一、需求和技术
1.企业对于大模型的不同类型个性化需求
提高模型对企业专有信息 的理解、增强模型再特定行业 领域的知识------SFT**(有监督微调)**Supervised Fine-Tuning:通过提供的人工标注的数据,进一步进行训练预训练模型,让模型能够精准的处理特定任务
提供个性化 和互动性强 的服务------RLHF**(强化学习)**(Reinforcement Learning from Human Feedback:DPO(Direct Preference Optimization)核心思想:通过人类对比选择 直接优化生成模型,使其产生更加符合用户需求的结果;调整幅度更大。
PPO(Proximal Policy Optimization):通过奖励信号来渐进式调整模型的行为;调整幅度小
提高模型对专有服务的理解、增强模型在特定领域的知识、获取和生成最新的、实时的信息 ------RAG**(检索增强生成)**(Retrieval-Augmented Generation)
2.微调与RAG的选择取决于具体需求、资源限制和应用场景。以下是关键考量因素:
数据可用性:微调需要大量高质量标注数据,适用于特定领域或任务。数据不足时效果受限。 RAG依赖外部知识库检索,适合动态或开放域信息需求,无需大量标注数据。
计算资源:微调需GPU资源训练模型,成本较高。适合长期稳定需求;能够直接提升模型固有能力;无需外部检索。 RAG推理时计算开销低,适合实时性要求高的场景。知识库更新无需重新训练模型。
知识更新频率 :微调模型知识固化,更新需重新训练。适合静态知识场景。 RAG通过更新检索库实时获取新知识。适合医疗、新闻等高频更新领域。RAG每次回答前耗时检索知识库;回答质量依赖于检索系统质量
任务复杂度:微调在封闭任务(文本分类、实体识别)表现更优。 RAG擅长开放生成任务(问答、摘要),通过检索增强事实一致性。
实现示例
微调代码框架(PyTorch):
python
from transformers import Trainer, TrainingArguments
training_args = TrainingArguments(output_dir='./results', num_train_epochs=3)
trainer = Trainer(model=model, args=training_args, train_dataset=train_data)
trainer.train()RAG流程伪代码:
python
retriever = VectorRetriever(index=knowledge_base)
generator = TransformerGenerator()
def answer(query):
contexts = retriever.search(query)
return generator.generate(query, contexts)总结:少量企业私有知识:微调和RAG都做;资源不足优先RAG
需要动态更新数据:RAG
大量垂直领域数据:微调
SFT:1.预训练模型(基座模型):在大量数据上训练过的模型,微调前需要下载的开源模型。它具备了通用知识的能力,能够解决常见的任务,在此基础上进行微调以适应特定领域任务。
3.微调算法分类
1.全参数微调:对整个预训练模型进行微调,更新全部参数。
优点:每个参数都调整,能够得到最佳性能;适应不同的工作场景
缺点:需要大量的计算资源并且容易出现过拟合
2.部分参数微调:只更新模型的部分参数
优点:减少了计算成本;降低过拟合风险;小的代价获得较好的模型
缺点:无法达到最佳性能
代表算法:lora
4.lora微调算法
低秩自适应:

h:模型的输出
W0:预训练模型的原始权重,是一个全秩矩阵
x:模型输入
*W0:微调后原始权重的变化,也是一个全秩矩阵,大小和W0相同
BA:两个低秩矩阵B和A,它们的乘积BA表示对原始权重的微调变化量*W0
:全参数微调输出
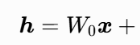
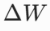 :全参数微调输出
:全参数微调输出
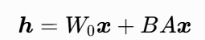 :用LoRA方法对部分参数微调输出
:用LoRA方法对部分参数微调输出
Lora核心:让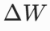 =BA,且BA存储数据量远远小于
=BA,且BA存储数据量远远小于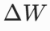 ------矩阵的低秩分解
------矩阵的低秩分解
线性代数中:100*100=2*100*2 400<10000
Lora训练后进行权重合并
5.Llama-factory 简介
Llama-factory 是一个专注于大语言模型(LLM)微调和推理的开源工具库,旨在简化模型适配特定任务的过程。其核心功能包括高效参数微调(如 LoRA、QLoRA)、分布式训练支持,以及针对消费级硬件的优化。(能够实现0代码的微调)
核心特性
高效微调技术
支持低秩适配(LoRA)、量化低秩适配(QLoRA)等方法,显著降低显存占用,使得在单张消费级显卡(如 RTX 4090)上微调数十亿参数模型成为可能。
多框架兼容
深度集成 Hugging Face Transformers 和 PyTorch,提供统一的接口管理模型加载、数据预处理和训练流程。
任务定制化
覆盖文本生成、对话系统、代码补全等场景,支持自定义数据集和评估指标,适配领域特定需求。
硬件优化
通过梯度检查点、混合精度训练等技术提升训练效率,支持多节点分布式训练以扩展至更大规模模型。
典型应用场景
领域适配
在医疗、法律等专业领域,通过微调提升模型对术语和上下文的理解能力。
轻量化部署
结合量化技术,将模型部署至边缘设备或资源受限环境。
研究实验
快速验证不同微调策略(如适配器架构、提示微调)对模型性能的影响。
安装与示例
通过 pip 安装最新版本:
bash
pip install llama-factory以下代码展示基于 LoRA 的微调流程:
python
from llama_factory import Trainer, load_model
model = load_model("meta-llama/Llama-2-7b", use_lora=True)
trainer = Trainer(
model,
train_dataset="your_dataset",
eval_dataset="your_eval_data"
)
trainer.train()性能对比
在相同硬件条件下,与传统全参数微调相比:
| 方法 | 显存占用 | 训练速度 |
|---|---|---|
| 全参数微调 | 24GB | 1x |
| LoRA | 8GB | 1.2x |
| QLoRA | 6GB | 0.9x |