训练好的LoRA适配器 → 模型合并 → 转换为GGUF → 量化压缩 → 部署。

model_name_or_path: /home/aistudio/text_lora/models/Qwen/Qwen3-4B-Instruct-2507 # 你的基础模型路径
adapter_name_or_path: output/qwen3-4b-sft-v9 # 你的LoRA适配器输出路径
template: qwen # 使用你模型对应的template,如qwen
finetuning_type: lora # 微调方式,与你训练时一致
export_dir: models/qwen3-4b-merged # 合并后模型的保存路径
export_size: 4 # 单文件大小上限,单位为GB (可选)
export_device: cpu # 导出计算设备,推荐cpu (可选)
export_legacy_format: false # 是否使用旧格式 (可选)conda activate /home/aistudio/work/my_conda_envs/llamafactory
执行命令:
llamafactory-cli export merge_config.yaml
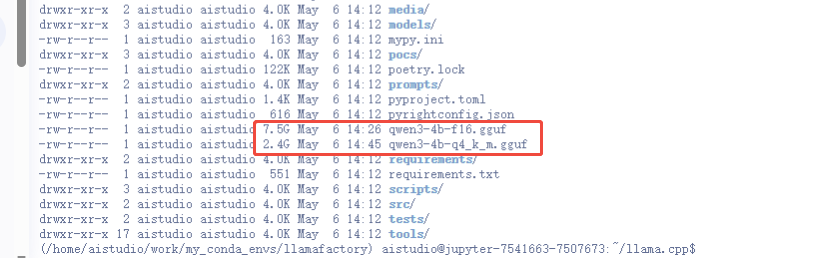
合并后的目录如下:

git clone https://git.ustc.edu.cn/USTC-OS-Lab/llama.cppcd llama.cpp
cmake -B build
cmake --build build --config Release -j --target llama-quantize
开始转换
进入 llama.cpp 目录,执行转换命令。
-
基础转换 (FP16):首先将合并后的模型转换为 FP16 精度的 GGUF 文件。
python convert_hf_to_gguf.py /home/aistudio/text_lora/LLaMA-Factory/models/qwen3-4b-merged/ --outfile /home/aistudio/llama.cpp/qwen3-4b-f16.gguf --outtype f16
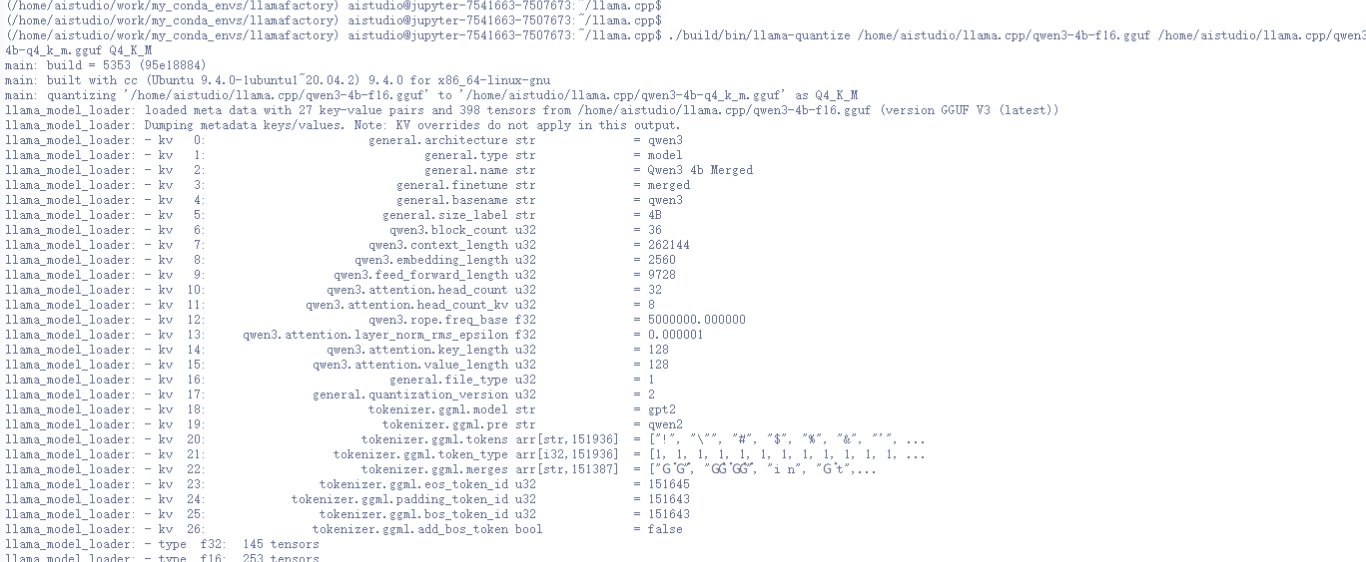
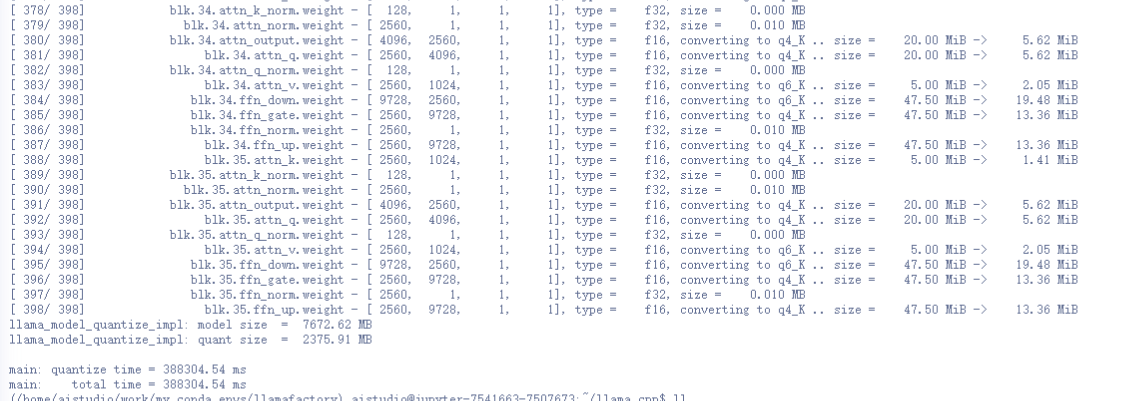
量化压缩 (Q4_K_M) :使用 llama-quantize 工具对上一步生成的 FP16 文件进行量化,以减小模型体积并提升推理速度。
./build/bin/llama-quantize /home/aistudio/llama.cpp/qwen3-4b-f16.gguf /home/aistudio/llama.cpp/qwen3-4b-q4_k_m.gguf Q4_K_M