推荐系统用
协同过滤和用户画像预测你的行为,精准到让人发毛。但它在算你,不是在懂你------理解这个区别,至少能让你下次被投喂时多一秒清醒。
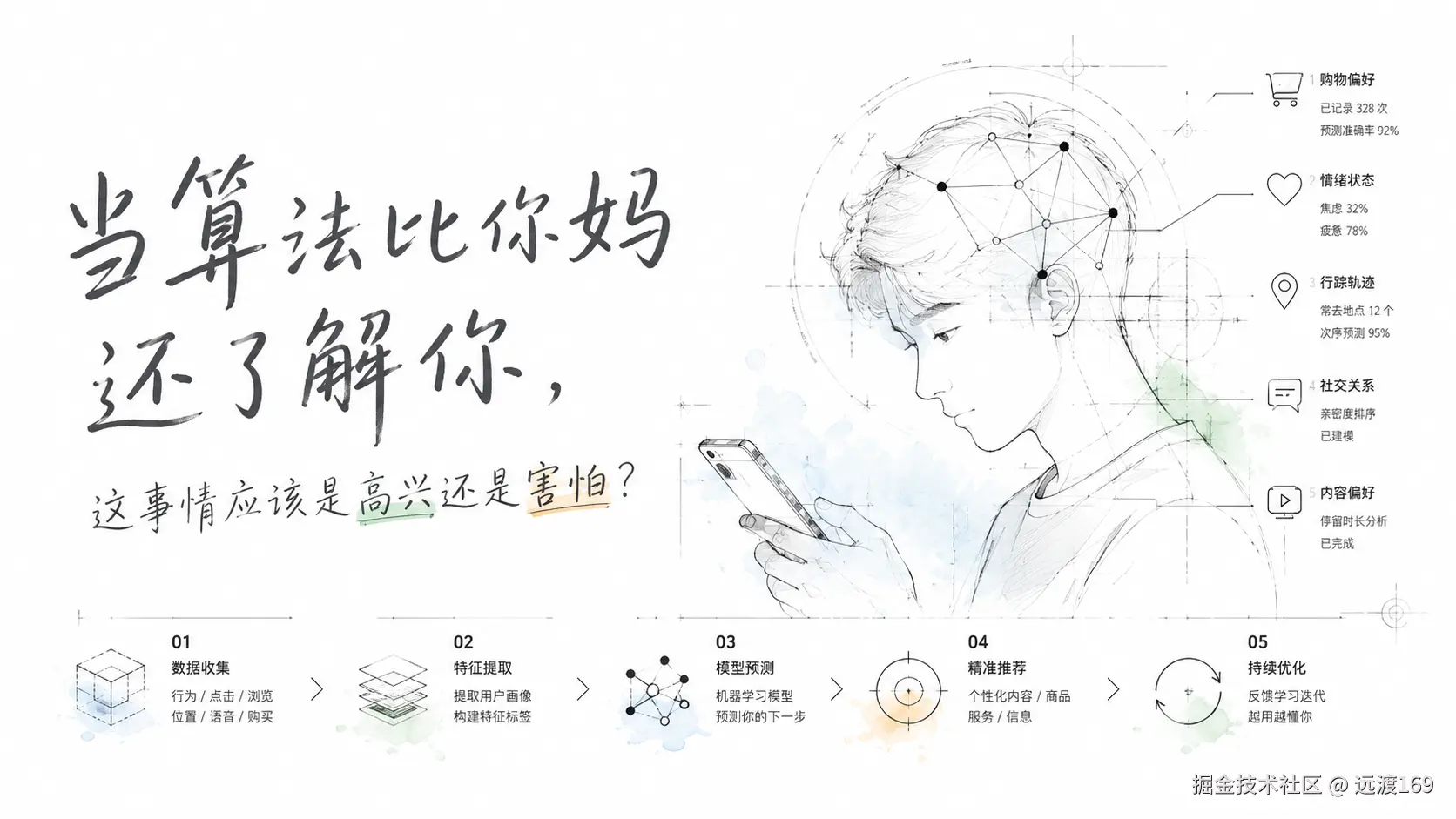
推荐算法比你妈还了解你:从 协同过滤 到信息茧房的底层逻辑
前两天我妈给我打电话,劈头盖脸就问:"你是不是最近手头紧?"
我说没有啊,怎么了?
她说她刷抖音,连续三天都给我推借钱广告和理财内容,"肯定是平台知道你需要钱"。
我哭笑不得。我只是前几天随手搜了一下房贷利率,看了两期财经博主的视频。但算法不这么想,在它眼里,我已经是一个急需资金周转的人了。
一、协同过滤 + 用户画像:推荐系统怎么"猜"你
有时候我自己都不知道自己想要什么,但算法知道。
上周我在淘宝搜了一次猫砂。就一次。接下来一周,抖音、小红书、知乎,猫粮测评、猫爬架推荐、"养猫人必看"铺天盖地。
我没有猫。帮朋友查个价格而已。
但推荐系统的逻辑不关心真相。它的工作流是这样的:
python
# 简化版协同过滤 + 用户画像流程
def recommend(user_id, action):
# 1. 捕获行为,打标签
tag = action_to_tag(action) # "搜索猫砂" → tag: "宠物兴趣"
# 2. 更新用户画像
user_profile[user_id][tag] += weight(action) # 权重累加
# 3. 从关联内容池召回
candidates = recall_by_tag(tag) # 猫粮/猫爬架/猫玩具
# 4. 排序 & 跨平台分发
ranked = rank(user_profile[user_id], candidates)
push_to_all_platforms(user_id, ranked)
# 5. 点击行为再次强化标签(闭环)
# 用户点击 → weight+1 → 推更多 → 循环一个搜索动作进去,标签打上,关联内容池召回,排序后跨平台分发。你在任何平台点了,权重再加一,推得更多。闭环就这么形成了。
这就是 协同过滤(Collaborative Filtering)和 用户画像(User Profile)的配合。前者找"跟你行为相似的人喜欢什么",后者记录"你本人表现出什么偏好",两个维度的结果一合并,精准度就上来了。
有时候它猜得真准。
上个月我有几天心情低落,没跟任何人说,晚上就随便刷了几个emo视频。第二天打开音乐app,首页全是伤感情歌。那一瞬间我居然有点感动------虽然我知道这就是 用户行为分析 的结果,但被代码"理解"的感觉,确实暖。
不过冷静下来想:它不是在理解你,它是在算你。
算和理解之间,隔着一整条马路。
二、"算得准"的代价:信息茧房是怎么工程化地建起来的
很多人觉得推荐算法方便。不用自己找内容,平台喂到嘴边,省事。
但你有没有想过,"省事"的同时交出去的东西有多少?
我用两个手机号注册了两个新的短视频账号做实验。一个只看科技类视频,另一个只看美食和萌宠。两周后,两个账号已经活在了完全不同的信息世界里。科技号全是AI动态、芯片战争、创业故事;萌宠号首页是猫狗打架、做饭教程和搞笑段子。
用推荐系统的术语说,这就是 Filter Bubble 的形成过程:
初始行为 → 打标签 → 筛选内容池 → 推送结果 → 用户点击/停留 → 再次强化标签。一个自我闭合的反馈环。
信息茧房这个词大家听烂了。我想说的是另一件事:这两个账号的主人是我同一个人,但算法把我割成了两个完全不同的"用户"。同一个人,不同账号,看到的现实就不一样。
算法不会提醒你"嘿,你可能也想看看别的内容"。它的优化目标是让你一直往下翻------你看得越久,广告越精准,平台赚得越多。它只会强化你已经表现出来的偏好,不会帮你拓宽边界。
你去一家餐厅,厨师发现你爱吃辣,之后每道菜都给你加辣椒。一开始你觉得爽,吃多了你就忘了食物还有别的味道。
而且你交出去的不只是"喜欢什么"。
经常凌晨三点还刷手机?算法标记了------失眠人群,适合推助眠产品和情感内容。发工资那几天明显更活跃?消费窗口期到了。某个视频停留时间特别长?那个视频里的东西大概率就是你下一次消费的目标。
情绪规律、收入水平、生活状态、性格弱点,这些碎片拼在一起就是一份 User Profile。搞不好比你自己对自己的认知还准。
人会骗自己,行为数据不会骗人。
三、A/B测试 与标题党:算法怎么反向改造内容
这部分说得可能有点难听,但我确实是这么感觉的:算法不光在迎合我们,也在改造我们。
你有没有发现,现在的标题越来越像了?"震惊!""万万没想到!""看完沉默了"。不是创作者们碰巧想到了同一个标题,是这类标题在 A/B测试 里点击率最高。
python
# 标题选择的简化模型
title_candidates = ["新版APP发布", "震惊!新版APP发布", "看完沉默了,新版APP"]
ctr = ab_test(title_candidates)
# "震惊!新版APP发布" 点击率 3.2x → 胜出
# 所有创作者学到:标题要加"震惊"一种表达方式一旦被数据证明有效,就会被疯狂复制,直到所有人都用同样的腔调说话。
内容也一样。某个类型的视频火了,一夜之间满屏都是同款。不完全是因为大家抄,是推荐机制给了同类内容更高的曝光权重。你喜欢→多推→更多人做→你看得更多。闭环又形成了。
我们都在往一个方向收缩,收缩成最容易被算法识别、最容易被推荐的版本。
我管这个叫"算法友好型人格"。
可能有人觉得我说得太邪乎。不就刷个视频嘛。
但算一下账:一个普通人每天花在手机上四五个小时不算夸张吧?这几个小时里接收的信息、看到的观点、产生的情绪,都被一套看不见的系统反复过滤。
时间长了,不可能没影响。
四、那我们能干嘛
写到这里我发现一个问题:这种文章很容易陷入一种套路------先描述问题有多严重,然后给几条不痛不痒的建议,最后升华一下收尾。我自己也烦这种写法。
但还是想说几个我觉得真有用的办法。
往画像里注噪声。 偶尔故意给算法喂点不一样的数据。平时只看科技?去搜两篇诗歌或者园艺的内容。只刷短视频?找个新闻app看几篇长文。不用多,一周几次。从推荐系统的角度说,这等于往你的 User Profile 里注入噪声(noise injection),降低模型对你预测的置信度。不是在对抗谁,就是让自己保持一点多样性。
关掉个性化推荐。 很多app有关闭选项,藏在设置深处,翻翻看。关掉之后体验肯定变差,你会看到大量不感兴趣的东西。但这恰恰是目的------你应该时不时看看那些你不感兴趣的世界有多大。
最难的一条:意识到自己在被影响。 下次你看到一个内容特别戳中你,停一秒想一想------是因为这个东西真的好,还是 推荐系统 算出来它恰好命中了你画像上的某个特征?
这一秒的停顿,可能就是你和这套系统之间仅剩的距离。
聊了这么多,简单收一下:
协同过滤和用户画像让算法精准预测你的行为,但它在算你,不是在懂你- 信息茧房是个自我强化的闭环,你交出去的不只是偏好,还有情绪、消费能力、性格弱点
A/B测试驱动下的内容同质化,正在把人往"算法友好型人格"的方向推- 应对思路:注噪声、关个性化、保持警觉
觉得有用就收藏,想讨论评论区见。