Documentation 是任何 data project 中的关键组成部分,它为理解和有效使用数据提供必要 context 和 insights。然而,它经常没有得到应有的优先级。编写 documentation 是一个耗时的过程,而且它通常不会像开发一个新 product feature 那样立刻带来明显结果。它不是那种 flashy、sexy、leaders 通常喜欢看到的工作,因此常常会被降级优先级。通常,每个人都同意它很重要,但似乎总有别的事情更加重要。此外,tech 变化非常快,很多人担心 documentation 很快就会过时,因此选择不写。
我们长期支持 documentation 尽可能靠近 developer 正在使用的 tools 和 services。虽然让 developer 停下来,离开正在做的事情,去另一个 application 中写 Word doc 或 article 是合理要求,但这确实很难做到。最好的 documentation,是 developer 在写代码时同步创建的 documentation,这样它就会成为日常工作的一部分。和本书中讨论过的其他领域一样,我们认为这正是 dbt 非常擅长的地方。本章中,我们将探索 dbt documentation features 的力量,并学习如何为 data models 和 schema 创建 comprehensive 且 effective 的 documentation。
借助 dbt,你可以生成清晰、直观的 documentation。它不仅捕获 data models 的 technical details,也能为 technical 和 nontechnical users 提供 valuable insights。dbt 的做法是收集关于你正在处理的数据和 dbt project 的信息,并以 JSON file 的形式存储这些信息。如果你使用 dbt Cloud,它有一个非常好的 feature,可以通过易用的 web page 展示这些信息。
在你提供少量帮助的情况下,dbt 会自动为你 extract metadata,收集关于 data models 的信息,包括 tables、columns、data types、nullability 等 object information,甚至还会收集关于 data 的 statistics,例如 row counts 和 table sizes。它也支持 customization,使你能够根据组织的 specific needs 调整 documentation。你可以为 models 添加 rich text descriptions,提供详细解释和 context,从而有效构建 data dictionary。
dbt 生成的 documentation 不只是 data models 和 schema 的 static representation。它提供 interactive features,使 users 能够有效探索并与 documentation 互动。Data lineage visualization 等功能允许 users 追踪 data transformations 的流动路径,从而更深入理解 data pipeline。此外,documentation 中查看 sample data 的能力,能让 users 预览 tables 和 columns 中实际存在的数据,帮助 data exploration 和 analysis。Automatic updates 确保 data models 或 schema 的任何 changes 都会反映在 documentation 中,从而消除 manual updates 的需要,节省宝贵时间和精力。
接下来的 sections 中,我们会引导你完成 documentation environment 的设置、使用 dbt 生成 documentation、通过 customization 增强 documentation,以及维护 documentation integrity 的过程。我们还会探索 collaboration 和 documentation workflows、advanced topics,以及持续维护 documentation 的重要性。让我们开始深入,释放 dbt documentation features 的力量,为 data projects 创建 comprehensive 且 informative 的 documentation。
Understanding dbt Documentation
为了充分发挥 dbt documentation capabilities,必须扎实理解它如何工作,以及它能提供什么。本节中,我们将深入介绍 dbt documentation 的关键方面,为你创建 comprehensive 且 insightful 的 data project documentation 提供必要知识。
虽然在本章 introduction 中已经触及其中一些内容,但我们仍希望逐一突出这些 benefits,并说明它们的作用:
- Interactive web page
- Metadata extraction
- Customization
- Showcase relationships and data lineage
- Automatic updates
通过 dbt Cloud 使用 dbt 构建 documentation 的最大好处之一,是它会为你创建一个 interactive web page,你可以直接从 dbt Cloud 访问并与之交互。不需要离开 developer environment,一切都在你工作的地方。并且,通过运行一条简单的 dbt command,也就是 dbt docs generate,你可以在几分钟内填充并运行这个页面。虽然后续还可以做大量 enrichment,但在 project 开始后,你会立刻获得很多自动填充的 valuable information。图 9-1 展示了页面填充后的样子。我们会在本章后面覆盖这个 web page 的各个 components。
图 9-1:dbt Cloud documentation web page
dbt documentation 提供 data models 和 schema 的 holistic view,让 users 能够获得关于 data infrastructure 中 structure 和 relationships 的 valuable insights。借助 dbt 的 metadata extraction capabilities,你可以自动提取 table 和 column names、data types、descriptions,以及 objects statistics 等关键信息。这些丰富信息会增强 documentation,使 users 能够快速理解 data assets 的 purpose 和 content。
除了捕获 technical details,dbt documentation 也允许你从 descriptions 开始添加自己的 customizations。这意味着你可以为 tables、columns 和其他 objects 添加 rich text descriptions,从而有效创建任何人都可以 reference 的 data dictionary。你还可以超越 technical specifications,包含每个 data model 的 purpose、assumptions,以及 applied transformations 的高层解释。这些 descriptive elements 为 users 提供 valuable context,帮助他们理解 data structures 背后的 rationale,以及它们在整体 data ecosystem 中扮演的角色。你也可以纳入 additional metadata,例如 business glossary terms 或 data quality indicators,以提供更全面的 insights。本章剩余部分会继续覆盖这些内容。
dbt documentation 的另一个关键方面,是它能够展示 relationships 和 data lineage。理解 data 如何在 data models 中流动和转换,对于理解 end-to-end data pipeline 至关重要。dbt 的 documentation features 通过 DAGs 提供这些 relationships 的 visual representations,使 users 能够追踪 data transformations 的路径,并洞察 data infrastructure 中 dependencies 和 changes 的影响。
最后一个 benefit 是:你的所有 documentation 都是 automated 的,并且可以作为 transformation pipeline 的一部分构建。不需要手动填充或更新 external page,dbt 会为你处理 heavy lifting。你仍然需要在 dbt 中保持一些信息更新,例如 descriptions 和 customized additions,但很多项目,例如 metadata fields,都会自动更新。
通过充分利用 dbt documentation,你可以创建不仅作为 technical reference 的 documentation,也可以成为 data consumers 和 stakeholders 的 valuable resource。它弥合了 technical complexity 与 user-friendly understanding 之间的 gap,使组织中不同角色的人都能基于可靠且充分文档化的数据资产做出 informed decisions。
Adding Descriptions
如果不使用 sources 和 tests 这类能力,就很难充分利用 dbt 提供的巨大价值。几乎每个 project 都至少会有一个 source YAML file,用于保存 source information。你也很可能会有多个 schema YAML files,用来保存 model information 和 generic test configurations。这些 YAML files 正是你添加 object descriptions 的地方,这些 descriptions 会被填充到 documentation web page 中。如果这听起来很熟悉,那是因为确实如此。本书之前在覆盖 sources、models 和 tests 的 YAML files 构建时,已经讲过这些内容,现在它们形成闭环。
dbt 允许你在 YAML files 中为 project 中几乎所有内容添加 descriptions,包括:
- models
- model columns
- seeds
- seed columns
- sources
- source tables
- source columns
- macros
- macro arguments
- snapshots
- snapshot columns
- analyses
- analyses columns
Descriptions 只能添加在 YAML files 中,不能在其他地方创建。例如,你不能在 model file 本身中添加关于 model 的 description。你可以使用 comments,但这些 comments 不会填充到 description fields 中。
在 YAML files 中添加 descriptions 非常简单。如果你跟着本书走到这里,应该已经比较熟悉。不过,我们还是来看一个示例。假设我有一个名为 Sales 的 model,它有三个 columns:product、sales_date 和 sales_total,我希望为它们添加 descriptions,并填充到 documentation site 中。我会打开包含该 model 信息的 schema.yml file,或者如果不存在就创建一个,然后添加对应 values。图 9-2 展示了它的样子。
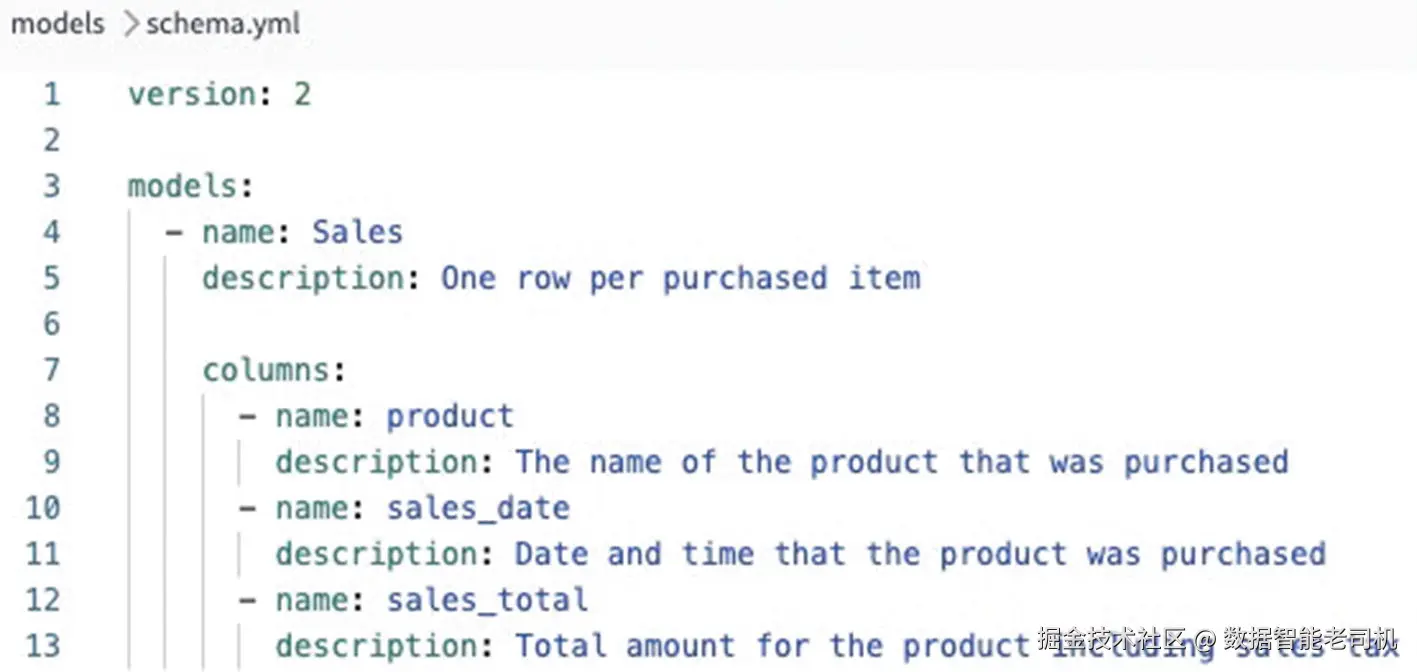
图 9-2:在 schema.yml file 中添加 description 的示例
Syntax 很简单,我们只需要在 name blocks 下包含 description:,并添加 text description。一般经验法则是:只要你在 YAML file 中看到 - name,通常就可以在它下面添加 description。
这是一个非常简单的例子,因为 model name 和 columns 本身已经比较 descriptive。但实际情况并不总是这样。即使名称本身有描述性,model 和 column name 也很难讲完整故事,可能仍然需要补充 additional context。例如,我们使用 sales_total,看起来足够简单,但 data user 可能不知道这个 field 已经包含 sales tax。在这里添加 description 可以提供 context,确保 consumers 以相同方式使用这份 data,并理解它的含义。
Descriptions 有一些很酷的能力,但如果不小心,也有一些可能踩坑的地方。下面是写 descriptions 时需要考虑的事项:
- Descriptions 不需要限制在一行内,可以在 YAML file 中延伸多行。不过,你不能直接换行开启新行,否则会 break。
- 可以使用 YAML block notation 为 models 添加 multiline descriptions。当你有较长 description,希望跨多行展开时,这很有帮助。
- Description 支持 Markdown。
- Descriptions 必须遵守 YAML semantics。如果使用冒号、方括号或花括号等特殊字符,需要给 description 加 quotes。否则 YAML parser 会困惑并失败。使用 Markdown syntax 通常几乎总是需要 quotes。
- 可以在 description 中使用 doc blocks。下一节会讨论它们。事实上,对于超过一两句简单句子的复杂内容,我们推荐使用 doc blocks。
- 可以在 description 中链接到其他 models。
- 可以在 descriptions 中包含 images,既可以来自 repo,也可以来自 Web。后面 section 也会覆盖这一点。
Note
Descriptions 需要遵守 YAML semantics。如果使用冒号、方括号或花括号等特殊字符,需要给 description 加 quotes,否则会失败。
Doc Blocks
在 dbt project 中,你可以在 YAML files 中添加任何想要的 description,但有时内容会变得很长。一旦开始向 YAML files 中添加长 descriptions,很快就会发现它们被大量信息淹没,变得难以导航。此外,同一个 column definition 在多个 models 中复用也很常见。如果可以只写一次 description,然后在整个 project 中复用它,会非常有用。这正是 doc blocks 发挥作用的地方。
借助 doc blocks,你可以在 project 中创建一个 Markdown file 来保存 additional documentation,然后只需要从 YAML files 中引用它。Markdown files 使用 .md extension,并可以创建在任何 resource path 中。默认情况下,dbt 会在所有 resource paths 中搜索 doc blocks,但我们建议将它们放在你计划引用它们的同一个 resource directory 中。最终 documentation 的结果仍然完全一样,但你的 YAML files 会保持干净很多,也更容易导航。此外,你可以更加遵循 DRY(Don't Repeat Yourself)实践,因为可以写一次 description 并复用它。一般规则是,我们喜欢只把短的 text-only descriptions 直接添加到 YAML files 中。如果需要包含大量信息,或者需要使用 Markdown,就使用 doc blocks。
Tip
一般规则是,我们喜欢只把短的 text-only descriptions 直接添加到 YAML file 中。如果需要包含大量信息并且 / 或者需要使用 Markdown,就使用 doc blocks。
你创建的每个 Markdown file 都可以包含任意数量的 doc blocks,我们通常也建议这样使用。你可以创建一个 Markdown file 来包含所有 documentation,例如 docs.md,也可以创建多个 Markdown files,并按自己喜欢的方式分组。我们建议先从一个开始,等需要时再拆分。
在 Markdown file 中,你会创建 doc blocks。Doc blocks 以 {% docs <your doc name> %} 开始,后面跟你的 text,然后以 {% enddocs %} 结束。这些 tags 告诉 dbt 如何解释它们。来看图 9-3,如果我们想为 order statuses 创建一张 table,它会是什么样子。
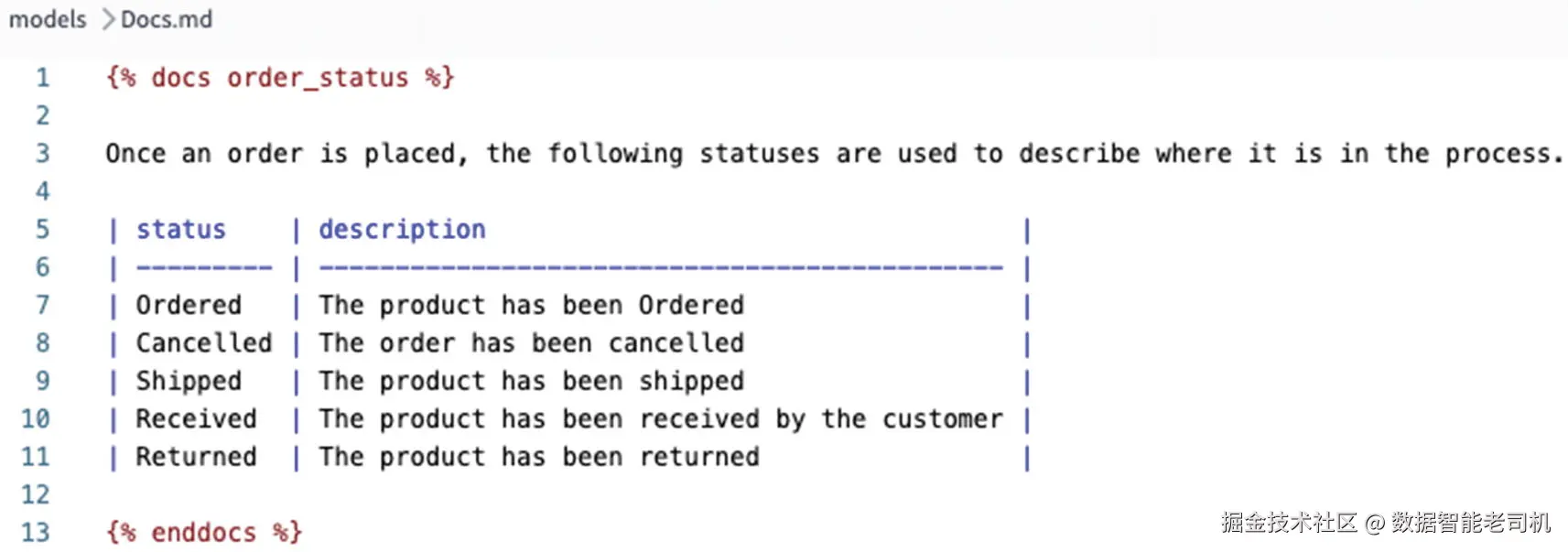
图 9-3:doc block 示例
可以看到,在这个示例中,我们有一张 table,其中包含各种 order statuses 及其 descriptions。我们本可以将这些 text 直接添加到 YAML file 中,但可以想象,那会变得非常 messy。而在这里,它很容易查看和理解。
只要内容被包含在 doc block 中,我们就可以使用 Markdown 任意编写和格式化 text。在第一行,我们必须为 doc block 命名,这也是从 YAML file 中引用它的方式。这个 doc block 名为 order_status,因此可以使用 {{ doc() }} Jinja command 引用它。来看图 9-4,了解如何引用它。
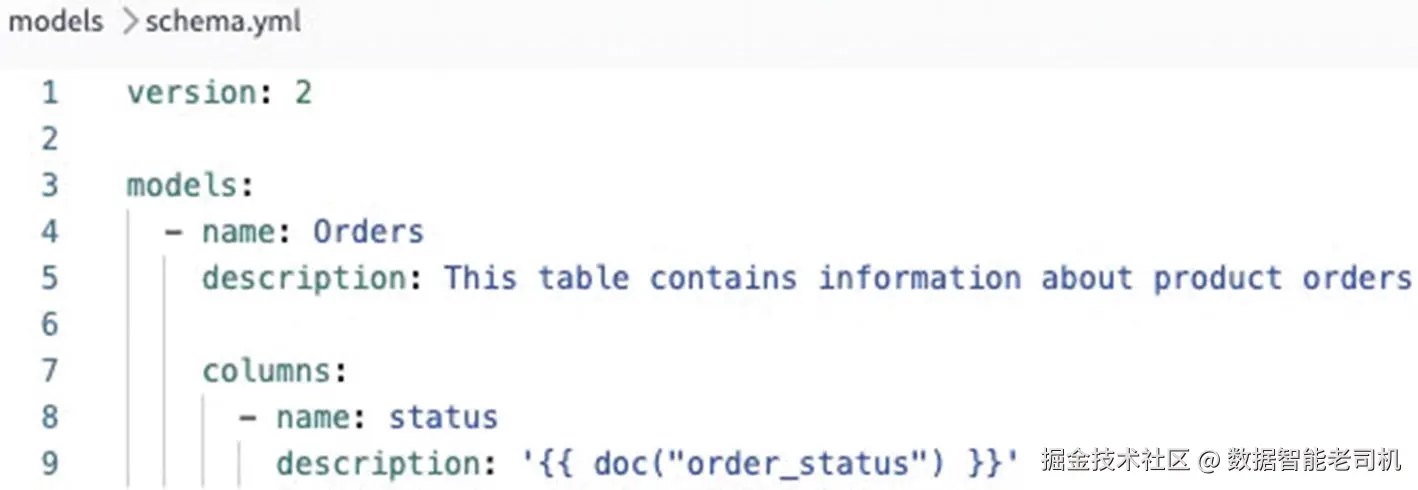
图 9-4:在 YAML file 中引用 doc block
可以看到,我们只需要插入 {{ doc() }} Jinja command,并传入 code block 的名称,它就会实现与直接把所有内容放在那里相同的效果。只是现在干净很多。
使用前面同一个 doc.md file,我们可以创建 additional doc blocks,并使用相同 Jinja command 引用它们。只需要把 order_status name 替换为新 doc block 的名称即可。
在 dbt Cloud 中创建 Markdown files 的另一个好处,是它包含 formatter 和 Markdown preview pane。其他 IDEs 可能也有类似 features,但它被直接内置在 dbt Cloud 中很方便。在图 9-3 中,看起来像是我们创建了一个格式完美的 diagram,但实际上我们只是逐行输入信息,让 dbt 帮我们处理 formatting。这使你能够很好地格式化内容,并在保存前查看 output 会是什么样。虽然你也可以在 YAML files 本身中使用 Markdown,但无法利用 formatter 和 preview features。
Understanding Markdown
由于刚才已经介绍了 doc blocks,我们稍微绕一下,帮助那些可能不熟悉 Markdown 的读者。本书不是 Markdown 教程,所以这里只会轻度覆盖,但我们想让你了解它是什么,以及如何使用。如果你已经熟悉 Markdown,可以直接跳到下一节。
Markdown 是一种 plain text formatting syntax,允许你用简单、可读的方式写内容,同时仍然可以添加 basic formatting elements。它由 John Gruber 于 2004 年创建,目标是让人更容易为 Web 写作,而不需要复杂的 HTML tags。Markdown files 使用 .md extension 保存。
Markdown 被广泛使用,并被各种 platforms 和 applications 支持。你可以使用 Markdown 编写 documentation、创建 blog posts、格式化 GitHub 上的 README files、写 forum comments 等。它提供了一种便捷方式来组织 text 并添加 basic formatting,而不需要担心 HTML 或其他 markup languages 的复杂性。
开始使用 Markdown 很简单,所有内容都用 plain text 编写。来看一些 Markdown 中的基础 syntax 和 formatting options。
Headers 对组织内容、创建不同层级 headings 很有用。可以通过在一行开头使用 hash(#)symbols 来创建 headers。Hash symbols 的数量决定 header level,一个 hash symbol 表示最大的 header(H1),六个 hash symbols 表示最小的 header(H6)。示例:
shell
# Heading 1
## Heading 2
### Heading 3要强调或高亮某些 words 或 phrases,可以使用 asterisks(*)或 underscores(_)。Italic text 使用单个 asterisk 或 underscore,例如 *italic* 或 _italic_。Bold text 使用双 asterisks 或双 underscores,例如 **bold** 或 __bold__。示例:
scss
This is *italic* and **bold** text.Markdown 同时支持 ordered 和 unordered lists。创建 unordered list 时,只需在每个 item 前使用 hyphens(-)、plus signs(+)或 asterisks(*)。创建 ordered list 时,在每个 item 前使用 numbers 加 periods(.)。示例:
markdown
- Item 1
- Item 2
- Item 3
1. Item 1
2. Item 2
3. Item 3Markdown 还支持创建 tables,正如本章前面图 9-3 所示。它们通过 pipes 和 hyphens 来分隔 headers 和 columns。
这些只是 Markdown 中最常见的一小部分能力,并非全部。其他 options 包括添加 code blocks、tables、task lists、footnotes 和 linking URLs。我们非常喜欢的一个资源是 Markdown Guide website,尤其是它的 cheat sheet:
bash
www.markdownguide.org/cheat-sheet/这个 cheat sheet 提供了一个快速查询表,可以查到 Markdown 中大多数操作该怎么做。
Adding Meta
dbt 允许你为 objects 创建 descriptions,并输入任何你想写的 text;但你也可以使用 meta field 为 resource 创建自己的 metadata。Metadata information 会在 autogenerated documentation 中作为独立 field 显示,并且可以是任何你想要的内容。例如 owner、contact information、refresh intervals,或者某个 field 是否包含 sensitive data。但你不受限制,可以添加任何想要的内容。事实上,添加其他 stack 中的 tools 可能会引用的 metadata 也很常见,例如 data orchestration platform。
Meta fields 与 descriptions 类似,定义在 YAML files 中;但对于某些 resource file types,也可以在 config() blocks 中定义。以下 items 支持 meta field:
- models
- model columns
- seeds
- seed columns
- sources
- source tables
- source columns
- macros
- macro arguments
- snapshots
- snapshot columns
- singular tests via the
config()block
先看一个示例,说明如何为一个名为 ProductDB 的新 source 添加 meta fields。对于这个 source,我们想在 source level 创建五个 metadata fields:department_owner、contact、contact_email、contains_pii 和 refresh_interval,并为它们赋值。图 9-5 展示了它在 sources.yml file 中的样子。
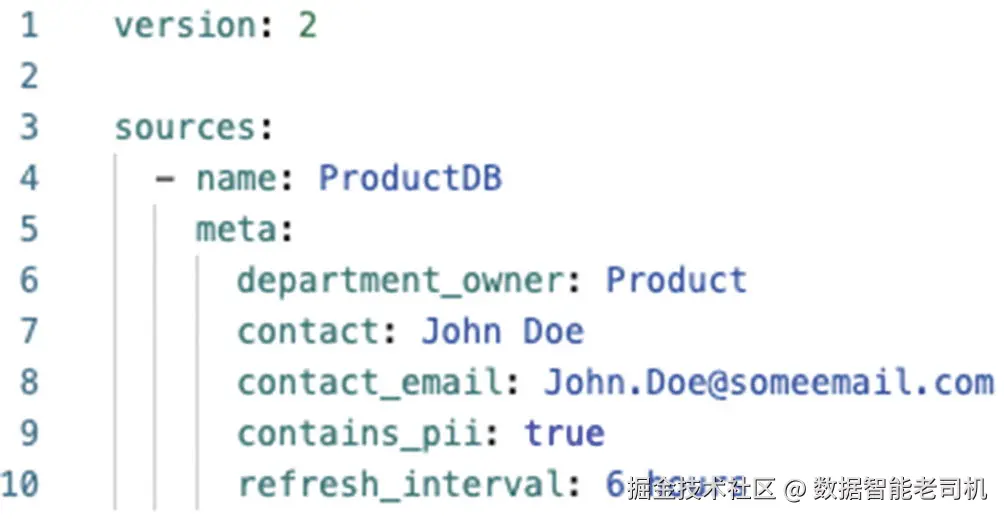
图 9-5:向 sources.yml file 添加 meta fields
如果愿意,你可以进一步 drill down,并在 individual columns 上包含 meta fields。此外,也可以在 schema.yml files 中以相同方式为 models 和其他 resource types 添加 meta fields。Syntax 是一样的。
你也可以使用 config() block 直接在 resource files,也就是 models 中分配 meta fields。这可以用于分配新的 meta value,或覆盖 YAML files 中定义的 existing value。可以使用以下 config block syntax:
ini
{{ config(
meta={<dict>},
) }}<dict> 只需要替换为 meta value 的名称和你希望设置的值。假设我想为这个 model 添加一个 contact,并设置为 John Doe,那么 syntax 会像这样:
ini
{{ config(
meta={"contact": "Jane Doe"},
) }}每当你添加 meta fields,它们都会在 dbt docs web page 中作为 separate fields 生成。本章后面在看如何导航 documentation website 时,会看到这些内容如何展示。
可以看到,meta fields 为记录 dbt project 中 objects 打开了很多可能性,非常有益。然而,如果没有计划,它们也可能变得很 messy,这与使用 tagging 的 systems 很相似,如果你用过那类系统的话。因此,我们强烈建议制定一个标准来规定它们如何使用,以避免创建一个混乱的 project。这个标准应包括添加哪些 meta fields、添加在哪里,以及如何命名。没有标准时,你可能会出现大量 meta fields 到处漂浮、缺失 values,或者同一件事有不同 spelling variations。
Utilizing Images
dbt 支持在 documentation 中使用 images,并且 images 可以通过两种方式引用。第一种是引用直接存储在 source control repository 中的 images。第二种是通过 URL links 引用 images。Images 可以直接从 YAML files 中引用,也可以从 doc blocks 中引用。
先说如何将 images 直接存储在 source control repository 中。为此,你需要在 dbt project 中创建一个新的 directory,命名为 assets。它应创建在 project root 下。创建 folder 后,需要更新 dbt_projects.yml file 来配置 assets path。为此,在 YAML file 中其他 resource paths 下方添加以下 entry。添加后它应该大概像这样:
rust
model-paths: ["models"]
analysis-paths: ["analyses"]
test-paths: ["tests"]
seed-paths: ["seeds"]
macro-paths: ["macros"]
snapshot-paths: ["snapshots"]
asset-paths: ["assets"]我们只添加了一个 new entry,但我也加入了其他 entries,作为它应该放在哪里的参考。添加完成后,将 changes commit 到 repository,以便 folder 被创建。
assets folder 是你可以存储 images 并引用它们的地方。不过,如果你是 dbt Cloud user,可能会尝试直接通过 Cloud IDE 上传 image,但不幸的是,截至本文写作时,这还不被支持。要上传 image file,需要在 Cloud IDE 之外直接将 image 添加到 repo 中。
Note
目前不能使用 dbt Cloud IDE 上传 images。
一旦 file 已经加载到 project 中,就可以在 documentation 中引用它。假设我创建了一个名为 company_logo.png 的 file,并将它加载到 repo 的 assets folder 中,同时想在 sales model 的 description 中引用它。为此,我会打开 schema.yml file,并使用图 9-6 中展示的 syntax 来引用它。

图 9-6:引用存储在 assets directory 中的 image
Square brackets 中包含 description 中 image 的名称,也就是 My Company Logo,directory 则指定 image 存储在哪里。现在当我运行 dbt docs generate 时,公司 logo image 会显示在 description 中。
如果不想将 image 上传到 dbt project,也可以使用 URL 引用 images。还是以图 9-6 中的同一个示例为基础,只需要将 directory,也就是 assets/company_logo.png,替换为 URL。图 9-7 展示了现在的样子。

图 9-7:通过 URL 引用 image
在 doc blocks 中,我还可以更有创造性地组合 Markdown、text 和 images,然后只通过 YAML files 引用它们。引用 images 使用的仍然是这里展示的相同 syntax。
How to Run
在 dbt 中构建 documentation 所需的大部分工作,其实就是输入关于所有内容的 descriptions。真正生成 documentation 是一个简单过程。你只需要运行 dbt docs generate command。这个 command 负责生成 project 的 documentation website,具体会做以下事情:
- 在 dbt project 的
targetdirectory 中创建 websiteindex.htmlfile。这个 directory 是 dbt 放置 generated artifacts 的位置,包括 documentation files。 - 将 project compile 到
target/manifest.json。这会将整个 dbt project,包括 models、tests、macros 和其他 resources,compile 成一个 single manifest file。该 file 包含关于 project structure、dependencies 和 definitions 的 metadata。 - 生成
target/catalog.json。它会为 project 中 models 创建的 tables 和 views 生成 catalog,例如 column names、data types、descriptions 和 relationships。
与许多其他 dbt commands 不同,dbt docs generate 不接受太多 arguments。它唯一支持的 argument 是 --no-compile,用于跳过 recompilation,也就是前面 process 的 step 2。使用该参数时,只会执行 step 1 和 step 3。如果你已经有一个希望 dbt 用来创建 documentation 的 manifest.json file,这会很有用。
你也可以使用 dbt docs serve command 生成本地 documentation site。这个 command 会在 localhost 上通过 port 8080 提供 documentation site,并使用默认 browser 打开。你仍然需要提前运行 dbt docs generate,因为这个 command 依赖它生成的 catalog artifact。dbt docs serve command 引入了一些 additional arguments:
css
dbt docs serve [--profiles-dir PROFILES_DIR]
[--profile PROFILE] [--target TARGET]
[--port PORT]
[--no-browser]可以看到,你可以指定 profile directory、profile 和 port,如果想使用其他 port 的话,也可以设置是否打开 browser window。
Local vs. dbt Cloud Documentation
正如本书反复强调的,dbt Cloud 中有两类 environments。第一类是 development environment,是 developers 用于开发的 environment;另一类是 deployment environment,用于运行 production-grade jobs。在 dbt Cloud 中,你只有一个 development environment,但可以有多个 deployment environments,例如 QA、UAT、Production 等。每当你直接在 dbt Cloud IDE 中工作,并通过 command line 执行 commands 时,它只会在 development environment 中执行。为了在 deployment environments 中执行 commands,需要创建 jobs 来完成。第 10 章会对此展开更多。
每当我们在 development environment 中执行 dbt docs generate command,它会创建一个只有你自己能看到的 local documentation site。在 dbt Cloud 中访问它,需要点击切换 branch 旁边的 book icon,如图 9-8 所示。不要点击顶部的 Documentation tab。顶部的 Documentation tab 是所有人共享的,而你的 local copy 只有你可见。
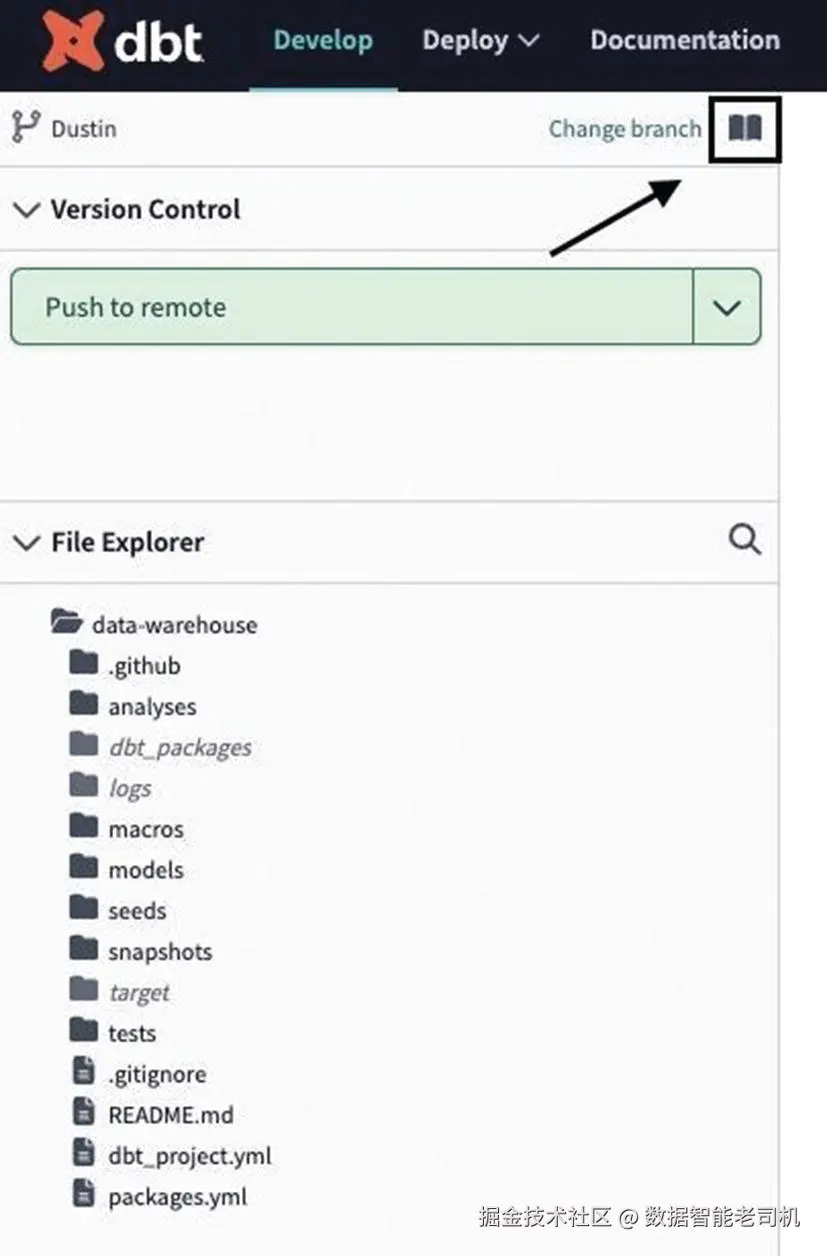
图 9-8:如何在 dbt Cloud 中查看 local docs
这样做的目的是让你在 documentation site "live" 到 production 之前,有一个地方可以 review 它。为了填充 Documentation tab 并与他人共享,还需要额外几个步骤。
每当你在 dbt 中创建一个 new job 时,有一个 checkbox 可以选择 "generate docs on run",如图 9-9 所示。它会在该 job 运行时自动运行 dbt docs generate,从而创建 documentation site。你可以在 job 中添加一行单独 command 来运行它,也可以勾选这个 box,本质上做同样的事情,只有一个小差异。当你勾选 box 时,即使该步骤失败,job 仍然会成功。如果你将 command 作为 line item 添加,那么它会让 job 失败,并且后续所有 steps 都会被跳过。大多数时候我们建议直接勾选 box,只有当你需要改变 behavior 时才添加 command。

图 9-9:dbt Cloud job 中 generate docs 的选项
这会运行并创建 documentation site;但如果没有再做一项 configuration,它仍然不会在 dbt Cloud environment 中生成 shared Documentation tab。你需要告诉 dbt 哪个 job 会生成 shared documentation。为此,需要进入 dbt Cloud account settings,并修改 documentation artifact。你可以通过编辑 project details,或者进入编辑 warehouse connection 和 source control repository 的同一个位置来完成。在那里你会找到 artifacts section,可以配置用于填充 shared documentation 的 job。图 9-10 展示了在哪里找到它。注意,这必须是一个设置在 deployment environment 上的 job,不能附加到 development environment。它也必须配置为 generate docs,否则不会作为选项出现。
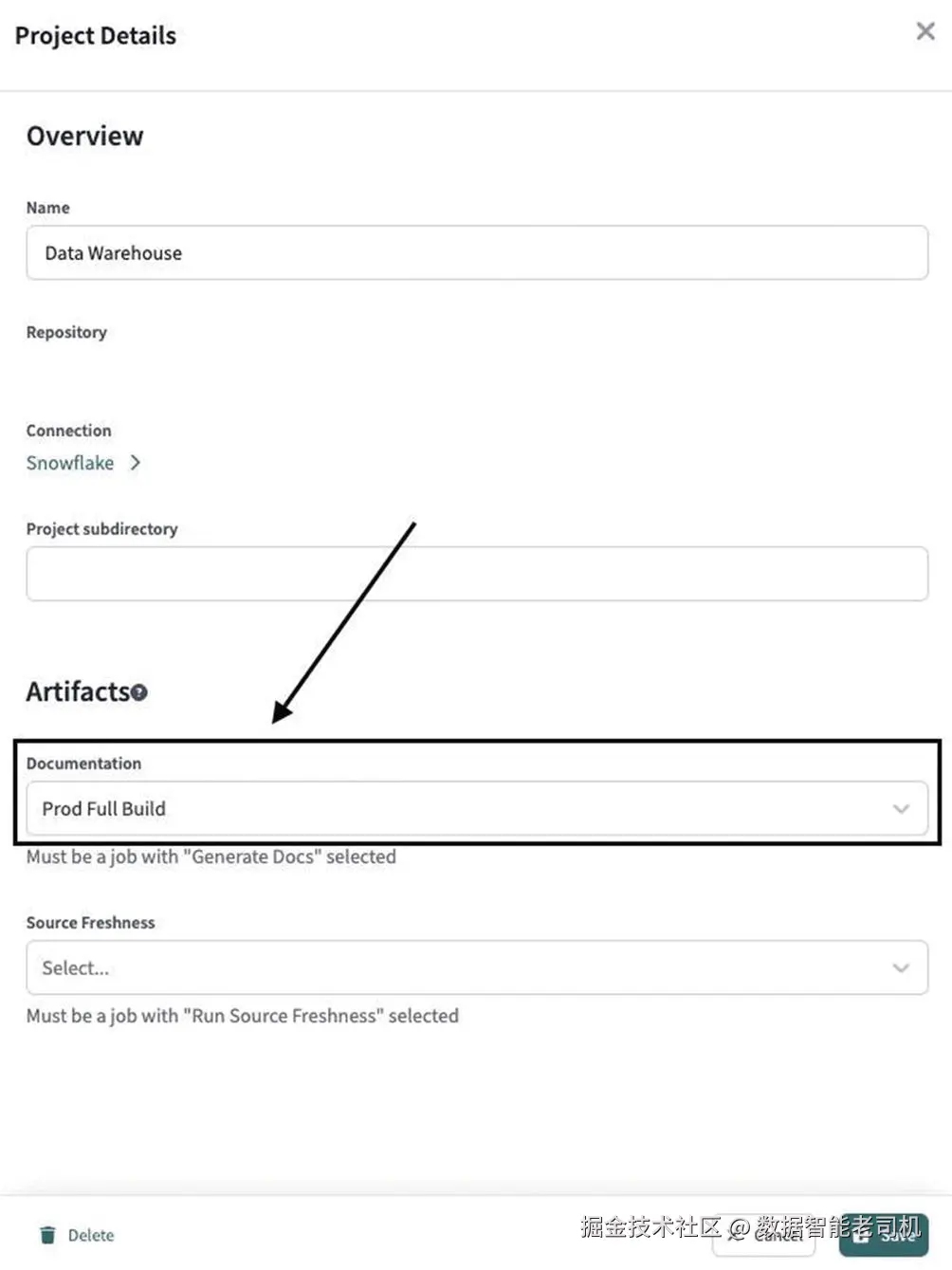
图 9-10:设置用于配置 shared documentation 的 job
在这个示例中,我有一个名为 "Prod Full Build" 的 job,用它来填充 shared documentation site。现在,每当这个 job 运行时,它都会填充所有人都能看到的 documentation site。其他所有运行 dbt docs generate 的操作,只会创建一个仅执行该 command 的人可见的 single copy。
Note
你的 documentation artifact 必须位于 deployment environment 中,并且必须配置为 generate docs。否则,它不会作为选项出现。
这些 guidelines 适用于使用 dbt Cloud 时部署 documentation。如果使用 dbt Core,deployment process 会更复杂一些,因为你需要思考 deployment strategy。第 10 章会覆盖 production documentation deployment considerations,但一些常见 approaches 包括:
- 在 Amazon S3 上托管 static site
- 使用 Netlify 发布
- 使用自己的 web server,例如 Apache / Nginx
Value of Reader Accounts in dbt Cloud
在 dbt Cloud 中,目前可以有两种 license:developer 和 reader accounts。每当购买 licenses 时,通常每购买一个 developer account,会包含一定数量的 reader accounts。如果需要更多 reader accounts,也可以以远低于 developer accounts 的价格额外购买。要查看 dbt Cloud 中的任何内容,包括 documentation,必须拥有 account。
你想要 reader accounts 的主要原因,是为了共享在 dbt Cloud 中构建和托管的 documentation。开发团队之外很可能有很多人会 query 和使用你的 data,并且需要理解它们。他们不需要在 dbt 中开发,但生成的 documentation 对他们非常有价值。不过,为了访问它,他们必须有一个 account。
Note
dbt Cloud 中生成的 documentation web page 只能由拥有 dbt Cloud account 的 users 访问。
如果你不想为 documentation viewers 分配或购买 additional reader licenses,也可以考虑前面章节提到的其他 alternatives。它们本质上是利用其他 services 来填充一个 custom web page,用于托管你的 documentation。
Navigating the Documentation Web Page
每当你在 dbt Cloud 中生成 documentation,系统都会为你生成一个 documentation web page。本节会带你了解如何使用这个 web page。先说明一下,我们预期在未来 dbt Cloud releases 中,它会持续增强,所以建议查看官方 documentation 获取最新消息。不过,我们预计这里提到的所有功能即使界面发生变化,也仍然会存在。
每当你在 dbt Cloud 中打开 documentation page,无论是 shared 版本还是 local 版本,都会看到一个 overview section。Overview section 提供关于如何导航 docs site 的信息和 guidelines。如果你第一次使用这个 site,这是一个很好的起点。图 9-11 展示了它的样子。
图 9-11:dbt Cloud docs site overview page
随着 documentation 逐渐成熟,你可能希望将 overview section 修改为更符合组织特点的内容,这是完全支持的。要修改它,需要创建一个名为 __overview__ 的 doc block,用来 override existing values。注意,overview 这个词前后各有两个 underscores。Doc block 可以包含在任何 Markdown file 中,但必须精确命名才能生效。示例如下:
arduino
{% docs __overview__ %}
<Add your new overview text here>
{% enddocs %}离开 overview page 后,你会注意到页面左侧有两个选项,叫 Project 和 Database。这个 switch 允许你在探索 project folder structure 和面向 database 的 tables / views compilation 之间切换。Project view 提供了 models 的便捷可访问性和组织方式,而 Database view 则为使用 warehouse 的人提供了关于 data presentation 的 insights。
Project Tab
先更深入地探索 Project tab。Project tab 被拆分为 Sources 和 Projects 两个 subviews,如图 9-12 所示。Sources section 包含你在 sources.yml files 中创建的每个 source 的 entry。Projects section 包含你创建的每个 project 的 folder。注意,每当你向 project 安装一个 package,它会被解释为一个 separate project。因此,即使你自己只处理一个 project,也可能在这里看到已安装 packages 的其他 entries。
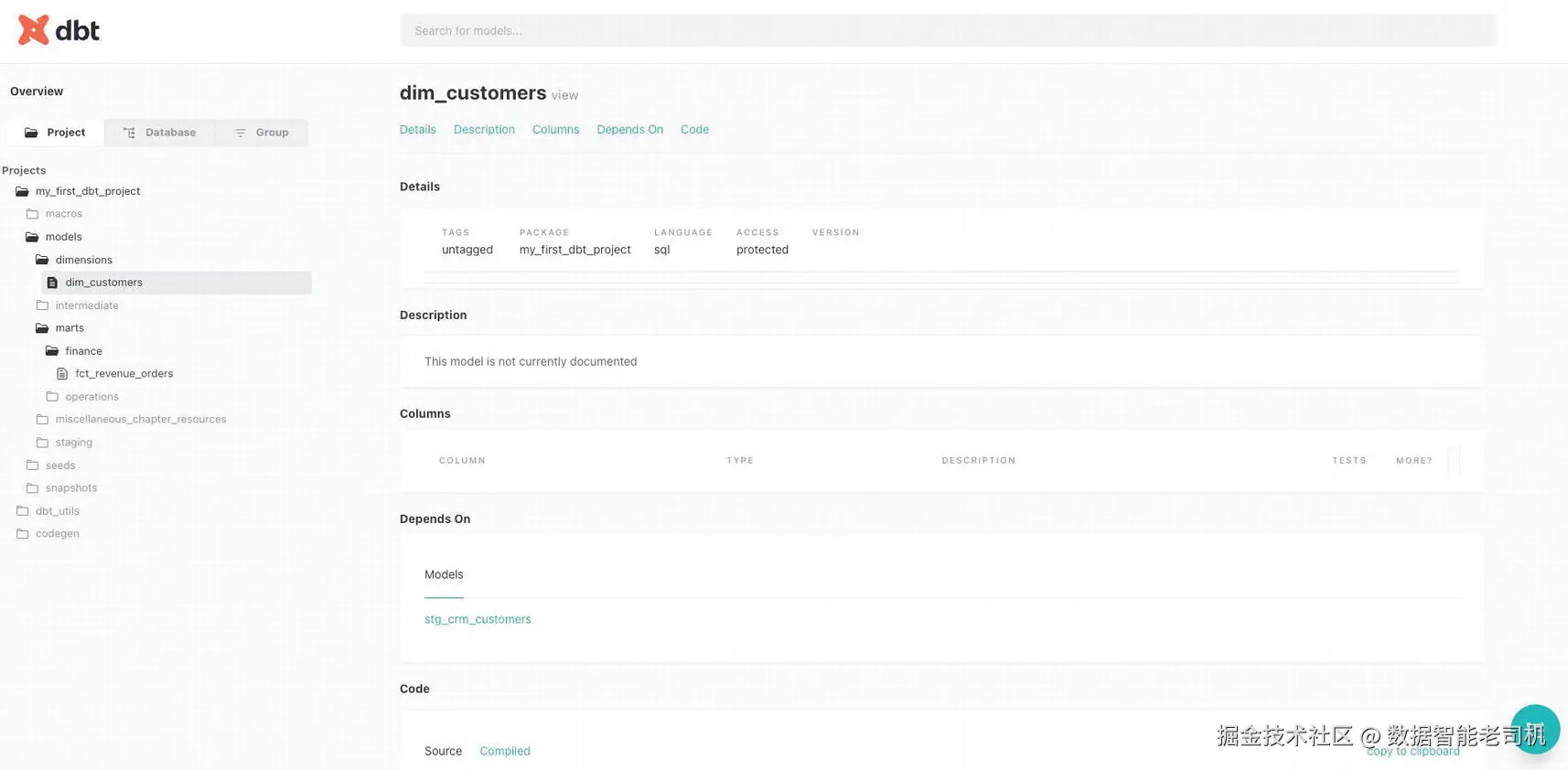
图 9-12:dbt Cloud docs site Projects section
点击 Sources 后,可以查看关于它们的 documentation。点击 source 后看到的 initial view 包含以下信息:
Details:包括你输入的任何 meta information、database 和 schema names,以及 tables 数量。
Description :如果 source 在 sources.yml file 中有 description,这里会显示你对 source 的描述。
Source tables:可以看到所有与该 source 关联的 tables,并带有 hyperlinks,可查看每张表的 individual docs。
每当你点击左侧 pane 中的某个 source,就会展开一个 folder,允许你点击 specific tables 来查看它们的 documentation。你也可以点击屏幕右侧默认 source page 中的 hyperlinks。查看 source tables 时,可以看到以下信息:
Details:包含 object information,例如 tags、owner、object type,以及一些 source 相关信息。你还会获得 object 的 size information、row count 和 last modified date。
Description :如果 source table 在 sources.yml files 中有 description,这里会显示你对 source table 的描述。
Meta:你创建的任何 meta fields 及其 values。
Columns :包含所有 columns 列表,包括 column names、data types、descriptions,如果已输入到 sources.yml files 中,以及在该 column 上运行的所有 tests 列表。
Referenced by:显示该 column 被哪些 models 和 tests 引用,并提供 hyperlinks 供查看。
Code :包含一个 sample SELECT command,用于 query 该 column。
进入 Project subview 后,你会看到所有 projects 的列表。你可能只看到一个,也可能看到很多,取决于你创建的 projects 和安装的 packages 数量。每个 project folder 的结构都类似你开发时的 dbt project,并根据 resource folders 区分,例如 macros、models、seeds、tests、snapshots 等。
每当你点击一个 project link,首先看到的是一个 overview section,类似第一次打开 docs site 时看到的页面。默认情况下,每个 project 看起来都一样,但你也可以修改它们。要设置 custom project-level overviews,只需要创建一个名为 __<Project Name>__ 的 doc block。Project name 前后各有两个 underscores。<Project Name> 应替换为 project 的名称。假设你有一个名为 "Sales" 的 dbt project,并想创建 custom overview page,就可以创建如下 doc block 来 override default setup:
arduino
{% docs __Sales__ %}
<Add your new overview text here>
{% enddocs %}你可以对 environment 中每个 project 都这么做,也可以保持默认,选择权在你。继续向 project subview 里 drill down,会看到 individual resource folders,可以继续向下进入,直到看到 individual objects。Documentation 会根据你查看的 resource type 不同而变化,但本质上可以看到以下内容:
Details(仅 models 和 seeds) :包含 object information,例如 tags、owner、object type,以及一些 source 相关信息。你还会获得 object size information、row count 和 last modified date。
Description :如果 object 在 schema.yml files 中有 description,这里会显示你对 object 的描述。
Meta:你创建的任何 meta fields 及其 values。
Columns(仅 models) :包含所有 columns 列表,包括 column names、data types、descriptions,如果已输入到 schema.yml files 中,以及在该 column 上运行的所有 tests 列表。
Referenced by:显示该 column 被哪些 models 和 tests 引用,并提供 hyperlinks 供查看。
Code:包含用于生成该 object 的代码副本。例如,如果这是一个 model,它会显示 model 中的 exact code。你也可以查看某些 resource types 的 compiled code 或 example SQL。Compiled code 是所有内容被翻译成 SQL 后的结果,可以直接复制并在 warehouse 上运行。
Arguments(仅 macros 和 tests) :关于 macros 和 tests arguments 的 details。
Database Tab
Database tab 显示的信息与 Project tab 相同,但格式更像 database explorer。Explorer 按 databases、tables 和 views 来查看 objects,如图 9-13 所示。
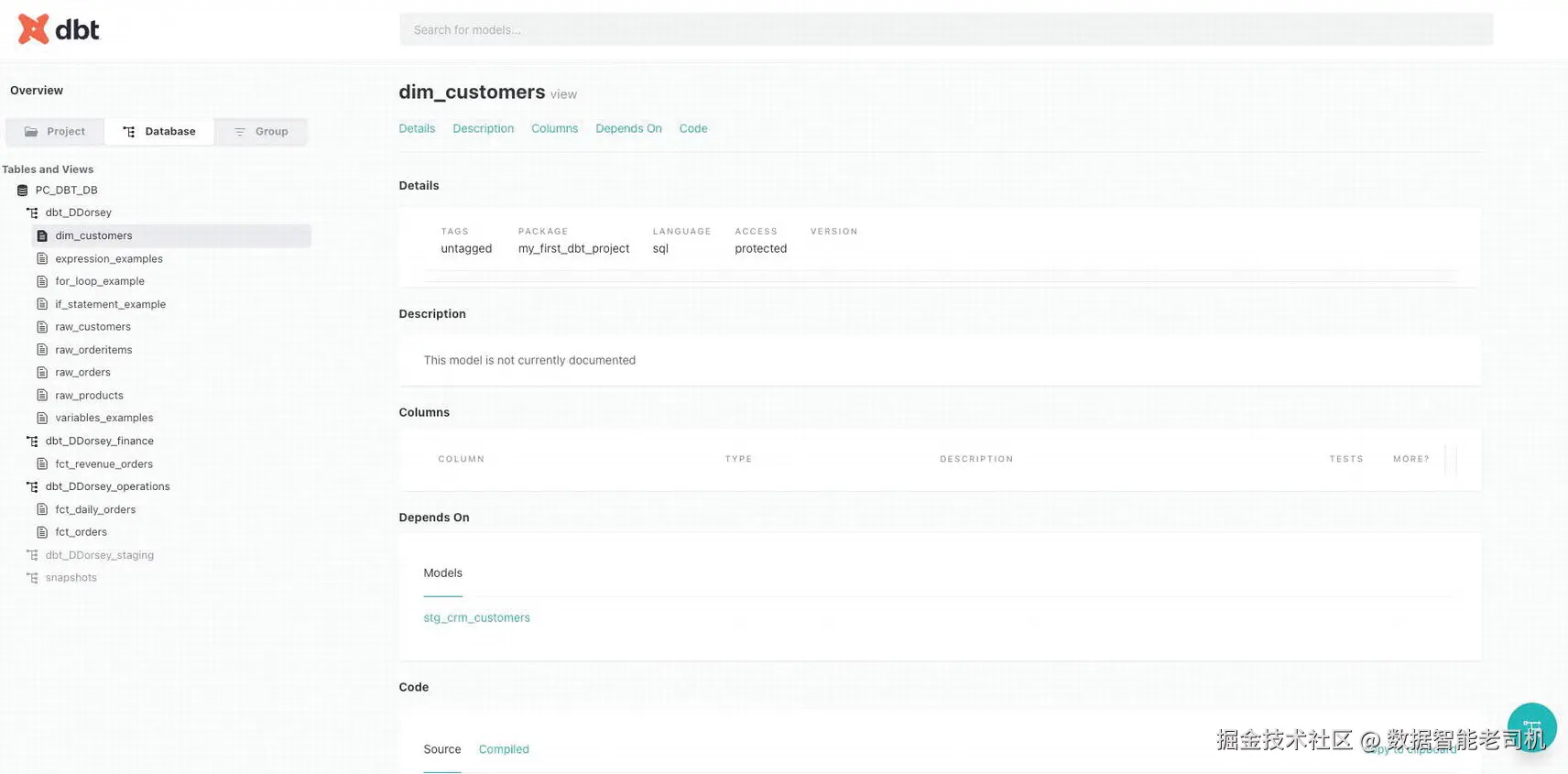
图 9-13:dbt Cloud docs site Database tab
在这个 tab 中,你只能看到 tables 和 views 的信息。你可以看到 database 和 schema names,但点击它们时不会出现页面。它们只是为了让你能继续向下导航到 tables 和 views。
当你 drill down 到 individual tables 和 views 时,可以访问以下信息:
Details:包含 object information,例如 tags、owner、object type,以及一些 source 相关信息。你还会获得 object size information、row count 和 last modified date。
Description :如果 object 在 sources.yml 或 schema.yml files 中有 description,这里会显示你对 object 的描述。
Meta:你创建的任何 meta fields 及其 values。
Columns :包含所有 columns 列表,包括 column names、data types、descriptions,如果已输入到 schema.yml files 中,以及在该 column 上运行的所有 tests 列表。
Referenced by:显示该 object 被哪些 models 和 tests 引用,并提供 hyperlinks 供查看。
Code :包含一个 sample SELECT command,用于 query 该 column。
Graph Exploration
dbt docs site 不仅提供 project 的 textual information,还可以通过 lineage graph 查看 project 内部 relationships。Lineage graph 是一个 DAG,允许你以 graph format 查看 model 的 dependencies。
在深入说明如何在 docs site 中查看它之前,先看 data lineage 是什么以及为什么重要。Data lineage 让 users 能够理解组织中 data 的 movement、utilization、transformation 和 consumption。它可以通过 DAG,也就是 lineage graph,或通过 Data Catalog 进行视觉化表示。在 dbt docs 中,你实际上两者都能获得。理解 data lineage 可以让 engineers 更高效地构建、troubleshoot 和分析 workflows。此外,它也让 data consumers 理解 data 的 origins。
Data 以及我们使用 data 的方式始终在变化,因此很容易理解为什么需要理解 data lineage。理解它重要主要有三个原因:
更快修复 data issues:通过快速识别 root causes 来解决问题。借助 data lineage,你可以从问题向上游快速回溯,判断 failure 发生在哪里。
理解 upstream changes 对 downstream 的影响:当 development team 需要做 upstream schema change,例如 drop 或 rename table 时,你可以快速识别 downstream impact。
为 team 提供价值:创建一个 holistic data view,让大家更好理解发生了什么;同时,它也能通过轻松识别 redundant 或 messy data flows,促使 pipelines 更干净。
现在我们已经覆盖了为什么 data lineage 重要的基础内容,回到 dbt 自带的 lineage graph。要访问 lineage graph view,只需要在 docs site 中点击对应 option。目前,它可以通过 docs web page 右下角的 teal box 访问。
你在 docs site 的哪个位置点击进入 lineage graph,会影响 default view。如果你正在查看某个 specific model 并进入 graph view,它默认只会显示该 model 以及它的 upstream 和 downstream dependencies。不管默认 view 是什么,你都可以 filter 和 customize,使它展示你想查看的内容。图 9-14 展示了一个简单视图。
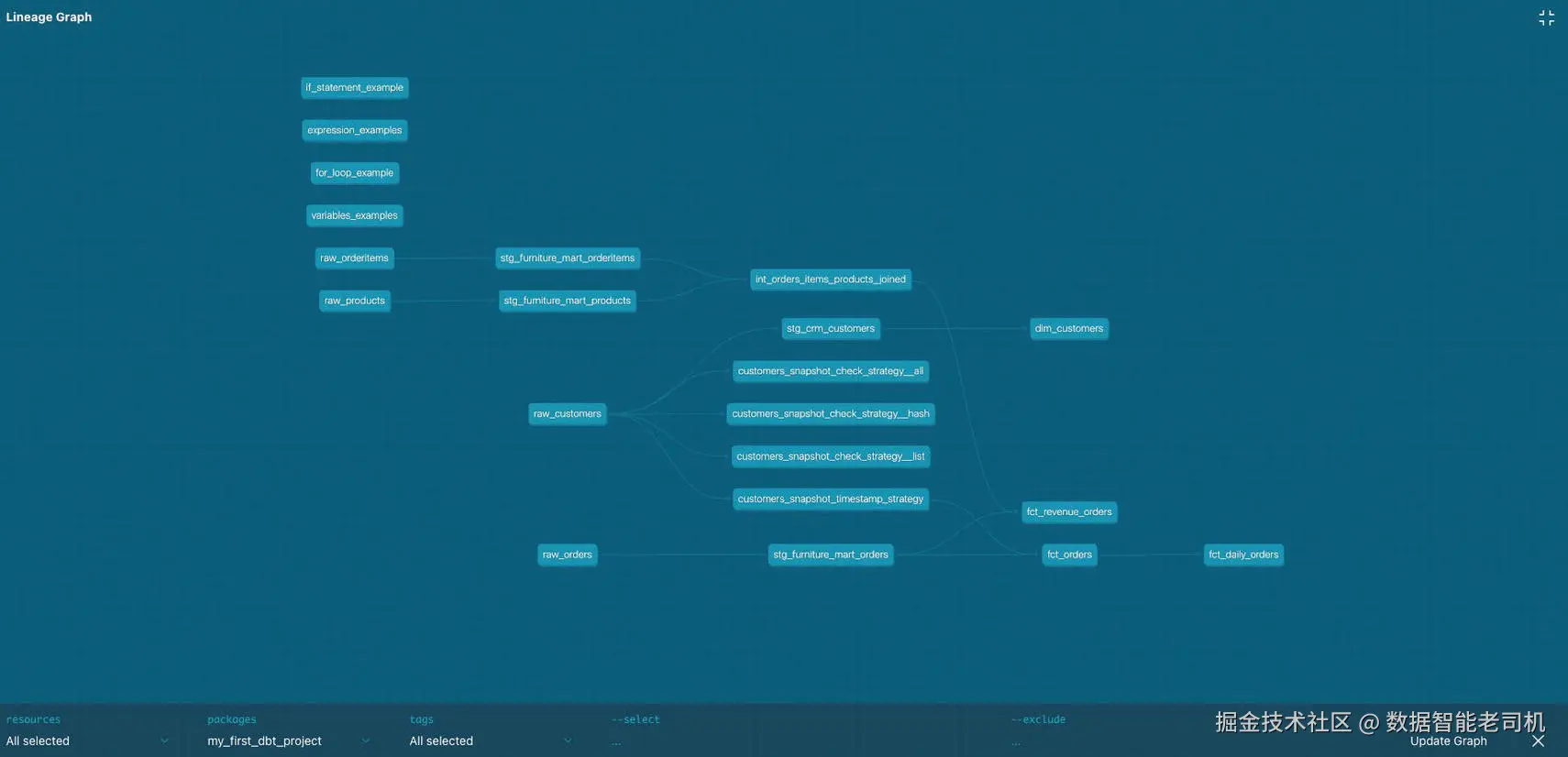
图 9-14:dbt Cloud docs site lineage graph
Lineage graph 非常 interactive,你可以移动 objects 来创建理想的 visual。你也可以选择 lineage graph 中的任意 object,它会高亮所有 dependencies。当你试图视觉化某个 object 的 dependencies 时,这非常好用。
你还可以应用多个 filters 来缩小或扩大 lineage graph 的 scope。下面是可用选项:
resources:可以选择想在 graph 上看到哪些 resource types。可以选择 models、seeds、snapshots、sources、tests、analyses、exposures、metrics 和 all。
packages:可以选择你感兴趣的 packages 或 projects。可以选择单个,也可以选择 all。
tags:如果 project 中使用 tags,可以在这里选择 / 取消选择。
--select :这是一个 free text field,允许你输入正在寻找的 specific objects。它的工作方式与 dbt run command 中使用 --select 相同。
--exclude :这是一个 free text field,允许你排除 specific objects。它的工作方式与 dbt run command 中使用 --exclude 相同。
有很多优秀 third-party tools 具备 lineage capabilities,但它们往往价格不菲。如果你还没有使用其他工具,我们认为 dbt 中的 lineage capabilities 对大多数公司来说已经足够,应该先从这里开始探索。毕竟,它已经包含在你的 dbt Cloud licensing costs 中。
Searching the Docs Site
dbt docs site 最后一个要覆盖的 component 是 search feature。虽然你完全可以通过 explorer 导航来找到所需内容,但也可以直接使用 docs site 顶部的 search bar 搜索。图 9-15 展示了 search bar 的示例。
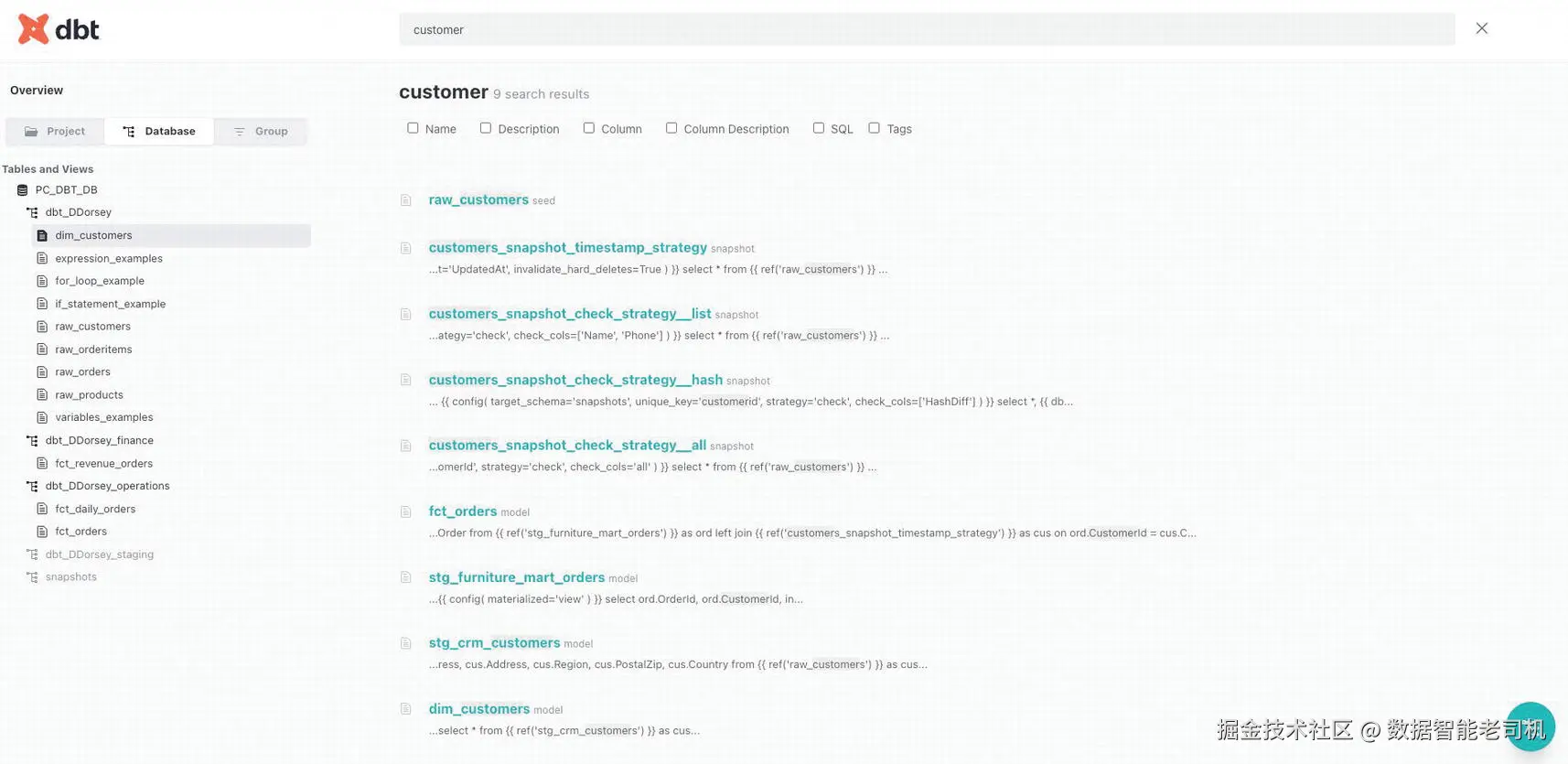
图 9-15:dbt Cloud docs site search 示例
你可以在 search bar 中开始输入任何内容,dbt 会展示任何包含你搜索 words 的内容。这包括 names、descriptions、columns、code 和 tags。如果你知道自己正在搜索 specific thing,也可以选择基于 name、description、column、SQL 和 tags 搜索。随着 project 扩展,能够 filter 会很方便,可以避免 overloaded results。
Maintaining Documentation
保持 documentation up-to-date 对确保其 relevance 和 usefulness 至关重要。随着 dbt project 演进,必须建立 processes,使 documentation 与最新 changes 保持同步。本节将探索保持 dbt documentation 最新的 strategies 和 best practices。高层来看,以下 considerations 可以提升你维护 documentation 的能力,随后我们会逐一深入:
- Make it part of your development workflow
- Create a documentation review process / make it part of code review
- Encourage open channels of communication
- Regularly revisit and define your documentation guidelines
- Foster a culture of ownership
Regular documentation updates 应该是 development workflow 的组成部分。dbt 的一个巨大好处是,它允许你在 development process 中创建 documentation,避免需要使用 Word docs 或 third-party tools。每当你对 dbt project 做 changes,无论是添加 new models、修改 existing ones,还是更新 schema structures,都要养成相应更新 documentation 的习惯。这确保 documentation 准确反映 data project 的 current state。在 development process 中持续文档化,比让它堆积起来再一次性补写要容易得多。
Tip
让 documentation 成为 development workflow 的一部分。
考虑在团队中建立 documentation review process。在 merge code changes 或部署 new features 之前,加入一个步骤,review documentation 的 accuracy 和 completeness。这个 review process 可以帮助发现 discrepancies 或 missing information,确保 documentation 保持 reliable 和 up to date。下一章会覆盖结合 source control 的 code promotion process,其中包括 mandatory code reviews。我们认为这正是检查 new 或 changed items 是否被 proper documented 的好地方。Code reviewer 应该在批准 pull request 之前检查这一点。
在保持 documentation 同步方面,communication 和 collaboration 是关键。鼓励团队成员之间保持开放沟通渠道,尤其是在对 data project 进行重大 changes 时。确保任何 updates 或 modifications 都传达给 relevant stakeholders,让每个人都 informed 和 aligned。Documentation 很重要,但它不能替代对 changes 的 proper communication。
定期 review 和 refine documentation guidelines and standards。随着 data project 演进和成熟,你可能会发现新的 practices 或 requirements 需要被捕获到 documentation 中。通过定期回顾 documentation guidelines,可以调整它们来反映 data project 不断变化的需求,确保 documentation 保持 comprehensive,并与 best practices 对齐。
最后,在团队中培养 documentation ownership 的文化。鼓励 team members 对自己 expertise areas 相关的 documentation 负责。这不仅包括维护自己的 documentation,也包括与其他人协作,确保 cross-functional coverage 和 accuracy。Documentation ownership 会形成 responsibility 和 accountability 意识,从而带来更 robust 和 reliable 的 documentation。
通过实施这些 strategies 和 best practices,你可以建立一个 documentation workflow,使 dbt documentation 与不断演进的 data project 保持同步。请记住,documentation 是一项持续工作,需要 regular updates 和 collaboration。有了良好的 documentation process,你可以最大化 dbt documentation 的价值,并赋能 users 基于 reliable 和 up-to-date information 做出 informed decisions。
Codegen Package
本书中,我们多次讨论过可以利用的 open source packages,其中对 documentation 最有帮助的 packages 之一是 Codegen package。Codegen package 可以在 dbt package hub 找到,我们认为它是 must-have。
在为 sources 和 models 添加 descriptions 时,Codegen package 本质上是一个 YAML templating tool。可以想象,仅仅输入所有 tables 和 columns 就可能花大量时间。不只是添加 descriptions 本身,还包括手动组织 YAML file,使其包含 tables、columns 和 descriptions。看图 9-16,你会看到添加一个 source 及其几个 tables 和 columns 的示例。这个只花了几分钟写出来,但想象一下,如果有很多 sources、数百张 tables、数千个 columns,都需要这么做,会怎么样。Engineer 可能会花几个小时甚至几天时间,只是创建 syntax,才达到可以添加 descriptions 的阶段。
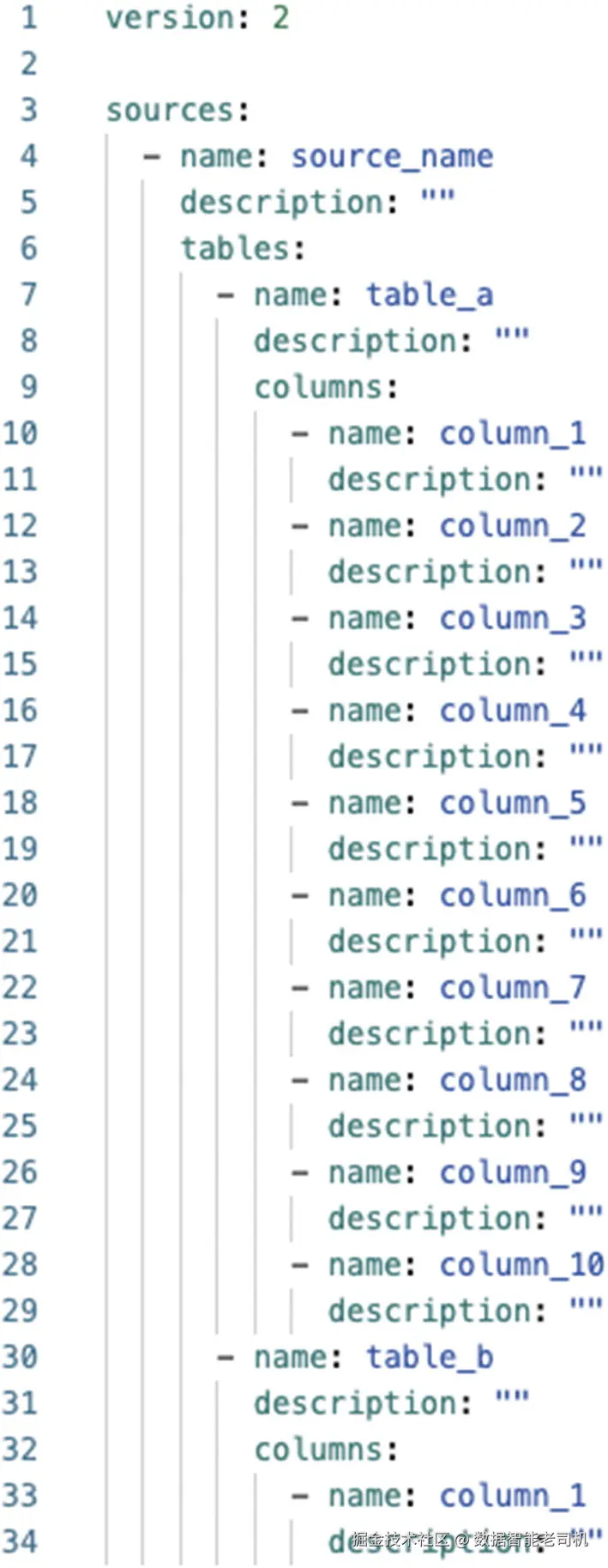
图 9-16:配置 shared documentation 的 job 示例
没有 engineer 想只做类似 data entry 的事情。相反,可以使用 Codegen package 中的 generate_source 和 generate_model_yaml macros,帮我构建出这些内容。运行时,这两个 macros 会为你生成 templates,这样你只需要专注于添加 descriptions。
这是一个由 dbt Labs 创建的 package,我们认为它不会消失。不过,我们也能想象 dbt 最终可能会将这个 functionality 集成进 core product,从而不再需要单独 package。
第 6 章以及整本书中,我们已经讨论过各种 packages。还有其他 packages 可以帮助,有时是间接帮助,生成 documentation。如果它们能提供任何帮助,我们强烈建议利用它们。作为 dbt 的一般原则,如果你不得不记住做某件事,或者做某种 manual 或 repetitive 的任务,那么很大概率已经有人构建了东西来解决这个需求。一定要查看 dbt package hub,看看有什么可用。
Tip
如果你在 dbt 中执行某项 manual 且 repetitive 的任务,那么很大概率已经有人构建了自动化工具来处理它。一定要查看 dbt package hub,看看有什么可用。
Summary
现在你已经完成了 dbt documentation 世界的旅程。我们已经覆盖了为 dbt projects 创建、管理和增强 documentation 的 essential aspects。通过遵循本章概述的 best practices 和 techniques,你已经具备创建 comprehensive、user-friendly 且 valuable documentation 的能力。
本章中,我们学习了 documentation 在确保 dbt projects 成功方面扮演的重要角色:它帮助 users 理解 data infrastructure,促进 collaboration,并推动 knowledge sharing。具体来说,我们查看了 dbt 为我们提供的 features,包括 automated metadata extraction,以及 descriptions、custom metadata、Markdown、images 等 customizations,这些都可以用于填充 dbt Cloud docs site。随后,我们看了如何填充 documentation。我们也学习了如何导航和搜索 docs web page,包括它提供的 project、database 和 graphical views。
请记住,documentation 不是一次性任务,而是一个持续过程。它需要 continuous effort、regular updates,以及维护其 quality 和 relevance 的 commitment。因此,虽然 dbt 在这里为我们提供了很棒的能力,但仍需要你和团队投入一些 effort,才能让它真正发挥作用。