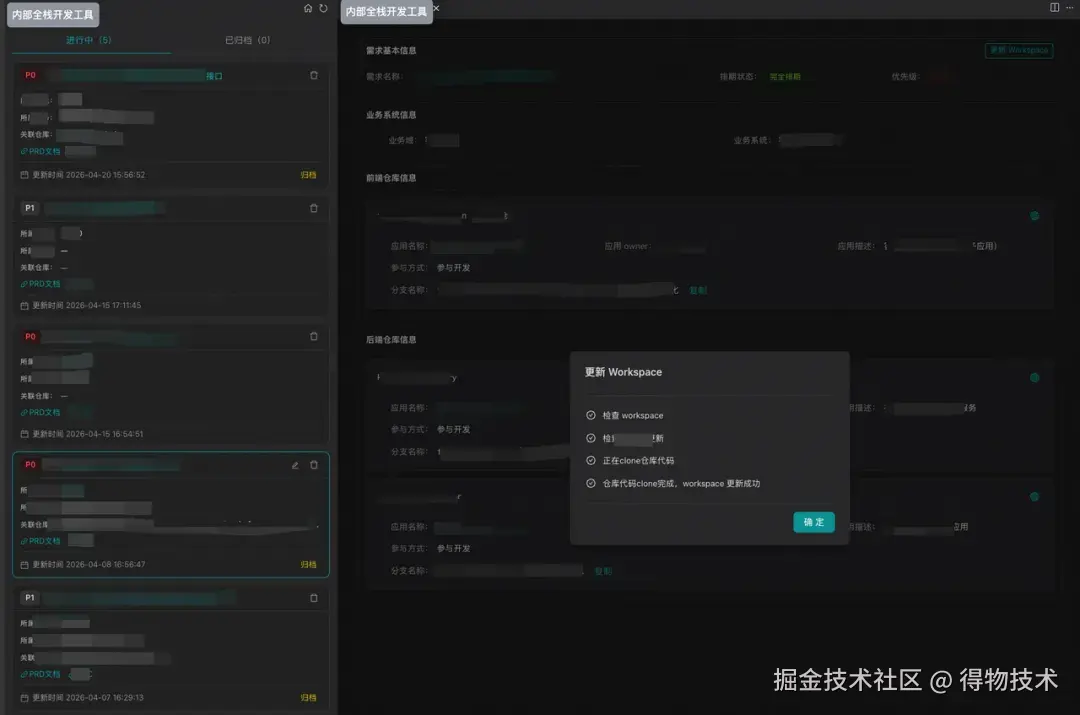
以上述需求为例,工作区结构如下,.claude 和 .cursor 中已对 SDD 能力进行初始化。
三、SDD 驱动的全栈代码生成流程
全栈 SDD 的特殊之处
与纯前端/纯后端 SDD 不同,全栈 SDD 需要:生成两份 SDD 文档 (前端一份、后端一份);接口契约对齐 ,前端 SDD 中的接口调用与后端 SDD 中的接口定义必须严格对应;字段映射一致,前端 VO 中的字段名与后端返回的 JSON 字段名一一对应。

相关概念术语
提示词编写范式
以下是经过实践验证的全栈 SDD 生成提示词模板:
bash
这是一个前后端全栈开发工作区,需要你设计技术接口方案,同时开发前后端项目;首先你需要 cd 到对应前后端应用目录中,创建 sdd 文件;所以你需要生成两份 sdd 文档,之后我会启动两个 agent 分别实现;在生成之前,如果你需要确认某些细节,你应当先确认后生成 sdd 文档。前端应用:service-frontend/sdd-propose feature/your-feature-name前端修改入口参考:@FeatureTable/index.tsx:53-58 @columns/index.tsx后端应用:service-backend/sdd-propose feature/your-feature-name后端修改入口参考接口:/api/v1/feature/list需求内容:(附上需求文档或描述,并提供前后端需求点清单)关键要素解读:

前后端需求点清单分工示例
前端需求功能点
主要是新增一个后台管理页面的 tab,涉及到搜索、展示、配置新增、删除等;利用内部 SDD 文档工具(如下图)从 PRD 描述和文档图片中提炼出需求点。
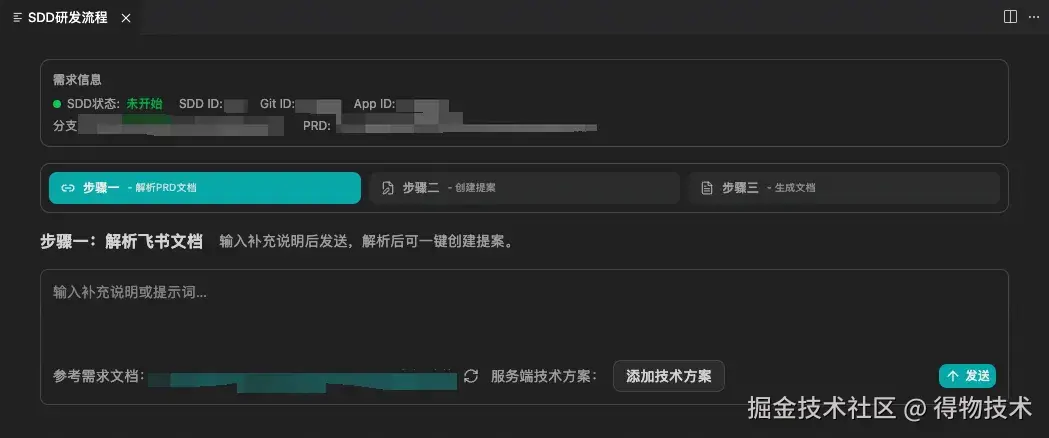
内部 SDD 文档工具
左侧导航新增"结束语" Tab。 右侧新增结束语列表页。 字段有:结束语内容、结束语描述、优先级、更新人、更新时间、操作列。
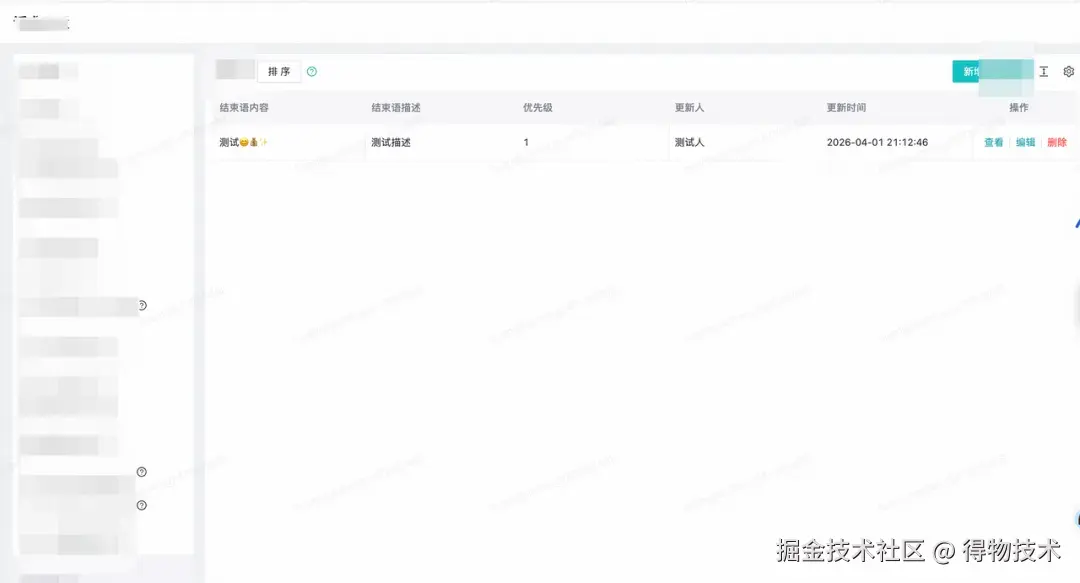
新增 / 编辑弹窗字段:结束语描述、生效日期、生效时段、生效时段、结束语话术(类型和规则这里不一一罗列)。
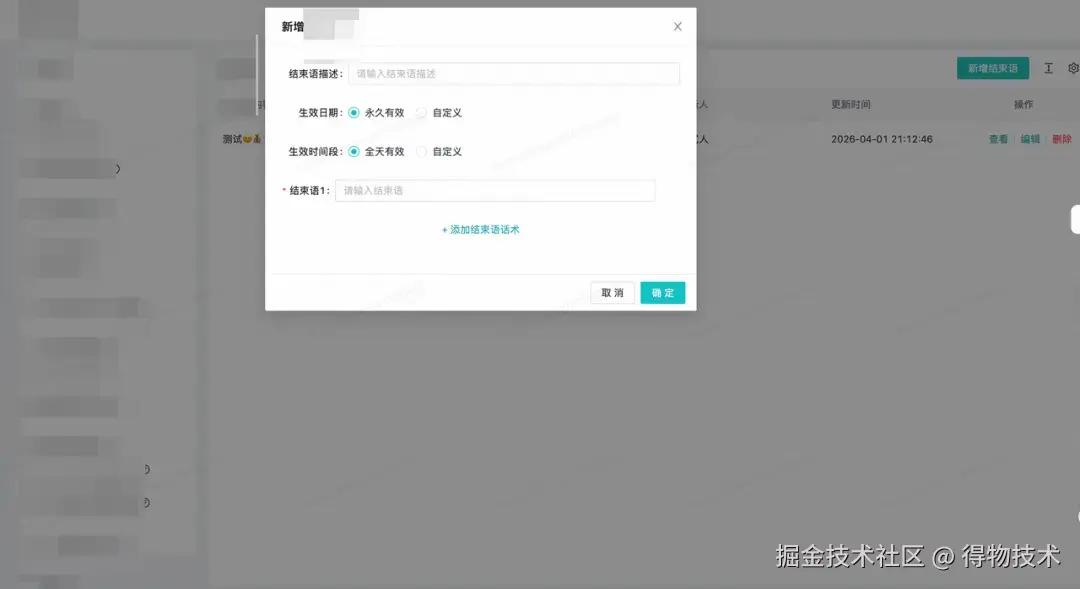
拖拽排序功能: 点击"排序"按钮进入排序状态,拖拽调整顺序后点击"保存"生效。
后端功能点(含接口清单)
后端功能由 AI 根据前端需求描述自主设计数据表和接口。以下是 AI 在生成 SDD 前需要明确的关键设计问题(这些问题应在提示词中列出,让 AI 先回答再生成)。
接口清单: 列表接口(支持分页,回显数据直接嵌入列表响应,无需单独回显接口)、新增接口、编辑接口(复用新增逻辑,根据 id 更新)、删除接口(逻辑删除,修改删除状态字段)、排序接口(批量更新,需考虑高效实现方案)。
字段设计: 结束语话术内容(数组类型)、结束语描述(文本)、优先级 / 序号(小整型)、更新人(字符串)、更新时间(时间戳)。
需要 AI 在 SDD 中明确回答的设计问题:
- 主键设计:如何设计主键字段?前端发起编辑、删除时需要传递该字段。
- 优先级自增逻辑:优先级应基于当前数据条数自增,无需前端传递,由后端自动处理。
- 排序如何高效更新:批量排序时如何设计接口,避免 N 次单条更新?
- 嵌套对象如何建表:参考已有的"场景欢迎语"接口,入参中存在嵌套子对象(如下方参考结构)。此类子对象应拆分到多张表,还是序列化为 JSON 字段存单张表?
- isNextDay 字段含义:次日逻辑的具体含义是什么?前端时段选择器中"次日"勾选状态如何映射到该字段?
- 列表回显设计:列表接口需要返回完整的回显数据(供编辑弹窗回填),无需单独提供详情接口。
为什么要把这份清单放进提示词?
这份清单做了两件重要的事:前端侧 给 AI 完整的 UI 细节,让 AI 知道组件状态、字段约束、交互逻辑,避免它做"最简实现"。后端侧把模糊的设计问题提前暴露,让 AI 在写 SDD 之前先回答这些问题------这正是 Harness 思维的体现:让 AI 参照已有实现(如"欢迎语")来解决"结束语",而不是凭空设计。
SDD 文档产出
一次完整的全栈 SDD 生成,会产出以下文档:
前端 SDD:
- proposal.md --- 需求提案,描述前端要做什么。
- spec.md --- 技术规格,组件设计、接口调用、状态管理。
- tasks.md --- 任务拆分,每个 task 对应一个可执行的代码变更。
后端 SDD:
- proposal.md --- 需求提案,描述后端要做什么。
- spec.md --- 技术规格,接口设计、数据库设计、分层架构。
- design.md --- 详细设计,类图、字段映射、SQL。
- tasks.md --- 任务拆分。
SDD 指令使用说明
典型工作流示例
入门引导:
- openspec-onboard(首次,不熟悉才走,引导完整步骤);
- openspec-continue-change(提示你下一步要干嘛);
- openspec-ff-change(快进)。
场景 A:初次开发
- openspec-explore(调研,脑暴);
- openspec-propose "..."(生成设计);
- openspec-apply-change(写代码);
- openspec-verify-change(自测,校验代码与 SDD 文档是否对应);
- openspec-archive-change(收尾,归档)。
场景 B:二次开发,修改迭代已有功能
- openspec-explore(定位旧代码/旧 spec);
- openspec-propose "修改..."(生成变更 Spec);
- openspec-apply-change(应用修改);
- openspec-verify-change(验证回归);
- openspec-archive-change(归档)。
场景 C:二次修改,需求变更
- openspec-explore(调研,脑暴);
- openspec-propose "..."(生成设计);
- openspec-apply-change(写代码);
- 发现有问题就用 openspec-explore 修改提案;
- openspec-explore "需求变更:xxx"(二次脑暴);
- openspec-propose "根据探索结果修改提案";
- openspec-apply-change(执行提案中变更内容);
- 【可选】openspec-verify-change(验证是否有未完成任务);
- openspec-archive-change(归档)。
场景 D:季度大清理
- openspec-bulk-archive-change --before 2023-12-31(批量归档)。
总的来说,上述相对来说还是比较繁琐,保持最简使用:想(openspec-propose)、做(openspec-apply-change)、收(openspec-archive-change) 即可。
四、多 Agent 协作:前后端并行开发
为什么需要多 Agent
SDD 文档生成完毕后,前后端的代码生成工作是相互独立的------前端根据前端 SDD 生成组件和页面,后端根据后端 SDD 生成 Controller/Service/Repository。这天然适合并行执行。
Cursor 中的多 Agent 协作
Cursor 支持多个 AI 编程模式并行工作,这是其核心优势之一。全栈开发场景下Tab 1 负责前端代码生成,Tab 2 负责后端代码生成,两个 Agent 同时运行、互不阻塞。
Claude Code 中的 Subagent 能力
Claude Code 内置了 Subagent(子代理)机制,适合命令行场景下的多任务并行。
Subagent 模式
Claude Code 提供了两种多 Agent 协作模式。(下个迭代再实践一下 Team 模式和普通 Subagent 的差别)
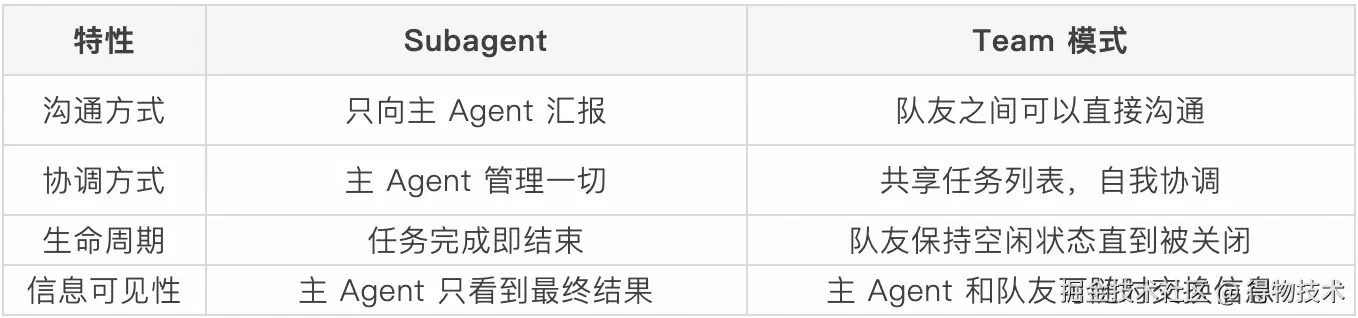
Subagent 配置与使用
Subagent 的核心配置项:
json
{ "description": "前端代码生成专家", "tools": ["Read", "Edit", "Write", "Bash", "Grep"], "permissionMode": "bypass", "model": "sonnet", "skills": ["前端编码规范"]}全栈开发场景中的应用:
yaml
主 Agent(你在对话的 Claude Code) ├── Subagent 1:读取前端 SDD,生成前端代码 │ ├── model: sonnet │ ├── tools: Read, Edit, Write, Bash │ └── 任务:按照 tasks.md 生成前端组件 │ ├── Subagent 2:读取后端 SDD,生成后端代码 │ ├── model: sonnet │ ├── tools: Read, Edit, Write, Bash │ └── 任务:按照 tasks.md 生成后端接口 │ └── Subagent 3:(可选)生成接口 Mock 数据 ├── model: haiku └── 任务:根据后端 SDD spec.md 生成 Mock多 Agent 实践建议

五、前后端联调:Mock 数据与分阶段验证
三阶段验证策略
直接联调往往是效率最低的验证方式,推荐采用三阶段分离验证:
python
阶段 1:前端 Mock 验证 前端代码 + Mock 数据 → 本地跑通页面交互,验证 UI 逻辑阶段 2:后端独立验证 后端代码 → mvn clean compile → 构建通过 → 部署到测试环境阶段 3:前后端联调 前端连接测试后端接口 → 端到端验证这样做的好处是:前后两端的问题可以提前发现、分别修复;避免在联调阶段才暴露;节省大量排查时间。
Mock 数据编写要点
Mock 数据质量直接决定前端自测的有效性,有三个关键要求:字段名和字段类型必须与后端 SDD 中定义的完全一致;参考已有接口的真实返回数据作为模板,而不是随意构造;覆盖边界场景(空列表、单条数据、多条数据、各字段极值如空字符串、超长字符串、null 值等)。
后端独立构建验证
后端代码不需要在本地完整启动整个 Java 服务,只需编译通过即可验证大部分代码问题。
shell
# 切换到 Java 8 环境(根据项目实际 JDK 版本调整)sdk use java 8# 进入后端项目目录cd service-backend# 编译验证(无需本地启动整个服务)mvn clean compile编译通过意味着:语法正确、依赖关系正确、类型兼容,是部署前最快速的验证手段。
前后端联调步骤
后端代码提交并部署到测试环境;前端本地开发服务通过代理配置,将 API 请求指向测试后端地址;前端请求携带功能路由标识,确保请求路由到对应的测试环境(而不是其他人的环境);逐接口验证,重点关注字段映射、状态处理、错误场景。
六、警惕 SDD 陷阱:测试如何介入全栈研发
SDD 不等于需求文档
这是 AI 全栈开发中最容易被忽视的问题。SDD 描述的是 "技术上怎么实现" ,而不是 "业务上所有的行为" 。AI 在模仿参考代码生成新代码时,会自动复刻很多隐性功能------这些功能在参考代码中存在,AI 认为是"理所当然"的,所以没有写进 SDD 文档,但实际上已经悄悄实现了。
隐性功能示例
示例 1:变量/表单清除(前端)
ini
// AI 模仿欢迎语弹窗生成结束语弹窗时,自动复刻了"关闭弹窗时清空表单"的逻辑const handleClose = () => { form.resetFields(); // ← 隐性功能:关闭时清空表单字段 setContentList([]); // ← 隐性功能:清空内容列表状态 setVisible(false);};示例 2:数据格式转换(后端)
vbscript
// AI 模仿已有接口,自动添加了业务逻辑判断if (extendInfo.getIsPermanent()) { extendInfo.setEffectiveDate(null); // ← 隐性:永久有效时自动清除开始日期 extendInfo.setExpirationDate(null); // ← 隐性:永久有效时自动清除结束日期}示例 3:默认值补齐(后端)
perl
// AI 自动实现了"优先级自增"逻辑,SDD 文档中未提及if (Objects.isNull(req.getSequence())) { req.setSequence(getMaxSequence() + 1); // ← 隐性:新增时优先级自动递增}这些隐性功能可能正是需要的,也可能完全不符合当前需求。问题在于你不知道它们的存在。
测试介入建议

给测试同学的实操建议:把 SDD 文档当作起点,而不是终点。重点 Review AI 生成的代码,问自己一个问题:"参考功能有哪些隐性行为?这些行为在新功能中是否合适?"
七、综合效益与总结
实践效益
通过本文介绍的"Harness + SDD + 多 Agent"全栈开发方法论,在实际项目中验证的效益如下:采纳率提升 ,相比传统前后端分离开发,工作区模式可以很好地把项目需求上下文放到一起,更便于 AI 理解需求,设计编码;尤其通过Cursor的索引能力,进一步提高采纳率以及功能实现的完整性。耗时降低 ,SDD 模式下,AI 分析需求后产生两套 SDD 文档,使得前后端开发完全可以并行;以本需求为例,原本前后端2+4人日需求,在这种模式下,算上环境准备、踩坑时间、联调自测时间,压缩至3人日,提效50%+。调试环节不依赖阻塞 ,前端功能在全栈开发的视野下,已知数据结构可mock数据自测;后端功能通过远程调试的方式,支持本地打点调试;最终一并上测试环境验证,能够明确知道问题来自于前端还是后端;AI 全栈学习成本骤降,只需掌握入门级别前后端知识,即可介入简单全栈需求开发;提高业务域需求吞吐率。
方法论总结
本文介绍的全栈 AI 开发方法论,核心可以用一张图概括:
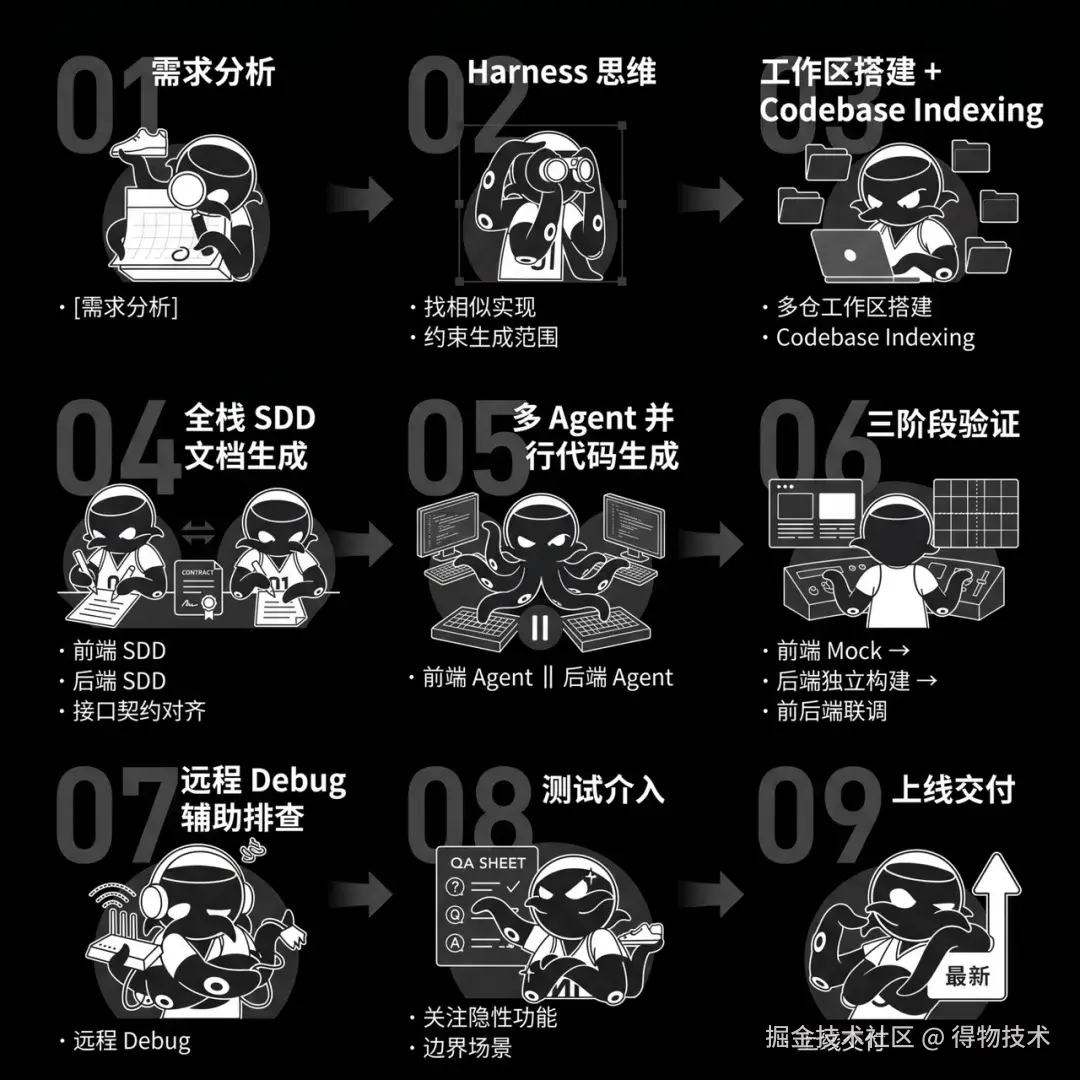
本文基于实际全栈开发项目经验整理,所有代码示例已脱敏处理,使用通用命名替代业务专有名词,如有问题欢迎交流探讨。
往期回顾
1.通用 AI Agent 驱动网关路由安全审计实践|得物技术
2.AI驱动:从运营行为到自动化用例的智能化实践|得物技术
3.生成式召回在得物的落地技术分享与思考
4.立正请站好:一个组件复用 Skill 的工程化实践|得物技术
5.财务数仓 Claude AI Coding 应用实战|得物技术
文 /盖伦
关注得物技术,每周更新技术干货
要是觉得文章对你有帮助的话,欢迎评论转发点赞~
未经得物技术许可严禁转载,否则依法追究法律责任。