LangChain → LangGraph 全解析
从 0.x 到 1.x,再到图引擎------架构原理、演进背景与对比指南
目录
- [LangChain 的诞生与演进(0.x 时代)](#LangChain 的诞生与演进(0.x 时代) "#1-langchain-%E7%9A%84%E8%AF%9E%E7%94%9F%E4%B8%8E%E6%BC%94%E8%BF%9B0x-%E6%97%B6%E4%BB%A3")
- [LangChain 1.0 架构详解](#LangChain 1.0 架构详解 "#2-langchain-10-%E6%9E%B6%E6%9E%84%E8%AF%A6%E8%A7%A3")
- [为什么诞生了 LangGraph?](#为什么诞生了 LangGraph? "#3-%E4%B8%BA%E4%BB%80%E4%B9%88%E8%AF%9E%E7%94%9F%E4%BA%86-langgraph")
- [LangGraph 架构原理详解](#LangGraph 架构原理详解 "#4-langgraph-%E6%9E%B6%E6%9E%84%E5%8E%9F%E7%90%86%E8%AF%A6%E8%A7%A3")
- [LangChain vs LangGraph 对比](#LangChain vs LangGraph 对比 "#5-langchain-vs-langgraph-%E5%AF%B9%E6%AF%94")
- 我该选哪个?决策指南
LangChain家族架构图
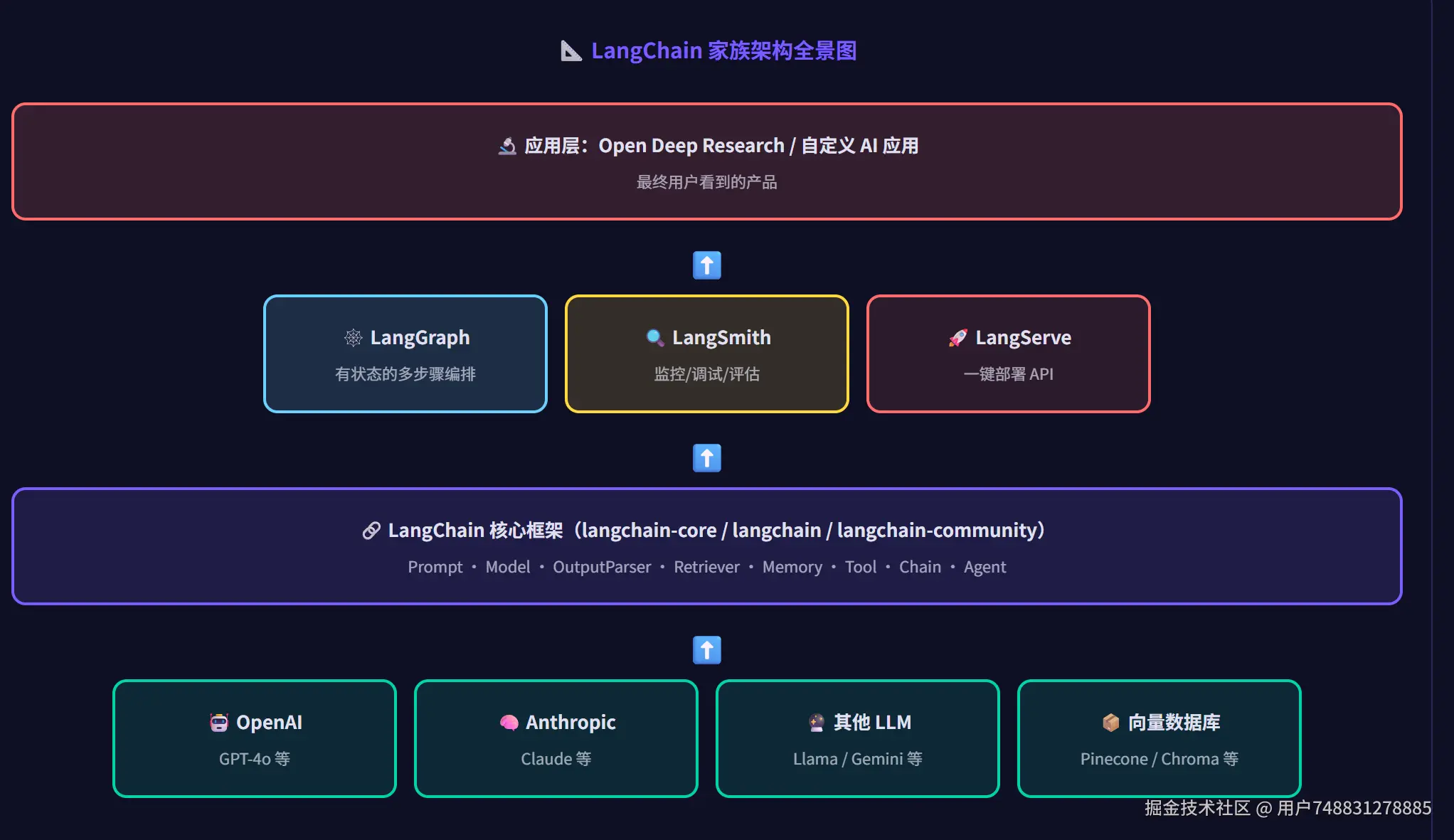
1. LangChain 的诞生与演进(0.x 时代)
2022 年秋,Harrison Chase 把一个 800 行的 Python 脚本推上了自己的 GitHub,没有任何宣传------这就是 LangChain 的起点。它解决了当时每个 LLM 开发者都在重复造轮子的问题:怎么把大模型和外部工具、数据、记忆拼在一起?
时间线
| 时间 | 里程碑 | 说明 |
|---|---|---|
| 2022 年 10 月 | 诞生 | HHarrison Chase 发布 LangChain,定义了 Chains、Agents、Memory 等核心抽象,开创了 LLM 应用开发框架 |
| 2023 年 4 月 | 融资 & 公司化 | Sequoia 领投 2000 万美元,估值超 2 亿美元,贡献者爆炸式增长,集成 300+ 服务 |
| 2023 年 7 月 | LangSmith 发布 | LLM 应用的可观测性平台,提供追踪、评估、调试和监控能力,解决"黑盒"问题 |
| 2023 年 10月 | LCEL 推出 | 引入 LangChain Expression Language(管道符 ` |
| 2024 年 1--5 月 | 架构拆包 | v0.1 正式版 + langchain-core 独立包;v0.2 弃用 AgentExecutor,推荐 LangGraph Agent |
| 2025 年 11 月 | LangChain 1.0 | 全面重写 Agent 接口(create_agent),引入 Middleware 中间件,语义化版本,API 稳定承诺 |
0.x 时代的三大痛点
痛点 1:巨石包依赖地狱
所有东西挤在 langchain 一个包里。装了 OpenAI 的集成,连带把 Pinecone、Chroma、HuggingFace 全装上。安装慢、冲突多、更新一次可能全线崩溃。
痛点 2:过度封装,不好定制
LLMChain、ConversationalRetrievalChain 等预制类用起来方便,一旦需要自定义就像掀开黑盒------里面藏着隐式 Prompt、隐式上下文,调试极难。
痛点 3:Agent 不适合生产环境
AgentExecutor 是线性执行器,没有持久化状态、没有人工介入点、无法处理复杂的多步骤循环,稍复杂的 Agent 场景就捉襟见肘。
LangChain ------ 一切的基础
连接大模型与真实世界的桥梁
🤔 为什么需要 LangChain? 你可能会问:我直接调 OpenAI API 不就行了?为什么还需要 LangChain?
arduino
问题在于:在真实的 AI 应用中,你往往需要的不仅仅是"问一句答一句"------你可能需要:让 AI 先去搜索网页、再读取你的文档、然后结合对话历史来回答、如果答案不好还要重新来一次...... 这些复杂的流程,如果纯手写,代码会又臭又长。
LangChain 就是帮你把这些复杂流程像搭积木一样组装起来的框架。LangChain 六大核心组件详解
一、Model I/O ------ 模型的输入与输出
这是最基础的部分,解决的是"怎么跟大模型对话"的问题。
- 📝 PromptTemplate(提示词模板) 把提示词做成"填空题"即占位符,避免每次手动拼字符串。比如: 「请把以下内容翻译成{language}:{text}」 使用时只需传入 language="英文",text="你好" 即可。
- 🤖 Chat Model(聊天模型) 对各家大模型的统一封装。不管你用 OpenAI、Claude 还是 Llama,都用同样的代码调用。切换模型只需改一行配置。
- 📤 OutputParser(输出解析器) 大模型返回的是一大段文字,但你可能想要 JSON、列表、或者特定格式。OutputParser 帮你把"自然语言"转成"结构化数据"。比如 PydanticOutputParser 可以直接把回答解析成 Python 对象。
ini
# 一个最简单的 Model I/O 示例
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
# 1. 创建提示词模板
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个专业的翻译官。"),
("human", "请把以下内容翻译成{language}:{text}")
])
# 2. 创建模型
model = ChatOpenAI(model="gpt-4o")
# 3. 组合并调用
chain = prompt | model # 这就是 LCEL!后面会详细讲
result = chain.invoke({"language": "英文", "text": "今天天气真好"})二、Retrieval ------ 检索增强生成(RAG)
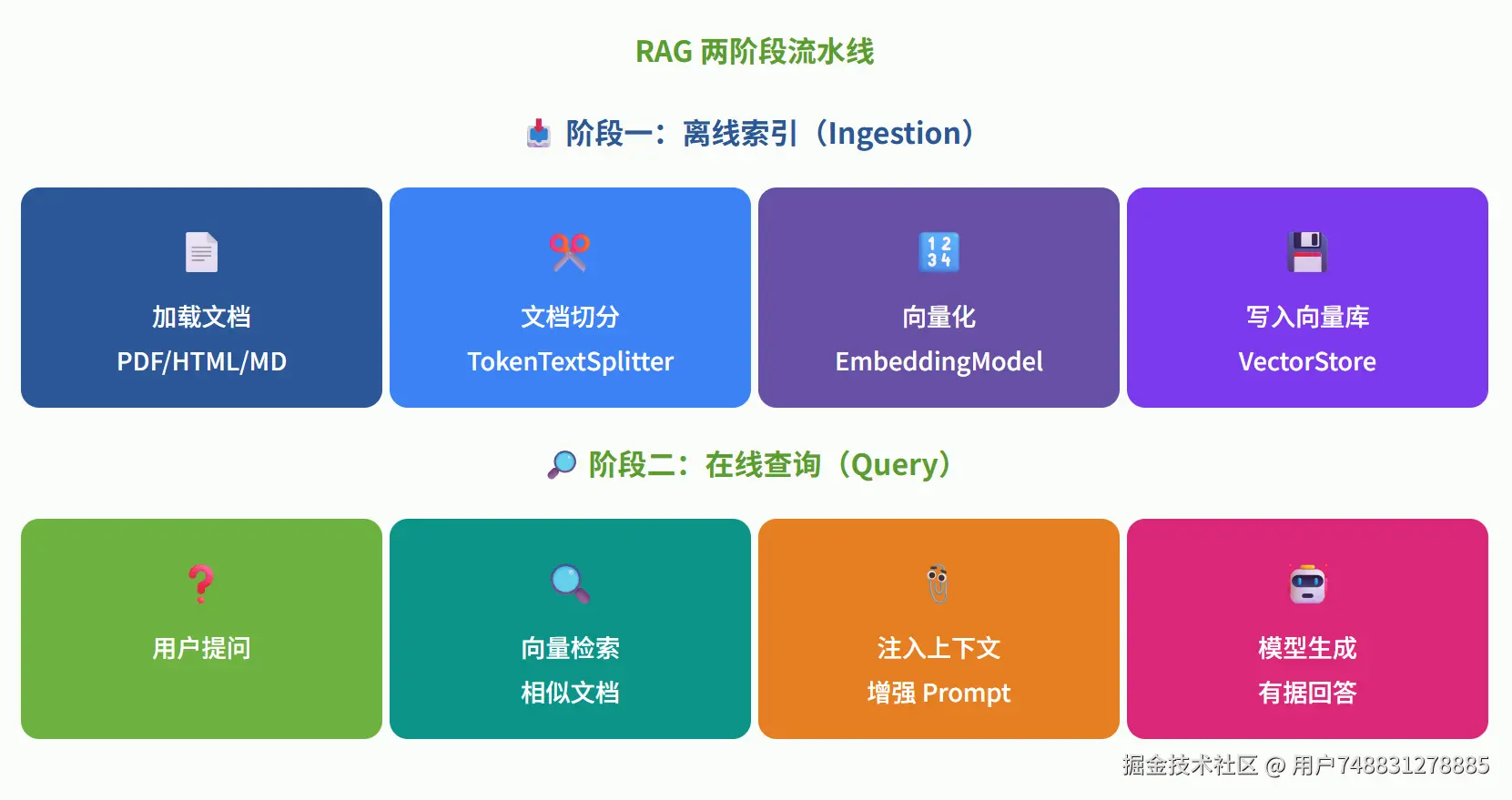
这是 LangChain 最核心的能力之一------让 AI 能"查资料"再回答。 大模型就像一个"学富五车但记忆停留在训练时"的学者。RAG 就是给他配一个"图书馆"------每次回答问题前,先去图书馆找找相关资料,再结合资料来回答。这样就能回答训练数据里没有的内容(比如你公司的内部文档)。
- RAG 整体流程
vbnet
📄 Document Loader(文档加载器)
支持加载 PDF、Word、网页、CSV、Notion、GitHub 等 160+ 种数据源。
✂️ Text Splitter(文本切分器)
文档太长,需要切成小块。支持按字符数、按语义、按代码结构等多种切分方式。
🔢 Embedding(向量嵌入)
把文字变成数学向量,这样计算机才能理解"这两段话意思相近"。
📐VectorStore --- 向量存储
🐘 PgVector
PostgreSQL 的向量扩展,最受欢迎的选择之一
🔷Redis
Redis Stack 的向量搜索功能
🌲Pinecone
云端托管的向量数据库
🔶Milvus
开源高性能向量数据库
📝SimpleVectorStore
内存实现,适合开发测试
🔍更多...
Chroma, Qdrant, Weaviate, Elasticsearch, Neo4j 等
🔍 Retriever(检索器)
根据用户问题,从向量数据库中找出最相关的文档片段。三、Memory ------ 对话记忆
LLM 本身是"无状态"的------每次对话都从零开始。Memory 让 AI 记住对话历史、用户偏好、重要事实。分为短期记忆(当前对话窗口)和长期记忆(跨会话持久化)。
⚡ 短期记忆
存在当前会话里,对话结束即消失。
适合:聊天机器人、问答助手。
💾 长期记忆
存到数据库,下次仍可读取。
适合:个人助手、企业知识库。
四、Chain ------ 链式调用
把多个步骤串成一条"流水线",数据从一个组件流向下一个。 注意:在新版 LangChain 中,官方推荐使用 LCEL(后面会讲)来代替旧式的 Chain 类。旧的 LLMChain、SequentialChain 等虽然还能用,但已经不推荐了。
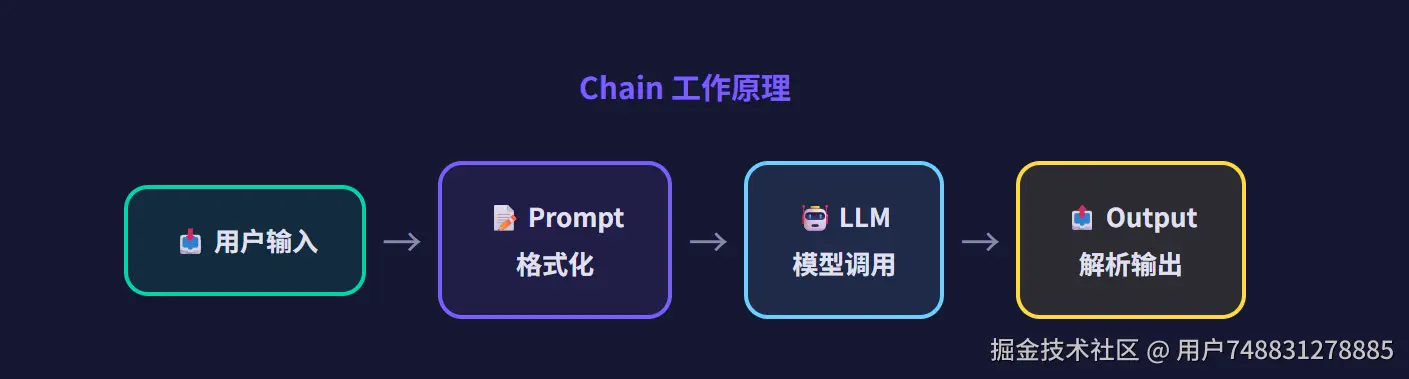
五、Agent ------ 智能体
这是 LangChain 最"酷"的部分------让 AI 自己决定该调用什么工具。
💡 Chain vs Agent 的区别
Chain 就像一条固定的流水线:第一步做什么、第二步做什么,都是你预先写死的。
Agent 就像一个有自主判断力的员工:你给他一堆工具(计算器、搜索引擎、数据库......),告诉他目标,他自己决定先用哪个工具、再用哪个,甚至会反复尝试直到完成任务。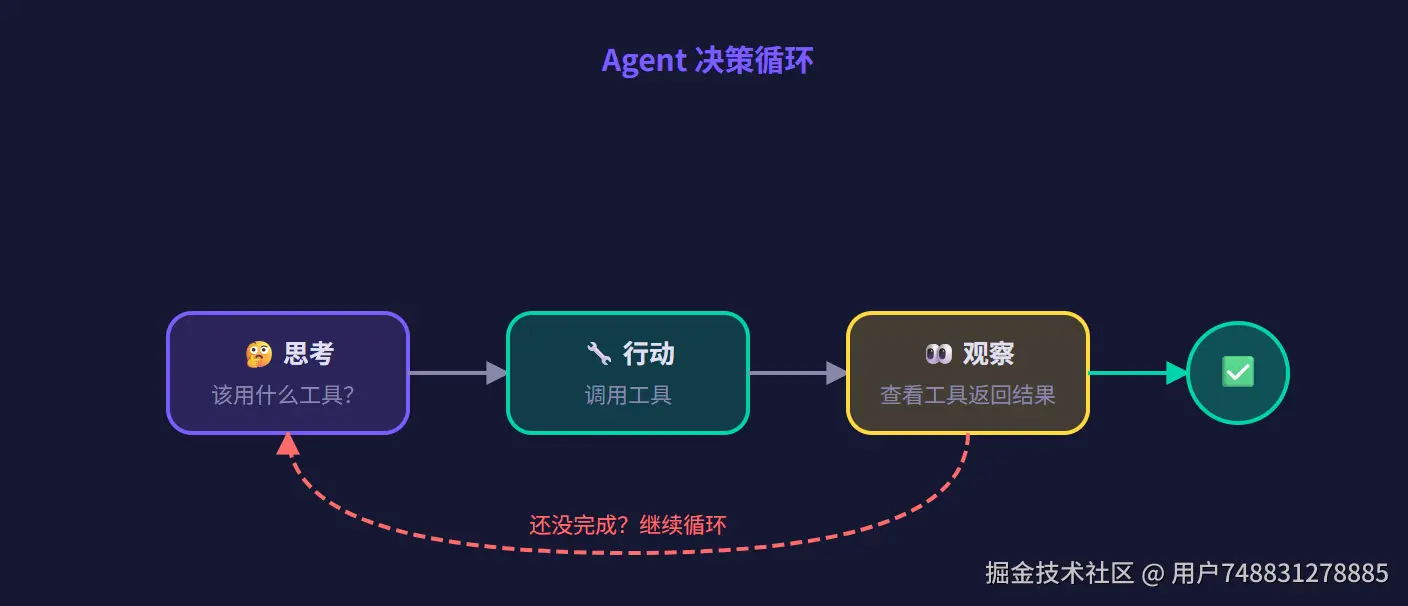
六、Tool ------ 工具
工具是 Agent 调用的外部函数,比如计算器、搜索引擎、数据库等。
diff
💡 工具的类型
- 🧮 计算工具(Calculator):Python REPL、Wolfram Alpha、数学计算器
- 🔍 搜索工具(Search):Google Search、Tavily、DuckDuckGo 等网络搜索
- 🗄 数据库工具(Database):SQL Database、MongoDB 等数据查询
- 📁 文件工具: 读写文件、处理 CSV/Excel
- 🌐 API 工具: 调用任意 REST API、WebSocket
- 🛠️ 自定义工具: 用 @tool 装饰器把任何 Python 函数变成工具
python
from langchain_core.tools import tool
@tool
def get_weather(city: str) -> str:
"""查询指定城市的天气。"""
# 这里可以调用真实的天气 API
return f"{city}今天晴,25°C"⛓️LCEL ------ LangChain 表达式语言
用管道符 | 把组件串起来 🎯 LCEL 是什么? LCEL(LangChain Expression Language)是 LangChain 推荐的"新写法",它让你用管道符 |(就像 Linux 命令行那样)把各种组件串联起来。 💡 打个比方 如果把 AI 流程想象成流水线,LCEL 就是连接各个工位的传送带。上一步的输出自动变成下一步的输入,一路流下去。
ini
# 传统写法(旧版,繁琐)
chain = LLMChain(llm=model, prompt=prompt, output_parser=parser)
# LCEL 写法(新版,优雅)
chain = prompt | model | parser
# 看到那个 | 了吗?它就是 LCEL 的核心
# prompt 的输出 → 传给 model → model 的输出 → 传给 parserLCEL 的超能力:
- 自动支持流式输出(Streaming)------ 一个字一个字蹦出来,用户体验更好
- 自动支持异步(Async)------ 高并发场景下性能更好
- 自动支持批处理(Batch)------ 一次性处理多个输入
- 自动支持重试和回退(Retry/Fallback)------ 调用失败自动重试或切换备用模型
- 与 LangSmith 无缝集成------ 每一步的输入输出都自动被记录
2. LangChain 1.0 架构详解
1.0 把原来的巨石包拆成了清晰的四层结构,每层职责单一,可以独立安装:

越往下越基础,越往上越具体。上层依赖下层,下层不知道上层存在。
1.0 三个核心新概念
create_agent --- 新 Agent 入口
一行代码创建 Agent,统一替代了过去的 AgentExecutor、initialize_agent 等零散 API。底层自动接入 LangGraph 运行时。
ini
from langchain.agents import create_agent
agent = create_agent("openai:gpt-4o", tools=[...])Middleware --- 上下文工程
在 Agent 执行前后插入自定义逻辑:注入系统提示、截断历史、过滤敏感词、记录 token 用量。告别隐式上下文污染。
ini
agent = create_agent(
"openai:gpt-4o",
tools=[search_tool, calc_tool],
middleware=[SummarizationMiddleware()],
prompt="你是一个智能助理"
)旧写法 vs 新写法对比
旧写法(0.x):
ini
from langchain.chains import LLMChain
from langchain.agents import initialize_agent, AgentType
from langchain.memory import ConversationBufferMemory
llm = ChatOpenAI(model="gpt-4")
memory = ConversationBufferMemory()
agent = initialize_agent(
tools, llm,
agent=AgentType.CHAT_CONVERSATIONAL_REACT,
memory=memory # 隐式封装,难以定制
)问题:多个入口、隐式魔法、升级必坏。
新写法(1.0):
ini
from langchain.agents import create_agent
from langchain.agents.middleware import SummarizationMiddleware
agent = create_agent(
"openai:gpt-4o-mini",
tools=[search_tool, calc_tool],
middleware=[SummarizationMiddleware()],
prompt="你是一个智能助理"
) # 清晰、显式、稳定改进:唯一入口、显式控制、底层接 LangGraph 运行时。
Chain 原生痛点
LangChain 原生的 Agent 有几个痛点:
- 控制力弱:Agent 自己决定一切,你很难插手干预
- 不好调试:Agent 在循环里跑来跑去,出了问题很难定位
- 没有状态管理:多步骤之间的数据传递很混乱
- 不支持复杂流程:比如并行执行、条件分支、人工审核、断点续跑等
Chain 的根本限制:只能直线走。遇到上述情况就撑不住了,引出了 LangGraph。
3. 为什么诞生了 LangGraph?
2023 年夏,LangChain 团队意识到 AgentExecutor 的根本性局限------它是个线性执行器,无法应对生产环境中 Agent 真正需要的能力。他们开始开发 LangGraph,2024 年初正式发布。基于图结构的 Agent 编排框架,支持循环、条件分支、人机交互,彻底革新了 Agent 的构建方式
AgentExecutor 的天花板
- 执行一崩就要从头来
- 没有断点,没有人工确认节点
- 状态全在内存里------服务器重启一切归零
- 复杂多步 Agent 根本上线不了
企业级需求无法满足
LinkedIn、Uber、J.P. Morgan 要求:Agent 决策可审计、高风险步骤需人工批准、多 Agent 并行协作。这些都超出了 Chain 能做的范围。
LangGraph 的解法
把 Agent 工作流建模成有向图:每一步是节点,流转条件是边,全局共享状态随时可持久化。灵感来自 Google 的 Pregel 分布式图计算系统。
💡 一句话理解 LangGraph
arduino
如果说 LangChain 的 Chain 是"一条直线",LangGraph 就是"一张地图"。
在地图上,你可以设计各种路线:直走、拐弯、遇到红灯等一等、岔路口选择走哪条路、甚至走回头路重新来过。这就是 Graph(图)的力量。4. LangGraph 架构原理详解
LangGraph 的核心思想:把 Agent 的执行流程建模成一张图。图由三个要素构成:
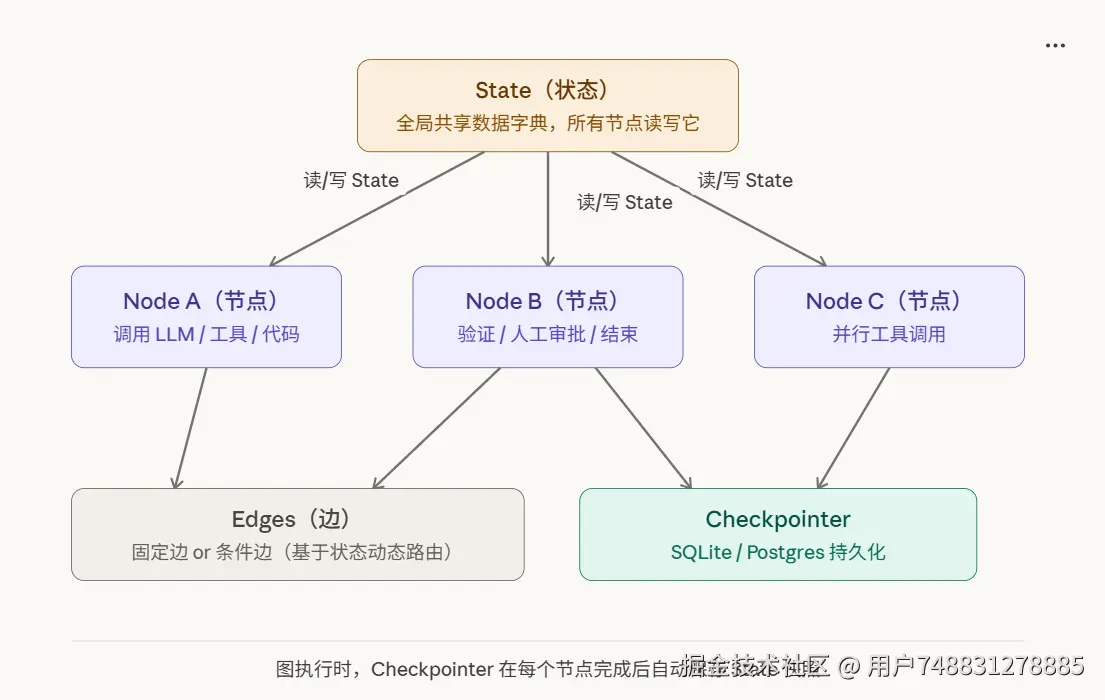
图执行时,Checkpointer 在每个节点完成后自动保存 State 快照。
三个核心概念
State 状态 ------ 信息的"背包"
TypedDict 或 Pydantic 模型。所有节点共享同一份状态,节点读取状态、执行逻辑、返回更新。Reducer 函数决定如何合并更新(覆盖 or 追加)。 State 就像一个背包,在整个工作流中随身携带。每个节点都可以从背包里拿东西、往背包里放东西。
python
# 定义状态:就像定义背包里有哪些口袋
from typing import TypedDict, Annotated
import operator
class ResearchState(TypedDict):
question: str # 用户的问题
search_results: list # 搜索结果
draft: str # 草稿
final_answer: str # 最终答案
revision_count: int # 修改次数Node 节点------ 干活的"工人"
每个 Node 就是一个函数,负责执行具体的任务。它从 State 中读取信息,处理后把结果写回 State。可以是 LLM 调用、工具调用、人工介入暂停点、自定义业务逻辑------完全透明,无隐藏逻辑。
python
# 一个节点就是一个普通函数
def search_node(state: ResearchState):
"""搜索节点:根据问题去搜索"""
question = state["question"]
results = tavily_search(question) # 调用搜索工具
return {"search_results": results}
def write_node(state: ResearchState):
"""写作节点:根据搜索结果写草稿"""
results = state["search_results"]
draft = llm.invoke(f"根据以下资料写一篇文章:{results}")
return {"draft": draft}Edge 边------ 连接的"路线
Edge 定义了节点之间怎么连接、数据怎么流动。有两种:
- ➡️普通边 (Normal Edge):无条件跳转:A 做完了一定去 B。
- 🔀条件边 (Conditional Edge):根据条件选择去哪:A 做完了,如果成功去 B,如果失败去 C。
python
# 条件边:让 AI 自己判断该走哪条路
def should_revise(state: ResearchState):
"""判断是否需要修改"""
# 修改次数达到3次,结束
if state["revision_count"] >= 3:
return "finish"
# 质量达标,结束
quality = evaluate(state["draft"])
if quality > 0.8:
return "finish"
# 质量不行,回去修改
return "revise"LangGraph 四大核心能力
| 能力 | 说明 |
|---|---|
| 💾持久化状态(Persistence) | 工作流的状态可以随时保存和恢复。就算服务器重启,也能从上次的进度继续。支持 SQLite、PostgreSQL 等存储后端。 |
| 🧑💼人工介入(Human-in-the-Loop) | interrupt_before/after 在任意节点设置暂停点,等待人类审批或修改状态,金融医疗等高风险场景必备 |
| 📡流式输出(Streaming) | 每个节点产生输出就实时推送,支持 Token 级别流式,多用户并发以 thread_id 隔离 |
| 🧵多 Agent 协作 | 不同节点代表不同 Agent,通过共享 State 协作,条件边做路由,天然支持 Supervisor 模式 |
| ⏱️断点续跑 (Checkpointing) | 自动在每个节点后保存快照(Checkpoint)。出错时可以回到任意一个快照重新开始,不用从头来过。 |
代码示例
python
# ========== 安装 ==========
# pip install langgraph langchain-openai tavily-python
from langgraph.graph import StateGraph, END
from typing import TypedDict
# ===== 第一步:定义状态 =====
class MyState(TypedDict):
question: str # 用户问题
search_results: str # 搜索结果
answer: str # 生成的回答
is_good: bool # 质量是否达标
# ===== 第二步:定义节点函数 =====
def search(state):
"""搜索节点:模拟搜索功能"""
q = state["question"]
results = f"搜索'{q}'的结果:LangGraph 是基于图的AI编排框架..."
return {"search_results": results}
def generate(state):
"""生成节点:根据搜索结果生成回答"""
answer = f"根据资料,{state['search_results']},所以答案是..."
return {"answer": answer}
def check_quality(state):
"""检查节点:检查答案质量"""
# 实际中可以用 LLM 来评估
return {"is_good": True}
# ===== 第三步:定义条件路由 =====
def route_after_check(state):
"""根据质量检查结果决定下一步"""
if state["is_good"]:
return "end"
return "search" # 不好就重新搜索
# ===== 第四步:构建图 =====
graph = StateGraph(MyState)
# 添加节点
graph.add_node("search", search)
graph.add_node("generate", generate)
graph.add_node("check", check_quality)
# 添加边
graph.set_entry_point("search") # 入口
graph.add_edge("search", "generate") # 搜索 → 生成
graph.add_edge("generate", "check") # 生成 → 检查
graph.add_conditional_edges(
"check",
route_after_check,
{
"end": END, # 通过 → 结束
"search": "search" # 不通过 → 重新搜索
}
)
# ===== 第五步:编译并运行 =====
app = graph.compile()
result = app.invoke({"question": "什么是 LangGraph?"})
print(result["answer"])5. LangChain vs LangGraph 对比
两者不是竞争关系,而是互补分层:LangChain 1.0 在内部依赖 LangGraph 运行时。
| 维度 | LangChain 1.0 | LangGraph 1.0 | 胜者 |
|---|---|---|---|
| 编程模型 | 线性 + 中间件管道,适合单轮/多轮对话、RAG、简单工具调用 | 有向图(节点 + 边 + 状态),支持循环、分支、并行、回退 | LangGraph(表达力) |
| 状态管理 | 无内置持久化,对话历史在内存中,重启丢失 | Checkpointer 一键持久化,天然断点续传、多会话隔离 | LangGraph |
| 人工介入 | 需在 Middleware 里手动实现暂停逻辑 | interrupt_before/after 原生一等公民 |
LangGraph |
| 学习曲线 | 低,create_agent() 一行代码,新手 30 分钟能跑起来 |
高,需理解图论、State 设计、Reducer、条件边路由 | LangChain |
| 多 Agent 协作 | 需要手动串联,缺少原生 Supervisor 模式 | 节点即 Agent,条件边即路由器,天然 Supervisor 架构 | LangGraph |
| 适用场景 | 聊天机器人、RAG 问答、单 Agent + 工具调用、内容生成流水线 | 多步骤自治 Agent、审批工作流、多 Agent 系统、高风险流程 | 视场景 |
6. 我该选哪个?决策指南
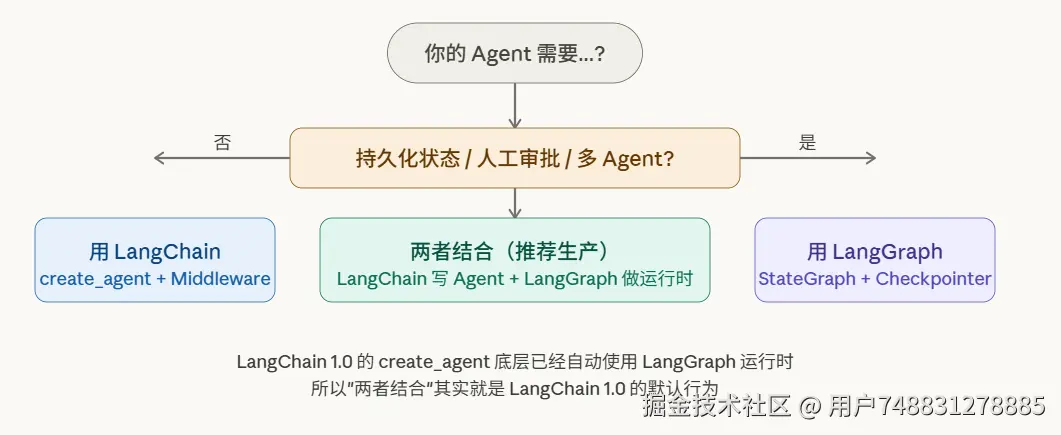
LangChain 1.0 的
create_agent底层已经自动使用 LangGraph 运行时,所以"两者结合"其实就是 LangChain 1.0 的默认行为。
一句话总结
- LangChain = 高层、快速、开箱即用的 Agent 框架。像乐高积木,快速拼出产品原型。
- LangGraph = 低层、精细、适合生产的状态机运行时。像搭电路,完全控制每一根导线的走向。
- 两者不对立------LangChain 1.0 站在 LangGraph 的肩膀上。初学者用 LangChain 快速上手,复杂场景用 LangGraph 精细控制,或者直接用 LangChain 1.0 让它自动帮你选。
一次完整的 Agent 执行流
下面再用一张图直观展示 LangGraph 的核心执行流程
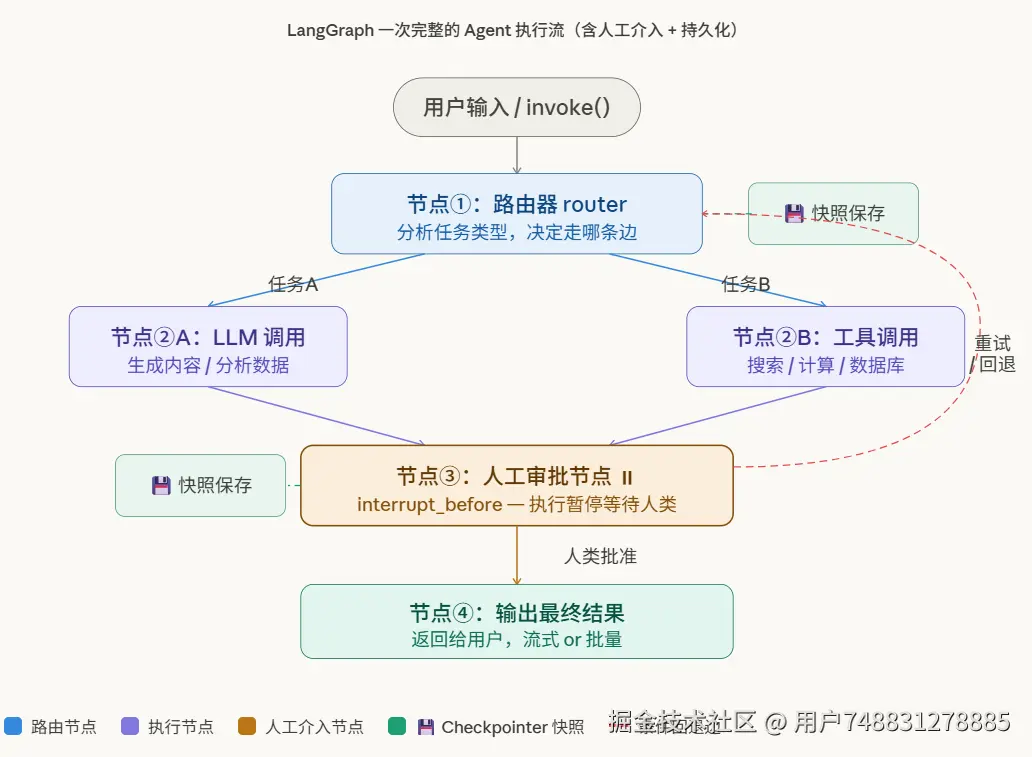
三句话记住全部内容:
- LangChain 0.x --- 野蛮生长期,功能强大但"魔法太多",依赖混乱、难以定制、AgentExecutor 不适合生产。
- LangChain 1.0 --- 大重构,四层架构清晰分离,create_agent 统一入口,Middleware 让上下文工程显式可控,底层悄悄接了 LangGraph 运行时。
- LangGraph --- 把 Agent 流程建模成图(节点 + 边 + 共享状态),天生支持持久化、断点续传、人工审批、多 Agent 并行------这是 LangChain 发现 AgentExecutor 不够用后,从零设计的生产级运行时引擎。
选哪个? 简单应用用 create_agent(LangChain 1.0),复杂审批流 / 多智能体 / 需要断点续传,就直接用 StateGraph(LangGraph)------两者同属一个生态,不是非此即彼。
参考来源:
- langchain官网:docs.langchain.com/
- langgraph文档:docs.langchain.com/oss/python/...
- langSmith:smith.langchain.com/
- LangChain Blog:blog.langchain.com/
- 官方教程:academy.langchain.com/