多人聊 MySQL 性能优化时,第一反应就是:
加索引。
索引当然重要,但如果只会说索引,其实还不够。
真正理解 MySQL 性能,还要知道 InnoDB 是怎么和磁盘、内存打交道的。比如:
- 为什么 MySQL 不每次都直接读磁盘?
- Buffer Pool 里到底缓存了什么?
- 什么是脏页?
- 事务提交时为什么不直接刷数据页?
- innodb_flush_log_at_trx_commit 有什么影响?
- Using temporary 和 Using filesort 为什么要关注?
这篇文章就围绕 InnoDB 内存结构和性能调优,把这些问题串起来。
一、InnoDB 为什么需要 Buffer Pool?
磁盘很慢,内存很快。
如果 MySQL 每次查询都直接从磁盘读取数据,性能会非常差。
所以 InnoDB 会把常用的数据页、索引页缓存到内存中,这块内存就叫 Buffer Pool。
可以简单理解为:
磁盘数据页 -> Buffer Pool -> SQL 查询使用
如果查询的数据已经在 Buffer Pool 中,就不需要再读磁盘,速度会快很多。
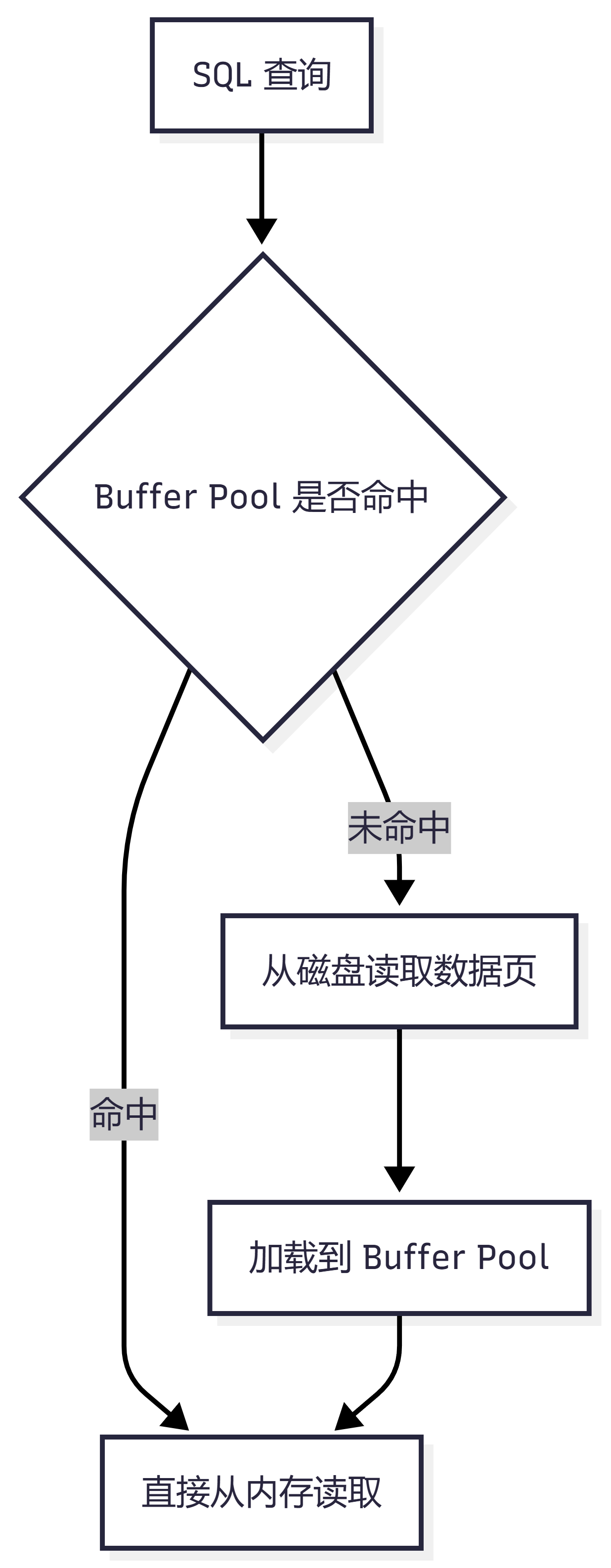
二、Buffer Pool 里缓存的是什么?
Buffer Pool 缓存的不是一行一行的数据,而是 数据页。
InnoDB 默认页大小一般是:
16KB
也就是说,哪怕你只查询一行数据,InnoDB 也可能把这一行所在的整个 16KB 数据页加载到 Buffer Pool。
可以理解为:
一个 16KB 数据页: [第1行][第2行][第3行]...[第N行]
所以索引设计会直接影响读取多少个数据页,也就影响 IO 次数。
三、什么是数据页?
数据页是 InnoDB 管理数据的基本单位。
数据库不是简单地把数据一行一行单独管理,而是按一个个页来组织:
数据页 1 数据页 2 数据页 3 ...
B+ 树索引里的节点,本质上也是页:
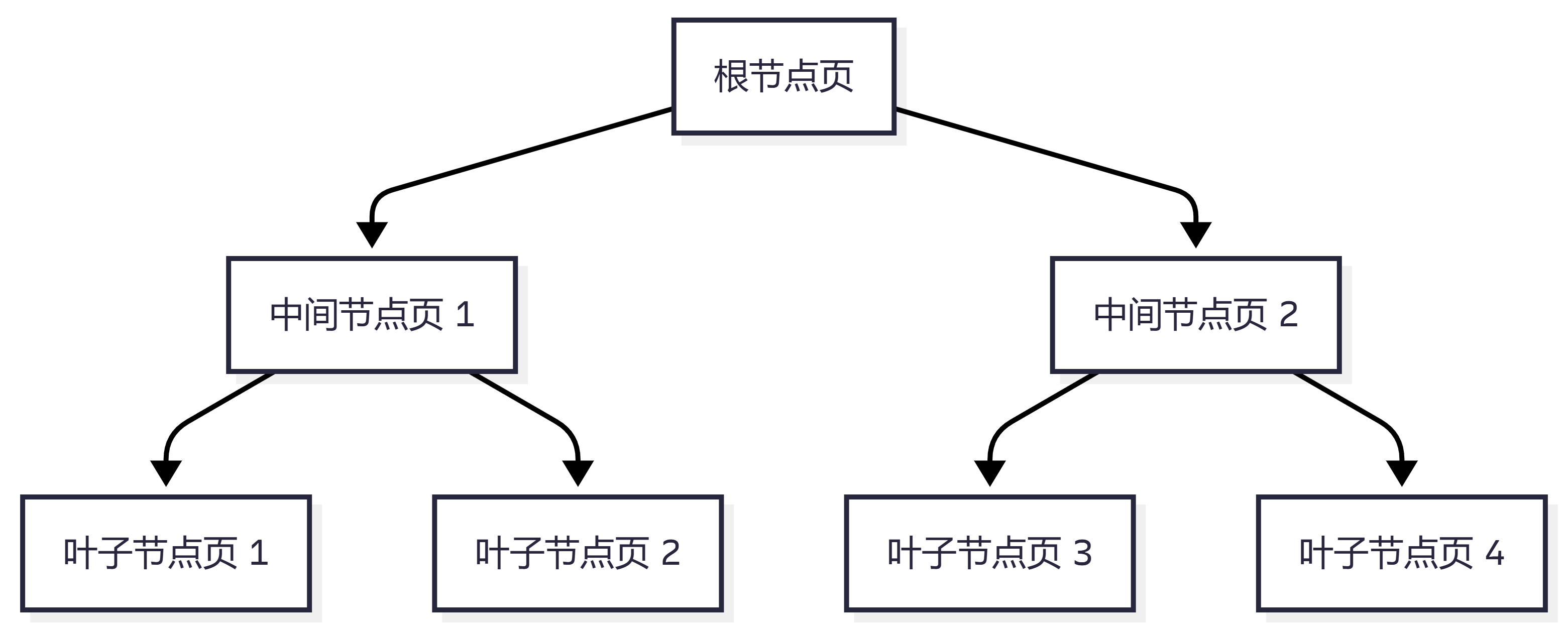
所以一次索引查询,其实就是读取多个页。
如果这些页都在 Buffer Pool 中,查询会很快;如果频繁从磁盘加载,性能就会下降。
四、什么是缓存命中率?
缓存命中率就是查询的数据能不能直接从 Buffer Pool 找到。
命中:Buffer Pool 里有,不需要读磁盘 未命中:Buffer Pool 没有,需要读磁盘
缓存命中率越高,性能通常越好。
如果 Buffer Pool 太小,热点数据和索引页放不下,就会频繁读磁盘,查询自然会变慢。
五、Buffer Pool 是不是越大越好?
不是绝对越大越好,但在内存足够的情况下,适当调大 Buffer Pool 通常能提升性能。
因为它可以缓存更多数据页和索引页,减少磁盘 IO。
不过也不能把机器内存全给 Buffer Pool,还要给这些部分留空间:
操作系统 数据库连接线程 排序内存 临时表内存 其他后台线程
面试可以这样说:
Buffer Pool 大小要结合机器内存和业务负载设置。太小会导致频繁磁盘 IO,太大可能挤压系统和其他执行内存。
六、什么是脏页?
执行更新时,InnoDB 通常先修改 Buffer Pool 中的数据页。
这时会出现一种状态:
内存中的数据页已经变了 磁盘上的数据页还没变
这个内存中被修改但还没有刷回磁盘的数据页,就叫 脏页。
例如:
Buffer Pool:balance = 80 磁盘:balance = 100
这时对应的数据页就是脏页。
七、脏页什么时候刷盘?
脏页不会在每次事务提交时都立刻刷盘,否则性能会很差。
常见刷盘时机包括:
| 时机 | 说明 |
|---|---|
| 后台线程定期刷盘 | InnoDB 后台异步刷新 |
| redo log 快写满 | 需要推进 checkpoint |
| Buffer Pool 空间不够 | 淘汰脏页前要先刷盘 |
| MySQL 正常关闭 | 尽量把脏页刷回磁盘 |
要注意:
事务提交时,关键是保证 redo log 持久化,不是马上把数据页刷盘。
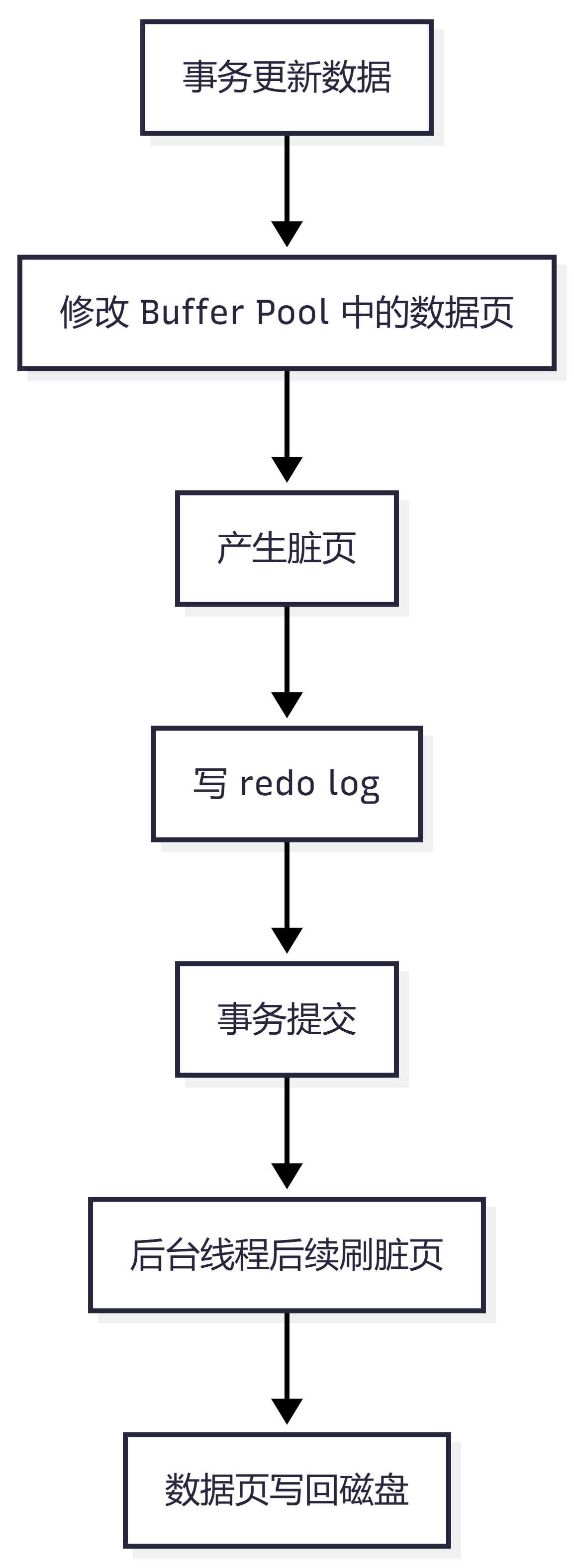
八、为什么事务提交不直接刷数据页?
因为数据页刷盘通常是随机 IO,比较慢。
如果每次事务提交都把数据页刷回磁盘,性能会非常差。
InnoDB 的做法是:
提交时先写 redo log 数据页以后慢慢刷
redo log 是顺序写,性能比随机刷数据页高很多。
这就是 WAL 思想:
Write-Ahead Logging:先写日志,再写数据页
流程如下:
九、redo log buffer 是什么?
redo log 也不是一产生就立刻写磁盘,它会先写入内存缓冲区。
这个内存区域叫:
redo log buffer
大致流程是:
修改数据页 ↓ 生成 redo log ↓ 写入 redo log buffer ↓ 事务提交时按策略刷到磁盘
这样可以减少频繁磁盘写入,提高整体性能。
十、innodb_flush_log_at_trx_commit 是什么?
innodb_flush_log_at_trx_commit 是控制 redo log 刷盘策略的重要参数。
常见取值如下:
| 值 | 含义 | 安全性 |
|---|---|---|
| 1 | 每次提交都写入并刷盘 | 最安全 |
| 2 | 每次提交写入 OS cache,每秒刷盘 | 可能丢 1 秒 |
| 0 | 每秒写入并刷盘 | 可能丢 1 秒以上 |
生产环境一般推荐:
sql
innodb_flush_log_at_trx_commit = 1它性能相对保守一些,但崩溃时最不容易丢已提交事务。
如果是对数据安全要求没那么高的日志、缓存类业务,可以根据实际情况调整,但核心交易类业务不建议随便改低。
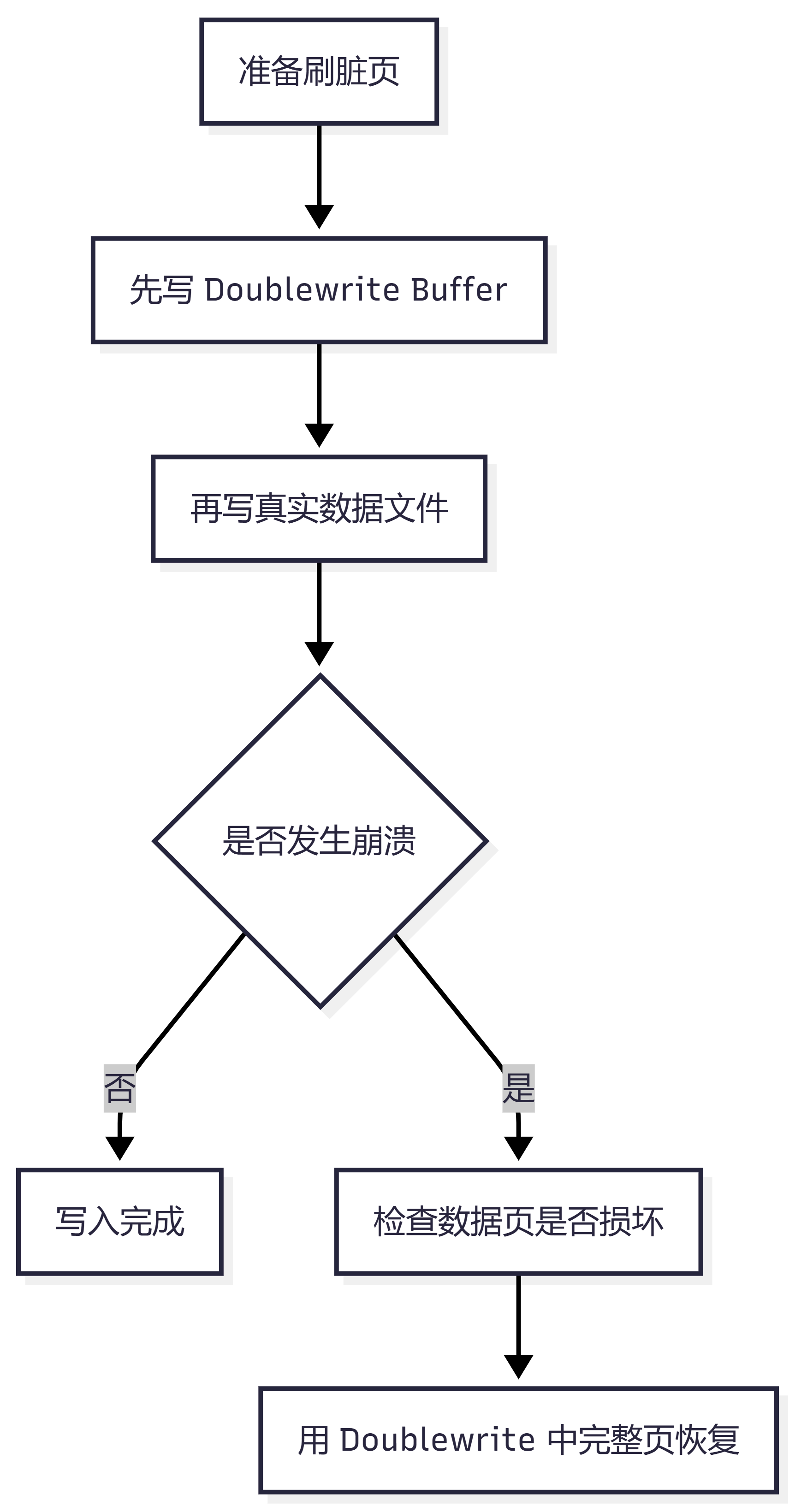
十一、什么是 Doublewrite Buffer?
Doublewrite Buffer 是 InnoDB 用来防止"页写坏"的机制。
InnoDB 一个数据页通常是 16KB,但操作系统写磁盘时,可能只写了一半就宕机了。
这种情况叫:
页断裂 / partial page write
Doublewrite 的思路是:
先把页完整写到 Doublewrite 区 再写到真正的数据文件位置
如果崩溃后发现数据页损坏,就可以用 Doublewrite 中的完整页进行恢复。
十二、Change Buffer 是什么?
Change Buffer 用来优化普通二级索引的写入。
假设你要更新一个二级索引页,而这个页不在 Buffer Pool 中。
如果每次都先从磁盘读出来再修改,成本会比较高。
Change Buffer 可以先把变更缓存起来:
二级索引页不在内存 ↓ 先记录变更到 Change Buffer ↓ 以后这个索引页被读入内存时再合并
它适合写多读少的场景,可以减少随机读磁盘。
十三、为什么唯一索引不能很好使用 Change Buffer?
因为唯一索引更新时,必须判断新值是否已经存在。
要判断是否唯一,就需要把对应索引页读出来检查。
既然已经读出来了,就没有必要再把变更先放到 Change Buffer。
所以 Change Buffer 主要优化的是:
普通二级索引
而不是唯一索引。
这也是为什么索引不是越多越好。
二级索引越多,写入时需要维护的索引结构就越多。
十四、什么是自适应哈希索引 AHI?
AHI 全称是:
Adaptive Hash Index,自适应哈希索引
InnoDB 如果发现某些索引页被频繁访问,可能会自动为热点数据建立哈希索引。
B+ 树查询需要从根节点一层层往下找,而哈希索引可以更快定位。
不过 AHI 是 InnoDB 自动维护的,不需要我们手动创建。
可以简单理解为:
热点 B+ 树访问 -> InnoDB 自动尝试建立哈希加速
十五、什么是预读机制?
预读就是 InnoDB 发现你在连续访问一些数据页时,可能会提前把后面的页加载到 Buffer Pool。
比如范围查询:
sql
select * from order_info where id between 1000 and 2000;InnoDB 可能判断你接下来还会读相邻页,于是提前加载。
预读的目标是:
减少后续真正访问时的磁盘等待
但如果预读进来的页后续没有被使用,也可能造成一定缓存浪费。
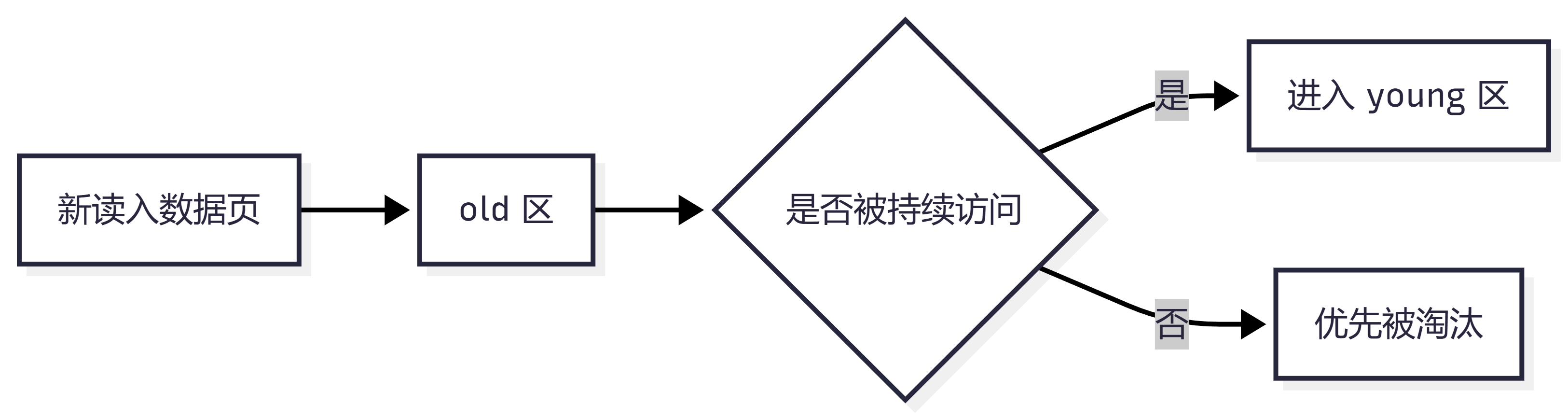
十六、什么是 Buffer Pool 的 LRU 淘汰?
Buffer Pool 空间有限,不能无限缓存所有数据页。
当空间不够时,需要淘汰一些不常用的页。
LRU 的思想是:
最近最少使用的数据页优先淘汰
但 InnoDB 不是简单 LRU,而是做了优化,大致分成:
| 区域 | 说明 |
|---|---|
| young 区 | 热点页 |
| old 区 | 新读入或较冷的页 |
新读入的页通常先进入 old 区,如果之后确实被频繁访问,才可能进入 young 区。
这样可以避免一次大查询把热点数据全部挤出去。
十七、为什么全表扫描可能污染 Buffer Pool?
假设 Buffer Pool 里原本都是热点数据,比如用户表、订单表的索引页。
突然执行:
select * from big_log_table;
这条 SQL 会加载大量不常用的数据页。
如果是简单 LRU,这些冷数据页可能会把原本的热点页挤出去,导致正常业务查询变慢。
InnoDB 的 young/old 分区机制,就是为了减少这种缓存污染。
但从业务角度看,也要避免在线库频繁执行大范围全表扫描。
十八、什么是临时表?
MySQL 执行某些 SQL 时,可能需要临时保存中间结果。
常见场景包括:
group by order by distinct union
如果内存临时表放不下,就可能变成磁盘临时表,性能会明显下降。
如果 EXPLAIN 里看到:
Using temporary
就要注意 SQL 是否存在优化空间。
常见优化方向:
减少参与分组和排序的数据量 给 group by 字段建立合适索引 拆分复杂 SQL 把重统计任务交给离线任务或缓存
十九、什么是 filesort?
filesort 不是一定指"文件排序",而是指 MySQL 不能直接利用索引顺序完成排序,需要额外排序。
例如:
select * from user order by create_time;
如果没有合适索引,可能会出现:
Using filesort
优化方向:
| 方向 | 说明 |
|---|---|
| 给排序字段建索引 | 利用索引顺序排序 |
| 使用联合索引 | 同时满足过滤和排序 |
| 减少排序数据量 | 先过滤,再排序 |
| 避免返回过多字段 | 减少排序过程中的数据搬运 |
比如常见订单查询:
select * from order_info where user_id = ? order by create_time desc limit 20;
可以考虑:
create index idx_user_time on order_info(user_id, create_time);
二十、如何从 InnoDB 角度理解性能优化?
从 InnoDB 的工作方式看,性能优化可以沿着这条链路理解:
查询尽量命中 Buffer Pool,减少磁盘 IO; 索引设计要减少读取的数据页数量; 更新通过 redo log 顺序写提升性能; 脏页后台刷盘,避免每次提交随机写; 如果脏页太多、redo log 压力大,可能导致性能抖动; order by、group by、临时表、filesort 都可能增加额外开销。
也可以画成一张图:
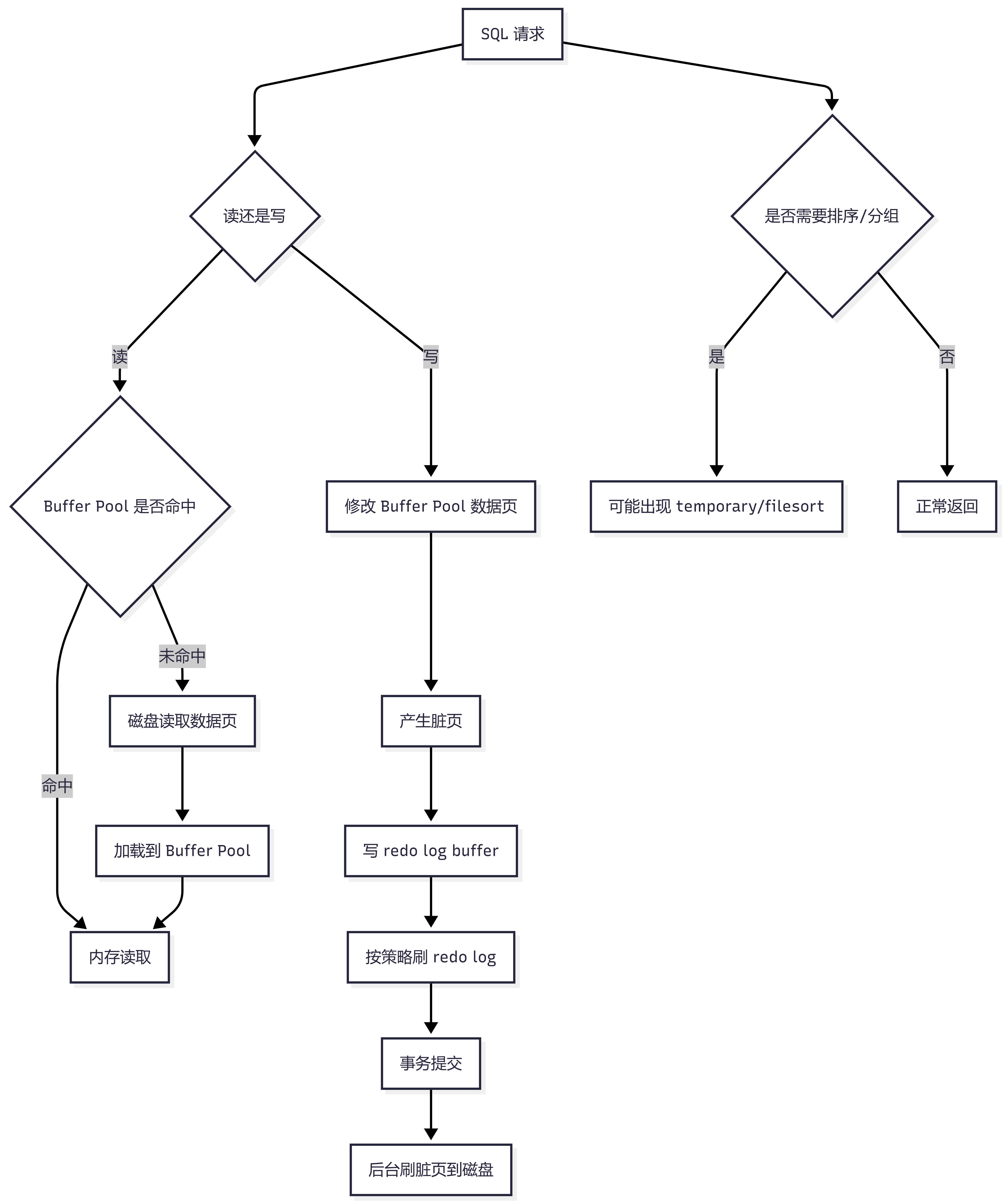
面试可以这样说:
MySQL 性能优化本质上是减少磁盘 IO、减少扫描数据量、减少排序和临时表开销。InnoDB 通过 Buffer Pool 缓存数据页,通过 redo log 顺序写保证性能和持久性,通过后台刷脏页减少提交时的随机 IO。
总结
这一组知识可以按一条线来记:
InnoDB 不是每次直接读写磁盘, 而是以 16KB 数据页为单位管理数据, 热点页缓存在 Buffer Pool 中。 查询时尽量命中 Buffer Pool, 更新时先改内存页,产生脏页, 提交时主要保证 redo log 刷盘, 脏页后续由后台线程刷回磁盘。 Buffer Pool、redo log、脏页刷盘、Doublewrite、Change Buffer、LRU、临时表和 filesort, 共同决定了 MySQL 的性能表现。
📌 码字不易,技术干货深度复盘!
如果这篇文章帮你看清了 MyBatis-Plus 查询的底层底细,别忘了 点赞、关注、收藏 三连走一波!支持作者不迷路,更多底层源码干货持续输出中!🚀