当 DigitalOcean VPC 发生网络故障时,若每位响应人员都遵循相同的诊断顺序而非即兴发挥,问题就能更快得到解决。本教程将引导你构建一个可复用的 runbook,用于应对常见的 VPC 故障,使用的工具包括 ping、traceroute、tcpdump、nmap、dig、nslookup、nmcli、ss 和 curl,并展示如何将最具重复性的检查步骤自动化,转化为 DigitalOcean Functions。
runbook 能够消除故障排查过程中的臆测。每位响应人员都从同一层开始,运行相同的命令,并生成相同的证据。这种一致性在关键故障中至关重要,因为响应人员必须先将 Cloud Firewall 拦截与 Droplet 云服务器 内部防火墙拦截区分开来,才能进行升级处理。
在本教程中,你将学习如何诊断 VPC 连接故障、区分 Cloud Firewall 与 Droplet 内部防火墙的拦截,以及构建一套结构化的网络故障排除 runbook。
核心要点
- 判断 Cloud Firewall 还是 Droplet 内部防火墙在拦截流量的最快方法:若目标接口的
tcpdump完全没有显示数据包,则为 Cloud Firewall 层面的拦截;若能看到数据包但无响应,则为 Droplet 内部的拦截。 - 按照固定的层级顺序运行诊断工具:先检查可达性,再进行数据包捕获,接着检查端口状态,然后是 DNS,最后是应用层。在未确认底层状况前就跳至更高层,若底层故障掩盖了真实症状,则会浪费时间。
- 当 Cloud Firewall 拦截 ICMP 时,必须使用
nmap -Pn。否则,即使主机可通过 TCP 连接,nmap也会报告所有主机均处于关闭状态。 - 使用
systemd-resolved的 Ubuntu 24.04 Droplet 会在/etc/resolv.conf中显示127.0.0.53,而非直接显示 DigitalOcean 的解析器 IP。运行resolvectl status eth1可查看实际使用的上游解析器。 - 具备结构化输入和输出(IP 地址、端口、DNS 名称)的 runbook 步骤,适合转化为 DigitalOcean Functions(云函数),并可注册为 AI Platform agent 中可调用的函数路由。
前提条件
开始学习本教程前,你需要准备:
-
两台或更多运行 Ubuntu 22.04 或更高版本的 Droplet,且位于同一 DigitalOcean VPC 中。
-
一个已关联到至少一个 Droplet 的 DigitalOcean Cloud Firewall。
-
一个至少指向一个后端 Droplet 的 DigitalOcean 负载均衡器(可选,步骤 5 和 Runbook 条目 2 必需)。
-
所有测试 Droplet 上的
sudo权限。 -
所有 Droplet 上安装
tcpdump、nmap、dnsutils、traceroute、iproute2、net-tools、curl和jq。安装命令如下:bashsudo apt update sudo apt install -y tcpdump nmap dnsutils traceroute iproute2 net-tools curl jq运行
tcpdump --version和nmap --version确认安装是否成功。两条命令都应返回版本号字符串,而非 "command not found"。
理解 DigitalOcean VPC 网络基础
如果你能先理清数据包路径控制、接口范围和健康检查流程,再查看日志,那么排查 DigitalOcean VPC 故障的速度会更快。
Cloud Firewall 与 Droplet 内部防火墙
Cloud Firewall 在虚拟机管理程序层面过滤流量,数据包在到达 Droplet 接口之前就被处理了。而 ufw、iptables 或 nftables 等 Droplet 内部工具,则是在数据包到达后,于操作系统内部运行。
这一区别决定了你的整个诊断路径:
- 如果预期数据包未出现在目标接口的
tcpdump中,应优先排查 Cloud Firewall 策略。 - 如果
tcpdump中能看到数据包,但应用没有响应,则应排查 Droplet 内部的防火墙规则、服务绑定或进程健康状态。
这两层可以同时生效,且各自独立执行规则。
使用以下步骤检查和修改 Cloud Firewall 规则。使用 doctl 列出 Cloud Firewall 上的所有入站规则:
yaml
doctl compute firewall list
ID Name Status Created At
a1b2c3d4-0000-0000-0000-111122223333 vpc-firewall succeeded 2026-01-10T09:00:00Z从第一列复制你要检查的防火墙 ID。以下命令将使用此 UUID 获取完整的规则集。
使用防火墙 ID 获取其完整规则集:
vbnet
doctl compute firewall get a1b2c3d4-0000-0000-0000-111122223333
ID: a1b2c3d4-0000-0000-0000-111122223333
Name: vpc-firewall
Status: succeeded
Inbound Rules:
Protocol Ports Sources
tcp 22 0.0.0.0/0
tcp 80 0.0.0.0/0如需添加一条缺失的入站规则,允许来自特定 Droplet 的 TCP 流量访问端口 5432,请将 <FIREWALL_ID> 替换为先前 doctl compute firewall list 命令返回的 ID,将 <DROPLET_ID> 替换为源 Droplet 的 ID,运行以下命令:
csharp
doctl compute firewall add-rules <FIREWALL_ID> \
--inbound-rules "protocol:tcp,ports:5432,droplet_id:<DROPLET_ID>"你也可以在 DigitalOcean 控制面板的 "Networking" > "Firewalls" 页面管理规则。选择防火墙,进入 "Inbound Rules" 标签页,添加所需的协议、端口范围和来源。
注意:Cloud Firewall 规则更改无需重启 Droplet 或服务即可生效。
使用以下步骤检查和修改 Droplet 内部防火墙规则。如果 tcpdump 确认数据包已到达但服务无响应,请检查 ufw 状态和活动规则:
vbnet
sudo ufw status verbose
Status: active
Logging: on (low)
Default: deny (incoming), allow (outgoing), disabled (routed)
To Action From
22/tcp ALLOW IN Anywhere
80/tcp ALLOW IN Anywhere检查 "To" 和 "Action" 列。此处未列出的任何端口都将被默认阻止。如果你服务使用的端口不在其中,请使用以下命令添加。
bash
sudo ufw allow 5432/tcp若未使用 ufw,则检查原始 iptables 规则:
sql
sudo iptables -L INPUT -n -v
Chain INPUT (policy DROP 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
1243 156K ACCEPT all -- lo * 0.0.0.0/0 0.0.0.0/0
892 87K ACCEPT tcp -- * * 0.0.0.0/0 0.0.0.0/0 tcp dpt:22
45 2700 ACCEPT tcp -- * * 0.0.0.0/0 0.0.0.0/0 tcp dpt:80
0 0 DROP tcp -- * * 0.0.0.0/0 0.0.0.0/0 tcp dpt:5432在上面的输出中,端口 22 和 80 的 ACCEPT 规则允许这些服务通过,而端口 5432 的 DROP 规则则阻止 PostgreSQL 流量,使其无法到达应用。如果你的服务端口前没有 ACCEPT 规则,而是直接出现 DROP,则意味着 Droplet 内部防火墙正在拦截流量,使其无法到达应用。
VPC 私有接口与公共接口
VPC 流量通过私有接口传输,通常是 eth1,在较新的、基于 networkd 的镜像上则是 ens4。在错误的接口上进行捕获,会产生虚假的阴性结果,因此务必在运行任何数据包捕获前,确认接口的命名。
负载均衡器健康检查
负载均衡器的可用性取决于能否成功对后端 Droplet 进行健康检查。当进程绑定到错误的接口、本地防火墙规则阻止探测流量,或健康检查路径返回非 2xx 状态码时,后端将无法通过健康检查。这种故障模式的诊断步骤将在步骤 5 中介绍。
必备的网络故障排除工具
将每个工具映射到相应的故障排除层,并按固定的顺序使用,从网络堆栈的底部向上进行。
| 工具 | 用途 | 层级 |
|---|---|---|
ping |
验证基本的 ICMP 可达性和数据包丢失情况 | 网络层 |
traceroute |
识别跳数路径和路由变更 | 网络层 |
nmcli |
检查连接配置文件和 DNS 设置 | 主机网络配置 |
tcpdump |
在接口和端口上捕获数据包级别的证据 | 网络层/传输层 |
nmap |
测试端口暴露和服务状态 | 传输层/应用层 |
ss |
确认本地监听套接字和进程绑定 | 主机传输层 |
dig |
查询 DNS 解析器并检查响应元数据 | 应用层 |
nslookup |
跨解析器快速比较 DNS 查询结果 | 应用层 |
curl |
验证 HTTP/S 端点行为和标头 | 应用层 |
步骤 1 - 使用 ping 和 traceroute 验证基本可达性
首先确认路径存在和丢包概况,因为在路由修复之前,可达性故障会导致后续的服务层面检查失去意义。
python
ping -c 4 10.116.0.22
PING 10.116.0.22 (10.116.0.22) 56(84) bytes of data.
64 bytes from 10.116.0.22: icmp_seq=1 ttl=64 time=0.512 ms
64 bytes from 10.116.0.22: icmp_seq=2 ttl=64 time=0.489 ms
64 bytes from 10.116.0.22: icmp_seq=3 ttl=64 time=0.476 ms
64 bytes from 10.116.0.22: icmp_seq=4 ttl=64 time=0.501 ms
--- 10.116.0.22 ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 3063ms
rtt min/avg/max/mdev = 0.476/0.494/0.512/0.013 ms如果 ping VPC 私有 IP 失败,请验证你的 Cloud Firewall 入站规则是否允许来自源 Droplet IP 或标签的 ICMP 流量。默认情况下,除非显式添加为入站规则,否则 ICMP 是不被允许的。
如果数据包丢失率高或完全无法 ping 通,运行 traceroute 来识别流量在何处分叉:
arduino
traceroute -n 10.116.0.22
traceroute to 10.116.0.22 (10.116.0.22), 30 hops max, 60 byte packets
1 10.116.0.22 0.372 ms 0.334 ms 0.297 ms在健康的 VPC 中,Droplet 之间的流量通常一跳即达,但 traceroute 的输出可能因路径上的 ICMP 处理方式而异。如果看到多跳或重复的 * * * 响应,请使用以下指南解释输出:
arduino
traceroute to 10.116.0.22 (10.116.0.22), 30 hops max, 60 byte packets
1 * * *
2 * * *
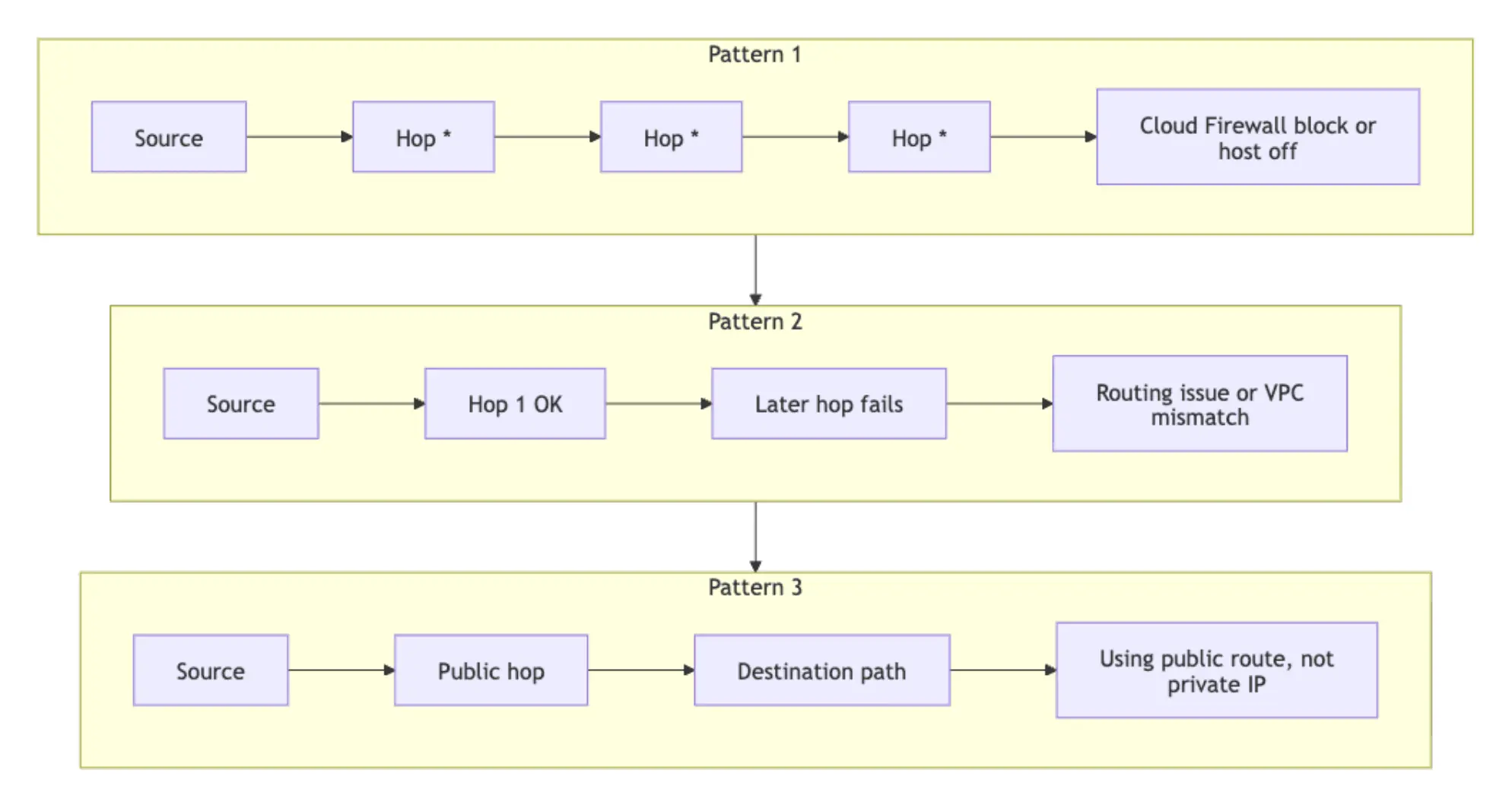
3 * * *所有跳数均返回 * * *:目标未响应 ICMP,且没有中间跳数回复。这可能表明 Cloud Firewall 正在拦截、目标已关机,或者路径上的 ICMP 回复被抑制。请在得出结论前使用 tcpdump 和防火墙检查进行确认。 第一跳有响应,但后续跳数无响应:流量已离开源端,但未能到达目的地。请检查两个 Droplet 是否在控制面板中被分配到同一个 VPC。 第一跳的 IP 既不是目标地址,也不在 VPC CIDR 范围内:流量正通过公共接口路由,而非 VPC 私有接口。请确认目标 IP 是私有 IP,而非公网 IP。 下图展示了防火墙拦截、路由或 VPC 不匹配以及公网路由错误情况下的 traceroute 故障模式。
对于使用 NetworkManager 的主机,可通过一条命令验证活动配置文件、接口状态和 DNS 设置:
bash
nmcli device show eth1
GENERAL.DEVICE: eth1
GENERAL.STATE: 100 (connected)
IP4.ADDRESS[1]: 10.116.0.12/20
IP4.GATEWAY: --
IP4.DNS[1]: 67.207.67.2
IP4.DNS[2]: 67.207.67.3如果 eth1 显示的状态不是 connected,则说明 VPC 私有接口未处于活动状态。这通常意味着 Droplet 在创建时未分配 VPC,或者接口在操作系统内被手动禁用。
步骤 2 - 使用 tcpdump 捕获数据包
当 ping 测试通过但服务仍然失败时,tcpdump 是下一步。数据包捕获可以清晰地回答两个问题:流量是否到达了目标接口,以及 TCP 握手是否真正完成。
首先在 VPC 接口上进行单接口捕获:
perl
sudo tcpdump -ni eth1
tcpdump: verbose output suppressed, use -v[v]... for full protocol decode
listening on eth1, link-type EN10MB (Ethernet), snapshot length 262144 bytes
15:03:11.101252 IP 10.116.0.12.53342 > 10.116.0.22.80: Flags [S], seq 249715243, win 64240, length 0
15:03:11.101406 IP 10.116.0.22.80 > 10.116.0.12.53342: Flags [S.], seq 94735512, ack 249715244, win 65160, length 0
15:03:11.101421 IP 10.116.0.12.53342 > 10.116.0.22.80: Flags [.], ack 1, win 502, length 0-ni 标志组合表示禁用反向 DNS 查找并指定接口。需要识别的 TCP 标志:
S是 SYN:客户端发起连接。S.是 SYN-ACK:服务器确认并响应。.是 ACK:客户端确认,会话建立。R是 RST:通常表示无监听程序、主动拒绝或策略重置。F是 FIN:会话正常关闭。
使用更精确的过滤器以减少故障排查时的干扰。
按源 IP 过滤,隔离来自特定 Droplet 的流量:
css
sudo tcpdump -ni eth1 src 10.116.0.12按端口过滤,查看特定服务的所有流量,无论源:
sudo tcpdump -ni eth1 port 443组合两个过滤器,将捕获范围限定到特定的源和端口对:
arduino
sudo tcpdump -ni eth1 'src 10.116.0.12 and port 443'将捕获结果保存到 PCAP 文件,以供后续比对或 Wireshark 分析:
vbnet
sudo tcpdump -ni eth1 port 443 -w incident-443.pcap
tcpdump: listening on eth1, link-type EN10MB (Ethernet), snapshot length 262144 bytes
128 packets captured
128 packets received by filter
0 packets dropped by kernel直接从捕获输出中测量 SYN 到 SYN-ACK 的握手延迟。-tt 标志输出原始的 Unix 时间戳,下面的 awk 脚本利用这些时间戳计算 SYN 数据包与其匹配的 SYN-ACK 之间的时间差。为避免混淆到同一主机的并发连接,脚本使用 TCP 的两个端点作为查找键:SYN 的 $3 和 $5,以及 SYN-ACK 的反向对。gsub 调用会去除地址字段末尾的冒号,以兼容旧版(4.9.x,会添加冒号)和新版(4.99.x,不添加冒号)的 tcpdump。
ini
sudo tcpdump -tt -ni eth1 'tcp[tcpflags] & (tcp-syn|tcp-ack) != 0 and port 443' | awk '
{gsub(/:$/, "", $3); gsub(/:$/, "", $5)}
/Flags \[S\]/ {key=$3 " " $5; if (!(key in syn)) syn[key]=$1}
/Flags \[S\.\]/ {key=$5 " " $3; if (key in syn) {print "Handshake latency:", ($1-syn[key])*1000, "ms"; delete syn[key]}}'
Handshake latency: 0.281572 ms
Handshake latency: 0.295401 ms
Handshake latency: 0.263208 ms步骤 3 - 使用 nmap 探测端口和服务状态
在 tcpdump 确认数据包到达主机后,使用 nmap 确定具体端口的服务状态。
默认的 nmap 扫描依赖于 ICMP 回复和 TCP 响应来发现主机。当 Cloud Firewall 拦截 ICMP 时,必须使用 -Pn 标志跳过主机发现,直接进行端口扫描:
bash
sudo nmap -Pn -p 22,80,443 10.116.0.22
Nmap scan report for 10.116.0.22
Host is up (0.00070s latency).
PORT STATE SERVICE
22/tcp open ssh
80/tcp filtered http
443/tcp closed https统一解读端口状态,并根据每个状态采取下一步行动:
open:应用已接受连接。进入应用层检查。filtered:探测被防火墙阻止或丢弃。进入 Cloud Firewall 和路由检查。closed:主机可达,但没有进程在该端口监听。进入服务启动和绑定地址检查。
当涉及 DNS 或其他基于 UDP 的协议时,运行 UDP 扫描:
bash
sudo nmap -sU -Pn -p 53,123 10.116.0.22
PORT STATE SERVICE
53/udp open|filtered domain
123/udp closed ntp当 nmap 因没有收到 ICMP 不可达响应而无法确认状态时,UDP 端口会返回 open|filtered。这是 UDP 的预期行为。将 open|filtered 视为潜在开放,并在应用层进行验证。
运行服务版本检测,确认预期的守护进程正在应答:
bash
sudo nmap -sV -Pn -p 80,443 10.116.0.22
PORT STATE SERVICE VERSION
80/tcp open http nginx 1.24.0
443/tcp open ssl/http nginx 1.24.0版本检测能发现两种常见的生产事故:部署未成功前推(运行版本与预期发布版本不符),以及 Droplet 在回滚后被恢复到之前的镜像。如果显示的版本与你部署的版本不匹配,则说明有错误的守护进程在端口上应答。如果某个端口在此处显示 closed,但在之前的扫描中显示 open,则说明服务在两次扫描之间停止了。
运行子网 ping 扫描,发现 VPC 中所有活动的主机:
csharp
nmap -sn 10.116.0.0/24
Nmap scan report for 10.116.0.12
Host is up.
Nmap scan report for 10.116.0.22
Host is up.
Nmap done: 256 IP addresses (2 hosts up) scanned in 2.84 seconds如果你期望找到的 Droplet 没有出现在结果中,请验证其是否已开机并被分配到同一个 VPC。此处主机缺失表明是 Droplet 状态或 VPC 分配问题,而非防火墙规则问题。
警告: 仅对你自己拥有且获得明确扫描授权的基础设施运行 nmap。对外部主机运行激进扫描可能违反 DigitalOcean 的服务条款和适用法律。
步骤 4 - 使用 dig 和 nslookup 诊断 DNS
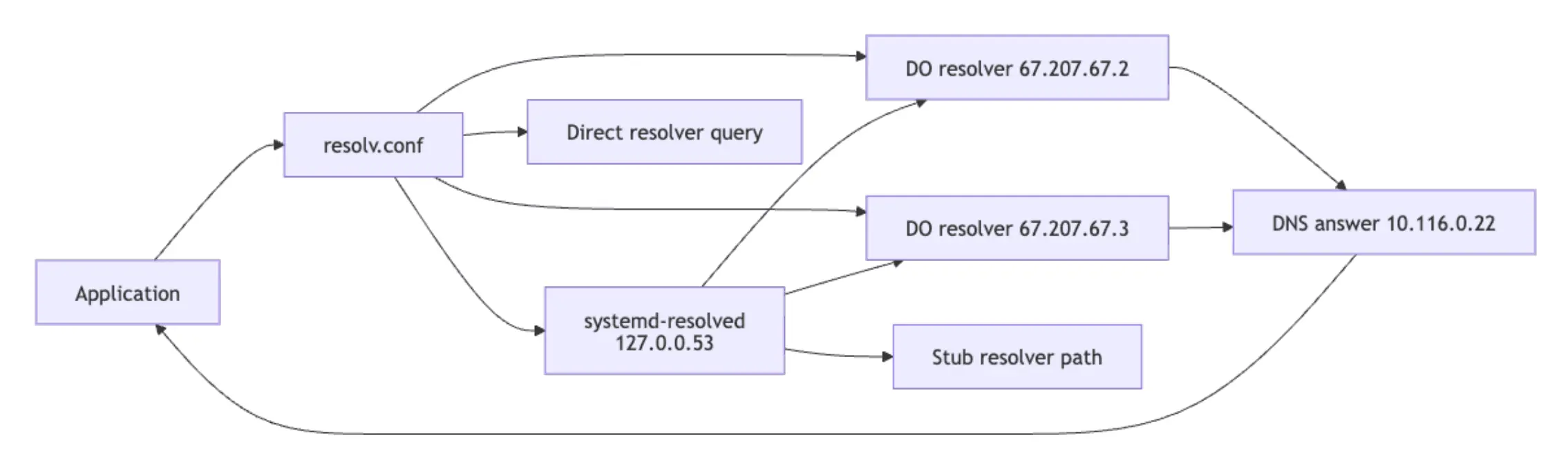
一个使用 IP 地址可以访问,但通过主机名却失败的服务,是 DNS 问题,而非网络问题。将其当作网络问题追查只会浪费时间。以下步骤旨在区分:是解析器错误、查询未离开 Droplet,还是两个 DigitalOcean 解析器的应答不一致。
首先检查解析器配置:
bash
cat /etc/resolv.conf
nameserver 67.207.67.2
nameserver 67.207.67.3
search internal.example如果两个 DigitalOcean 解析器 IP(67.207.67.2 和 67.207.67.3)都出现在这里,那么对于默认的 DigitalOcean 设置,解析器配置很可能正确。
在使用 systemd-resolved 的 Ubuntu 24.04 Droplet 上,/etc/resolv.conf 会指向位于 127.0.0.53 的本地存根解析器。运行以下命令确认实际使用的上游解析器:
yaml
resolvectl status eth1
Link 3 (eth1)
Current Scopes: DNS
DefaultRoute setting: no
LLMNR setting: yes
MulticastDNS setting: no
DNSOverTLS setting: no
DNSSEC setting: no
DNSSEC supported: no
Current DNS Server: 67.207.67.2
DNS Servers: 67.207.67.2 67.207.67.3如果显示的上游解析器不是 DigitalOcean 的解析器,请检查 /etc/systemd/resolved.conf 或 nmcli 的连接专用设置。
使用 dig 进行有控制的查询,指定一个 IP 解析器以避免集成本地主机存根问题:
csharp
dig @67.207.67.2 api.internal.example A +short
10.116.0.22当怀疑存在委派问题或记录过期时,运行迭代跟踪:
css
dig +trace example.com
. 518400 IN NS a.root-servers.net.
com. 172800 IN NS a.gtld-servers.net.
example.com. 172800 IN NS a.iana-servers.net.
example.com. 3600 IN A 93.184.216.34使用 nslookup 作为快速获取第二意见的查询方式:
yaml
nslookup api.internal.example 67.207.67.2
Server: 67.207.67.2
Address: 67.207.67.2#53
Name: api.internal.example
Address: 10.116.0.22通过在另一个终端运行 dig 查询的同时,捕获端口 53 的流量,来交叉验证 DNS 的出站情况:
less
sudo tcpdump -ni eth1 port 53
15:22:54.119091 IP 10.116.0.12.52402 > 67.207.67.2.53: 61545+ A? api.internal.example. (38)
15:22:54.119608 IP 67.207.67.2.53 > 10.116.0.12.52402: 61545 1/0/0 A 10.116.0.22 (54)每一行数据包包含:时间戳、源 IP 和端口、目标 IP 和端口、查询 ID、查询类型和载荷大小。在此输出中,10.116.0.12 向 67.207.67.2 的端口 53 发送查询 ID 61545,查询 api.internal.example 的 A 记录,解析器在 0.5 毫秒后回复了一个答案(1/0/0),解析为 10.116.0.22。这既确认了到解析器的出站可达性,也确认了成功的响应。
如果查询数据包离开了接口且收到了响应,说明解析器可达并正常响应。如果完全没有数据包出现,首先确认你捕获的是正确的接口,且查询确实离开主机。如果这两点都成立,问题可能出在接口状态、路由或解析器可达性上,而非 DNS 记录本身。
如果一个 Droplet 可以解析,而另一个失败,请并排比对 cat /etc/resolv.conf、nmcli device show eth1 和直接的 dig @resolver 查询,以区分问题出在每个 Droplet 的配置上还是上游。
步骤 5 - 故障排除负载均衡器连接
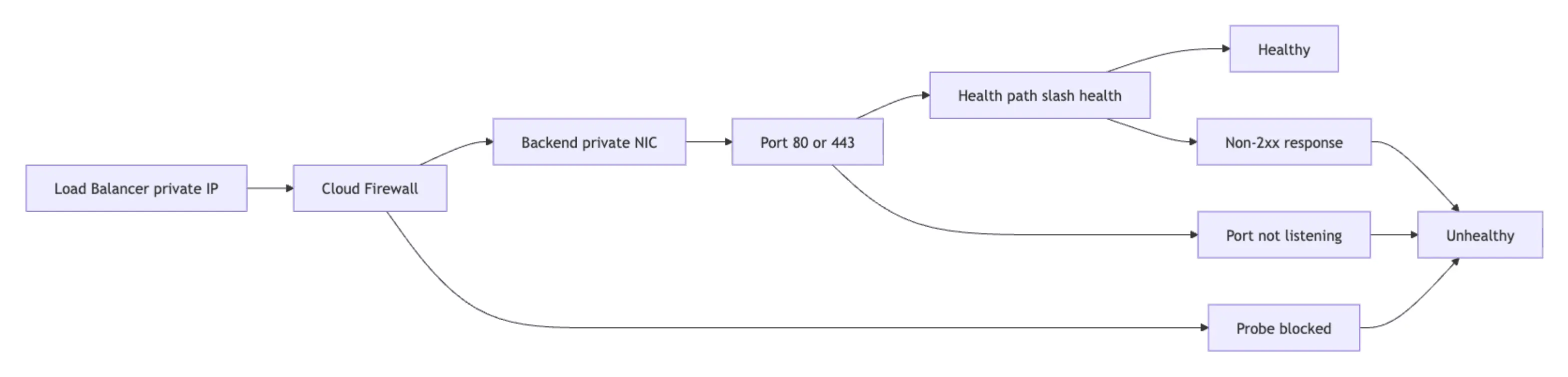
负载均衡器返回 502 或 503 错误,几乎总是指向以下三种情况之一:后端进程未在健康检查端口监听、健康检查路径返回非 200 状态码,或 Cloud Firewall 规则丢弃了来自负载均衡器私有 IP 的探测流量。在进行任何更改之前,请按以下顺序检查,因为不清楚这三个原因中的哪一个就更改配置,通常会使问题更难定位。
注意:要查找负载均衡器的私有 IP,请在 DigitalOcean 控制面板中导航至 "Networking" > "Load Balancers",选择负载均衡器,然后在 "Settings" 标签页中查看分配给 VPC 的私有 IP 地址。
从 VPC 内部测试前端可达性:
yaml
ping -c 3 10.116.0.50
PING 10.116.0.50 (10.116.0.50) 56(84) bytes of data.
64 bytes from 10.116.0.50: icmp_seq=1 ttl=64 time=0.659 ms
64 bytes from 10.116.0.50: icmp_seq=2 ttl=64 time=0.633 ms
64 bytes from 10.116.0.50: icmp_seq=3 ttl=64 time=0.641 ms
curl -v http://10.116.0.50/health
* Trying 10.116.0.50:80...
* Connected to 10.116.0.50 (10.116.0.50) port 80
> GET /health HTTP/1.1
> Host: 10.116.0.50
> User-Agent: curl/8.5.0
> Accept: */*
>
< HTTP/1.1 200 OK
< server: nginx/1.24.0
< date: Tue, 05 May 2026 10:22:55 GMT
< content-type: application/json
< content-length: 16
< connection: keep-alive
<
{"status":"ok"}如果 curl 返回的响应不是 200 OK,请检查后端进程的运行状况。
验证后端正在监听负载均衡器探测的端口和协议:
perl
sudo ss -tlnp | grep -E ':80|:443'
bash
LISTEN 0 511 0.0.0.0:80 0.0.0.0:* users:(("nginx",pid=1123,fd=6))
LISTEN 0 511 0.0.0.0:443 0.0.0.0:* users:(("nginx",pid=1123,fd=7))如果进程绑定在 127.0.0.1:80 而不是 0.0.0.0:80,或者绑定在 eth0 的 IP 上,那么负载均衡器的探测将不会到达服务。将监听地址重新配置为 0.0.0.0 或 VPC 私有地址。
直接检查后端的健康端点响应:
arduino
curl -v http://127.0.0.1/health
markdown
* Trying 127.0.0.1:80...
* Connected to 127.0.0.1 (127.0.0.1) port 80
> GET /health HTTP/1.1
> Host: 127.0.0.1
< HTTP/1.1 200 OK
< Content-Type: text/plain
<
OK捕获来自负载均衡器的健康检查探测流量:
ini
sudo tcpdump -ni eth1 host 10.116.0.50 and port 80
15:34:42.002011 IP 10.116.0.50.44902 > 10.116.0.22.80: Flags [S], seq 1483102, win 64240, length 0
15:34:42.002114 IP 10.116.0.22.80 > 10.116.0.50.44902: Flags [S.], seq 2891002, ack 1483103, win 65160, length 0
15:34:42.002129 IP 10.116.0.50.44902 > 10.116.0.22.80: Flags [.], ack 1, win 502, length 0输出显示了一个完整的 TCP 三次握手。10.116.0.50(负载均衡器)发送 SYN(标志 S),后端 10.116.0.22 以 SYN-ACK(标志 S.)响应,负载均衡器再以 ACK(标志 .)确认。看到这三个步骤依次发生,证实了探测到达了后端,且后端在 TCP 层进行了响应。如果你只看到 S 标志而没有 S.,说明后端尽管收到了数据包,但未接受连接。
如果探测数据包缺失,检查负载均衡器源 IP 的 Cloud Firewall 规则。如果探测数据包存在但后端仍被标记为不健康,检查 Droplet 内部防火墙策略和健康路径的响应代码。
如果探测数据包存在且健康端点本地返回 200,但后端在控制面板中仍为不健康状态,请检查以下两种额外情况:
- 健康检查路径不匹配 :确认负载均衡器健康检查设置中配置的路径,与应用实际提供服务的路径一致。例如,如果负载均衡器配置为探测
/health,但应用仅提供/healthz,那么每次探测都会返回 404,后端即被标记为不健康。你可以在控制面板的 "Networking" > "Load Balancers" > "Settings" > "Health Checks" 中检查配置的路径。 - TLS 不匹配:如果负载均衡器配置了 HTTPS 健康检查,但后端 Droplet 仅在健康检查端口提供 HTTP 服务,TLS 握手将失败,后端即被标记为不健康。确认健康检查配置中的协议设置与应用实际提供的服务相匹配。
网络故障排除 Runbook
以下 runbook 将上述诊断步骤编排成一个结构化的、可重复的故障响应流程。每个条目都按可观察到的症状组织,以便运维人员在事件发生时能快速定位到正确的处置流程。
Runbook 条目 1:Droplet 无法从另一 Droplet 访问(VPC 内部)
症状:Droplet A 无法通过已知的服务端口连接到 Droplet B 的私有 IP。
检查与操作:
-
在目标 Droplet 上确认接口和私有 IP:
sqlip addr show eth1 -
从源 Droplet 测试基线可达性:
rping -c 4 10.116.0.22 traceroute -n 10.116.0.22 -
确认目标上存在对应端口的监听器:
perlsudo ss -tlnp | grep -E ':22|:80|:443' -
在从源端重试连接的同时,在目标接口上捕获预期流量:
sudo tcpdump -ni eth1 host 10.116.0.12 and port 443 -
根据捕获证据分类根本原因:
- 捕获中未看到数据包:检查 Cloud Firewall 入站规则和 VPC 路由。
- 看到数据包但无回复 :检查目标端的
ufw或iptables,然后验证服务绑定。 - 回复数据包带有
R标志:服务未正确监听或正在主动拒绝连接。
Runbook 条目 2:负载均衡器返回 502 或 503
症状:客户端向负载均衡器端点发起请求,收到 HTTP 502 或 503 响应。
检查与操作:
-
参考:详细的负载均衡器诊断步骤和输出解释,请参见步骤 5 - 故障排除负载均衡器连接。
-
确认后端服务正在监听:
perlsudo ss -tlnp | grep <port> -
验证负载均衡器探测类型(TCP 或 HTTP/S)与后端监听的服务类型是否匹配。
-
直接对负载均衡器私有 IP 运行
curl -v,检查健康检查路径的响应代码:arduinocurl -v http://10.116.0.50/health -
在后端 Droplet 上,使用过滤条件捕获来自负载均衡器私有 IP 的流量,以区分是可达性问题还是阈值问题:
sudo tcpdump -ni eth1 host 10.116.0.50 and port 80 -
根据捕获证据分类根本原因:
- 未看到探测数据包:Cloud Firewall 不允许探测源 IP,或存在路由问题。
- 探测数据包存在且握手成功,但返回非 2xx 响应:应用健康路由不匹配。
- 探测数据包存在但会话超时:后端本地防火墙拦截或应用延迟飙升。
Runbook 条目 3:VPC 内部 DNS 解析失败
症状:应用报告内部或外部名称的主机解析失败。
检查与操作:
-
参考:详细的输出解释和解析器漂移诊断,请参见步骤 4 - 使用 dig 和 nslookup 诊断 DNS。
-
检查故障 Droplet 上配置的解析器:
bashcat /etc/resolv.conf -
直接查询 DigitalOcean 解析器,确认它们可达并返回应答:
csharpdig @67.207.67.2 api.internal.example A dig @67.207.67.3 api.internal.example A -
对公共域运行跟踪,排查委派问题:
dig +trace example.com -
验证 DNS 数据包在活动出站路径上是否离开主机并收到回复:
arduinosudo tcpdump -ni any port 53 -
根据结果分类根本原因:
- 两个 Droplet 查询结果不同:解析器或搜索域配置漂移。
- 在所有接口捕获中未看到出站 DNS 数据包,但查询正在生成:查询可能未离开主机,或主机解析器路径配置错误。
- 有出站数据包但无回复:Cloud Firewall、路由或上游解析器路径问题。
Runbook 条目 4:间歇性连接或延迟飙升
症状:服务大部分时间可达,但偶尔出现间歇性连接失败、偶发超时,或超出正常基线的延迟飙升。
检查与操作:
-
在比默认
ping更长的间隔内,测量持续可达性和丢包概况:cssping -c 100 -i 0.2 10.116.0.22 -
在故障活跃期间,捕获受影响服务的 TCP 握手流量:
scsssudo tcpdump -tt -ni eth1 'tcp[tcpflags] & (tcp-syn|tcp-ack) != 0 and port 443' -w latency-incident.pcap -
从实时捕获中测量握手延迟,以量化飙升情况:
scsssudo tcpdump -tt -ni eth1 'tcp[tcpflags] & (tcp-syn|tcp-ack) != 0 and port 443' | awk ' {gsub(/:$/, "", $3); gsub(/:$/, "", $5)} /Flags \[S\]/ && !/Flags \[S\.\]/ {syn[$3 SUBSEP $5]=$1} /Flags \[S\.\]/ {key=$5 SUBSEP $3; if (key in syn) {print "Handshake latency:", ($1-syn[key])*1000, "ms"; delete syn[key]}}' -
检查目标端套接字级别的丢包计数器和重传计数:
perlss -s netstat -s | grep -iE 'retrans|drop|reset' -
根据测量结果分类根本原因:
- 丢包率超过 1% 且无防火墙变更:调查 VPC 接口健康状况,并联系技术支持并提供捕获文件。
- 握手延迟持续低于 1 毫秒,偶尔出现数毫秒的飙升:应用层争用,而非网络问题。
- 重传计数增加,但
ping未见丢包:上游拥塞或路径 MTU 不匹配。 - 仅在高峰时段出现丢包:调查后端容量,而非网络策略。
使用 DigitalOcean Functions 和 AI Platform 自动化 Runbook
具备明确输入、确定性命令和结构化输出的 runbook 步骤,适合通过 DigitalOcean Functions 实现自动化。DigitalOcean Functions 是 DigitalOcean AI Platform agent 中函数路由所使用的无服务器层。被路由的函数必须是 web 函数,在 body 键中返回输出,并且通过控制面板或 API 注册时,需使用符合 OpenAPI 3.0 规范的输入模式。
在实施前,请查看官方参考文档:Route Functions in Agents。这种模式与 Modal 的autoscaling autoresearch post 中描述的方法类似,其中确定性的、可重复的操作成为代理可以编排的可调用单元。本教程中的 runbook 条目就是这样的基础:每一步都有明确范围,能产生结构化输出,并可直接映射到代理可以调用的函数。
以下示例函数接受目标 IP 和端口,运行 nmap 扫描,并以 AI Platform 函数路由所需的格式返回端口状态:
python
import re
import subprocess
def main(args):
target_ip = args.get("target_ip")
port = args.get("port")
if not target_ip or not port:
return {
"statusCode": 400,
"body": {
"error": "target_ip and port are required"
}
}
cmd = ["nmap", "-Pn", "-p", str(port), str(target_ip)]
try:
proc = subprocess.run(cmd, capture_output=True, text=True, timeout=20, check=False)
raw = (proc.stdout or "") + (proc.stderr or "")
except subprocess.TimeoutExpired:
return {
"statusCode": 504,
"body": {
"target_ip": target_ip,
"port": int(port),
"state": "timeout",
"raw": "nmap execution timed out"
}
}
state = "unknown"
match = re.search(rf"{re.escape(str(port))}/tcp\s+(open|filtered|closed)\b", raw)
if match:
state = match.group(1)
return {
"statusCode": 200,
"body": {
"target_ip": target_ip,
"port": int(port),
"state": state,
"raw": raw.strip()
}
}一个具有代表性的函数响应如下所示:
json
{
"body": {
"target_ip": "10.116.0.22",
"port": 443,
"state": "open",
"raw": "PORT STATE SERVICE\n443/tcp open https"
}
}部署并注册为 AI Platform agent 中的函数路由后,该 agent 便可响应诸如"10.116.0.22 上的 443 端口无响应"的消息,自动调用此诊断函数,然后利用结构化输出来路由响应、升级给人工处理或触发后续检查。如果你通过 Python 集成 agent 逻辑,可以使用 AI Python SDK。
注意: 要实现 DigitalOcean AI Platform 函数路由,该函数必须是一个 DigitalOcean web 函数,并且必须在 body 键中返回输出。你的路由定义必须遵循 Route Functions in Agents 文档 中的 schema 要求。
维护网络 Runbook 的最佳实践
- 在 Git 中为每个 runbook 条目标注日期、环境和责任人元数据,以便追踪哪些基础设施变更引入了新的故障模式。在根因分析过程中,使用
git log --follow runbook/<entry>.md追溯修改历史。 - 为每个关键服务存储一份已知的、正确的数据包捕获样本和代表性命令输出。故障期间与已知正常基线进行比对,而非从基本原理出发推理。使用
sudo tcpdump -ni eth1 -w baseline-<service>-<date>.pcap -c 200捕获基线。 - 为每次事件标准化一个命令执行顺序:可达性、数据包捕获、端口状态、DNS,然后是健康检查。当低层问题掩盖了高层症状时,跳过步骤只会浪费时间。
- 在事件发生后 24 小时内补充事后更新,包括哪些证据改变了诊断方向以及最终解决方案。
- 每次基础设施变更后,重新测试 Cloud Firewall 规则、Droplet 内部防火墙配置以及负载均衡器健康检查。从与之前相同的源重新运行
nmap -Pn -p <port> <target>,并将输出与先前结果进行对比,以发现隐蔽的策略回退。 - 将频繁重复的诊断步骤封装为 DigitalOcean Functions,并将其注册为 agent 工作流的函数路由,以逐步减少值班响应人员的手动操作负担。
常见问题解答
什么是网络故障排查 runbook?
网络故障排查 runbook 是针对特定症状的一系列诊断步骤的文档化记录,包括命令、预期输出、解读规则以及升级路径。它能标准化事件响应,确保无论哪位团队成员响应,都能获得一致的诊断证据。
如何使用 tcpdump 调试 DigitalOcean VPC 内部的网络问题?
在目标 Droplet 上运行 sudo tcpdump -ni eth1,将 eth1 替换为你的 VPC 私有接口名称。使用诸如 port 443 或 src 10.116.0.12 and port 443 等过滤器,将捕获范围缩小到相关流量。如果捕获结果中未出现来自预期源的数据包,则拦截发生在更上游的 Cloud Firewall 层。如果数据包存在但会话失败,则需排查 Droplet 内部防火墙策略、服务绑定及应用行为。
DigitalOcean Cloud Firewall 与 ufw 等 Droplet 内部防火墙有何区别?
Cloud Firewall 在虚拟机管理程序层面过滤流量,在流量到达 Droplet 网络接口之前就已处理。被 Cloud Firewall 拦截的流量根本不会出现在 Droplet 内部的 tcpdump 捕获中。ufw 和 iptables 则在数据包已送达接口之后,于操作系统内部运行。这两层可以同时生效,并各自独立执行规则。tcpdump 中缺失数据包指向 Cloud Firewall 拦截;数据包存在但服务无响应则指向 Droplet 内部防火墙或应用问题。
nmap 如何帮助排查 DigitalOcean 负载均衡器和 VPC 连接问题?
nmap 将端口分类为 open、filtered 或 closed,这直接对应事件响应中的下一步行动。从同一 VPC 内的一个 Droplet 运行 nmap -Pn -p <port> <target-ip>,测试指向后端 Droplet 或负载均衡器 IP 的可达性。filtered 结果将调查方向引向 Cloud Firewall 规则。closed 结果则将调查方向引向服务启动与绑定地址配置。
这些 runbook 步骤可以自动化吗?
可以。那些接受结构化输入(如 IP 地址、端口或主机名)并返回结构化输出(如端口状态、DNS 结果或数据包计数)的步骤,都适合转化为 DigitalOcean Functions。这些函数随后可注册为 AI Platform agent 中的函数路由,使 agent 能够根据症状描述自动执行诊断步骤。有关函数要求和 schema 格式,请参阅 Route Functions in Agents 文档。
如何在不靠猜测 eth1 和 ens4 的情况下,确定哪个接口是我的 VPC 接口?
运行以下命令,找出与你的私有 VPC IP 关联的接口:
bash
ip -4 addr | grep -E '10\.|172\.(1[6-9]|2[0-9]|3[0-1])\.|192\.168\.'该命令会列出所有私有 IP 地址。将 IP 与其上方显示的接口名称(例如 eth1 或 ens4)匹配。该接口即为你的 VPC 接口,应将其用于 tcpdump、ss 及其他诊断操作。
或者,你也可以使用:
bash
ip route get <目标私有IP>这能显示系统使用哪个接口来访问 VPC 中的另一台 Droplet。
如果我的 Droplet 是在配置当前 VPC 之前创建的,该怎么办?
在分配 VPC 之前创建的 Droplet 不会自动加入该 VPC。要解决此问题:
- 在控制面板中关闭 Droplet。
- 编辑该 Droplet 的网络设置,将其分配到正确的 VPC。
- 重新开机。
重新连接后,使用以下命令验证接口是否已出现并带有私有 IP:
bash
ip addr如果没有出现私有接口,则说明该 Droplet 未能成功连接到 VPC。
如何将 tcpdump 的时间戳与应用日志关联起来?
使用带有高精度时间戳的 tcpdump,并将其与应用日志对齐。
bash
sudo tcpdump -tttt -ni eth1 port 443-tttt 标志会打印出包含日期和时间的、人类可读的时间戳。直接将这些时间戳与应用日志进行比对,以匹配传入请求、连接尝试或超时等事件。
为确保事件期间关联更严格:
- 通过
timedatectl和 NTP 确保两个系统使用同步时间。 - 在日志中记下某个请求的精确时间戳,然后在
tcpdump中找到匹配的数据包序列。
这有助于确认延迟是发生在网络层(数据包到达时)还是应用内部(处理延迟)。
结论
本教程涵盖了如何构建一套用于排查 DigitalOcean VPC 故障的、以事件为导向的工作流,从可达性检查、数据包捕获到 DNS 验证、负载均衡器诊断,再到为快速事件响应而整理的基于症状的 runbook 条目,面面俱到。
现在,你可以排查 Droplet 连接故障、识别 Cloud Firewall 与 Droplet 内部防火墙行为、诊断 DNS 解析问题,并将可重复的检查自动化,转化为用于 DigitalOcean AI Platform agent 路由的 DigitalOcean Functions。
下一步,你可以通过 VPC 对等连接技术深度剖析 加深路由分析,然后借助 使用 nmap 和 tcpdump 测试防火墙配置 指南来扩展你的验证工作流。