你好,我是 Guide。先算一笔账:**ChatGPT Plus 套餐 20/月,现在可以直接用GPT−5.5∗∗。ClaudeOpus4.6/4.7呢?Pro套餐同样是20/月。
相同的价格,GPT 更耐用,换来的能力却接近甚至部分场景更强。
我在之前的模型评测里说过:GPT-5.5 和 Claude Opus 4.6 双王并列,没有绝对第一。两个偶尔都会翻车,只是翻车的姿势不一样。 但如果加上"性价比"这个维度,GPT-5.5 的优势就太明显了------工程场景最稳、API 生态最广、量大管饱。
GPT-5.5 在 2026 年 4 月 23 日发布,Plus、Pro、Business、Enterprise 用户当天就能在 ChatGPT 和 Codex 里直接使用。Codex 端更是给到了 400K 上下文窗口,Plus 用户就能享受到(订阅方法见文末,非广)。
发布当天我就开始用了,这几天也用它处理了一些非常典型的真实工程问题,只能说真的是夯爆了,夯中夯!
这篇文章接近实战复盘,三个实战案例均来自真实项目。通过本文你将搞懂:
- GPT-5.5 的能力定位:用 benchmark 数据说话,它到底在什么水平。
- "贵模型出方案、便宜模型干活"的实战效果:GPT-5.5 出方案 V4-Pro 实现、V4-Pro 扫问题 GPT-5.5 修,两个案例验证这条方法论。
- 多模型配置中心怎么设计更合理:DB 为事实来源,YAML 只做启动种子,API Key 加密存储。
- RAG 场景为什么必须拆分 Chat Provider 和 Embedding Provider,以及向量维度踩坑实录。
- GPT-5.5 + Codex 怎么搭配最有效:行动优先、上下文收集、AGENTS.md 等实战方法论。
- 性价比到底怎么算 : 20/月vs200/月,背后的实际差异。
GPT-5.5 到底什么水平?
先看数据。OpenAI 在发布时公布了一组 benchmark 对比,我挑了几个跟工程场景最相关的:
| 指标 | GPT-5.4 | GPT-5.5 | 提升幅度 |
|---|---|---|---|
| Terminal-Bench 2.0 | 75.1% | 82.7% | +7.6 个百分点 |
| SWE-Bench Pro | 57.7% | 58.6% | +0.9 个百分点 |
| MRCR v2(512K-1M tokens) | 36.6% | 74.0% | +37.4 个百分点 |
| 幻觉率 | 基线 | 减少 60% | 相比 GPT-5.4 |
几个值得关注的点:
- 长上下文推理暴涨:MRCR v2 从 36.6% 跳到 74.0%,接近翻倍。这意味着处理大型代码库时,GPT-5.5 能在更大的上下文窗口里保持推理质量。
- 终端/编码场景持续领先:Terminal-Bench 2.0 的 82.7% 在目前所有模型中排在前列。
- 幻觉大幅减少:60% 的幻觉降低,在实际编码中意味着更少的"看起来对但其实错了"的代码。
但 benchmark 归 benchmark,真实工程场景到底怎么样?下面进入实战。
实战一:让 GPT-5.5 出方案,DeepSeek V4-Pro 来实现
我想要对手头的多智能体股票分析项目进行优化改进,但我已经快一个月没打开了,实在没有什么思路。我就说:
markdown
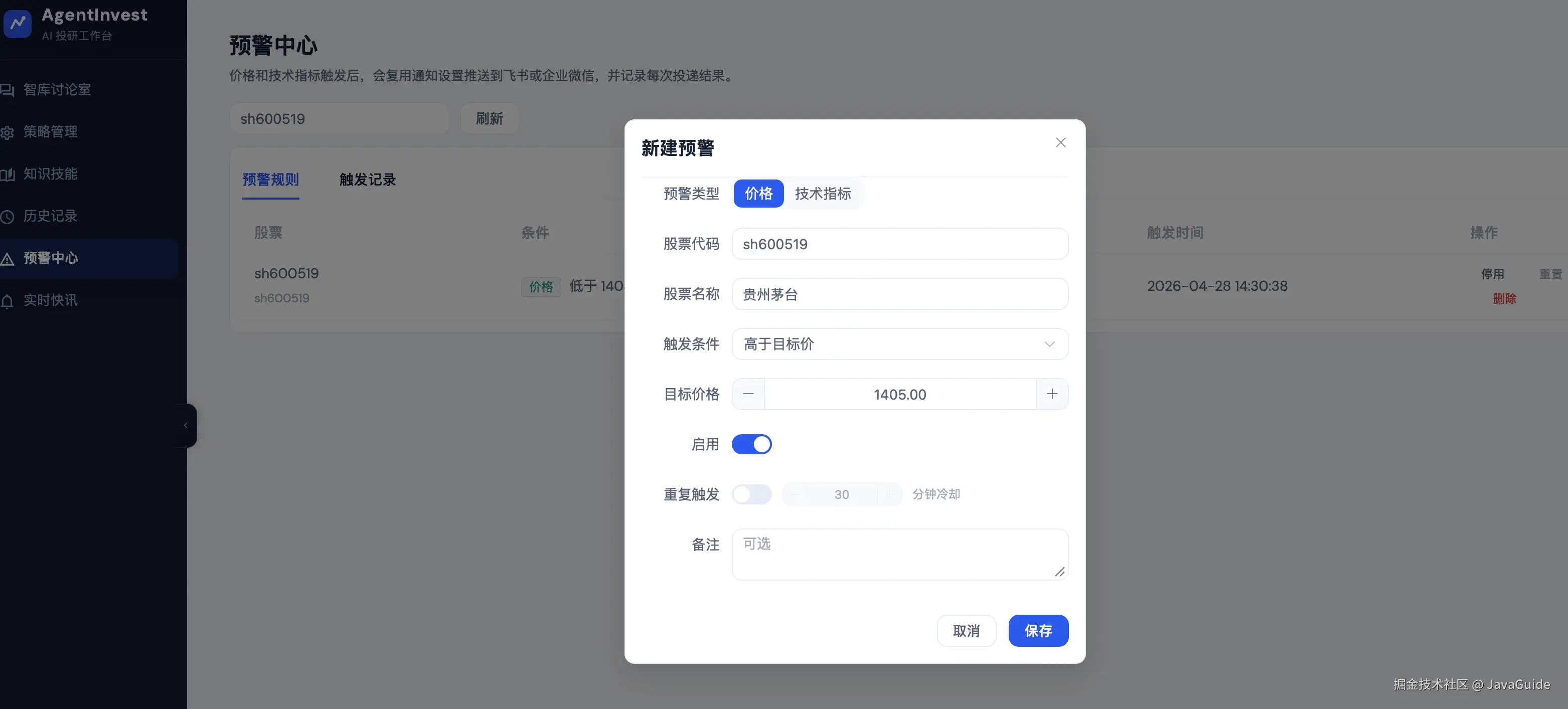
请参考当前比较成熟的 AI 股票分析开源项目,对本项目提供一些进一步优化改进的建议,例如股票预警通知。GPT-5.5 没有急着改代码,而是先参考了几个近期活跃的类似开源项目,结合当前项目给出了一组建议:

分成了五个优先级,第一个优先级是完善告警功能。项目里已经有 alert 雏形,但目前主要是内存态:priceAlerts、technicalAlerts 都存在 ConcurrentHashMap,重启会丢,且没有对应 Controller/API/UI。
因为这个时候我还想测试一下 DeepSeek V4-Pro,所以让 GPT-5.5 出了一份整体实现方案,然后交给 V4-Pro 实现。
这个思路 Guide 一直在用:让贵的模型做方案和决策,让便宜的模型去干活。
不过,如果你的 Token 随便造的话,那就不需要用这种省钱模式了。
V4-Pro 实现得还不错,虽然没有一次过,但第二次给了错误原因之后立马就修复了。
新建预警的实现效果如下:
我们当天也是成功在飞书收到了通知:
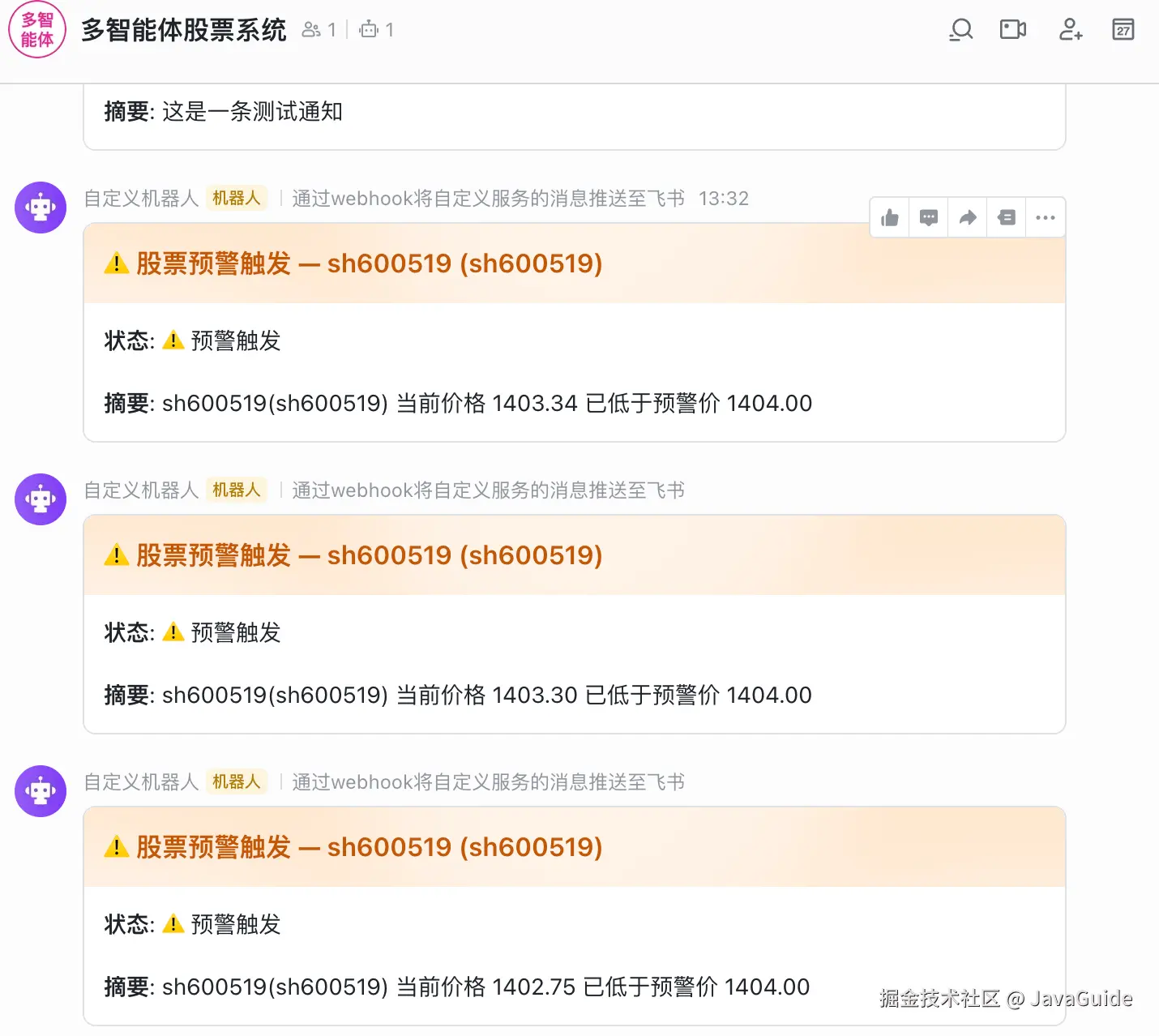
实战二:V4-Pro 做审计,GPT-5.5 复核修复
还是那个多智能体股票分析项目,功能都跑通了,但前阵子赶着上线,代码质量确实有些地方经不起细看。
Guide 这次的思路是:把审计和修复拆给两个模型,便宜的负责扫,贵的负责改。
具体操作是在 Claude Code 里让 DeepSeek V4-Pro 同时派出多个 Agent,分别盯着安全性、功能正确性、代码质量这几条线,把整个项目过了一遍,结果汇总到一份文档里。

扫完之后,V4-Pro 给出了一份问题清单,按紧急程度排了个序,前五条是这样的:
- API Key 明文存储 --- 加密器已实现但未接入
- 系统管理接口无权限控制 --- 普通用户可修改 LLM 配置
- Redis 反序列化漏洞 ---
activateDefaultTyping允许任意类实例化 - 硬编码第三方 API Key --- Bocha 真实密钥提交在代码中
- 功能 Bug --- History 页"重新分析"按钮因路由参数未读取而失效
我逐条看了一遍,结论基本靠谱。安全相关的尤其不能拖,第 3 条 Redis 反序列化那个,真要被人利用了,后果不堪设想。
下一步,我把 V4-Pro 的审计报告直接喂给了 GPT-5.5,让它逐条复核并修复。

为什么不让 V4-Pro 一把梭? 因为"找问题"和"改问题"对模型能力的要求完全不同。审计看重覆盖面------宁可多报不能漏报;修复看重精准度------改动要恰到好处,不能引入新的副作用。两个模型各做各擅长的事,比一个模型从头干到尾靠谱得多。
这也是我在《从夯爆开始锐评我用过的 AI 编程模型》里反复强调的:遇到真正棘手的工程问题,GPT-5.5 和 Claude Opus 4.6 这两个旗舰模型还是最稳的。
GPT-5.5 复核后直接动手改,每个问题的修复逻辑都交代得清楚,整个流程跑下来很顺畅。
回到这个案例本身,V4-Pro 的表现确实不差,但更值得说的是背后的成本账:便宜模型扫问题、贵模型定方案,V4-Pro 特惠期跑一轮全项目扫描,费用几乎可以忽略不计。同样的活儿交给 GPT-5.5 或者 Claude Opus 4.6 来干,成本至少翻两个量级。
实战三:面试平台多模型配置改造
AI 智能面试辅助平台 + RAG 知识库(已开源)的项目技术栈大概是这样:
- 后端:Spring Boot 4.0、Java 21、Spring AI 2.0、JPA、PostgreSQL、pgvector、Redis Stream
- 前端:React 18、TypeScript、Vite、TailwindCSS 4
- AI 能力:简历分析、模拟面试、语音面试、知识库 RAG、多 Provider 模型配置
项目里已经有一个模型配置页面,可以配置 DashScope、DeepSeek、GLM、Kimi 等 Provider。
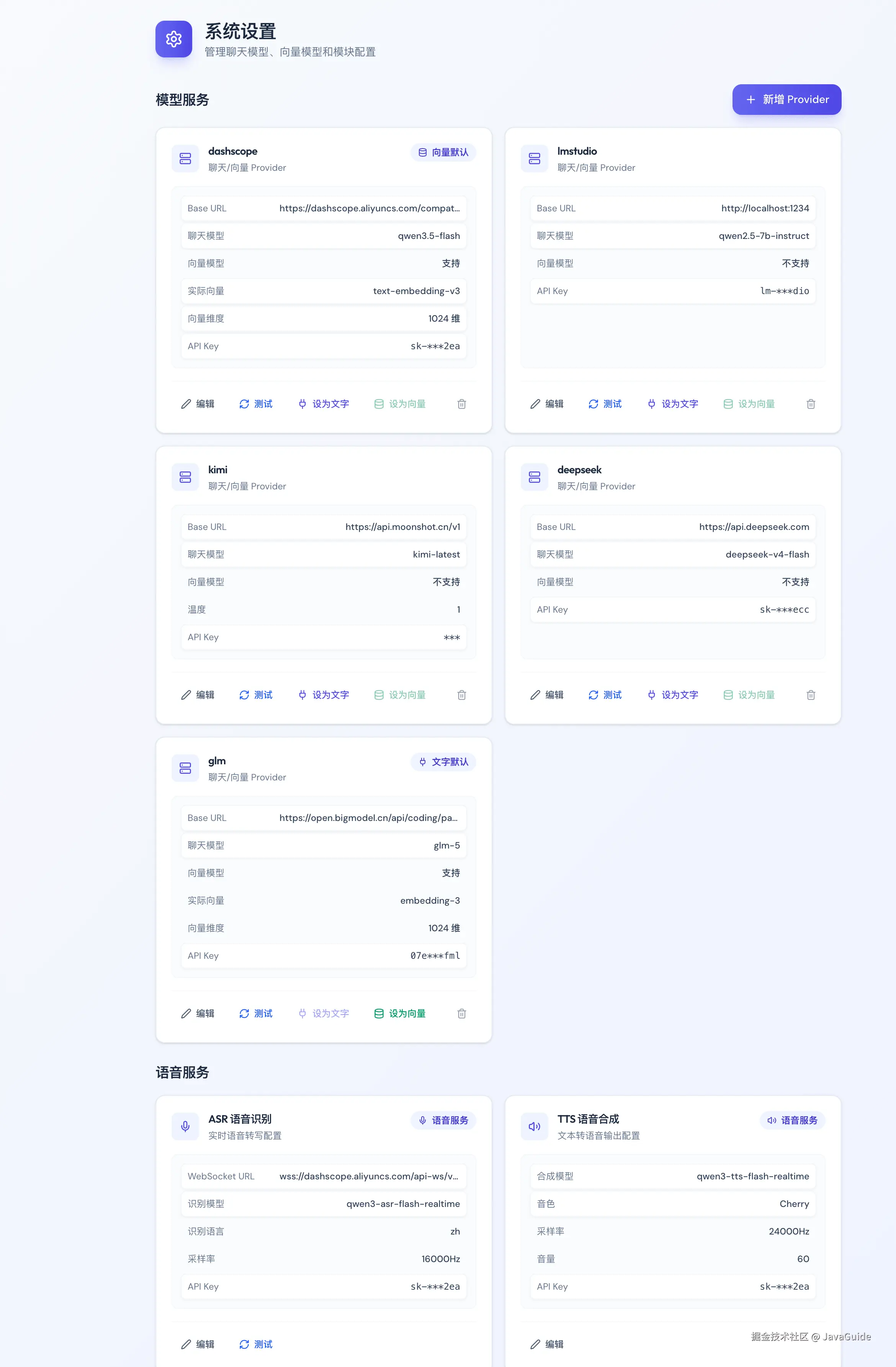
上图已经是优化后的效果,球友 PR 的初版,整体实现有几个明显问题:
- 配置主要写 YAML /
.env,不是以数据库为准。 - 默认聊天模型和默认向量模型绑在一起。
LlmEmbeddingConfig启动时创建一个固定的EmbeddingModelBean,运行时切模型并不会真正影响向量化链路。- 前端虽然有
Embedding Model输入框,但没有把"聊天模型"和"向量模型"的差异讲清楚。
我给 GPT-5.5 的第一句需求大概是:
当前的模型配置界面没有存入数据库或者缓存中持久化,如果我重启了项目就会丢失。另一个问题是 DeepSeek 和 Kimi 不支持 Embedding,但项目有 RAG 知识库功能,需要优化体验。
它没有直接上来改代码,而是先读项目结构。这一点很重要。真实项目里,最怕模型一上来按自己的想象造一套架构。
GPT-5.5 先定位到了几个关键文件,然后才开始给方案、改代码、跑测试。
配置持久化
原来的实现更像"开发环境临时方案":配置改完写回 YAML 或 .env。本地跑起来似乎能用,但一旦进入真实部署环境,问题就很明显:
- Jar 包里的 classpath 配置不可写。
- 多实例部署时每个实例各写各的。
ReentrantReadWriteLock只能管单 JVM,管不了集群。- 配置变更和 Spring Boot 配置绑定生命周期天然不匹配。
GPT-5.5 给出的方向是:

- Provider 配置进 PostgreSQL。
- Redis 只做缓存,不做唯一持久化来源。
- YAML 只作为启动种子配置。
- 运行时所有配置以 DB 为准。
最终落地了两张表:
text
llm_provider_config
llm_global_setting这里我中途还专门跟它讨论了 API Key 是否应该明文入库。
GLM 给的建议是第一版先明文,理由是现在 .env 也是明文。我不太赞同这个判断,因为 .env 明文和数据库明文完全不是一个风险级别。
数据库会被备份、被 SQL 查询、被只读账号访问。一旦 API Key 明文进库,暴露面明显扩大。
所以这次没有偷懒,最终实现了 AES-256-GCM 应用层加密:
这块我比较满意。它不是只会写 CRUD,而是能顺着安全约束继续往下推。
| 项目 | 改造前 | 改造后 |
|---|---|---|
| 配置事实来源 | YAML / .env |
PostgreSQL |
| 启动配置 | 直接绑定配置文件 | YAML 作为 DB 种子 |
| API Key | 环境变量明文 | DB 加密存储 |
| 默认模型 | 一个 default provider | Chat / Embedding 两个默认值 |
| 运行时刷新 | 依赖单 JVM 锁 | Registry 缓存失效后重建 |
Chat Provider 和 Embedding Provider 必须分离
第二个问题更关键:DeepSeek 和 Kimi 可以做聊天模型,但不能做 Embedding。
如果项目里只有普通对话,这没问题。但 RAG 知识库必须要把文档向量化。
国内主流厂商的 Embedding 支持大概是这样:
| 厂商 | 有 Embedding | 常见模型 |
|---|---|---|
| 阿里通义 | 支持 | text-embedding-v3 |
| 智谱 GLM | 支持 | embedding-3 |
| 百度文心 | 支持 | Embedding-V1 |
| MiniMax | 支持 | embo-01 |
| DeepSeek | 不支持 | - |
| Kimi / Moonshot | 不支持 | - |
原来的设计是:
text
default-provider -> ChatClient
default-provider -> EmbeddingModel这就很危险。
比如默认模型切到 DeepSeek:
- 简历分析、面试题生成可以走 DeepSeek。
- 知识库向量化却没有可用的 Embedding 模型。
更隐蔽的是,LlmEmbeddingConfig 是启动时创建固定 Bean。如果你运行时切换默认 Provider,ChatClient 可能变了,但 EmbeddingModel 不一定跟着变。
GPT-5.5 的改法是:
- 默认聊天 Provider 和默认向量 Provider 分离。
LlmProviderRegistry同时管理ChatClient和EmbeddingModel缓存。LlmEmbeddingConfig不再创建固定模型,而是创建一个委托型EmbeddingModel。- 每次向量化时,都从 Registry 获取当前默认 Embedding Provider。
核心思路类似这样:
java
@Bean
public EmbeddingModel embeddingModel(LlmProviderRegistry registry) {
return new EmbeddingModel() {
@Override
public EmbeddingResponse call(EmbeddingRequest request) {
return registry.getDefaultEmbeddingModel().call(request);
}
@Override
public float[] embed(Document document) {
return registry.getDefaultEmbeddingModel().embed(document);
}
};
}这个改动很小,但意义很大。
它把 Spring Bean 的生命周期问题绕开了:VectorStore 仍然注入一个 EmbeddingModel Bean,但这个 Bean 背后会动态委托到当前默认向量模型。
这才是真正适合"运行时切换模型配置"的实现。
GLM embedding-3 的维度坑
接下来踩到一个更真实的坑。
我把 GLM 设为默认向量服务,向量模型填 embedding-3,结果异步向量化失败:
text
ERROR: expected 1024 dimensions, not 2048这次不是模型填错了。
问题是:
- 项目的 pgvector 表是 1024 维。
- GLM
embedding-3默认返回 2048 维。 - Spring AI 如果不显式传
dimensions,就会按服务端默认维度返回。
这类问题非常隐蔽,因为模型名是对的,Provider 也是对的,API Key 也没问题,但最终写库时才炸。
GPT-5.5 的修复是把"向量维度"也纳入 Provider 配置。
后端新增:
text
embedding_dimensions配置里给 GLM 和 DashScope 都加上:
yaml
embedding-dimensions: 1024创建 OpenAiEmbeddingOptions 时显式传:
java
OpenAiEmbeddingOptions options = OpenAiEmbeddingOptions.builder()
.model(config.embeddingModel())
.dimensions(resolveEmbeddingDimensions(config.embeddingDimensions()))
.build();前端也增加了"向量维度"输入框,默认 1024。
这个点我觉得很值得单独拿出来说。
RAG 系统里,Embedding 模型不是只看"模型名能不能用",还要看:
- 向量维度
- 距离函数
- pgvector 表结构
- 旧数据是否需要重新向量化
- 不同知识库是否允许混用不同维度
这次我们没有一下子搞多维度共存,而是先锁定当前系统使用 1024 维。这个决策是合理的,因为项目当前的 vector_store.embedding 表本来就是固定 1024 维。
第一版先保证可用和稳定,后续如果要支持多维度,再设计多表或按知识库维度隔离。
GPT-5.5 这次表现怎么样?
整体来说,我对 GPT-5.5 这次表现是非常满意的。
它最明显的优点是:不会只盯着报错修一行代码,而是会顺着系统边界往上追。
比如最开始的"重启配置丢失",它没有只建议把 YAML 写对,而是判断出:
- YAML 不是运行时配置的好事实来源。
- DB 才适合作为 Provider 配置中心。
- Redis 只能做缓存。
- Registry 要支持运行时刷新。
- EmbeddingModel 也要跟 ChatClient 一样 registry 化。
再比如 GLM embedding-3 维度问题,第一次确实没在初始方案里直接想到。但看到真实错误后,它很快把问题从"模型不能用"纠正为"向量维度不匹配",并把维度纳入配置链路。
这就是实战里最重要的能力:能根据日志快速修正自己的假设。
不过 GPT-5.5 也不是完美的。这次暴露出几个需要人把关的点:
- Provider 最新模型名不能靠记忆 比如 DeepSeek 的模型名,必须查官方文档或者实际接口。模型如果凭记忆写一个看起来很新的名字,容易直接 400。
- RAG 维度问题需要真实运行才能暴露 纸面方案里容易漏掉 pgvector 维度和 Embedding API 默认维度的差异。
- 工具调用兼容性不能默认乐观 OpenAI-compatible 只是接口形状兼容,不代表 tool-call 细节完全兼容。
- 安全规则需要结合上下文调试
PromptSanitizer报警不是坏事,但要分清是用户输入触发,还是系统内部格式误报。
GPT-5.5 + Codex:怎么搭配最有效?
GPT-5.5 已经在 Codex 云端智能体中可用,Plus 用户就能用,上下文窗口 400K。这一节分享几个 Guide 在实战中总结的搭配技巧,更详细的 Codex 使用指南可以参考我写的《OpenAI Codex 最佳实践指南》。
行动优先:让模型直接干活
Codex 的提示设计有一个核心原则------行动偏向(Action Bias)。好的提示应该引导模型直接交付可工作的代码,而不是用一堆问题结束回复。
具体来说:
- 明确告知模型"交付可工作的代码,而不仅仅是计划"
- 模型应该默认做出合理假设并向前推进
- 只有在真正被阻塞(缺少关键信息或存在矛盾约束)时才向用户提问
反面示例:提示中要求模型"先列出计划,等确认后再执行"。这会让模型在完成工作前就停下来等待,严重降低效率。
正面示例:提示中写明"接到任务后立即开始工作,合理假设模糊部分,完成后展示结果。如有无法自行判断的阻塞问题,再询问用户。"
上下文收集:先规划再并行
Codex 在开始修改代码之前,应该先充分理解代码库。提示中应明确要求:
- 批量读取:在调用工具前先想清楚需要哪些文件,然后一次性并行读取
- 避免串行探索:不要一个文件一个文件地逐个查看
- 先搜索后新增:在添加新实现之前,先搜索代码库中是否已有类似功能
这种"先规划、再并行"的策略可以显著减少往返轮次。实战三中 GPT-5.5 先读项目结构、定位关键文件,再开始给方案,就是这种策略的自然体现。
AGENTS.md:给 Codex 注入项目上下文
AGENTS.md 的作用和 Claude Code 的 CLAUDE.md 类似,都是给 AI 注入项目级的上下文和规范。Codex 会自动扫描并注入 AGENTS.md 文件,加载逻辑遵循分层覆盖原则:
| 层级 | 路径 | 适用范围 |
|---|---|---|
| 全局 | ~/.codex/AGENTS.md |
所有项目的通用默认行为 |
| 项目 | 仓库根目录 AGENTS.md |
项目级约定 |
| 模块 | 子目录 AGENTS.md |
模块级特殊规则 |
建议在项目根目录放一份 AGENTS.md,至少覆盖:构建命令、测试规范、代码风格约定、Git 工作流规范。
安全模式的选择
Codex 提供三种安全模式:
| 模式 | 说明 | 适用场景 |
|---|---|---|
| Suggest | 可读取文件,但所有写操作和命令需确认 | 代码审查、学习 |
| Auto Edit | 自动编辑文件,但命令行操作需确认 | 日常开发 |
| Full Auto | 全自动,编辑和命令都自动执行 | CI/CD、批量任务 |
Guide 的建议是:先用 Suggest 模式建立信任,再用 Auto Edit 提效,最后才考虑 Full Auto。 一上来就 Full Auto,翻车了连怎么翻的都不知道。
贵模型出方案、便宜模型干活
实战一和实战二都用了这个思路:GPT-5.5 出方案、V4-Pro 执行实现。在 Codex 里也可以这样做------用 GPT-5.5 做架构决策和复杂问题排查,日常编码和代码扫描交给便宜的模型。
这样做的成本优势非常明显。以 Codex 的按量计费来算,同样一个项目级代码扫描任务,用 GPT-5.5 的成本是用 V4-Pro 的几十倍。
总结
写到这里,Guide 想把这次 GPT-5.5 实战的几个核心感受摊开来说。
第一,它确实能扛中大型项目的改造。 但前提很明确:你得喂真实日志、真实代码、真实报错。如果只给一句"优化一下模型配置",它大概率给出一套泛泛的方案。但如果你把"重启配置丢了""GLM embedding-3 写库维度报错""DeepSeek 语音链路 400"这些具体问题丢过去,它就能沿着工程链路一层层拆到底。
第二,三个实战背后有一条共用的方法论:把不同模型用到它们各自最擅长的环节。 GPT-5.5 出方案、V4-Pro 执行实现;V4-Pro 扫问题、GPT-5.5 定方案改代码。这不是什么新鲜思路,但 GPT-5.5 让这件事变得更容易落地------它的方案质量足够高,交给便宜模型去执行的时候翻车率很低。
Guide 的态度很明确:GPT-5.5 和 Claude Opus 4.6/4.7 各有擅长的场景,我日常是搭配着用。但如果你只能选一个,或者团队预算有限,GPT-5.5 + ChatGPT Plus 是当前性价比最高的选择------没有之一。