May 7, 2026,昨天,我刷到 Hugging Face 上一个很离谱的模型: gpt-oss-20b-tq3
它本质上是 OpenAI 开源的 GPT-OSS-20B,被社区重新做了一层 TurboQuant 3bit 极限量化,再配合 Apple Silicon 的 MLX 推理框架优化。
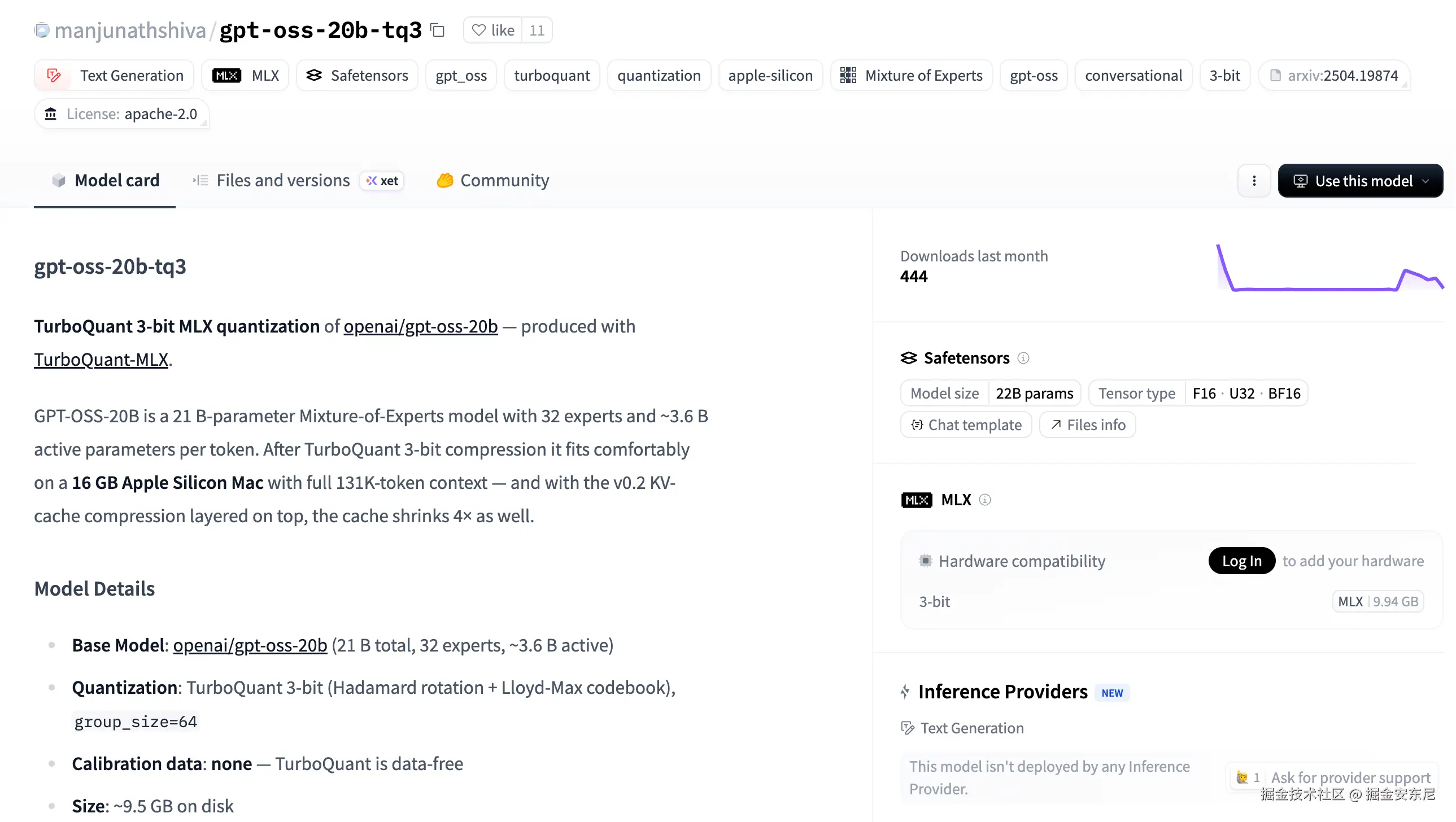
最关键的是:
一个 20B 级别的 MoE 大模型,现在居然能在 16GB MacBook 上本地丝滑跑起来了。
而且是真正能:本地聊天、长上下文问答、写代码、做推理、跑 Agent、做 RAG、长文本生成的那种可用状态。
我是安东尼(tuaran.me),一名专注于前端与 AI 工程化的独立开发者。
我在建设 「博主联盟」------连接AI产品方与技术博主的品牌增长平台,帮AI产品精准触达开发者,也帮博主拿到推广资源与成长机会。
同时也在做 「前端下一步」------一个聚焦前端、AI Agent 与大模型的技术情报站,帮你从技术革新焦虑中解脱,得到技术转向判断。
希望以下的内容对你有所启发。
这模型到底是什么?
先拆一下名字:
GPT-OSS-20B
这是 OpenAI 开源的一个 MoE(Mixture of Experts)模型。
参数结构:
| 项目 | 数值 |
|---|---|
| 总参数量 | 21B |
| Expert 数量 | 32 个 |
| 每次激活参数 | 约 3.6B |
| Context Length | 131K |
重点其实不是"21B"。
而是:
它是 MoE。
什么意思?可能有小白还不是太懂,传统 Dense 模型:
每次推理都全量激活所有参数。
MoE:只会动态调用部分 Expert。
所以:虽然总参数 21B,但每个 token 实际只跑约 3.6B 参数。
这也是它能在消费级设备上跑起来的核心原因。
最猛的是 TurboQuant 3bit
真正让我惊到的是这个:
TurboQuant 3-bit MLX Quantization
简单说:社区把模型压到了 3bit。而且不是传统暴力压缩。
它用了:
- Hadamard Rotation
- Lloyd-Max Codebook
- Data-free Quantization
属于一种非常激进但效果 surprisingly 好的量化方案。
最终结果:
| 项目 | 数据 |
|---|---|
| 模型大小 | 约 9.5GB |
| 推理峰值内存 | 约 11GB |
| 运行设备 | 16GB MacBook |
| 推理速度 | 60~80 tok/s |
| 上下文 | 131K |
你没看错。一个 20B 级别模型。
现在:9.5GB 就能装下。
为什么这件事意义很大?
因为它直接改变了:
「本地大模型」的门槛。
以前:
想跑 20B:
- 4090
- 24GB 显存
- Linux
- CUDA
- 各种折腾
现在:
一台普通 M 系列 MacBook:
- M1
- M2
- M3
- M4
都能直接跑。
而且还是:
- 全离线
- 不联网
- 不订阅
- 不 API
- 不限调用
这意味着:也许本地 AI 开始真正进入"个人电脑时代"。
MLX 生态现在越来越猛了
这里面还有一个关键角色:
MLX
这是苹果专门给 Apple Silicon 做的大模型框架。
核心优势:
- Unified Memory
- Metal GPU 调度
- Apple Silicon 深度优化
- 超低 overhead
所以你会发现:很多模型在 CUDA 上很重。
到了 MLX:突然变得极其轻盈。
现在整个生态已经开始出现:
- MLX-LM
- MLX-VLM
- MLX-Whisper
- TurboQuant-MLX
KV Cache 压缩更离谱
这个模型还有个狠活:
KV Cache Compression
官方给的方案:
css
--kv-k-bits 8
--kv-v-bits 3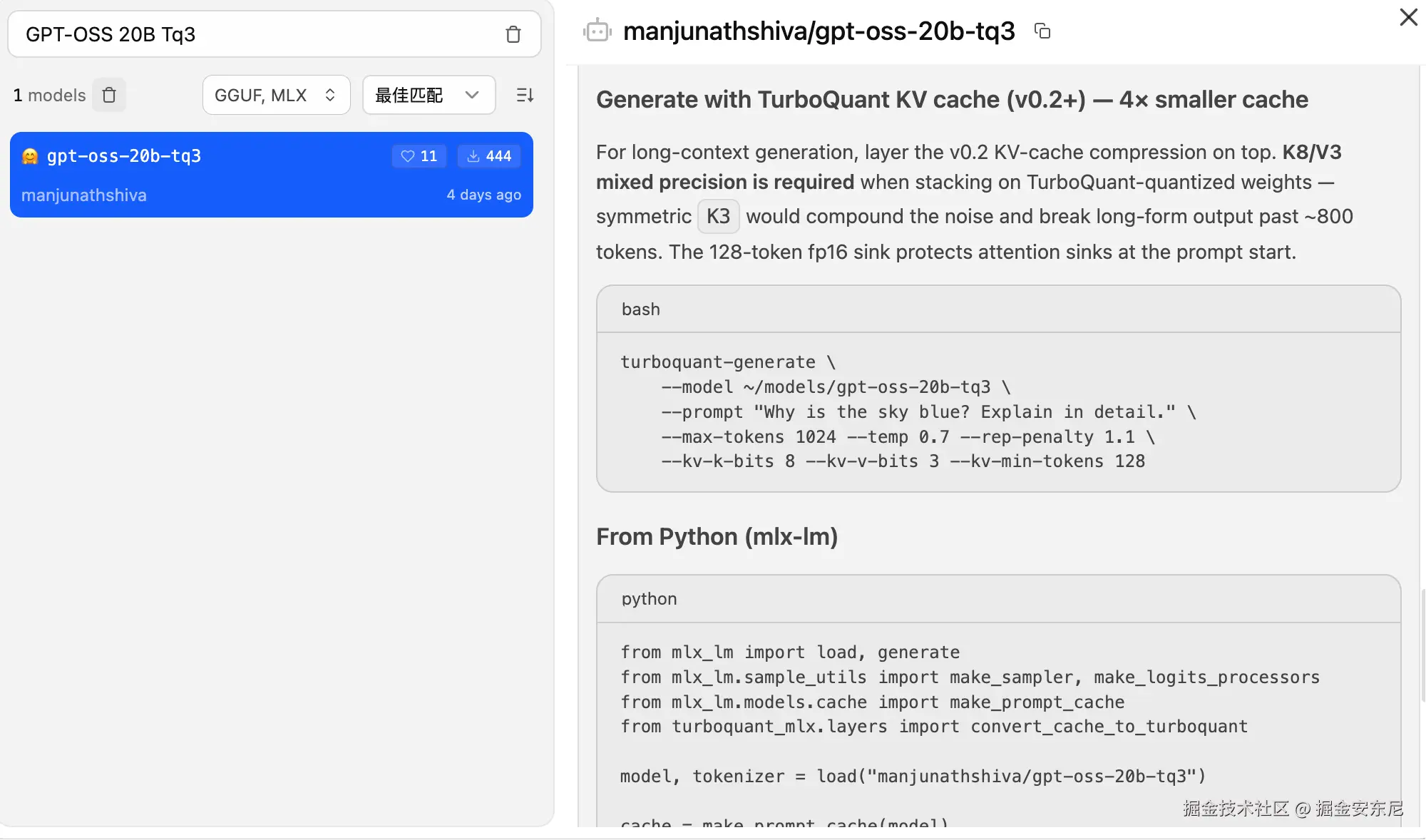
直接把 KV Cache 再压缩 4 倍。
什么意思?大模型真正吃内存的, 很多时候已经不是模型本体。
而是:
长上下文 KV Cache。
上下文越长:缓存越恐怖。现在它直接:
- K Cache → 8bit
- V Cache → 3bit
而且还能维持长文本稳定输出。这其实已经非常接近:
"消费级设备长上下文 Agent Runtime"的方向了。
实测效果怎么样?
我看到,社区做了 6 组压力测试。结果挺稳。
长文生成
1500 字罗马帝国文章:
- 无循环
- 无崩坏
- 无尾部退化
数学推理
低温度:
css
--temp 0.3时效果明显稳定。能正确列方程:
scss
60t + 75(t-0.5) = 215并求出正确结果。
高温度:
css
--temp 0.7会开始"放飞自我"。
这其实也说明:20B 以下模型,推理能力已经很依赖 sampler 策略了。
代码生成
Merge Intervals 这种经典题: 函数逻辑基本正确。
偶尔:
- 单测断言 hallucination
- 边界 case 漏掉
但已经具备:本地 Copilot 的可用水平。
为什么 sampler 很关键?
这个模型官方甚至专门写了建议:
| 场景 | 推荐参数 |
|---|---|
| 聊天 / 创作 | temp 0.7 |
| 数学 / 代码 | temp 0.3 |
这其实很真实。因为:小模型最怕:
推理漂移。
temperature 一高:
它会突然:
- 跳步骤
- 自信胡说
- 逻辑断裂
所以:低温度更容易稳定推理轨迹。
安装其实很简单
安装依赖:
arduino
pip install "turboquant-mlx-full>=0.2.0" "mlx-lm>=0.31.3"下载模型:
bash
hf download manjunathshiva/gpt-oss-20b-tq3 \
--local-dir ~/models/gpt-oss-20b-tq3运行:
lua
turboquant-generate \
--model ~/models/gpt-oss-20b-tq3 \
--prompt "Why is the sky blue?" \
--max-tokens 1024 \
--temp 0.7就结束了。
没有 CUDA。
没有 Docker。
没有折腾驱动。
现在最有意思的是:
大模型开始进入:
「个人长期运行」时代
以前:本地模型更多像 Demo。
现在已经开始变成:
- 本地知识库
- 本地 Agent
- 本地工作流
- 本地长期记忆
- 本地代码助手
- 本地 AI Runtime
尤其 Apple Silicon 这一代:统一内存架构太适合跑 MoE 了。
这件事背后的真正趋势
过去两年:大家都觉得:AI 一定会越来越中心化。越来越依赖:
- 云 GPU
- API
- 大厂订阅
但现在开始出现另一条路线:
小型高质量 MoE + 极限量化 + 本地推理
它未必追求:"世界最强模型"。而是追求:
"个人设备长期可运行的 AI 系统"。
这个方向其实非常像:
- Linux 当年对 Unix
- Ollama 对云 API
- VSCode 对大型 IDE
它不是最贵。但会越来越普及。
最后
我现在越来越觉得:2026 年的大模型竞争,已经不只是"参数大战"。
而是:谁能真正进入个人电脑。
因为:只有进入本地,AI 才能真正变成:
- 长期记忆
- 私有上下文
- 持续工作流
- 个人 Agent Runtime
而 gpt-oss-20b-tq3 这种模型,
已经开始让这件事变得越来越现实了。