作者:周弘懿(锦琛)
背景
当前,越来越多的企业开始构建语义检索、RAG 知识库、智能问答及多模态搜索系统。然而在实际落地过程中,团队面临的首要瓶颈往往并非检索效果不佳,而是向量化链路本身的复杂性。
传统方案要求企业自行完成 Embedding 模型的选型与部署,由业务系统调用模型将原始数据转换为向量后写入 Milvus,查询阶段还需再次调用模型进行向量化。这一流程涉及模型管理、接口封装、服务运维、监控告警等多个环节------在 PoC 阶段尚可拼接运行,一旦进入生产环境,复杂度将迅速攀升。
阿里云 Milvus Embedding 服务正是为解决这一痛点而生。它将向量化能力从业务侧收敛至向量数据库平台,让用户无需自建 Embedding 推理服务,即可在 Milvus 中直接完成从原始数据到向量检索的全流程,大幅缩短系统搭建周期。
一、产品介绍
产品定位
阿里云 Milvus Embedding 服务是内置于 Milvus 的托管式向量化能力。用户在控制台开通模型服务并绑定至 Milvus 实例后,即可在数据写入、更新和检索环节直接传入原始文本或多模态数据,由平台自动完成向量生成与检索处理。
相较传统模式,该服务将 "模型服务 + 向量写入 + 查询向量化" 整合为一条平台内闭环链路,显著降低了业务系统的接入和维护成本。
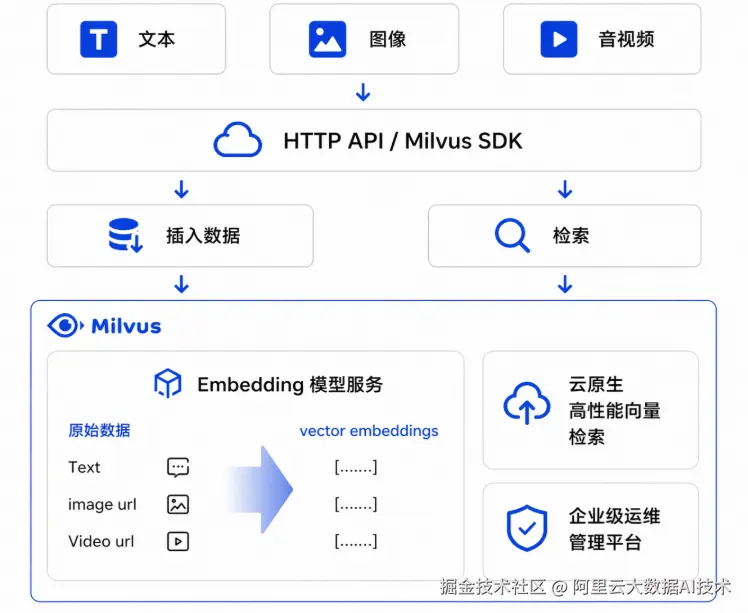
解决的核心问题
-
接入链路复杂: 传统方案需分别处理模型调用、服务部署、接口封装和 Milvus 接入,工程链路长,团队协作成本高。
-
上线周期偏长: 从模型选型、服务部署到数据联调,往往需要算法、平台和应用团队多方配合,周期不可控。
-
运维负担沉重: 自建模型服务还需额外关注稳定性保障、监控告警和弹性扩缩容等基础设施问题。
-
用量缺乏统一管理: 调用量、Token 消耗和异常波动分散在不同系统环节,难以形成统一的观测视图。
核心能力
| 功能 | 说明 |
|---|---|
| 控制台一站式管理 | 在统一控制台完成 Embedding 模型服务的创建、配置与实例绑定,无需跳转多个平台。 |
| 托管式模型服务 | 由平台提供高可用的 Embedding 推理服务,免去自建模型服务的复杂度与稳定性风险。 |
| 原始数据直写直检 | 写入、更新和查询阶段均可直接传入原始文本或多模态内容,向量化过程对业务透明。 |
| 多模型灵活切换 | 支持主流 Embedding 模型,便于按业务场景进行模型对比与持续优化。 |
| 调用量与 Token 统计 | 提供实例级的调用量与 Token 用量统计面板,资源消耗一目了然。 |
| 生产级监控告警 | 支持面向生产环境的监控与告警配置,异常状况可及时发现和处置。 |
业务价值
-
门槛更低: 无需自建 Embedding 服务,在 Milvus 控制台开通即可直接使用。
-
落地更快: 从原始数据到语义检索的链路大幅缩短,PoC 与生产验证均可提速。
-
开发更少: 开发者可围绕原始数据直接编程,无需自行维护向量化流程。
-
运维更轻: 模型服务由平台托管,稳定性与可观测性由平台统一支撑。
-
优化更易: 支持多模型切换与持续验证,方便按效果、成本和时延灵活迭代。
典型适用场景
-
RAG 知识库: 将文档、FAQ、制度和产品资料导入 Milvus,快速完成向量化与语义检索,支撑智能知识服务。
-
企业搜索与智能问答: 用户输入自然语言问题,系统自动完成查询向量化并返回语义最相关的结果。
-
内容推荐与召回: 将文章、商品描述、评论等内容向量化,用于相似内容匹配和个性化召回。
-
多模态搜索: 将图片、视频、文本等多类型数据统一纳入检索体系,支持文搜图/视频、图搜图/视频等跨模态场景。
-
快速 PoC 验证: 无需额外建设模型基础设施,即可快速验证 AI 检索场景的业务可行性。
二、功能演示
下面通过一个完整的体验流程,展示阿里云 Milvus Embedding 服务如何从服务开通走到文本检索和多模态检索验证。
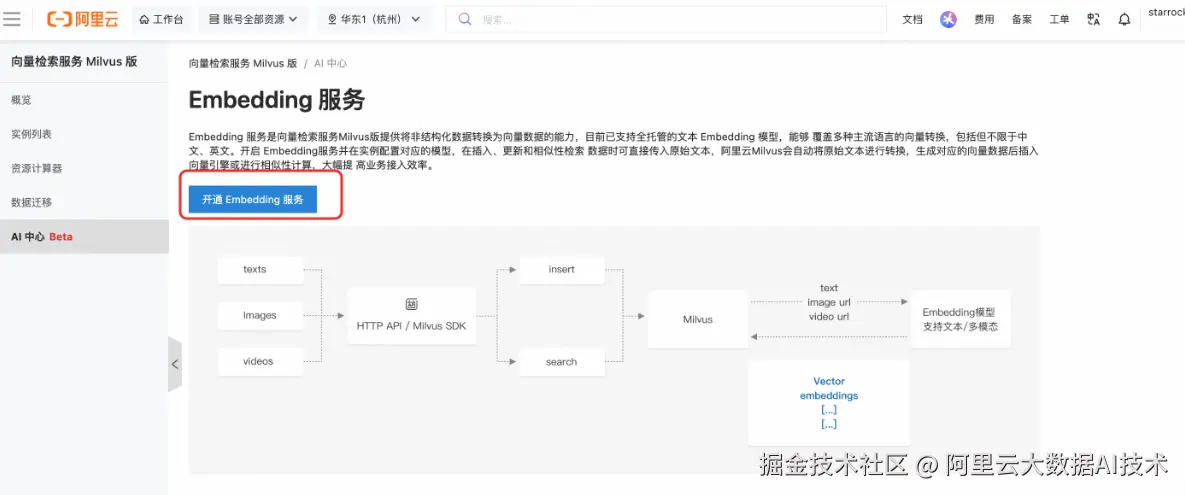
1. 开启 Embedding 服务
在阿里云 Milvus 控制台中创建并开启 Embedding 服务后,用户即可在阿里云 Milvus 平台侧统一管理模型服务能力。
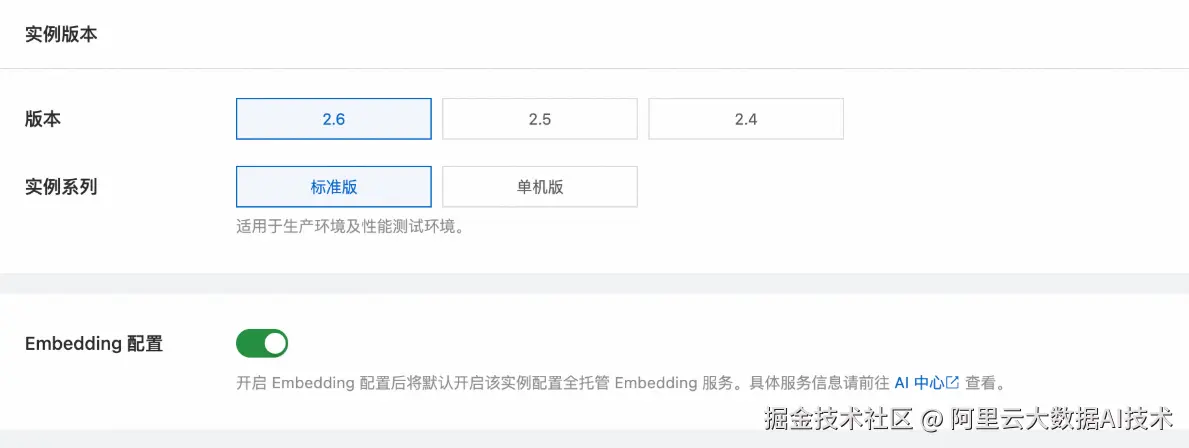
2. 关联 Milvus 实例
Embedding 能力依赖 Milvus 2.6 版本实例,可以通过以下两种方式关联:
-
创建 2.6 版本集群时直接开启 Embedding
-
对存量实例启用 Embedding 模型
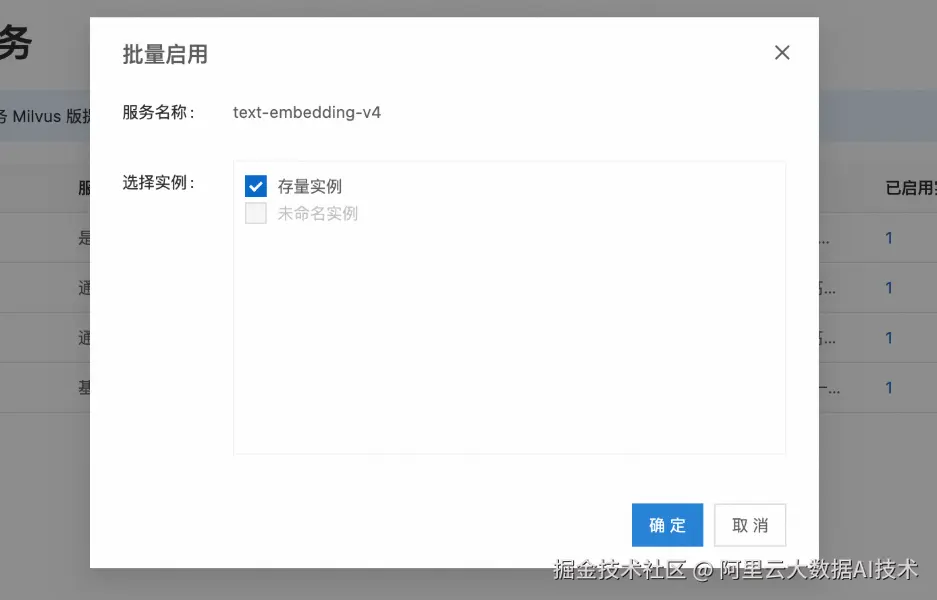
您可在实例列表中查看已启用 Embedding 的实例或者停用某个模型,完成服务开通和实例关联后,就可以直接进入业务验证。 
3. Embedding 调用查看
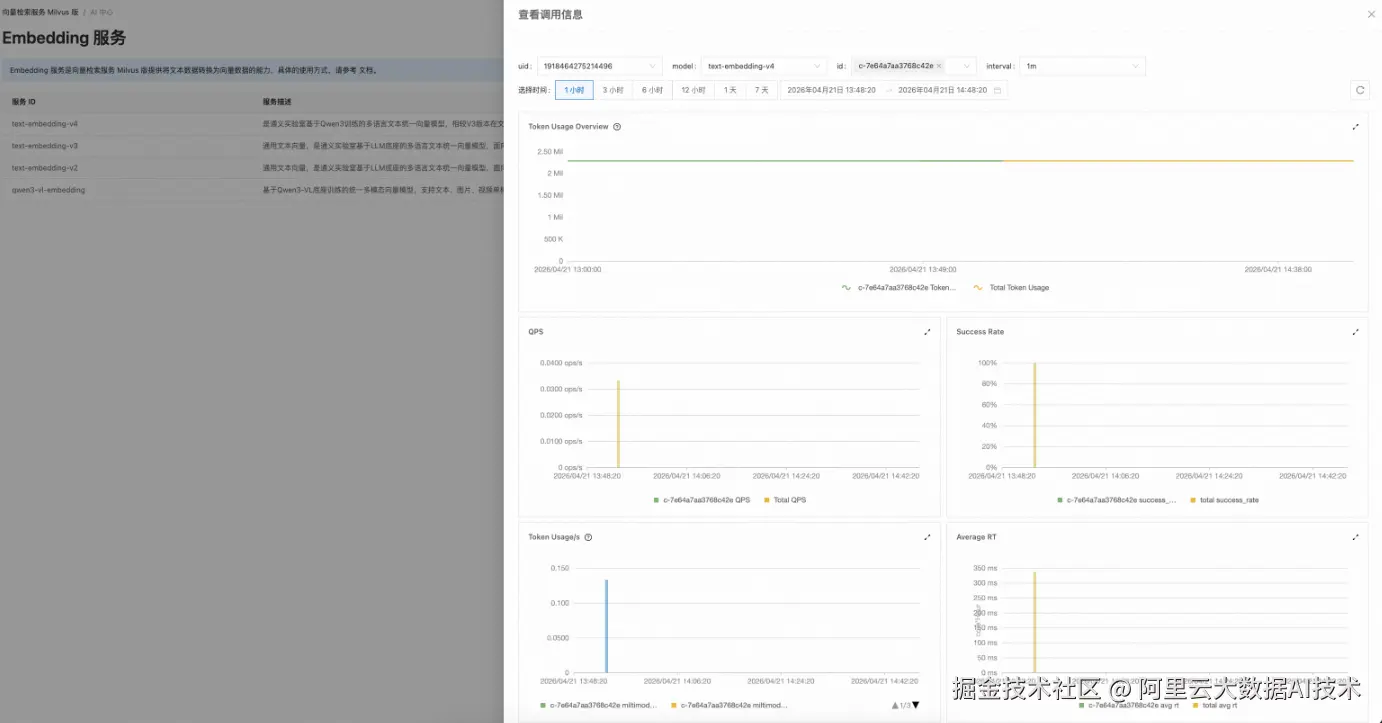
如下图所示,可以针对每个模型进行 token 消耗、qps、成功率、RT 等指标查看,方便客户更清楚 token 使用情况。

4. 案例一:文搜文语义检索
场景说明
这是最常见的知识库和企业搜索场景。用户将一批原始文本写入 Milvus,无需预先生成向量;在查询时直接输入自然语言问题,Milvus 即可自动完成查询向量化,并返回语义最相关的结果。
该案例适用于验证以下能力:
-
原始文本直接入库
-
平台自动完成向量生成
-
面向自然语言问题的语义检索效果
-
从 PoC 到业务接入的最小闭环
演示步骤
-
创建 Collection,定义原始文本字段
document和向量字段dense -
通过
Function绑定text-embedding-v4模型 -
插入一批与向量数据库、RAG、语义检索相关的测试文本
-
直接使用自然语言问题发起检索,返回最相关的文本片段
示例代码
python
import random
from pymilvus import MilvusClient, DataType, Function, FunctionType
client = MilvusClient(
uri="http://c-xxxx.milvus.aliyuncs.com:19530",
token='root:xxx',
)
# ========== 创建 Collection ==========
collection_name = 'demo1'
schema = client.create_schema()
schema.add_field("id", DataType.INT64, is_primary=True, auto_id=False)
schema.add_field("document", DataType.VARCHAR, max_length=9000)
schema.add_field("dense", DataType.FLOAT_VECTOR, dim=1024)
text_embedding_function = Function(
name="dashscope_api_test123",
function_type=FunctionType.TEXTEMBEDDING,
input_field_names=["document"],
output_field_names=["dense"],
params={
"provider": "aliyun_milvus",
"model_name": "text-embedding-v4"
}
)
schema.add_function(text_embedding_function)
index_params = client.prepare_index_params()
index_params.add_index(
field_name="dense",
index_type="AUTOINDEX",
metric_type="COSINE"
)
client.drop_collection(collection_name)
client.create_collection(
collection_name=collection_name,
schema=schema,
index_params=index_params
)
insert_data = []
record_id = 1
mock_texts = [
"向量数据库通过将文本转换为高维向量来实现语义检索,能够理解查询的真实意图。",
"深度学习模型可以从大量图片数据中学习特征表示,用于图像分类和目标检测等任务。",
"检索增强生成通过召回相关文档为大模型提供外部知识,减少幻觉并提升答案可靠性。",
"在客服场景中,语义搜索可以快速定位历史工单,提高首次响应效率和问题解决率。",
"相似度搜索常用余弦距离衡量向量方向接近程度,适合文本语义匹配任务。",
"数据清洗是向量化前的重要步骤,去噪和统一格式能显著提升召回质量。",
"embedding 维度并非越高越好,需要在效果、延迟和存储成本之间做平衡。",
"通过分块策略将长文档切分为小段,可以提高检索命中率并减少上下文冗余。",
"为每条知识添加来源字段有助于结果可解释性,方便在前端展示引用证据。",
"多语言检索可借助统一向量空间实现跨语言匹配,提升国际化系统体验。",
"索引参数如 ef 和 M 会影响 HNSW 的召回率与查询性能,需要结合业务调优。",
"在上线前进行离线评测可以量化不同模型和参数组合的检索质量差异。",
"向量库中的元数据过滤能够与语义召回结合,实现更精准的范围限定搜索。",
"对于高频问题,可将检索结果做短时缓存以降低后端计算压力和响应时间。",
"语义检索链路应记录查询日志,便于后续分析零结果查询并持续优化知识库。",
"当知识内容更新频繁时,增量索引策略可以减少全量重建带来的资源消耗。",
"在问答系统中加入重排序模型可以提升前几条结果的相关性和可读性。",
"为敏感数据建立访问控制策略是企业级向量检索系统的基础安全要求。",
"合理设置 topK 能在覆盖率与噪声之间取得平衡,避免返回过多低相关结果。",
"将用户反馈回流到训练与评估流程,可以持续改进检索与问答整体效果。",
]
for text in mock_texts:
insert_data.append({
"id": record_id,
"document": text,
})
record_id += 1
BATCH_SIZE = 30
print(f"准备插入 {len(insert_data)} 条数据,batch_size={BATCH_SIZE}...")
for batch_start in range(0, len(insert_data), BATCH_SIZE):
batch = insert_data[batch_start:batch_start + BATCH_SIZE]
client.insert(collection_name, batch)
print(f" 已插入 {min(batch_start + BATCH_SIZE, len(insert_data))}/{len(insert_data)} 条")
print("数据插入完成!\n")
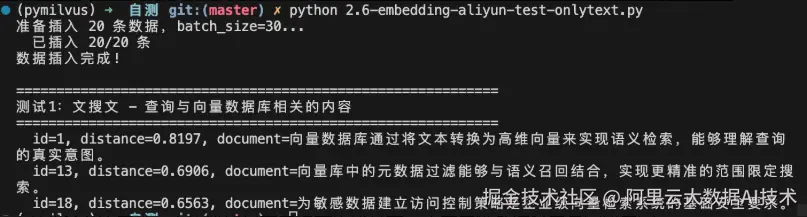
# ========== 测试1:文搜文(通过 dense 字段做纯文本语义检索) ==========
print("=" * 60)
print("测试1:文搜文 - 查询与向量数据库相关的内容")
print("=" * 60)
results = client.search(
collection_name=collection_name,
data=['什么是语义检索?向量数据库如何工作?'],
anns_field='dense',
limit=3,
output_fields=['document'],
)
for hits in results:
for hit in hits:
print(f" id={hit['id']}, distance={hit['distance']:.4f}, document={hit['entity']['document'][:50]}")演示结果
案例价值
该案例展示了阿里云 Milvus Embedding 服务在文本检索场景中的最小接入路径:
-
对业务系统来说,入库阶段只需要提交原始文本,不需要额外准备向量字段内容。
-
对查询侧来说,用户可以直接输入自然语言问题,无需在应用层额外调用 Embedding 服务。
-
对 PoC 场景来说,这种方式可以快速验证"检索结果是否足够相关",而不必先投入大量模型服务建设工作。
如果企业正在建设知识库问答、文档搜索、FAQ 检索或 RAG 检索底座,该案例通常是首选落地方案。
5. 案例二:多模态检索
场景说明
在零售、电商、内容平台和媒体场景中,检索对象往往不只是文本,还包括图片、视频、商品素材和其他多媒体内容。阿里云 Milvus Embedding 服务支持将文本描述与视觉内容纳入统一的向量化与检索流程,帮助业务同时支持文搜图 / 视频、图搜图 / 视频等能力。
该案例重点验证三类能力:
-
多媒体资源 URL 直接接入多模态 Embedding 链路
-
文本描述搜索图片或视频,即文搜图 / 视频
-
以图片搜索相似图片或视频,即图搜图 / 视频
演示步骤
-
将本地测试图片或视频上传到 OSS,生成可访问的签名 URL
-
创建 Collection,定义文本字段
document、多媒体地址字段url、文本向量字段dense和多模态向量字段dense_mm -
分别为文本和多媒体字段绑定
text-embedding-v4与qwen3-vl-embedding -
插入香蕉、橙子两类测试素材及对应文本描述
-
执行文搜文、文搜图 / 视频、图搜图 / 视频等检索,验证统一检索链路
图片可到thoth.inrialpes.fr/~jegou/data...地址下载,下载后将目录替换下代码中目录位置
示例代码
plaintext
import glob
import os
import random
import oss2
from pymilvus import MilvusClient, DataType, Function, FunctionType
client = MilvusClient(
uri="http://c-xxxx.milvus.aliyuncs.com:19530",
token='root:xxx',
)
# ========== OSS 配置:上传多媒体资源并生成签名 URL ==========
SCRIPT_DIR = os.path.dirname(os.path.abspath(__file__))
OSS_ACCESS_KEY_ID = os.environ['OSS_ACCESS_KEY_ID']
OSS_ACCESS_KEY_SECRET = os.environ['OSS_ACCESS_KEY_SECRET']
OSS_ENDPOINT = 'https://oss-cn-hangzhou.aliyuncs.com'
OSS_BUCKET_NAME = '002test'
auth = oss2.Auth(OSS_ACCESS_KEY_ID, OSS_ACCESS_KEY_SECRET)
bucket = oss2.Bucket(auth, OSS_ENDPOINT, OSS_BUCKET_NAME)
def upload_and_sign(relative_path, oss_key_prefix="milvus-embedding-test"):
"""上传本地多媒体资源到 OSS 并返回签名 URL(有效期 1 小时)"""
full_path = os.path.join(SCRIPT_DIR, relative_path)
oss_key = f"{oss_key_prefix}/{os.path.basename(relative_path)}"
bucket.put_object_from_file(oss_key, full_path)
signed_url = bucket.sign_url('GET', oss_key, 3600)
print(f" 上传成功: {oss_key} -> {signed_url[:80]}...")
return signed_url
def upload_directory_with_patterns(
directory_relative_path,
patterns,
oss_key_prefix="milvus-embedding-test",
random_pick_count=None,
):
"""上传目录下匹配后缀的多媒体文件到 OSS,返回 {文件名: 签名 URL}"""
full_dir = os.path.join(SCRIPT_DIR, directory_relative_path)
matched_files = []
for pattern in patterns:
matched_files.extend(glob.glob(os.path.join(full_dir, pattern)))
matched_files = sorted(set(matched_files))
if random_pick_count is not None and len(matched_files) > random_pick_count:
matched_files = random.sample(matched_files, random_pick_count)
result = {}
for file_path in matched_files:
filename = os.path.basename(file_path)
relative_path = os.path.join(directory_relative_path, filename)
signed_url = upload_and_sign(relative_path, oss_key_prefix)
result[filename] = signed_url
return result
# 上传 banana 和 orange 目录下的测试素材到 OSS
print("上传测试素材到 OSS...")
banana_urls = upload_directory_with_patterns("qwen-vl/train/banana", ["*.JPEG"])
orange_urls = upload_directory_with_patterns("qwen-vl/train/orange", ["*.JPEG"])
print(f"banana 目录上传 {len(banana_urls)} 张,orange 目录上传 {len(orange_urls)} 张")
print("图片素材上传完成!\n")
# 上传视频到 OSS(与图片素材逻辑一致)
print("上传视频到 OSS...")
selected_video_urls = upload_directory_with_patterns(
"qwen-vl/short_video_10_of_42",
["*.mp4", "*.MP4", "*.mov", "*.MOV"],
random_pick_count=5,
)
print(f"short_video_10_of_42 目录上传并选用 {len(selected_video_urls)} 个视频")
print("视频上传完成!\n")
banana_url_list = list(banana_urls.values())
orange_url_list = list(orange_urls.values())
selected_video_url_list = list(selected_video_urls.values())
# ========== 创建 Collection ==========
collection_name = 'demo11'
schema = client.create_schema()
schema.add_field("id", DataType.INT64, is_primary=True, auto_id=False)
schema.add_field("document", DataType.VARCHAR, max_length=9000)
schema.add_field("url", DataType.VARCHAR, max_length=9000)
schema.add_field("dense", DataType.FLOAT_VECTOR, dim=1024)
schema.add_field("dense_mm", DataType.FLOAT_VECTOR, dim=1024)
text_embedding_function = Function(
name="dashscope_api_test123",
function_type=FunctionType.TEXTEMBEDDING,
input_field_names=["document"],
output_field_names=["dense"],
params={
"provider": "aliyun_milvus",
"model_name": "text-embedding-v4"
}
)
mm_embedding_function = Function(
name="dashscope_api_mm123",
function_type=FunctionType.TEXTEMBEDDING,
input_field_names=["url"],
output_field_names=["dense_mm"],
params={
"provider": "aliyun_milvus",
"model_name": "qwen3-vl-embedding",
"dim": "1024"
}
)
schema.add_function(text_embedding_function)
schema.add_function(mm_embedding_function)
index_params = client.prepare_index_params()
index_params.add_index(
field_name="dense",
index_type="AUTOINDEX",
metric_type="COSINE"
)
index_params.add_index(
field_name="dense_mm",
index_type="AUTOINDEX",
metric_type="COSINE"
)
client.drop_collection(collection_name)
client.create_collection(
collection_name=collection_name,
schema=schema,
index_params=index_params
)
# ========== 插入中文测试数据,多媒体资源使用 OSS 签名 URL ==========
banana_descriptions = [
'一串成熟的黄色香蕉挂在热带果园的树上,阳光透过叶片洒下斑驳的光影。',
'超市水果区摆放着整齐的香蕉,旁边的价签标注着今日特价,吸引了不少顾客驻足挑选。',
'厨房桌上放着几根香蕉和一杯牛奶,这是一份简单而健康的早餐搭配。',
'刚从树上摘下来的青皮香蕉整齐地码放在竹筐里,等待自然催熟后上市销售。',
'小朋友手里拿着一根香蕉,开心地在公园里边走边吃,脸上洋溢着满足的笑容。',
'烘焙师将熟透的香蕉捣成泥,准备制作一款经典的香蕉蛋糕,厨房里弥漫着甜香。',
'热带雨林中野生的香蕉树成片生长,巨大的叶片在微风中轻轻摇曳。',
'早餐桌上切好的香蕉片搭配燕麦和酸奶,是一份营养均衡的健康早餐。',
'水果摊老板正在给顾客称量一大串新鲜香蕉,秤上显示刚好三斤。',
'几根香蕉和苹果、橙子一起摆放在果盘中,色彩鲜艳,赏心悦目。',
]
orange_descriptions = [
'果园里挂满枝头的橙子在阳光下泛着金黄色的光泽,丰收的季节令人喜悦。',
'一杯鲜榨橙汁放在桌上,旁边摆着切开的橙子,果肉饱满多汁。',
'妈妈正在厨房里剥橙子,空气中弥漫着清新的柑橘香气,孩子们围在旁边等着吃。',
'超市货架上整齐排列着脐橙和血橙,不同品种的橙子各有特色。',
'冬日午后,一盘切好的橙子摆在茶几上,是全家人最爱的下午茶水果。',
'橙子皮被巧手的奶奶晒干后泡茶,据说有理气健脾的功效。',
'果农小心翼翼地将刚采摘的橙子装进纸箱,准备发往全国各地的客户手中。',
'甜品店橱窗里展示着精美的橙子慕斯蛋糕,橙色的外观十分诱人。',
'一颗被切成两半的橙子露出鲜嫩的果肉,汁水丰富,让人垂涎欲滴。',
'小区门口的水果店挂出了赣南脐橙到货的招牌,引来不少居民排队购买。',
]
video_descriptions = [
"一段水果主题短视频,展示果园采摘与运输过程。",
"一段水果门店陈列短视频,镜头近距离展示果实细节。",
"一段饮品制作短视频,包含切片、压榨与装杯过程。",
"一段甜品制作短视频,展示果肉装饰和成品呈现。",
]
insert_data = []
record_id = 1
for idx, img_url in enumerate(banana_url_list):
insert_data.append({
'id': record_id,
'document': banana_descriptions[idx],
'url': img_url,
})
record_id += 1
for idx, img_url in enumerate(orange_url_list):
insert_data.append({
'id': record_id,
'document': orange_descriptions[idx],
'url': img_url,
})
record_id += 1
for idx, video_url in enumerate(selected_video_url_list):
insert_data.append({
"id": record_id,
"document": video_descriptions[idx % len(video_descriptions)],
"url": video_url,
})
record_id += 1
# 纯文本数据(url 字段填文本,dense_mm 也会生成对应的文本向量)
insert_data.append({
'id': record_id,
'document': '向量数据库通过将文本转换为高维向量来实现语义检索,能够理解查询的真实意图。',
'url': '向量数据库通过将文本转换为高维向量来实现语义检索,能够理解查询的真实意图。',
})
record_id += 1
insert_data.append({
'id': record_id,
'document': '深度学习模型可以从大量图片数据中学习特征表示,用于图像分类和目标检测等任务。',
'url': '深度学习模型可以从大量图片数据中学习特征表示,用于图像分类和目标检测等任务。',
})
BATCH_SIZE = 20
print(f"准备插入 {len(insert_data)} 条数据,batch_size={BATCH_SIZE}...")
for batch_start in range(0, len(insert_data), BATCH_SIZE):
batch = insert_data[batch_start:batch_start + BATCH_SIZE]
client.insert(collection_name, batch)
print(f" 已插入 {min(batch_start + BATCH_SIZE, len(insert_data))}/{len(insert_data)} 条")
print("数据插入完成!\n")
# ========== 测试1:文搜文(通过 dense 字段做纯文本语义检索) ==========
print("=" * 60)
print("测试1:文搜文 - 查询与向量数据库相关的内容")
print("=" * 60)
results = client.search(
collection_name=collection_name,
data=['什么是语义检索?向量数据库如何工作?'],
anns_field='dense',
limit=3,
output_fields=['document', 'url'],
)
for hits in results:
for hit in hits:
print(f" id={hit['id']}, distance={hit['distance']:.4f}, document={hit['entity']['document'][:50]}")
# ========== 测试2:文搜图 / 视频(通过 dense_mm 字段,用文本查询匹配多媒体内容) ==========
print("\n" + "=" * 60)
print("测试2:文搜图 / 视频 - 用文本描述搜索香蕉相关的图片和视频素材")
print("=" * 60)
results = client.search(
collection_name=collection_name,
data=['黄色香蕉'],
anns_field='dense_mm',
limit=3,
output_fields=['document', 'url'],
)
for hits in results:
for hit in hits:
has_image = "有图" if hit['entity'].get('url') else "无图"
print(f" id={hit['id']}, distance={hit['distance']:.4f}, [{has_image}] document={hit['entity']['document'][:50]}")
# ========== 测试3:图搜图 / 视频(通过 dense_mm 字段,用视觉素材查询匹配多媒体内容) ==========
print("\n" + "=" * 60)
print("测试3:图搜图 / 视频 - 用 orange 目录中的视觉素材搜索相似图片和视频")
print("=" * 60)
results = client.search(
collection_name=collection_name,
data=[orange_url_list[0]],
anns_field='dense_mm',
limit=3,
output_fields=['document', 'url'],
)
for hits in results:
for hit in hits:
has_media = "有媒体" if hit['entity'].get('url') else "无媒体"
print(f" id={hit['id']}, distance={hit['distance']:.4f}, [{has_media}] document={hit['entity']['document'][:50]}")演示结果

案例价值
该案例展示了阿里云Milvus Embedding 服务从文本场景向多模态场景的自然扩展能力:
-
对内容平台、电商和媒体场景,可以直接用文本描述搜索图片或视频素材,提升素材检索效率。
-
对图库、视频库、商品库和媒体资产管理场景,可以基于图片发起相似检索,返回图片或视频等相关多媒体内容。
-
对平台建设者来说,文本模型和多模态模型都由 Milvus 平台统一托管,业务只需围绕字段定义和检索逻辑做集成。
这意味着企业不需要分别建设文本向量化链路、图片向量化链路和视频向量化链路,而可在一个统一的平台内完成多数据类型的检索能力建设。
总结
阿里云 Milvus Embedding 服务将原本分散在业务系统各环节中的向量化能力统一收敛至 Milvus 平台,帮助企业以更低的接入复杂度、更短的上线周期完成文本与多模态数据的向量化、入库与检索。
无论是快速验证 AI 检索场景的 PoC,还是面向生产环境的大规模部署,该服务都能有效降低工程门槛,让团队将更多精力聚焦于业务逻辑和检索效果的优化。