消息在kafka当中最终存放在一个一个的segment当中,而segment由两个部分组成,一个是log文件,一个是index文件。
如果消费者需要查找指定的指定的offset这样的消息,那么是怎么查找消息的?
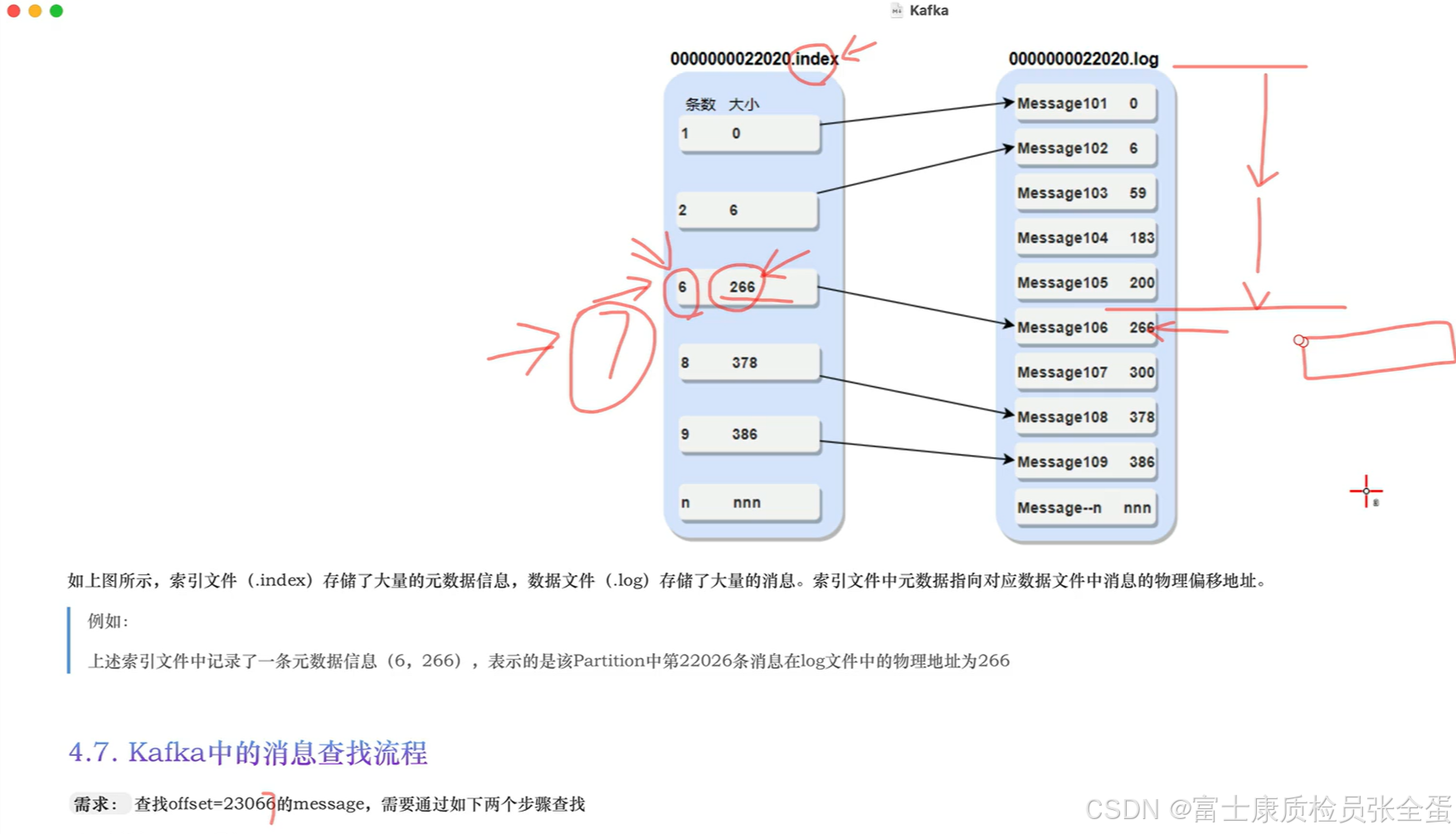

如果查找的消息是23067,那么偏移量出来得到7,很显然7不在index里面,那么找到比它小的,那就是6,那么就可以定位到第六条消息的位置,而每个消息的头部都是记录着大小,可以叠加大小就可以找到之后的信息。

如果在segment中快速定位到消息?先通过segment的名字定位segment file,在哪个文件当中。之后再去index文件当中找物理偏移量,物理地址,找到之后再往下顺序读取就行了。
