端侧YOLO + 端侧CLIP + 云端CLIP(AI Mission Cloud):云-边-端协同语义感知与任务系统架构
通过端侧 YOLO 的实时感知与 CLIP 的语义编码,将复杂视频流转化为结构化语义数据;AI Mission Cloud 在云端完成跨设备、跨时间的语义推理与任务编排,让无人系统具备可扩展、可协作、可演进的 AI 能力。

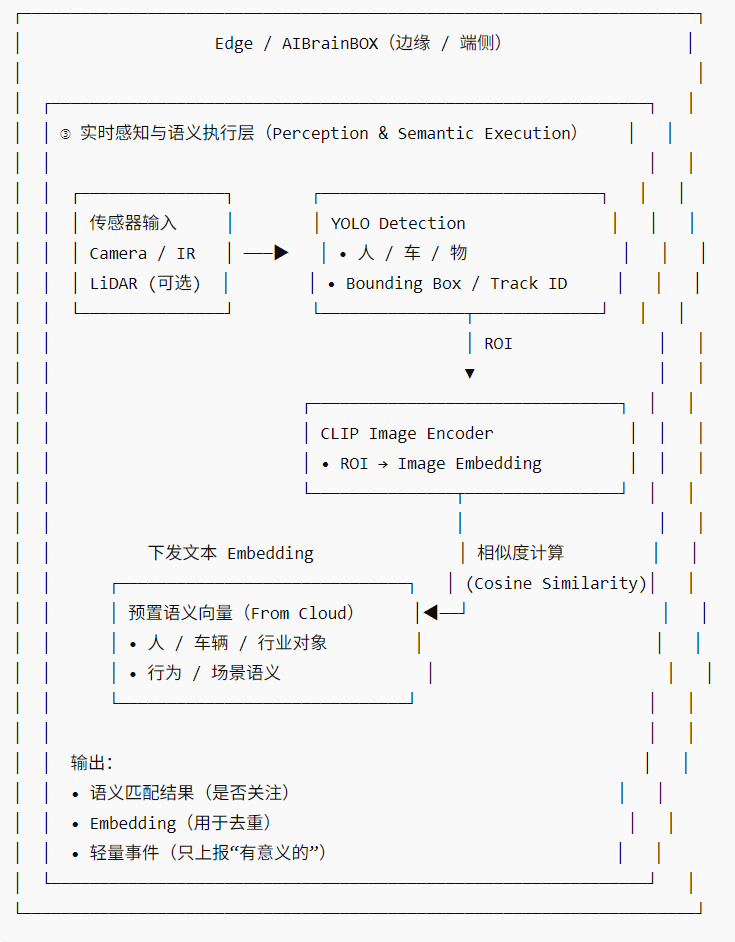
数据流拆解
🔁 数据流分为 两条平行通道
① 控制面(云 → 端)【低频】

特点:
-
不实时
-
可热更新
-
不依赖视频流
-
决定"你关心什么"
② 数据面(端 → 云)【高频 / 但已过滤】
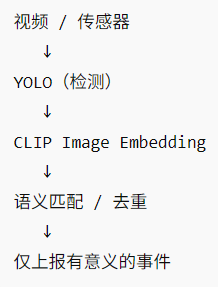
特点:
-
实时
-
强过滤
-
降带宽
-
降误报
YOLO / CLIP / Cloud 的边界
| 模块 | 只做什么 | 不做什么 |
|---|---|---|
| YOLO | 看见目标 | 不理解语义 |
| CLIP | 语义相似度 | 不做规则 |
| Cloud | 定义语义与任务 | 不跑实时视频 |
-
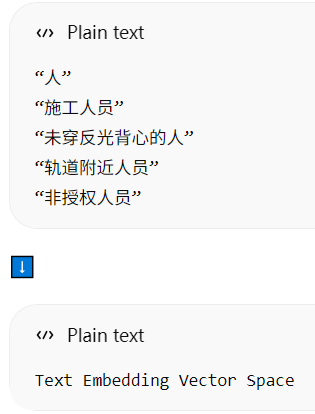
云端 CLIP 的核心职责之一,就是"文本 → 语义向量"的统一语义定义中心
-
端侧如果做语义过滤,必须使用"已经在云端定义好的文本向量"
-
端侧一般不"自由理解语义",而是做"向量相似度判断"
-
端侧不做语义筛选,并不是"不能算",而是"不可控、不稳定、不可演化"
语义"定义权"在云端,语义"执行权"可以在端侧
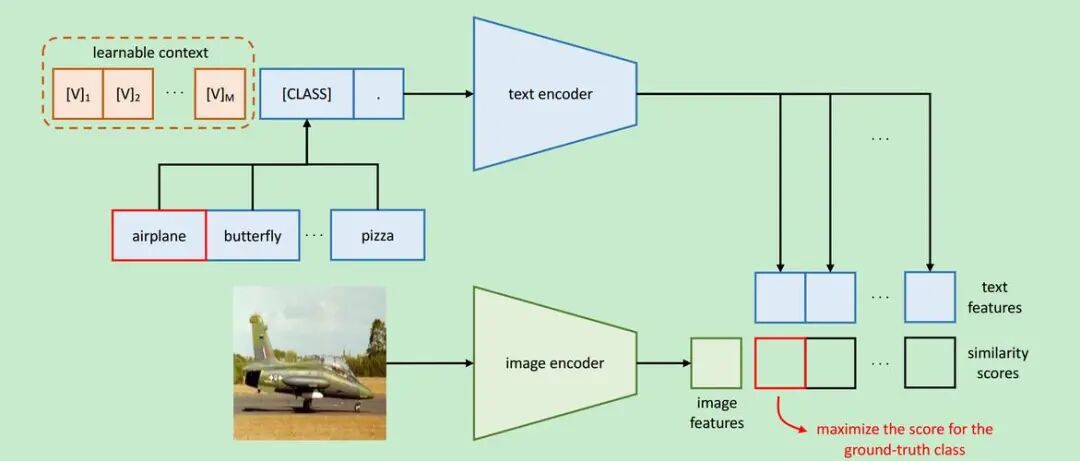
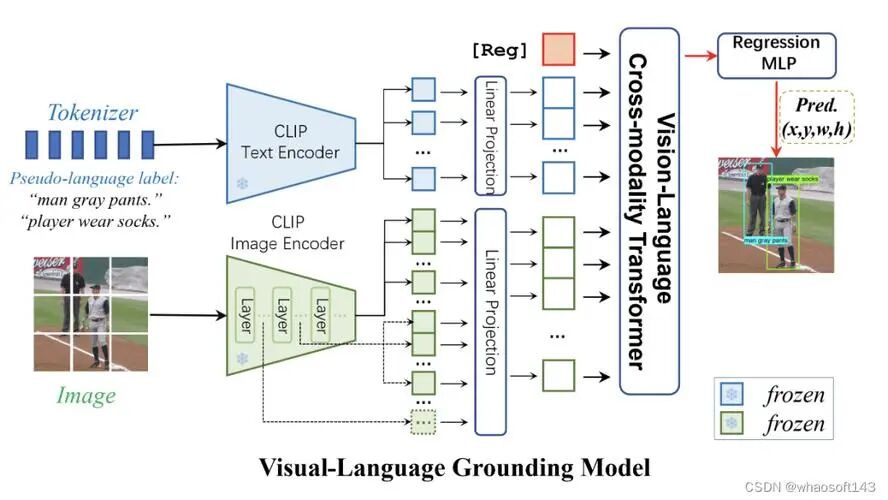
CLIP 本质
把「图像」和「文本」映射到同一个语义向量空间
两个 Encoder:
| 模块 | 输入 | 输出 |
|---|---|---|
| Image Encoder | 图片 / ROI | 图像向量(Embedding) |
| Text Encoder | 文本 prompt | 文本向量(Embedding) |
目标只有一个:
"相关的图文 → 向量距离近,不相关 → 距离远"
云端 CLIP 的核心职责
1️⃣ 语义词表的"向量化定义中心"
云端 CLIP 负责:
这一步建议在云端完成
原因:
-
文本 prompt 的措辞极其敏感
-
"person / worker / staff / pedestrian"向量差异很大
-
需要不断调整、试验、验证
所以云端负责:
-
设计 prompt
-
调优 prompt
-
训练 LoRA(如果需要)
-
产出 "标准文本语义向量"
2️⃣ 复杂语义组合 & 策略逻辑
云端可以做的,而端侧不适合做的:
-
语义组合
-
person AND railway -
vehicle BUT NOT authorized
-
-
规则版本管理
-
多模型 ensemble
-
历史统计 / 误报分析
云端是"语义决策层"
3️⃣ LoRA 训练与语义扩展
"CLIP 对某个行业语义不稳定 / 不敏感"
例如:
-
穿工装的矿工
-
港口地勤
-
军用特种车辆
云端负责:
-
采集数据
-
基于 CLIP 做 LoRA 轻量微调
-
生成 行业增强版 CLIP
去重(Deduplication)与 CLIP 的关系
去重的三种层级
① 目标级(Bounding Box)-YOLO 层面
-
IoU
-
Track ID
-
SORT / ByteTrack
② 外观级(Embedding 去重)-端侧CLIP
同一人反复出现?
同一车辆不同角度?
-
计算 CLIP image embedding
-
cosine similarity > 阈值 → 认为是同一实体
③ 语义级(事件去重)-云端CLIP
同一人多次进入危险区
-
时间窗口
-
语义标签
-
空间关系
事件层去重,云端完成
NPU-6T(YOLO)+26T(CLIP)
