1. CLI 看到的任务列表是怎么样的
Claude Code CLI 里的任务列表,是当前请求的进度视图。它通常由多条任务项组成,每条任务项对应一个可以被跟踪的步骤。
一个典型任务列表可以理解成这样:
text
□ 修改登录错误提示
□ 补充登录错误提示测试当模型开始处理第一项时,状态会变化:
text
◐ 修改登录错误提示
□ 补充登录错误提示测试第一项完成后,又会变成:
text
✓ 修改登录错误提示
□ 补充登录错误提示测试所以在单 Agent CLI 会话里,用户看到的不是一个后台任务调度队列,而是一份当前请求的结构化进度记录。它表达三个核心信息:
| 信息 | 含义 |
|---|---|
| 任务标题 | 当前请求被拆成了哪些步骤 |
| 任务状态 | 每一步是待处理、进行中还是已完成 |
| 当前进度 | 模型现在推进到哪一步 |
任务状态一般可以抽象成三类:
text
pending 待处理
in_progress 进行中
completed 已完成这份任务列表的作用是让复杂请求变得可跟踪。它不直接修改代码、不运行命令,也不自动推进下一步;它只是保存"模型认为当前工作应该如何完成"的进度状态。
这篇文章只讨论单个 Claude Code CLI 会话里,模型如何通过任务工具维护用户看到的任务列表。团队协作、swarm、external tasks mode 里的共享任务队列、任务认领和跨进程调度不在本文范围内;那些场景会复用同一套任务数据结构,但职责比这里讲的单 Agent 进度视图更宽。
2. 任务列表是如何生成和更新的
任务列表由模型通过任务工具维护。模型不是在脑子里默默记住进度,而是通过工具把进度写成结构化状态。
这里的任务工具不是用户在终端里手动输入的 CLI 命令,而是模型在一次请求执行过程中可以调用的内部工具。CLI 里看到的列表,是这些工具读写后的任务状态再被界面渲染出来的结果。
这套工具可以分成四类。
| 工具 | 作用 |
|---|---|
TaskCreate |
创建一个新的任务项,写入标题、描述、状态等字段 |
TaskUpdate |
更新任务项,例如标记进行中、标记完成、修改描述、设置依赖 |
TaskList |
查看当前任务列表摘要 |
TaskGet |
查看某个任务的完整详情 |
一个复杂请求进来后,模型会先判断是否需要拆分。如果需要,它会调用 TaskCreate 创建任务项。创建出来的任务默认是待处理状态。
例如用户说:
text
帮我修改登录错误提示,并补一个测试。模型可能创建两个任务:
text
#1 修改登录错误提示
#2 补充登录错误提示测试接下来模型开始处理第一个任务,就调用 TaskUpdate 把它标记为 in_progress。修改完成并确认结果后,再调用 TaskUpdate 把它标记为 completed。
如果模型需要重新确认当前还有哪些任务,可以调用 TaskList。如果某个任务的摘要不够,需要读取完整描述,可以调用 TaskGet。
这几个工具共同完成一件事:让模型能够生成、读取和更新任务列表状态。
但这些工具本身不负责判断"代码是否真的改好了",也不负责判断"现在是否该继续下一项"。这些判断仍然由模型根据工具返回结果来完成。
更细一点看,TaskCreate 会把新任务写成 pending 状态,并保存 subject、description、activeForm、metadata 等字段;TaskUpdate 会按任务 ID 读取现有任务,再合并要修改的字段,比如 status、owner、blocks、blockedBy;TaskList 只返回列表页需要的摘要信息;TaskGet 才返回单个任务的完整描述和依赖关系。
任务列表的维护过程可以概括成:
text
创建任务项
-> 标记当前任务进行中
-> 执行实际工作
-> 根据结果更新任务状态
-> 必要时读取任务列表决定下一步2.1 任务状态如何持久化
在实现层,任务列表不是只存在于模型上下文里的自然语言文本,而是落到本地 JSON 文件里的结构化状态。
任务会写到配置目录下的 tasks 子目录中,路径为:
text
<claude-config-home>/tasks/<taskListId>/<taskId>.json每个任务对应一个 JSON 文件。一个任务对象大致可以理解成这样:
json
{
"id": "1",
"subject": "修改登录错误提示",
"description": "把登录失败时的提示改得更清楚",
"activeForm": "修改登录错误提示",
"status": "in_progress",
"blocks": [],
"blockedBy": [],
"metadata": {}
}创建任务时,系统会在任务列表级别加锁,读取已有任务文件和 .highwatermark,计算下一个任务 ID,然后写入新的 <taskId>.json。.highwatermark 用来记住曾经分配过的最大 ID,避免任务被删除或列表 reset 后复用旧 ID。
更新任务时,系统会先确认任务文件存在,再对单个任务文件加锁,读取 JSON、合并字段、重新写回。这样做的目的不是让任务工具替模型决策,而是让任务状态成为一份模型可以反复读写、CLI 可以稳定渲染、长流程中也可以重新取回的外部进度记录。
3. 从用户输入到任务完成,发生了什么
用一个具体例子来看完整流程。
用户输入:
text
帮我修改登录错误提示,并补一个测试。模型会把这个请求拆成两个任务:
text
#1 修改登录错误提示
#2 补充登录错误提示测试然后模型按顺序推进:先修改实现,再补测试,最后汇总结果。
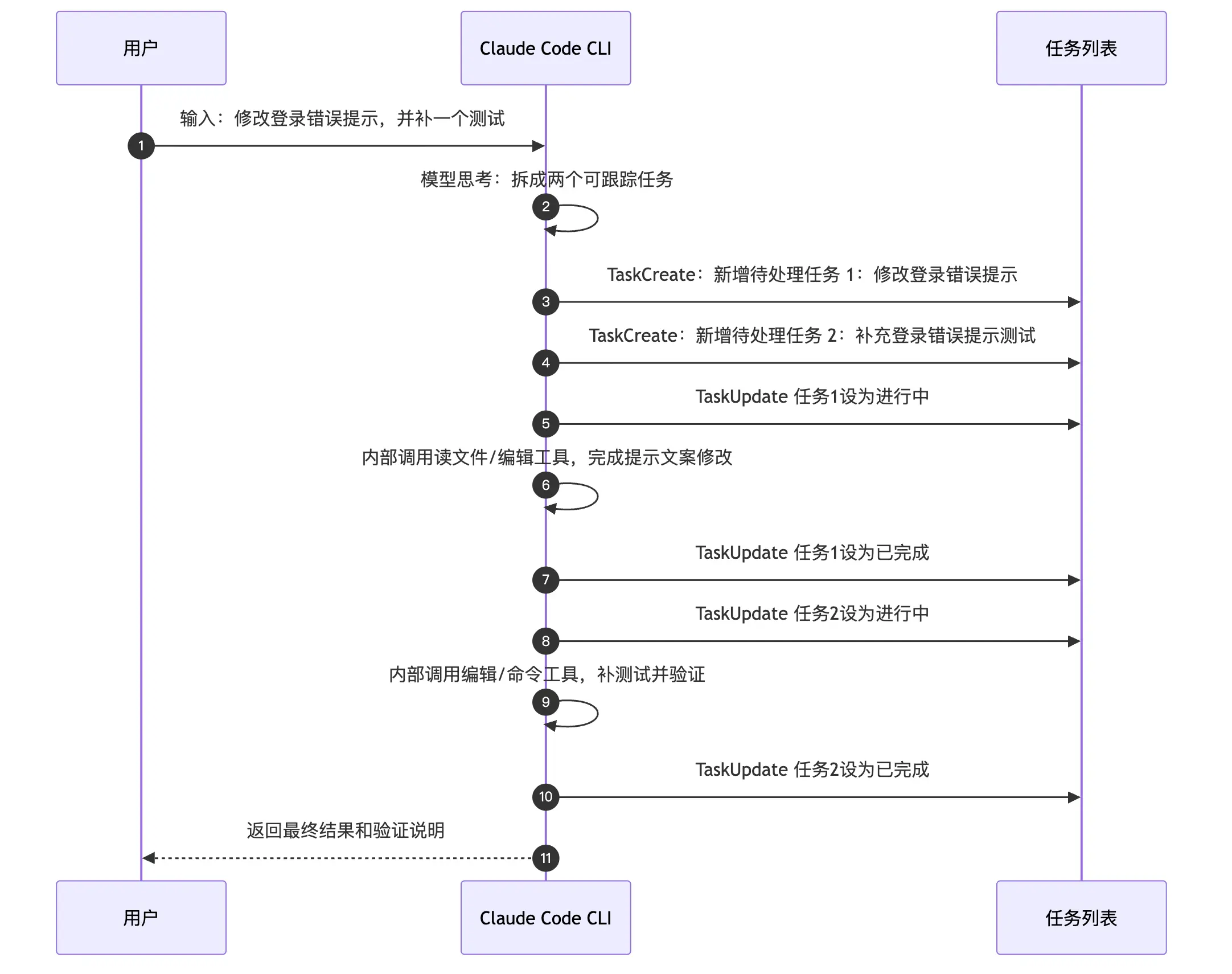
这张图里有几个关键点:
- 模型先理解请求,再决定是否拆成任务;不是所有请求都会生成任务列表。
TaskCreate只负责新增单个任务,所以两个任务对应两次创建。TaskUpdate负责推进状态:设为进行中、设为已完成。
3.1 任务列表和 Agent loop 的关系
任务列表经常让人误以为:只要里面还有未完成任务,Claude Code 就会自动继续执行。
要解释这个误解,先要看 Agent loop 是什么。一次请求不会只经历"模型回答一次"这么简单;更接近真实情况的是:模型先根据当前上下文决定下一步,如果它需要动作,就发出工具调用;CLI 执行工具,把结果收集回来,再和已有上下文一起交给模型,让模型继续判断下一步。
在这个循环里,任务列表只是可被模型调用和读取的一类工具状态,和读文件、改文件、运行命令一样,都属于模型可以借助的外部能力。它能影响模型判断,但不是 Agent loop 的驱动器。
Agent loop 的基本关系可以理解为:
text
模型决定下一步
-> 如果需要动作,就发出工具调用
-> Claude Code CLI 执行对应工具
-> 工具结果被收集起来
-> 组装成下一轮模型上下文
-> 模型再次决定下一步对应到源码里的核心分支,可以抽象成下面这段伪代码:
ts
while (true) {
const response = await llm.chat(messages) // 想:让模型决定下一步
if (response.toolCalls.length === 0) {
break // 模型认为任务完成了,没有工具要调
}
for (const toolCall of response.toolCalls) {
const result = await executeTool(toolCall) // 做:执行工具
messages.push(result) // 看:把结果加入上下文
}
}这段伪代码省略了错误恢复、上下文压缩、stop hook 等旁支,只保留和任务列表最相关的主线。
在这个循环里,任务列表工具只负责一件事:维护进度状态。
所以,在单 Agent 主循环里,任务列表不是 Agent loop 的驱动器,也不是后台调度器。它不会因为还有 pending 任务就自动触发下一步。
真正决定 Agent loop 是否继续的是:模型下一次输出的是工具调用,还是最终回复。
如果模型看到任务列表里还有未完成项,并决定继续处理,它会继续发出工具调用;如果模型认为事情已经完成,就会输出最终回复,Agent loop 也就结束。
3.2 如何判断是否有未完成的任务
任务列表里是否还有未完成任务,可以通过任务状态判断。
只要还有 pending 或 in_progress,就说明任务列表里仍然存在未完成项:
text
#1 completed
#2 in_progress这表示第一项完成了,第二项还在进行。
但这个判断本身有两种用途:
- 用于展示层。CLI 可以根据任务状态决定任务列表是否还需要展示、是否还需要继续监听变化、是否可以在全部完成后隐藏。
- 间接辅助模型决策
需要强调的是,执行层并不是这样工作的:
text
if 还有未完成任务:
自动继续 Agent loop真实情况并不是这样。更准确地说,任务列表状态会进入模型上下文,影响模型下一步输出;但 Agent loop 真正检查的是模型下一次响应里有没有工具调用。
也就是说,"是否继续"不是任务列表自己决定的。如果模型看完上下文后继续输出工具调用,Agent loop 就继续;如果模型没有输出工具调用,而是输出最终回复,Agent loop 就结束。
长上下文下模型忘记进度或产生幻觉怎么办
极端情况下,上下文很长,模型可能不再清楚当前任务列表的最新状态。比如它创建过两个任务,完成了第一个,但后续经过很多轮工具调用后,模型可能误以为第二个也已经处理完,或者忘记把第二个任务标记为进行中。
Claude Code 对这种情况有一个补偿机制:任务状态提醒。它的目的不是判断上下文够不够长,而是在长流程里定期把结构化任务状态重新放回模型视野,降低模型凭记忆猜进度的概率。
当系统发现模型已经有一段时间没有维护任务列表时,会把当前任务列表重新放回上下文,提醒模型检查进度。这里的"一段时间"不是按现实时间计算,也不是按上下文长度直接触发,而是按模型响应轮次计算:如果距离上次 TaskCreate / TaskUpdate 已经经过足够多轮,同时距离上次提醒也经过足够多轮,就可以生成一次 task_reminder。
这个补偿发生在 Agent loop 的中间位置:工具执行完成之后、下一轮模型调用之前。
更具体地说,一轮模型输出工具调用后,Claude Code 会先执行这些工具,并把工具结果收集起来。随后系统会检查是否需要补充上下文附件;如果满足任务状态提醒条件,就生成一条任务提醒附件,把当前任务列表放进去。最后,Claude Code 再把工具结果和这些附件一起组装进下一轮上下文,发起下一次模型调用。
继续用上一节的伪代码看,它不是在任务刚创建时立即提醒,也不是在最终回复之后提醒,而是在这里补偿:
ts
while (true) {
const response = await llm.chat(messages) // 想:让模型决定下一步
if (response.toolCalls.length === 0) {
break // 模型认为任务完成了,没有工具要调
}
for (const toolCall of response.toolCalls) {
const result = await executeTool(toolCall) // 做:执行工具
messages.push(result) // 看:把结果加入上下文
}
// 补偿点:工具调用完成后、下一轮模型调用前。
// 系统会在这里检查是否需要补充 task_reminder,
// 再把提醒一起放进下一轮上下文。
}这个提醒大致起到这样的作用:
text
当前还有任务列表状态。
如果这些任务仍然和当前工作相关,请考虑更新它们。它不会替模型完成判断,也不会强制模型继续执行。它只是把任务进度重新放回模型视野,让模型少依赖模糊记忆,多依赖刚刚注入上下文的结构化状态,从而降低长上下文中忘记进度或凭空补全进度的概率。
所以长上下文下的处理方式可以概括为:
text
任务列表保存状态
工具执行完成后,系统在进入下一轮模型调用前重新提醒
模型重新看到状态后决定是否继续或更新4. 总结
Claude Code 的任务列表实现,关键不在于"列出几个待办",而在于把任务进度从模型脑海里的临时判断,变成一份可以被创建、更新、读取的结构化状态。
这样做有三个直接结果。
第一,任务进度变得可见。CLI 能把当前有哪些任务、做到哪一步、哪一项正在进行中,稳定地展示给用户,而不是完全依赖模型临时生成一段自然语言说明。
第二,任务进度变得可操作。模型不是只能"记得自己做到哪",而是可以通过 TaskCreate、TaskUpdate、TaskList、TaskGet 明确地创建任务、推进状态、重新读取现状。这样任务列表就不只是显示层,而是 Agent loop 里可被模型反复使用的一份外部状态。
第三,任务进度变得可恢复。随着上下文变长,模型未必始终清楚当前还剩哪些任务;但因为任务列表已经被工具写成了结构化记录,Claude Code 就可以在合适的时候把它重新注入上下文,提醒模型恢复对当前进度的视野。
因此,这套机制的分工其实很清楚:
- 任务列表:保存结构化进度
- 任务工具:负责创建、更新、读取这份进度
- 模型:基于当前上下文的进度决定下一步
- Agent loop:负责执行工具调用,并把结果推进到下一轮上下文
用一句话收束就是:
text
任务列表把进度状态显式保存起来;长流程中多轮未维护任务工具时,系统还会把当前任务列表重新注入上下文;模型结合整体上下文决定下一步,Agent loop 负责执行模型产出的工具调用。更多 AI 工程、Agent 和技术实践相关内容,欢迎关注公众号。
