一、前言
本系列仅做个人笔记使用,内容大部分来自所引用文章,侵删。
二、gRPC
RPC(Remote Procedure Call)即 远程过程调用,核心思想是 让调用远程服务的方法,就像调用本地函数一样简单,不用关心网络、TCP、HTTP、序列化这些底层细节。
RPC 是一种指导远程服务通信的设计思想,而 Dubbo、gRPC 则是该思想的高性能具体实现。
gRPC 是 Google 开源的现代化 RPC 框架,基于 HTTP/2 协议与 Protobuf 序列化格式,是一款具备高性能、跨语言、流式通信、强接口契约特性的 RPC 实现。
Protobuf 是一种通用、高效的二进制序列化协议,不仅是 gRPC 的默认数据格式,还广泛应用于数据存储、消息队列、日志传输、跨语言数据交互等场景,是追求高性能与小体积时的常用选择。
三、Protobuf
Protobuf(Protocol Buffers)是 Google 提出并开源的一种通用、高效、跨语言的二进制序列化协议。它不仅是 gRPC 默认的数据格式,还广泛用于数据存储、消息队列、日志传输、配置文件、跨语言数据交互等场景,是追求高性能、小体积、强契约时的首选方案。
1. 与 JSON 比对
| 核心对比 | Protobuf(二进制协议) | JSON(文本格式) |
|---|---|---|
| 编码格式 | 采用二进制编码,结构极其紧凑,核心特点是用数字编号替代字段名,完全摒弃引号、逗号、大括号等冗余格式符号,仅存储有效数据本身,无需额外携带格式信息,从根源上减少数据冗余。 | 采用纯文本编码,依赖大量冗余字符来定义数据结构,包括字段名的完整文本、引号、逗号、大括号、中括号等,这些格式符号不承载实际数据意义,却会占用大量传输空间。 |
| 传输体积(含 gzip 压缩) | 原始体积远小于 JSON,即使开启 gzip 压缩,体积依然是最小的(比 JSON+gzip 小10%~30%)。原因是其本身无冗余,压缩空间虽小,但基础体积极低,压缩后无需弥补文本格式的固有冗余。 | 原始体积最大,开启 gzip 压缩后体积会大幅下降(通常压缩至原始大小的20%~30%),但仍大于 Protobuf+gzip。因为其依赖文本冗余实现压缩,即使压缩后,也无法完全抵消字段名、格式符号带来的额外体积。 |
| 序列化/反序列化性能 | 性能极高,序列化和反序列化速度比 JSON 快3~10倍。因为二进制数据可直接按固定结构读取,无需解析文本字符串、处理冗余符号,无需判断字段格式,直接映射到对应数据类型,解析效率极高。 | 性能较差,解析速度较慢。因为需要先解析文本字符串,识别引号、逗号等格式符号,再提取字段名和对应值,还要进行类型转换(如字符串转数字),整个过程存在大量文本处理开销,效率远低于二进制解析。 |
| 契约约束与兼容性 | 强契约约束,通过 .proto 文件明确定义数据结构、字段类型和字段编号,编译时会自动校验字段类型和格式,避免联调时出现字段缺失、类型错误等问题;版本兼容性极强,新增字段可在末尾追加,废弃字段标记为 reserved,不影响旧版本服务正常运行。 | 弱契约约束,无统一的结构定义,字段名、字段类型可随意修改,无编译校验,容易出现字段缺失、类型不匹配等运行时错误;版本兼容性一般,字段增删改后,需要手动适配新旧版本,容易出现数据解析错乱。 |
| 适用场景与使用成本 | 适合微服务内部调用、高并发、低延迟、大数据量传输等对性能和体积要求极高的场景;使用成本中等,需编写 .proto 文件,通过编译器生成对应语言代码,团队需熟悉其语法和版本管理规则。 | 适合公开接口、前端与后端交互、简单数据传输、调试等轻量场景;使用成本极低,无需额外工具和代码生成,可直接编写文本格式数据,上手简单,所有语言均原生支持,调试时可直接肉眼查看数据内容。 |
需要注意:虽然 Protobuf 相较于 JSON 具备体积更小、序列化 / 反序列化速度更快等明显优势,但如果把它放到整个二进制序列化协议里横向对比,Protobuf 在单纯速度、极致压缩率这类单项指标上,并不一定是最优的,但Protobuf 是综合能力最均衡、工程化最成熟、长期维护成本最低的序列化方案,其他二进制协议可能在速度或体积上单项优于 Protobuf,但它们要么跨语言差、要么兼容性弱、要么生态不成熟、要么长期维护成本高。因此 Protobuf 仍活跃在各个场景下。
- 速度上:MemoryPack(.NET)、FlatBuffers、Cap'n Proto 都比 Protobuf 更快
- 体积上:有更极致的压缩协议(如 CBOR、自定义二进制格式)
- 零拷贝上:FlatBuffers、Cap'n Proto 反序列化几乎不耗时
2. proto 文件
.proto 文件是 gRPC 和 Protobuf 的 接口定义文件,他的核心作用就是 统一约定服务之间 传什么数据、怎么调用、数据结构长什么样, 保证跨语言兼容。
如:
-
定义数据结构 :用 message 定义要传输的对象
javamessage User { string name = 1; int32 age = 2; } -
定义服务接口 :用 service 定义服务能提供哪些方法
javaservice UserService { rpc getUser(UserRequest) returns (UserResponse); } -
自动生成代码 :编译器根据
.proto自动生成 :数据类(get/set、构造器)、服务端接口、客户端调用类
总的来说 :.proto 文件是 gRPC 与 Protobuf 的核心契约文件,用于定义服务接口、数据结构、字段类型与编号。它不依赖任何编程语言,却能自动生成多语言代码,确保服务之间通信格式统一、类型安全、向后兼容。简单说:先写 proto,再生成代码,最后实现业务,这就是 gRPC 的标准开发流程。
上面可以看到,我们定义的 .proto 文件是一种与语言无关的 IDL(接口定义语言),本身不依赖 Java、Go 等任何编程语言。因此需要通过专门的工具,将它编译转换为对应语言的可执行代码。
在 Maven 项目中,Protobuf 与 gRPC 官方提供了配套的编译插件,用来自动完成这一过程。
我们可以在 pom.xml 中添加如下插件配置来来完成 Protobuf 和 gRPC 的编译插件的引入:
xml
<build>
<extensions>
<extension>
<!-- 操作系统识别插件,会自动识别你当前的操作系统,并且给后面的 proto 编译器提供 `${os.detected.classifier}` 变量,让同一个 pom.xml 能在所有系统上通用,不用改配置 -->
<groupId>kr.motd.maven</groupId>
<artifactId>os-maven-plugin</artifactId>
<version>1.7.0</version>
</extension>
</extensions>
<plugins>
<!-- 编译 .proto 生成 Java 代码 -->
<plugin>
<!-- 核心编译插件,是 Protobuf 官方推荐的 Maven 编译插件。其作用是找到 `src/main/proto/` 下的所有 `.proto` 文件,调用编译器生成代码 -->
<groupId>org.xolstice.maven.plugins</groupId>
<artifactId>protobuf-maven-plugin</artifactId>
<version>0.6.1</version>
<configuration>
<!-- 指定 Protobuf 编译器(protoc)的版本, 插件会自动下载对应你系统的编译器(Windows/Mac/Linux),编译器负责把 .proto 编译成数据类 -->
<!-- 指定 Protobuf 编译器(protoc)的版本,与 protobuf-java 运行时版本保持一致 -->
<protocArtifact>com.google.protobuf:protoc:${protobuf.version}:exe:${os.detected.classifier}</protocArtifact>
<!-- 指定 proto 文件的根目录 -->
<protoSourceRoot>${project.basedir}/src/main/proto</protoSourceRoot>
<!-- 指定生成的代码输出目录 -->
<outputDirectory>${project.build.sourceDirectory}</outputDirectory>
<!-- 不清除输出目录,避免每次编译都删除所有生成的代码 -->
<clearOutputDirectory>false</clearOutputDirectory>
<pluginId>grpc-java</pluginId>
<!-- gRPC 代码生成插件, 是 gRPC 专用代码生成器。如果无需 GRPC 功能则可以不引入-->
<!-- gRPC 代码生成插件,与 grpc-netty-shaded 等运行时版本保持一致 -->
<pluginArtifact>io.grpc:protoc-gen-grpc-java:${grpc.version}:exe:${os.detected.classifier}</pluginArtifact>
</configuration>
<executions>
<execution>
<!-- 开启 goals -->
<goals>
<!-- 生成 Protobuf 数据类 -->
<goal>compile</goal>
<!-- 生成 gRPC 接口代码 -->
<goal>compile-custom</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>下文 【示例】有 GRPC 调用的完整示例。
需要注意的是:
从 JDK 9 开始,javax.annotation 包被从 JDK 标准库中移除了(模块化改造的一部分)。所以在 JDK 9+ 环境下,如果不额外引入 javax.annotation-api 这个依赖,编译生成的 gRPC 代码时就会报 cannot find symbol: class Generated 的错误。
xml
<!-- JDK9+ 需要的注解(javax.annotation.Generated) -->
<dependency>
<groupId>javax.annotation</groupId>
<artifactId>javax.annotation-api</artifactId>
<version>1.3.2</version>
</dependency>四、示例
下面我们给出一套 gRPC + Protobuf 在 Java 中的示例程序。
需要注意,本示例中使用 JDK 17 版本,不同版本引入的版本可能略有不同。
1. 基本使用
-
pom.xml 的引入:为了使用 gRPC 功能,除了上面的配置之外,还要用引入 gRPC的相关依赖,如下:
xml<properties> <maven.compiler.source>17</maven.compiler.source> <maven.compiler.target>17</maven.compiler.target> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <!-- 统一 gRPC 版本,避免各依赖版本不一致 --> <grpc.version>1.64.0</grpc.version> <protobuf.version>3.25.3</protobuf.version> </properties> <dependencyManagement> <dependencies> <!-- 引入 gRPC BOM,统一管理所有 gRPC 模块版本,避免被父 pom(Spring Boot)干扰 --> <dependency> <groupId>io.grpc</groupId> <artifactId>grpc-bom</artifactId> <version>${grpc.version}</version> <type>pom</type> <scope>import</scope> </dependency> </dependencies> </dependencyManagement> <dependencies> <!-- gRPC 核心 3 件套,版本由 grpc-bom 统一管理 --> <dependency> <groupId>io.grpc</groupId> <artifactId>grpc-netty-shaded</artifactId> </dependency> <dependency> <groupId>io.grpc</groupId> <artifactId>grpc-protobuf</artifactId> </dependency> <dependency> <groupId>io.grpc</groupId> <artifactId>grpc-stub</artifactId> </dependency> <!-- Protobuf 运行时,与 protoc 编译器版本保持一致 --> <dependency> <groupId>com.google.protobuf</groupId> <artifactId>protobuf-java</artifactId> <version>${protobuf.version}</version> </dependency> <!-- JDK9+ 需要的注解(javax.annotation.Generated) --> <dependency> <groupId>javax.annotation</groupId> <artifactId>javax.annotation-api</artifactId> <version>1.3.2</version> </dependency> </dependencies> <build> <extensions> <extension> <!-- 操作系统识别插件,会自动识别你当前的操作系统,并且给后面的 proto 编译器提供 `${os.detected.classifier}` 变量,让同一个 pom.xml 能在所有系统上通用,不用改配置 --> <groupId>kr.motd.maven</groupId> <artifactId>os-maven-plugin</artifactId> <version>1.7.0</version> </extension> </extensions> <plugins> <!-- 编译 .proto 生成 Java 代码 --> <plugin> <!-- 核心编译插件,是 Protobuf 官方推荐的 Maven 编译插件。其作用是找到 `src/main/proto/` 下的所有 `.proto` 文件,调用编译器生成代码 --> <groupId>org.xolstice.maven.plugins</groupId> <artifactId>protobuf-maven-plugin</artifactId> <version>0.6.1</version> <configuration> <!-- 指定 Protobuf 编译器(protoc)的版本,与 protobuf-java 运行时版本保持一致 --> <protocArtifact>com.google.protobuf:protoc:${protobuf.version}:exe:${os.detected.classifier}</protocArtifact> <!-- 指定 proto 文件的根目录 --> <protoSourceRoot>${project.basedir}/src/main/proto</protoSourceRoot> <!-- 指定生成的代码输出目录 --> <outputDirectory>${project.build.sourceDirectory}</outputDirectory> <!-- 不清除输出目录,避免每次编译都删除所有生成的代码 --> <clearOutputDirectory>false</clearOutputDirectory> <pluginId>grpc-java</pluginId> <!-- gRPC 代码生成插件,与 grpc-netty-shaded 等运行时版本保持一致 --> <pluginArtifact>io.grpc:protoc-gen-grpc-java:${grpc.version}:exe:${os.detected.classifier}</pluginArtifact> </configuration> <executions> <execution> <!-- 开启 goals --> <goals> <!-- 生成 Protobuf 数据类 --> <goal>compile</goal> <!-- 生成 gRPC 接口代码 --> <goal>compile-custom</goal> </goals> </execution> </executions> </plugin> </plugins> </build> -
随后定义
.proto文件,如下(包括 数据类 和 gRPC API 的定义):java// 使用 proto3 语法(现在统一用 proto3) syntax = "proto3"; // 生成的 Java 包名 option java_package = "com.kingfish.proto"; // 每个 message 单独生成一个类(推荐) option java_multiple_files = true; // ====================== // 1. 定义 gRPC 服务 // ====================== service HelloService { // 定义一个接口方法:接收请求 → 返回响应 rpc sayHello (HelloRequest) returns (HelloResponse); } // ====================== // 2. 请求结构体 // ====================== message HelloRequest { // 字段格式:类型 字段名 = 编号; // 编号一旦分配不能改、不能删 string name = 1; int32 age = 2; } // ====================== // 3. 响应结构体 // ====================== message HelloResponse { string message = 1; }结合上面 pom.xml 的配置,我们可以通过
mvn compile对项目进行编译,编译后会在com.kingfish.proto目录下生成 proto 对应的 Java 文件,如下图:
-
gRpc 服务端代码如下:
javaimport io.grpc.Server; import io.grpc.ServerBuilder; import io.grpc.stub.StreamObserver; /** * gRPC 服务端 * 1. 启动端口 * 2. 实现接口逻辑 * 3. 响应客户端 */ public class GrpcServer { public static void main(String[] args) throws Exception { // 构建服务:端口 50051 Server server = ServerBuilder.forPort(50051) // 注册我们的服务实现 .addService(new HelloServiceImpl()) .build() .start(); System.out.println("gRPC 服务已启动,监听端口:50051"); // 阻塞主线程,保持服务运行 server.awaitTermination(); } /** * 真正实现 gRPC 接口的类 * 继承自动生成的 XxxImplBase */ static class HelloServiceImpl extends HelloServiceGrpc.HelloServiceImplBase { /** * 实现接口方法:sayHello * * @param request 客户端发来的请求对象 * @param responseObserver 用于向客户端回写响应 */ @Override public void sayHello(HelloRequest request, StreamObserver<HelloResponse> responseObserver) { // 1. 从请求里取参数 String name = request.getName(); // 2. 业务逻辑 String resultMsg = "Hello " + name + ", 欢迎使用 gRPC!"; // 3. 构造响应对象 HelloResponse response = HelloResponse.newBuilder() .setMessage(resultMsg) .build(); // 4. 发送响应给客户端 responseObserver.onNext(response); // 5. 结束本次调用 responseObserver.onCompleted(); } } } -
gRPC 客户端
javaimport io.grpc.ManagedChannel; import io.grpc.ManagedChannelBuilder; /** * gRPC 客户端 * 1. 建立连接通道 * 2. 创建阻塞式 Stub(同步调用) * 3. 发起远程调用并输出结果 */ public class GrpcClient { public static void main(String[] args) { // 1. 建立与服务端的连接通道 ManagedChannel channel = ManagedChannelBuilder .forAddress("localhost", 50051) .usePlaintext() // 测试用:不加密 .build(); try { // 2. 创建阻塞式客户端 Stub(同步调用) HelloServiceGrpc.HelloServiceBlockingStub stub = HelloServiceGrpc.newBlockingStub(channel); // 3. 构造请求 HelloRequest request = HelloRequest.newBuilder() .setName("张三") .build(); // 4. 发起 gRPC 远程调用 HelloResponse response = stub.sayHello(request); // 5. 输出响应 System.out.println("服务端返回:" + response.getMessage()); } finally { // 关闭通道 channel.shutdown(); } } } -
依次启动 GrpcServer 和 GrpcClient 就可以完成 gRPC 的服务调用即可。
2. 基于 Spring Boot 使用
- GRPC 在 Spring Boot 中也有提供对应的 starter,因此我们可以直接引入该依赖:
java
<dependency>
<groupId>net.devh</groupId>
<artifactId>grpc-spring-boot-starter</artifactId>
<version>2.15.0.RELEASE</version>
</dependency>-
proto 文件与上面【基本使用】的场景相同,这里不再说明。
-
随后编写客户端和服务端代码即可发起 GRPC 调用。
java@Component public class HelloGrpcClient { @GrpcClient("grpc-server") private HelloServiceGrpc.HelloServiceBlockingStub stub; public String sayHello(String name) { HelloRequest request = HelloRequest.newBuilder().setName(name).build(); HelloResponse response = stub.sayHello(request); return response.getMessage(); } } @GrpcService public class HelloServiceImpl extends HelloServiceGrpc.HelloServiceImplBase { @Override public void sayHello(HelloRequest request, StreamObserver<HelloResponse> responseObserver) { String result = "Hello " + request.getName() + "! 来自 Spring Boot gRPC"; HelloResponse response = HelloResponse.newBuilder() .setMessage(result) .build(); responseObserver.onNext(response); responseObserver.onCompleted(); } }
--
五、扩展内容
1. Protobuf 的解析过程
Protobuf 的由于是基于二进制进行传输,所以可读性差、版本约束极强,只有在明确出现性能瓶颈的场景下才推荐使用。
并且由于 Protobuf 是基于字段编号做序列化和兼容的,所以一旦定义发布,就不能随意改动,否则会直接导致新旧版本解析错乱、业务异常。
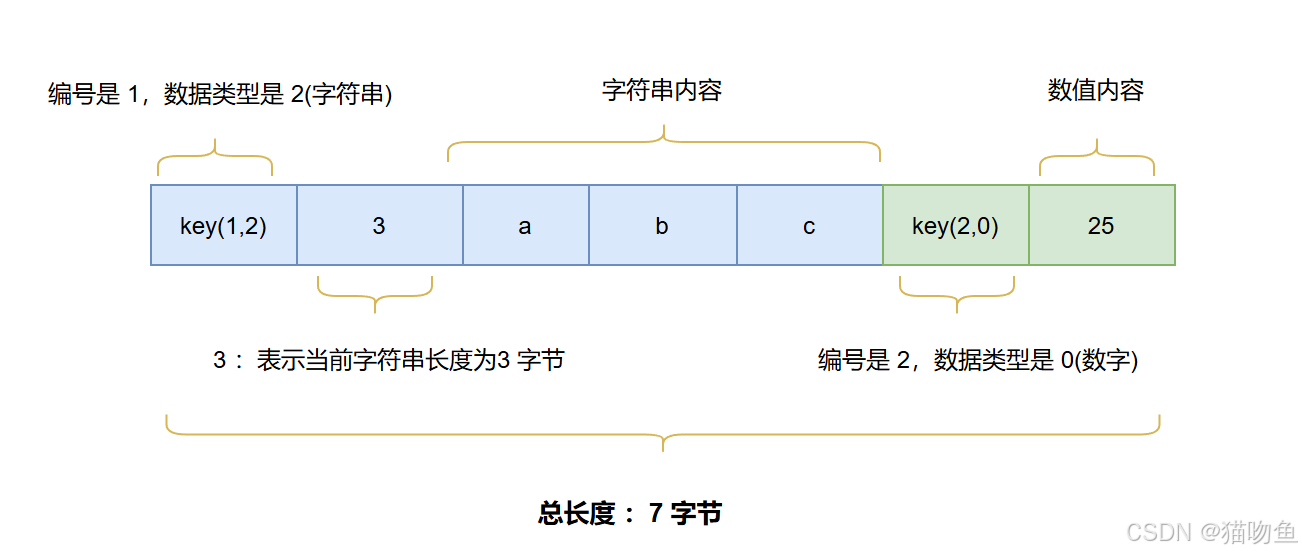
Protobuf 在传输时并不会传输字段名,只传输【编号 + 类型 + 值】。解析时,然后根据编号和类型,把二进制还原成对象。
每一个字段,传输时都变成两部分 :Key (字段编号 + 数据类型) + Value (真实值),其中 Key = (字段编号 << 3) | 类型,占用 1 字节
以下面的 User.proto 为例
java
message User {
string name = 1; // 编号1,类型2(字符串)
int32 age = 2; // 编号2,类型0(Varint)
}假设我们的数据如下:
java
name = "abc"
age = 25该数据结构在 Protobuf 解析过程中会将其编译为如下结构,共用 7 个字节:
由于 Protobuf 进行数据解析的时候是通过编号来判定(不认识的编号会直接忽略),因此我们在使用 Protobuf 时需要注意下面几点:
-
已发布的字段,绝对不能直接删除 : 删除字段会让新旧客户端/服务端对编号的理解不一致,数据解析直接出错。
-
已使用的字段编号,永远不能修改 : 编号是 Protobuf 识别字段的唯一依据,修改编号等同于字段错乱。
-
正确的废弃方式:使用 reserved 标记 : 字段不再使用时,不能删除,也不能复用编号,必须标记为保留:
protobufmessage User { string name = 1; reserved 2; // 旧字段废弃,标记为保留,禁止复用 bool vip = 3; } -
新增字段只能在末尾追加编号 : 新版本扩展只能使用从未用过的更大编号,保证向前、向后兼容。
2. Protobuf 传输体积比对
为了直观验证 Protobuf 的传输效率,我们对 JSON 原始、JSON + GZIP、Protobuf 原始、Protobuf + GZIP 这四种常见的数据传输方式进行真实场景对比,通过小数据量 与大数据量两种测试,观察体积变化规律。
2.1 验证代码
-
我们基于
User.proto文件 来进行验证:javasyntax = "proto3"; option java_package = "com.kingfish.proto"; option java_multiple_files = true; // 批量请求,用于大数据测试 message User { string name = 1; int32 age = 2; } message UserList { repeated User users = 1; }User 映射出来的 Java 对象结构如下:
jsonpublic class User { public String name; public int age; } -
编写测试代码 :通过构造批量数据,分别对四种场景进行序列化与压缩,最终输出体积对比:
javapublic class BigDataProtoVsJsonCompare { private static final int DATA_COUNT = 1000; // 1000条大数据量,1 条小数据量 public static void main(String[] args) throws Exception { // 1. 构造 1000 条模拟数据 List<User> userList = new ArrayList<>(); List<UserJson> jsonUserList = new ArrayList<>(); for (int i = 0; i < DATA_COUNT; i++) { String name = "kingfish_" + i; int age = 20 + i % 30; // Protobuf 对象 userList.add(User.newBuilder().setName(name).setAge(age).build()); // JSON 对象 jsonUserList.add(new UserJson(name, age)); } // 2. 构建 Protobuf 列表 UserList protoList = UserList.newBuilder().addAllUsers(userList).build(); byte[] protoRaw = protoList.toByteArray(); // 3. JSON 字符串 String json = JSON.toJSONString(jsonUserList); byte[] jsonRaw = json.getBytes(StandardCharsets.UTF_8); // 4. GZIP 压缩 byte[] protoGzip = gzip(protoRaw); byte[] jsonGzip = gzip(jsonRaw); // 5. 输出结果 System.out.println("===== 大数据量 1000 条用户对比 ====="); System.out.println("JSON 原始: " + jsonRaw.length + " 字节"); System.out.println("JSON + GZIP: " + jsonGzip.length + " 字节"); System.out.println("Protobuf 原始: " + protoRaw.length + " 字节"); System.out.println("Protobuf + GZIP: " + protoGzip.length + " 字节"); System.out.println("==================================="); } private static byte[] gzip(byte[] data) throws IOException { ByteArrayOutputStream out = new ByteArrayOutputStream(); try (GZIPOutputStream gzip = new GZIPOutputStream(out)) { gzip.write(data); } return out.toByteArray(); } // JSON 用的实体类 static class UserJson { public String name; public int age; public UserJson(String name, int age) { this.name = name; this.age = age; } } } -
验证输出结果
-
场景 1:大数据量(1000 条 User)
bash===== 大数据量 1000 条用户对比 ===== JSON 原始: 32891 字节 JSON + GZIP: 2669 字节 Protobuf 原始: 17890 字节 Protobuf + GZIP: 2534 字节 =================================== -
场景 2:小数据量(1 条 User)
bash===== 单条数据体积对比 ===== JSON 原始: 32 字节 JSON + GZIP: 50 字节 Protobuf 原始: 16 字节 Protobuf + GZIP: 36 字节 ===================================
-
2.2 结果总结
从两组测试结果可以明显看出:
- 无论数据量大小,Protobuf 原始体积都小于 JSON :Protobuf 使用二进制编码,不传输字段名,因此天然具备体积优势。
- 小数据量场景下,GZIP 反而会增加数据体积 :单条接口数据的体积很小,GZIP 压缩算法本身需要存储固定头部信息、校验位等额外数据,导致压缩后体积不减反增。
- 大数据量场景下,GZIP 压缩效果显著 :当数据量足够大时,重复内容变多,GZIP 可以高效消除冗余,压缩率极高。
- 最优组合:Protobuf + GZIP :在大数据量场景下,该组合体积最小,是微服务批量接口的最佳传输方案。
2.3 GZIP 算法
上面我们在结果验证中发现,小数据量场景下,GZIP 反而会增加数据体积,这是由于 GZIP 的特性导致的,因此这里我们来介绍下 GZIP 算法。
GZIP 是一种基于 LZ77 + Huffman 编码的通用无损压缩算法,擅长消除文本、重复字符串的冗余,常被用于 HTTP、RPC 传输中减少网络流量。
但 GZIP 有一个关键特点:它存在固定的头部与尾部开销(约 18~28 字节)。
这就导致:
- 数据量越小,压缩收益越低,甚至出现负优化
- 数据量越大,重复内容越多,压缩效果越明显
在微服务接口这种以小报文为主 的场景中:直接使用 Protobuf 裸传,往往比开启 GZIP 更高效、更省流量、更低延迟。只有在批量数据、日志上报、大对象传输等场景,GZIP 才能发挥真正价值。
在 Nginx 中,我们可以通过 gzip_min_length 参数设置报文达到指定长度后才会开启 GZIP 。