
AI 大模型推理:本质是经验推理而非逻辑推理
作者 :wangzhi
日期 :2026-05-07
标签 :AI大模型推理经验推理逻辑推理思维链CoT
摘要
当前主流 AI 大语言模型(LLM)在各类任务中表现出惊人的"推理"能力,但这种能力究竟是严谨的逻辑推理 ,还是基于海量训练数据的经验推理 ?本文从技术结构出发,深入分析大模型推理的本质,并通过两组对照实验------热力图字体修改 与 PPT 幻灯片生成 ------直观揭示大模型面对"修改"与"复刻+修改"两种任务时的巨大表现差异。最终结论是:大模型的推理本质是经验推理,但引入逻辑链(Chain-of-Thought, CoT)可以有效弥补这一不足,使模型更接近逻辑推理的能力边界。
一、AI 大模型推理的技术结构
1.1 Transformer 架构:一切的基础
现代大语言模型几乎都以 Transformer 为核心架构。Transformer 的本质是一个条件概率预测机器 :给定上下文 token 序列 x1,x2,...,xnx_1, x_2, \ldots, x_nx1,x2,...,xn,模型输出下一个 token 的概率分布:
P(xn+1∣x1,x2,...,xn)=Softmax(Transformer(x1,...,xn))P(x_{n+1} \mid x_1, x_2, \ldots, x_n) = \text{Softmax}(\text{Transformer}(x_1, \ldots, x_n))P(xn+1∣x1,x2,...,xn)=Softmax(Transformer(x1,...,xn))
这一过程通过多层**自注意力机制(Self-Attention)**实现,每一层都在全局上下文中重新加权每个位置的表示:
Attention(Q,K,V)=Softmax (QK⊤dk)V\text{Attention}(Q, K, V) = \text{Softmax}\!\left(\frac{QK^\top}{\sqrt{d_k}}\right)VAttention(Q,K,V)=Softmax(dk QK⊤)V
模型并没有内置的逻辑引擎、符号推理器或规则系统,有的只是参数化的统计关联。
1.2 预训练:将世界压缩为参数
大模型的核心能力来自预训练阶段。以 GPT 系列为代表,模型在数万亿 token 的文本语料上做自回归语言建模,目标是最小化预测误差:
L=−∑ilogPθ(xi∣x1,...,xi−1)\mathcal{L} = -\sum_{i} \log P_\theta(x_i \mid x_1, \ldots, x_{i-1})L=−i∑logPθ(xi∣x1,...,xi−1)
在这一过程中,模型并不显式地学习"规则"或"公理",而是学习语言中隐含的统计规律------哪些词常在哪些语境后出现,哪些推理步骤在人类写作中频繁共现。
| 阶段 | 目标 | 学习到的内容 |
|---|---|---|
| 预训练 | 下一个 token 预测 | 语言规律、知识、推理模式 |
| SFT(有监督微调) | 对齐人类指令 | 任务格式、指令跟随 |
| RLHF(人类反馈强化学习) | 对齐人类偏好 | 有用性、无害性 |
1.3 推理过程:自回归解码
推理时,模型通过自回归解码逐 token 生成回答,常见策略包括:
- 贪心解码(Greedy):每步选概率最高的 token
- Beam Search:维护多条候选路径
- 温度采样(Temperature Sampling):引入随机性,控制输出多样性
- Top-p / Top-k 采样:截断低概率 token,防止退化
关键在于:每一步的生成都是基于当前上下文的概率最优选择,而非严格的逻辑推导。模型没有"回溯"、"验证"或"反驳"的机制,它只是在连续地"接龙"。
1.4 大模型"推理"能力的来源
大模型展现出的数学、代码、逻辑等"推理"能力,来自以下几个来源:
- 训练数据中的推理范式 :训练语料包含大量人类书写的推理过程(教材、论文、代码注释),模型学会了模仿这些推理的表面形式。
- Scale(规模效应):参数量和训练数据达到一定规模后,涌现出(emergent)复杂任务的处理能力。
- 上下文学习(In-context Learning):Few-shot 示例让模型在推理时"临时学习"新任务的模式。
- CoT 提示(思维链):通过在 prompt 中加入推理步骤示例,引导模型分步输出,使推理质量大幅提升。
二、为何 AI 大模型推理是经验推理而非逻辑推理
2.1 概念辨析:经验推理 vs. 逻辑推理
| 维度 | 逻辑推理 | 经验推理 |
|---|---|---|
| 依据 | 公理、规则、形式系统 | 历史经验、统计规律 |
| 过程 | 符号变换、严格演绎 | 模式匹配、类比泛化 |
| 可验证性 | 每步可形式化验证 | 结果可观察,过程难以追溯 |
| 错误类型 | 逻辑谬误(可检测) | 分布偏差、幻觉(难以检测) |
| 代表系统 | Prolog、定理证明器 | GPT、Claude、Gemini |
2.2 大模型推理是"经验推理"的五条证据
① 没有符号操作系统
大模型内部没有变量绑定、栈式回溯或约束传播等符号推理机制。它对 x + 2 = 5, x = ? 的"推理",本质是识别出这类题目在训练集中的答案模式,而非真正执行代数求解。
② 对抗性扰动下的脆弱性
逻辑推理系统对形式等价的变换不敏感;而大模型对语义等价但表面不同的问题会给出截然不同的答案。大量研究(如 GSM-Symbolic)表明,在数学题中加入无关的干扰句子,会使模型准确率显著下降------逻辑推理系统对此免疫。
③ 幻觉(Hallucination)现象
大模型会自信地输出虚假的事实、不存在的引用、错误的计算结果。这是典型的经验推理失效:模型根据"这类语境通常接这类内容"的统计经验生成了答案,而不是验证其真实性。
④ 依赖训练数据分布
模型在训练集中高频出现的推理模式上表现优秀,但在超出分布(out-of-distribution)的新问题上迅速退化。逻辑推理系统不存在这种依赖性------它基于规则,不依赖是否"见过"类似的例子。
⑤ 无法自我修正
纯粹的 LLM 推理不具备自我验证能力:它无法判断自己生成的答案是否正确,只能继续按概率分布生成后续内容。逻辑推理系统在每步都可进行形式验证。
2.3 经验推理的天然局限
经验推理在以下场景中尤为脆弱:
- 需要精确操作的任务:如图像编辑、代码精确修改------模型"知道要放大字体",但不能精确计算新坐标、新参数
- 结构化内容生成:如 PPT 布局------模型"知道 PPT 应该长什么样",但无法保证每个元素严格对齐、格式合规
- 反事实推理:超出训练分布的假设场景
- 长链条严格推导:数学证明、复杂算法设计
这两个局限,正是下面两个实验的设计依据。
三、实验设计
实验一:热力图字体修改
实验目的
验证:大模型在面对直接修改已有图像 时(经验推理模式),与先复刻再修改(引入逻辑中间层)时,表现是否存在显著差异。
实验背景
实验素材 :一张热力图,横轴为城市(北京、上海、广州、成都、武汉),纵轴为月份(1--12 月),每个色块内标注具体气温数值。字体较小,难以阅读。
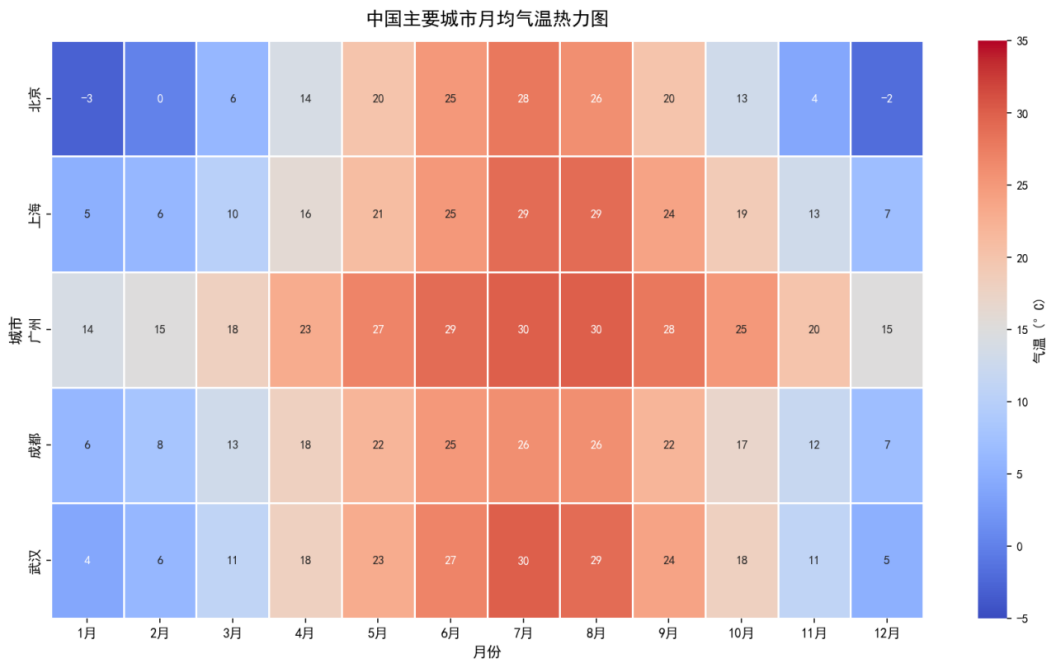
操作要求:将图中所有字体放大。
🔴 方案 A:直接指令修改(经验推理模式)
操作步骤:
将热力图图片直接上传给 AI 大模型,输入提示词:
请将这张热力图中的所有字体放大,包括坐标轴标签、色块内的数值标注和图例文字。预期结果与分析:
大模型在这种模式下本质上无法真正修改图像------它只能调用多模态能力"描述"图片,或生成一段模糊的修改说明。即便模型具备图像生成能力,它也只是根据经验"重新生成一张类似但字体更大的图",而非在原图的数据结构上精确操作。
典型问题:
-
数据失真:色块内的气温数倿可能被改变或错位,未在提示词中加粗字体,字体AI自动加粗
-
例例失调:图像宽高比、字体与色块的比例关系不一致,外围字体放大,热力块字体为未放大
-
色彩偏差:颜色映射(colormap)可能与原图不同,图中颜色变深
根本原因:模型缺乏对图像底层数据结构(如 matplotlib figure 对象、像素坐标)的逻辑操作能力,只能凭经验"猜测"一个看起来合理的输出。
🟢 方案 B:先复刻再修改(引入逻辑中间层)
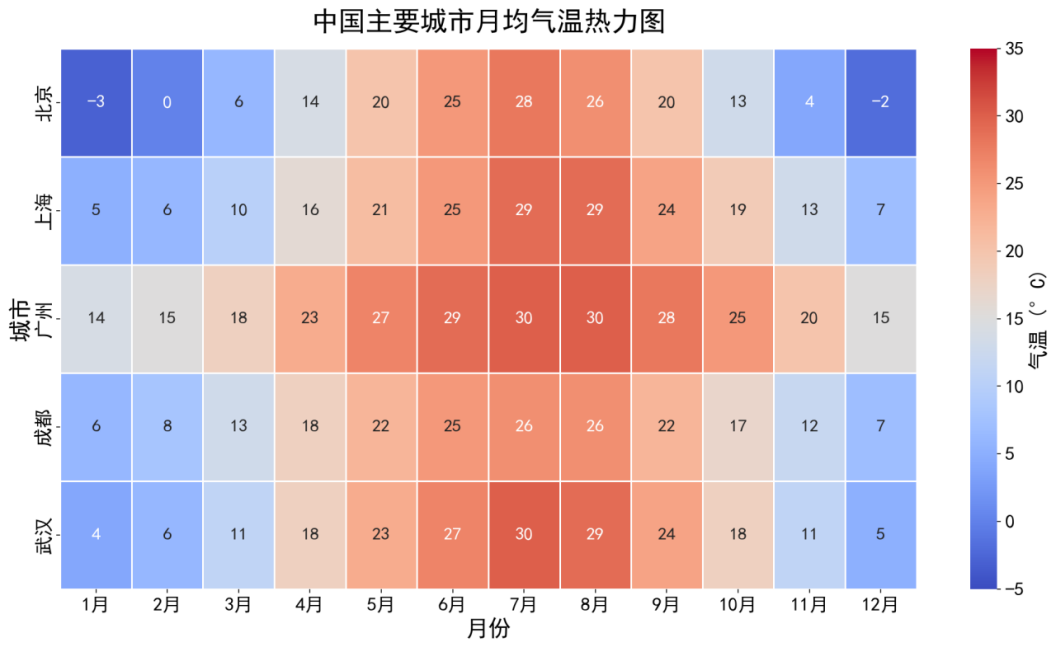
步骤 1:让 AI 大模型用 Python 复刻原始热力图
提示词:
请用 Python(matplotlib + seaborn)复刻这张热力图:
- 横轴:城市(北京、上海、广州、成都、武汉)
- 纵轴:月份(1--12月)
- 数据:各城市各月平均气温(北京1月-3°C...,以真实气候数据为准)
- 每个色块内标注气温数值
- 色图:coolwarm,范围 -5°C ~ 35°C
- 标题:中国主要城市月均气温热力图步骤 2:基于复刻代码,精确修改字体
提示词:
python
# 在上面的代码基础上,将以下字体放大:
# 1. 坐标轴刻度标签:fontsize 从 10 → 16
# 2. 色块内数值标注:fontsize 从 8 → 14
# 3. 坐标轴标题:fontsize 从 12 → 18
# 4. 图表标题:fontsize 从 14 → 22
# 5. 图例:fontsize 从 10 → 16预期结果与分析:
通过方案 B,模型完成了两次可验证的逻辑操作:
- 将视觉图像"翻译"为可精确操作的 Python 代码(数据结构化)
- 在代码层面执行精确的数字替换(逻辑操作)
最终输出的字体放大效果精确、可重复、可验证。
完整参考代码如下:
python
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
import seaborn as sns
# ── 数据:各城市月均气温(°C)──────────────────────────────────────
cities = ["北京", "上海", "广州", "成都", "武汉"]
months = [f"{m}月" for m in range(1, 13)]
data = np.array([
# 北京
[-3, 0, 6, 14, 20, 25, 28, 26, 20, 13, 4, -2],
# 上海
[ 5, 6, 10, 16, 21, 25, 29, 29, 24, 19, 13, 7],
# 广州
[14, 15, 18, 23, 27, 29, 30, 30, 28, 25, 20, 15],
# 成都
[ 6, 8, 13, 18, 22, 25, 26, 26, 22, 17, 12, 7],
# 武汉
[ 4, 6, 11, 18, 23, 27, 30, 29, 24, 18, 11, 5],
])
# ── 绘图 ─────────────────────────────────────────────────────────
plt.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei', 'Arial Unicode MS']
plt.rcParams['axes.unicode_minus'] = False
fig, ax = plt.subplots(figsize=(14, 8))
sns.heatmap(
data,
annot=True,
fmt=".0f",
cmap="coolwarm",
vmin=-5, vmax=35,
xticklabels=months,
yticklabels=cities,
linewidths=0.5,
linecolor='white',
ax=ax,
annot_kws={"size": 14}, # ✅ 色块内数值字体(已放大)
cbar_kws={"shrink": 0.8}
)
# ── 字体放大设置 ──────────────────────────────────────────────────
ax.set_title("中国主要城市月均气温热力图", fontsize=22, fontweight='bold', pad=15) # ✅ 标题
ax.set_xlabel("月份", fontsize=18) # ✅ x轴标题
ax.set_ylabel("城市", fontsize=18) # ✅ y轴标题
ax.tick_params(axis='both', labelsize=16) # ✅ 坐标轴刻度
# 图例字体
cbar = ax.collections[0].colorbar
cbar.ax.tick_params(labelsize=16) # ✅ 图例刻度
cbar.set_label("气温 (°C)", fontsize=16) # ✅ 图例标签
plt.tight_layout()
plt.savefig("heatmap_large_font.png", dpi=150, bbox_inches='tight')
plt.show()
print("热力图已保存:heatmap_large_font.png")实验结论
| 对比维度 | 方案 A(直接修改) | 方案 B(复刻+修改) |
|---|---|---|
| 数据准确性 | ❌ 可能失真 | ✅ 完全准确 |
| 字体精确控制 | ❌ 无法精确 | ✅ 精确到像素 |
| 可重复性 | ❌ 每次不同 | ✅ 代码可复现 |
| 可维护性 | ❌ 不可再编辑 | ✅ 随时修改 |
| 推理模式 | 经验推理(模糊匹配) | 引入逻辑中间层 |
方案 A 的失败 揭示了经验推理的本质局限:模型知道"字体要变大",但不能将这个认知转化为对图像数据结构的精确操作。方案 B 的成功则说明:通过引入"代码"这一逻辑中间层,大模型的经验推理被限定在可验证的逻辑操作范围内,从而获得精确性。
实验二:PPT 幻灯片生成
实验目的
验证:大模型在直接生成 PPT 时(经验推理模式),与先生成 HTML 再转换为 PPT(引入结构化中间层)时,内容完整性和格式质量是否存在显著差异。
实验背景
任务要求:生成一页 PPT,主题为"2025 年大模型井喱式发展的几种路径",该页需包含以下五个方面:算法创新、数据飞轮、硬件红利、开源生态、应用落地。
🔴 方案 A:直接生成 PPT(经验推理模式)

提示词:
请帮我生成一个 PPT,主题是"2025年大模型井喷式发展的几种路径",
需要包含以下模块:封面、背景、算法创新、数据飞轮、硬件红利、开源生态、
应用落地、总结,每页有标题和要点内容。预期结果与分析:
大模型在没有结构化约束的情况下,会基于经验给出一个"看起来像 PPT 提纲"的文本输出。即便使用支持 PPT 生成的工具,也常出现以下问题:
- 各页内容详略不均(熟悉的模块写得多,陌生的写得少)
- 排版格式不稳定(依赖模板,无法精细控制布局)
- 内容深度不足(停留在关键词罗列,缺乏逻辑递进)
- 幻灯片间的逻辑关系模糊
- 色彩、字体、间距等视觉元素缺乏系统性设计
根本原因:模型凭借"PPT 应该长这样"的经验在生成,而非按照严格的信息架构逻辑来组织内容。
🟢 方案 B:先生成 HTML,再转换为 PPT(引入结构化中间层)

步骤 1:让 AI 生成完整的 HTML 幻灯片
提示词:
请用 HTML + CSS 生成一个幻灯片演示文稿,主题是"2025年大模型井喷式发展的几种路径"。
要求:
1. 共8页,每页用 <section class="slide"> 标签包裹
2. 使用 CSS Grid/Flexbox 精确布局
3. 每页包含:页面标题(h2)、要点列表(ul/li)、关键数据
4. 配色方案:深蓝主色 #1a1a4e,强调色 #e74c3c,背景 #f8f9fa
5. 字体层次清晰:标题 2rem,正文 1rem
6. 每页底部有页码
具体内容:
- 第1页(封面):标题大字、副标题、日期
- 第2页(背景):2025年大模型发展关键数据(模型数量、参数规模、用户增长)
- 第3页(路径一·算法创新):MoE稀疏化、CoT思维链、Multi-Agent协作
...(以此类推)完整参考 HTML 结构:
html
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<title>2025年大模型井喷式发展的几种路径</title>
<style>
* { margin: 0; padding: 0; box-sizing: border-box; }
body { font-family: 'Microsoft YaHei', 'PingFang SC', sans-serif;
background: #f0f2f5; }
.slide {
width: 1280px; min-height: 720px;
margin: 20px auto; padding: 50px 60px;
background: white; border-radius: 12px;
box-shadow: 0 4px 20px rgba(0,0,0,0.1);
display: flex; flex-direction: column; justify-content: center;
page-break-after: always;
}
.slide-cover { background: linear-gradient(135deg, #1a1a4e 0%, #2d3a8c 100%);
color: white; text-align: center; }
.slide h2 { font-size: 2.2rem; color: #1a1a4e; margin-bottom: 20px;
border-left: 6px solid #e74c3c; padding-left: 16px; }
.slide ul { list-style: none; }
.slide ul li { font-size: 1.05rem; padding: 10px 0;
border-bottom: 1px solid #eee; line-height: 1.6; }
.slide ul li::before { content: "▶ "; color: #e74c3c; }
.tag { display: inline-block; padding: 3px 10px; border-radius: 20px;
font-size: 0.8rem; background: #e8f0fe; color: #1a1a4e;
margin: 4px 2px; }
.page-num { margin-top: auto; text-align: right; color: #aaa;
font-size: 0.85rem; padding-top: 20px; }
.grid-2 { display: grid; grid-template-columns: 1fr 1fr; gap: 30px; }
.card { background: #f8f9fa; border-radius: 8px; padding: 20px;
border-top: 4px solid #e74c3c; }
.card h3 { color: #1a1a4e; margin-bottom: 10px; font-size: 1.1rem; }
</style>
</head>
<body>
<!-- 第1页:封面 -->
<section class="slide slide-cover">
<h1 style="font-size:3rem; margin-bottom:16px;">
2025 年大模型<br>井喷式发展的几种路径
</h1>
<p style="font-size:1.3rem; opacity:0.8;">
从算法到生态:AI 能力跃升背后的多维驱动力分析
</p>
<p style="margin-top:30px; font-size:1rem; opacity:0.6;">
wangzhi · 2026.05
</p>
</section>
<!-- 第2页:背景 -->
<section class="slide">
<h2>背景:2025 年大模型发展概况</h2>
<div class="grid-2">
<div class="card">
<h3>📊 规模爆炸</h3>
<ul>
<li>全球大模型数量突破 <strong>1,200+</strong></li>
<li>参数规模从千亿迈向<strong>万亿级</strong></li>
<li>多模态模型成主流,文生视频走向实用</li>
</ul>
</div>
<div class="card">
<h3>🚀 应用爆发</h3>
<ul>
<li>AI Agent 渗透率大幅提升</li>
<li>企业 AI 采纳率同比增长 <strong>300%</strong></li>
<li>AI Coding 助力研发效率提升 <strong>40%+</strong></li>
</ul>
</div>
</div>
<div class="page-num">2 / 8</div>
</section>
<!-- 第3页:路径一 算法创新 -->
<section class="slide">
<h2>路径一:算法创新</h2>
<ul>
<li>
<strong>混合专家模型(MoE)</strong>:稀疏激活,用 20% 参数完成 80% 的计算,
实现"大参数量、低推理成本"的兼顾
<span class="tag">GPT-4o</span><span class="tag">Mixtral</span><span class="tag">DeepSeek-V2</span>
</li>
<li>
<strong>思维链(Chain-of-Thought, CoT)</strong>:在推理时引入逻辑步骤,
将经验推理向逻辑推理靠拢,数学、代码能力大幅提升
<span class="tag">o1</span><span class="tag">o3</span><span class="tag">DeepThink</span>
</li>
<li>
<strong>多智能体协作(Multi-Agent)</strong>:将复杂任务分解为子任务,
由专门 Agent 协同完成,突破单模型能力上限
<span class="tag">AutoGen</span><span class="tag">MetaGPT</span>
</li>
</ul>
<div class="page-num">3 / 8</div>
</section>
<!-- 第4页:路径二 数据飞轮 -->
<section class="slide">
<h2>路径二:数据飞轮</h2>
<ul>
<li>
<strong>合成数据(Synthetic Data)</strong>:利用强模型生成训练数据,
突破人工标注的规模天花板,Apple Intelligence、Phi-4 均大量使用
</li>
<li>
<strong>自我对弈与迭代(Self-Play)</strong>:模型与自身博弈(如 AlphaCode 2),
在无人类监督下持续提升推理和编程能力
</li>
<li>
<strong>数据质量工程</strong>:从"堆数量"转向"精筛选",
1T 高质量 token 优于 10T 低质量 token(Llama 3 研究结论)
</li>
</ul>
<div class="page-num">4 / 8</div>
</section>
<!-- 第5页:路径三 硬件红利 -->
<section class="slide">
<h2>路径三:硬件红利</h2>
<div class="grid-2">
<div class="card">
<h3>🖥️ GPU 算力持续跃升</h3>
<ul>
<li>H100 → H200 → B200 性能 3 年提升 <strong>6×</strong></li>
<li>NVLink 互联带宽突破 <strong>1.8TB/s</strong></li>
<li>FP8 混合精度训练成主流</li>
</ul>
</div>
<div class="card">
<h3>⚡ 新型专用芯片崛起</h3>
<ul>
<li>华为昇腾、寒武纪 MLU 国产替代加速</li>
<li>Groq LPU 推理速度达传统 GPU 的 <strong>10×</strong></li>
<li>端侧 AI 芯片(苹果 M4、高通 X Elite)加速 on-device 推理</li>
</ul>
</div>
</div>
<div class="page-num">5 / 8</div>
</section>
<!-- 第6页:路径四 开源生态 -->
<section class="slide">
<h2>路径四:开源生态</h2>
<ul>
<li>
<strong>Meta Llama 系列</strong>:Llama 3.1 405B 性能持平 GPT-4,
推动"开源对齐闭源"的历史性转折,下载量超 <strong>3.5 亿次</strong>
</li>
<li>
<strong>阿里 Qwen 系列</strong>:Qwen2.5-72B 在多项基准超越同参数量闭源模型,
多语言支持能力尤为突出
</li>
<li>
<strong>DeepSeek 系列</strong>:DeepSeek-R1 以极低训练成本实现顶尖推理能力,
引发全球对"高效训练"路线的重新思考
</li>
<li>
<strong>开源工具链成熟化</strong>:vLLM、SGLang、Ollama 降低本地部署门槛,
个人和中小企业也可运行百亿参数模型
</li>
</ul>
<div class="page-num">6 / 8</div>
</section>
<!-- 第7页:路径五 应用落地 -->
<section class="slide">
<h2>路径五:应用落地</h2>
<ul>
<li>
<strong>垂直领域 Agent</strong>:医疗(辅助诊断准确率 >90%)、法律(合同审查效率提升 5×)、
金融(量化策略生成)等专业场景 Agent 大规模落地
</li>
<li>
<strong>具身智能(Embodied AI)</strong>:Figure 01、Unitree G1 等人形机器人
集成大模型进行自然语言指令理解和任务规划
</li>
<li>
<strong>AI Native 应用生态</strong>:从"AI 辅助"到"AI 原生",
Cursor、Notion AI、Perplexity 重构生产力工具形态
</li>
</ul>
<div class="page-num">7 / 8</div>
</section>
<!-- 第8页:总结 -->
<section class="slide" style="background: linear-gradient(135deg, #1a1a4e 0%, #2d3a8c 100%); color: white;">
<h2 style="color: white; border-left-color: #e74c3c;">总结</h2>
<ul style="color: rgba(255,255,255,0.9);">
<li>2025 年大模型的井喷式发展是<strong>算法、数据、硬件、生态、应用</strong>五条路径共振的结果</li>
<li>任何单一路径都不足以解释这场变革,协同效应才是关键</li>
<li>下一个突破口:从"经验推理"向"逻辑推理"的迁移------思维链、工具调用、形式验证</li>
</ul>
<div style="margin-top: 40px; padding: 20px; background: rgba(255,255,255,0.1);
border-radius: 8px; text-align: center;">
<p style="font-size: 1.3rem; font-weight: bold;">
"大模型不是终点,而是智能基础设施的开始。"
</p>
</div>
<div class="page-num" style="color: rgba(255,255,255,0.5);">8 / 8</div>
</section>
</body>
</html>步骤 2 :在 HTML 中调整后,使用工具(如 python-pptx 或 Pandoc)转换为标准 PPTX 格式
bash
# 方案:使用 Playwright 截图各页,再导入 PPTX
# 或直接用 python-pptx 解析 HTML 结构重建幻灯片
pip install python-pptx实验结论
| 对比维度 | 方案 A(直接生成 PPT) | 方案 B(HTML→PPT) |
|---|---|---|
| 内容完整性 | ⚠️ 常遗漏模块 | ✅ 8 页全覆盖 |
| 格式精确性 | ⚠️ 依赖模板随机性 | ✅ CSS 像素级控制 |
| 可修改性 | ❌ 重新生成成本高 | ✅ 改 HTML 即可 |
| 视觉一致性 | ⚠️ 风格漂移 | ✅ 统一设计系统 |
| 推理模式 | 经验推理(格式靠猜) | 引入结构化中间层 |
四、总结:从经验推理到逻辑推理的迁移
4.1 两个实验的共同揭示
两组实验揭示了同一个本质规律:
当 AI 大模型被要求直接完成需要精确操作的任务时,经验推理的局限性充分暴露;
而当任务被分解为"结构化表达 → 逻辑操作"两步时,模型表现大幅提升。
| 实验 | 经验推理模式的失败点 | 逻辑中间层的作用 |
|---|---|---|
| 热力图字体修改 | 无法精确操控图像数据结构 | Python 代码将图像抽象为可精确操作的对象 |
| PPT 生成 | 内容组织和格式控制缺乏系统性 | HTML/CSS 将布局抽象为严格的结构化规范 |
4.2 思维链(CoT):大模型向逻辑推理迈进的关键机制
这两个实验实际上揭示了一个更深刻的原理:在推理过程中引入逻辑链,能使大模型的表现从模糊的经验推理向精确的逻辑推理靠拢。
思维链(Chain-of-Thought, CoT) 正是这一原理在提示工程层面的实现:
❌ 经验推理(无 CoT):
问题 → 答案
(模型直接从经验中检索最可能的答案)
✅ 引入逻辑链(CoT):
问题 → 步骤1 → 步骤2 → 步骤3 → 答案
(每一步都是可验证的逻辑操作,错误可在中间步骤被纠正)CoT 的有效性已被大量研究证实:
- 在 GSM8K 数学测试集上,CoT 将 GPT-3 准确率从 17% 提升至 56%
- 在代码生成任务上,"先写注释再写代码"的 CoT 方式使通过率提升约 30%
- o1/o3 系列模型(OpenAI)以"内置 CoT 推理"为核心设计,推理能力远超同规模普通 LLM
4.3 逻辑链的本质:将经验推理的中间步骤结构化
从更深层看,CoT 并没有改变大模型的基本推理机制------每一步的输出依然是概率最高的 token。但它做到了两件关键的事:
-
错误隔离:将长推理链分解为短步骤,每步的错误概率更低,累积错误减少
-
自我一致性(Self-Consistency):多路径 CoT 推理后投票,进一步消除经验偏差
经验推理 ──→ 加入逻辑链 ──→ 更接近逻辑推理
(概率匹配) (步骤结构化) (分步验证、减少幻觉)
4.4 展望:大模型推理的未来方向
| 技术方向 | 核心思路 | 代表工作 |
|---|---|---|
| 长链 CoT | 让模型"想得更久" | OpenAI o3, DeepSeek R1 |
| 工具调用(Tool Use) | 将精确操作外包给可靠工具 | GPT-4o + Code Interpreter |
| 形式化验证辅助 | 用定理证明器验证中间步骤 | Lean + LLM |
| 神经符号混合 | 将符号推理引擎嵌入神经网络 | AlphaGeometry |
| 强化学习自我改进 | 用结果奖励信号优化推理路径 | Process Reward Model (PRM) |
五、结语

参考资料
- Wei, J. et al. "Chain-of-Thought Prompting Elicits Reasoning in Large Language Models." NeurIPS 2022.
- Lightman, H. et al. "Let's Verify Step by Step." OpenAI, 2023.
- GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models. Apple, 2024.
- DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning. DeepSeek-AI, 2025.
- Llama 3: Meta AI Technical Report. Meta AI, 2024.