作者:洛水石
> 标签:分库分表、Sharding-JDBC、MySQL、数据库优化
一、为什么需要分库分表
1.1 单机数据库的性能瓶颈
|------------|------|-------------|
| 数据量级 | 表记录数 | 常见问题 |
| < 500万 | 小表 | 无明显问题 |
| 500万-5000万 | 中表 | 查询变慢,需要索引优化 |
| 5000万-2亿 | 大表 | 索引失效,DDL变慢 |
单表性能瓶颈表现 :
- 查询响应时间 QUOTE_2
1.2 分库分表的驱动力
``_INLINE
┌─────────────────────────────────────────────────────────────┐
│ 单机 MySQL 性能极限 │
├─────────────────────────────────────────────────────────────┤
│ 连接数:默认 151,最大约 10000 │
│ 存储:单实例建议 < 500GB │
│ QPS:纯内存查询约 10万,磁盘查询约 1万 │
│ TPS:写操作约 2000-5000 │
└─────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────┐
│ 分库分表解决方案 │
├─────────────────────────────────────────────────────────────┤
│ 分库:解决连接数瓶颈、存储瓶颈、单点故障 │
│ 分表:解决单表数据量过大、索引效率下降、并发写入瓶颈 │
└─────────────────────────────────────────────────────────────┘
__`_INLINE
1.3 什么场景需要分库分表
必须分表的场景 :
- 日增数据 QUOTE_3
必须分库的场景 :
-
单库连接数打满
-
单库存储空间 QUOTE_4
二、分库分表核心概念
2.1 分片策略

__`_INLINE
┌────────────────────────────────────────────────────────────┐
│ 分片维度选择 │
├────────────────┬────────────────┬──────────────────────────┤
│ 分片键 │ 示例 │ 适用场景 │
├────────────────┼────────────────┼──────────────────────────┤
│ 用户ID │ user_id │ 用户相关数据(订单、日志) │
│ 订单ID │ order_id │ 订单系统 │
│ 时间 │ create_time │ 日志、流水类数据 │
│ 地区 │ region_code │ 地域性业务(配送、仓储) │
│ 哈希 │ hash(id) │ 数据分布均匀的业务 │
└────────────────┴────────────────┴──────────────────────────┘
__`_INLINE
2.2 分片算法
|------------|---------------|-----------|--------|
| 算法 | 原理 | 优点 | 缺点 |
| **取模** | user_id % 8 | 分布均匀,扩容简单 | 数据迁移量大 |
| **范围** | 按时间范围 | 便于归档,查询高效 | 热点问题 |
| **哈希** | hash(user_id) | 分布均匀 | 范围查询困难 |
| **混合** | 范围+哈希 | 兼顾两者优点 | 复杂度较高 |
推荐策略 :
-
用户数据:_user_id % 16__INLINE 分16张表
-
订单数据:按 _create_time 年月分表 + user_id__INLINE 取模
-
日志数据:按天/月分表
2.3 分库分表架构
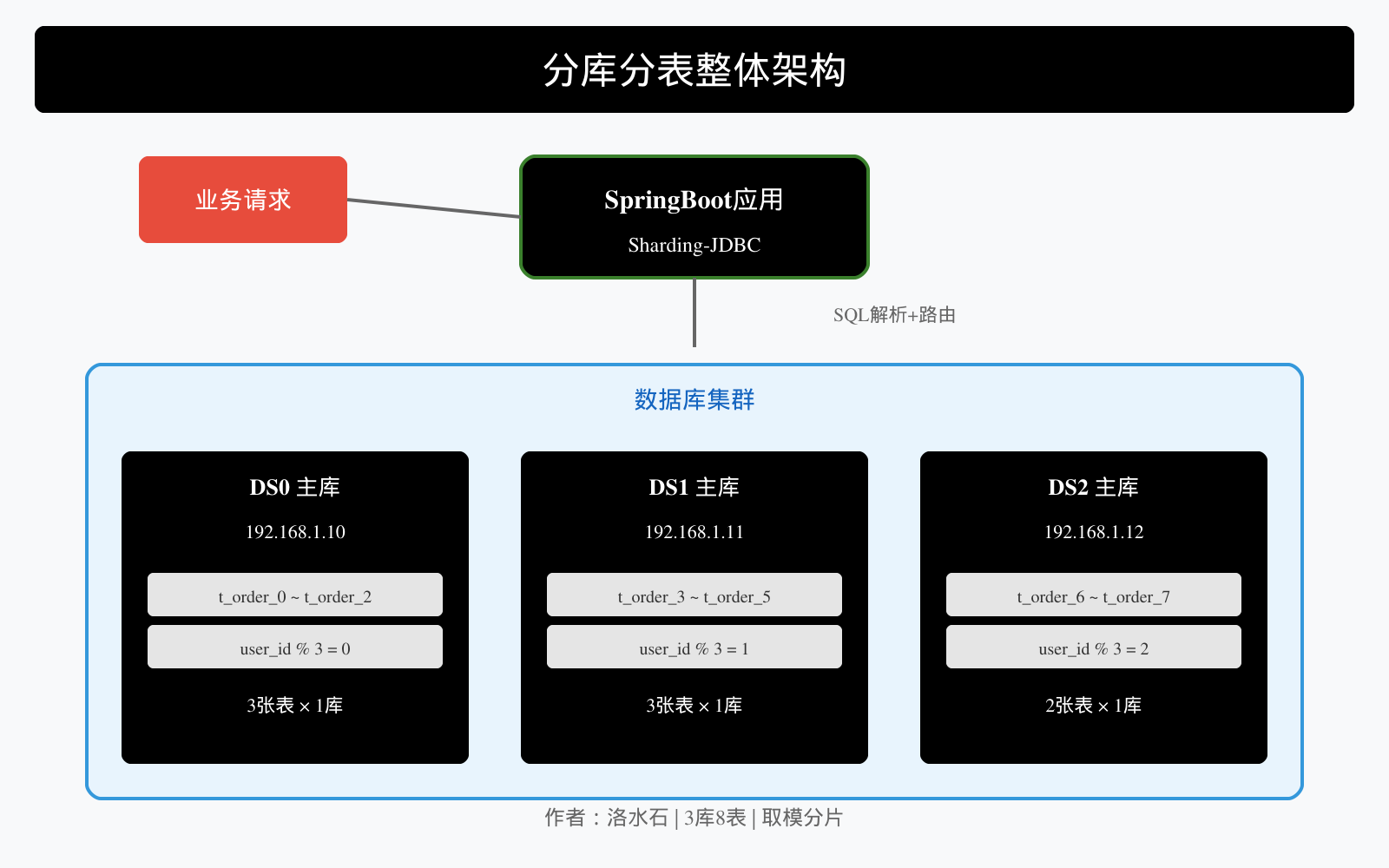 __`_INLINE
__`_INLINE
┌─────────────┐
│ 应用层 │
│ SpringBoot │
└──────┬──────┘
│
┌──────▼──────┐
│ Sharding-JDBC│
│ 中间件 │
└──────┬──────┘
│
┌──────────────────┼──────────────────┐
│ │ │
┌────▼────┐ ┌─────▼─────┐ ┌─────▼─────┐
│ ds_0 │ │ ds_1 │ │ ds_2 │
│ 主从库 │ │ 主从库 │ │ 主从库 │
└────┬────┘ └─────┬─────┘ └─────┬─────┘
│ │ │
┌────┴────┐ ┌────┴────┐ ┌────┴────┐
│t_order_0│ │t_order_0│ │t_order_0│
│t_order_1│ │t_order_1│ │t_order_1│
│ ... │ │ ... │ │ ... │
│t_order_7│ │t_order_7│ │t_order_7│
└─────────┘ └─────────┘ └─────────┘
__`_INLINE
三、Sharding-JDBC 快速入门
3.1 引入依赖
__`__INLINE_xml
<dependencies>
<!-- Sharding-JDBC -->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId>
<version>5.4.0</version>
</dependency>
<!-- MySQL 驱动 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.33</version>
</dependency>
<!-- MyBatis-Plus -->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.5.4.1</version>
</dependency>
</dependencies>
__`_INLINE
3.2 基础配置
__`__INLINE_yaml
数据源配置
spring:
shardingsphere:
datasource:
names: ds0, ds1, ds2
ds0:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://192.168.1.10:3306/db_order_0?useUnicode=true&characterEncoding=utf8
username: root
password: 123456
ds1:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://192.168.1.11:3306/db_order_1?useUnicode=true&characterEncoding=utf8
username: root
password: 123456
ds2:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://192.168.1.12:3306/db_order_2?useUnicode=true&characterEncoding=utf8
username: root
password: 123456
分片规则
rules:
sharding:
tables:
订单表分片配置
t_order:
actual-data-nodes: ds{0..2}.t_order_{0..7}
库分片策略
database-strategy:
standard:
sharding-column: user_id
sharding-algorithm-name: db-inline
表分片策略
table-strategy:
standard:
sharding-column: user_id
sharding-algorithm-name: table-inline
主键生成策略
key-generate-strategy:
column: order_id
key-generator-name: snowflake
分片算法定义
sharding-algorithms:
db-inline:
type: INLINE
props:
algorithm-expression: ds${user_id % 3}
table-inline:
type: INLINE
props:
algorithm-expression: t_order_${user_id % 8}
主键生成器
key-generators:
snowflake:
type: SNOWFLAKE
props:
worker-id: ${WORKER_ID:0}
属性配置
props:
sql-show: true
__`_INLINE
3.3 实体类定义
__`__INLINE_java
@Data
@TableName("t_order")
public class Order {
@TableId(type = IdType.INPUT)
private Long orderId;
private Long userId;
private String orderNo;
private BigDecimal totalAmount;
private Integer status;
private LocalDateTime createTime;
private LocalDateTime updateTime;
}
__`_INLINE
3.4 数据访问层
__`__INLINE_java
@Mapper
public interface OrderMapper extends BaseMapper<Order__QUOTE_5__
四、高级分片策略
4.1 复合分片策略(标准分片)
__`__INLINE_java
/**
* 自定义分片算法:按用户ID取模分库,按订单ID取模分表
*/
@Component
public class CustomShardingAlgorithm implements
StandardShardingAlgorithm<Long>, ComplexKeysShardingAlgorithm<Long__QUOTE_6__
4.2 时间范围分片(日志场景)
__`__INLINE_yaml
按月分表配置
spring:
shardingsphere:
rules:
sharding:
tables:
t_operation_log:
actual-data-nodes: ds0.t_operation_log_{2024..2026}{(01..12)}
table-strategy:
standard:
sharding-column: create_time
sharding-algorithm-name: log-month-sharding
sharding-algorithms:
log-month-sharding:
type: CLASS_BASED
props:
strategy: STANDARD
algorithmClassName: com.example.sharding.algorithm.MonthShardingAlgorithm
__`_INLINE
__`__INLINE_java
/**
* 按月分片算法
*/
public class MonthShardingAlgorithm implements StandardShardingAlgorithm<Date__QUOTE_7__
4.3 读写分离配置
__`__INLINE_yaml
spring:
shardingsphere:
rules:
readwrite-splitting:
data-sources:
ds_master:
type: Static
props:
write-data-source-name: ds_master
read-data-source-names: ds_slave_0, ds_slave_1
load-balancer-name: round-robin
load-balancers:
round-robin:
type: ROUND_ROBIN
sharding:
tables:
t_order:
actual-data-nodes: rw_ds_{0..2}.t_order_{0..7}
__`_INLINE
五、分布式主键生成
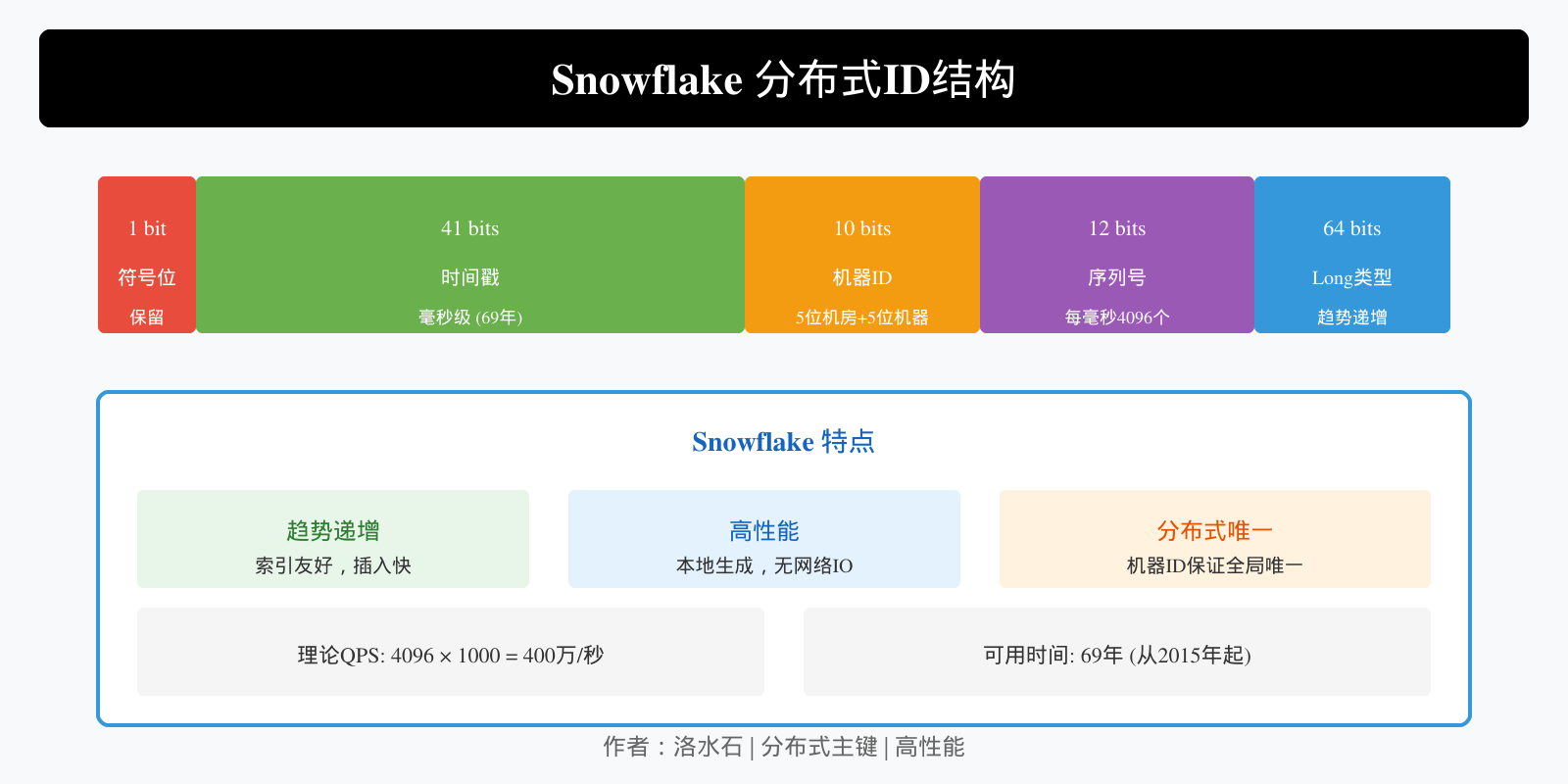
5.1 Snowflake 算法
__`_INLINE
┌─────────────────────────────────────────────────────────────────┐
│ Snowflake 结构 │
├──────────┬────────────┬──────────────┬──────────────┬───────────┤
│ 1 bit │ 41 bits │ 10 bits │ 12 bits │ 共64bit │
│ 符号位 │ 时间戳 │ 机器ID │ 序列号 │ │
│ (保留) │ (毫秒级) │ (5位机房+5位) │ (每毫秒4096) │ │
└──────────┴────────────┴──────────────┴──────────────┴───────────┘
__`_INLINE
特点 :
-
趋势递增,性能高
-
不依赖数据库
-
支持分布式部署
5.2 自定义主键生成器
__`__INLINE_java
@Component
public class OrderIdGenerator implements KeyGenerateAlgorithm {
private final Snowflake snowflake;
public OrderIdGenerator() {
// workerId 从配置中心获取
long workerId = getWorkerIdFromConfigCenter();
this.snowflake = new Snowflake(workerId, 0);
}
@Override
public Comparable<?QUOTE_8
5.3 业务 ID 生成(带业务含义)
__`__INLINE_java
@Service
public class OrderNoGenerator {
private final StringRedisTemplate redisTemplate;
/**
* 生成订单号:时间戳(14位) + 用户ID后4位 + 随机数(4位) + 序号(2位)
* 示例:20240505143000123456789012
*/
public String generateOrderNo(Long userId) {
String date = LocalDateTime.now().format(DateTimeFormatter.ofPattern("yyyyMMddHHmmss"));
String userSuffix = String.format("%04d", userId % 10000);
String random = RandomStringUtils.randomNumeric(4);
String seq = getSequence();
return date + userSuffix + random + seq;
}
private String getSequence() {
String key = "order:seq:" + LocalDate.now();
Long seq = redisTemplate.opsForValue().increment(key);
redisTemplate.expire(key, 1, TimeUnit.DAYS);
return String.format("%02d", seq % 100);
}
}
__`_INLINE
六、分页与排序
6.1 分页查询的挑战
__`__INLINE_sql
-- 跨分片分页查询需要合并多个数据源结果
SELECT * FROM t_order
WHERE create_time QUOTE_9
Sharding-JDBC 分页策略 :
-
改写 SQL:去掉 LIMIT,查询所有分片
-
内存归并:合并结果后排序、分页
-
流式归并:大数据量时避免OOM
6.2 分页优化方案
__`__INLINE_java
@Service
public class OrderService {
/**
* 优化分页:基于游标/上次查询位置
*/
public List<Order__QUOTE_10__
6.3 全局排序方案
__`__INLINE_java
/**
* 全局排序:基于时间范围限定
*/
public List<Order__QUOTE_11__
七、数据迁移与扩容
7.1 平滑扩容方案
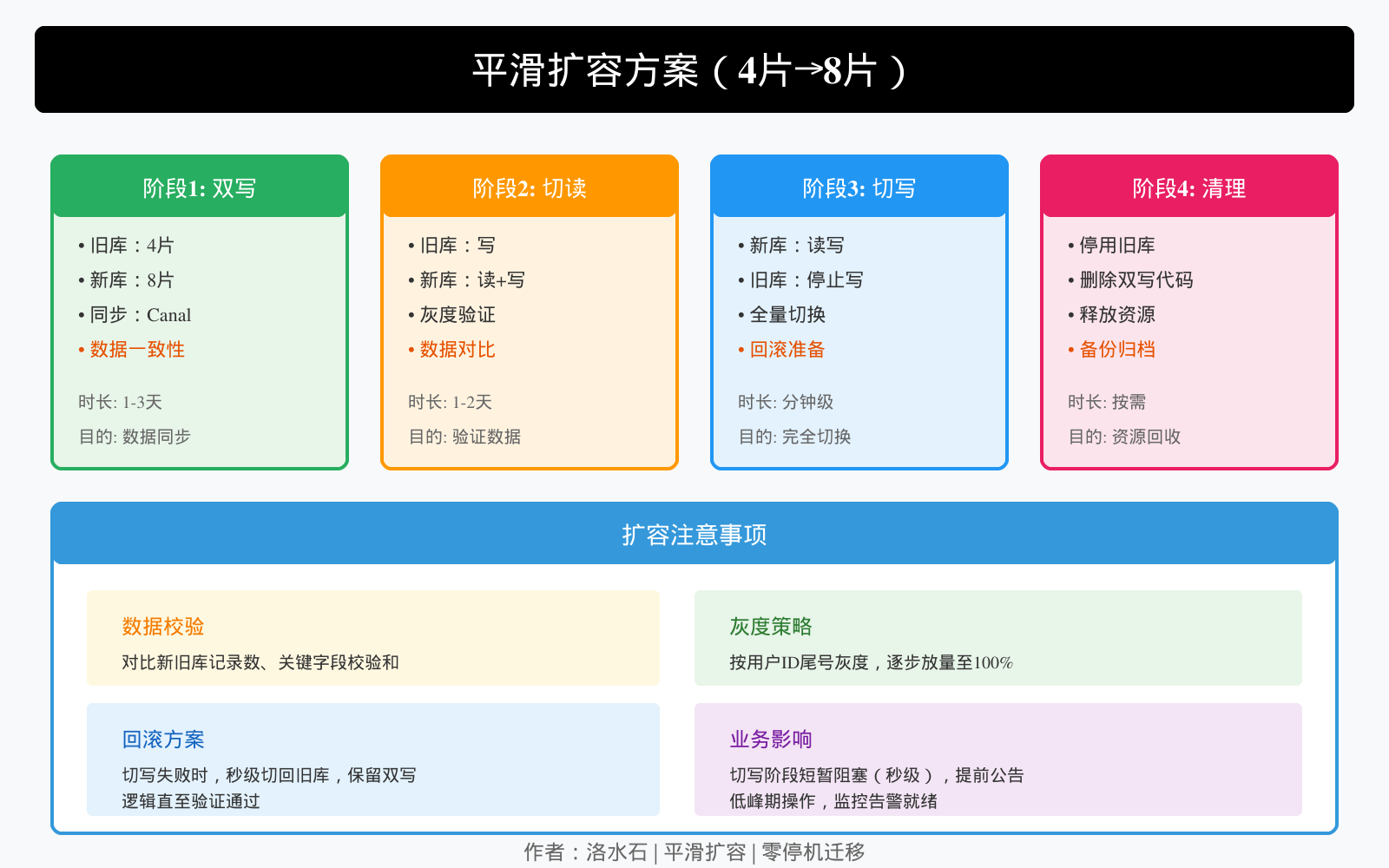
__`_INLINE
阶段1:双写阶段(数据同步)
应用 ─────→ 旧库(4片)
│
└──────→ 新库(8片)← 同步工具(Canal)
阶段2:切读阶段(验证数据)
应用 ─────→ 旧库(写)
│
└──────→ 新库(读+写)
阶段3:切写阶段(完全切换)
应用 ─────→ 新库(8片)
↑
旧库停止写入
阶段4:清理阶段
停用旧库,释放资源
__`_INLINE
7.2 双写实现
__`__INLINE_java
@Component
public class DualWriteInterceptor implements Interceptor {
@Autowired
private DataSource oldDataSource;
@Autowired
private DataSource newDataSource;
private volatile boolean writeToNew = false;
@Override
public Object intercept(Invocation invocation) throws Throwable {
Object result = invocation.proceed();
// 异步写入新库
if (writeToNew && isWriteOperation(invocation)) {
asyncWriteToNew(invocation);
}
return result;
}
private void asyncWriteToNew(Invocation invocation) {
executor.submit(() -QUOTE_12
7.3 数据校验与补偿
__`__INLINE_java
@Service
public class DataMigrationService {
/**
* 数据一致性校验
*/
public void verifyDataConsistency(Date startTime, Date endTime) {
List<Order__QUOTE_13__
八、常见问题与解决方案
8.1 跨分片 JOIN 问题
问题 :Sharding-JDBC 不支持跨分片 JOIN
解决方案 :
__`__INLINE_java
/**
* 方案1:应用层组装(推荐)
*/
public OrderDetail getOrderDetail(Long orderId, Long userId) {
// 1. 查询订单(路由到具体分片)
Order order = orderMapper.selectById(orderId, userId);
// 2. 查询用户(另一张表,同样路由)
User user = userMapper.selectById(order.getUserId());
// 3. 组装结果
OrderDetail detail = new OrderDetail();
detail.setOrder(order);
detail.setUser(user);
return detail;
}
/**
* 方案2:冗余字段(宽表设计)
*/
@Data
@TableName("t_order")
public class Order {
// 基础字段
private Long orderId;
private Long userId;
// 冗余用户字段,避免JOIN
private String userName;
private String userPhone;
private String userAddress;
}
/**
* 方案3:绑定表(关联表同分片)
*/
// YAML配置
spring:
shardingsphere:
rules:
sharding:
binding-tables:
- t_order,t_order_item
订单和订单项使用相同的分片策略,确保在同一分片
__`_INLINE
8.2 分布式事务
__`__INLINE_java
@Service
public class OrderService {
@ShardingSphereTransactionType(TransactionType.BASE)
@Transactional
public void createOrder(Order order, List<OrderItem__QUOTE_14__
8.3 热点数据问题
__`__INLINE_java
/**
* 热点用户数据缓存
*/
@Service
public class HotDataService {
@Cacheable(value = "hot:user:order", key = "#userId")
public List<Order__QUOTE_15__
九、监控与运维
9.1 Sharding-JDBC 指标监控
__`__INLINE_java
@Component
public class ShardingMetricsCollector {
@Autowired
private MeterRegistry meterRegistry;
@PostConstruct
public void init() {
// 注册分片路由指标
meterRegistry.gauge("sharding.route.time",
Tags.of("type", "routing"),
this,
ShardingMetricsCollector::getAvgRouteTime
);
// 注册SQL执行指标
meterRegistry.counter("sharding.sql.execute",
Tags.of("type", "execute")
);
}
}
__`_INLINE
9.2 慢查询监控
__`__INLINE_yaml
慢查询日志配置
spring:
shardingsphere:
props:
sql-show: true
sql-simple: false
__`_INLINE
__``java
@Component
@Slf4j
public class SlowSqlInterceptor implements QueryInterceptor {
private static final long SLOW_SQL_THRESHOLD = 100; // ms
@Override
public Object intercept(QueryInvocation invocation) throws Throwable {
long start = System.currentTimeMillis();
try {
return invocation.proceed();
} finally {
long cost = System.currentTimeMillis() - start;
if (cost QUOTE_16
总结
|---------------|----------------|-------------|
| 核心概念 | 实现要点 | 注意事项 |
| **分片键选择** | 业务维度、查询频率 | 避免热点、便于扩展 |
| **分片算法** | 取模/范围/哈希 | 考虑数据分布、扩容迁移 |
| **主键生成** | Snowflake/业务ID | 趋势递增、分布式唯一 |
| **分页查询** | 游标/限定分片键 | 避免深分页、内存归并 |
| **分布式事务** | BASE/Seata | 最终一致性 |
| **数据迁移** | 双写/校验/补偿 | 平滑切换、数据一致 |
作者:洛水石 | 数据库优化 | 分库分表实战
作者:洛水石 | 数据库优化 | 分库分表实战