GitHub :https://github.com/Lanqingsong/rag-from-scratch
技术栈:LangChain · DeepSeek · FAISS · 阿里云 DashScope · Flask · rank-bm25 · SearXNG
前言
一直以来我想创建一个属于自己的私有知识库,和一般知识库不同,我还希望能够连接互联网让AI能判断我的知识库内容并且提供有效补充,之前也尝试了不少开源知识库,感觉从灵活性来说还是自己搭建下来更方便,因为现在编写代码借助AI也很方便,所以就自己搭了一个基于PYTHON的完整知识库,通过webui调用,
最后的效果是这样的
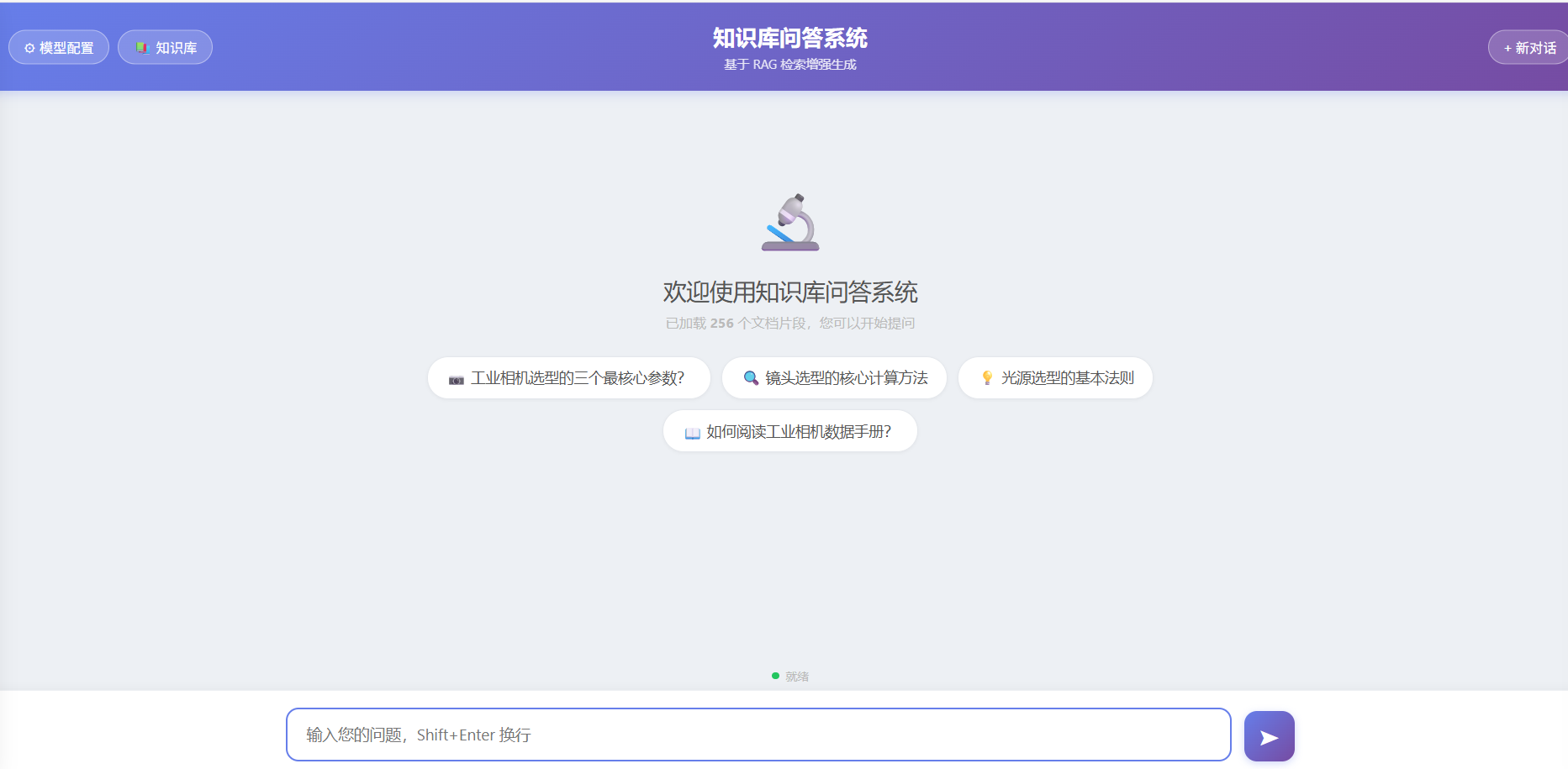
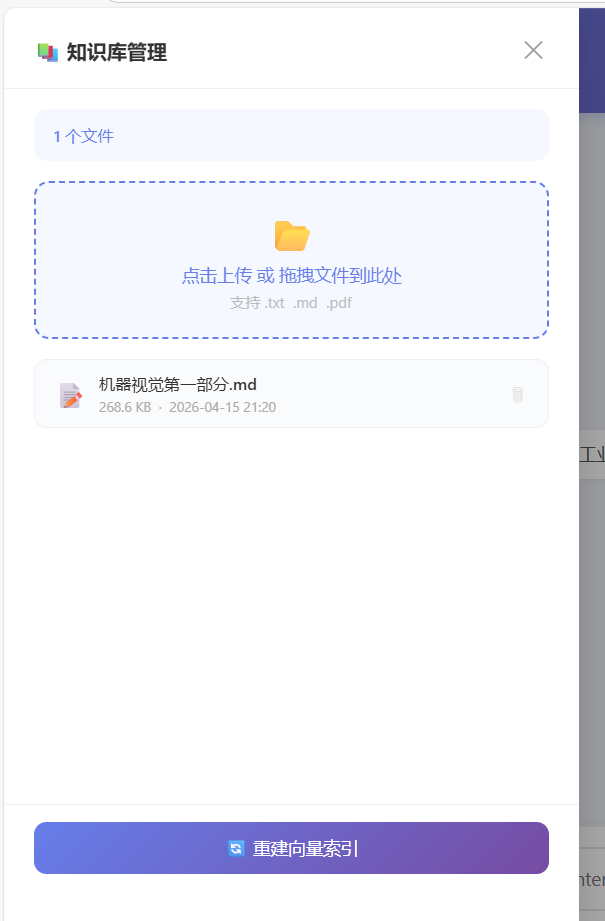
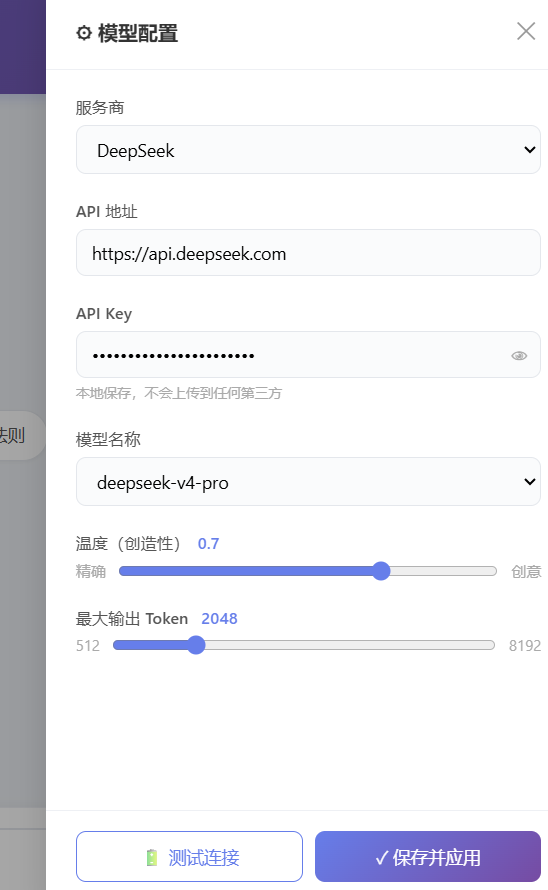
1. 为什么要自己搭,而不用 Dify / Coze
市面上已经有很多现成的 RAG 工具,Dify、Coze、FastGPT 都能快速搭出一个知识库问答。如果你的需求很简单,这些工具完全够用。但有几类场景它们满足不了:
数据不能出服务器。 企业内网的技术手册、工艺参数、设备档案,涉及内部数据的文档通常不适合上传到任何第三方平台。本项目完全本地运行,唯一的出站请求是 LLM API 调用,向量库和文档文件都在本地。
文档结构需要精准切分。 Dify 的文档处理是固定逻辑,切出来的 chunk 不一定尊重文档的语义边界。对于技术手册、参数表、Q&A 文档,如果切割点落错了,型号和它的规格参数就在两个 chunk 里,检索必然失败。自己写,切分策略完全可控。
检索逻辑需要干预。 向量检索对专有名词天生不敏感,BM25 关键词检索可以补这个缺,但 Dify 没有暴露这层控制。如果召回效果不好,你看不到内部发生了什么,也改不了。
想真正理解 RAG 怎么工作。 点按钮搭出来的系统,你只知道"RAG 是这么用的"。从代码层面搭一遍,你才能说清楚为什么要用 RRF 而不是直接取 top-K、为什么 Reranker 比 Embedding 精度高、为什么流式输出要缓冲 40 个字符再推给前端。这些是面试和实际工作中真正有价值的东西。
项目同时附带 19 篇教学文档(lessons/ 目录),每篇对应一个核心模块,讲原理、讲代码、讲设计动机,适合想系统学习 RAG 工程实现的人。
2. 系统整体架构
在讲具体的技术问题之前,先把系统的全貌交代清楚,后面的内容会更容易理解。
2.1 系统做什么
用户上传自己的文档(.md / .txt / .pdf),系统自动切分、向量化、建索引。之后用户用自然语言提问,系统检索相关内容,交给 LLM 生成回答,支持流式输出和多轮对话。
除了本地知识库,系统还可以接入 SearXNG 自托管搜索,在本地知识库无法回答时自动联网补充,两路结果合并后一起送给 LLM。
2.2 技术选型
| 组件 | 选型 | 原因 |
|---|---|---|
| LLM | DeepSeek | 中文理解好,兼容 OpenAI SDK,价格合理 |
| Embedding | 千问 text-embedding-v2 | 中文语料训练,DashScope 统一调用 |
| Reranker | 千问 qwen3-rerank | 与 Embedding 同一生态 |
| 向量库 | FAISS | 纯文件,无需启动服务,C++ 实现速度快 |
| 关键词检索 | rank-bm25 | 轻量纯 Python,无外部依赖 |
| LLM 框架 | LangChain | LCEL 管道语法,MultiQueryRetriever |
| Web 框架 | Flask | SSE 流式输出简洁,现有代码同步友好 |
| 网络搜索 | SearXNG | 自托管,不依赖第三方 API 限额 |
2.3 一次问答的完整流程
用户提问
↓
[对话引用检测] ── 是"你刚才说的"类问题 → 跳过检索,走对话历史
↓
并行检索
├── FAISS 语义检索(+ MultiQueryRetriever 查询改写)
├── BM25 关键词检索
└── SearXNG 网络搜索(可选)
↓
RRF 融合 FAISS + BM25 两路结果
↓
Qianwen Reranker 精排
↓
LangChain LCEL 链(Prompt 注入 → DeepSeek → StrOutputParser)
↓
SSE 流式推送给前端每一层都有它存在的具体原因,后面逐一展开。
3. 文档切分:决定召回质量的第一步
3.1 为什么切分比 chunk_size 更重要
很多教程把注意力放在 chunk_size 设多大上。这个参数有影响,但对于结构化程度高的技术文档,在哪里切比切多大重要得多。
举个例子。一份相机技术规格文档结构是这样的:
## GigE Vision 接口规格
- 传输带宽:1 Gbps(GigE)/ 10 Gbps(10GigE)
- 触发延迟:< 1 μs
- 支持协议:GigE Vision 2.0如果按固定字符数切割,标题和它下面的参数可能被切成两个 chunk。用户搜"GigE 触发延迟是多少",召回的 chunk 里没有数值,LLM 只能回答"未找到相关信息"。切错了,后面再怎么优化也是在填坑。
3.2 五种切分策略
项目实现了五种策略,每个知识库子目录可以通过 kb_config.json 独立配置:
3.2.1 Markdown 标题切割
按 ## / ### / #### 标题行切割,每个标题和它下面的内容作为一个完整 chunk。超长 chunk 自动按下一级标题二次切割,最终回退到递归字符切割。
适用于有良好 Markdown 结构的技术手册和教程。
json
{"strategy": "markdown", "heading_level": 3, "chunk_size": 1000}3.2.2 自定义正则边界
用户提供一个正则表达式,匹配每个 chunk 的起始行。适用于 1.1 焦距计算、Q12: 如何标定相机 这类有明确逻辑边界但不是 Markdown 标题的文档。
json
{"strategy": "regex", "pattern": "\\d+\\.\\d+\\s+[^\\n]+"}3.2.3 语义切割
计算相邻句子的 Embedding 余弦相似度,在相似度骤降处(话题切换点)切割。适合完全无结构的自由文本。调用次数多、成本高,代码里有异常保底,失败时自动回退到递归切割。
json
{"strategy": "semantic", "threshold_type": "percentile", "threshold_value": 95}3.2.4 递归字符切割
LangChain 的 RecursiveCharacterTextSplitter,按 \n\n → \n → 。 → ; → 空格 层级递归切割,任何文档的最终保底策略。
3.2.5 Auto 自动探测
不想手写配置时,auto 策略会检测每份文档的结构并自动选策略:有 3 个及以上 ### 标题 → markdown(heading_level=3);有编号格式行 → regex;否则 → recursive。默认配置就是 auto。
3.3 per-directory 配置
不同目录的文档格式往往不同,可以分别配置:
knowledge_base/
├── cameras/
│ ├── kb_config.json ← {"strategy": "markdown", "heading_level": 3}
│ └── basler_ace2.md
└── faq/
├── kb_config.json ← {"strategy": "regex", "pattern": "Q\\d+[.::]"}
└── common_questions.md4. 混合检索:为什么四层管道比单路向量检索强
4.1 向量检索的盲区
Embedding 模型的训练目标是语义相似度,它擅长把"相机分辨率"和"图像像素数量"映射到相近的向量位置。
但它有一个硬伤:对训练语料里低频的专有名词不敏感。型号编码"CS-040GX"、参数代码"GigE-X01-A",这些词在训练数据里极少出现,模型对它们几乎没有语义记忆,向量表示接近随机方向。用户搜这个型号,余弦相似度低于阈值,FAISS 返回 0 条结果。
这不是 Bug,是 Embedding 的设计特性。它擅长语义理解,不擅长精确字符匹配。
4.2 BM25 补刀关键词盲区
BM25 是基于词频统计的检索算法,它的逻辑和 Embedding 完全不同:一个词在文档里出现,就得分;越罕见的词,权重越高;文档越长,归一化惩罚越重。
score ( D , Q ) = ∑ i IDF ( q i ) ⋅ f ( q i , D ) ⋅ ( k 1 + 1 ) f ( q i , D ) + k 1 ⋅ ( 1 − b + b ⋅ ∣ D ∣ avgdl ) \text{score}(D, Q) = \sum_i \text{IDF}(q_i) \cdot \frac{f(q_i, D) \cdot (k_1 + 1)}{f(q_i, D) + k_1 \cdot (1 - b + b \cdot \frac{|D|}{\text{avgdl}})} score(D,Q)=i∑IDF(qi)⋅f(qi,D)+k1⋅(1−b+b⋅avgdl∣D∣)f(qi,D)⋅(k1+1)
对"CS-040GX"这个查询,BM25 直接字符匹配,精确找到包含这个型号的文档,跟语义理解没有任何关系。
两路并行检索,覆盖的场景互补:语义模糊的问题靠 FAISS,精确名词靠 BM25。
4.3 RRF 把两路结果合并
FAISS 和 BM25 各自返回一个排序列表,但两者的打分量纲完全不同,不能直接合并。RRF(Reciprocal Rank Fusion)的思路是只用排名不用分数:
python
def _rrf_merge(self, faiss_docs, bm25_docs, k, rrf_k=60):
scores = {}
doc_map = {}
for rank, doc in enumerate(faiss_docs):
key = doc.page_content[:80]
scores[key] = scores.get(key, 0) + 1.0 / (rrf_k + rank + 1)
doc_map[key] = doc
for rank, doc in enumerate(bm25_docs):
key = doc.page_content[:80]
scores[key] = scores.get(key, 0) + 1.0 / (rrf_k + rank + 1)
doc_map[key] = doc
sorted_keys = sorted(scores, key=lambda x: scores[x], reverse=True)
return [doc_map[key] for key in sorted_keys[:k]]rrf_k=60 来自 Cormack 等人 2009 年的论文,实验发现这个值在多种任务上稳健。两路都命中的文档得分叠加,天然排到前面;只有一路命中的也能参与排名。
4.4 Reranker 解决"Lost in the Middle"问题
即使召回准了,还有一个问题:把 10 条文档都塞给 LLM,LLM 对开头和结尾的注意力更高,中间的内容容易被忽略。这是斯坦福 2023 年 Lost in the Middle 论文里验证的现象------正确答案在第 6~9 条时,LLM 的准确率比放在第 1 条低约 30%。
解法是在送给 LLM 之前加一层精排,把 10 条压缩到 3 条,让 3 条里都是高相关的内容。
Reranker 用的是交叉编码器 :把查询和文档拼在一起送进同一个模型,每一层 attention 都能看到两者的交互,直接输出一个精确的相关性分数。Embedding 检索用的是双编码器:查询和文档各自独立编码,精度受限于"两者编码时互不可见"这个约束。
代价是慢:每个候选文档都要重新推理一次,不能预计算。所以 Reranker 放在最后一步,候选集已经缩小到 10~20 条时再精排,这样开销可控:
python
if self.reranker and len(results) > 1:
try:
results = self.reranker.rerank_documents(query, results)
except Exception as e:
print(f"Rerank 失败,使用原始结果: {e}")失败时降级到原始 RRF 结果,不影响主流程。
4.5 MultiQueryRetriever:一个问题变三个角度
用户表述问题的方式多种多样,"GigE 接口最大带宽"和"千兆以太网相机传输速率上限"在语义上等价,但向量空间里距离未必很近。MultiQueryRetriever 让 LLM 把原始问题改写成 3 个不同角度的查询,三路并行检索取并集,命中率对多义性问题提升明显。
5. 多轮对话的两个工程问题
5.1 对话引用识别
用户问完"镜头焦距怎么计算",接着问"那工作距离呢"。如果拿"那工作距离呢"去检索知识库,什么都找不到------这个问题的语义锚点在对话历史里,不在知识库里。
在进入检索之前先做一个轻量判断:
python
_DIALOGUE_REF = re.compile(
r'(上一个|上一条|刚才|之前(说|问|讲|提到?)?|你说|你提到|'
r'你刚|继续|你上面|你前面|解释一下刚|你说的)',
re.IGNORECASE
)
def _is_dialogue_ref(query: str, history: list) -> bool:
if not history:
return False
if _DIALOGUE_REF.search(query):
return True
if len(query) <= 15 and re.search(r'(这个|那个|它|这些|那些)', query):
return True # 短问题 + 指代词 → 大概率引用历史
return False命中时直接跳过检索,带完整对话历史发给 LLM。
这个正则方案有误检和漏检,更精确的做法是用小模型做意图分类,但那意味着每次请求多一次 LLM 调用。对于当前体量,接受少量错误、在日志里记录,后续根据频率再决定是否升级。
5.2 Token 预算管理
对话历史不能无限累积。截断策略是从最新一轮往前截,超出预算就停:
python
items = list(reversed(history_data or []))
total_tokens = 0
selected = []
for item in items:
t = _count_tokens(item.get('content', ''))
if total_tokens + t > Config.MAX_HISTORY_TOKENS:
break
selected.insert(0, (item['role'], item['content']))
total_tokens += t为什么从最新往前截,而不是从最早往后保留:距离当前问题最近的对话轮次,对理解当前问题的价值最高。当历史过长时,优先丢弃早期的轮次。Token 计数用 tiktoken,不可用时降级到字符数 ÷ 2(中文约 2 字/token)。
6. 网络搜索与熔断器
6.1 并行检索,不串行等待
知识库检索和网络搜索并行发起,互不阻塞:
python
with ThreadPoolExecutor(max_workers=2) as ex:
kb_f = ex.submit(kb.search, query, Config.TOP_K_RESULTS, llm.llm)
web_f = ex.submit(web_searcher.search, query)
return kb_f.result(timeout=20), web_f.result(timeout=15)网络搜索用 SearXNG 自托管实例,不依赖任何第三方 API 限额。
6.2 熔断器防止搜索服务拖慢主流程
SearXNG 不稳定时,如果每次都等到超时,整个响应会被拖慢十几秒。熔断器在连续失败 3 次后自动"断路",后续请求直接跳过网络搜索,60 秒后自动尝试恢复:
python
class _CircuitBreaker:
def __init__(self, failure_threshold=3, recovery_timeout=60):
self._failures = 0
self._threshold = failure_threshold
self._timeout = recovery_timeout
self._opened_at = None
@property
def is_open(self):
if self._opened_at is None:
return False
if time.time() - self._opened_at > self._timeout:
self._opened_at = None
self._failures = 0
return False
return True搜索失败时还有指数退避重试(1s、2s、4s),三次都失败才触发熔断器计数。这是 Martin Fowler 的 Circuit Breaker 模式在 RAG 场景里的应用。
7. 流式输出的两个细节
7.1 过滤开头套话
LLM 经过 RLHF 训练后,有参考资料时习惯以"根据知识库内容..."开头。这是训练强化的习惯,改 Prompt 能缓解但不能根治------不同模型、不同温度下这个行为强度不同。
SSE 是逐 token 推送的,第一个 token 到就直接出去了。要拦截开头,需要在服务端设缓冲区,等攒够 40 个字符再决定要不要清洗:
python
BUF_SIZE = 40 # 足够覆盖最长的"根据..."开头
buf = ""
buf_flushed = False
for chunk in llm.stream(...):
if not chunk:
continue
if not buf_flushed:
buf += chunk
if len(buf) >= BUF_SIZE:
buf = _BAD_OPENER.sub('', buf, count=1).lstrip()
buf_flushed = True
yield _sse({'type': 'token', 'content': buf})
else:
yield _sse({'type': 'token', 'content': chunk})40 个字符是经验值,中文"根据您提供的知识库内容,"约 15 个字,留 40 个缓冲足够判断、又不会让用户感知到延迟。
7.2 参考资料先推,再流式输出
SSE 事件有 type 字段:refs 是参考来源,token 是 LLM 输出的每个 chunk,done 是最终 Markdown HTML。
检索一完成就立刻推 refs,不等 LLM 开始生成。用户在 LLM 还在生成答案时,就已经能看到参考来源是哪些文档。这个时序设计让响应体感更流畅。
8. Prompt 版本管理
8.1 为什么 Prompt 需要版本控制
Prompt 工程是反复迭代的过程,改动频率比代码高。某次为了改善"参数比较类"问题修改了 system.txt,几天后发现另一类问题质量下降了,想回到之前的版本------如果只有一个被反复覆盖的文件,什么记录都没有。
8.2 三层方案
存档与回滚:每次修改前手动存档,文件名带时间戳,可随时激活历史版本,立即生效。
bash
POST /api/prompts/save_version # 存档当前版本
POST /api/prompts/activate/system_20260528_143022.txt # 激活历史版本变量插值 :system.txt 里用 {``{domain}}、{``{user_type}} 占位,variables.json 里存实际值。调整定制内容不需要改主文件,减少版本分叉。
热重载 :POST /api/prompts/reload 重建 LLM 链,不需要重启 Flask 进程,对正在进行的会话无影响。
9. 几个架构决策的取舍
9.1 FAISS vs ChromaDB
ChromaDB 有 Web UI、更方便的持久化和元数据过滤。选 FAISS 的原因:向量库是本地两个文件(.faiss + .pkl),无需启动任何服务,整个知识库打包即可迁移;C++ 实现,几千个向量的检索延迟在毫秒级。代价是没有在线增量更新,修改文档需要重建索引。对当前场景,这个代价可以接受。
9.2 Flask vs FastAPI
SSE 流式输出在 Flask 里只需要 Response(generator, mimetype='text/event-stream'),极简。FastAPI 需要装 sse-starlette,并且项目里大量模块是同步的(FAISS 检索、BM25 检索),用异步框架需要 run_in_executor 包装,得不偿失。如果未来要支持高并发,迁移到 FastAPI 是合理的升级路径。
9.3 LangChain 的争议与取舍
LangChain 接口不稳定、版本间 breaking change 多------这个批评是真实的,项目里就踩过 langchain_classic 的导入问题。但它在这个项目里提供了三个真实价值:LCEL 管道语法(切换 LLM 只改一个对象)、MultiQueryRetriever(查询改写现成实现)、SemanticChunker(语义切分现成实现)。接受它的前提是:只用具体功能,核心检索逻辑(FAISS + BM25 + RRF + Reranker)自己控制,不把整个应用架在 LangChain 的高层抽象上。
10. 总结
这套系统的每一层都对应一个具体问题:
- 向量检索找不到型号编码 → 加 BM25
- BM25 和 FAISS 打分量纲不同 → 用 RRF 融合排名
- LLM 忽视中间文档 → 加 Reranker 精排压缩候选集
- 对话引用触发无效检索 → 进检索前判断意图
- 历史记录超出上下文窗口 → 从最新往前按 Token 数截取
- 流式输出开头有废话 → 服务端缓冲 40 字符过滤
- SearXNG 不稳定拖慢响应 → 熔断器 + 指数退避重试
- Prompt 改了改不回来 → 存档 + 热重载
。如果你在搭类似系统并且遇到了其中某个问题,希望这里的思路对你有帮助。
完整代码和 19 篇教学文档在 GitHub:
本项目由 lanqingsong874953727@outlook.com 与 AI 助手协作开发。
编写时间:2026 年 5 月 28 日