快速入门
快速安装
使用 helm-chart 安装
sql
helm repo add volcano-sh https://volcano-sh.github.io/helm-charts
helm repo update
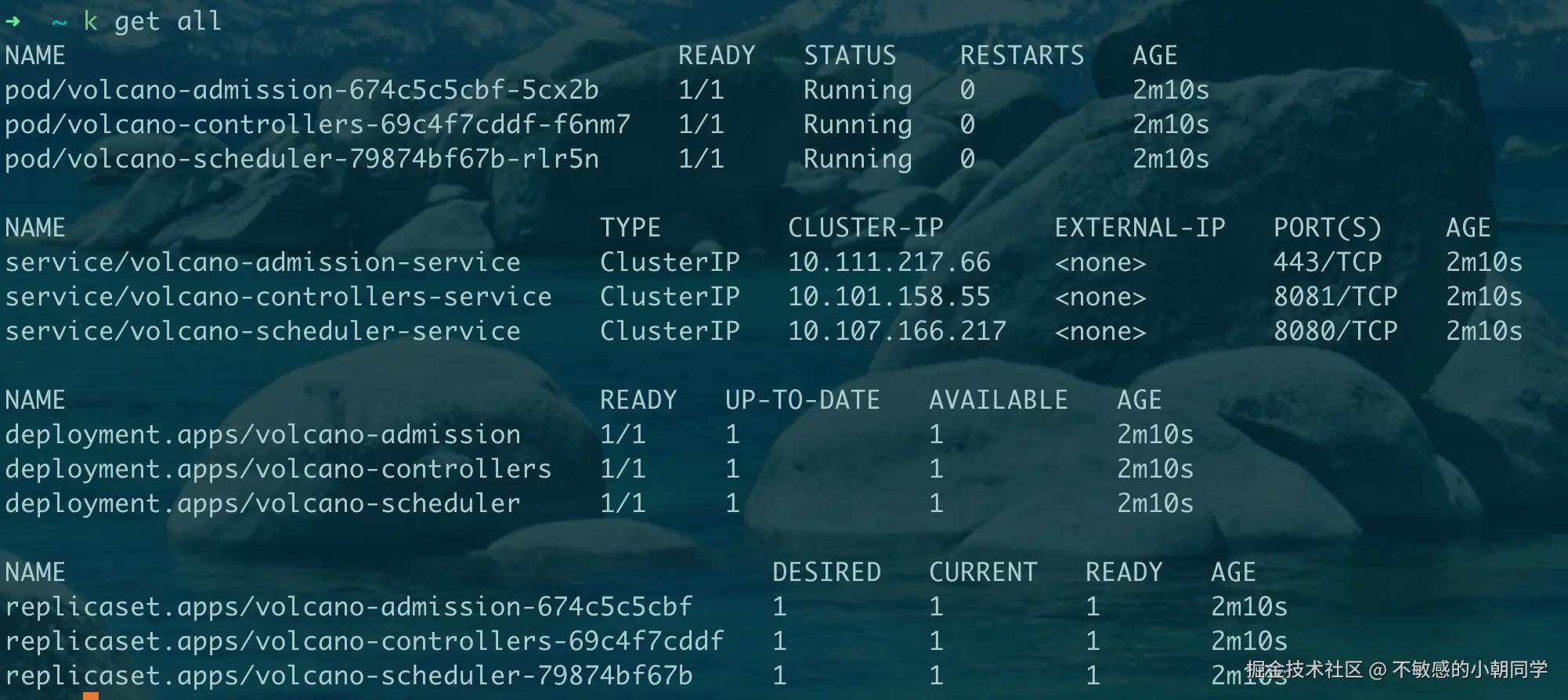
helm install volcano volcano-sh/volcano -n volcano-system --create-namespace安装成功之后可看到如下资源
测试应用
创建 deploy
yaml
# queue.yaml
apiVersion: scheduling.volcano.sh/v1beta1
kind: Queue
metadata:
name: development-queue
namespace: volcano-system
spec:
weight: 1 # Relative weight for scheduling priority among queues
reclaimable: false # If true, jobs in other queues can reclaim resources in this queue
capability:
cpu: 2
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-app-deployment
namespace: volcano-system
annotations:
scheduling.volcano.sh/group-min-member: "2" # 最小副本数
labels:
app: my-app
spec:
replicas: 3
selector:
matchLabels:
app: my-app
template:
metadata:
annotations:
scheduling.volcano.sh/queue-name: development-queue # 注意目标队列是写在这里
labels:
app: my-app
spec:
schedulerName: volcano
containers:
- name: my-container
image: busybox
command: ["sh", "-c", "echo 'Hello Volcano from Deployment'; sleep inf"]
resources:
requests:
cpu: 1
limits:
cpu: 1查看 PodGroup 的状态

查看pod的状态

其中 pending 的 Pod 的事件如下

整体架构
架构总览
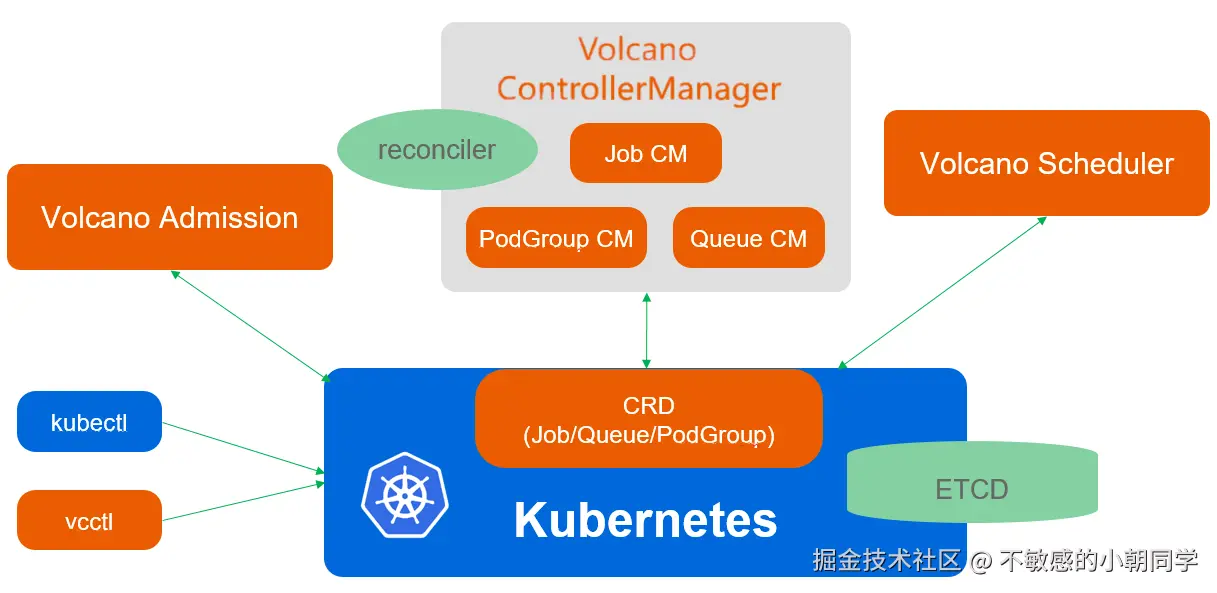
Scheduler: 负责进行调度,即应用具体应该下发到哪些 node 上 ControllerManger:负责 CRD 的生命周期管理,比如管理 Queue、PodGroup 和 VCJob
Admission:负责进行权限管控
Vcctl:提供命令行来操作 Volcano
调度逻辑
Volcano 无缝对接 k8s ,那具体是怎么实现的呢?
实现上会发现我们只需要在 schedulerName 这里指定调度器为 volcano 即可
首先要明白,k8s 是支持多调度器的,就是默认的调度器也是通过 list-watch APIServer 里面的数据来进行逻辑处理的,各个调度器都是相互独立的
- 当 pod 指定了 scheduler 为 volcano 时,kube-scheduler 看到这个 pod 的 schedulerName != "default-scheduler", 直接跳过不处理
- volcano-scheduler 注册的时候会监听属于这个特定的 scheduler 的 pod 的行为
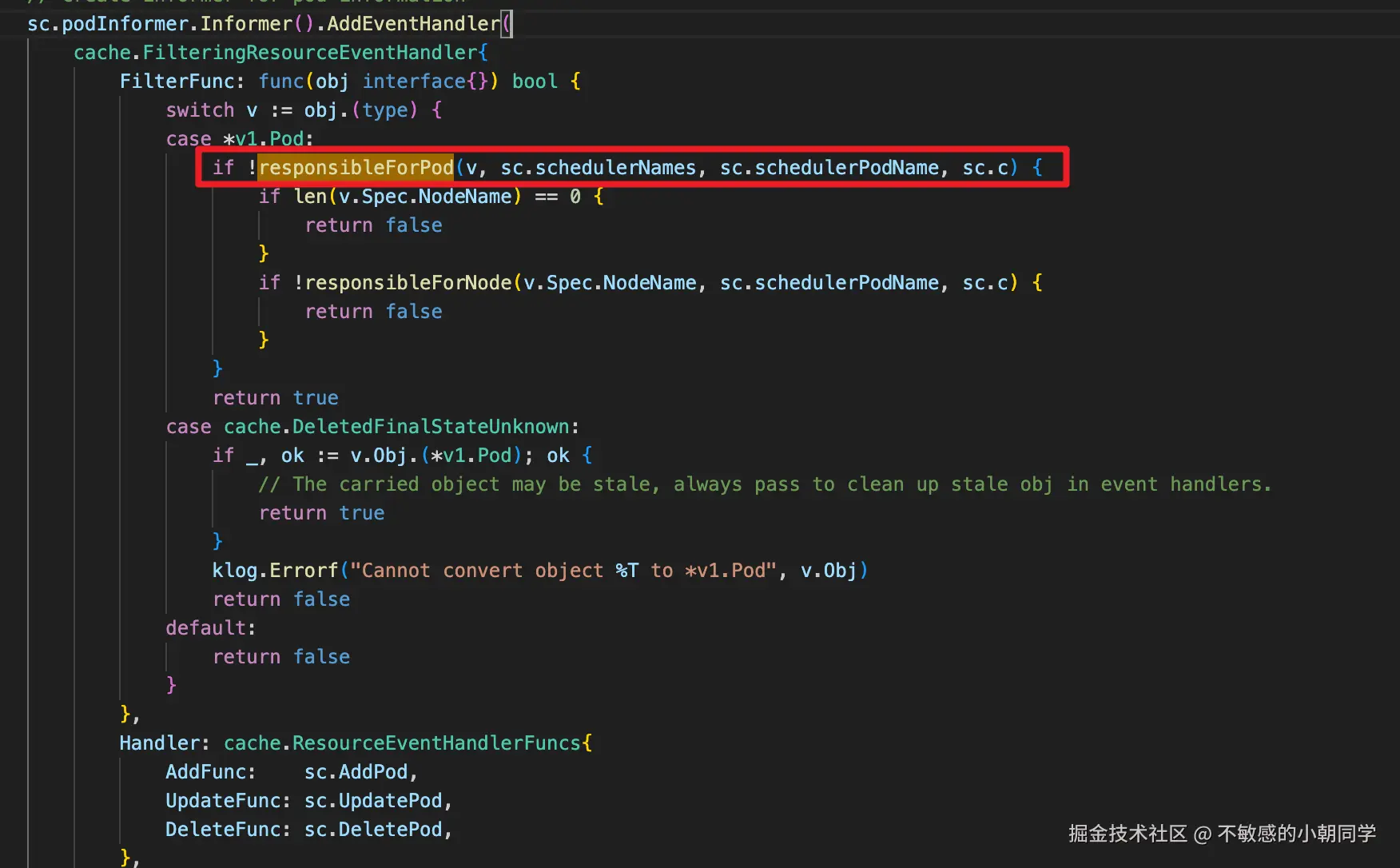
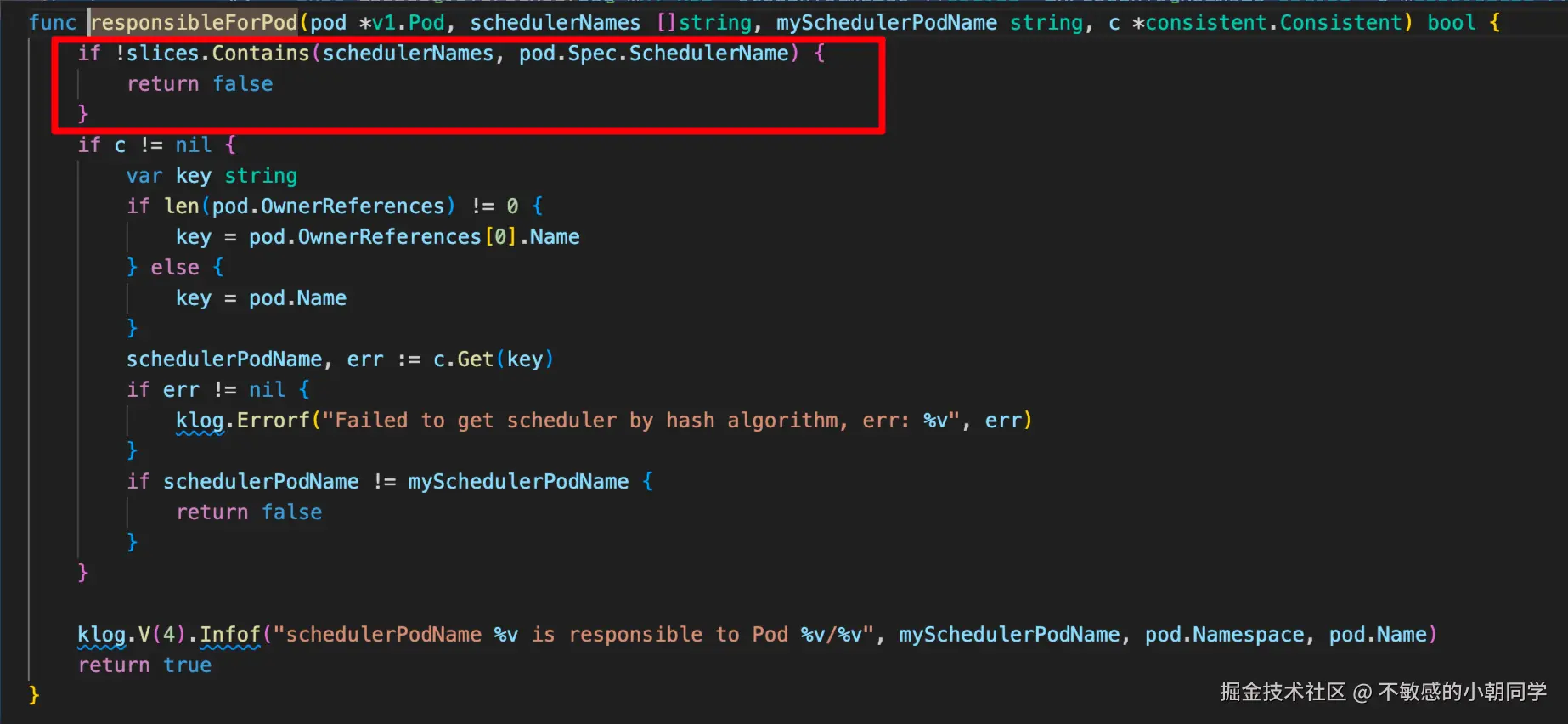
如果不是属于这个 scheduler 会直接丢弃
- 接下来就是进入调度队列,执行调度逻辑直到找到最合适的节点
Queue
Volcano 的 queue 起始就是一组 podGroup 的集合,采用 FIFO 算法来分配
拿下面这个 Queue 的 yaml 文件来说明
yaml
apiVersion: scheduling.volcano.sh/v1beta1
kind: Queue
metadata:
creationTimestamp: "2024-12-30T09:31:12Z"
generation: 1
name: test
resourceVersion: "987630"
uid: 88babd01-c83f-4010-9701-c2471c1dd040
spec:
capability:
cpu: "8"
memory: 16Gi
# deserved field is only used by capacity plugin
deserved:
cpu: "4"
memory: 8Gi
guarantee:
resource:
cpu: "2"
memory: 4Gi
priority: 100
reclaimable: true
# weight field is only used by proportion plugin
weight: 1
status:
allocated:
cpu: "0"
memory: "0"
state: Open基本关键字段解释如下
guarantee:表示该队列保底的资源,即这部分资源是一定有的
deserved:表示该队列应得的资源
capability:表示该队列的能够使用的最多的资源
三者关系如下:以 guarantee:20,deserved:40,capability:60 为例
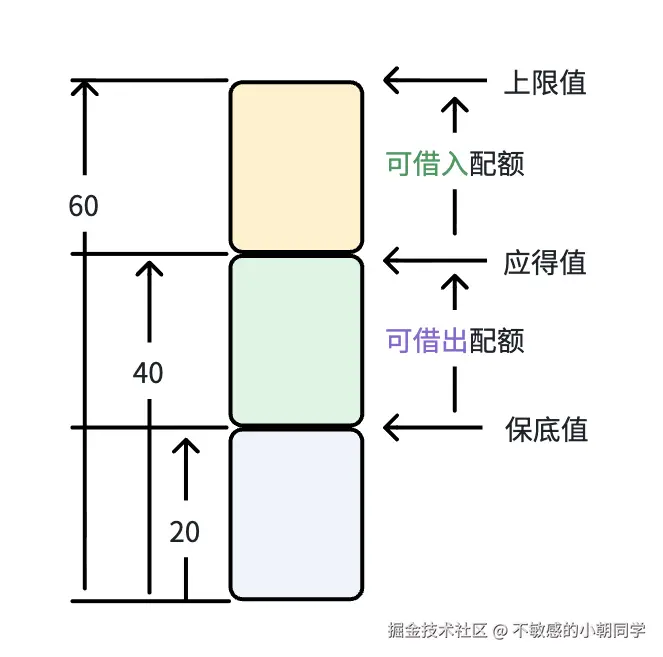
weight:表示该队列在整个集群资源层面的相关权重;按照 weight 的 deserverd resource 计算公式如下:(weight/total_weight) * total_weight; 这个功能需要配置 propotion 这个插件才能生效
队列状态:
-
open:表示队列可用状态且可接受新的pg
-
closed:表示队列不可用
-
closing:中间状态,表示队列即将不可用
-
unknown:状态不合预期
默认队列
volcano在启动的时候,会创建如下两个队列
default queue:这个队列用于兜底,任务使用 volcano 调度器但是没有指定队列时便会使用这个默认队列
yaml
➜ ~ k get q default -oyaml
apiVersion: scheduling.volcano.sh/v1beta1
kind: Queue
metadata:
creationTimestamp: "2026-04-22T08:10:20Z"
generation: 2
name: default
resourceVersion: "47489893"
uid: f6f5781d-dcdf-4176-98f9-794554ac9413
spec:
dequeueStrategy: traverse
guarantee: {}
parent: root
reclaimable: true
weight: 1
status:
allocated:
cpu: "0"
memory: "0"
reservation: {}
state: Openroot queue:这个队列用于支持层级队列的功能,默认作为所有子队列的根队列的形式存在
yaml
➜ ~ k get q root -oyaml
apiVersion: scheduling.volcano.sh/v1beta1
kind: Queue
metadata:
creationTimestamp: "2026-04-22T08:10:20Z"
generation: 2
name: root
resourceVersion: "47490789"
uid: b013f282-d887-437b-b310-ed7ab968789c
spec:
dequeueStrategy: traverse
deserved:
cpu: "0"
memory: "0"
guarantee:
resource:
cpu: "0"
memory: "0"
reclaimable: false
weight: 1
status:
allocated:
cpu: "2"
memory: "0"
pods: "2"
reservation: {}
state: OpenPodGroup
pg 是 volcano 里面一个很重要的概念,用来实现批处理调度,pg 顾名思义是一组pod的集合,在机器学习场景中,往往需要一组pod同时被调度,这种情况下 pg 的作用就很明显
拿官方给出的 pg 的 yaml 文件举例介绍
yaml
apiVersion: scheduling.volcano.sh/v1beta1
kind: PodGroup
metadata:
creationTimestamp: "2020-08-11T12:28:55Z"
generation: 5
name: test
namespace: default
ownerReferences:
- apiVersion: batch.volcano.sh/v1alpha1
blockOwnerDeletion: true
controller: true
kind: Job
name: test
uid: 028ecfe8-0ff9-477d-836c-ac5676491a38
resourceVersion: "109074"
selfLink: /apis/scheduling.volcano.sh/v1beta1/namespaces/default/podgroups/job-1
uid: eb2508f5-3349-439c-b94d-4ac23afd71ff
spec:
minMember: 1
minResources:
cpu: "3"
memory: "2048Mi"
priorityClassName: high-priority
queue: default
status:
conditions:
- lastTransitionTime: "2020-08-11T12:28:57Z"
message: '1/0 tasks in gang unschedulable: pod group is not ready, 1 minAvailable.'
reason: NotEnoughResources
status: "True"
transitionID: 77d5be3f-6169-4f86-8e65-0bdc621ce983
type: Unschedulable
- lastTransitionTime: "2020-08-11T12:29:02Z"
reason: tasks in gang are ready to be scheduled
status: "True"
transitionID: 54514401-5c90-4b11-840d-90c1cda93096
type: Scheduled
phase: Running
running: 1minMember:代表在这个pg下面的批量运行的最小的副本数
queue:代表这个pg属于哪个 queue
priorityClassName:代表 pg 的优先级
minResources:代表 pg 调度运行成功所需的最小资源
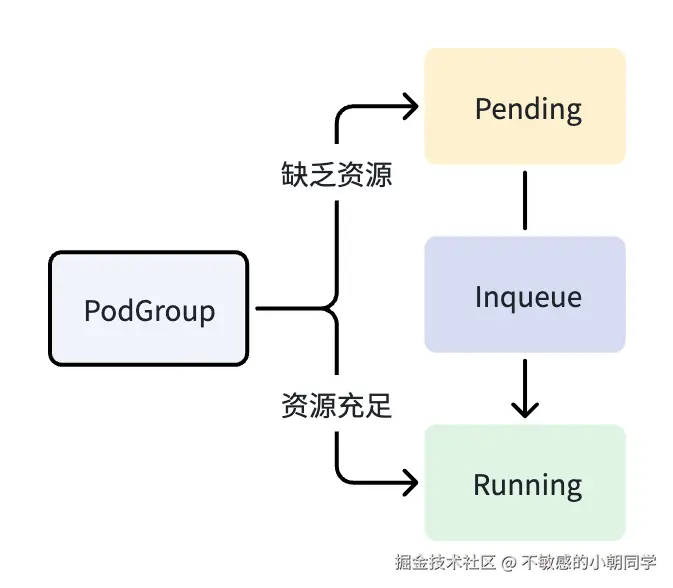
pg 的状态:
- pending:表示待调度,但是现在资源不足,不能调度
- runing:表示 minMember 已经满足,并且运行起来了
- inqueue:表示 pg 已经通过了验证,现在等待绑定到特定的node上进行调度,这个是介于 pending 和running 的中间状态
- unknown:未知状态,表示在 minMember 里面的 pod,有的是 runing 状态有的还未被调度
总结如下
核心特性
Volcano 作为目前最主流的批处理引擎,其主要的能力就在于两点,队列资源预留 和 批处理调度
层级队列
摘自官方的一张图
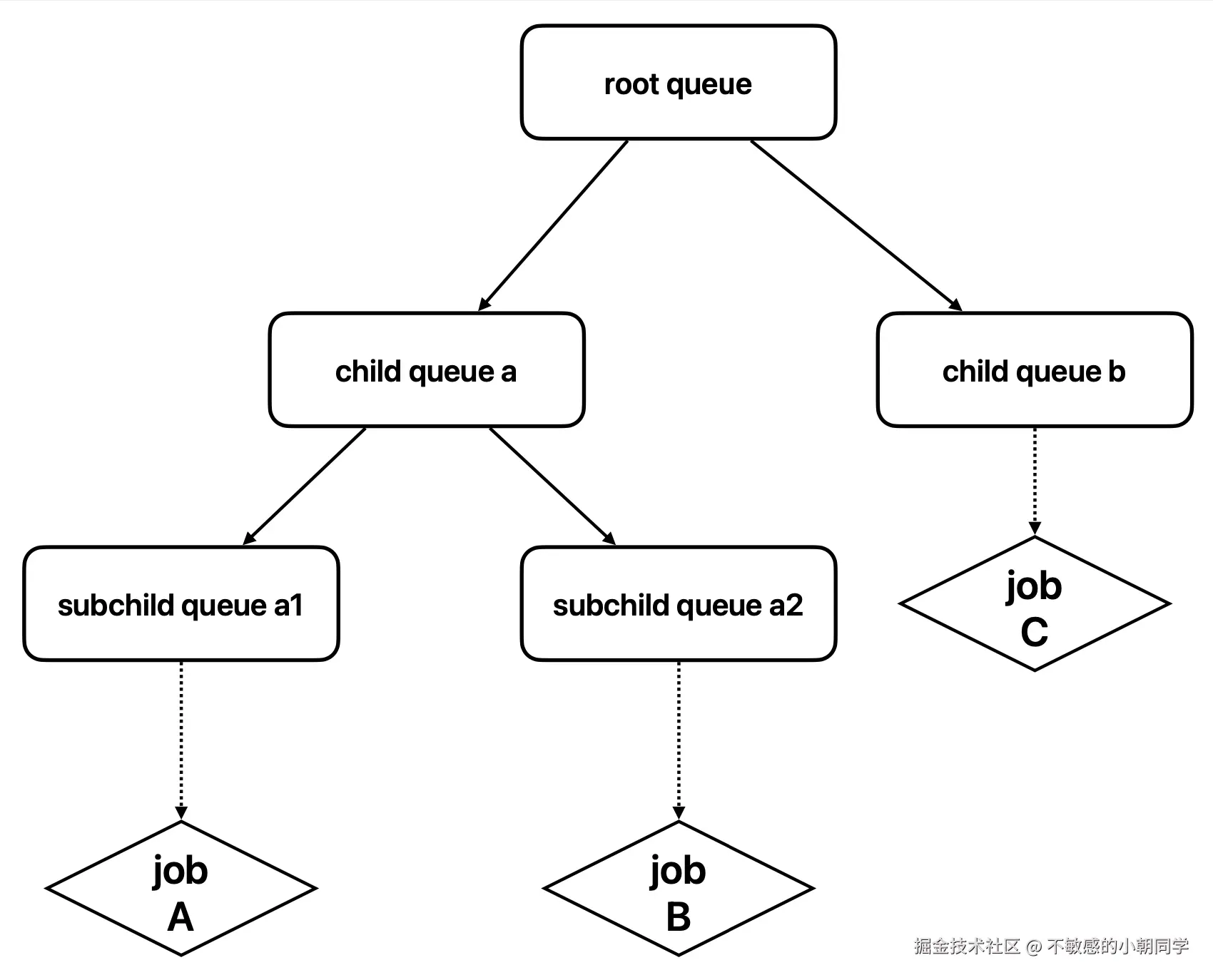
层级队列有个最重要的功能就是资源的借用和回收
资源借用&回收
假设部门 A(deserved: 10GPU),实际使用了 15GPU,借了 5 个
假设部门 B(deserved: 10GPU),实际使用了 5GPU,空闲 5 个被借走
当部门 B 需要资源时,回收部门 A 超过 deserved 的 5GPU
回收优先级:
-
先从兄弟队列中超出 deserved 的部分回收
-
不够再向上层祖先队列遍历回收
-
实现跨层级的动态资源再分配
批处理调度
配置介绍
Volcano 的调度配置是在一个名为 volcano-scheduler-configmap 的文件底下
vbnet
➜ ~ k get cm volcano-scheduler-configmap -oyaml
apiVersion: v1
data:
volcano-scheduler.conf: |
actions: "enqueue, allocate, backfill"
tiers:
- plugins:
- name: priority
- name: gang
enablePreemptable: false
- name: conformance
- plugins:
- name: overcommit
- name: drf
enablePreemptable: false
- name: predicates
- name: proportion
- name: nodeorder
- name: binpack
kind: ConfigMap
metadata:
........这个配置基本分为两个部分:actions 和 tiers
Actions 是调度流程的步骤,Plugin 是每个步骤里面的决策逻辑,Tier 决定决策逻辑的执行顺序
比如上面的 Actions,调度顺序就是先调用 enqueue, 再调用 allocate, 最后调用 backfill
Action 和 Plugin 之前通过一个名为 Extension Points 的东西来进行连接
实际实现原理就是 Action 定义了我需要调用哪些函数(也就是上面提到的 Externsion Points),Plugin 只是用来实现这些函数的,具体逻辑可参考如下
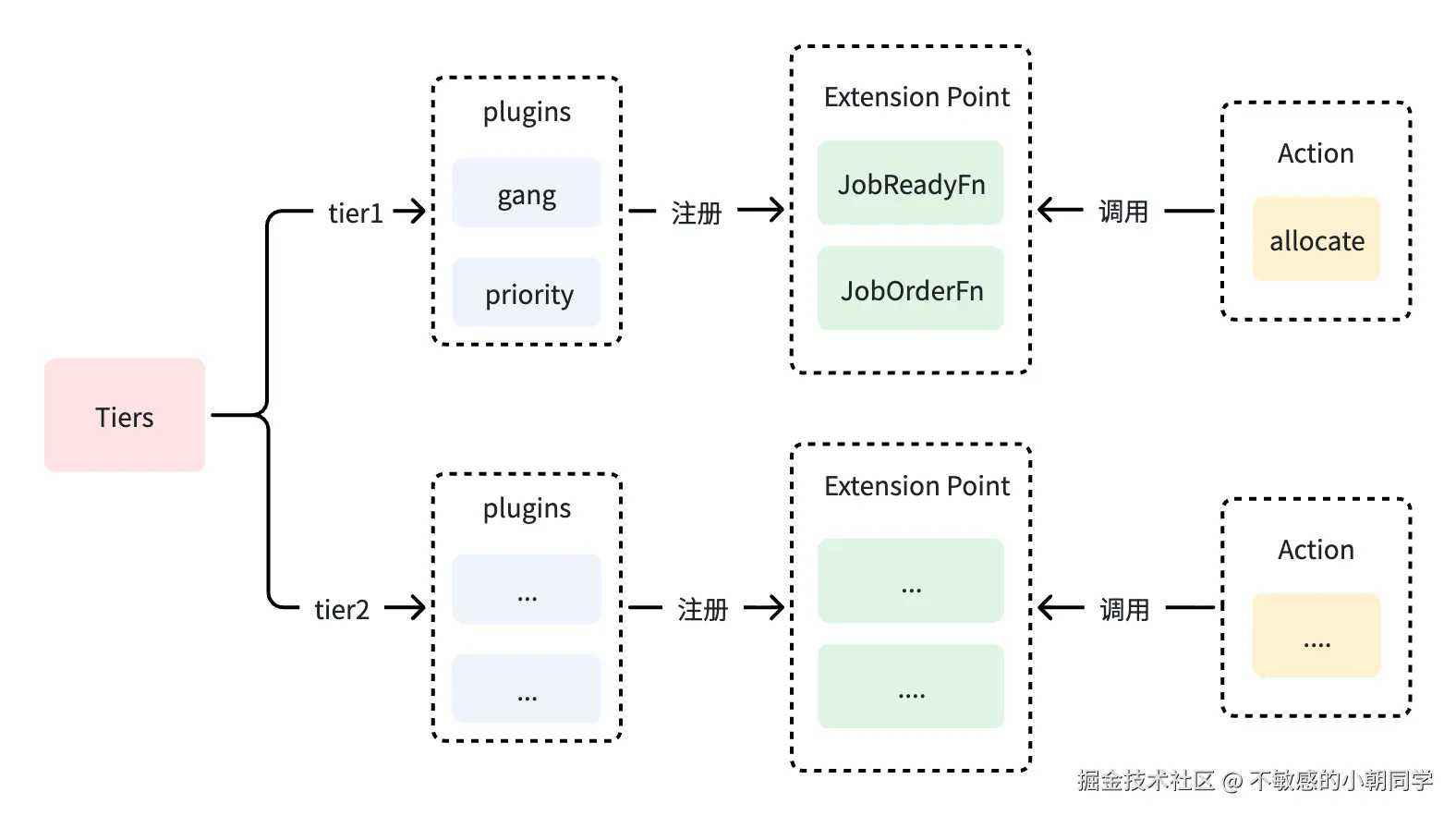 tier1 会比 tier2 优先调用,尽管都实现了同一个 ExtersionPoint
tier1 会比 tier2 优先调用,尽管都实现了同一个 ExtersionPoint
插件介绍
Volcano 内置了非常多的插件,这些插件组合起来实现了一个个泛型的 Action 操作
所有的插件都是通过一个 Register 方法注册到一个公共的 plugin management 接口里面,而每个插件都要实现这个名为 Plugin 的接口
scss
type Plugin interface {
// The unique name of Plugin.
Name() string
OnSessionOpen(ssn *Session)
OnSessionClose(ssn *Session)
}
// PluginBuilder plugin management
type PluginBuilder = func(Arguments) Plugin
// Plugin management
var pluginBuilders = map[string]PluginBuilder{} // 这个map存储所有的插件
// RegisterPluginBuilder register the plugin
func RegisterPluginBuilder(name string, pc PluginBuilder) {
pluginMutex.Lock()
defer pluginMutex.Unlock()
pluginBuilders[name] = pc
}下面介绍几个重要的插件机制
Gang 插件
Gang 插件的核心是要么一起调度,要么都不调度, 一个 Job 的 Pod 必须满足最少数量(MinAvailable)才能整体运行,否则全部等待
注意这上面提到的的 Job 的概念,JobInfo 不是一次调度动作,也是 Volcano 调度器内部对 "一组需要一起调度的Pod"的抽象,其实就是 volcano 里面的 podGroup 的概念
整体逻辑如下
OnSessionOpen
go
func (gp *gangPlugin) OnSessionOpen(ssn *framework.Session) {
validJobFn := func(obj interface{}) *api.ValidateResult {
job, ok := obj.(*api.JobInfo)
if !ok {
return &api.ValidateResult{
Pass: false,
Message: fmt.Sprintf("Failed to convert <%v> to *JobInfo", obj),
}
}
if valid := job.CheckTaskValid(); !valid {
return &api.ValidateResult{
Pass: false,
Reason: v1beta1.NotEnoughPodsOfTaskReason,
Message: "Not enough valid pods of each task for gang-scheduling",
}
}
vtn := job.ValidTaskNum()
if vtn < job.MinAvailable {
return &api.ValidateResult{
Pass: false,
Reason: v1beta1.NotEnoughPodsReason,
Message: fmt.Sprintf("Not enough valid tasks for gang-scheduling, valid: %d, min: %d",
vtn, job.MinAvailable),
}
}
return nil
}
ssn.AddJobValidFn(gp.Name(), validJobFn)
...
}本质是往 Session 里面添加一些必要的 function,每个 function 存入的都是 k-v 的形式保存到一个 map 里面
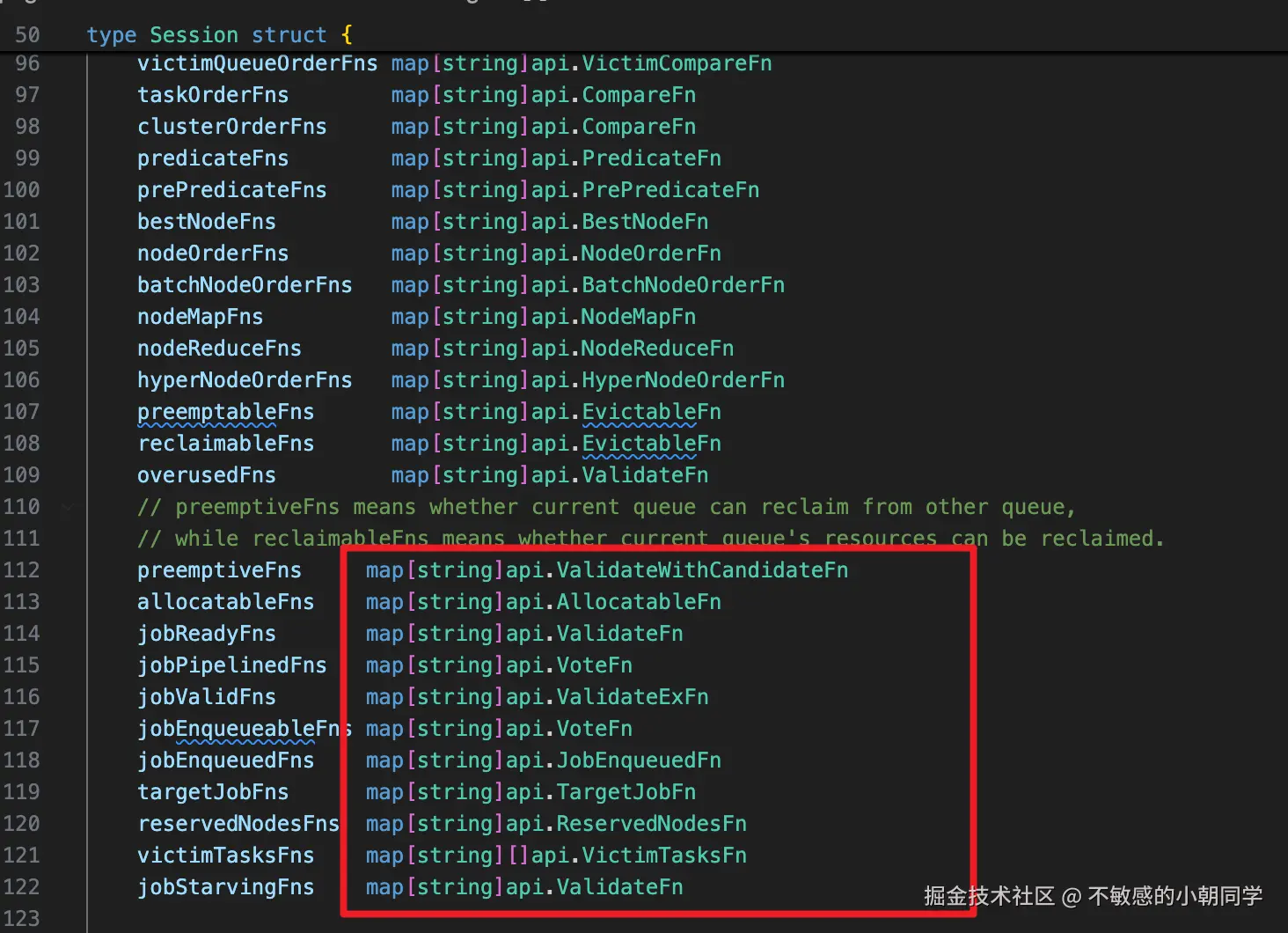
比如我们利用 gang 插件注册的其中一个 jobValidFns 是会被 Action: allocate 调用,逻辑如下
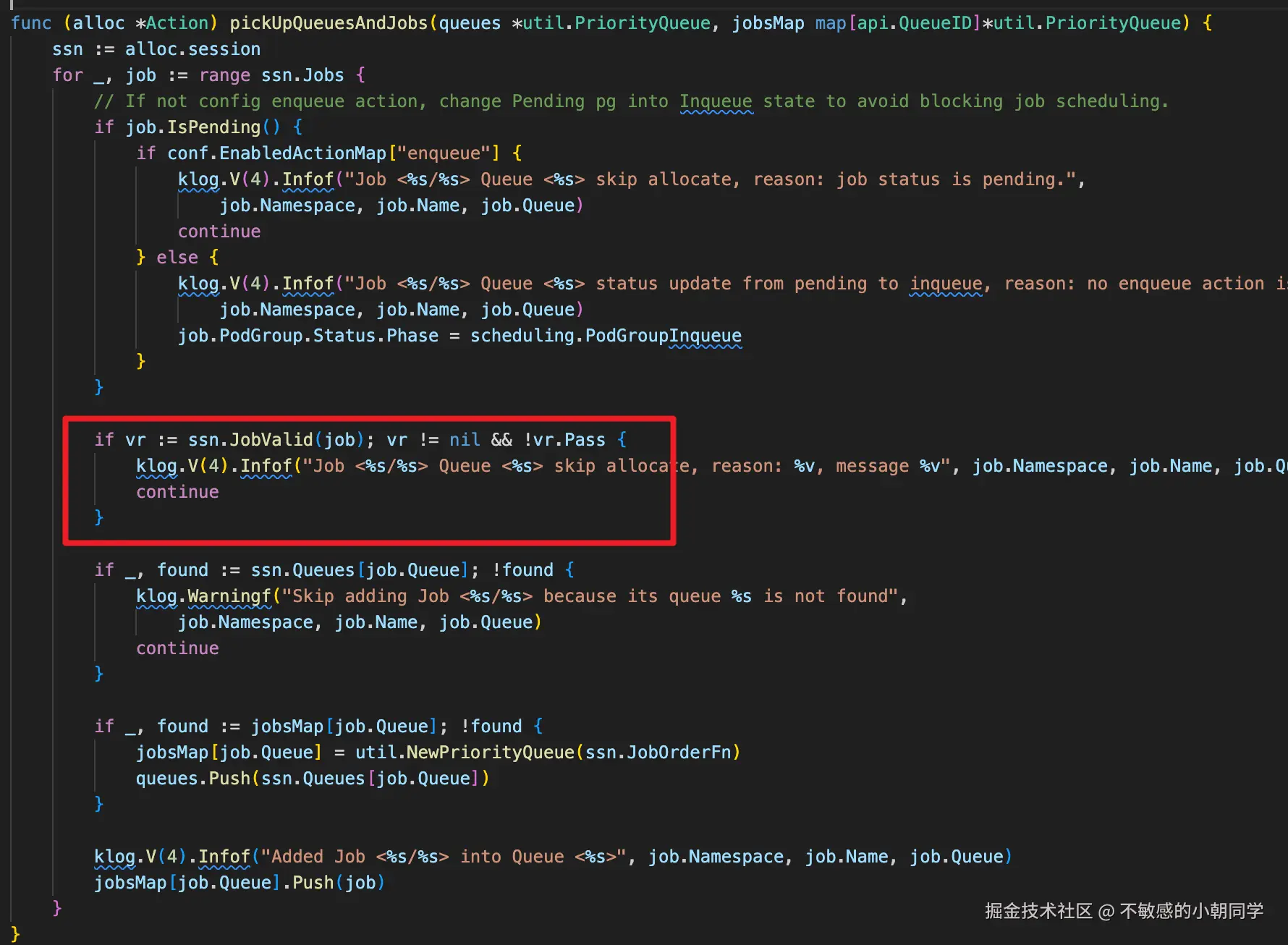
这里会执行 Session 的 JobValid 方法,而这个方法定义如下
go
func (ssn *Session) JobValid(obj interface{}) *api.ValidateResult {
for _, tier := range ssn.Tiers {
for _, plugin := range tier.Plugins {
jrf, found := ssn.jobValidFns[plugin.Name]
if !found {
continue
}
if vr := jrf(obj); vr != nil && !vr.Pass {
return vr
}
}
}
return nil
}从上面这个方法就可以看出,Tiers 的优先级作用就体现出来了,先保存在 Tiers 的前面的 plugin 会优先被调用;主要是插件注册了对应的扩展点,则 Actions 调用时会按照插件的顺序逐个调用确定优先级
OnSessionClose
go
func (gp *gangPlugin) OnSessionClose(ssn *framework.Session) {
var unreadyTaskCount int32
var unScheduleJobCount int
for _, job := range ssn.Jobs {
// skip the jobs that have no tasks.
if len(job.Tasks) == 0 {
continue
}
if !job.IsReady() {
schedulableTaskNum := func() (num int32) {
for _, task := range job.TaskStatusIndex[api.Pending] {
ctx := task.GetTransactionContext()
if task.LastTransaction != nil {
ctx = *task.LastTransaction
}
if api.AllocatedStatus(ctx.Status) {
num++
}
}
return num + job.ReadyTaskNum()
}
unreadyTaskCount = job.MinAvailable - schedulableTaskNum()
msg := fmt.Sprintf("%v/%v tasks in gang unschedulable: %v",
unreadyTaskCount, len(job.Tasks), job.FitError())
unScheduleJobCount++
metrics.RegisterJobRetries(job.Name)
// TODO: If the Job is gang-unschedulable due to scheduling gates
// we need a new message and reason to tell users
// More detail in design doc pod-scheduling-readiness.md
jc := &scheduling.PodGroupCondition{
Type: scheduling.PodGroupUnschedulableType,
Status: v1.ConditionTrue,
LastTransitionTime: metav1.Now(),
TransitionID: string(ssn.UID),
Reason: v1beta1.NotEnoughResourcesReason,
Message: msg,
}
if err := ssn.UpdatePodGroupCondition(job, jc); err != nil {
klog.Errorf("Failed to update job <%s/%s> condition: %v",
job.Namespace, job.Name, err)
}
} else {
jc := &scheduling.PodGroupCondition{
Type: scheduling.PodGroupScheduled,
Status: v1.ConditionTrue,
LastTransitionTime: metav1.Now(),
TransitionID: string(ssn.UID),
Reason: "tasks in gang are ready to be scheduled",
Message: "",
}
if err := ssn.UpdatePodGroupCondition(job, jc); err != nil {
klog.Errorf("Failed to update job <%s/%s> condition: %v",
job.Namespace, job.Name, err)
}
}
metrics.UpdateUnscheduleTaskCount(job.Name, int(unreadyTaskCount))
unreadyTaskCount = 0
}
metrics.UpdateUnscheduleJobCount(unScheduleJobCount)
}这里主要逻辑是汇报 PodGroup 的状态以及上报 metric
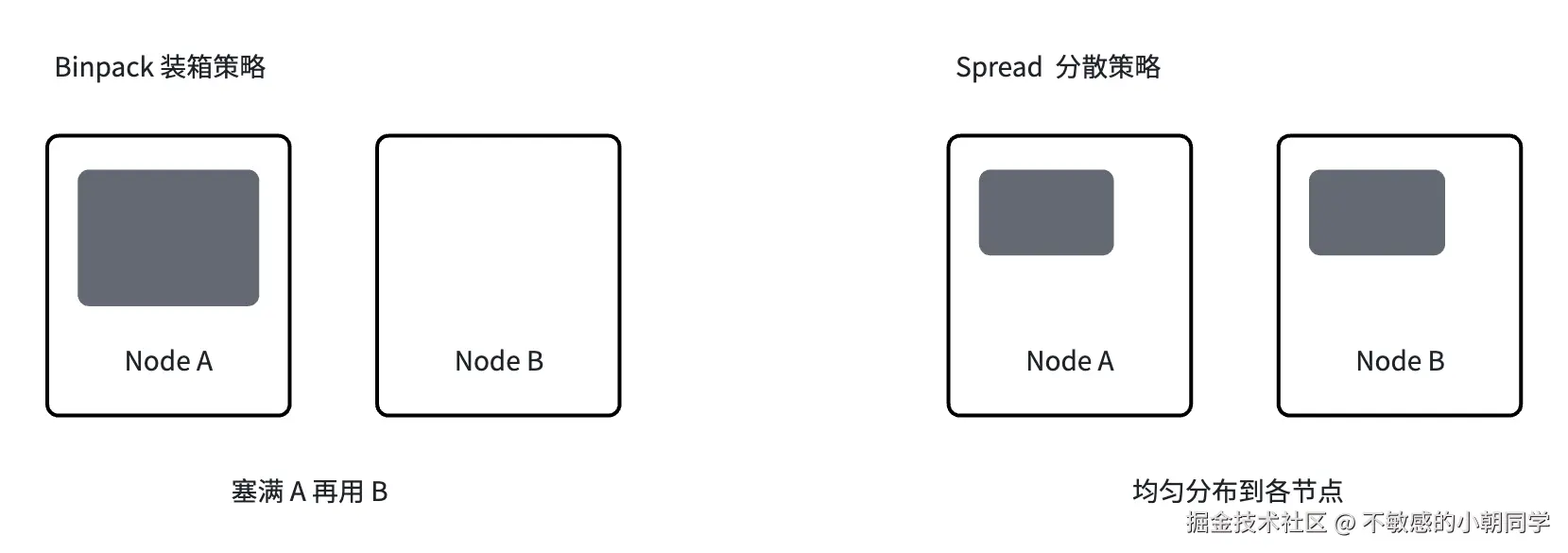
Binpack 插件
Binpack 也称为装箱:核心特点就是尽量把 Pod 集中调度到已经有负载的节点上,而不是分散到空闲节点
主要作用如下
- 提高资源利用率:把节点尽量塞满,减少资源的碎片
- 节省成本:空闲节点可以回收(如果集群支持 AutoScaler 弹缩)
- 减少碎片化:避免每个节点都只用了一点点资源,导致大任务无法调度
Binpack(装箱)策略和 Spread(分散)策略对比如下:
配置
参考官网代码给出的一个配置选项
yaml
actions: "enqueue, reclaim, allocate, backfill, preempt"
tiers:
- plugins:
- name: binpack
arguments:
binpack.weight: 10 # 整个 binpack 插件的总权重,影响最终打分的放大系数
binpack.cpu: 5 # CPU 维度的权重
binpack.memory: 1 # 内存维度的权重
binpack.resources: nvidia.com/gpu, example.com/foo # 声明额外参与打分的扩展资源
binpack.resources.nvidia.com/gpu: 2 # GPU 维度的权重
binpack.resources.example.com/foo: 3 # 自定义资源 foo 的权重仔细看打分函数
go
// ResourceBinPackingScore calculate the binpack score for resource with provided info
func ResourceBinPackingScore(requested, capacity, used float64, weight int) (float64, error) {
if capacity == 0 || weight == 0 {
return 0, nil
}
usedFinally := requested + used
if usedFinally > capacity {
return 0, fmt.Errorf("not enough")
}
// 这里的 usedFinally 会加上 used 的量,所以使用率越高最后选中的概率就越大
score := usedFinally * float64(weight) / capacity
return score, nil
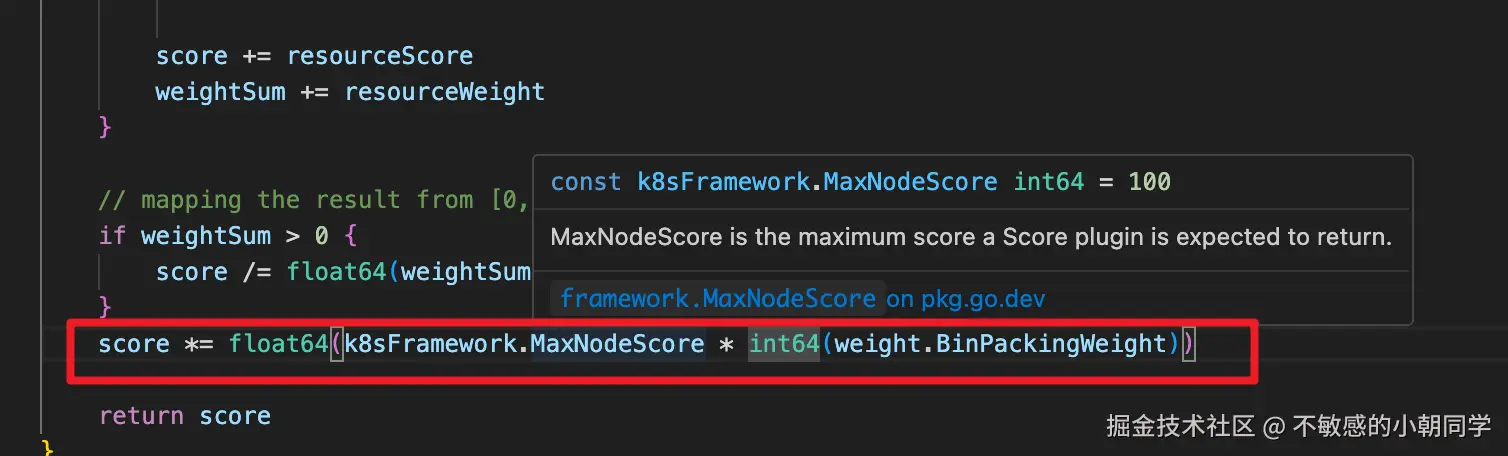
}对每种资源:score = (已用 + 本次请求) / 节点总量 × 该资源权重。使用率越高,分数越高
各资源加权得分求和之后,再除以权重的总和,归一化到 0,1
然后再乘以 MaxNodeScore(100) × BinPackingWeight(10),得到最终节点分数
举例
假设某节点有 8 核 CPU、16Gi 内存、4 张 GPU,当前已用 4 核 CPU、8Gi 内存、2 张 GPU。一个 Pod 请求 2 核 CPU、2Gi 内存、1 张 GPU
| 资源 | (已用+请求)/总量 | 权重 | 加权得分 |
|---|---|---|---|
| CPU | (4+2)/8 = 0.75 | 5 | 0.75 × 5 = 3.75 |
| Memory | (8+2)/16 = 0.625 | 1 | 0.625 × 1 = 0.625 |
| GPU | (2+1)/4 = 0.75 | 2 | 0.75 × 2 = 1.5 |
那么算得的 weightSum = 5 + 1 + 2 = 8
归一化得分 = (3.75 + 0.625 + 1.5)/ 8 = 0.734
最终得分 = 0.734 × 100 × 10 = 734
OnSessionOpen
go
func (bp *binpackPlugin) OnSessionOpen(ssn *framework.Session) {
...
nodeOrderFn := func(task *api.TaskInfo, node *api.NodeInfo) (float64, error) {
binPackingScore := BinPackingScore(task, node, bp.weight)
klog.V(4).Infof("Binpack score for Task %s/%s on node %s is: %v", task.Namespace, task.Name, node.Name, binPackingScore)
return binPackingScore, nil
}
if bp.weight.BinPackingWeight != 0 {
ssn.AddNodeOrderFn(bp.Name(), nodeOrderFn)
} else {
klog.Infof("binpack weight is zero, skip node order function")
}
}主要是实现了 nodeOrderFn 的扩展方法
OnSessionClose
scss
func (bp *binpackPlugin) OnSessionClose(ssn *framework.Session) {
}不需要实现 SessionClose 方法
Action 逻辑
所有的 Action 都会实现一个共同的接口
scss
// Action is the interface of scheduler action.
type Action interface {
// The unique name of Action.
Name() string
// Initialize initializes the allocator plugins.
Initialize()
// Execute allocates the cluster's resources into each queue.
Execute(ssn *Session)
// UnInitialize un-initializes the allocator plugins.
UnInitialize()
}
// Action management
var actionMap = map[string]Action{}
// RegisterAction register action
func RegisterAction(act Action) {
pluginMutex.Lock()
defer pluginMutex.Unlock()
actionMap[act.Name()] = act
}
// GetAction get the action by name
func GetAction(name string) (Action, bool) {
pluginMutex.RLock()
defer pluginMutex.RUnlock()
act, found := actionMap[name]
return act, found
}Volcano 实际运行的时候就通过这个配置文件的 Action 的顺序及其加载所有的 Action,依次来确定执行的先后顺序
go
actionNames := strings.Split(schedulerConf.Actions, ",")
for _, actionName := range actionNames {
if action, found := framework.GetAction(strings.TrimSpace(actionName)); found {
actions = append(actions, action)
} else {
klog.Errorf("Failed to find Action %s, ignore it", actionName)
}
}