数据库序列(Sequence) 是一种生成唯一整数序列 的对象 ,主要用于自动生成主键值 或唯一标识符。
核心概念
序列是一个数据库对象,按照指定的规则(起始值、增量、最大值等)生成一系列唯一的整数。每次调用序列时,都会返回下一个值。
主要特点
1. 唯一性保证
序列生成的每个值都是唯一的
即使在高并发环境下也能保证不重复
2. 独立性
序列独立于表 存在,可以被多个表共享
不依赖于事务 ,即使事务回滚,序列值也不会回退
3. 可配置性
起始值 (START WITH)
增量 (INCREMENT BY)
最小值/最大值 (MINVALUE/MAXVALUE)
是否循环 (CYCLE/NOCYCLE)
缓存大小(CACHE)
不同数据库的实现
Oracle
sql
-- 创建序列
CREATE SEQUENCE user_seq
START WITH 1
INCREMENT BY 1
NOCACHE
NOCYCLE;
-- 使用序列
INSERT INTO users (id, name) VALUES (user_seq.NEXTVAL, '张三');
SELECT user_seq.CURRVAL FROM dual; -- 查看当前值PostgreSQL
sql
-- 创建序列
CREATE SEQUENCE order_id_seq
START WITH 1000
INCREMENT BY 1;
-- 使用序列
INSERT INTO orders (id, amount)
VALUES (nextval('order_id_seq'), 100.00);
-- 或者在表中直接使用
CREATE TABLE products (
id SERIAL PRIMARY KEY, -- 自动创建序列
name VARCHAR(100)
);SQL Server
sql
-- 创建序列
CREATE SEQUENCE employee_seq
AS INT
START WITH 1
INCREMENT BY 1;
-- 使用序列
INSERT INTO employees (id, name)
VALUES (NEXT VALUE FOR employee_seq, '李四');MySQL
MySQL 没有原生的序列对象,但可以通过以下方式实现:
方式1: AUTO_INCREMENT(最常用)
sql
CREATE TABLE users (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(100)
);方式2: 模拟序列
sql
CREATE TABLE sequence_table (
seq_name VARCHAR(50) PRIMARY KEY,
current_value INT
);
-- 获取下一个值
UPDATE sequence_table
SET current_value = LAST_INSERT_ID(current_value + 1)
WHERE seq_name = 'user_seq';
SELECT LAST_INSERT_ID();序列 vs 自增主键
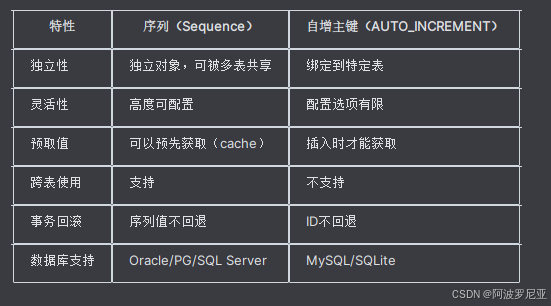
注意事项
⚠️ 序列值不连续的情况 :
事务回滚后 ,已使用的序列值不会回收
数据库重启 可能导致缓存的序列值丢失
高并发 下可能出现跳号
⚠️性能考虑 :
使用 CACHE 可以提高性能(减少磁盘I/O)
但缓存越大,数据库重启时丢失的序列值越多
序列和索引
序列(Sequence)和索引(Index)是数据库中两个完全不同的概念,它们的用途、工作原理和使用场景都有本质区别。
核心区别对比
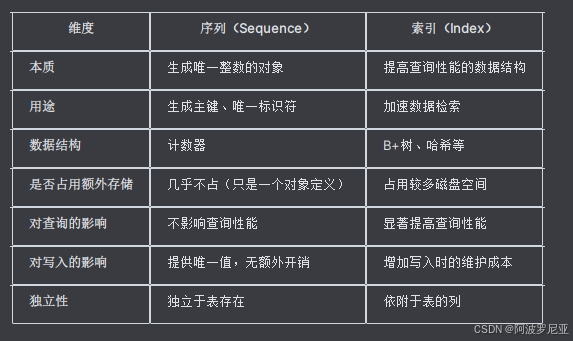
详细对比分析
1. 功能目的不同
序列:生成唯一值
sql
-- 创建序列用于生成主键
CREATE SEQUENCE user_id_seq
START WITH 1
INCREMENT BY 1;
-- 使用序列生成唯一ID
INSERT INTO users (id, name)
VALUES (user_id_seq.NEXTVAL, '张三');索引:加速查询
sql
-- 在用户名字段上创建索引,加速查询
CREATE INDEX idx_user_name ON users(name);
-- 查询时会使用索引加速
SELECT * FROM users WHERE name = '张三';2. 工作原理不同
序列的工作方式:
sql
序列内部维护一个计数器:
调用 NEXTVAL → 计数器 +1 → 返回新值
当前值: 100 → 调用 NEXTVAL → 返回 101,计数器更新为 101索引的工作方式:
sql
索引是数据的有序副本(以B+树为例):
原始数据: 索引结构:
id | name B+树索引(idx_user_name)
---|-------- root: [李, 王, 张]
1 | 张三 / | \
2 | 李四 李四 王五 张三,赵六
3 | 王五 ↑
4 | 赵六 查询"张三"时,通过树快速定位
查询 "WHERE name='张三'"
→ 遍历B+树(3层) → 直接定位到数据
→ 无需全表扫描3. 使用场景不同
序列的典型场景:
sql
-- 场景1: 主键自动生成
CREATE TABLE orders (
id NUMBER PRIMARY KEY,
order_no VARCHAR2(50),
amount NUMBER
);
INSERT INTO orders (id, order_no, amount)
VALUES (order_seq.NEXTVAL, 'ORD20260506001', 1000);
-- 场景2: 订单号生成
SELECT 'ORD' || TO_CHAR(SYSDATE, 'YYYYMMDD') ||
LPAD(order_seq.NEXTVAL, 8, '0') as order_no
FROM dual;
-- 结果: ORD2026050600000001
-- 场景3: 多表共享ID生成器
INSERT INTO table_a (id) VALUES (common_seq.NEXTVAL);
INSERT INTO table_b (id) VALUES (common_seq.NEXTVAL);
-- 保证跨表的ID唯一性索引的典型场景:
sql
-- 场景1: 加速 WHERE 条件查询
CREATE INDEX idx_email ON users(email);
SELECT * FROM users WHERE email = 'test@example.com'; -- 快速定位
-- 场景2: 加速 ORDER BY 排序
CREATE INDEX idx_create_time ON orders(create_time);
SELECT * FROM orders ORDER BY create_time DESC; -- 利用索引顺序
-- 场景3: 加速 JOIN 连接
CREATE INDEX idx_order_user_id ON orders(user_id);
SELECT u.name, o.order_no
FROM users u
JOIN orders o ON u.id = o.user_id; -- 连接时使用索引
-- 场景4: 唯一性约束
CREATE UNIQUE INDEX idx_unique_phone ON users(phone);
-- 既加速查询,又保证唯一性4. 性能影响不同
序列的性能特点:
sql
// 序列几乎不影响性能
// INSERT 操作:只是获取一个数字,开销极小
Long id = sequenceGenerator.nextValue(); // 内存操作,非常快
insertUser(id, "张三");✅ 读取:NEXTVAL 操作非常快(尤其是使用 CACHE 时)
✅ 写入:不增加额外的写入开销
⚠️ 并发:高并发下可能成为瓶颈(可通过 CACHE 优化)
索引的性能特点:
sql
-- 查询性能提升明显
-- 无索引: 全表扫描 1000万条记录 → 耗时 5秒
SELECT * FROM users WHERE phone = '13800138000';
-- 有索引: B+树查找只需3-4次I/O → 耗时 5毫秒
CREATE INDEX idx_phone ON users(phone);
SELECT * FROM users WHERE phone = '13800138000';
-- 但写入性能下降
INSERT INTO users (...) VALUES (...);
-- 需要同时更新数据和所有相关索引✅ 查询:大幅提升 SELECT 性能
❌ 写入:每次 INSERT/UPDATE/DELETE 都要维护索引,降低写入性能
⚠️ 存储:索引占用额外的磁盘空间
5. 维护成本不同
序列的维护:
sql
-- 几乎不需要维护
-- 查看序列状态
SELECT sequence_name, last_number, cache_size
FROM user_sequences
WHERE sequence_name = 'USER_ID_SEQ';
-- 修改序列(很少需要)
ALTER SEQUENCE user_id_seq INCREMENT BY 2;索引的维护:
sql
-- 需要定期维护
-- 重建索引(碎片整理)
ALTER INDEX idx_user_name REBUILD;
-- 分析索引使用情况
SELECT index_name, leaf_blocks, distinct_keys
FROM user_indexes
WHERE table_name = 'USERS';
-- 删除无用索引(减少写入开销)
DROP INDEX idx_unused_column;总结
