前言
入职现在这家公司之后已经经历了两次数据库的迁移工作了, 第一次是将一个项目的阿里云PolarDB数据库迁移至另一个PolarDB数据库; 一次是将RDS数据库迁移至阿里云PolarDB数据库. 两次迁移都有不程度地踩坑, 第二次迁移时候也吸取了第一次的教训进行了检查, 但是不可避免还是遇到了新的坑点. 所以写下这篇文章记录下踩过的坑,引以为戒.
迁移流程
两次迁移流程类似, 都是使用DTS将源库数据同步至目标库, 同时保持DTS实时同步, 将源库增量数据同步至目标库, 然后通过修改项目的jdbc连接并重新部署服务后实现数据源切换
区别是, 第一次PolarDB间的迁移,DTS可以实现双向同步; 第二次RDS迁移PolarDB仅支持源库同步目标库, 无法实现双向同步.所以RDS迁移PolarDB时增加了一个克隆库的步骤,先将源库的数据克隆一个出来, 部署一个预生产的服务,进行数据验证, 通过执行常规业务读写操作验证目标库的读写是否正常
踩坑
字符集及排序规则问题
问题出现
这个问题出现在第一次的PolarDB间迁移时, 迁移后的目标库,有部分表的字段的字符集和排序规则与源库不一致, 且影响的数据表在凌晨有批量推送数据的操作, 由于排序规则变化导致索引无法生效(这个记不清了,而且我当时也没有主力参与,此处存疑), 进而导致数据库崩溃, 服务不可用
具体表现
源库:
sql
CREATE TABLE `问题表` (
`bill_id` varchar(50) CHARACTER SET utf8 COLLATE utf8_bin NOT NULL COMMENT '单据ID',
......其他字段
PRIMARY KEY (`bill_id`),
UNIQUE KEY `bill_id` (`bill_id`),
......其他索引
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci ROW_FORMAT=DYNAMIC ;目标库:
sql
CREATE TABLE `问题表` (
`bill_id` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '单据ID',
......其他字段
PRIMARY KEY (`bill_id`),
UNIQUE KEY `bill_id` (`bill_id`),
......其他索引
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci ROW_FORMAT=DYNAMIC ;这张表的字段源库的排序规则是utf8_bin, 迁移后的目标库的排序规则变成了utf8mb4_general_ci ,引发了问题
这两者区别是:
utf8_bin:将字符串中的每一个字符用二进制数据存储,区分大小写(在二进制中 ,小写字母 和大写字母 不相等.即 a !=A)。
utf8_genera_ci:不区分大小写
原因
具体的原因由运维与阿里云进行交涉后, 得到的答复是: 任务调度的机器结构迁移包的版本比较旧导致, 定性为阿里云迁移服务导致的事故
教训
虽然最终定性为三方事故, 但是也给了我们警示, 在后续的迁移中需要格外注意字符集和排序规则的检查. 也是进行迁移时验证方案不完备的问题, 否则此问题应在迁移后检查核对时就体现出来
排序问题
问题出现
此问题出现在RDS迁移PolarDB时. 业务中存在一个场景是: 批量导入一些数据后, 手动批量更新状态字段, 然后外部系统定时请求API拉取数据. 其中外部系统拉取数据是一个分页操作, 根据时间范围查询数据并分批拉取这部分数据,直到拉取完为止.
但是迁移后, 某次处理这个业务时, 我观察到分批约3000条的数据, 每页500条, 接口请求了7次全部拉取完成后, 这3000条数据的拉取标识并未全部更新, 还有1000条未更新拉取标识.
排查API调用日志发现, 拉取的数据中存在重复的, 如第一次请求时拉取了这个数据, 第二次拉取时仍然包含这个数据. 就导致有的数据被拉取了多次,有的数据一次都没拉取到
原因
检查了一下分页查询的语句, 发现语句中并没有排序字段,即order by , 当无排序字段,或排序字段值相同时, PolarDB由于查询优化或分布式的原因, 查询结果的排序并不一定一致, 所以多次分页查询的数据顺序并不一致,进而导致分页数据不正确的问题
参考资料: PolarDB-X最佳实践系列(三):如何实现高效的分页查询
同时我们观察到另一个项目也出现了这样的问题, 订单列表是创建时间倒序查询的, 但有些订单是由父订单拆分得到的,创建时间完全想通过, 由于排序不一致,导致翻页之后有些订单重复出现,有些订单未显示
RDS没有这个问题, 迁移至PolarDB才体现
问题解决
解决方式也很简单, 查询加排序即可order by id
同时在日常开发进行分页查询时注意排序字段问题,当排序字段可能相同时,加入id排序
带时区的日期字符串问题
此问题也发生在RDS迁移PolarDB中, 关于时区的问题之前运维有提过, 据说是之前其他部门尝试迁移此项目的DB时发生了这个问题, 导致迁移被迫终止. 关于这个问题原本的描述是:
项目中日期类型使用的
java.util.Date, 可能包含时区信息, 迁移至PolarDB后可能无法支持带时区存储, 如有必要可能需要修改代码中的Date类型为其他日期时间类型
我们在接受迁移任务后也进行了一些调研, java.util.Date确实可以存储时区信息, 但时区来源是jdbc连接参数, db本身并不存储时区信息, 即迁移前的RDS和迁移后的PolarDB的datetime字段本身都不存储时区信息, 何来的迁移后不兼容问题呢? 所以我们在调研后对此问题并未在意.
问题出现
但是实际这个问题还是出现了, 在迁移之后第二天, 用户在执行某项操作时, 发生了数据库操作异常, 排查报错日志是某个update语句更新时包含带时区的时间, 导致更新异常
问题原因
仔细研究了一下报错的语句,并分析原因
-
报错日志
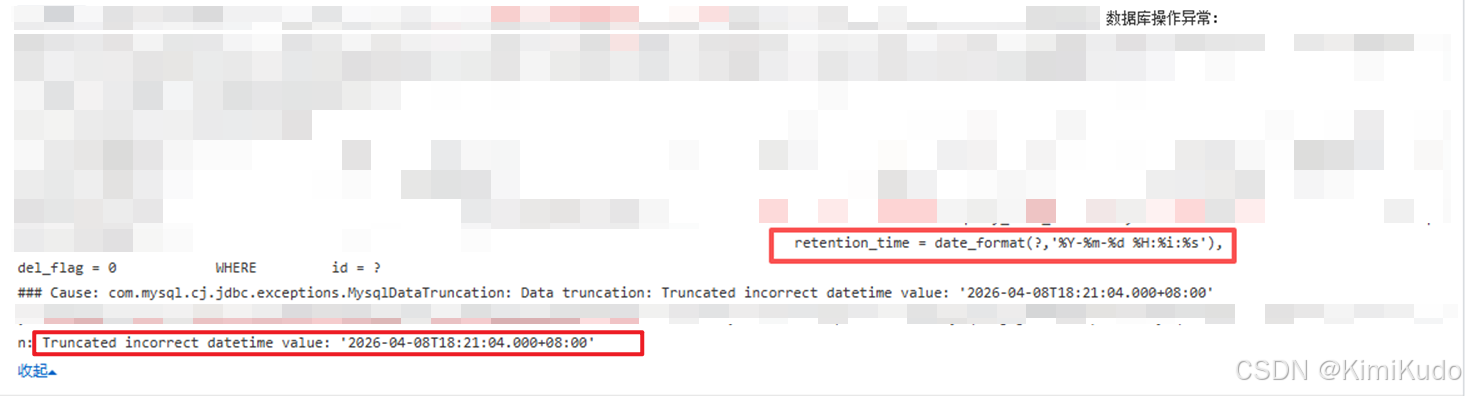
可以看到, 报错的语句实际上是一个带时区的字符串进行date_format导致的,即语句本身应该是:sqlUPDATE t_table SET retention_time = date_format('2026-04-08T18:21:04.000+08:00', '%Y-%m-%d %H:%i:%s') WHERE id = xxxx -
函数验证 既然已经定位了问题语句,我尝试进行SELECT测试, 发现SELECT可以执行, 虽然SELECT可以返回结果, 但仍会有相同的incorrect datetime value的提示
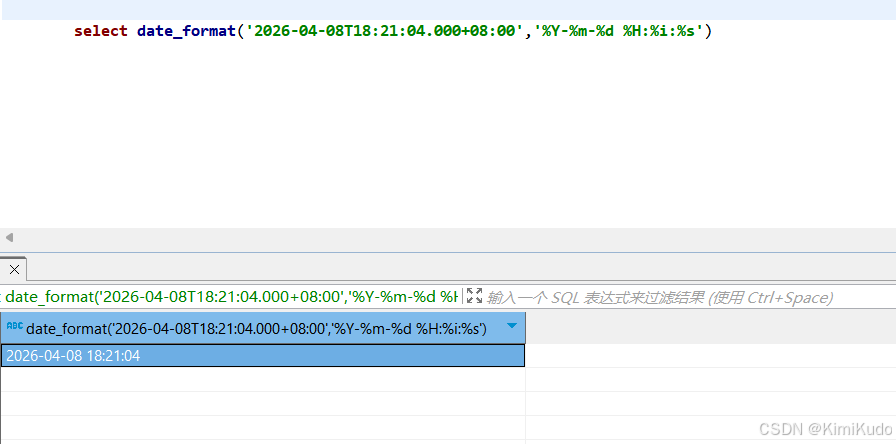
-
更新测试 于是为了模拟生产问题, 我进行了一次更新测试, 发现更新时确实提示异常,无法成功, 于是怀疑是SELECT时存在隐式转换, 但是UPDATE有较为严格的校验, 导致失败. 同时也提工单咨询了一下阿里云, 反馈确实如此

-
带时区原因 已经定位了DB层的问题, 那么就开始排查应用层为何会传入带时区的字符串了, 检查了一下代码, 发现这个字段是通过某个详情接口返回给前端的Date类型数据(带时区), 前端在更新时将数据原样回传, 后端用String类型接收并执行UPDATE导致的. 所以实际上是Date类型返回给前端时,被jackson的默认格式序列化为了带时区的字符串, 然后后端又接收了这个带时区的字符串的原因
问题解决
由于报错的这个业务场景其实是不需要更新这个时间字段的, 所以处理上我们简单粗暴地在UPDATE语句中移除了这个字段的更新
但实际上, 问题根本在于jackson序列化Date的问题, 所以也可以增加jackson的配置, 使Date返回前端时是yyyy-MM-dd HH:mm:ss格式, 回传时也是这个格式即可
yml
spring:
jackson:
time-zone: GMT+8
date-format: yyyy-MM-dd HH:mm:ss # 自定义格式,不带时区
serialization:
write-dates-as-timestamps: false # 不以时间戳形式输出总结就是! 这个问题跟Date类型或者DB存储时区根本没多大关系, 纯纯代码问题!!!
hash join问题
此问题出现在RDS迁移PolarDB时, 迁移并将数据源切换后, 发现数据库CPU/内存短时内飚高, 查看SQL日志发现有大量的慢SQL积压. 被迫进行了一批SQL调优
问题出现
但是调优过程中发现, 同样的SQL,在RDS命中的索引与PolarDB完全一致, 但是查询时间想差很大, RDS一秒内就能执行的查询,PolarDB一分钟也不一定能查询出来.
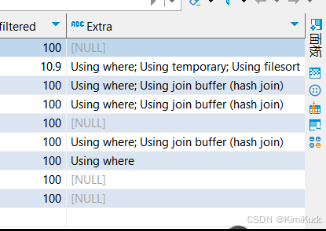
举个例子: 分别在两个数据源查看相同SQL的执行计划, 发现索引命中相同, 仅有Extra不同
RDS:
PolarDB:
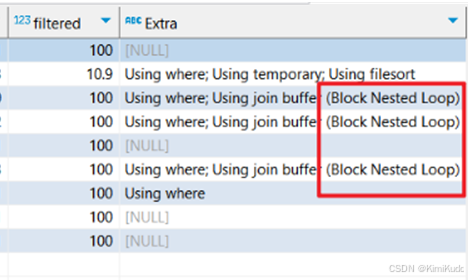
问题原因
查阅了一下hash join的资料, 这是一个MySQL的新特性, 可以在大表连接时不依赖索引而实现高效的连接效率, 具体实现原理可以查阅下相关资料.
但是hash join也需要在配置中进行开启, 可以通过此查询确认是否开启
sql
SHOW VARIABLES LIKE 'optimizer_switch';
-- 查看是否有 hash_join=on检查了目标库PolarDB的配置,发现无此配置, 进行设置后也未生效, 直到我翻阅阿里云PolarDB官方文档时,看到了如下内容:
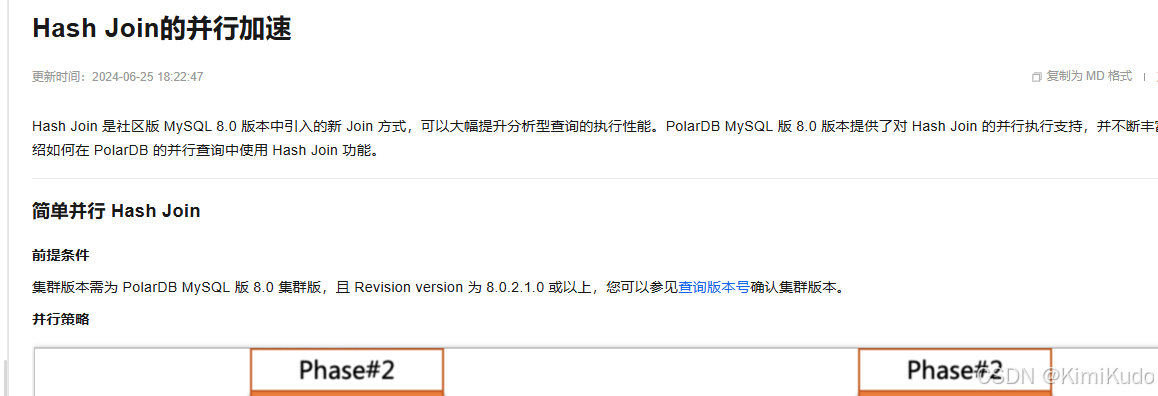
文档要求小版本需要高于8.0.2 , 而我们PolarDB版本为8.0.13, 并不支持hash join, 这也就是为什么迁移后挤压了大量的慢SQL
问题解决
解决方式就比较笨了, 由于无法直接升级小版本, 只能对慢SQL进行索引优化, 之前依赖hash join的性能有很多大表未加索引或者索引设计不佳, 通过分析SQL添加索引进行慢SQL优化
同时我们后续也部署了一个8.0.2版本的PolarDB数据库,并克隆了一份数据进行验证, 发现高版本的PolarDB在未新增索引的情况下, 相同SQL确实可以使用hash join进行查询优化, 可以得出结论,此次问题确实是版本问题.
总结
至此, 已将两次DB迁移中踩过的坑和解决方案进行了记录, 在日后有相似迁移时进行警醒和注意. 特此记录