前言
Kafka 用起来不难,但要真正用好,对底层机制的理解和线上运维经验都有要求。"会用"和"用好"之间,隔着消息丢失、重复消费、ISR 抖动、集群雪崩这些问题。这些问题出的时候,往往是对 Kafka 某块机制理解不够深入,或者配置调优没做到位。
这篇文章分两部分:一块是 Kafka 核心原理,涵盖分区与副本机制、日志存储结构、Controller 选举、生产者幂等性、消费者位移管理;另一块是部署和实践,CentOS 7 上的 JDK 环境安装、Kafka 3.9 单机部署、ZooKeeper 配置、生产者和消费者 Topic 操作、cpolar 穿透实现异地调试。
适用人群:刚接触 Kafka 想打基础的开发者、负责生产环境稳定的 SRE、想系统了解消息队列原理的同学。整体偏深度,入门选手需要对照文档边看边操作。
本文将深入Kafka的核心原理------从分区与副本机制、日志存储结构、Controller选举,到生产者幂等性、消费者位移管理,并结合多年线上实践经验,总结出一套高可用、高性能、易运维的Kafka最佳实践。无论你是刚接触Kafka的开发者,还是负责生产环境稳定性的SRE,都能从中获得可落地的参考方案,真正打造出稳定、可靠、高效的消息中间件系统。

1.安装前准备
1.1 操作系统要求
Kafka可以在多种 Linux 发行版(https://so.csdn.net/so/search?q=Linux 发行版&spm=1001.2101.3001.7020)上运行,本文以CentOS 7为例,其他发行版步骤类似,只需调整包管理命令。
1.2 java环境要求
Kafka基于Java开发,需安装 JDK 8 或以上版本:
shell
java -version
1.3 安装JDK
下载 JDK
- Oracle 官网或 OpenJDK 官网下载 Linux 版本
- 示例(OpenJDK 8):
shell
wget https://download.java.net/openjdk/jdk8u41/ri/openjdk-8u41-b04-linux-x64-14_jan_2020.tar.gz解压安装包
shell
mkdir -p /usr/local/java
tar -zxvf openjdk-8u41-b04-linux-x64-14_jan_2020.tar.gz -C /usr/local/java配置环境变量
在 /etc/profile 末尾追加:
shell
export JAVA_HOME=/usr/local/java/jdk1.8.0_41
export PATH=$PATH:$JAVA_HOME/bin使配置生效:
shell
source /etc/profile验证安装
shell
java -version2.安装 Kafka
2.1 下载 Kafka
- 官网下载
- 示例版本:3.6.2
linux系统可以直接命令一键安装:
shell
wget https://downloads.apache.org/kafka/3.9.1/kafka_2.13-3.9.1.tgz
tar -xzf kafka_2.13-3.9.1.tgz
mv kafka_2.13-3.9.1 kafka
2.2 创建数据日志目录
在kafka解压目录同一路径下:创建一个kafka_data,用于装kafka和zookeeper的log和数据等:
shell
mkdir -p /opt/kafka_data
mkdir -p /opt/kafka_data/zookeeper
mkdir -p /opt/kafka_data/log
mkdir -p /opt/kafka_data/log/kafka
mkdir -p /opt/kafka_data/log/zookeeper
2.3 配置Kafka配置文件
编辑这个文件:
shell
broker.id=0
port=9092
host.name=ip
log.dirs=/opt/kafka_data/log/kafka
zookeeper.connect=localhost:2181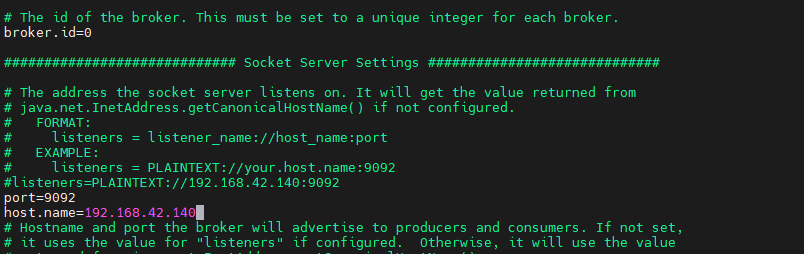


2.4 配置zookeeper配置文件
shell
dataDir=/opt/kafka_data/zookeeper
dataLogDir=/opt/kafka_data/log/zookeeper
clientPort=2181
maxClientCnxns=100
tickTimes=2000
initLimit=10
syncLimit=5
3.启动与停止Kafka
3.1开启ZooKeeper
开启ZooKeeper:
shell
./zookeeper-server-start.sh ../config/zookeeper.properties &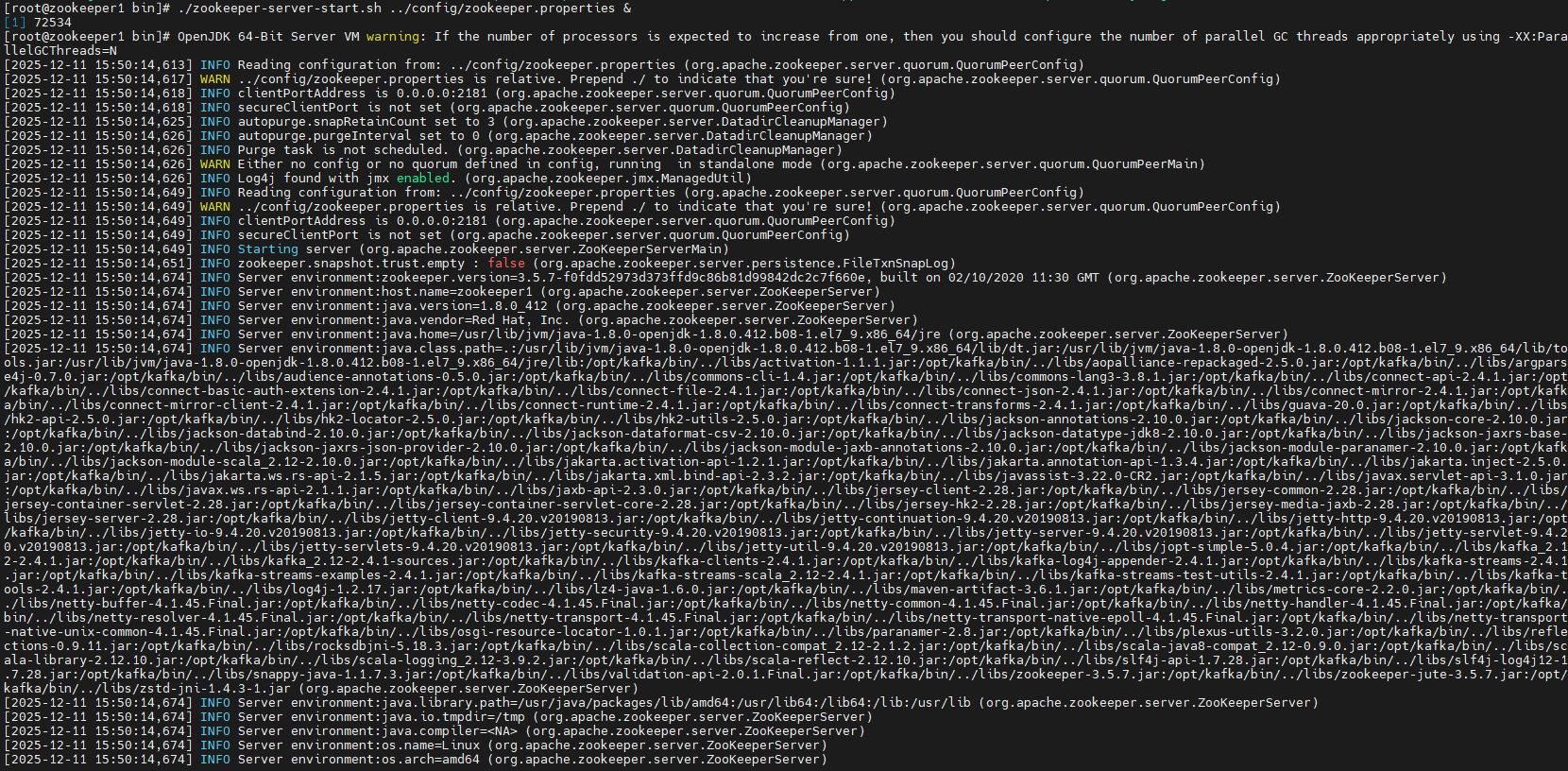
3.2启动Kafka:
shell
./kafka-server-start.sh ../config/server.properties &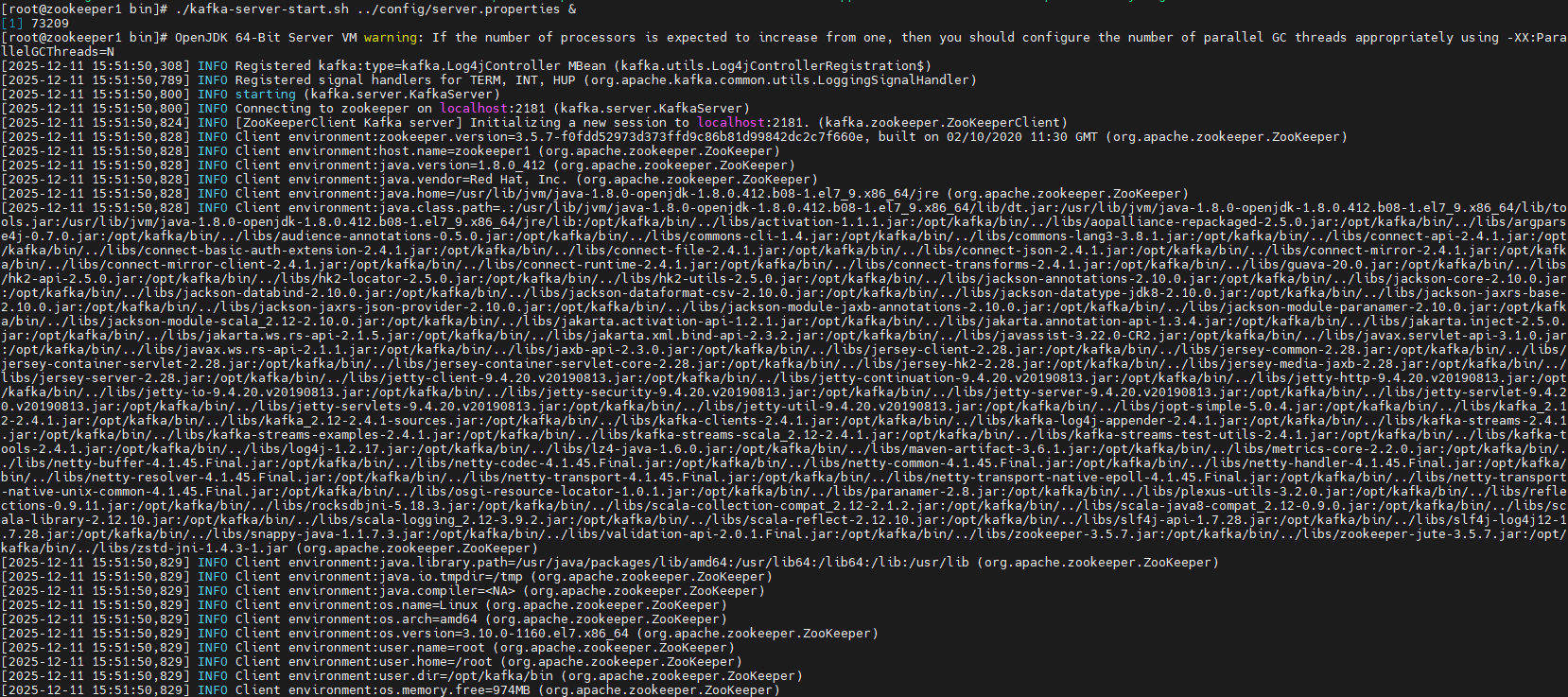
验证是否启动成功:
shell
jps输出应包含:
shell
QuorumPeerMain
Kafka
3.3停止zookeeper
shell
./zookeeper-server-stop.sh ../config/zookeeper.properties &3.4停止kafkfa
shell
./kafka-server-stop.sh ../config/server.properties &4.创建生产者topic和消费者topic简单示例
在一个终端执行创建生产者: (推消息到shan)
shell
cd /opt/bin/ #进入kafka目录
./kafka-console-producer.sh --broker-list 192.168.42.140:9092 --topic wd_test #wd_test你要建立的topic名
在一个终端执行创建消费者: (从shan上消费消息)
shell
cd /opt/bin/ #进入kafka目录
./kafka-console-producer.sh --broker-list 192.168.42.140:9092 --topic wd_test #消费shan中topic消息
查看效果: 一个终端不断输入推送的消息,另一个终端则消费这个消息
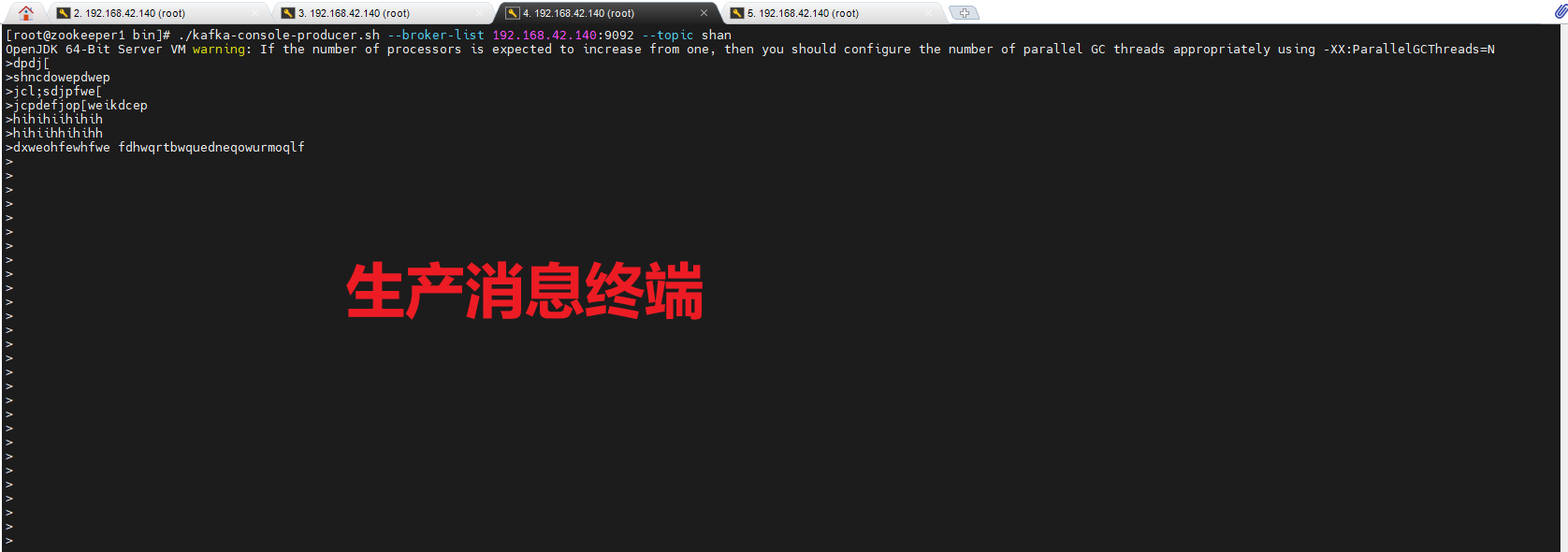
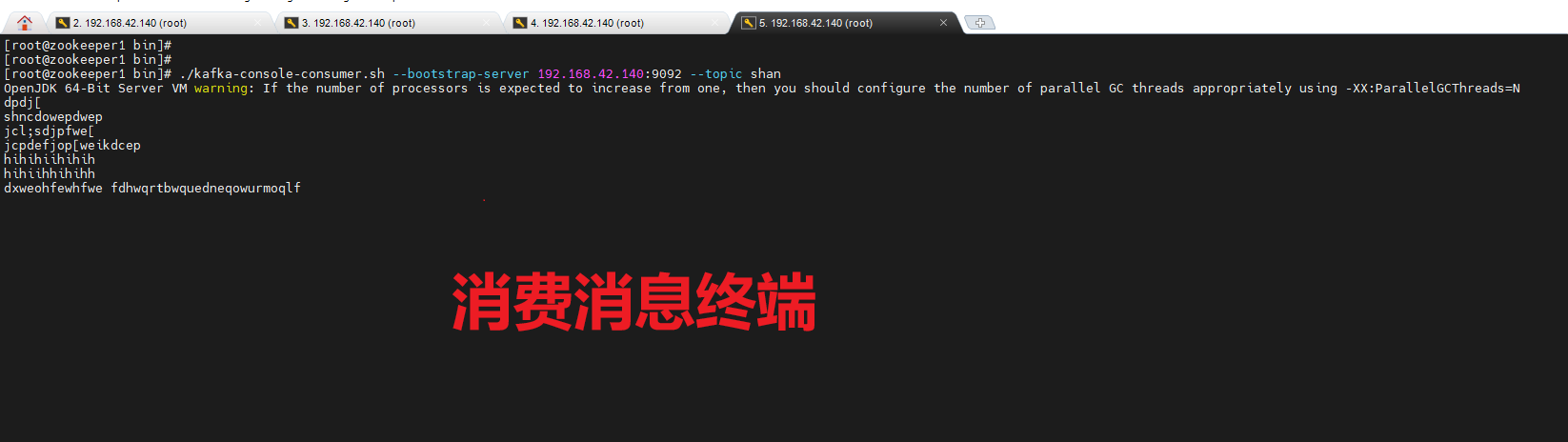
查看当前主题:
shell
./kafka-topics.sh --zookeeper localhost:2181 --list
你正在家里远程办公,突然接到任务:需要验证一个新业务模块的消息生产与消费逻辑。
但Kafka集群部署在公司内网测试环境,没有公网IP,防火墙也不开放9099/9092端口------你既无法连接Broker创建Topic,也无法从本地启动生产者或消费者进行调试。
传统的做法是:
- 提交代码到CI/CD触发部署(慢)
- 求运维临时开防火墙(麻烦)
- 或干脆去公司(不现实)
有没有更敏捷的方式?
有!借助内网穿透工具,我们可以将内网Kafka的9092端口安全暴露到公网。
只需一条隧道命令,你的本地开发机就能像在内网一样:
- 通过 kafka-topics.sh 创建测试 Topic
- 用 kafka-console-producer.sh 发送消息
- 用 kafka-console-consumer.sh 实时消费验证
整个过程无需改动 Kafka 配置、无需网络权限审批,5 分钟打通内外网,让开发调试回归高效。
跟我一起来操作吧~
5.安装cpolar内网穿透工具
cpolar 可以将你本地电脑中的服务(如 SSH、Web、数据库)映射到公网。即使你在家里或外出时,也可以通过公网地址连接回本地运行的开发环境。
❤️以下是安装cpolar步骤:
使用一键脚本安装命令:
shell
sudo curl https://get.cpolar.sh | sh
安装完成后,执行下方命令查看cpolar服务状态:(如图所示即为正常启动)
shell
sudo systemctl status cpolar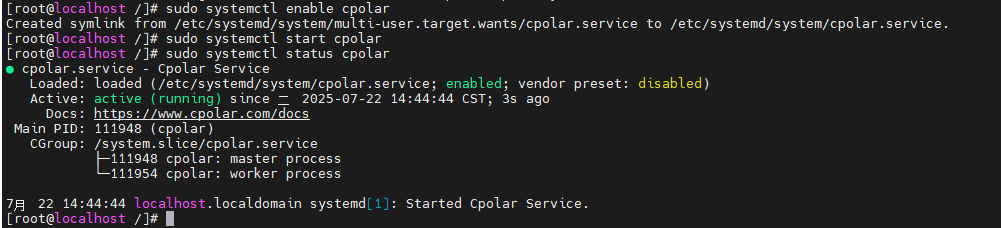
Cpolar安装和成功启动服务后,在浏览器上输入虚拟机主机IP加9200端口即:【ip:9200】访问Cpolar管理界面,使用Cpolar官网注册的账号登录,登录后即可看到cpolar web 配置界面,接下来在web 界面配置即可:
打开浏览器访问本地9200端口,使用cpolar账户密码登录即可,登录后即可对隧道进行管理。
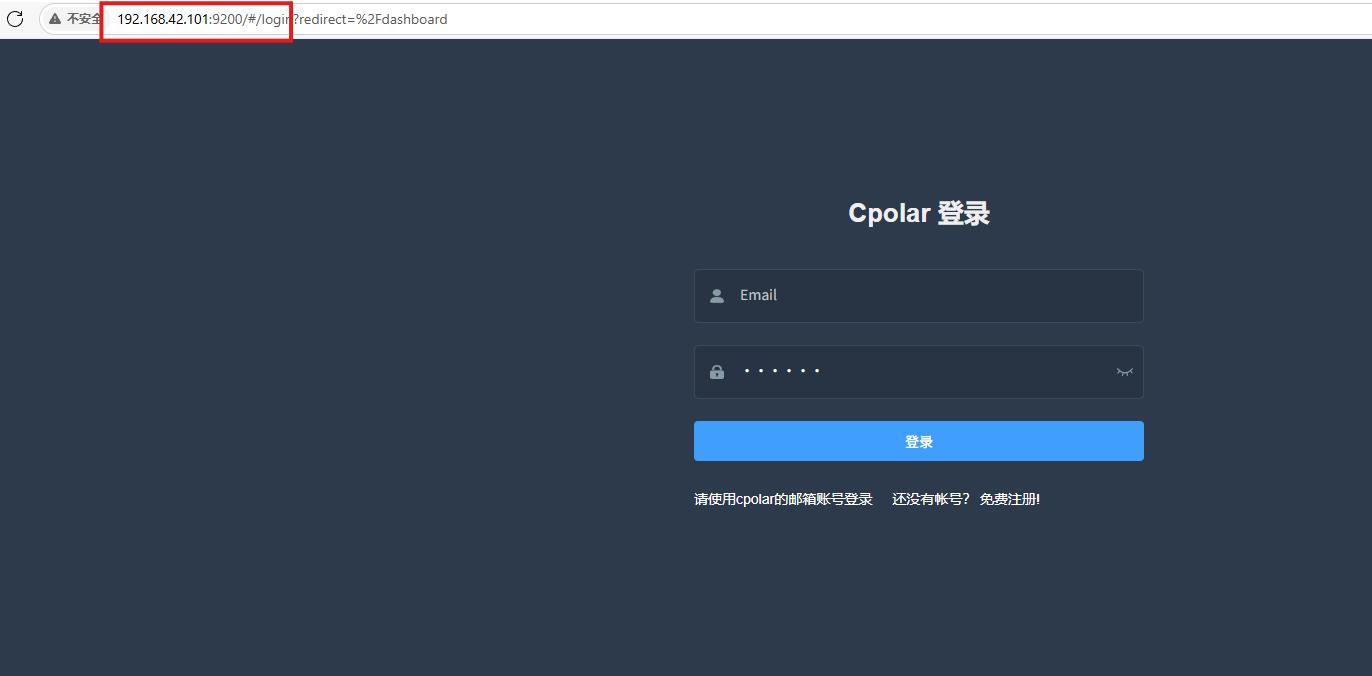
6.配置公网地址
通过配置,你可以在本地 WSL 或 Linux 系统上运行 SSH 服务,并通过 Cpolar 将其映射到公网,从而实现从任意设备远程连接开发环境的目的。
- 隧道名称:可自定义,本例使用了:zookeeper,注意不要与已有的隧道名称重复
- 协议:tcp
- 本地地址:2181
- 端口类型:随机临时TCP端口
- 地区:China Top
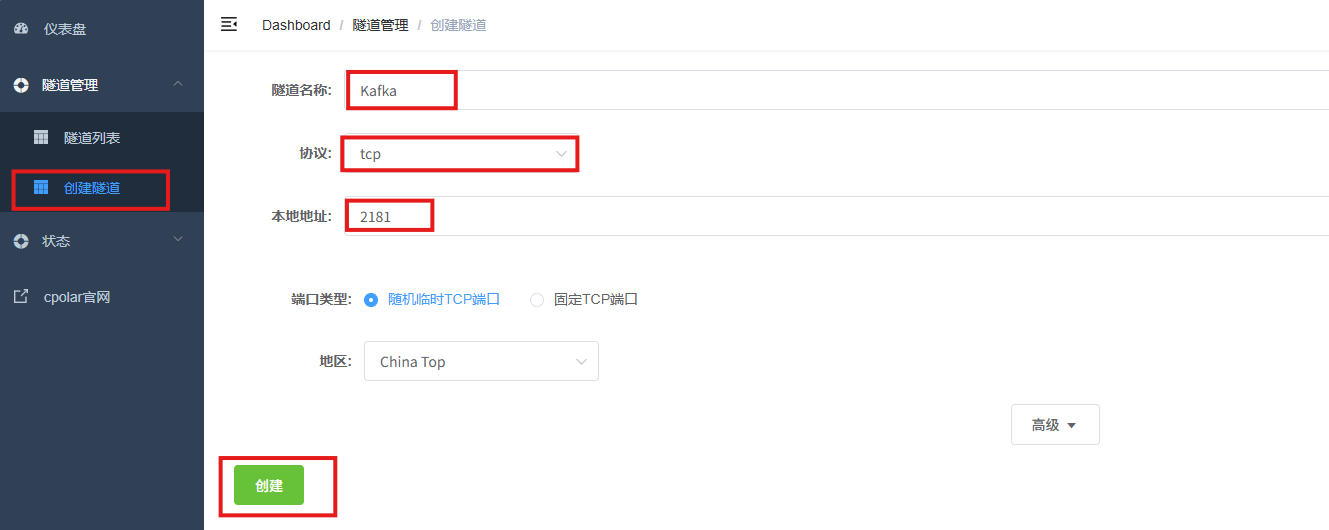
创建成功后,打开左侧在线隧道列表,可以看到刚刚通过创建隧道生成了公网地址,接下来就可以在其他电脑或者移动端设备(异地)上,使用任意一个地址在终端中访问即可。
-
tcp 表示使用的协议类型
-
2.tcp.cpolar.top是 Cpolar 提供的域名
-
13917是随机分配的公网端口号
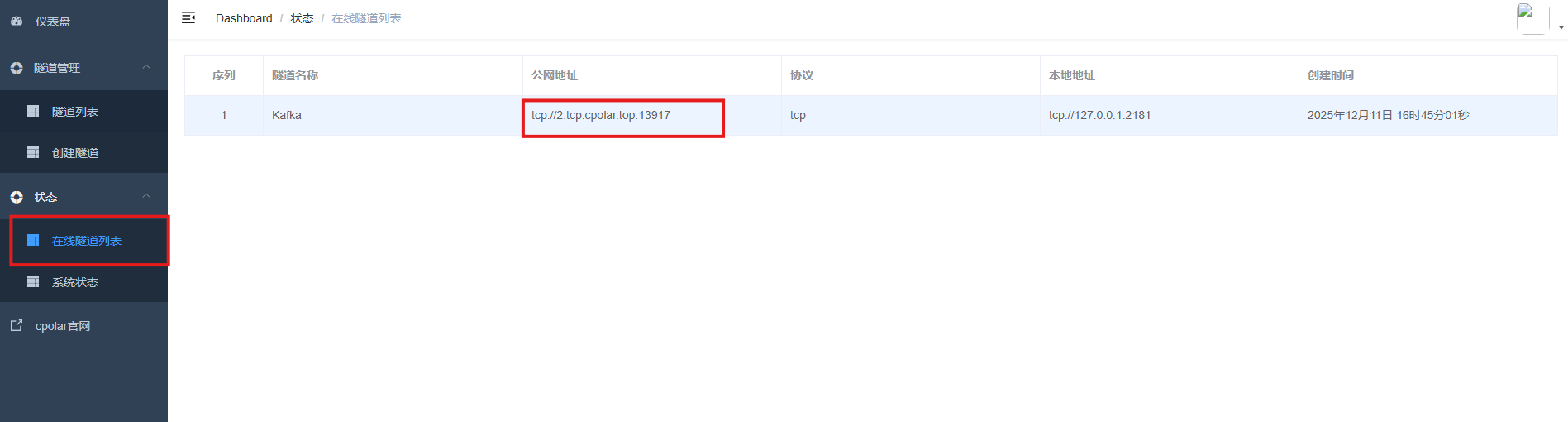
通过Cpolar提供的公网地址和端口,Kafka就能从本地启动生产者或消费者进行调试啦!
生产:
shell
./kafka-console-producer.sh --broker-list 2.tcp.cpolar.top:13917 --topic shan消费:
shell
./kafka-console-consumer.sh --bootstrap-server 2.tcp.cpolar.top:13917 --topic shan7.保留固定TCP公网地址
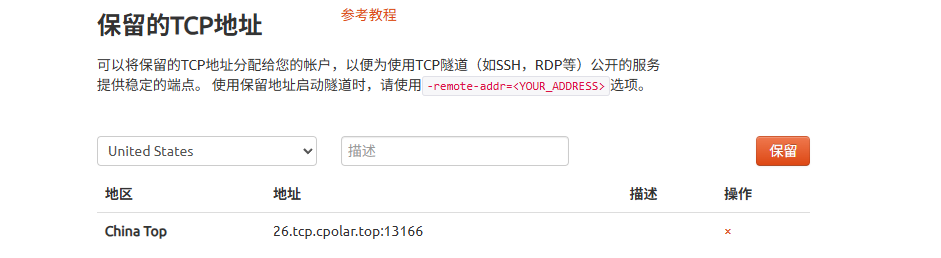
使用cpolar为其配置TCP地址,该地址为固定地址,不会随机变化。

选择区域和描述:有一个下拉菜单,当前选择的是"China Top"。
右侧输入框,用于填写描述信息。
保留按钮:在右侧有一个橙色的"保留"按钮,点击该按钮可以保留所选的TCP地址。
列表中显示了一条已保留的TCP地址记录。
-
地区:显示为"China Top"。
-
地址:显示为"26.tcp.cpolar.top:13166"。
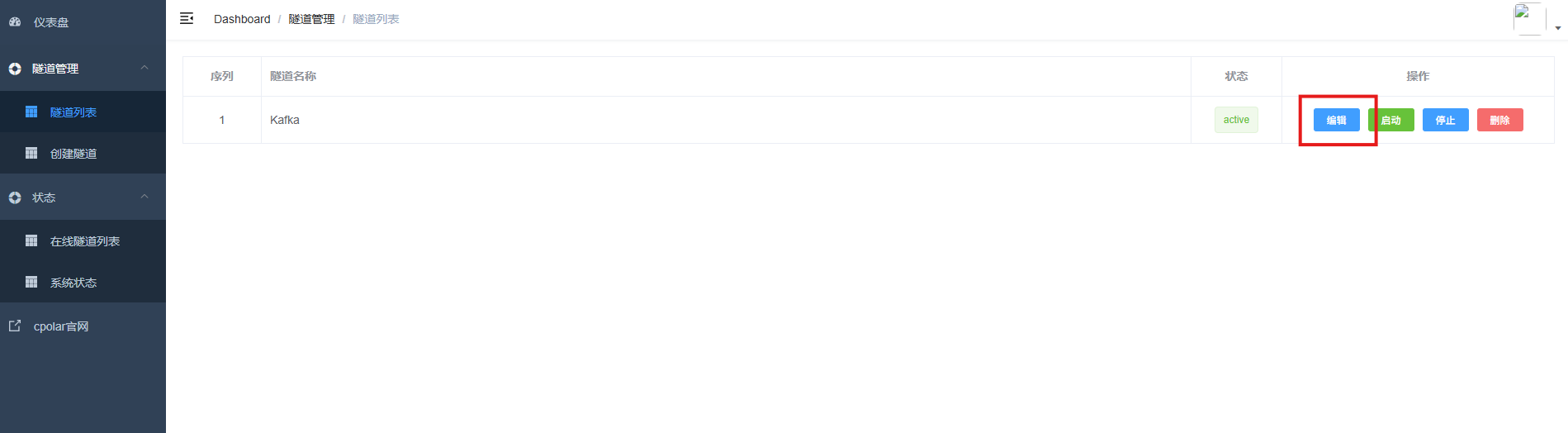
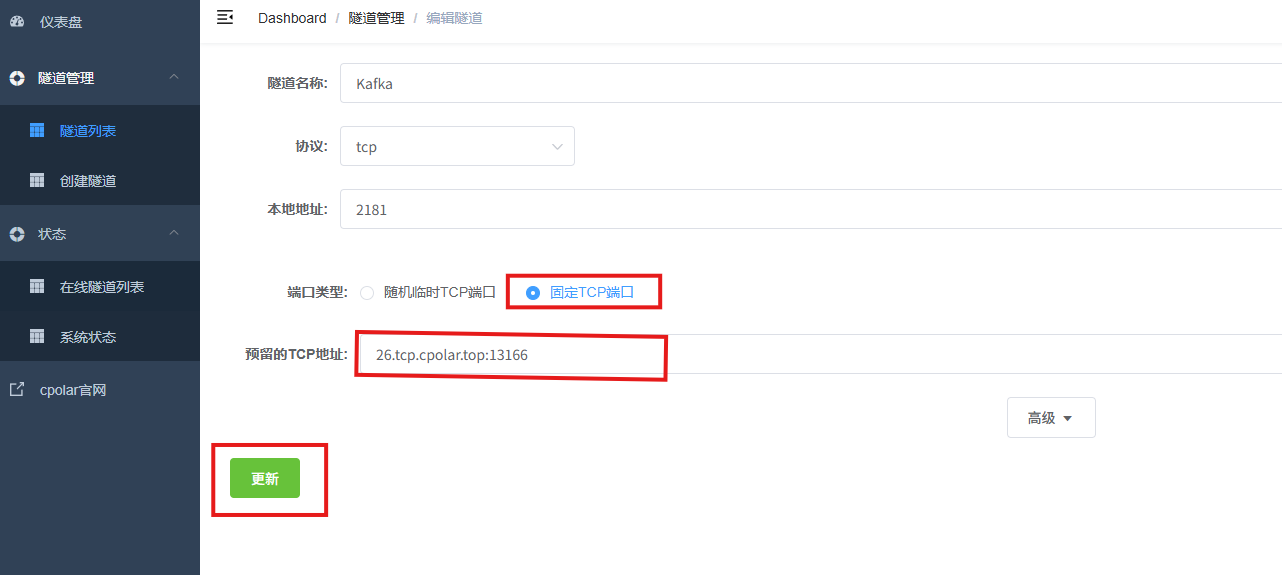
登录cpolar web UI管理界面,点击左侧仪表盘的隧道管理------隧道列表,找到所要配置的隧道Kafka,点击右侧的编辑。
修改隧道信息,将保留成功的TCP端口配置到隧道中。
- 端口类型:选择固定TCP端口
- 预留的TCP地址:填写保留成功的TCP地址
点击更新。
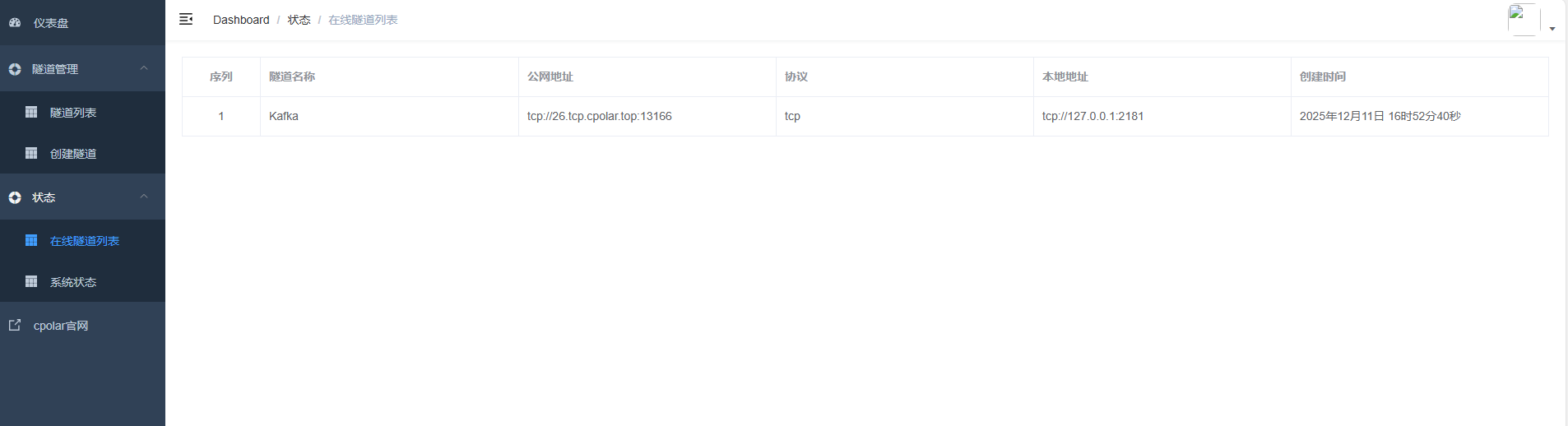
创建完成后,打开在线隧道列表,此时可以看到随机的公网地址已经发生变化,地址名称也变成了保留和固定的TCP地址。
最后就可以使用命令测试啦!
总结
Kafka 本身的核心能力体现在三个方面:高吞吐低延迟、可持久化存储、水平扩展性。但真正跑在生产环境里,可靠性才是最核心的追求------消息不丢、不重、顺序正确,这些都需要对分区副本机制、ISR 动态集合、ack 策略有清晰认知才能做到。
搭建一套稳定的消息中间件系统,光靠默认配置远远不够。副本数量、分区策略、acks 级别、消费位移管理,这些细节决定了系统在故障时的实际表现。文章里这套部署流程和最佳实践,是过去踩过不少坑之后总结出来的经验,参考价值在于帮后来者绕开同样的问题。