从零构建 AIGC 无限画布:AIGCCanvasFlow 技术全解析
当 AI 生成内容遇上可视化工作流编排,会碰撞出什么火花?本文详细拆解 AIGCCanvasFlow 的架构设计与核心实现。
项目背景
在 AIGC 大爆发的时代,用户往往需要在多个工具之间切换:写提示词、生成图片、生成视频、剪辑拼接......整个创作流程极度碎片化。我们想做的,是把这些能力统一放进一张无限画布里。
AIGCCanvasFlow 是一个基于节点图(Node Graph)范式的 AIGC 内容创作平台。用户可以在画布上拖拽节点、连线建立数据流、触发 AI 生成,最终在同一个空间内完成从文本创作到多媒体内容生成的全链路操作。
整体架构
项目采用前后端分离 + 独立 AI 服务的三层架构:
scss
┌─────────────────────────────────────────────────┐
│ 前端 (Vue 3 + VueFlow) │
│ 无限画布 · 节点编辑 · 实时预览 · 模型中心 │
└────────────────────┬────────────────────────────┘
│ HTTP / WebSocket
┌────────────────────▼────────────────────────────┐
│ 后端 (Spring Cloud 微服务) │
│ aigc-gateway · aigc-auth · aigc-canvas │
│ aigc-user · aigc-notify │
└────────────────────┬────────────────────────────┘
│ REST
┌────────────────────▼────────────────────────────┐
│ AI 生成服务 (LangChain + FastAPI) │
│ 文字润化 · 文字生图 · 文字生视频 · 图生视频 │
│ Celery 异步任务 · MinIO 对象存储 │
└─────────────────────────────────────────────────┘前端:用 VueFlow 构建无限画布
技术选型
前端的核心是 @vue-flow/core,一个专为 Vue 3 设计的节点图引擎,基于 React Flow 的思路用 Vue 重新实现。对比其他方案:
| 方案 | 优势 | 劣势 |
|---|---|---|
| VueFlow | Vue 生态原生,API 友好 | 生态相对小 |
| react-flow | 社区最大 | 需要 React |
| AntV X6 | 功能全面 | 学习曲线陡 |
| Mermaid | 简单 | 不支持交互式编辑 |
我们选择 VueFlow + Pinia 的组合,以受控模式(Controlled Pattern)管理画布状态,避免了组件内部状态与全局状态的撕裂问题。
受控模式的关键设计
VueFlow 默认是非受控的,但在复杂业务场景下必须接管状态:
javascript
// flowStore.js - 节点变更统一走 Pinia
function handleNodesChange(changes) {
nodes.value = applyNodeChanges(changes, nodes.value)
}
function updateNodeData(id, patch) {
const node = nodes.value.find(n => n.id === id)
Object.assign(node.data, patch)
// 将 outputValue 传播到下游边的 label
propagateToEdges(id, patch.outputValue)
}模板中通过绑定 :nodes + @nodes-change 实现双向同步:
vue
<VueFlow
:nodes="nodes"
:edges="edges"
@nodes-change="handleNodesChange"
@edges-change="handleEdgesChange"
/>这一模式的好处是:所有对画布的修改都经过 Pinia,持久化、撤销/重做、服务端同步都有了统一的切入点。
数据流:让节点"对话"
AIGCCanvasFlow 最有趣的特性之一是节点间的数据流。当你连接两个节点时,上游节点的输出值会自动显示在边(Edge)的中间:
javascript
function propagateToEdges(sourceId, value) {
edges.value
.filter(e => e.source === sourceId)
.forEach(e => {
e.label = value ? value.slice(0, 30) : ''
})
}这使得画布不只是静态展示,而是一个活的数据流图------你可以直观看到数据从文本节点流向 AI 生成节点,再流向视频合成节点。
节点类型设计
每种节点都是独立的 Vue 组件,通过工厂模式注册:
javascript
// FlowCanvas.vue
const nodeTypes = {
text: markRaw(TextNode),
image: markRaw(ImageNode),
video: markRaw(VideoNode),
note: markRaw(NoteNode),
group: markRaw(GroupNode),
}markRaw 是关键------VueFlow 内部会存储节点组件引用,若不标记为原始对象,Vue 的响应式系统会尝试递归代理整个组件定义,导致性能问题。
分组节点(GroupNode)
分组是实现"画布中的画布"的核心机制,利用 VueFlow 的 parentNode + extent:'parent' 实现子节点约束:
javascript
function groupSelectedNodes() {
const selected = nodes.value.filter(n => n.selected && n.type !== 'group')
// 计算包围盒
const bbox = computeBoundingBox(selected)
const groupId = `group-${Date.now()}`
// 添加 Group 节点
nodes.value.push({
id: groupId,
type: 'group',
position: { x: bbox.x - PADDING, y: bbox.y - PADDING },
data: { width: bbox.w + PADDING*2, height: bbox.h + PADDING*2 }
})
// 将选中节点绑定为子节点
selected.forEach(n => {
n.parentNode = groupId
n.extent = 'parent'
// 转换为相对坐标
n.position = { x: n.position.x - bbox.x + PADDING, y: n.position.y - bbox.y + PADDING }
})
}视频处理:在浏览器里截帧
视频节点是整个项目技术含量最高的部分之一。我们实现了纯前端的视频逐秒截帧,无需服务端介入:
Canvas 截帧原理
javascript
// useVideoFrames.js
async function extractFrames(videoEl, interval = 1) {
const canvas = document.createElement('canvas')
const ctx = canvas.getContext('2d')
canvas.width = videoEl.videoWidth
canvas.height = videoEl.videoHeight
const frames = []
const duration = videoEl.duration
for (let t = 0; t < duration; t += interval) {
await seekTo(videoEl, t) // 跳转到指定时间点
ctx.drawImage(videoEl, 0, 0)
frames.push({
time: t,
dataURL: canvas.toDataURL('image/jpeg', 0.7)
})
}
return frames
}截帧后,用户可以点击任意帧缩略图,播放器会立即跳转到对应时间点。更强大的是"+图"功能:以视频原始分辨率无损截取该帧为 PNG,在画布上自动生成一个图片节点并与视频节点连边。
ffmpeg.wasm 集成
对于需要转码或片段拼接的场景,我们集成了 @ffmpeg/ffmpeg (基于 WebAssembly 的 ffmpeg 移植)。由于 ffmpeg.wasm 需要 SharedArrayBuffer,Vite 配置了 COOP/COEP 响应头:
javascript
// vite.config.js
server: {
headers: {
'Cross-Origin-Opener-Policy': 'same-origin',
'Cross-Origin-Embedder-Policy': 'credentialless',
}
}credentialless 模式比 require-corp 更宽松,允许加载第三方资源(如 YouTube iframe),同时满足 SharedArrayBuffer 的安全要求。
AI 生成服务:LangChain + Celery 的异步工作流
为什么需要独立的 AI 服务?
AI 生成任务(尤其是视频生成)往往耗时数十秒甚至数分钟,无法用同步 HTTP 响应处理。我们用 FastAPI + Celery + Redis 实现了标准的异步任务模式:
bash
客户端 POST /api/v1/t2i/generate
→ 创建 Celery 任务,返回 task_id
→ 客户端轮询 GET /api/v1/tasks/{task_id}
→ Celery Worker 执行生成,更新任务状态
→ 完成后返回 result_urlPromptEnhanceChain:让中文提示词"开口说英文"
大多数图像/视频模型对英文提示词响应更好,但用户自然用中文输入。我们设计了 PromptEnhanceChain 来桥接:
python
class PromptEnhanceChain:
def run(self, user_input: str, mode: str = "image") -> dict:
system = IMAGE_ENHANCE_SYSTEM if mode == "image" else VIDEO_ENHANCE_SYSTEM
response = self.llm.invoke([
SystemMessage(content=system),
HumanMessage(content=user_input)
])
return parse_prompt_response(response.content)
# 输出: { "prompt": "...", "negative_prompt": "..." }系统提示词分别针对图像和视频场景优化,包含构图、光线、风格等专业描述词引导。
统一模型适配器
为了方便切换底层模型,我们设计了统一的适配器接口:
python
class BaseImageModel(ABC):
@abstractmethod
async def generate(self, prompt: str, **kwargs) -> str:
"""返回生成结果的 URL"""
pass
class FluxAdapter(BaseImageModel):
async def generate(self, prompt, **kwargs):
output = replicate.run("black-forest-labs/flux-1.1-pro",
input={"prompt": prompt, ...})
url = await upload_to_minio(output)
return url目前已对接:DALL·E 3 / Flux 1.1 Pro / SDXL (图像),可灵 2.0 / Wan 2.1 / CogVideoX / MiniMax Hailuo(视频)。
后端:Spring Cloud 微服务设计
微服务拆分逻辑
css
aigc-gateway (8080) --- 统一入口,路由转发,全局 CORS
aigc-auth --- JWT 签发/验证,登录/注册
aigc-canvas --- 画布、模型、资产核心业务
aigc-user --- 用户信息管理
aigc-notify --- 消息通知(预留)
aigc-common --- 公共模块:JWT 工具、统一响应、全局异常网关层统一处理跨域和路由,下游服务只需关注业务。JWT 鉴权通过 JwtAuthFilter 在各服务独立校验,无需回调 auth 服务------无状态设计,水平扩展友好。
模型库设计
用户可以将"广场模型"添加到个人库,也可以自定义接入私有模型,核心表结构:
sql
-- 平台模型广场
CREATE TABLE t_ai_model (
id BIGINT PRIMARY KEY,
name VARCHAR(100),
provider VARCHAR(50),
model_key VARCHAR(200),
category VARCHAR(50), -- text/image/video/audio
tags VARCHAR(500), -- JSON 数组
is_public TINYINT DEFAULT 1
);
-- 用户个人模型库
CREATE TABLE t_user_model_library (
id BIGINT PRIMARY KEY,
user_id BIGINT NOT NULL,
model_id BIGINT, -- 关联广场模型(可为空)
custom_name VARCHAR(100), -- 自定义模型名
api_key VARCHAR(500), -- 加密存储
base_url VARCHAR(300),
is_enabled TINYINT DEFAULT 1
);这一设计支持两种使用模式:平台托管 (用户只需选择,无需填写 Key)和自带密钥(BYOK)(用户填写自己的 API Key)。
交互设计亮点
拖拽创建节点
工具栏的节点拖拽利用了 HTML5 原生 Drag & Drop API + VueFlow 的坐标转换:
javascript
// Toolbar.vue
function onDragStart(e, type) {
e.dataTransfer.setData('application/vueflow', type)
}
// FlowCanvas.vue
function onDrop(e) {
const type = e.dataTransfer.getData('application/vueflow')
const { x, y } = project({ x: e.clientX, y: e.clientY }) // 屏幕坐标→画布坐标
addNodeOfType(type, { x, y })
}右键上下文菜单
通过 Vue 的 Teleport 将菜单渲染到 body 层,避免 z-index 和 overflow: hidden 的裁剪问题:
vue
<Teleport to="body">
<ContextMenu
v-if="contextMenu.visible"
:x="contextMenu.x"
:y="contextMenu.y"
:target="contextMenu.target"
/>
</Teleport>性能与工程化
- WASM 懒加载:ffmpeg.wasm 体积较大(~30MB),采用按需加载,首次调用时才下载,不影响初始加载速度
- 骨架屏:模型广场列表使用骨架屏(Skeleton)加载,改善感知性能
- markRaw 优化 :所有节点组件类型用
markRaw包裹,避免 Vue 对其进行响应式代理 - Nacos 配置中心:Spring Cloud 服务配置统一托管,支持热更新
当前状态与路由规划
| 路由 | 状态 | 说明 |
|---|---|---|
/ |
已上线 | 首页,登录入口 |
/login |
已上线 | 登录/注册(深色主题) |
/canvas |
已上线 | 无限画布编辑器 |
/models |
已上线 | 模型中心(广场 + 我的模型库) |
/projects |
开发中 | 项目列表,多画布管理 |
本地运行
bash
# 前端
cd h5 && npm install && npm run dev
# 访问 http://localhost:5173
# AI 服务
cd LangChain && cp .env.example .env
pip install -r requirements.txt
make all # uvicorn + celery 一键启动
# 后端(需 JDK 17+, MySQL, Nacos)
cd admin
mvn spring-boot:run -pl aigc-gateway
mvn spring-boot:run -pl aigc-auth
mvn spring-boot:run -pl aigc-canvas界面预览
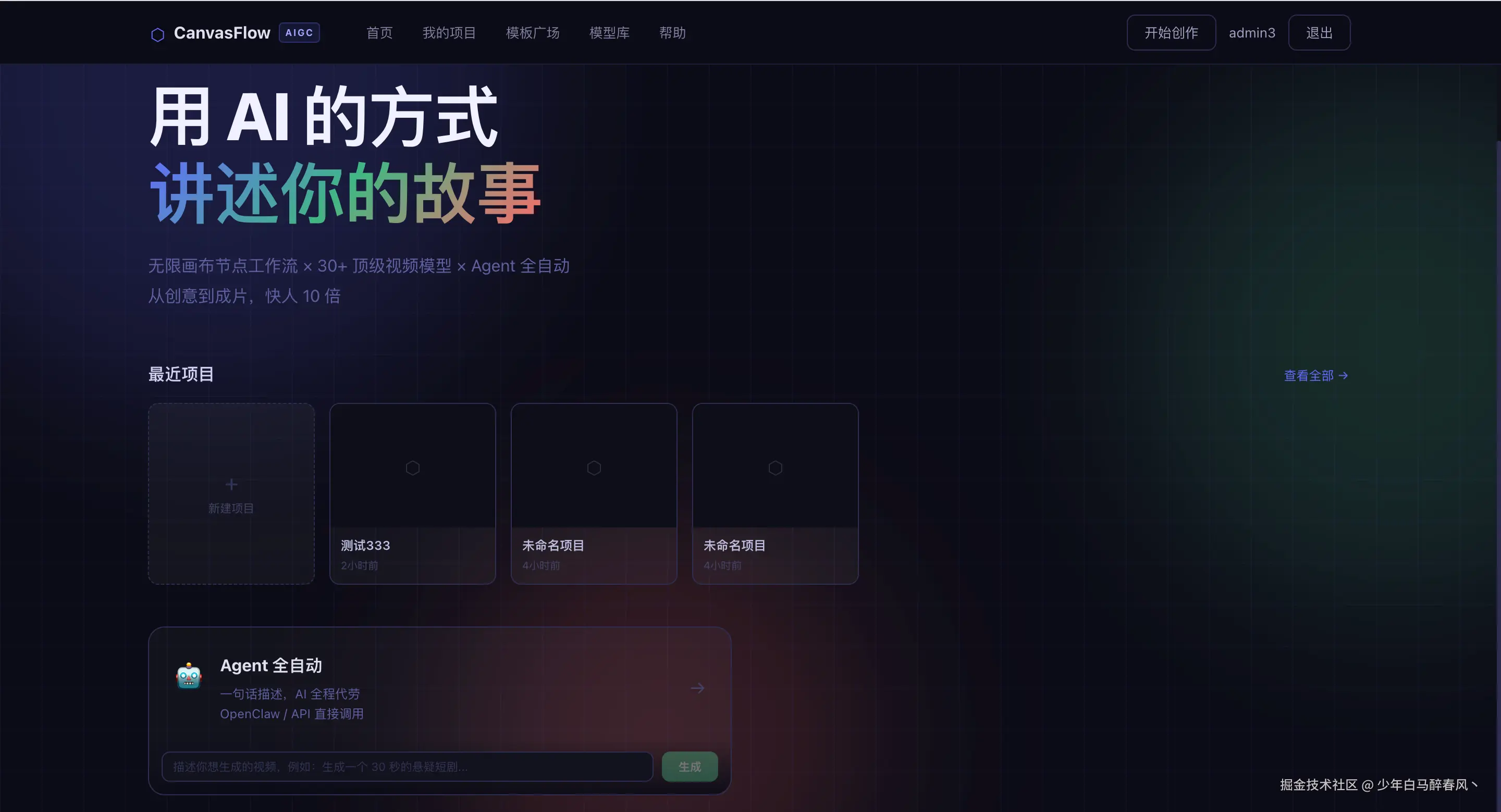
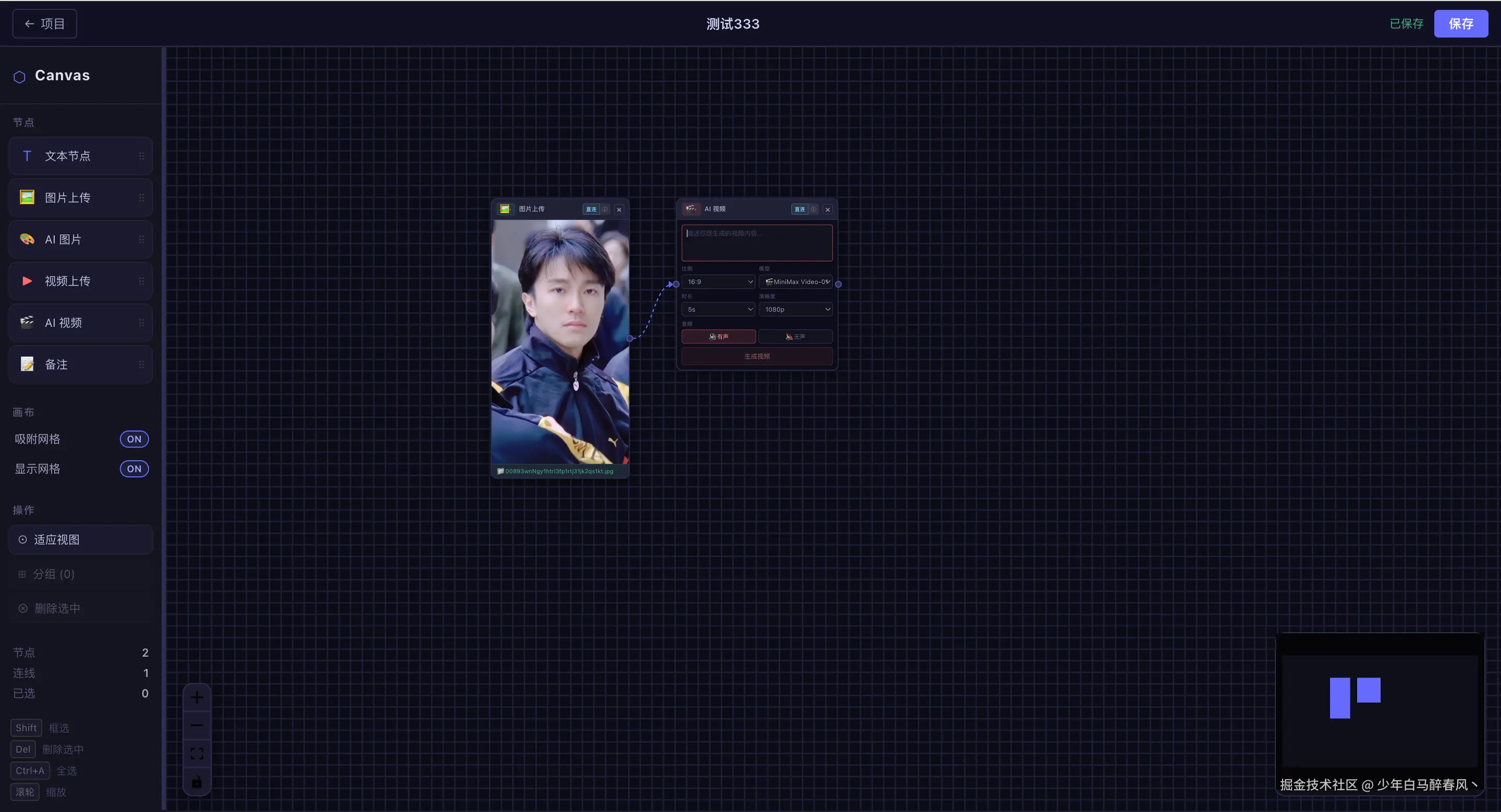
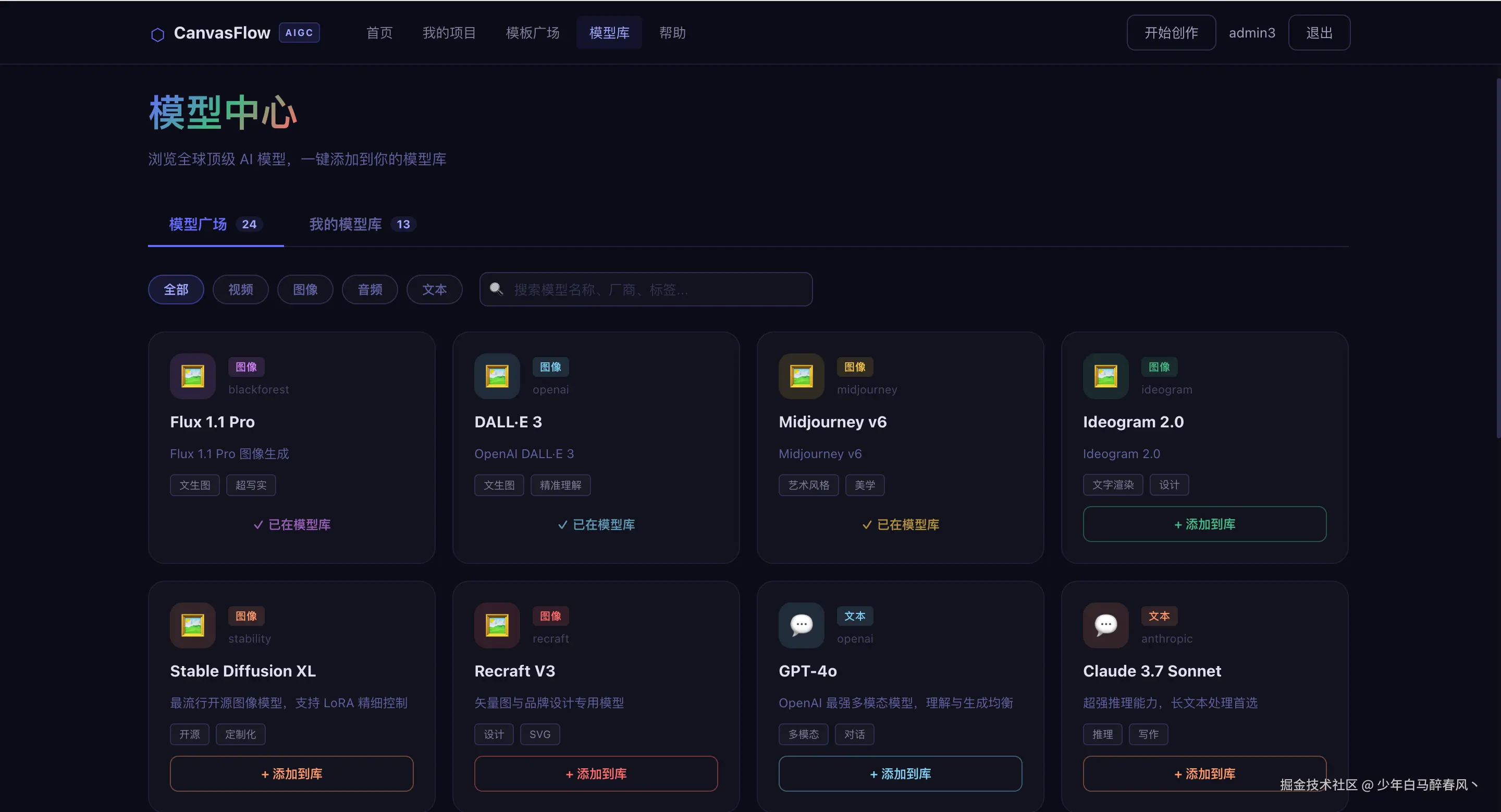
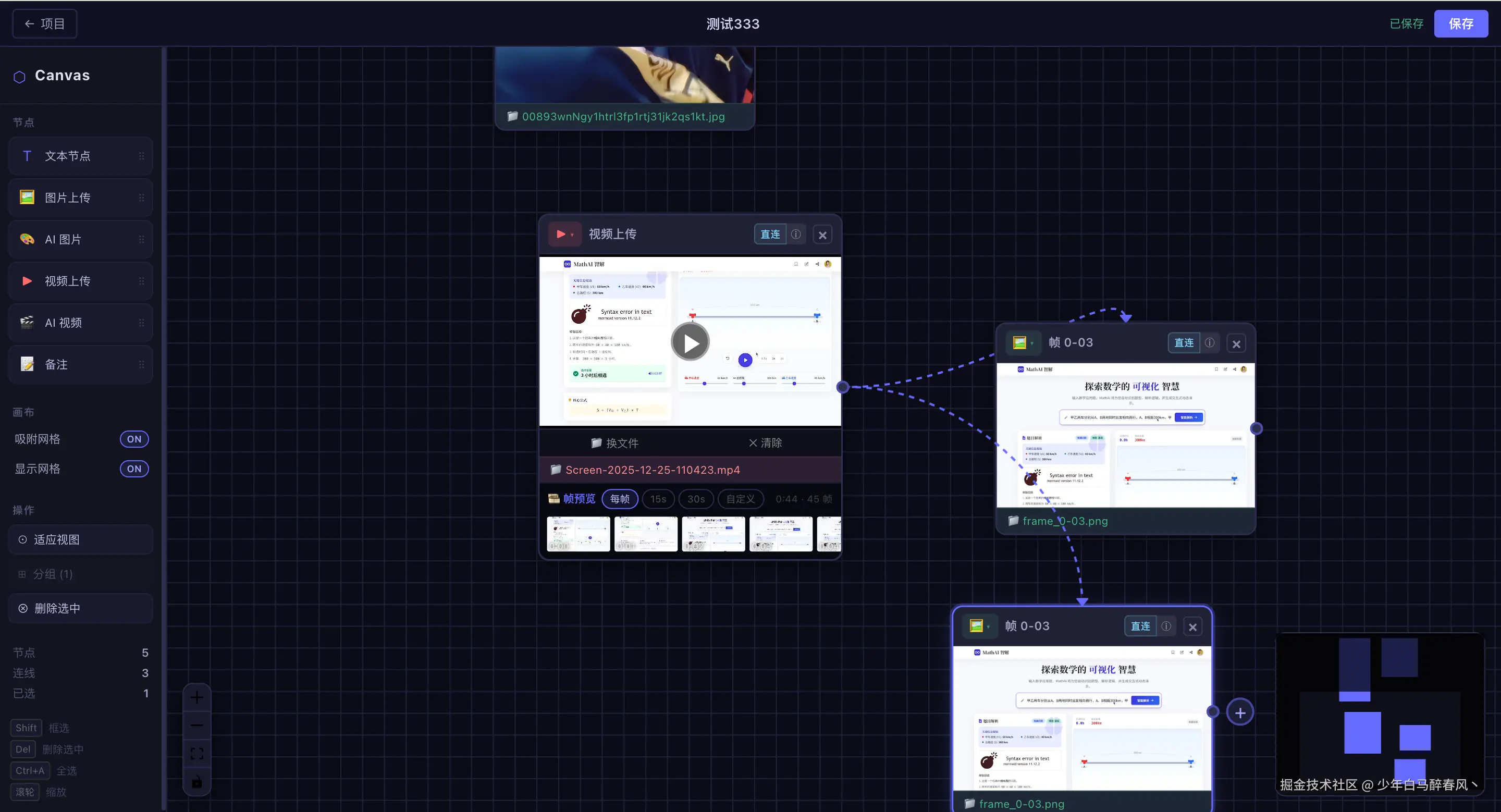
总结
AIGCCanvasFlow 探索了一种"画布即工作流"的 AIGC 创作范式,核心设计理念有三:
- 可视化数据流:节点图不只是 UI,节点间的连线即代表数据/内容的流动路径
- 端能力下沉:视频截帧、格式转换等能力尽量在前端完成,减少服务端压力
- 模型无关性:通过统一适配器抽象底层 AI 模型,方便接入新模型或替换现有模型
这只是一个起点。接下来计划实现:多人协同编辑(CRDT/WebSocket) 、工作流自动执行 (节点连线即 Pipeline)、生成历史版本管理,以及更丰富的节点类型(音频、3D、代码执行)。
技术栈:Vue 3.5 · VueFlow · Pinia · Spring Cloud · LangChain · FastAPI · Celery · ffmpeg.wasm
如果你对 AIGC 工具链、节点图引擎、或者前端视频处理感兴趣,欢迎一起探讨。 github.com/MaLunan/AIG... 欢迎start