一、Redis 环境准备
- Redis 不支持 Windows 电脑,所以我所有的操作都是基于 Docker 中的 Redis 进行的。
- Redis 的镜像版本是 8.4.2
(一)安装redis
【1】Ubuntu 安装
-
更新包列表
powershellsudo apt update -
安装 redis
powershellsudo apt install redis-server -
在终端中使用如下命令可以看到 redis 相关的文件
powershellls -la /usr/bin/redis* -
可执行文件及说明
文件名 说明 redis-server Redis 服务器程序 redis-cli Redis 命令行客户端 redis-benchmark Redis 性能测试工具 redis-check-aof AOF 文件检查工具 redis-check-rdb RDB 文件检查工具 redis-sentinel Redis 哨兵(高可用解决方案)
【2】docker 安装
-
搜索 redis,点击 pull 按钮,拉取 redis 镜像
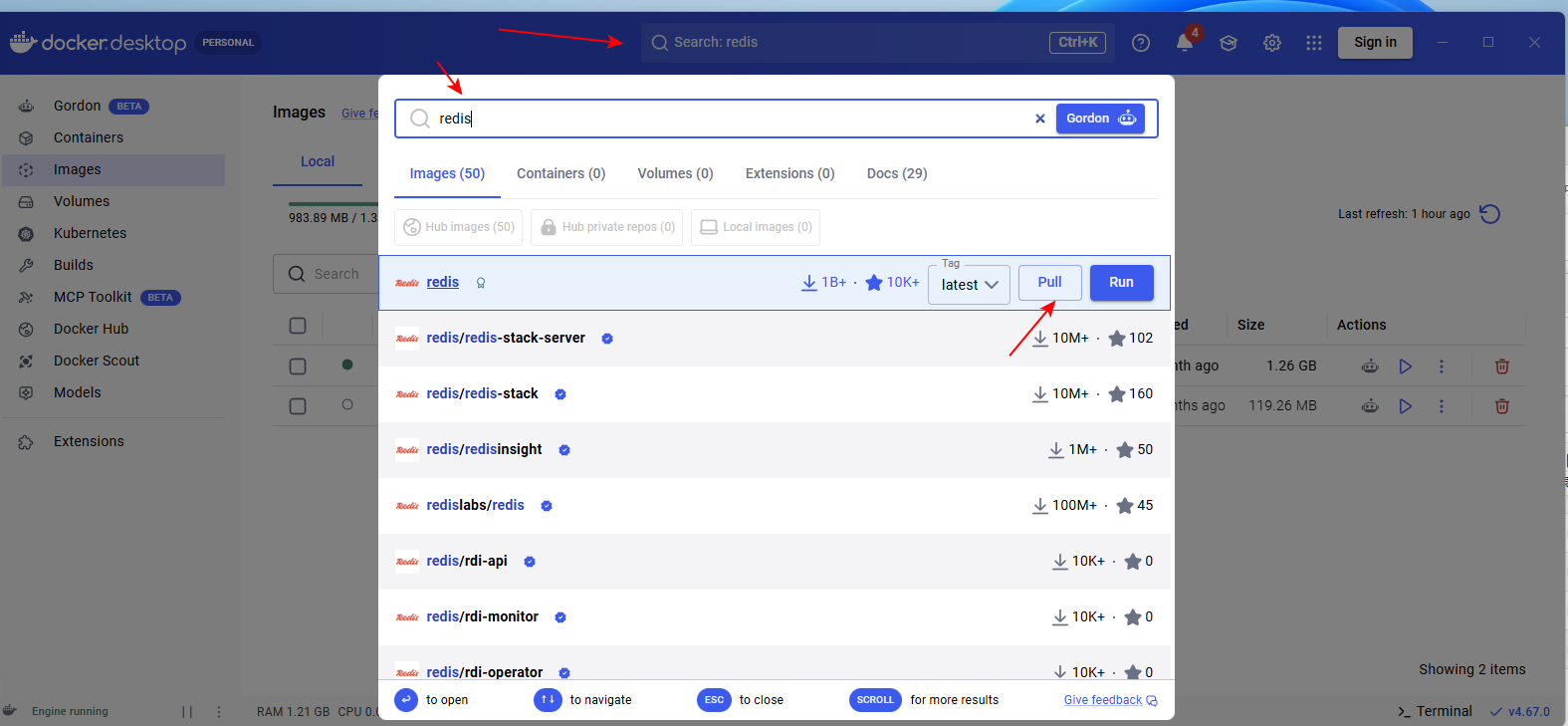
-
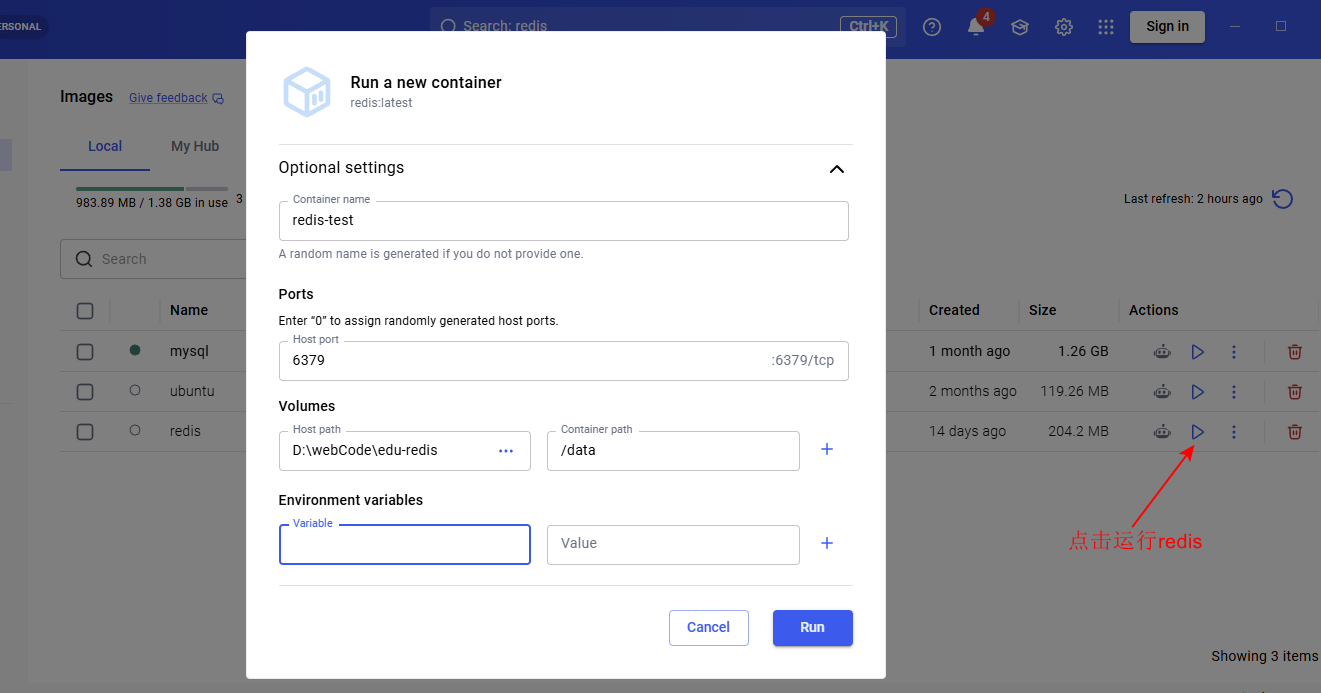
下载完redis 镜像后,运行redis镜像,填入一些信息,然后点击 "Run" 按钮
- 端口映射就是把主机的 6379 端口映射到容器内的 6379 端口,这样就能直接通过本机端口访问容器内的服务了。
- 指定数据卷,用本机的任意一个目录挂载到容器内的 /data 目录,这样数据就会保存在本机。
(二) 启动和停止 Redis
【1】ubuntu 启动Redis
-
在 ubuntu 中启动 redis,在命令行中输入如下命令
- redis 服务器的默认端口号是 6379,可以使用
--port参数自定义端口号
powershell# 使用默认端口号 redis-server # 自定义端口号 redis-server --port 6380 - redis 服务器的默认端口号是 6379,可以使用
-
当看到如下输出就说明启动成功了
powershell3351:C 20 Apr 2026 23:29:41.675 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo 3351:C 20 Apr 2026 23:29:41.675 # Redis version=7.0.15, bits=64, commit=00000000, modified=0, pid=3351, just started 3351:C 20 Apr 2026 23:29:41.675 # Warning: no config file specified, using the default config. In order to specify a config file use redis-server /path/to/redis.conf -
在终端中输入
redis-cli,见到如下输出,就进入交互模式powershell127.0.0.1:6379>
【2】docker 启动Redis
-
在容器中点击运行 redis 容器
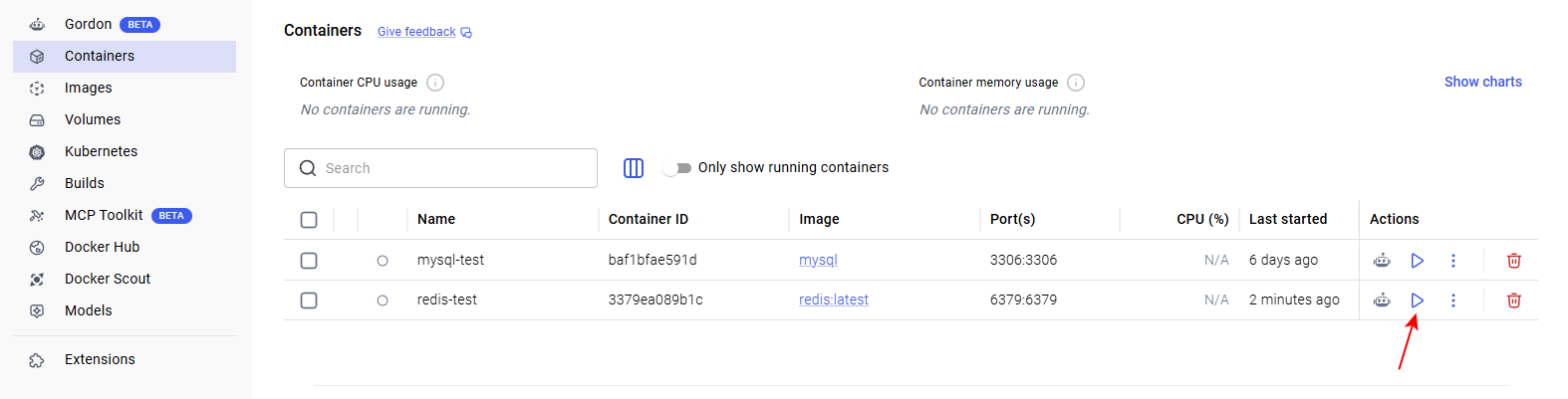
-
在redis 运行起来后,点击容器界面
redis-test
-
在 exec 输入 redis-cli,进入交互模式
【3】停止Redis
-
考虑到Redis有可能正在将内存中的数据同步到硬盘中,强行终止Redis进程可能会导致数据丢失。正确停止Redis的方式应该是向Redis发送SHUTDOwN命令,方法为:
powershell# 终端中 redis-cli SHUTDOWN # redis-cli 中(可以看下边的【4】区分他俩的区别) SHUTDOWN -
当Redis接收到SHUTDOWN命令后,会先断开所有客户端连接,然后根据配置执行持久化,最后完成退出。
【4】向 Redis 发送命令
- redis-cli 就是 Redis 自带的基于命令行的 Redis 客户端。
- redis 命令不区分大小写,键名和键值区分
-
Ubuntu 向 Redis 发送命令有两种方式:
-
在终端通过
redis-cli+命令的方式,如:测试客户端与Redis 的连接是否正常,如果连接正常会返回PONG, 命令如下powershellredis-cli PING -
第二种是不带
redis-cli的命令。先在终端中执行redis-cli,就会进入到redis 的交互模式,然后就可以自由输入命令了powershell# 进入到交互模式 redis-cli # 进入到交互模式后终端将会显示 127.0.0.1:6379> # 然后输入 PING 命令,会输出 PONG 127.0.0.1:6379> PING
-
-
Docker 中发送命令
- 在Docker 容器中的Reis 也能执行像Ubuntu 的那两种模式。
- 启动redis,然后找到redis的容器名称,点击名称选择终端,输入
redis-cli就进入到redis的交互模式了
(三) Redis Insight
- Redis Insight 是 Redis 官方推出的免费图形化管理工具,专为开发者设计,用于构建、调试、优化和可视化 Redis 数据库。它支持多种 Redis 部署方式(包括社区版、云服务、集群等),并提供直观的 GUI 和强大的 CLI 功能。
- 下载地址,里边的信息随便填填就可以下载了:https://redis.io/downloads/?_gl=1*nx8art*_gcl_au\*NDQzNjg2MjM4LjE3NjQ2MTY0NDE.#Redis_Insight
- 安装好之后,其实默认就会连接本机的redis,就不多赘述了
- 点击自己的 redis 就可以可视化的看见自己定义的所有类型的key 和值
- 窗口放大,就可以点击key 后看到值了
二、Redis 类型
- Redis 是一个键值对数据库。
- 下面的命令都是在redis的交互模式下进行的(交互模式可以看上一章的
【4】向Redis 发送命令) - redis 命令不区分大小写,键名和键值区分大小写
(一) 一些通用操作
【1】获取键名
-
语法
powershellKEYS pattern -
pattern 支持 glob 风格通配符格式,具体规则如下:
符号 含义 ? 匹配一个字符 * 匹配任意个(包括0个)字符 \[\] 匹配括号间的任一字符,可以使用"-"符号表示一个范围,如ab-d可以匹配"ab"、"ac"和"ad" \x 匹配字符x,用于转义符号。如要匹配"?"就需要使用? -
获取 Redis 中所有键
powershellkeys * -
获取以 ba 开头的键
powershellkeys ba*
【2】判断一个键是否存在
-
语法:如果键存在返回整数类型 1 否则返回 0
powershellEXISTS key -
判断键是否存在
powershellEXISTS bar # 返回 (integer) 1 EXISTS eesss # 返回 (integer) 0
【3】删除键
-
语法:可以删除一个或多个键,返回值是删除的键的个数
powershellDEL key [key ...] -
删除键
powershell# 删除多个键 DEL bar bar2 # 返回,假如只有bar存在会返回 1 (integer) 2 # 删除一个不存在的键 DEL aass (integer) 0 -
DEL 命令不支持通配符,但是可以用组合命令的方式在终端中(不是redis的交互模式)进行批量删除
powershell# 删错所有以 bar 开头的键 redis-cli del `redis-cli keys bar*`
【4】获取键类型
-
语法
powershellTYPE key -
获取键类型
powershellTYPE bar # 返回 string
【5】键名的命名推荐
- Redis对于键的命名并没有强制的要求,但比较好的实践是用
对象类型:对象ID:对象属性来命名一个键,如使用键user:1:friends来存储ID为1的用户的好友列表。对于多个单词则推荐使用.分隔,一方面是沿用以前的习惯(Redis以前版本的键名不能包含空格等特殊字符),另一方面是在redis-cli中容易输入,无需使用双引号包裹,比如使用article:1:page.view记录文章id为1的访问次数。
(二) 字符串类型
- 字符串类型(string)是Redis中最基本的数据类型,它能存储任何形式的字符串,包括二进制数据。你可以用字符串类型存储用户的邮箱、JSON序列化的对象甚至是一张图片。一个字符串类型键允许存储的数据的最大容量是512MB。
- Redis 的 string 类型不区分字符串和数字
【1】赋值与取值
-
赋值语法
powershellSET key valuepowershell# 用例:等同于编程的 key1 = "hello" SET key1 hello # 再次设置会进行覆盖 SET key1 world -
获取值语法
powershellGET keypowershell# 用例 GET key1 # 当键不存在时会返回空 GET key2 # 返回 (nil)
【2】递增数字
- 字符串类型可以存储任何形式的字符串,当存储的字符串是整数形式时,Redis提供了一条实用的命令INCR,其功能是使当前键值递增,并返回递增后的值。
- 如果要操作的键不存在时默认的键值将会是0。
- 如果操作的不是整数形式的字符串时,会报错
-
先直接用一个不存在的键名,将会创建该键名和值
powershellINCR myNum # 返回 (integer) 1 -
定义一个键值对,值为字符串1,然后使用 INCR
powershellSET myStrNum "1" # 等同于(注意:在 redis insight 中添加字段时 "1" 的引号会被保留) SET myStrNum 1 # 使用 INCR INCR myStrNum # 返回 (integer) 2
【3】增加/减少指定的整数/浮点数
-
语法
powershell# 增加指定的整数 INCRBY key increment # 减少 DECR key # 减少指定的整数 DECRBY key decrement # 增加指定浮点数(要减少时使用负数) INCRBYFLOAT key increment
-
直接用一个不存在的键名,将会创建该键名和值
powershellDECR aabbcc # 返回 (integer) -1 -
增加和减少指定的整数
powershell# 增加 5 INCRBY aabbcc 5 # 减少 5 DECRBY aabbcc 5 -
增加和减少浮点数
powershell# 增加 INCRBYFLOAT aabbcc 4.5 # 减少 INCRBYFLOAT aabbcc -4.5
【4】向尾部追加值
-
如果键名不存在则会添加键名,键值就是value
-
语法,返回追加后的字符串的总长度
powershellAPPEND key value
-
键名不存在将会创建
powershellAPPEND name zhangsan # 等同于 SET name zhangsan -
对数字字符串追加
powershell# aabbcc 键值为 4 APPEND aabbcc 1 # 返回(键值为 41) (integer) 2 -
对文字字符串追加
powershell# name 键值为 zhangsan(注意:不要给值添加引号) APPEND name -male # 返回 (integer) 13
【5】获取字符串长度
-
语法:如果键名不存在返回0
powershellSTRLEN key -
键名不存在
powershell# 键名不存在 STRLEN aaee # 返回 (integer) 0
【6】同时获得/设置多个键值
-
语法
powershell# 获取多个键值 MGET key [key ...] # 设置多个键值 MSET key value [key value ...] -
使用
powershell# 设置 key1 值为1, key2值为2,key3值为3 MSET key1 1 key2 2 key3 3 # 返回 OK # 获取多个键的键值,aaaa 不存在 MGET key1 key3 aaaa # 返回 1) "1" 2) "3" 3) (nil)
(三) 哈希类型
- Redis是采用字典结构以键值对的形式存储数据的,而哈希类型(hash)的键值也是一种字典结构,其存储了字段(field)和字段值的映射,但字段值只能是字符串,不支持其他数据类型,换句话说,哈希类型不能嵌套其他数据类型。一个哈希类型键可以包含至多2^32-1个字段。
- 除了哈希类型,Redis的其他数据类型同样不支持数据类型嵌套。例如集合类型的每个元素都只能是字符串,不能是另一个集合或哈希表等。
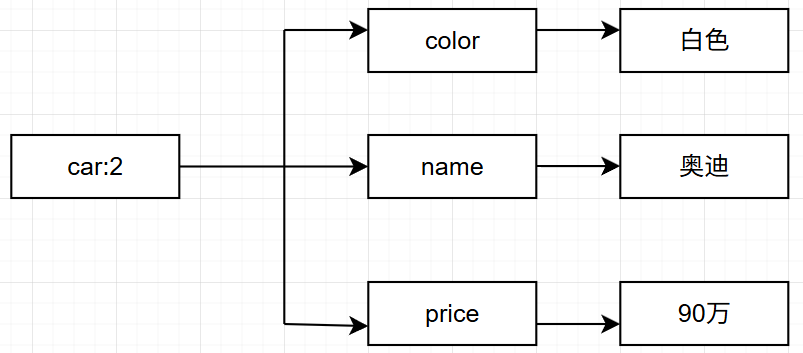
- 哈希类型适合存储对象:使用对象类别和 ID 构成键名,使用字段表示对象的属性,而字段值则存储属性值。例如要存储ID为2的汽车对象,可以分别使用名为color、name和price的3个字段来存储该辆汽车的颜色、名称和价格,存储结构如图所示。
【1】 赋值与取值
-
赋值语法
powershell# 给一个字段赋值 HSET key field value # 设置多个字段值 HMSET key field value [field valaue ...] -
取值语法
powershell# 获取一个字段值 HGET key field # 获取多个字段值 HMGET key field [field ...] # 获取全部字段和字段值 HGETALL key -
使用
powershell# key 为 car 字段为 price 值为 500 # 类似 {car: {price: 500}} HSET car price 500 # 返回 (integer) 1 # 获取字段值 HGET car pricepowershell# 设置多个字段的值 HMSET car name BMW color 白色 # 返回 OK # 获取多个字段的值 HMGET car name colorpowershell# 获取键中的所有字段和字段值 HGETALL car # 返回 1) "price" 2) "500" 3) "name" 4) "BMW" 5) "color" 6) "\xe7\x99\xbd\xe8\x89\xb2"
【2】判断字段是否存在
-
语法
powershellHEXISTS key field -
使用
powershellHEXISTS car name # 返回 (integer) 1 # key 存在键不存在 HEXISTS car name123 # 返回 (integer) 0 # 键也不存在时 HEXISTS car123 name # 返回 (integer) 0
【3】给不存在的字段赋值
-
语法
- NX 表示:if N ot eXists
HSETNX命令与HSET命令类似,区别在于如果字段已经存在,HSETNX命令将不执行任何操作。
powershellHSETNX key field value -
使用
powershell# 赋值一个已经存在的字段 HSETNX car name BYD # 返回 (integer) 0 # 赋值一个不存在的字段 HSETNX car msg zzz # 返回 (integer) 1
【4】递增数字
-
语法
- 没有类似
INCR的HINCR
powershellHINCRBY key field increment - 没有类似
-
使用
powershellHINCRBY car price 20 # 返回 (integer) 520 HINCRBY car price -50 # 返回 (integer) 470powershell# 字段不存在,默认是0,并给car 添加了 cost 字段 HINCRBY car cost 80 # 返回 (integer) 80 # 键不存在,默认是 0,并添加键和键的字段 HINCRBY person score 60 # 返回 (integer) 60
【5】删除字段
-
语法
powershell# 可以删除一个或多个字段 HDEL key field [field ...] -
使用
powershell# 删除多个字段,aaa 字段不存在,所以返回2 HDEL car cost msg aaa # 返回 (integer) 2
【6】只获取字段名或字段值
-
语法
powershell# 只获取字段名 HKEYS key # 只获取字段值 HVALS key -
用法
powershellHKEYS car # 返回 1) "price" 2) "name" 3) "color" # HVALS car 1) "470" 2) "BMW" 3) "\xe7\x99\xbd\xe8\x89\xb2"
【7】获取字段数量
-
语法
powershellHLEN key -
用法
powershellHLEN car # 返回 (integer) 3
(四) 列表类型
- 列表类型(list)可以存储一个有序的字符串列表,常用的操作是向列表两端添加元素,或者获取列表的某一个片段。
- 列表类型内部是使用双向链表(double linkedlist)实现的,所以向列表两端添加元素的时间复杂度为O(1),获取的元素越接近两端速度就越快。这意味着即使是一个有几千万个元素的列表,获取头部或尾部的10条记录也是极快的(和从只有20个元素的列表中获取头部或尾部的10条记录的速度是一样的)。
- 不过使用链表的代价是通过索引访问元素比较慢,因为如果向访问第500个元素,需要从第一个元素开始找,一直找到第500
- 与哈希类型键最多能容纳的字段数量相同,一个列表类型键最多能容纳2^32 - 1个元素。
【1】向列表两端增加元素
-
语法
powershell# 向列表左边添加元素(key 不存在时会自动创建) LPUSH key value [value ...] # 向列表右边添加元素 RPUSH key value [value ...] -
使用
powershell# 向列表左边添加元素 LPUSH numbers 1 # 返回 (integer) 1 # 向列表左边添加元素,注意顺序 LPUSH numbers 0 -1 # 返回 (integer) 3 # 此时列表为:[-1 0 1] # 向列表右边添加两个元素 RPUSH numbers 2 3 # 返回 (integer) 5 # 此时列表为:[-1 0 1 2 3]
【2】从列表两端弹出元素
-
如果想把列表当作栈,则搭配使用LPUSH和LPOP,或者搭配使用RPUSH和RPOP;
-
如果想把列表当作队列,则搭配使用LPUSH和RPOP,或者搭配使用RPUSH和LPOP。
-
语法
powershell# 列表左边弹出元素 LPOP key # 列表右边弹出元素 RPOP key -
使用
powershell# 初始列表为:[-1 0 1 2 3] LPOP numbers # 返回 -1 RPOP numbers # 返回 3 # 此时列表为:[0 1 2]
【3】获取列表中元素的个数
-
语法
powershellLLEN key -
使用
powershellLLEN numbers # 返回 (integer) 3 # 键不存在 LLEN aabbcc # 返回 (integer) 0
【4】获取列表片段
-
LRANGE命令将返回索引从start到stop之间的所有元素(包含两端的元素)。与大多数人的直觉相同,Redis的列表起始索引为0
-
语法
powershellLRANGE key start stop -
使用
powershell# 初始列表为:[0 1 2] LRANGE numbers 0 2 # 返回 1) "0" 2) "1" 3) "2" -
LRANGE命令也支持负索引,表示从右边开始计算序数,如"-1"表示最右边第一个元素,"-2"表示最右边第二个元素,依次类推
powershellLRANGE numbers -2 -1 # 返回 1) "1" 2) "2" -
获取列表中的所有元素
powershellLRANGE numbers 0 -1 # 返回 1) "0" 2) "1" 3) "2"
【5】删除列表中指定的值
-
LREM命令会删除列表中前 count个值为value的元素,返回值是实际删除的元素个数。根据 count值的不同,LREM命令的执行方式会略有差异。
- 当count>0时,LREM命令会从列表左边开始删除前count个值为value的元素。
- 当count<0时,LREM命令会从列表右边开始删除前 count 个值为value的元素。
- 当count=0时,LREM命令会删除所有值为value的元素。
-
语法
powershellLREM key count value -
使用
powershell# 初始列表为:0 1 2 0 1 2 0 1 2 # 删除所有值为 1 的元素 LREM numbers 0 1 # 返回 (integer) 3 # 列表为:0 2 0 2 0 2 # 删除 1 个 2 LREM numbers 1 2 # 返回:(integer) 1 # 列表为:0 0 2 0 2 # 从右边开始删除两个0 LREM numbers -2 0 # 返回:(integer) 2 # 列表为:0 2 2
【6】获取/设置指定索引的元素值
-
索引从 0 开始。如果索引为负数,则表示从右边开始计算,最右边元素的索引是 -1。
-
语法
powershell# 获取指定位置的元素值 LINDEX key index # 设置指定位置的元素值 LSET key index value -
使用
powershellLINDEX numbers 1 # 返回 2 # 获取一个不存在的索引 LINDEX numbers 100 # 返回 (nil)powershell# 设置元素值 LSET numbers 1 7 # 返回 OK # 给一个不存在的索引设置值 LSET numbers 100 3 # 返回 (error) ERR index out of range
【7】只保留列表指定片段
-
LTRIM 命令可以删除指定索引范围之外的所有元素。LTRIM 也支持负索引,表示从右边开始计算序数。
-
语法
powershellLTRIM key start end -
使用
powershell# 此时列表为[-2 -1 0 1 2 3 4 5] # 一个都没删 LTRIM 0 -1 # 返回 OK # 查看 LRANGE numbers 0 -1 # 1~3 不删 LTRIM numbers 1 3 # 返回 OK 此时列表为 [-1 0 1] -
LTRIM命令常和LPUSH命令一起使用来限制列表中元素的数量,例如记录日志时我们希望只保留最近的100条日志,则每次加入新元素时调用一次LTRIM命令即可
powershellLPUSH logs $newLog PTRIM logs 0 99
【8】向列表中插入元素
-
LINSERT命令首先会在列表中从左到右查找值为pivot的元素,然后根据第二个参数是BEFORE还是AFTER来决定将value插入该元素的前面还是后面。
-
LINSERT命令的返回值是插入后列表的元素个数。
-
语法
powershellLINSERT key BEFORE|AFTER pivot value -
使用
powershell# 此时 numbers 值为 [-1 0 1] # 找到numbers 中值为 1 的数的位置,在其后插入值 3 LINSERT numbers AFTER 1 3 # 返回 (integer) 4 此时列表为 [-1 0 1 3]
【9】将元素从一个列表转移到另一个列表
-
RPOPLPUSH命令会先从source列表类型键的右边弹出一个元素,然后将其加入destination列表类型键的左边,并返回这个元素的值,整个过程是原子的。
-
语法
powershellRPOPLPUSH source destination -
使用
powershell# 此时列表为 [-1 0 1 3] RPOPLPUSH numbers numbers1 # 返回 3 # 现在的 numbers 列表为 [-1 0 1] # 现在的 numbers1 列表为 [3]
(五) 集合类型
-
集合(Set)中的每个元素都是不同的,且没有顺序。一个集合类型(set)键可以存储至多2^32-1个字符串。
-
集合和列表的对比
对比项 集合类型 列表 存储内容 至多2^32-1个字符串 至多2^32-1个字符串 有序性 否 是 唯一性 是 否 -
集合类型的常用操作是向集合中增加或删除元素、判断某个元素是否存在等,由于集合类型在Redis内部是使用值为空的哈希表(hash table)实现的,因此这些操作的时间复杂度都是O(1)。最方便的是多个集合类型键之间还可以进行并、交和差运算。
【1】增加/ 删除元素
-
SADD命令用来向集合中增加一个或多个元素,如果键不存在则会自动创建。因为在一个集合中不能有相同的元素,所以如果要加入的元素已经存在于集合中就会忽略这个元素。此命令的返回值是增加成功的元素个数(忽略的元素不计算在内)。
-
SREM命令用来从集合中删除一个或多个元素,并返回删除成功的元素个数
-
语法
powershellSADD key member [member ...] SREM key member [member ...] -
使用
powershell# 添加多个元素 SADD letters a b c # 返回 (integer) 3 # 添加已经存在的元素 SADD letters c # 返回 (integer) 0powershell# d 元素不存在 SREM letters a d # 返回 (integer) 1
【2】获取集合中的所有元素
-
语法
powershellSMEMBERS KEY -
使用
powershellSMEMBERS letters # 返回 1) "b" 2) "c"
【3】判断元素是否在集合中
-
判断一个元素是否在集合中是一个时间复杂度为O(1)的操作,无论集合中有多少个元素,SISMEMBER命令始终可以极快地返回结果。
-
当值存在时SISMEMBER命令返回1,当值不存在或键不存在时返回0,
-
语法
powershellSISMEMBER key member -
使用
powershellSISMEMBER letters b # 返回 (integer) 1 SISMEMBER letters e # 返回 (integer) 0
【4】集合间运算
-
语法
powershell# 差集 SDIFF key [key ...] # 交集 SINTER key [key ...] # 并集 SUNION key [key ...] -
使用
powershell# 创建两个集合 SADD setA 1 2 3 SADD setB 2 3 4 # 差集 SDIFF setA setB # 返回 1) "1" # 交集 SINTER setA setB # 返回 1) "2" 2) "3" # 并集 SUNION setA setB # 返回 1) "1" 2) "2" 3) "3" 4) "4"
【5】获取集合元素个数
-
语法
powershellSCARD key -
使用
powershellSCARD letters # 返回 (integer) 2
【6】对集合运算结果进行存储
-
SDIFFSTORE命令和SDIFF命令功能一样,唯一的区别就是前者不会直接返回运算结果,而是将结果存储在destination键中。
-
SDIFFSTORE命令常用于需要进行多步集合运算的场景中,如需要先计算差集再将结果和其他键计算交集。
-
语法
powershell# 差集 SDIFFSTORE destination key [key ...] # 交集 SINTERSTORE destination key [key ...] # 并集 SUNIONSTORE destination key [key ...]
【7】随机获取集合中的元素
-
可以传递 count 参数来一次随机获取多个元素,根据 count 的正负性不同,具体表现也不同。
-
当 count > 0 时,SRANDMEMBER会随机从集合里获取 count 个不重复的元素。如果 count 的值大于集合中的元素个数,则 SRANDMEMBER 会返回集合中的全部元素。
-
当 count < 0 时,SRANDMEMBER会随机从集合里获取 count 个元素,这些元素有可能相同。
-
并不是真随机(出现的概率并不一样,原因是集合类型采用哈希表存储)
-
语法
powershellSRANDMEMBER key [count] -
使用
powershell# 此时集合中的元素为 [a b c d] # 获取一个随机元素 SRANDMEMBER letters # 返回 b # 随机获取两个随机元素 SRANDMEMBER letters 2 # 返回 1) "b" 2) "c"
【8】从集合中弹出一个元素
-
因为集合类型的元素是无序的,所以 SPOP 命令会从集合中随机选择一个元素弹出。
-
语法
powershellSPOP key -
使用
powershell# 此时集合为 [a b c d ] SPOP letters # 返回 b SMEMBERS letters # 此时集合为 [a c d ]
(六) 有序集合类型
- 在集合类型的基础上有序集合类型(sorted set)为集合中的每个元素都关联了一个分数,这使得我们不仅可以完成插入、删除和判断元素是否存在等集合类型支持的操作,还能够获得分数最高(或最低)的前N个元素、获得指定分数范围内的元素等与分数有关的操作。虽然集合中每个元素都是不同的,但是它们的分数却可以相同。
【1】有序集合类型和列表类型
- 相似点
- 二者都是有序的
- 二者都可以获得某一范围得元素
- 区别
-
(1) 列表类型是通过链表实现的,获取靠近两端的数据速度极快,而当元素增多后,访问中间数据的速度会较慢,所以它更加适合实现如"新鲜事"或"日志"这样很少访问中间元素的应用。
-
(2) 有序集合类型是使用散列表和跳跃表(Skiplist)实现的,所以即使读取位于中间部分的数据速度也很快(时间复杂度是O(log(N)))。
-
(3) 列表中不能简单地调整某个元素的位置,但是有序集合可以(通过更改这个元素的分数)。
-
(4)有序集合要比列表类型更耗费内存。
-
【2】增加元素
-
ZADD命令用来向有序集合中加入一个元素和该元素的分数,如果该元素已经存在则会用新的分数替换原有的分数。ZADD命令的返回值是新加入到集合中的元素个数(不包含之前已经存在的元素)。
-
分数可以是整数、小数、双精度浮点数 (+inf 和 -inf 表示正负无穷)
-
语法
pythonZADD key score member [score member ...] -
使用
powershell# 记录三个人的分数 ZADD scoreboard 89 Tom 67 Peter 100 David # 返回 (integer) 3 # 修改 Peter 的分数 ZADD scoreboard 76 Peter # 返回 (integer) 0 # 无穷大的数 ZADD testboard +inf c
【3】获取元素的分数
-
语法
powershellZSCORE key member -
使用
powershellZSCORE scoreboard Peter # 返回 76 ZSCORE testboard c # 返回 inf
【4】获取排名在某个范围的元素列表
-
ZRANGE 命令会按照元素分数从小到大的顺序返回索引从 start 到 stop 之间的所有元素(包含两端的元素)。
-
ZRANGE 命令与 LRANGE 命令十分相似,如索引都是从0开始,负数代表从后向前查找(-1表示最后一个元素)。
-
如果需要同时获得元素的分数的话可以在ZRANGE 命令的尾部加上WITHSCORES参数
-
ZREVRANGE 命令和 ZRANGE 的唯一不同在于 ZREVRANGE 命令是按照元素分数从大到小的顺序给出结果的。
-
如果两个元素的分数相同,Redis会按照字典顺序(即"O"<"9"<"A"<"Z"<"a"<"z"这样的顺序)来进行排列。
-
语法
powershellZRANGE key start stop [WITHSCORES] ZREVRANGE key start stop [WITHSCORES] -
使用:
powershellZRANGE scoreboard 0 2 # 返回 1) "Peter" 2) "Tom" 3) "David" ZRANGE scoreboard 1 -1 # 返回 1) "Tom" 2) "David" # 获取全部数据和他们的分数 ZRANGE scoreboard 0 -1 WITHSCORES # 返回 1) "Peter" 2) "76" 3) "Tom" 4) "89" 5) "David" 6) "100"
【5】获取指定分数范围的元素
-
该命令按照元素分数从小到大的顺序返回分数在min和max之间(包含min和max)的元素。
-
如果希望分数范围不包含端点值,可以在分数前加上
(符号。 -
min和max还支持无穷大,同ZADD命令一样,-inf 和 +inf 分别表示负无穷和正无穷。
-
如果需要同时获得元素的分数的话可以在ZRANGE 命令的尾部加上WITHSCORES参数
-
LIMIT offset count与SQL中的用法基本相同,即在获得的元素列表的基础上向后偏移 offset 个元素,并且只获取前 count个元素。
-
语法
powershellZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count] ZREVRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count] -
使用
powershell# 获取分数在 80~100 之间的数据 ZRANGEBYSCORE scoreboard 80 100 # 返回 1) "Tom" 2) "David" # 获取分数在 80~100 之间的数据,不包含 100 ZRANGEBYSCORE scoreboard 80 (100 # 返回 1) "Tom" # 获取分数大于 80 的数据,不包含 80 ZRANGEBYSCORE scoreboard (80 +inf # 返回 1) "Tom" 2) "David" # 向 scoreboard 再加几个数据 ZADD scoreboard 56 Jerry 92 Wendy 67 Ynonne # 获取分数高于 60 分的从第二个人开始的3个人 ZRANGEBYSCORE scoreboard 60 +inf LIMIT 1 3 # 返回 1) "Peter" 2) "Tom" 3) "Wendy"
(七) 流类型
- 流类型(stream)是Redis5.0推出的新的数据类型。这个类型的推出是作为列表、有序列表以及"发布/订阅"模式的补充。也正因如此,流类型或多或少地带有一些列表、有序列表和"发布/订阅"模式的特性,同时又有一些不同的地方。
- 流类型与列表类型的相同点是都可以在列表(或流)的末尾追加内容,流类型与列表类型的不同点如下
- 列表类型可以在头部和中间插入内容,而日志没有类似的需求,所以流类型也只支持在末尾追加内容。不过流类型比列表类型强大的是,在插入一个新条目时可以自动为其生成一个在流中的唯一ID(类似于日志的行号)。这个ID可以用来进行查询等操作。
- 列表类型的每个条目只能是一个字符串。类似的还有哈希类型的字段值和有序集合类型的值,它们也都只能是字符串。而流类型的每个条目都可以是若干键值对,可以方便我们结构化地存储日志的详情。
- 此外,流类型的另一个重要用途是作为消息中间件使用。
【1】增加条目
-
作为唯一 一个用来向流中增加条目的命令,XADD命令可以分成两部分:第一部分用来向流中插入新条目,第二部分(下面命令定义中
MAXLEN所在的指令组)类似LTRIM命令,用来要求流最多只保持指定数量的条目。其中,第二部分是可选的。 -
语法
*|ID这个参数的含义是新增加的条目的主键,在绝大多数时候,我们只需要Redis帮我们按照上面的规则自动生成一个就可以了,此时用*代替具体的ID,然后根据返回值就可以知道自动生成的ID是什么了。- 在一些很特殊的场景下,用户可能会需要指定ID。这种需求的出现大多是因为系统中存在多个组件(如 Redis和MySQL),用户希望Redis和MySQL对于同样的条目的ID是相同的。不过需要注意的是,因为流类型只支持在末尾追加,所有的ID都是单调递增的,所以如果指定的ID小于或等于流中最后一个条目的ID时,Redis就会报错。
powershellXADD key [MAXLEN [=|~] threshold] *|ID field value [field value ...] # 返回 条目ID,格式如下:时间戳-序列号 <millisecondsTime>-<sequenceNumber> -
使用
powershell# 添加条目,这里的 * 就是参数 * 用于说明 id 由 redis 生成 # key 是 nginxLogs,值 XADD nginxLogs * IP 127.0.0.1 status 200 # 返回 "1777298886540-0" # 最多保存100个条目 XADD demo-incr MAXLEN 100 * f v # 不精确的保存100个条目,可以多一些,性能比精确的高一些 XADD demo-incr MAXLEN ~ 100 * f v
【2】根据ID来按范围查询条目
-
XRANGE命令提供根据两个条目ID来查找它们之间的条目列表的方法。因为条目ID是由时间戳组成的,所以这条命令可以让我们查询某个时间范围内的条目列表。
-
语法
powershellXRANGE key start end [COUNT count] #根据反向ID 按范围查询条目 XREVRANGE key end start [COUNT count] -
使用
powershellXRANGE nginxLogs 1777298886540-0 1777299264887-0 # 返回数据 1) 1) "1777298886540-0" 2) 1) "IP" 2) "127.0.0.1" 3) "status" 4) "200" 2) 1) "1777299257696-0" 2) 1) "IP" 2) "127.0.0.2" 3) "status" 4) "201" 3) 1) "1777299264887-0" 2) 1) "IP" 2) "127.0.0.3" 3) "status" 4) "202" # 可以只提供时间戳,而不提供序号,这样可以返回两个时间戳之间的所有条目 XRANGE nginxLogs 1777298886540 1777299264887 # 获取流的所有条目 XRANGE nginxLogs - + # 获取流的所有条目,但只返回 1 个 XRANGE nginxLogs - + COUNT 1
【3】删除指定元素
-
XDEL命令可以根据指定的ID来删除流中的某些元素,并返回被删除的元素的个数,即除去本来就不在流中的元素的数量。
-
语法
powershellXDEL key ID [ID...] -
使用
powershellXDEL nginxLogs 1777298886540 # 返回 (integer) 1
【4】裁剪流
-
XTRIM命令相当于把XADD中的裁剪功能提取出来了,所以用法也和XADD的MAXLEN参数相同,返回值是被删除的条目的数量。
-
语法
powershellXTRIM key MAXLEN [=|~] threshold -
使用
powershell# 先添加几个条目 XADD test-trim * a 1 # 返回 1777300042545-0 XADD test-trim * a 2 # 返回 1777300079995-0 XADD test-trim * a 3 # 返回 1777300093444-0 # 裁剪 XTRIM test-trim MAXLEN 2 # 返回 (integer) 1 # 剩余 XRANGE test-trim - + 1) 1) "1777300079995-0" 2) 1) "a" 2) "2" 2) 1) "1777300093444-0" 2) 1) "a" 2) "3"
【5】获取流长度
-
语法
powershellXLEN key -
使用
powershellXLEN test-trim # 返回 (integer) 2
三、进阶
(一) 事务
- Redis中的事务(transaction)是一组命令的集合。事务同命令一样都是Redis的最小执行单位,一个事务中的命令要么都执行,要么都不执行。事务的应用非常普遍,例如银行转账过程中A给B汇款,首先系统从A的账户中将钱划走,然后向B的账户增加相应的金额。这两个步骤必须属于同一个事务,要么全执行,要么全不执行。否则只执行第一步会导致钱凭空消失,这显然让人无法接受。
【1】用法
-
Redis保证一个事务中的所有命令要么都执行,要么都不执行。如果在发送EXEC命令前客户端断线了,则Redis会清空事务队列,事务中的所有命令都不会执行。而一旦客户端发送了EXEC命令,所有的命令就都会被执行,即使此后客户端断线也没关系,因为Redis中已经记录了所有要执行的命令。
-
除此之外,Redis的事务还能保证一个事务内的命令依次执行而不被其他命令插入。试想客户端A需要执行几条命令,同时客户端B发送了一条命令,如果不使用事务,则客户端B的命令可能会插入客户端A的几条命令中间执行。如果不希望发生这种情况,也可以使用事务。
powershell# 开始事务 MULTI # 返回 OK # 命令1 SADD number1 1 # 返回 QUEUED # 命令2 SADD number2 1 # 返回 QUEUED # 执行事务 EXEC # 返回 # 1) (integer) 1 # 2) (integer) 1
【2】错误处理
- Redis 在事务报错后是没有回滚的功能的
1) 语法错误
-
语法错误指命令不存在或者命令参数的个数不对。
-
跟在MULTI命令后执行了3条命令:一条是正确的命令,其成功地加入事务队列;其余两条命令都有语法错误。而只要有一条命令有语法错误,执行EXEC命令后 Redis就会直接返回错误消息,即使语法正确的命令也不会执行。
-
Redis 2.6.5 之前的版本会忽略有语法错误的命令,然后执行食物中其他语法中期的命令。也就是下面的命令执行
EXEC时,第一个命令会被执行。powershellMULTI # OK SET key value # QUEUED SET key # (error) ERR wrong number of arguments for 'set' command ERRORCOMMAND KEY # (error) ERR unknown command 'ERRORCOMMAND', with args beginning with: 'key' EXEC # (error) EXECABORT Transaction discarded because of previous errors.
2) 运行错误
-
运行错误指在执行命令时出现的错误,例如使用哈希类型的命令操作集合类型键,这种错误在实际执行之前Redis是无法发现的,所以在事务里这样的命令是会被Redis接受并执行的。如果事务里的一条命令出现了运行错误,事务里其他的命令依然会继续执行(包括出错命令之后的命令)
powershellMULTI # OK SET key 1 # QUEUED SADD key 2 # QUEUED SET key 3 # QUEUED EXEC # 返回 # 1) OK # 2) (error) WRONGTYPE Operation against a key holding the wrong kind of value # 3) OK
【3】WATCH 命令
-
WATCH 的核心作用就是把某些 key 加上"乐观锁"监控,只有这些 key 在提交前没被别人改过,事务才会执行。
-
WATCH 是乐观锁,不阻塞别人写;它是"先放行,提交时检查有没有冲突"。
-
事务失败后,业务代码通常要做重试(重新 WATCH -> GET -> MULTI -> EXEC)。
-
在 Redis 里它通常和 MULTI/EXEC 一起用,流程是:
- WATCH key:先监控 key
- 读取并计算新值(比如 GET 后 +1)
- MULTI 开启事务并入队写命令
- EXEC 提交
- 如果监控期间 key 没变:事务执行成功
- 如果被其他客户端改过:EXEC 返回 nil,事务整批取消(需要重试)
-
下面的例子:如果另一个客户端在你 GET 之后把 counter 改成了 20,那么你的 EXEC 会失败(返回 nil),避免把 20 覆盖成 11。
powershellWATCH counter GET counter # 假设返回 10 MULTI SET counter 11 EXEC # 如果期间没人改 counter,则成功;有人修改返回 (nil)
【4】UNWATCH 命令
-
当你执行了 WATCH key1 key2 后,Redis 会在当前客户端连接上记录这些监控。
-
如果你后来决定"不提交这个事务了"或"要换一批 key 重新监控",就可以执行:
UNWATCH;执行后,这个连接上的监控全部清空,后续 EXEC 不再受之前 WATCH 的影响。 -
UNWATCH 主要用于:在 EXEC 之前主动取消监控。因为EXEC 不管成功还是失败,都会结束当前这次监控。
-
第一次尝试监控 a, 然后放弃,改为监控 b 后再提交事务。
powershellWATCH a GET a UNWATCH WATCH b MULTI SET b 100 EXEC
(二) 过期时间
- 在实际的开发中,我们经常会遇到一些有时效性的数据,如限时优惠活动、缓存或验证码等,过了一定的时间就需要删除这些数据。在关系数据库中,一般需要用一个额外的字段记录过期时间,然后定期检测并删除过期数据。而在Redis中可以使用EXPIRE命令设置一个键的过期时间,到期后Redis会自动删除它。
【1】设置过期时间
-
语法
- seconde 表示过期的时间,单位是秒
- seconds 参数必须是整数,所以最小单位是1秒
- 如果想要更精确地控制键的过期时间,应该使用PEXPIRE命令,PEXPIRE命令与EXPIRE的唯一区别是前者的时间单位是毫秒
powershell# 设置过期时间 EXPIRE key seconde # 还剩多久被删除 TTL keypowershell# 以毫秒来设置时间 PEXPIRE key millisecond # 查看剩余的时间 PTTL key -
使用
powershell# 设置 SET session 123 # 获取 GET session # 返回 123 # 设置15秒后过期 EXPIRE session 15 # 返回 (integer) 1 表示设置成功 # 返回 (integer) 0 表示键不存在或设置失败 TTL session # 返回 (integer) 5 # 15 秒后 GET session # (nil) # 15秒后,返回 -2 表示键不存在 TTL session # 返回 (integer) -2 # key 没有设置过期时间 SET cookie 123 TTL cookie # 返回 (integer) -1
【2】清除过期时间
-
语法
- 除了
PERSIST外,SET或GETSET命令为键赋值时也会同事清理键的过期时间 - 其他只对键值进行操作的命令(如INCR、LPUSH、HSET、ZREM)均不会影响键的过期时间。
powershellPERSIST key - 除了
-
使用
powershellSET foo bar # 设置过期时间 EXPIRE foo 200 # 清除过期时间 PERSIST foo (integer) 1 # 查看多长时间后过期 TTL foo (integer) -1
(三) 排序
【1】SORT 命令
-
可以使用有序集合来实现排序。
-
除了使用有序集合,我们还可以借助Redis提供的SORT命令对列表类型、集合类型和有序集合类型键进行排序,并且可以完成与关系数据库中的连接查询相类似的任务。
-
SORT 默认是按"元素本身"做数值排序,如果想要按字母排序可以使用
ALPHA参数,希望倒叙排序可以使用DESC- key:要排序的列表/集合/有序集合 key
- BY pattern:按外部 key 的值排序(如 user:*->age)
- LIMIT offset count:分页
- GET pattern:返回指定模式对应的值(可写多个)
- ASC | DESC:升序 / 降序(默认 ASC)
- ALPHA:按字符串排序(不是按数字)
- STORE destination:将结果保存到新 key,不直接返回
powershellSORT key [BY pattern] [LIMIT offset count] [GET pattern [GET pattern ...]] [ASC | DESC] [ALPHA] [STORE destination]
1) 列表类型
powershell
LPUSH mylist 4 2 6 1 3 7
# 查看此时的排序
LRANGE mylist 0 -1
# 返回
# 1) "7"
# 2) "3"
# 3) "1"
# 4) "6"
# 5) "2"
# 6) "4"
SORT mylist
# 返回
# 1) "1"
# 2) "2"
# 3) "3"
# 4) "4"
# 5) "6"
# 6) "7"2) 集合类型
集合类型经常被用于存储对象的ID,其在很多情况下都是整数。所以Redis对这种情况进行了特殊的优化,元素的排列是有序的。
powershell
SADD members 5 4 8 7 9
# 获取集合类型
SMEMBERS members
# 返回
# 1) "4"
# 2) "5"
# 3) "7"
# 4) "8"
# 5) "9"
SORT members
# 结果和上边一样3) 有序集合类型
-
在对有序集合类型排序时,会忽略元素的分数,只针对元素自身的值进行排序。
-
ZADD myzset 20 c 10 b 5 d 15 a添加一个有序列表,然后使用SORT myzset会报错(error) ERR One or more scores can't be converted into double,原因是 SORT 默认按"元素本身"做数值排序,元素是 c b d a(字符串),不能转成数字,如果想用 SORT 按字母排成员,可以用SORT myzset ALPHApowershell# 注意语法:第一个值是score 第二个才是 key ZADD myzset 50 2 40 3 20 1 60 5 # 查看此时的排序 ZRANGE myzset 0 -1 # 返回 # 1) "1" # 2) "3" # 3) "2" # 4) "5" sort myzset # 返回 # 1) "1" # 2) "2" # 3) "3" # 4) "5"
4)注意点
- SORT命令是Redis中最强大最复杂的命令之一,如果使用不好很容易造成性能瓶颈。SORT命令的时间复杂度是O(+mlogm),其中n表示要排序的列表(集合或有序集合)中的元素个数,m表示要返回的元素个数。当n较大的时候SORT命令的性能相对较低,并且Redis在排序前会建立一个大小为n的容器来存储待排序的元素。虽然这是一个临时的过程,但如果同时进行较多的大数据量排序操作则会严重影响性能。所以在开发中使用SORT命令时,需要注意以下几点。
- (1)尽可能减少待排序键中的元素个数(使n尽可能小)。
- (2)使用LIMIT参数只获取需要的数据(使m尽可能小)。
- (3)如果要排序的数据数量较大,尽可能使用STORE参数将结果缓存。
【2】BY 参数
-
很多情况下,列表(或集合、有序集合)中存储的元素值代表的是对象的ID(如标签集合中存储的是文章对象的ID),单纯对这些ID自身排序有时意义并不大。更多的时候我们希望根据ID对应的对象的某个属性进行排序。
-
BY 不是独立命令,它是 SORT 的一个子参数。
-
BY参数的语法为BY参考键。其中,参考键可以是字符串类型键或者是哈希类型键的某个字段(表示为键名->字段名)。如果提供了BY参数,SORT命令将不再依据元素自身的值进行排序,而是对每个元素使用元素的值替换参考键中的第一个"*"并获取其值,然后依据该值对元素排序。
powershellSORT key [BY pattern] [LIMIT offset count] [GET pattern [GET pattern ...]] [ASC | DESC] [ALPHA] [STORE destination] -
例子
powershellSADD user_ids 1 2 3 HSET user:1 name "Tom" age 30 HSET user:2 name "Alice" age 20 HSET user:3 name "Bob" age 25 # 按 age 进行排序 # BY user:*->age 里的 * 会替换成集合中的元素(1/2/3) SORT user_ids BY user:*->age # 返回 # 1) "2" # 2) "3" # 3) "1" # 名字也返回出来 SORT user_ids BY user:*->age GET user:*->name GET user:*->age # 返回 # 1) "Alice" # 2) "20" # 3) "Bob" # 4) "25" # 5) "Tom" # 6) "30" -
元素参考值相同时,SORT 命令会再比较元素本身的值来确定元素的顺序。
-
如果某个元素的参考键不存在时,会默认参考键的值为 0
powershellLPUSH sortbylist 2 1 3 4 5 SET iemscore:1 50 SET itemscore:2 100 SET itemscore:3 -10 # 与iemscore:1的值相同,会比较 "4" 和 "1" SET itemscore:4 50 # 没有itemscore:5 所以认为其值为0 SORT sortbylist BY itemscore:* DESC # 返回 # 1) "2" # 2) "4" # 3) "5" # 4) "1" # 5) "3"
【3】GET 参数
-
GET 不是独立命令,它是 SORT 的一个子参数。
-
GET参数不影响排序,它的作用是使SORT命令的返回结果不再是元素自身的值,而是GET参数中指定的键值。GET参数的规则和BY参数一样,GET参数也支持字符串类型键和哈希类型键,并使用*作为占位符。
powershellSORT key [BY pattern] [LIMIT offset count] [GET pattern [GET pattern ...]] [ASC | DESC] [ALPHA] [STORE destination] -
用例:
powershellDEL user_ids user:1 user:2 user:3 SADD user_ids 1 2 3 HSET user:1 name "Tom" age 30 city "Beijing" HSET user:2 name "Alice" age 20 city "Shanghai" HSET user:3 name "Bob" age 25 city "Shenzhen" # 按年龄排序,并用 GET 取出多个字段 # 获取ID使用 GET # SORT user_ids BY user:*->age GET # GET user:*->name GET user:*->city GET user:*->age # 返回 # 1) "2" # 2) "Alice" # 3) "Shanghai" # 4) "20" # 5) "3" # 6) "Bob" # 7) "Shenzhen" # 8) "25" # 9) "1" # 10) "Tom" # 11) "Beijing" # 12) "30"
【4】STORE 参数
-
默认情况下 SORT命令会直接返回排序结果,如果希望保存排序结果,可以使用STORE参数。
-
保存后的键的类型为列表类型,如果键已经存在则会覆盖它。加上STORE参数后,SORT命令的返回值为结果的个数。
-
用例
powershellDEL nums nums_sorted RPUSH nums 30 5 100 20 # 排序并保持 SORT nums STORE nums_sorted # 返回 (integer) 4 # 查看结果 LRANGE nums_sorted 0 -1 # 返回 # 1) "5" # 2) "20" # 3) "30" # 4) "100"powershellDEL user_ids user:1 user:2 user:3 user_names_sorted SADD user_ids 1 2 3 HSET user:1 name "Tom" age 30 HSET user:2 name "Alice" age 20 HSET user:3 name "Bob" age 25 SORT user_ids BY user:*->age GET user:*->name STORE user_names_sorted # 返回 (integer) 3 LRANGE user_names_sorted 0 -1 # 返回 # 1) "Alice" # 2) "Bob" # 3) "Tom"
(四) 消息通知
【1】任务队列
-
BRPOP 可以理解为:阻塞版的 RPOP。RPOP是当队列没数据就立刻返回 nil,BRPOP队列没数据就"等一会儿"(阻塞),直到有数据或超时
-
timeout 表示阻塞超时,当其为 0 时表示一直阻塞,直到有元素可弹出
-
可以同时监听多个 key(列表),一旦接收到数据,监听任务就结束
powershellBRPOP key [key ...] timeout -
用例:
powershell
# 开始监听(在docker/ 自己的电脑中)
BRPOP task_queue 0
# 打开另一个redis终端(在 redis insight)
# 然后向队列(列表)中 插入两个数据
LPUSH task_queue "order:1001"
# 监听端返回
# 1) "task_queue"
# 2) "order:1001"
# 监听端结束任务(可以在编程中使用死循环来一直进行监听)
# 需要重新监听
# 然后输入
LPUSH task_queue "order:1002"
# 监听端返回
# 1) "task_queue"
# 2) "order:1002
# 监听端结束任务【2】优先级队列
-
BRPOP 命令可以同时接收多个键,并按 key 从左到右选第一个非空队列弹出。
-
所以将优先级高的队列放到左边,优先级低的放右边。一旦监听到左边队列有数据,就会优先处理,即使此时右边队列也有数据。
powershell# 向三个队列(列表)中都添加数据 LPUSH queue:1 task1 LPUSH queue:2 task2 LPUSH queue:3 task3 # 开始监听 BRPOP queue:1 queue:2 queue:3 0 # 返回 # 1) "queue:1" # 2) "task1" BRPOP queue:1 queue:2 queue:3 0 # 返回 # 1) "queue:2" # 2) "task2"
【3】发布/订阅模式
-
"发布/订阅"模式中包含两种角色,分别是发布者和订阅者。订阅者可以订阅一个或若干频道(channel),而发布者可以向指定的频道发送消息,所有订阅此频道的订阅者都会收到此消息。
-
发出去的消息不会被持久化,也就是说当有客户端订阅频道后只能接收到后续发布到该频道的消息,之前发送的就接收不到了。
-
发布(返回订阅者数量)
powershellPUBLISH channel message -
订阅(处于订阅状态的客户端不能使用除 SUBSCRIBE、UNSUBSCRIBE、PSUBSCRIBE和PUNSUBSCRIBE 折个属于"发布/订阅"模式命令之外的命令,否则会报错)
powershellSUBSCRIBE channel [channel ...] -
取消订阅(如果不指定频道会取消订阅过的所有频道)
powershellUNSUBSCRIBE channel [channel ...] -
用例
powershell# 向频道2发布一个消息 PUBLISH channel2 hi # 返回 (integer) 0 # 表示有 0 个订阅者 # 订阅频道2,然后就会等待发布者发布消息 SUBSCRIBE channel2 # 返回:第一个是订阅订购时得反馈信息;第二个是订阅成功的频道名称;第三个是当前客户端订阅的频道数量 # 1) "subscribe" # 2) "channel2" # 3) (integer) 1 # 开启另一个redis-cli 进行消息发布(可以在 redis insight) PUBLISH channel2 hello # 返回 (integer) 1 # 此时订阅者返回 # 1) "message" # 2) "channel2" # 3) "hello" # 可以取消订阅 # 在订阅者的 redis-cli 中输入 UNSUBSCRIBE chanel2 # 返回如下: 第一个值表示成功取消订阅某个频道;第二个值表示频道名称;第三个值是此频道还有几个订阅者 # 1) "unsubscribe" # 2) "channel2" # 3) (integer) 0
【4】按照规则订阅
-
可以使用PSUBSCRIBE命令订阅指定的规则。规则支持glob风格通配符格式。
-
PUNSUBSCRIBE 命令可以退订指定的规则。使用PUNSUBSCRIBE命令只能退订通过PSUBSCRIBE命令订阅的规则,不会影响直接通过SUBSCRIBE命令订阅的频道;同样,UNSUBSCRIBE 命令也不会影响通过PSUBSCRIBE命令订阅的规则。另外,容易出错的一点是,使用PUNSUBSCRIBE命令退订某个规则时不会将其中的通配符展开,而是进行严格的字符串匹配,所以PUNSUBSCRIBE *无法退订 channel.*规则,而是必须使用 PUNSUBSCRIBEchannel.*才能退订.
powershellPUNSUBSCRIBE [pattern[pattern...]]powershell# 订阅以channel 开头的频道 PSUBSCRIBE channel?* # 返回 # 1) "psubscribe" # 2) "channel?*" # 3) (integer) 1 # 在另一个 redis-cli 发送消息 PUBLISH channel2 hi! # 返回 # (integer) 1 # 订阅者会返回 # 1) "pmessage" # 2) "channel?*" # 3) "channel2" # 4) "hi!" # 订阅者取消订阅 PUNSUBSCRIBE # 返回 # 1) "punsubscribe" # 2) "channel?*" # 3) (integer) 0
【5】强大的流
-
流类型除了能高效存储日志结构的数据,还有一个非常重要的用途,即消息中间件。
对比项 列表 发布/订阅 流 保存消息历史 支持 不支持 支持 查询消息历史 支持,但低效 不支持 支持,且高效 一对多消息 不支持 支持 支持 -
XREAD命令的作用是从流中读取数据,
- COUNT 是表示读取多少个条目
- BLOCK表示阻塞多久。如果不提供BLOCK参数,XREAD命令不会阻塞来等待新消息,而是直接返回读取到的结果。
powershellXREAD [COUNT count] [BLOCk millliseconds] STREAMS key [key ...] ID [ID ...] -
XREAD 命令和 XRANGE 命令有以下几点不同。
- (1)XRANGE命令需要指明起止两个端点的条目ID,而XREAD命令只需要指明起始
的ID,并且会直接读取最新的条目(除非指明了COUNT参数)。 - (2)XREAD命令可以支持同时读取多个键的数据。
- (1)XRANGE命令需要指明起止两个端点的条目ID,而XREAD命令只需要指明起始
powershell
# 向 mystream 追加消息,返回消息 ID
XADD mystream * name Alice age 30
# 返回 "1779688416043-0"
XADD mystream * name Bob age 25
# 返回 "1779688444645-0"
XADD mystream * name Carol age 28
# 返回 "1779688460732-0"
# 从头读取
XREAD STREAMS mystream 0
# 返回
# 1) 1) "mystream"
# 2) 1) 1) "1779688416043-0"
# 2) 1) "name"
# 2) "Alice"
# 3) "age"
# 4) "30"
# 2) 1) "1779688444645-0"
# 2) 1) "name"
# 2) "Bob"
# 3) "age"
# 4) "25"
# 3) 1) "1779688460732-0"
# 2) 1) "name"
# 2) "Carol"
# 3) "age"
# 4) "28"
# 1779688416043-0 之后开始读取
XREAD STREAMS mystream 1779688416043-0
# 1) 1) "mystream"
# 2) 1) 1) "1779688444645-0"
# 2) 1) "name"
# 2) "Bob"
# 3) "age"
# 4) "25"
# 2) 1) "1779688460732-0"
# 2) 1) "name"
# 2) "Carol"
# 3) "age"
# 4) "28"
# 最多等 5000ms;只读「此刻之后」新写入的消息
# 注意这里用到了 $ ,表示 只读此刻之后新写入的消息
XREAD BLOCK 5000 STREAMS mystream $【6】流与消费组
-
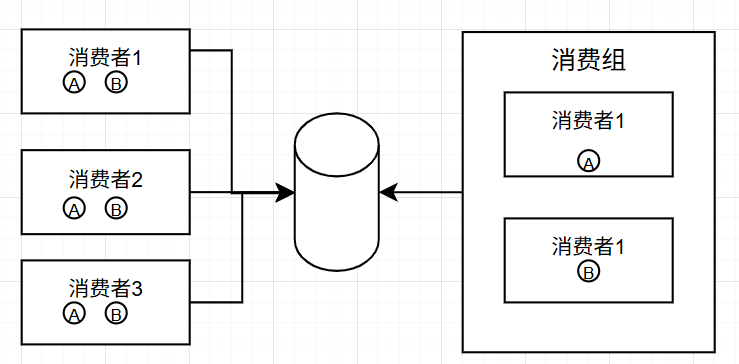
消费组是若干消费者组成的一个组,这个组对外在接收消息时会被当作一个虚拟的消费者。当消费组接收到一条消息时,会将这条消息分发给组内的其中一个消费者,并且会保证对于同一条消息不会发给组内的多个消费者。如下图所示,图中有5个消费者和一个消费组,其中两个消费者在消费组内,A和B分别代表一条消息。
-
语法:
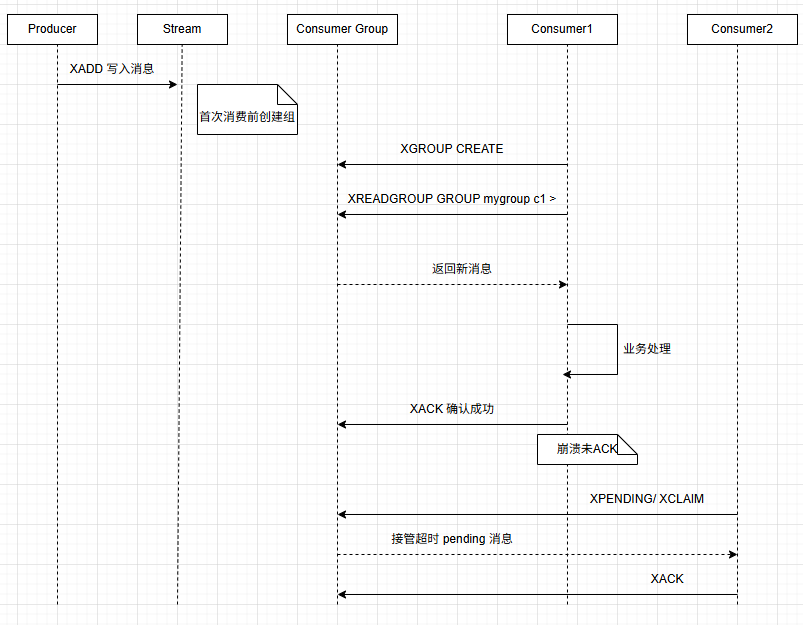
powershell# 创建消费者组 # id:组从哪条消息开始消费 # $:只消费 创建组之后 新写入的消息(常用) # 0 或 0-0:从流 开头 消费历史消息 # 具体 ID:如 1650000000000-0,从该 ID 之后 的消息开始 # MKSTREAM:若 Stream 不存在则自动创建(空流) XGROUP CREATE key groupname id|$ [MKSTREAM] [BUSYGROUP ...]powershell# 组内的消费者读取流 XREADGROUP GROUP group consumer # GROUP + 组名 + 消费者名(组须先用 XGROUP CREATE 创建) [COUNT count] # 每个 Stream 最多 返回条数 [BLOCK milliseconds] # 阻塞等待(毫秒);0 表示无限阻塞(同 XREAD) [CLAIM min-idle-time] # 空闲 ≥ 该毫秒数的 pending 消息可被 认领(仅当 id 为 > 时生效) [NOACK] # 读到的消息 不进 PEL,等同读完即确认(可丢消息) STREAMS key [key ...] id [id ...] # 一个或多个 Stream;每个 key 对应一个 idpowershell# 确认消息已处理(从该组的 PEL(待处理列表) 中移除指定消息,表示 已成功处理。) # key Stream 键名 # group 消费者组名 # id 消息ID,可多个 XACK key group id [id ...]powershell# 认领别人的 pending 消息 # key Stream 键名 # group 消费者组名 # consumer 新所有者 消费者名(认领后归它处理) # min-idle-time 最小空闲时间(毫秒);只有 idle ≥ 该值的消息才能被认领 # id 要认领的消息 ID,可多个 XCLAIM key group consumer min-idle-time id [id ...] [IDLE ms] # 设置认领后该消息的 idle 时间(默认重置为 0) [TIME unix-time-milliseconds] # 用 Unix 毫秒时间设置 idle(多用于 AOF 重写) [RETRYCOUNT count] # 设置重试计数;不指定则认领时 投递次数 +1 [FORCE] # 即使 ID 不在 PEL 里也强制创建 pending(消息须在 Stream 中仍存在) [JUSTID] # 只返回认领成功的 ID 数组,不返回消息体;且不增加 retry 计数 [LASTID lastid] # 内部/AOF 相关,一般业务少用powershell# 查看处于等待(pending)状态的消息 # key Stream 键名 # group 消费者组名 # IDLE min-idle-time 只返回 idle 超过 该毫秒数的条目(6.2+) # start ID 范围起点(同 XRANGE,可用 -) # end ID 范围终点(可用 +) # count 最多返回条数 # consumer 只查该消费者的 pending XPENDING key group [[IDLE min-idle-time] start end count [consumer]]
-
使用
powershell# 创建名为 mygroup 的消费组 XGROUP CREATE mystream mygroup $ MKSTREAM # 返回 OK # 向 mystream 流中插入两条记录 XADD mystream * mseeage A # 返回 "1779691891159-0" XADD mystream * message B # 返回 "1779691893862-0" # 消费者 consumer1 读取 mystream 流记录 # > 表示一个特殊ID,意思是 "给我还没人领过的新任务"。 XREADGROUP GROUP mygroup consumer1 COUNT 1 STREAMS mystream > # 返回 # 1) 1) "mystream" # 2) 1) 1) "1779691891159-0" # 2) 1) "mseeage" # 2) "A" # 注意:上边的 XREADGROUP 并没有 ACK,此时记录处于等待(Pending)队列 # 消费者 consumer2 读取 mystream 流记录 XREADGROUP GROUP mygroup consumer2 COUNT 1 STREAMS mystream > # 返回 # 1) 1) "mystream" # 2) 1) 1) "1779691893862-0" # 2) 1) "message" # 2) "B" # 查看处于等待(pending)状态的消息 XPENDING mystream mygroup # 返回 # 1) (integer) 2 # 2) "1779691891159-0" # 3) "1779691893862-0" # 4) 1) 1) "consumer1" # 2) "1" # 2) 1) "consumer2" # 2) "1" # 确认 1779691893862-0 消息 XACK mystream mygroup 1779691893862-0 # 返回 (integer) 1 # consumer2 认领 consumer1 的 pending XCLAIM mystream mygroup consumer2 0 1779691891159-0 # 返回 # 1) 1) "1779691891159-0" # 2) 1) "mseeage" # 2) "A" # 确认 1779691891159-0 消息 XACK mystream mygroup 1779691891159-0 # 返回 (integer) 1 # 查看处于 pending 状态的消息 XPENDING mystream mygroup