ReAct的痛点
ReAct 的核心局限:每一轮工具调用和返回结果都被完整地追加到消息历史中。完成一个需要 20 步工具调用的研究任务,上下文会积累几万甚至十几万 token,极容易超出模型窗口限制,且越到后期模型越难「记住」最初的任务目标。
IterResearch 的解法
把 Deep Research 建模为马尔可夫决策过程(MDP),核心创新是引入「常量工作空间」。在 MDP 框架下,Agent 每一时刻的决策只依赖于当前的状态(State),而不需要完整的历史。
不再把完整的对话历史传给模型,而是维护一个结构化的状态文档,每步更新这个文档:
json
{
"research_question": "比较 2024 年中美两国电动车政策对特斯拉和比亚迪的影响",
"confirmed_facts": [
{
"fact": "中国 2024 年新能源补贴延续至 2025 年",
"source": "工信部政策文件"
},
{
"fact": "美国 IRA 法案对在华生产电动车征收 100% 关税",
"source": "白宫官网"
}
],
"pending_questions": [
"比亚迪 2024 年海外销量数据",
"特斯拉上海工厂受关税影响的具体测算"
],
"search_history": [
"中国电动车补贴政策 2024",
"US IRA EV tariff China"
],
"current_focus": "查询比亚迪 2024 年出口数据"
}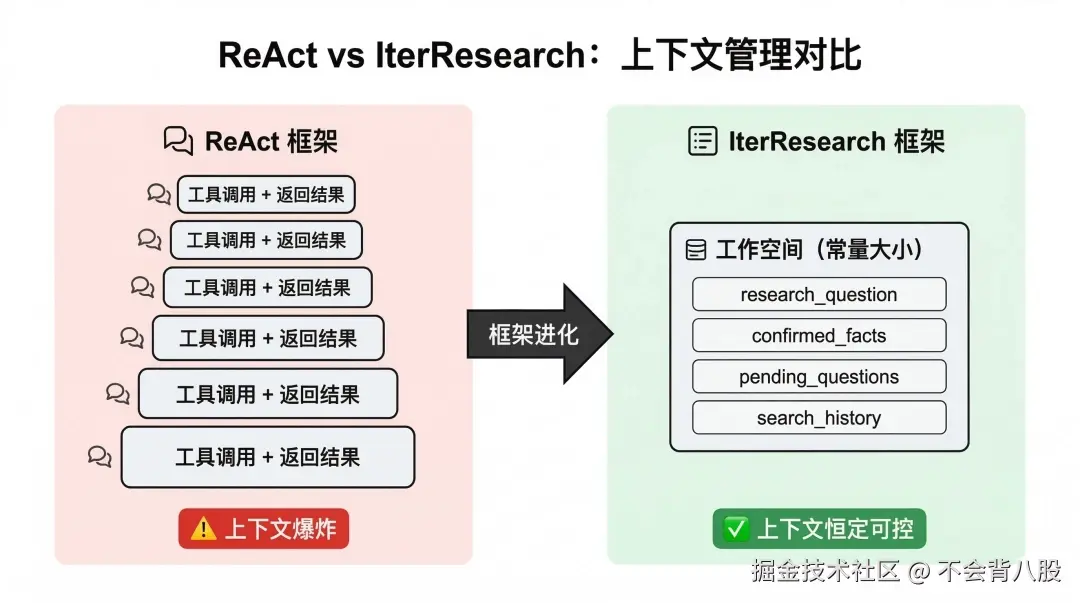 每步模型只看这个状态文档 + 最近一次工具返回,而不是完整的历史对话。工具的原始响应处理完即丢弃,只把提取的关键事实写入 confirmed_facts。这样无论任务做了多少步,传给模型的上下文长度始终接近常量,从根本上解决了上下文爆炸问题。
每步模型只看这个状态文档 + 最近一次工具返回,而不是完整的历史对话。工具的原始响应处理完即丢弃,只把提取的关键事实写入 confirmed_facts。这样无论任务做了多少步,传给模型的上下文长度始终接近常量,从根本上解决了上下文爆炸问题。
推理过程
IterResearch 采取的是 「读取-修改-覆盖」 策略:
-
Read(读取) :模型读取当前的「状态文档」。
-
Think & Act(思考与行动) :模型输出
<think>和<tool_call>。 -
Execute & Observe(执行与观察) :系统运行工具,获得原始结果(比如 5000 字的网页内容)。
-
Refine(更新状态 - 关键一步) :
- 重点 :系统不再把 5000 字原文塞进对话历史。
- 而是启动一个 小模型(或再次调用主模型) ,要求它:"根据刚才的搜索结果,更新上面的「状态文档」,把新知识填入「事实集」,把已解决的「盲区」划掉"。
-
Clean Slate(清空重置) :下一轮开始时,清空 之前的中间推理过程,只给模型发送更新后的「状态文档」。