1. 什么是 Rerank?
Rerank(重排序) 是 RAG(检索增强生成)系统中的一种优化技术,用于提升检索精度。它采用两阶段检索架构:
第一阶段(粗排):使用向量检索快速获取大量候选文档(如 topK=200)
第二阶段(精排):使用专门的重排序模型对候选文档进行精确评分和重新排序
Rerank 的核心价值
✅ 提升检索精度:通过专业化模型更准确地评估文档相关性
✅ 解决语义漂移:深度理解查询和文档的完整上下文
✅ 优化排序质量:将最相关的文档排在前面
✅ 过滤低质量文档:通过分数阈值过滤不相关内容
2. 为什么需要Rerank?
为什么一个Embedding模型还不够,还需要再加一个Rerank模型?
下图为Embedding模型的缺点:
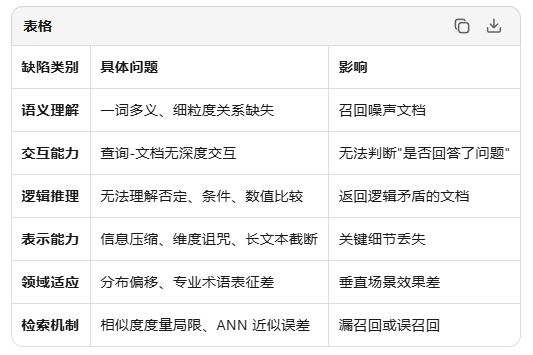
其中最主要的原因就是,查询与文档缺乏深度交互(Bi-Encoder 的先天局限)
Bi-Encoder是将查询的问题和文档分别编码,文档是提前已经编码好存储在向量库中,然后将问题进行编码,计算问题向量和文档片段向量之间的余弦相似度,最后返回相似度最高的TOP N个文档片段。
造成的结果:Embedding 无法判断"查询中的关键词是否在文档中被充分回答"。
如何解决Embedding模型带来的问题呢,以下是解决方案
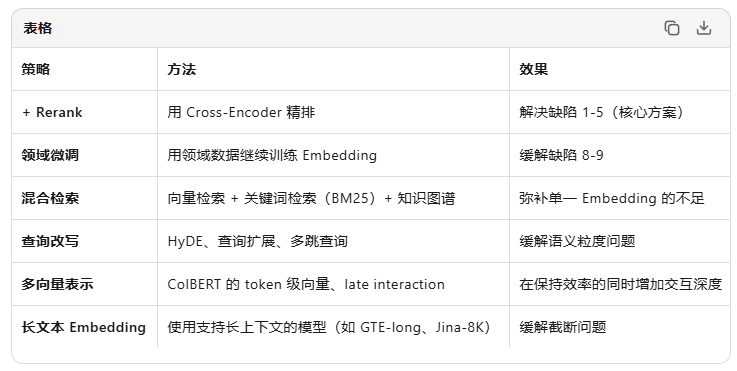
其中rerank模型能够解决以下问题

3. rerank的原理
Rerank 是一个交叉编码器(Cross-Encoder) ,它同时接收查询和文档,进行深度交互后输出相关性分数。
查询和文档一起输入模型,在 Transformer 内部进行 token 级别的交叉注意力计算。
单独用 Embedding 的问题:
-
向量相似度是"浅层匹配",无法理解复杂的查询意图
-
例如查询"苹果的价格",可能召回"苹果公司的股价"和"水果店苹果的价格",Embedding 难以区分
单独用 Rerank 的问题:
-
无法直接对海量文档逐一打分(计算量太大)
-
必须有候选集才能工作

4. 其他优化策略


